Airflow2.2.5任务调度工具

一、Airflow介绍
1.基本概念
Airflow是一个以编程方式创作,可进行调度和监控工作流程的开源平台。基于有向无环图(DAG),airflow可以定义一组有依赖的任务,按照依赖依次执行。airflow提供了丰富的命令行工具用于系统管控,而其web管理界面同样也可以方便的管控调度任务,并且对任务运行状态进行实时监控,方便了系统的运维和管理。
2.Airflow用途和优势
2.1.用途
Airflow的用途非常广阔,包括以下几种
- 监控自动化工作的情况(通过web UI和各个worker上记录的执行历史)
- 自动处理并传输数据
- 为机器学习或推荐系统提供一个数据管道和使用框架
2.2.优势
- 便于管理:可系统配置、作业管理、运行监控、报警、日志查看
- 内嵌感应器:假如你的工作流并不依赖于定时执行,而是依赖于例如某个文件的大小超过1GB,内嵌感应器就会派上用场
- 内嵌重试机制:如果工作流中任意一个环节出现了问题,都可以通过内嵌的重试机制,要求它重新执行
- 可追溯性强:大到整个工作流的数据流动,小到每个worker的执行历史,Airflow都会为提供来龙去脉,便于在出现问题的时候定位复现
- 自主定制性强:支持各种connnections的hook
2.3.缺点
- airflow页面不支持中文,所有选项填入中文都会报错: General Error <class ‘UnicodeEncodeError’>
- airflow的dag文件中不支持中文,会报错:UnicodeEncodeError: ‘charmap’ codec can’t encode characters in position 143-148: character maps to
- 学习成本较大,不是开箱即用,用着也那么不简单
- 中文社区和中文相关资料较少,更新较慢,出错后参考着实有些犯难,这点就不如dolphinScheduler好
4.Airflow基本结构
4.1.Airflow组件及架构
在一个可扩展的生产环境中,Airflow通常含有以下组件:
-
MetaStore:
用于保存Airflow的元数据,需要MySQL5.7+ 或 Postgresql9.6+作为元数据库的支持
-
Executor:
执行器,DAG任务的执行者,当worker的执行器为celeryExecutor时,可分布式去执行任务,这需要有对应的消息队列
-
Scheduler:
任务调度器,其将会不停轮询编译dag文件,【发送可执行的任务到消息队列中,】将dag信息和调度信息写入元数据库中,不停更新dag状态
-
Webserver:
提供web ui界面的dag操作,dag任务的启停,task的运行管理等,查看task的运行情况
组件架构关系图
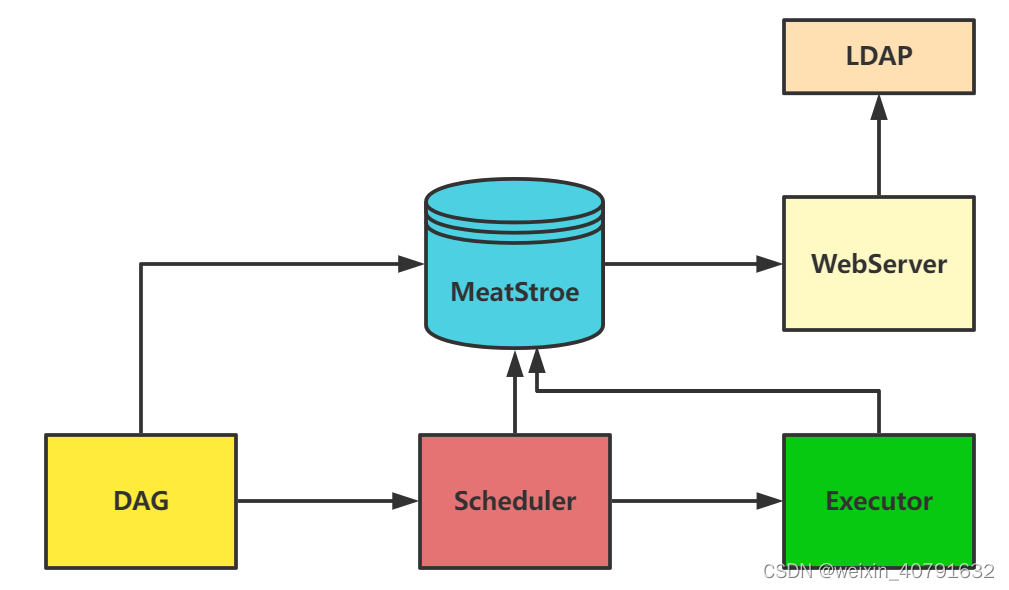
- 一个DAG就是一个工作流,里面包含了许多个task,这些DAG通过Scheduler来进行调度,然后通过Executor进行执行。
- Executor包括SequentialExecutor、LocalExecutor以及CeleryExecutor,用的较多的是LocalExecutor和CeleryExecutor。
- 元数据库存放了DAG和DAG执行相关信息,通过Webserver的UI界面可以查看这些信息。
- LDAP是轻量目录访问协议,英文全称是Lightweight Directory Access Protocol,一般都简称为LDAP
- 若airflow为分布式的时候就需要消息队列进行订阅发布多通道模式,消息队列可以是Redis或RabbitMQ,接收从scheduler端发送过来的task执行命令,等待worker端的celery去消费task
4.2.不同Executor的架构
4.2.1.基于SequentialExecutor架构原理图
SequentialExecutor表示单进程顺序执行,通常只用于测试。
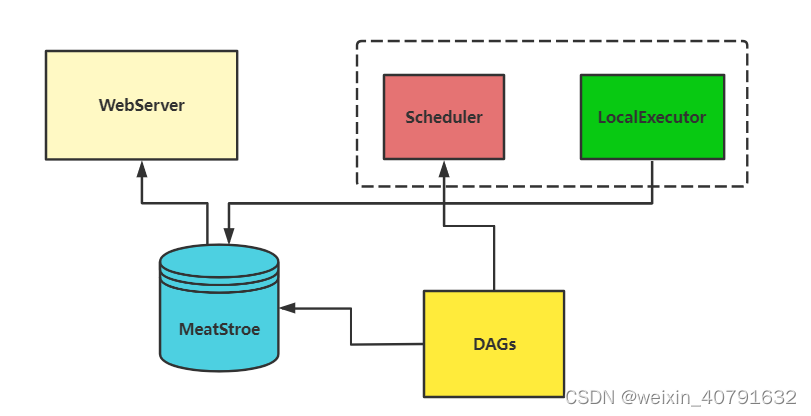
4.2.2.基于LocalExecutor架构原理图
一个dag分配到1台机器上执行。如果task不复杂同时task环境相同,可以采用这种方式,方便扩容、管理,同时没有master单点问题。
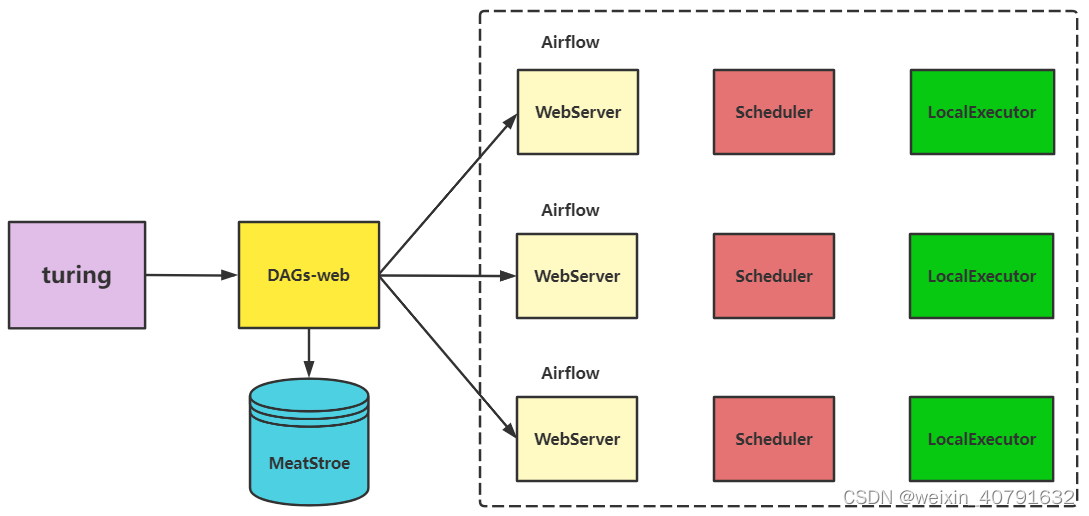
4.2.3.基于celeryExecotor的分布式架构图
- master节点webui管理dags、日志等信息
- scheduler负责调度,只支持单节点,多节点启动scheduler可能会挂掉
- worker负责执行具体dag中的task。这样不同的task可以在不同的环境中执行
- turing为外部系统
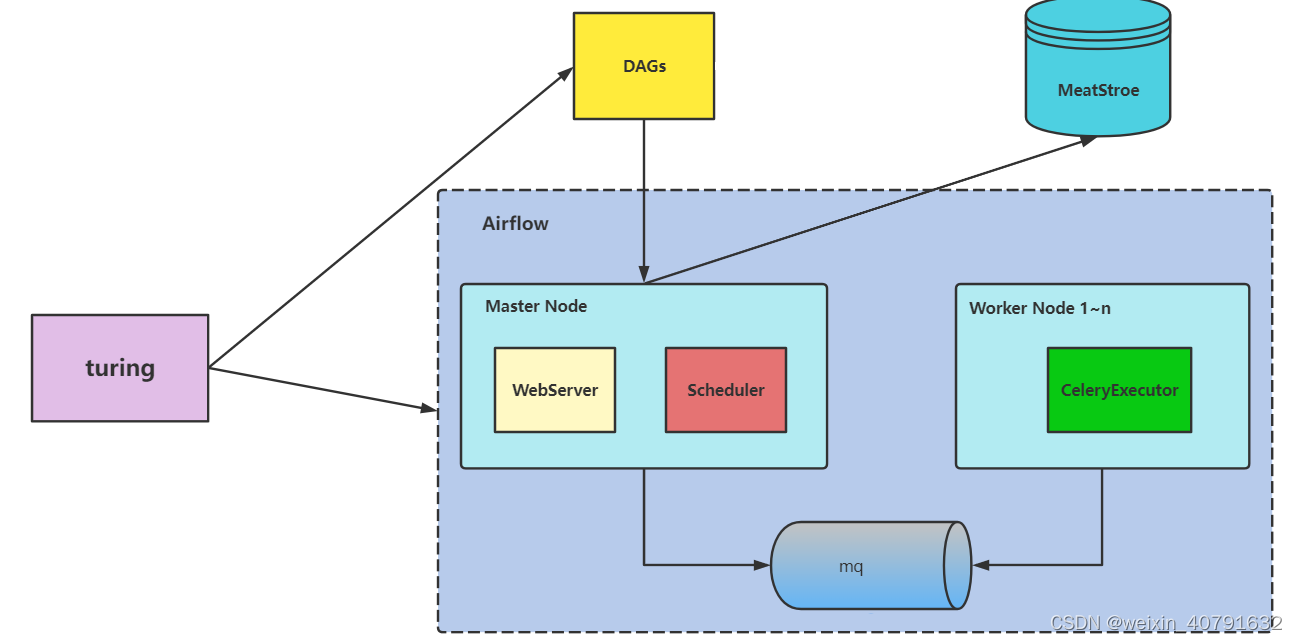
调度过程
- Scheduler读取DAG配置文件,将需要执行的Job信息发给MQ,并且在MetaStore里面注册Job信息和存储DAG文件相关信息。
- MQ里面按照环境有很多channel,Scheduler的Job会根据需要执行的环境发到相应的channel里面。
- Executor消费MQ相应的channel,进行执行,执行结果更新到metastore中,并将log暴露到Executor的某个http端口上调用,并存入数据库中。
- Web读取数据库里面的Job信息,展示Job的执行结果,并从数据库中获取log的url,展示log。
- Web上发现执行错误的Job可以点击重试,直接发送Job给MQ里,并改变数据库里面Job的状态。
4.2.Worker和celery
celery是一个分布式调度框架,其本身无队列功能,需要使用第三方组件,比如redis或者rabbitmq,支持异步定时调用。
- worker:独立的进程,任务执行单元,持续监控队列中是否有需要处理的任务
- broker:消息传输中间件,任务调度队列,接受生产者发送的消息,将任务存入队列
- 任务模块:包含异步任务和定时任务,异步任务通常在业务逻辑中被触发发往任务队列,定时任务由beat进程周期性发送
- result_backend:存储任务执行结果, 例如mysql或pg
4.3.Airflow依赖处理
Airflow的核心概念,是DAG(有向无环图),DAG由一个或多个TASK组成,而这个DAG正是解决了任务间的依赖问题。Task A 执行完成后才能执行 Task B,多个Task之间的依赖关系可以很好的用DAG表示完善。
Airflow完整的支持crontab表达式,也支持直接使用python的datatime表述时间,还可以用datatime的delta表述时间差。这样可以解决任务的时间依赖问题。
Airflow在CeleryExecuter下可以使用不同的用户启动Worker,不同Worker监听不同的Queue,这样可以解决用户权限依赖问题。Worker也可以启动在多个不同的机器上,解决机器依赖的问题。
Airflow可以为任意一个Task指定一个抽象的Pool,每个Pool可以指定一个Slot数。每当一个Task启动时,就占用一个Slot,当Slot数占满时,其余的任务就处于等待状态。这样就解决了资源依赖问题。
Airflow中有Hook机制,作用时建立一个与外部数据系统之间的连接,比如Mysql,HDFS,本地文件系统(文件系统也被认为是外部系统)等,通过拓展Hook能够接入任意的外部系统的接口进行连接,这样就解决的外部系统依赖问题。
4.4.Dag任务及其生命周期
airflow以dag为调度单位,一个dag包含一个或多个task。
dag文件定义了dag的调度详情,其中包含dag的基本信息和dag中task的基本信息。
scheduler不停地编译dag文件,根据dag文件中的crontab表达式、dag运行的历史记录、dag的开关状态,去发现哪些dag需要进行调度,发现了dag需要调度,立马新增一个dag_run实例,修改为running状态,接着不停地调度该dag中的task。
dag的生命周期分为
- none
- running
- success
- failed
正常生命周期的task分为以下几个状态
- none
- scheduled
- queued
- running
- success
异常生命周期的task分为
- up_for_retry
- failed
- shutdown
5.Airflow运行流程
以celeryExecutor为例
7.1.RUN命令运行过程
读取DAG文件生成task依赖关系,然后生成封装了airflow run的command命令,通过celery发送到多个executor端,重新执行该airflow run命令。
7.2.scheduler命令运行过程
调度器通过SchedulerJob类run方法执行整个流程,包括使用多进程处理DagDir,包括生成Dag,产生DagRun,每个DagRun下又生成多个TaskInstance,然后将任务通过Executor分发到执行节点运行。涉及到的方法有:SchedulerJob类create_dag_run创建DagRun,DagRun类verify_integrity生成TaskInstance,任务封装为command命令后发送到执行节点,执行节点通过airflow run命令执行该command,此时Job类型为LocalTaskJob
7.3.数据库表关系
dag_run表通过execution_date和task_instance关联
task_instance通过job_id和job表关联
7.4.airflow run整个流程
cli.py的run函数
关键语句dag = get_dag(args),根据dag_id获取dag实例
进入get_dag函数,关键语句dagbag = DagBag(process_subdir(args.subdir))
进入DagBag类__init__函数,关键语句self.collect_dags(dag_folder)
进入collect_dags函数,关键语句self.process_file(dag_folder, only_if_updated=only_if_updated)
进入process_file函数,关键语句
m = imp.load_source(mod_name, filepath) //filepath:DagDir目录下的一个Dag文件,假设为test.py
通过该语句test.py会被导入,语句被执行。在语句被执行时,比如test.py中有操作为:run_this_last = DummyOperator(task_id='run_this_last', dag=dag),在基类BaseOperator的__init__函数中存在语句self.dag = dag,进而调用dag的setter方法,DummyOperator的实例被添加到该dag实例中。
所有的dag被保存在一个字典中。
task = dag.get_task(task_id=args.task_id),所有task的实例已经被添加到dag实例的字典中
_run(args, dag, ti)
进入_run函数,我们查看else项针对远程执行任务的分支。关键语句
executor = GetDefaultExecutor() //获取executor的实例
executor.start()
executor.queue_task_instance(
ti,
mark_success=args.mark_success,
pickle_id=pickle_id,
ignore_all_deps=args.ignore_all_dependencies,
ignore_depends_on_past=args.ignore_depends_on_past,
ignore_task_deps=args.ignore_dependencies,
ignore_ti_state=args.force,
pool=args.pool)
executor.heartbeat() //将命令队列中的命令拿出来调用executor的execute_async方法发送过去,然后同步等结果
executor.end()
进入queue_task_instance函数,此处是CeleryExcutor类的实例,基类BaseExecutor
command = task_instance.command(
local=True,
mark_success=mark_success,
ignore_all_deps=ignore_all_deps,
ignore_depends_on_past=ignore_depends_on_past,
ignore_task_deps=ignore_task_deps,
ignore_ti_state=ignore_ti_state,
pool=pool,
pickle_id=pickle_id,
cfg_path=cfg_path)
self.queue_command( //将command放入队列
task_instance,
command,
priority=task_instance.task.priority_weight_total,
queue=task_instance.task.queue)
再次进入command函数,我们发现它依次调用了command_as_list、TaskInstance.generate_command
iso = execution_date.isoformat()
cmd = ["airflow", "run", str(dag_id), str(task_id), str(iso)]
cmd.extend(["--mark_success"]) if mark_success else None
cmd.extend(["--pickle", str(pickle_id)]) if pickle_id else None
cmd.extend(["--job_id", str(job_id)]) if job_id else None
cmd.extend(["-A"]) if ignore_all_deps else None
cmd.extend(["-i"]) if ignore_task_deps else None
cmd.extend(["-I"]) if ignore_depends_on_past else None
cmd.extend(["--force"]) if ignore_ti_state else None
cmd.extend(["--local"]) if local else None
cmd.extend(["--pool", pool]) if pool else None
cmd.extend(["--raw"]) if raw else None
cmd.extend(["-sd", file_path]) if file_path else None
cmd.extend(["--cfg_path", cfg_path]) if cfg_path else None
return cmd
结果就是:服务端发送一个airflow run命令到executor,然后通过Celery执行shell命令,命令内容就是上面的cmd结果。然后executor端会重新执行一遍airflow run命令。
整个流程结束
二、Airflow安装配置
1.安装Airflow2.x-单机
目标式安装Airflow2.x,而Airflow2.x的版本请依赖于python3高阶版本,但服务器中默认一般都是python2.7
2.1.配置airflow用户
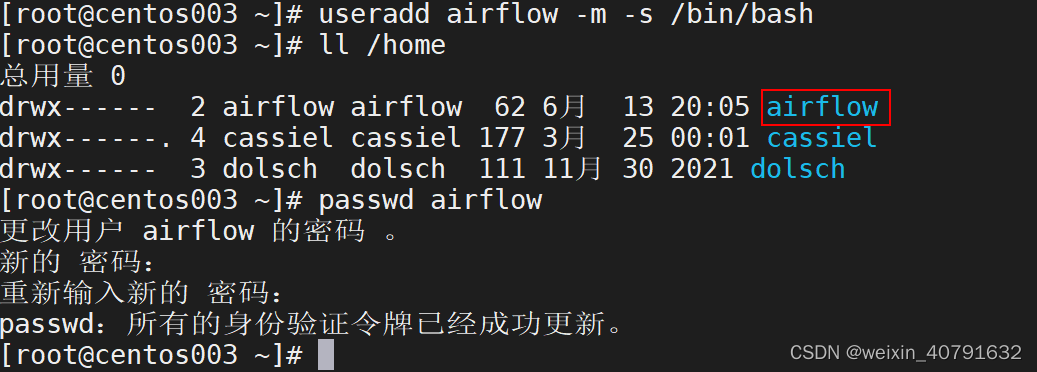
在root用户下操作
useradd airflow -m -s /bin/bash
passwd airflow
### 密码是:Aflow@123~
2.2.安装python3虚拟环境
切换到airflow用户
su - airflow
通过部署miniconda,创建虚拟python3环境就可以满足airflow的要求。
下载miniconda版本
yum install -y wget
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
安装 minicopnda
#直接在服务器中安装下载的miniconda,安装目录默认是家目录
sh Miniconda3-latest-Linux-x86_64.sh
#按 enter 键继续,有一步需要输入自定义目录,不输入,则默认家目录,这里输入的为/appcom/modules/miniconda
配置conda环境变量
vi ~/.bashrc
# 在文件末尾添加
export MINICONDA_HOME=/appcom/modules/miniconda
export PATH=$PATH:$MINICONDA_HOME/bin
source ~/.bashrc #刷新配置
配置conda 镜像源
conda config --set show_channel_urls yes
vi ~/.condarc
##用下面内容覆盖
channels:
- https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- defaults
show_channel_urls: true
安装jupyter (miniconda3默认没有jupyter ,完整版的Anaconda3有jupyter,所以根据版本忽略)
pip3 install jupyter
配置jupyter
""" 第一步 生成配置文件 """
jupyter notebook --generate-config --allow-root //配置文件生成在:/home/airflow/.jupyter/jupyter_notebook_config.py
""" 第二步 生成密码 """
jupyter notebook password //密码设置的是 123456 自己设置 文件生成在 /home/airflow/.jupyter/jupyter_notebook_config.json
""" 第三步 编辑/home/airflow/.jupyter/jupyter_notebook_config.py文件 """
vim /home/airflow/.jupyter/jupyter_notebook_config.py
c.NotebookApp.ip = '192.168.244.161'
c.NotebookApp.open_browser = False
c.NotebookApp.port = 8888
c.NotebookApp.password = 'argon2:$argon2id$v=19$m=10240,t=10,p=8$Z4FzhnirRGrPwhwg2oWa9A$b5KuKRMr9l+zyK2I0W6KCA'
//该密码在上面有生成
2.3.安装mysql
选择了mysql8.0.16,安装步骤:略
配置mysql
--创建airflow数据库 并指定字符集
create database if not exists airflow default charset utf8 collate utf8_general_ci;
--创建用户,8.0默认密码插件是caching_sha2_password,需要改成mysql_native_password,否则初始化数据库报错
CREATE USER 'airflow'@'%' IDENTIFIED WITH mysql_native_password BY 'airflow';
--给用户授权
grant all privileges on airflow.* to 'airflow'@'%';
--但是你airflwo db init 初始化的情况下会出现问题:
/* raise Exception("Global variable explicit_defaults_for_timestamp needs to be on (1) for mysql")
Exception: Global variable explicit_defaults_for_timestamp needs to be on (1) for mysq
mysq的全局变量explicit_defaults_for_timestamp需要为on (1)
*/
--所以这里你就需要将 explicit_defaults_for_timestamp设置下:
set global explicit_defaults_for_timestamp =1;
2.4.创建airflow项目
由于上面我们已经安装好Miniconda,所以现在可以创建任意python版本的项目
新建AirFlow项目 。使用python3.7.5
# 新建项目
conda create -n airflow python==3.7.5
#激活创建的airflow项目中
source activate airflow
查看是否创建好,如果python版本变成了3.7.5说明创建好了

2.5.安装airflow依赖包
airflow有很多依赖包,根据需求选择对应的依赖包, 更多依赖包请参考官网
| 包名 | 安装命令 | 说明 |
|---|---|---|
| all | pip install apache-airflow[all] | 所有 Airflow 功能,全家桶 |
| all_dbs | pip install apache-airflow[all_dbs] | 所有集成的数据库 |
| async | pip install apache-airflow[async] | Gunicorn 的异步 worker classes |
| celery | pip install apache-airflow[celery] | CeleryExecutor |
| cloudant | pip install apache-airflow[cloudant] | Cloudant hook |
| crypto | pip install apache-airflow[crypto] | 加密元数据 db 中的连接密码 |
| devel | pip install apache-airflow[devel] | 最小开发工具要求 |
| devel_hadoop | pip install apache-airflow[devel_hadoop] | Airflow + Hadoop stack 的依赖 |
| druid | pip install apache-airflow[druid] | Druid.io 相关的 operators 和 hooks |
| gcp_api | pip install apache-airflow[gcp_api] | Google 云平台 hooks 和 operators(使用google-api-python-client ) |
| github_enterprise | pip install apache-airflow[github_enterprise] | Github 企业版身份认证 |
| google_auth | pip install apache-airflow[google_auth] | Google 身份认证 |
| hdfs | pip install apache-airflow[hdfs] | HDFS hooks 和 operators |
| hive | pip install apache-airflow[hive] | 所有 Hive 相关的 operators |
| jdbc | pip install apache-airflow[jdbc] | JDBC hooks 和 operators |
| kerberos | pip install apache-airflow[kerberos] | Kerberos 集成 Kerberized Hadoop |
| kubernetes | pip install apache-airflow[kubernetes] | Kubernetes Executor 以及 operator |
| ldap | pip install apache-airflow[ldap] | 用户的 LDAP 身份验证 |
| mssql | pip install apache-airflow[mssql] | Microsoft SQL Server operators 和 hook,作为 Airflow 后端支持 |
| mysql | pip install apache-airflow[mysql] | MySQL operators 和 hook,支持作为 Airflow 后端。 MySQL 服务器的版本必须是 5.6.4+。 确切的版本上限取决于mysqlclient包的版本。 例如, mysqlclient 1.3.12 只能与 MySQL 服务器 5.6.4 到 5.7 一起使用。 |
| password | pip install apache-airflow[password] | 用户密码验证 |
| postgres | pip install apache-airflow[postgres] | Postgres operators 和 hook,作为 Airflow 后端支持 |
| qds | pip install apache-airflow[qds] | 启用 QDS(Qubole 数据服务)支持 |
| rabbitmq | pip install apache-airflow[rabbitmq] | rabbitmq 作为 Celery 后端支持 |
| redis | pip install apache-airflow[redis] | Redis hooks 和 sensors |
| s3 | pip install apache-airflow[s3] | S3KeySensor,S3PrefixSensor |
| samba | pip install apache-airflow[samba] | Hive2SambaOperator |
| slack | pip install apache-airflow[slack] | SlackAPIPostOperator |
| ssh | pip install apache-airflow[ssh] | SSH hooks 及 Operator |
| vertica | pip install apache-airflow[vertica] | 做为 Airflow 后端的 Vertica hook 支持 |
因为是单机版,安装一个mysql依赖包即可
## 生成的目录默认在/home/airflow/airflow,若想改变家目录位置,需要在安装aiflow操作之前设置AIRFLOW_HOME,如下命令
export AIRFLOW_HOME=/appcom/modules/airflow # 需要放到~/.bashrc中末尾,source ~/.bashrc刷新
pip3 install "apache-airflow[mysql]~=2.2.5"
pip3 install "apache-airflow[celery]~=2.2.5"
pip3 install "apache-airflow[password]~=2.2.5"
pip3 install "apache-airflow[redis]~=2.2.5"
2.6.安装airflow
pip3 install "apache-airflow~=2.2.5"
生成airflow映射目录
airflow -h #确定~/.bashrc中有export AIRFLOW_HOME=.......,否则目录价出现在/home/aiflow中
2.7.配置airflow
进入airflow目录中,修改airflow.cfg配置
vim /home/airflow/airflow/airflow.cfg
[core]
# 存放dag的目录,需要使用绝对路径
dags_folder = /appcom/modules/airflow/dags
# 时区设置
default_timezone = Asia/Shanghai
# worker执行器的类型
# SequentialExecutor(默认,顺序执行): 一次只能执行一个任务,只使用于测试
# LocalExecutor(本地执行): 多进程本地执行,它用python的多进程库达到多任务并发的
# CeleryExecutor(远程分布式执行): 使用celery作为执行器,可以多服务器跑任务,分布式可扩展,多用于生产
# DaskExecutor(任务执行):则用于动态任务调度,常用于数据分析
# KubernetesExector(k8s执行)
executor = LocalExecutor
# 数据库连接设置
# mysql://用户名:密码@主机名:端口号/数据库
sql_alchemy_conn = mysql://airflow:airflow@192.168.31.120:3306/airflow
# 数据库编码方式
sql_engine_encoding = utf-8
# 是否与SqlAlchemy库进行数据交互
sql_alchemy_pool_enabled = True
# 最大数据连接池初始化连接数
sql_alchemy_pool_size = 5
# 控制每个Airflow worker可以一次同时运行task实例的数量,默认是32
parallelism = 32
# 用来控制每个dag运行过程中最大可同时运行的task实例数,若DAG中没有设置concurrency,则使用默认值
dag_concurrency = 16
# 创建新的DAG时,是否暂停
dags_are_paused_at_creation = True
# 同一时间最大运行dag的数量,默认为16,
max_active_runs_per_dag = 1
# 任务失败重试次数
max_db_retries = 3
# 是否加载示例dags,默认为True, miniconda3/envs/airflow/lib/python3.7/site-packages/airflow/example_dags
load_examples = False
# airflow插件存放位置
plugins_folder = /appcom/modules/airflow/plugins
# 任务强行呗杀掉后,清理时间 默认60s
killed_task_cleanup_time = 120
# 默认pool任务插槽数量为128个,
default_pool_task_slot_count = 128
[logging]
# airflowbu本地日志存储目录
base_log_folder = /appcom/modules/airflow/logs
# 若想设置远程陌路存储,需要设置为True
remote_logging = False
# 需要在connections中设置hook,并将conn_id填写在这里
remote_log_conn_id =
# S3 需要以 "s3://"开头
# Cloudwatch 需要以 "cloudwatch://"开头
# GCS 需要以 "gs://"开头
# Stackdriver 需要以 "stackdriver://"开头
remote_base_log_folder =
# 日志级别
logging_level = INFO
fab_logging_level = WARNING
[api]
# 如果想让rest api有授权使用basic_auth,默认是deny_all(拒绝所有请求)
# auth_backend = airflow.api.auth.backend.deny_all
auth_backend = airflow.api.auth.backend.basic_auth
[webserver]
base_url = http://192.168.31.122:8089
# web ui页面使用的时区
default_ui_timezone = Asia/Shanghai
# web的IP地址
web_server_host = 192.168.31.122
# 运行web服务端口号
web_server_port = 8089
# 超时时间,默认120S
web_server_master_timeout = 300
web_server_worker_timeout = 300
# 表示开启4个gunicorn worker(进程)处理web请求,默认4
workers = 4
# 刷新时间,默认6000s
worker_refresh_interval = 30
# 设置web端Configuration不显示配置信息
expose_config = False
# 加载Airflow UI界面的时间
default_dag_run_display_number = 15
[email]
# 任务重试时是否发送邮件提醒
default_email_on_retry = False
# 任务失败时是否发送邮件提醒
default_email_on_failure = True
[smtp]
# 邮箱smtp的host, 默认localhost
smtp_host = smtp.163.com
# 加密通讯。默认true
smtp_starttls = True
smtp_ssl = False
# Example: smtp_user = airflow
smtp_user = 你的邮箱
# Example: smtp_password = airflow
smtp_password =你邮箱设置里smtp密码
# smtp端口,默认25,若smtp_ssl=true,则为465
smtp_port = 25
smtp_mail_from = 你的邮箱
smtp_timeout = 30
smtp_retry_limit = 5
[scheduler]
# 调度程序尝试触发新任务的时间(秒)
scheduler_heartbeat_sec = 60
# 检测新dag的时间(秒),默认30s
min_file_process_interval = 10
# 是否使用catchup功能, 即是否执行自上次execute_date以来所有未执行的DAG Run, 另外定义每个DAG对象可传递catchup参数进行覆盖
catchup_by_default = True
# 调度程序应多久(以秒为单位)检查一次孤立的任务和调度对象
orphaned_tasks_check_interval = 300.0
child_process_log_directory = /appcom/modules/airflow/logs/scheduler
创建目录
cd /appcom/modules/airflow
mkdir dags plugins
2.8.初始化airflow数据库
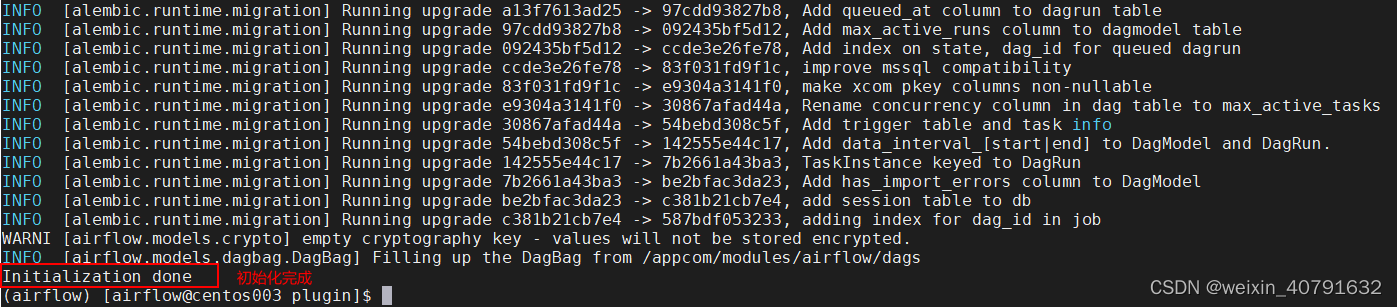
airflow db init
2.9.创建airflow账户
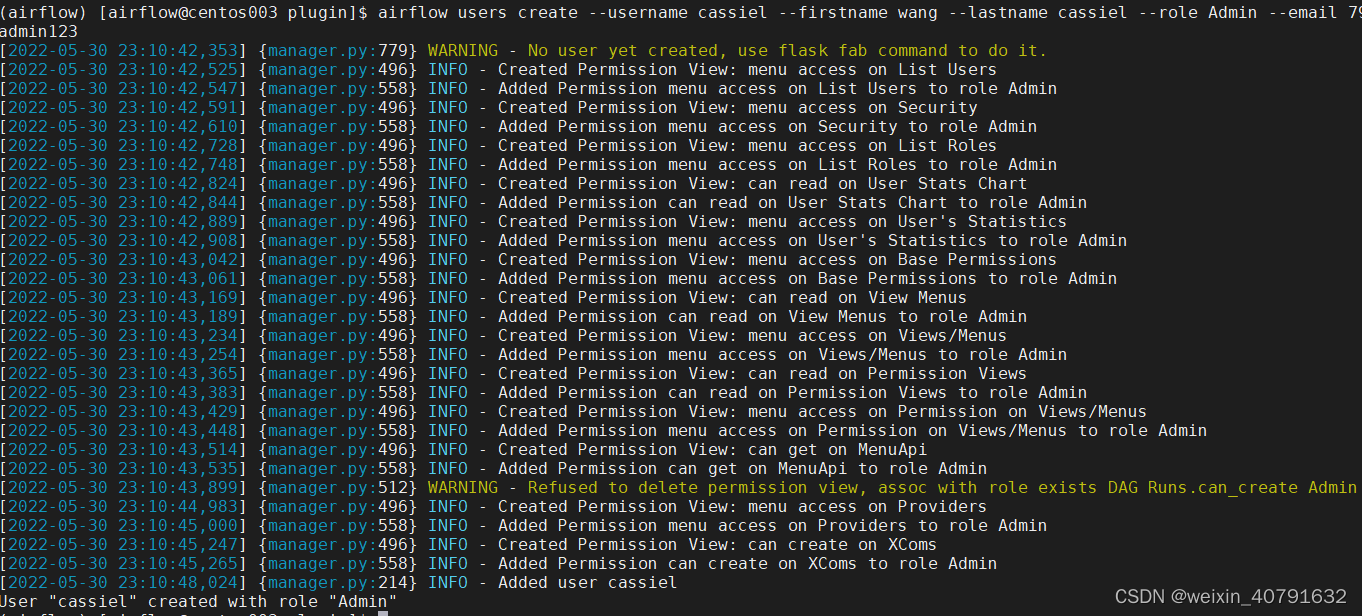
## airflow users create --username 账号 --firstname 姓 --lastname 名字 --role Admin --email asd@xxx.com --password 密码
airflow users create --username cassiel --firstname wang --lastname cassiel --role Admin --email 798320308@qq.com --password admin123
2.10.启动airflow
# 启动 web 服务器,后台运行加 -D
airflow webserver --port 8089 -D
# 启动定时器,后台运行加 -D
airflow scheduler -D
2.安装Airflow2.x-分布式
组件:miniconda(python3.7) + airflow2.2.5 + celery4.4.7(airflow含有) + flower0.9.7(airflow含有) + redis6.0.6 + mysql8.0.16
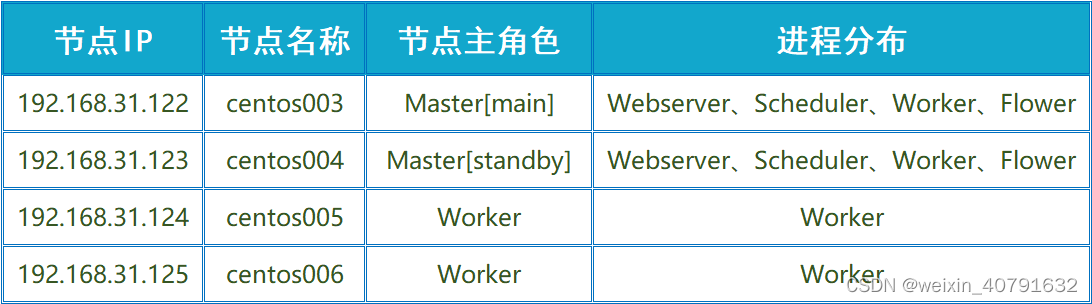
3.1.节点规划
正常情况下node1和node2都不应该安装Worker节点,这里给他们加了Worker节点,免得资源浪费
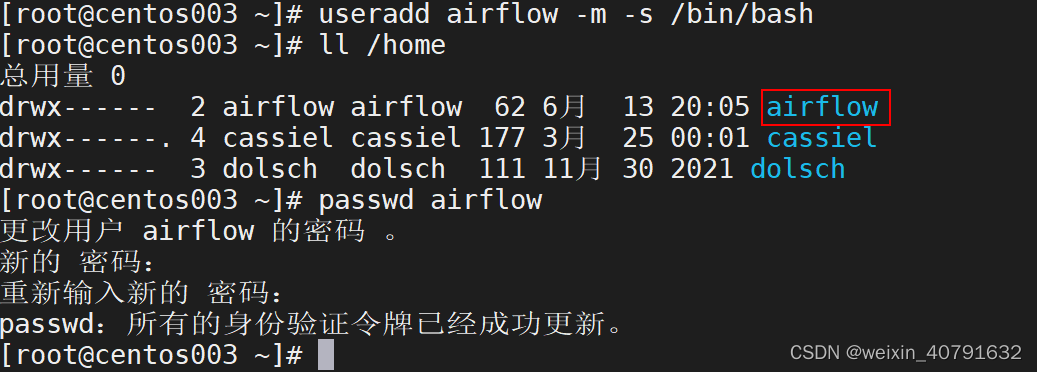
3.2.配置airflow用户
在每个节点的root用户下创建airflow用户,这个用户主要用来操作airflow的
useradd airflow -m -s /bin/bash
passwd airflow
### 密码是:自定义设置密码,需要输入两次
#切换airflow时
su - airflow # 在root用户下不需要输入密码,在其他用户下需要密码
3.2.安装python3虚拟环境
在所有节点上都安装python3的虚拟资源,linux的各个厂商版本的系统里集成的python都是v.2x,不适用于airflow2.x以上版本,所以安装虚拟环境承载python3.x。
创建miniconda的安装目录和airflow的home目录
[root@centos003 ~]# mkdir /appcom/modules/miniconda
[root@centos003 ~]# chown airflow:airflow /appcom/modules/virtual_envs
[root@centos003 ~]# mkdir /appcom/modules/airflow
[root@centos003 ~]# chown airflow:airflow /appcom/modules/airflow
所有节点都切换到airflow用户
su - airflow
通过部署miniconda,创建虚拟python3环境就可以满足airflow的要求。
所有节点都下载miniconda版本
yum install -y wget
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
所有节点都安装 minicopnda
#直接在服务器中安装下载的miniconda,安装目录默认是家目录
sh Miniconda3-latest-Linux-x86_64.sh
#按 enter键继续,有一步需要输入自定义目录,不输入,则默认家目录
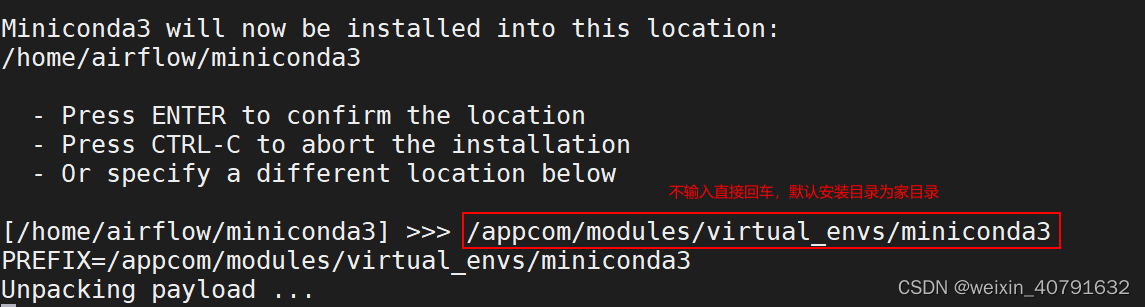
所有节点都配置miniconda环境变量
vi ~/.bashrc
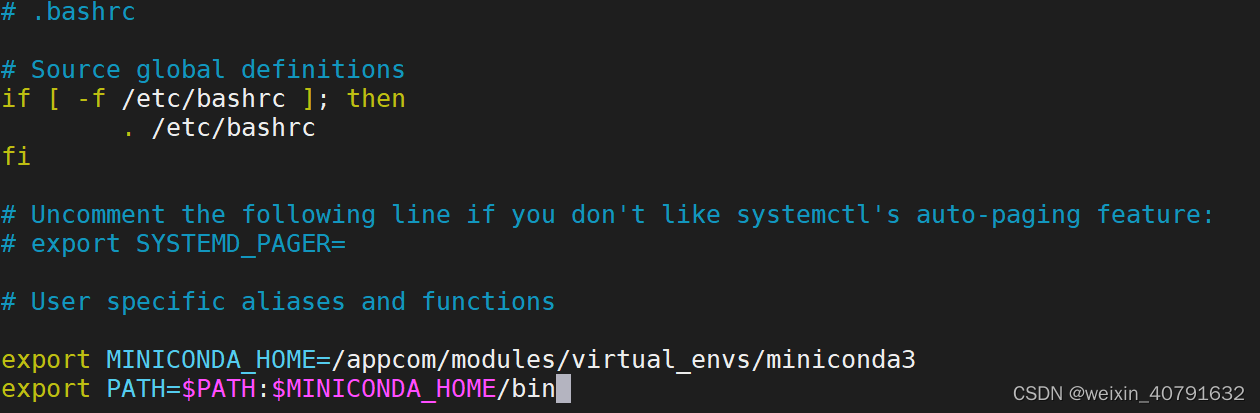
# 在文件末尾添加
export MINICONDA_HOME=/appcom/modules/virtual_envs/miniconda3
export PATH=$PATH:$MINICONDA_HOME/bin
source ~/.bashrc #刷新配置
# 查看是否起效果
cond # 然后按tab键,若补全为conda即可
配置conda 镜像源
conda config --set show_channel_urls yes
vi ~/.condarc
##覆盖下面内容
channels:
- https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- defaults
show_channel_urls: true
安装jupyter (miniconda3默认没有jupyter ,完整版的Anaconda3有jupyter,所以根据版本忽略)
pip3 install jupyter
配置jupyter
""" 第一步 生成配置文件 """
jupyter notebook --generate-config --allow-root //配置文件生成在:/home/airflow/.jupyter/jupyter_notebook_config.py
""" 第二步 生成密码 """
jupyter notebook password //密码设置的是 123456 自己设置 文件生成在 /home/airflow/.jupyter/jupyter_notebook_config.json
""" 第三步 编辑/home/airflow/.jupyter/jupyter_notebook_config.py文件 """
vim /home/airflow/.jupyter/jupyter_notebook_config.py
c.NotebookApp.ip = '192.168.31.122'
c.NotebookApp.open_browser = False
c.NotebookApp.port = 8888
c.NotebookApp.password = 'argon2:$argon2id$v=19$m=10240,t=10,p=8$Z4FzhnirRGrPwhwg2oWa9A$b5KuKRMr9l+zyK2I0W6KCA' //该密码在上面有生成
3.4.安装mysql/redis/celery
3.4.1.安装mysql
mysql可以不安装在当前的airflow集群中,也可以安装在当前集群中,这里选择安装远程安装。
选择了mysql8.0.16,安装步骤:略
配置mysql
--创建airflow数据库 并指定字符集
create database if not exists airflow default charset utf8 collate utf8_general_ci;
--创建用户,8.0默认密码插件是caching_sha2_password,需要改成mysql_native_password,否则初始化数据库报错
CREATE USER 'airflow'@'%' IDENTIFIED WITH mysql_native_password BY 'airflow';
--给用户授权
grant all privileges on airflow.* to 'airflow'@'%';
--但是你airflwo db init 初始化的情况下会出现问题:
/* raise Exception("Global variable explicit_defaults_for_timestamp needs to be on (1) for mysql")
Exception: Global variable explicit_defaults_for_timestamp needs to be on (1) for mysq
mysq的全局变量explicit_defaults_for_timestamp需要为on (1)
*/
--所以这里你就需要将 explicit_defaults_for_timestamp设置下:
set global explicit_defaults_for_timestamp =1;
--为了避免出现sqlalchemy.exc.OperationalError: (MySQLdb._exceptions.OperationalError) (2006, 'MySQL server has gone away')
--需要查看这几个参数的值是否如下,若小于如下值,应改成如下值,若大于如下值,则不用在意。
max_allowed_packet = 500MB
wait_timeout = 288000
interactive_timeout = 288000
3.4.2.安装celery
celery是一个分布式调度框架,其本身无队列功能,需要使用第三方异步消息队列的组件,比如redis或者rabbitmq,这里选择了redis
airflow内置了celery4.4.7和flower0.7.9
3.4.3.安装redis
选择了Redis6.0.6,安装步骤:略,配置步骤:略
3.5.创建airflow项目
由于上面我们已经安装好Miniconda,所以现在可以创建任意python版本的项目
所有节点上都新建AirFlow项目 。使用python3.7.5
# 新建一个airflow项目
conda create -n airflow python==3.7.5
#激活创建的airflow项目
source activate airflow
查看是否创建好,如果python版本变成了3.7.5说明创建好了,如果还是2.7.5则时未创建好

3.6.安装airflow依赖包
airflow有很多依赖包,根据需求选择对应的依赖包, 更多依赖包请参考官网
| 包名 | 安装命令 | 说明 |
|---|---|---|
| all | pip install apache-airflow[all] | 所有 Airflow 功能,全家桶 |
| all_dbs | pip install apache-airflow[all_dbs] | 所有集成的数据库 |
| async | pip install apache-airflow[async] | Gunicorn 的异步 worker classes |
| celery | pip install apache-airflow[celery] | CeleryExecutor |
| cloudant | pip install apache-airflow[cloudant] | Cloudant hook |
| crypto | pip install apache-airflow[crypto] | 加密元数据 db 中的连接密码 |
| devel | pip install apache-airflow[devel] | 最小开发工具要求 |
| devel_hadoop | pip install apache-airflow[devel_hadoop] | Airflow + Hadoop stack 的依赖 |
| druid | pip install apache-airflow[druid] | Druid.io 相关的 operators 和 hooks |
| gcp_api | pip install apache-airflow[gcp_api] | Google 云平台 hooks 和 operators(使用google-api-python-client ) |
| github_enterprise | pip install apache-airflow[github_enterprise] | Github 企业版身份认证 |
| google_auth | pip install apache-airflow[google_auth] | Google 身份认证 |
| hdfs | pip install apache-airflow[hdfs] | HDFS hooks 和 operators |
| hive | pip install apache-airflow[hive] | 所有 Hive 相关的 operators |
| jdbc | pip install apache-airflow[jdbc] | JDBC hooks 和 operators |
| kerberos | pip install apache-airflow[kerberos] | Kerberos 集成 Kerberized Hadoop |
| kubernetes | pip install apache-airflow[kubernetes] | Kubernetes Executor 以及 operator |
| ldap | pip install apache-airflow[ldap] | 用户的 LDAP 身份验证 |
| mssql | pip install apache-airflow[mssql] | Microsoft SQL Server operators 和 hook,作为 Airflow 后端支持 |
| mysql | pip install apache-airflow[mysql] | MySQL operators 和 hook,支持作为 Airflow 后端。 MySQL 服务器的版本必须是 5.6.4+。 确切的版本上限取决于mysqlclient包的版本。 例如, mysqlclient 1.3.12 只能与 MySQL 服务器 5.6.4 到 5.7 一起使用。 |
| password | pip install apache-airflow[password] | 用户密码验证 |
| postgres | pip install apache-airflow[postgres] | Postgres operators 和 hook,作为 Airflow 后端支持 |
| qds | pip install apache-airflow[qds] | 启用 QDS(Qubole 数据服务)支持 |
| rabbitmq | pip install apache-airflow[rabbitmq] | rabbitmq 作为 Celery 后端支持 |
| redis | pip install apache-airflow[redis] | Redis hooks 和 sensors |
| s3 | pip install apache-airflow[s3] | S3KeySensor,S3PrefixSensor |
| samba | pip install apache-airflow[samba] | Hive2SambaOperator |
| slack | pip install apache-airflow[slack] | SlackAPIPostOperator |
| ssh | pip install apache-airflow[ssh] | SSH hooks 及 Operator |
| vertica | pip install apache-airflow[vertica] | 做为 Airflow 后端的 Vertica hook 支持 |
分布式需要用到的依赖有mysql、celery、redis,后面使用api需要密码认证
在所有节点上都按照如下进行安装
## 生成的目录默认在/home/airflow/airflow,若想改变家目录位置,需要在安装aiflow操作之前设置AIRFLOW_HOME,如下命令
export AIRFLOW_HOME=/appcom/modules/airflow # 需要放到~/.bashrc中末尾,source ~/.bashrc刷新
pip3 install "apache-airflow[mysql]~=2.2.5"
pip3 install pymysql
pip3 install "apache-airflow[celery]~=2.2.5"
pip3 install "apache-airflow[password]~=2.2.5"
pip3 install "apache-airflow[redis]~=2.2.5"
3.7安装airflow
pip3 install "apache-airflow~=2.2.5"
生成airflow映射目录
airflow -h
3.8.配置airflow
进入主节点airflow目录中,修改airflow.cfg配置,最后将主节点的配置分发到其他节覆盖掉原来的配置
vim /appcom/modules/airflow/airflow.cfg
[core]
# 存放dag的目录,需要使用绝对路径
dags_folder = /appcom/modules/airflow/dags
# 时区设置
default_timezone = Asia/Shanghai
# worker执行器的类型
# SequentialExecutor(默认,顺序执行): 一次只能执行一个任务,只使用于测试
# LocalExecutor(本地执行): 多进程本地执行,它用python的多进程库达到多任务并发的
# CeleryExecutor(远程分布式执行): 使用celery作为执行器,可以多服务器跑任务,分布式可扩展,多用于生产
# DaskExecutor(任务执行):则用于动态任务调度,常用于数据分析
# KubernetesExector(k8s执行)
executor = CeleryExecutor
# 数据库连接设置
# mysql://用户名:密码@主机名:端口号/数据库
sql_alchemy_conn = mysql://airflow:airflow@192.168.31.120:3306/airflow
# 数据库编码方式
sql_engine_encoding = utf-8
# 是否与SqlAlchemy库进行数据交互
sql_alchemy_pool_enabled = True
# 最大数据连接池初始化连接数
sql_alchemy_pool_size = 5
# 控制每个Airflow worker可以一次同时运行task实例的数量,默认是32
parallelism = 32
# 用来控制每个dag运行过程中最大可同时运行的task实例数,若DAG中没有设置concurrency,则使用默认值
dag_concurrency = 16
# 创建新的DAG时,是否暂停
dags_are_paused_at_creation = True
# 同一时间最大运行dag的数量,默认为16,
max_active_runs_per_dag = 1
# 任务失败重试次数
max_db_retries = 3
# 是否加载示例dags,默认为True, airflow/lib/python3.7/site-packages/airflow/example_dags
load_examples = True
# airflow插件存放位置
plugins_folder = /appcom/modules/airflow/plugins
# 任务强行呗杀掉后,清理时间 默认60s
killed_task_cleanup_time = 120
# 默认pool任务插槽数量为128个,
default_pool_task_slot_count = 128
[logging]
# airflowbu本地日志存储目录
base_log_folder = /appcom/modules/airflow/logs
# 若想设置远程陌路存储,需要设置为True
remote_logging = False
# 需要在connections中设置hook,并将conn_id填写在这里
remote_log_conn_id =
# S3 需要以 "s3://"开头
# Cloudwatch 需要以 "cloudwatch://"开头
# GCS 需要以 "gs://"开头
# Stackdriver 需要以 "stackdriver://"开头
remote_base_log_folder =
# 日志级别
logging_level = INFO
fab_logging_level = WARNING
[api]
# 如果想让rest api有授权使用Password_auth,默认是deny_all(拒绝所有请求)
# auth_backend = airflow.api.auth.backend.deny_all
auth_backend = airflow.api.auth.backend.basic_auth
[webserver]
base_url = http://192.168.31.122:8089
# web ui页面使用的时区
default_ui_timezone = Asia/Shanghai
# web的IP地址
web_server_host = 192.168.31.122
# 运行web服务端口号
web_server_port = 8089
# 超时时间,默认120S
web_server_master_timeout = 300
web_server_worker_timeout = 300
# 表示开启4个gunicorn worker(进程)处理web请求,默认4
workers = 4
# 刷新时间,默认6000s
worker_refresh_interval = 30
# 设置web端Configuration不显示配置信息
expose_config = False
# 加载Airflow UI界面的时间
default_dag_run_display_number = 15
[email]
# 任务重试时是否发送邮件提醒
default_email_on_retry = False
# 任务失败时是否发送邮件提醒
default_email_on_failure = True
[smtp]
# 邮箱smtp的host, 默认localhost
smtp_host = smtp.163.com
# 加密通讯。默认true
smtp_starttls = True
smtp_ssl = False
# Example: smtp_user = airflow
smtp_user = 你的邮箱
# Example: smtp_password = airflow
smtp_password =你邮箱设置里16位授权码
# smtp端口,默认25,若smtp_ssl=true,则为465
smtp_port = 25
smtp_mail_from = 你的邮箱
smtp_timeout = 30
smtp_retry_limit = 5
[celery] #用于生产,测试环境不需要
# 配置celery的broker_url(存储要执行的命令然后celery的worker去消费)
# redis没设置密码
# broker_url = redis://192.168.31.121:6379/0
# redis设置了密码,redis一般默认user是default
broker_url = redis://default:airflow@192.168.31.121:6379/0
# 配置celery的result_backend(存储任务执行状态)、 也可以用redis存储
# result_backend = db+postgresql://postgres:airflow@postgres/airflow
result_backend = db+mysql://airflow:airflow@192.168.31.120:3306/airflow
[scheduler]
# 调度程序尝试触发新任务的时间(秒)
scheduler_heartbeat_sec = 60
# 检测新dag的时间(秒),默认30s
min_file_process_interval = 10
# 是否使用catchup功能, 即是否执行自上次execute_date以来所有未执行的DAG Run, 另外定义每个DAG对象可传递catchup参数进行覆盖
catchup_by_default = True
# 调度程序应多久(以秒为单位)检查一次孤立的任务和调度对象
orphaned_tasks_check_interval = 300.0
child_process_log_directory = /appcom/modules/airflow/logs/scheduler
创建目录
# 创建DAG存储的目录和插件存储的目录
cd /appcom/modules/airflow
mkdir dags plugins
3.9.初始化airflow数据库
airflow db init
3.10.创建web账户
3.10.1.创建admin用户
## airflow users create --username 账号 --firstname 姓 --lastname 名字 --role Admin --email asd@xxx.com --password 密码
airflow users create --username cassiel --firstname wang --lastname cassiel --role Admin --email 798320308@qq.com --password admin123
3.10.2.创建view用户
## airflow users create --username 账号 --firstname 姓 --lastname 名字 --role Admin --email asd@xxx.com --password 密码
airflow users create --username xingyue --firstname wang --lastname xingyue --role viewer --email 1136496916@qq.com --password view123
3.11.配置airflow高可用
3.11.1.下载failover组件
登录https://github.com/teamclairvoyant/airflow-scheduler-failover-controller下载 airflow-scheduler-failover-controller 第三方组件,将下载好的zip包上传到master主节点下
# 在root用户下执行
mkdir /appcom/modules/airflow_failover
chmod 755 /appcom/modules/airflow_failover
chown airflow:airflow /appcom/modules/airflow_failover
# 在airflow用户下执行
## 上传airflow-scheduler-failover-controller-master.zip到~目录下
mv ~/airflow-scheduler-failover-controller-master.zip /appcom/
cd /appcom/modules/airflow_failover
unzip -o airflow-scheduler-failover-controller-master.zip # 如果没有unzip命令,运行安装:yum -y install unzip
3.11.2.pip安装failover依赖
(airflow) [airflow@centos003 airflow_failover]# cd airflow-scheduler-failover-controller-master
(airflow) [airflow@centos003 airflow-scheduler-failover-controller-master]# pip install -e .
3.11.3.初始化failover
(airflow) [airflow@centos003 airflow-scheduler-failover-controller-master]# ./bin/scheduler_failover_controller init
Adding Scheduler Failover configs to Airflow config file...
Finished adding Scheduler Failover configs to Airflow config file.
Finished Initializing Configurations to allow Scheduler Failover Controller to run. Please update the airflow.cfg with your desired configurations.
注意:初始化airflow时,会向airflow.cfg配置中追加配置,因此需要先安装 airflow
3.11.4.修改airflow.cfg
修改master主节点的配置,修改完毕,需要分发到其他的节点进行配置覆盖。
[scheduler_failover]
# 配置airflow Master节点,两节点需要ssl免密配置,准备linux系统时就可以进行了
scheduler_nodes_in_cluster = centos003,centos004
# 特别注意,需要去掉一个分号,不然后期自动重启Scheduler不能正常启动
airflow_scheduler_start_command = export AIRFLOW_HOME=/appcom/modules/airflow;nohup airflow scheduler >> ${AIRFLOW_HOM}/logs/scheduler.logs &
配置完成后,可以通过如下命令进行验证master
(airflow) [airflow@centos003 airflow-scheduler-failover-controller-master]# ./bin/scheduler_failover_controller test_connection
Testing Connection for host 'centos003'
(True, ['Connection Succeeded', ''])
Testing Connection for host 'centos004'
(True, ['Connection Succeededn'])
3.12.启动airflow
master主节点上启动:
# 启动 web 服务器,后台运行加 -D
airflow webserver --port 8089 -D
# 启动定时器,后台运行加 -D
airflow scheduler -D
# 当设置airflow的executors设置为CeleryExecutor时才需要开启worker守护进程。
##如提示addres already use ,则查看 worker_log_server_port = 8793 是否被占用,如是则修改为 8974 等
airflow celery worker -D # 后台运行worker
## airflow celery worker -c 1 -D # 后台运行celery worker并指定任务并发数为1,配置中默认是32
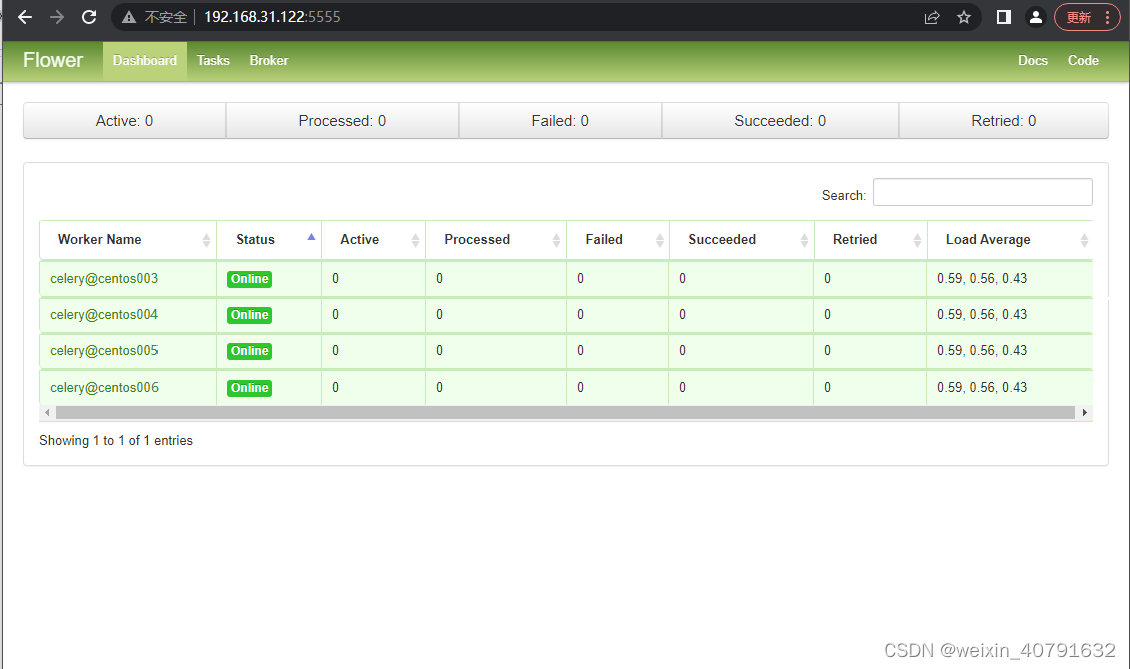
# 后台运行flower,用于是监控celery worker,可以启动,可以不启动
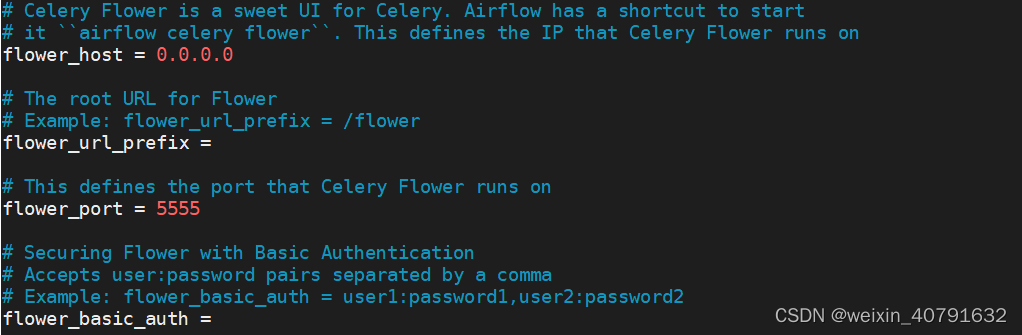
airflow celery flower -D
如果启动了flower,既可以通过flower来监控worker,flower相关配置在airflow.cfg中有配置
master备用节点启动:
# 启动 web 服务器,后台运行加 -D
airflow webserver --port 8089 -D
# 后台运行flower,用于是监控celery worker,可以启动,可以不启动
airflow celery flower -D
worker节点启动:
# 当设置airflow的executors设置为CeleryExecutor时才需要开启worker守护进程。
airflow celery worker -D # 后台运行worker
## airflow celery worker -c 1 -D # 后台运行celery worker并指定任务并发数为1,配置中默认是32
最后在master主节点启动failover:
mkdir /appcom/modules/airflow/logs/scheduler_failover
chmod 755 /appcom/modules/airflow/logs/scheduler_failover
nohup ./bin/scheduler_failover_controller start > /appcom/modules/airflow/logs/scheduler_failover/scheduler_failover_run.log &
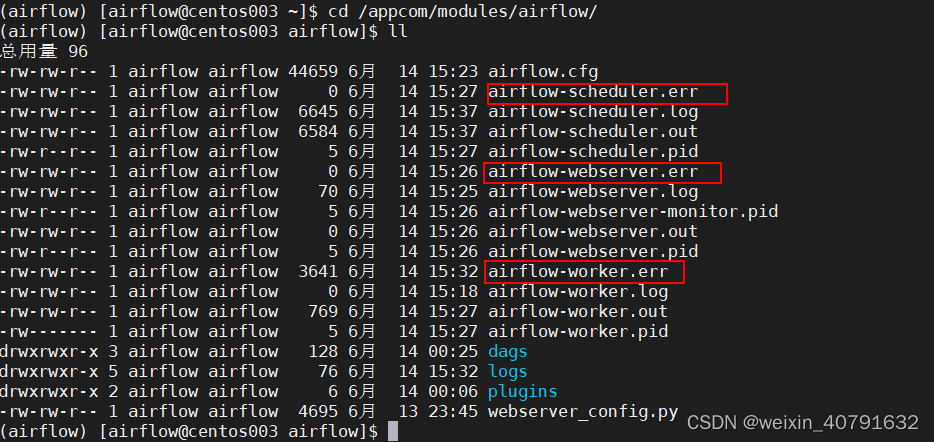
启动报错
查看各个节点的err日志,有无报错信息
3.13.airflow的HA功能说明
当在webserver的master主节点的scheduler进程挂了之后,查看sheduler_failover日志,会发现scheduler_failover_controller将会尝试再次启动scheduler进程。如果启动不起来,则会转到master备份节点上启动scheduler进程,这时候可以通过备份节点访问UI。
三、Airflow页面介绍
1.登录airflow
http://192.168.31.122:8089/login
首页
看到上方黄色的字,描述的是未启动scheduler,需要去启动scheduler
2.页面菜单-DAGs
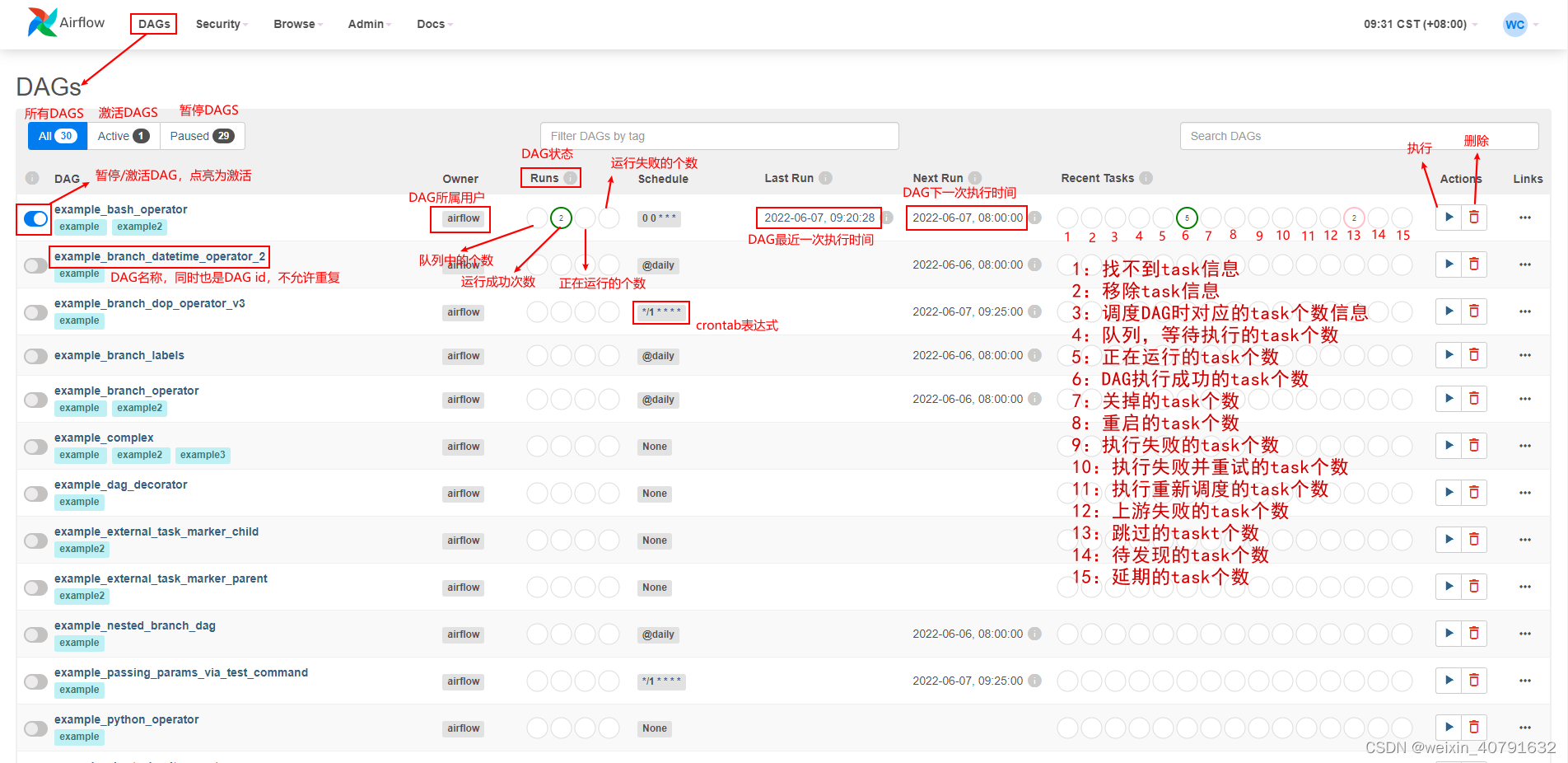
以上Runs和Recent Tasks两个列种的圈圈代表着DAG执行的某种状态及个数,鼠标放在圈圈上则可以看到对应的提示说明,点击links则会出现如下菜单

点击每个dag的名称(dag id)可以进入到对应dag的Graph view视图,可以查看当前DAG任务执行的顺序图。
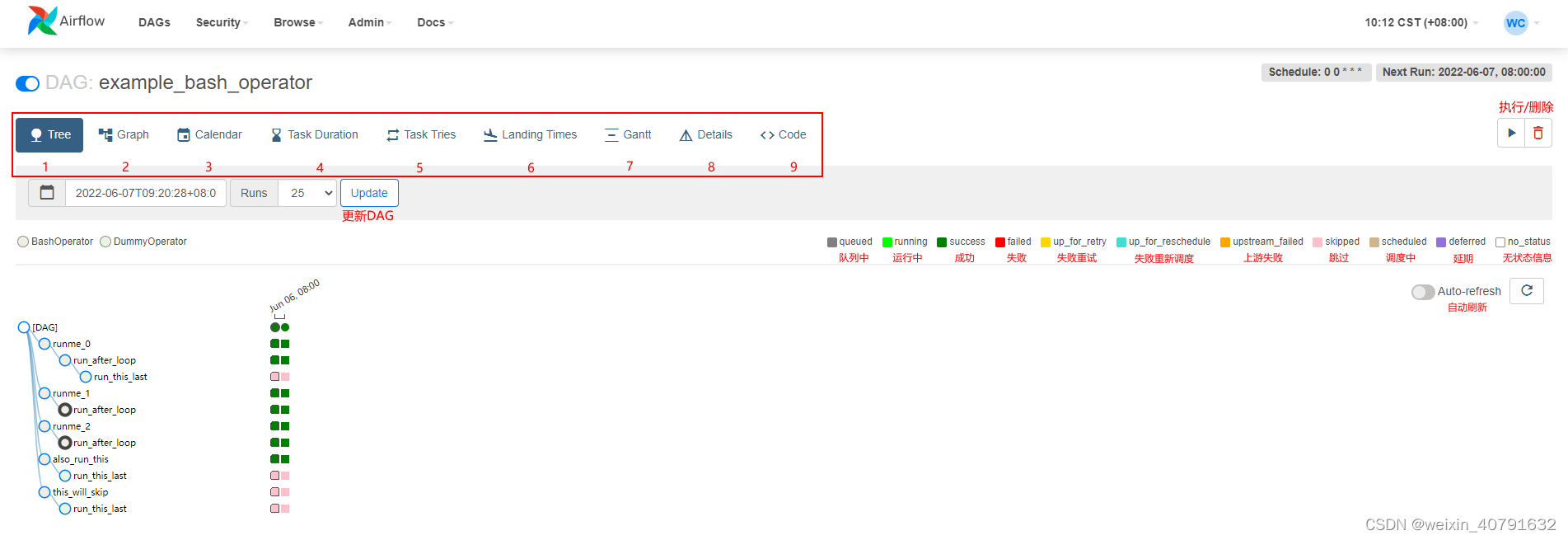
- Tree: DAG的树状结构,用来查看每个分支每次执行的情况
- Graph: DAG的有向无环图传递依赖图
- Calender: 日期视图,查看当前每年每月每日任务的执行情况
- Task Duration: 查看任务每天执行的时长,对比分析任务耗时情况,方便后续优化
- Task Tries: 展示每个任务重试次数
- Landing Times: 用来查看任务延迟状况
- Grant: 甘特图,用来展示DAG中每个task的执行时间分布
- Details: 查看当前任务属性详情
- Code: 显示当前DAG的python代码
2.1.Tree
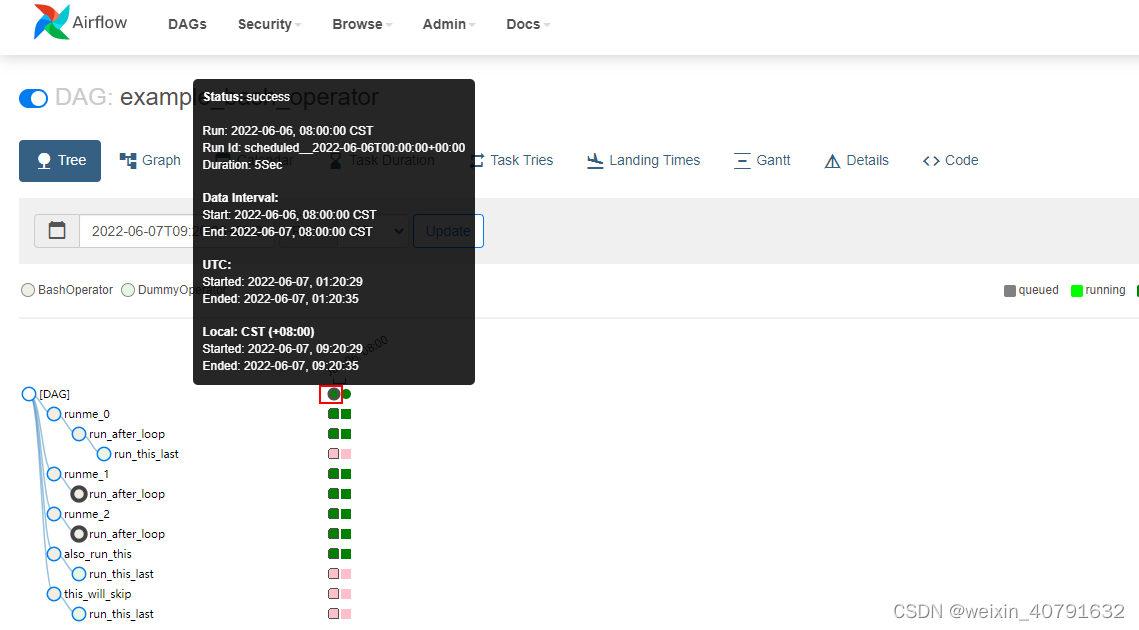
将DAG以树的形式表示,如果执行过程中有延迟也可以通过这个界面查看问题出现在哪个步骤,在生产环境下,经常通过这个页面查看每个任务执行情况。
通过Tree可以看到每天的每个task执行的情况,有黑框为周期正常调度,没有黑框则是手动调度触发的。
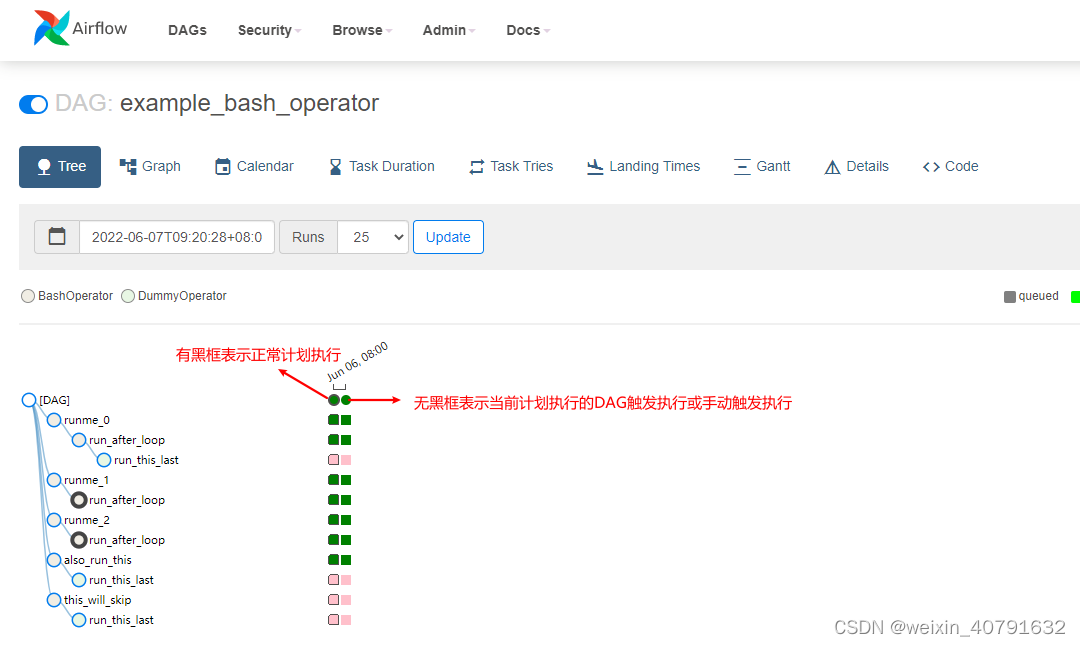
每个有颜色的“小块”都可以看到task详情
2.2.Graph
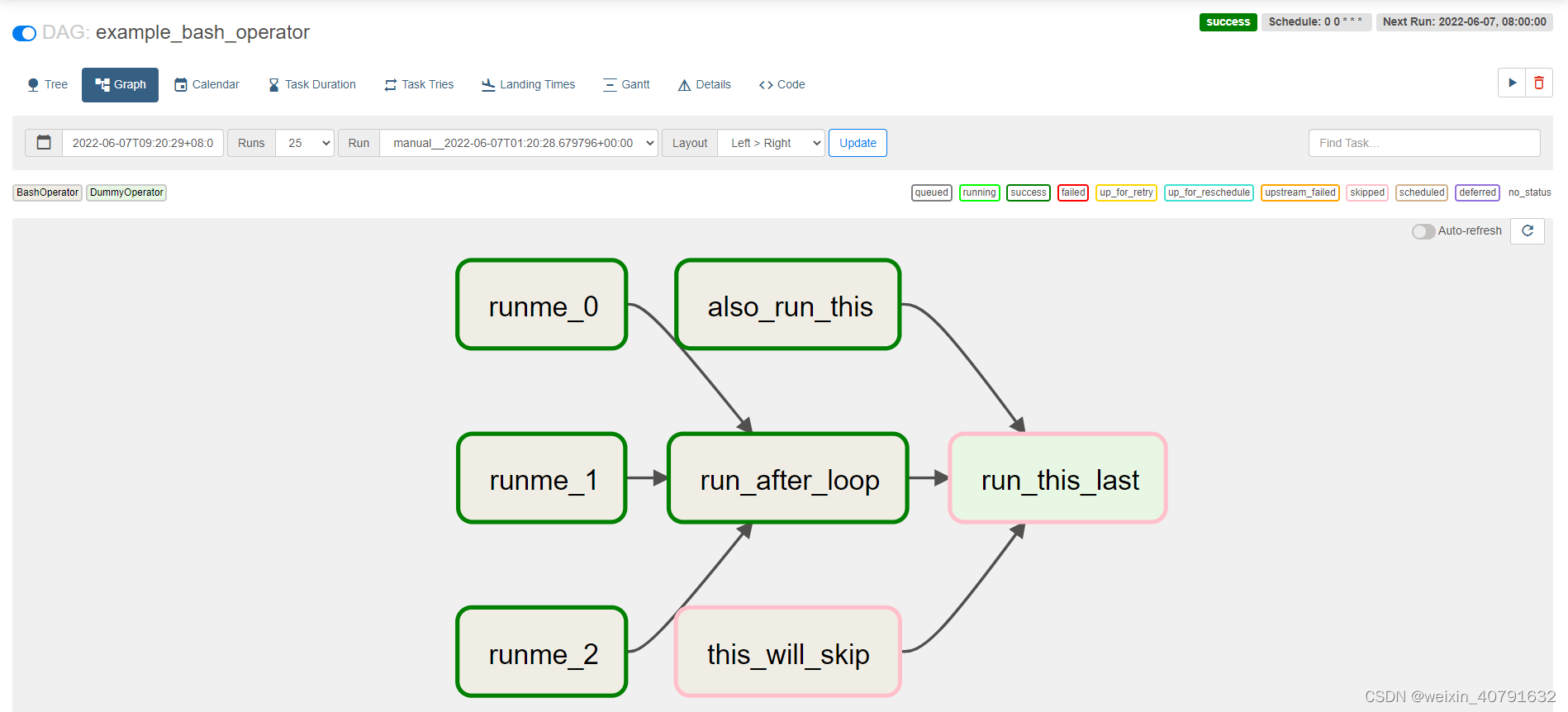
此页面以图形方式呈现DAG有向无环图,对于理解DAG执行非常有帮助,不同颜色代表task执行的不同状态。
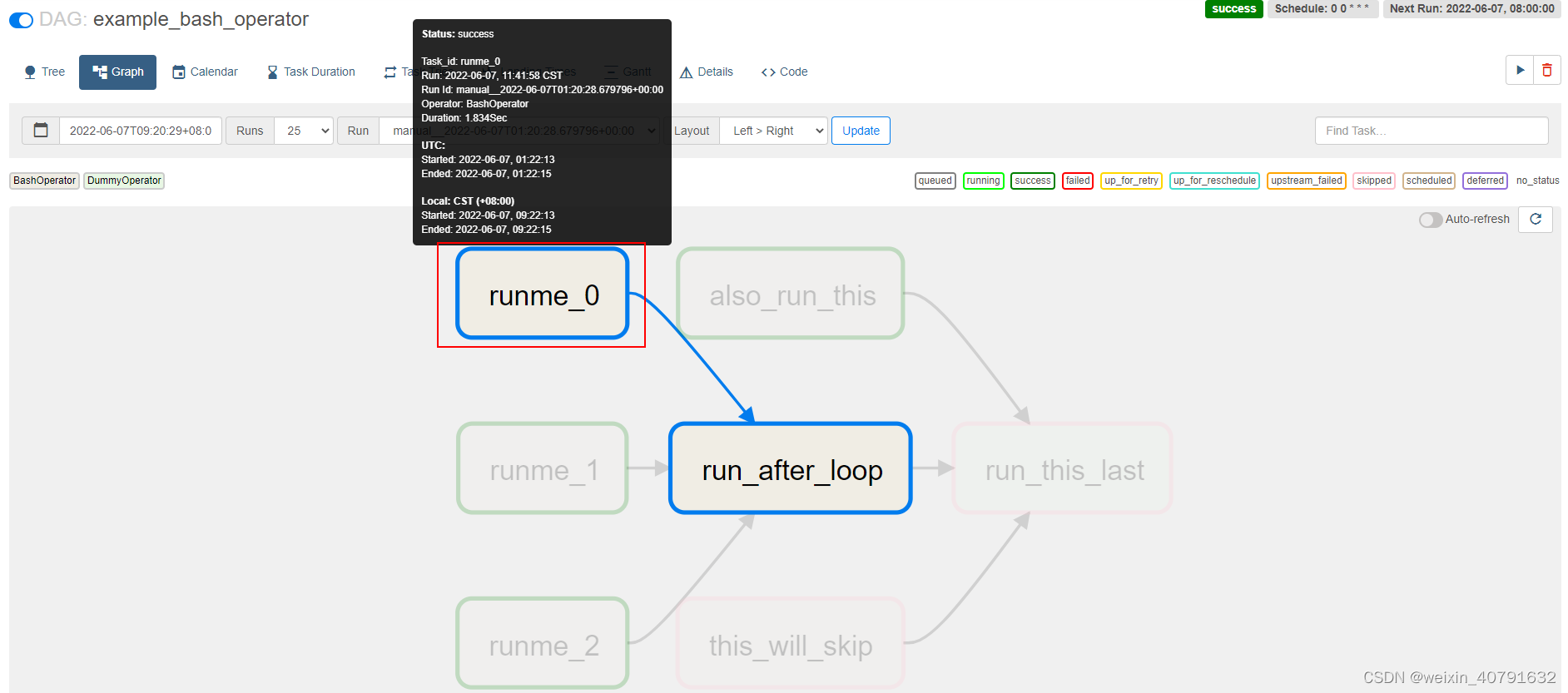
点击任何一个任务都可以看到任务详情
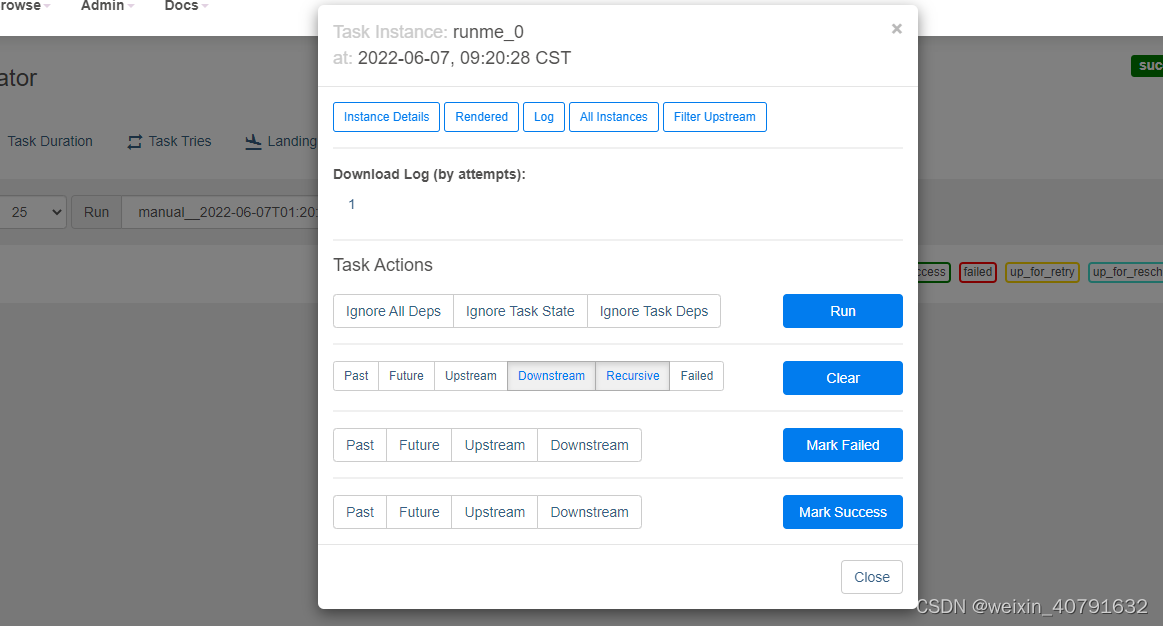
查看日志
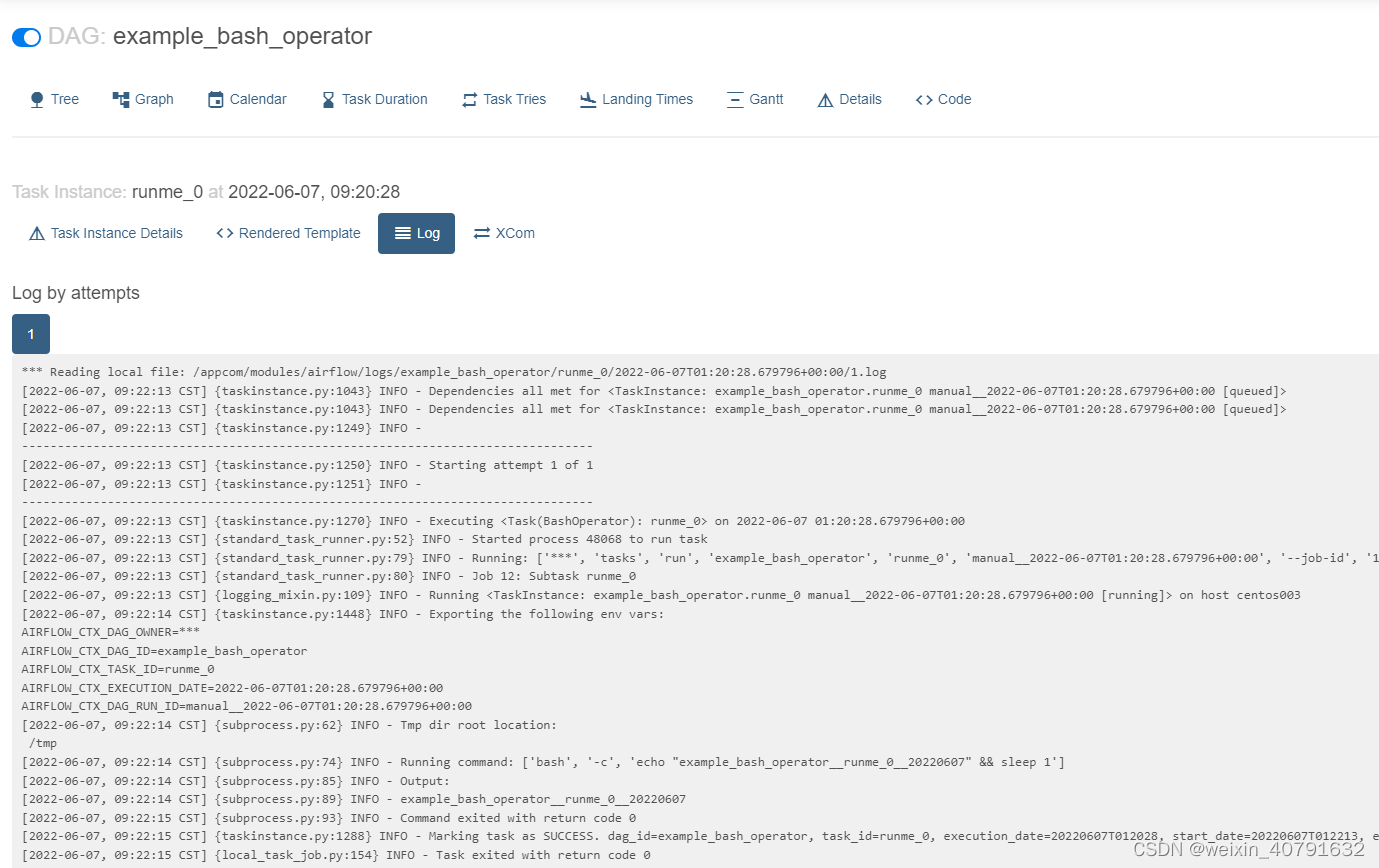
2.3.Calender
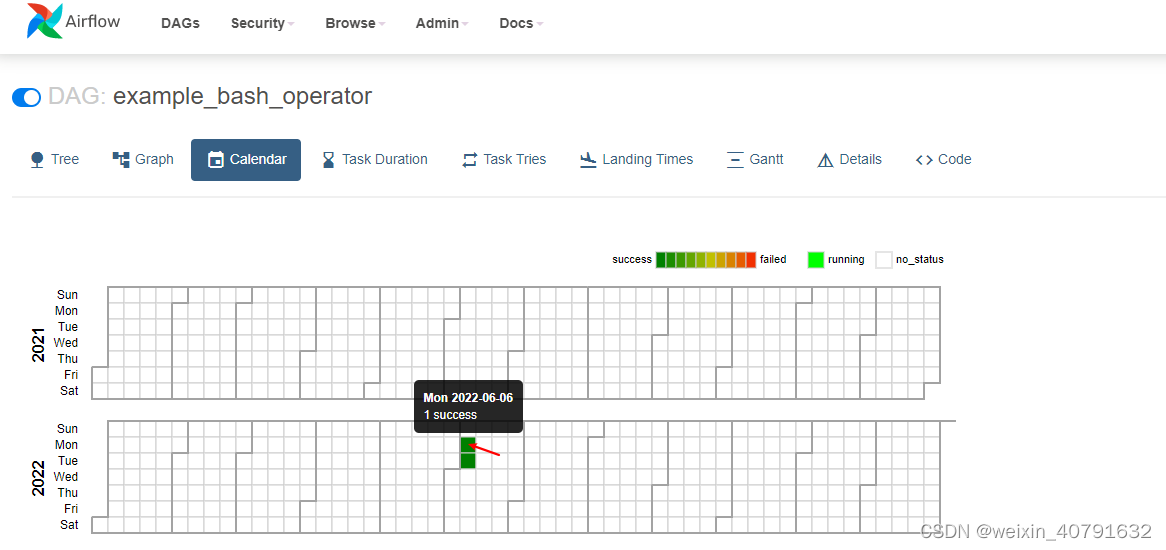
日期视图,显示当前年每月每天任务执行情况。清晰可见在每年的每月中每天的执行状况,如果某一天执行失败很容易查看到。
2.4.Task Duration
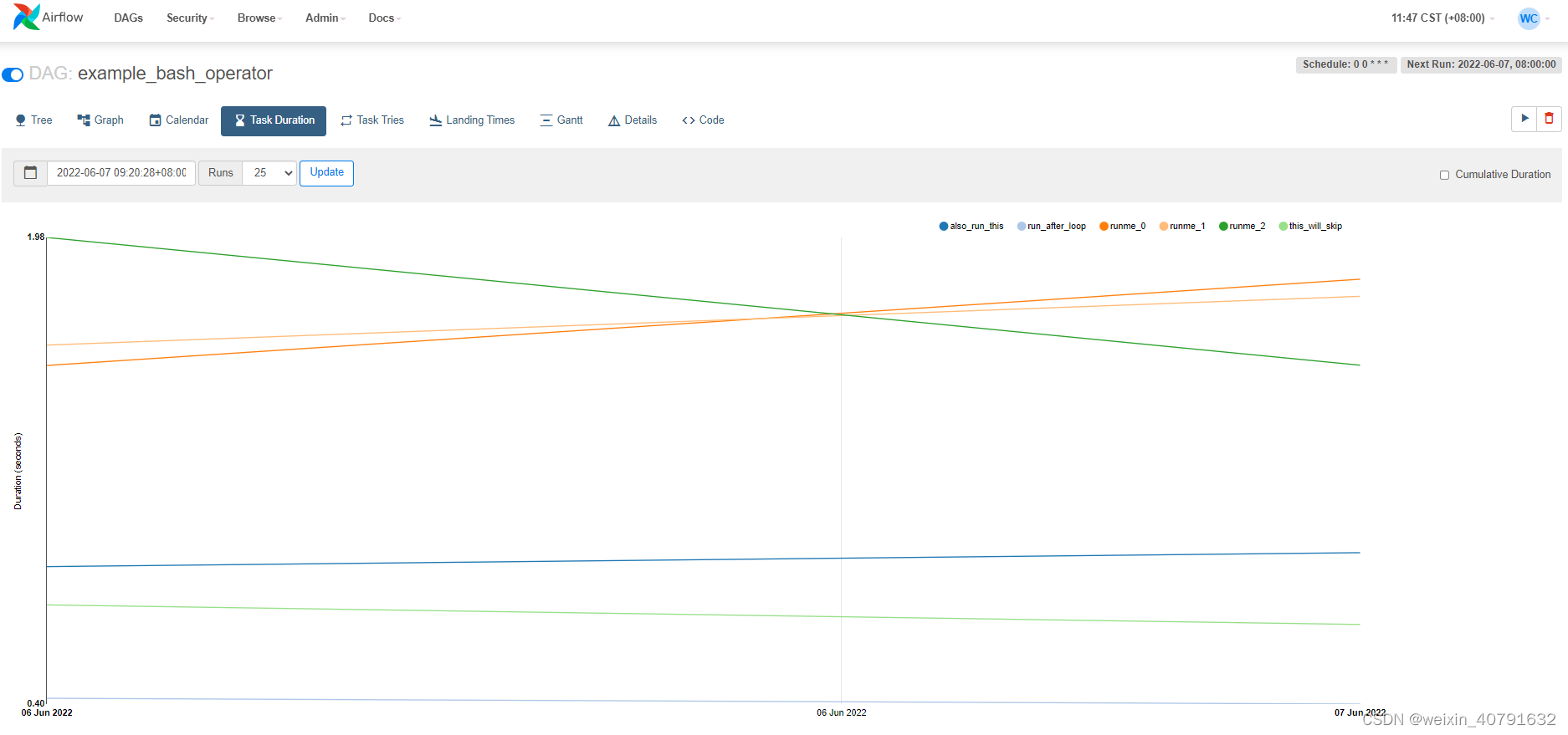
此视图表示不同的task在过去每天执行的时长,可以通过每日执行时长对比,发现同一个task执行耗时情况。
2.5.TaskTries
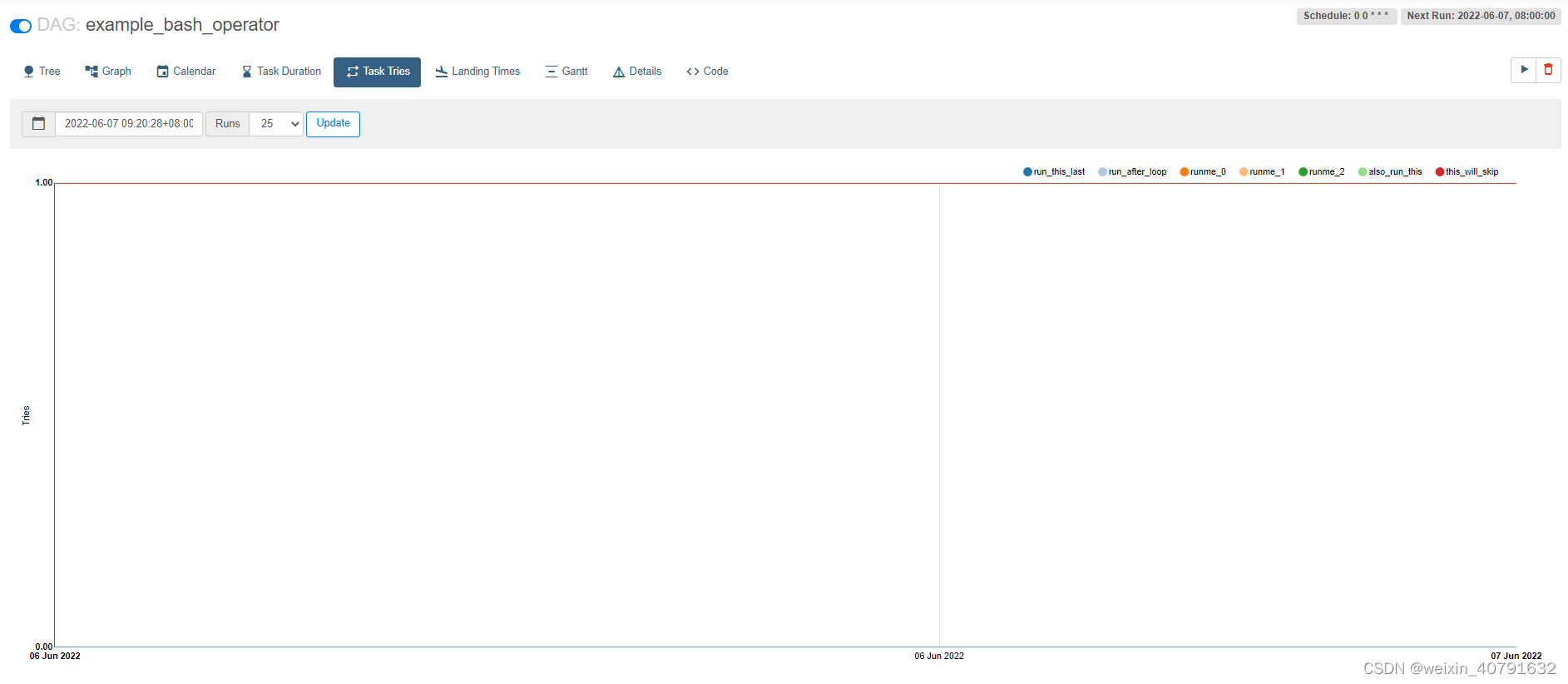
此视图显示每个task重试次数情况。
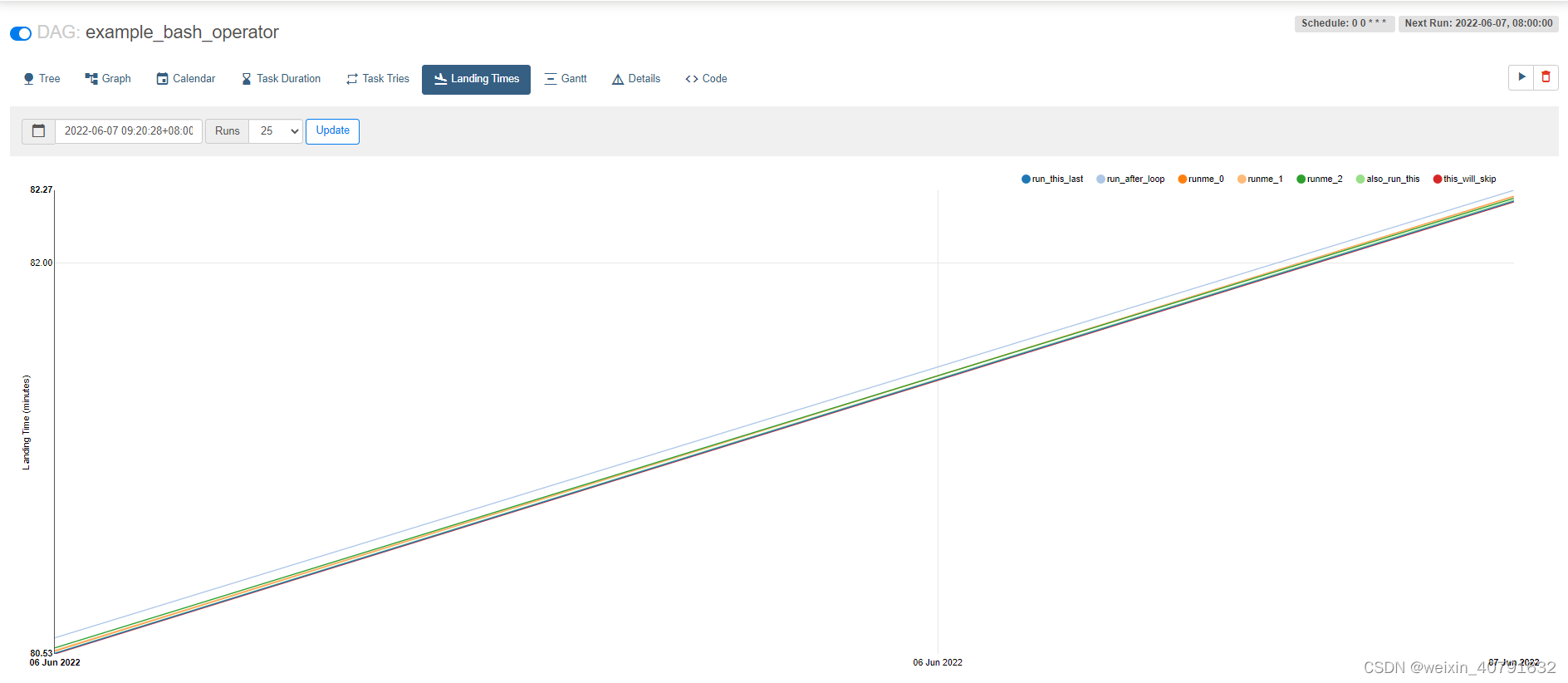
2.6.Landing Times
Landing Times显示每个任务实际执行完成时间减去该task定时设置调度的时间,得到的小时数,可以通过这个图看出任务每天执行耗时、延迟情况。
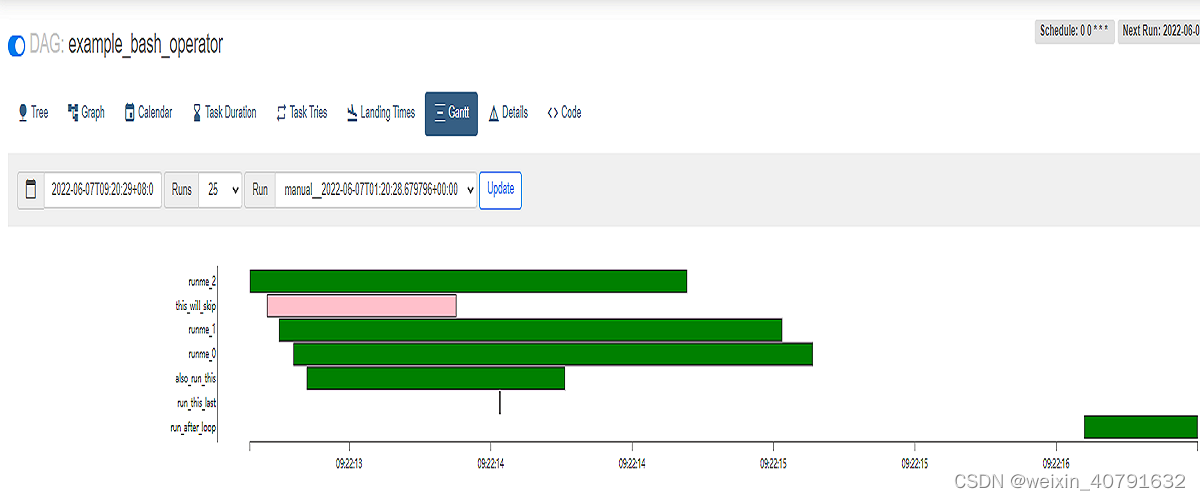
2.7.Grant
甘特图,可以通过甘特图来分析task执行持续时间和重叠情况,可以直观看出哪些task执行时间长。
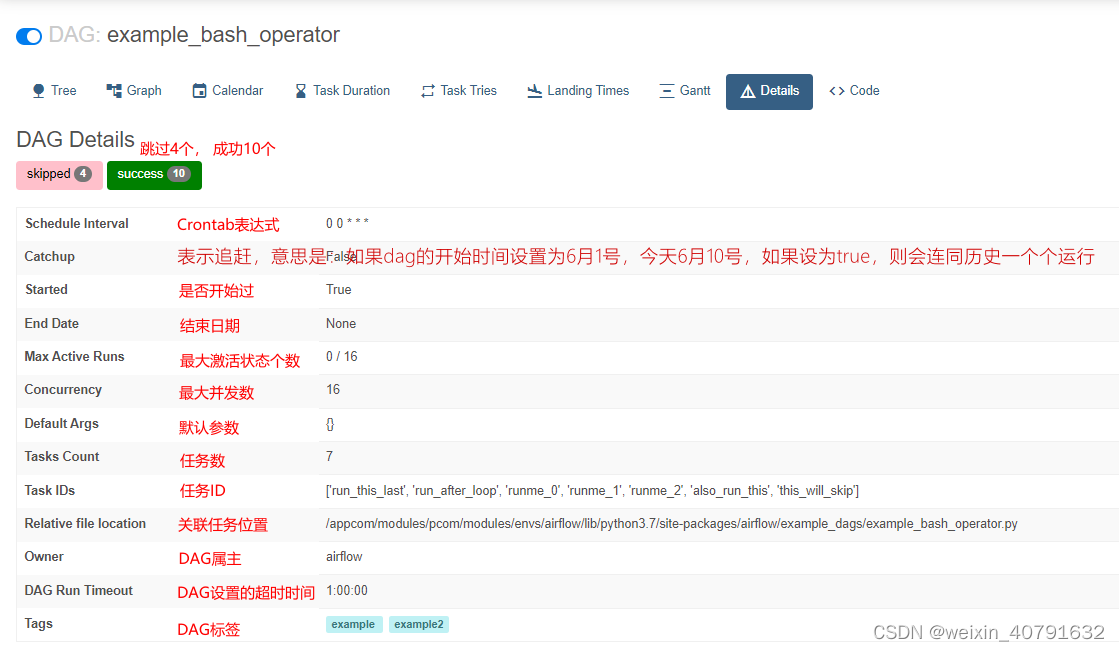
2.8.Details
可以通过“Details”发现任务详细情况。
-
Max Active Runs : 最大激活状态个数时相对于DAG来说的
-
Concurrency : 最大并发数时相对于一个DAG内Task来说的
-
DAG Run Timeout : 超出DAG设置的时间仍未完成就会被kill掉
-
Catchup :意为 “追赶” ,在实现DAG具体逻辑后,如果将catchup设置为True(默认就为True), Airflow将 “回填” 所有过去的DAG run,如果将catchup设置为False, Airflow将从最新的DAG run时刻前一时刻开始执行 DAG run,忽略之前所有的记录。
例如:
现在某个DAG每隔1分钟执行一次,调度开始时间为2021-01-01 ,当前日期为2022-06-01 15:23:21,如果catchup设置为True,那么DAG将从2021-01-01 00:00:00 开始每分钟都会运行当前DAG。如果catchup 设置为False,那么DAG将从2021-06-01 15:22:20(当前2021-06-01 15:23:21前一时刻)开始执行DAG run。
2.9.Code
Code页面主要显示当前DAG python代码编码,当前DAG如何运行以及任务依赖关系、执行成功失败做什么,都可以在代码中进行定义。
3.页面菜单-Security
“Security”涉及到Airflow中用户、用户角色、用户状态、权限等配置。
3.1.List Users
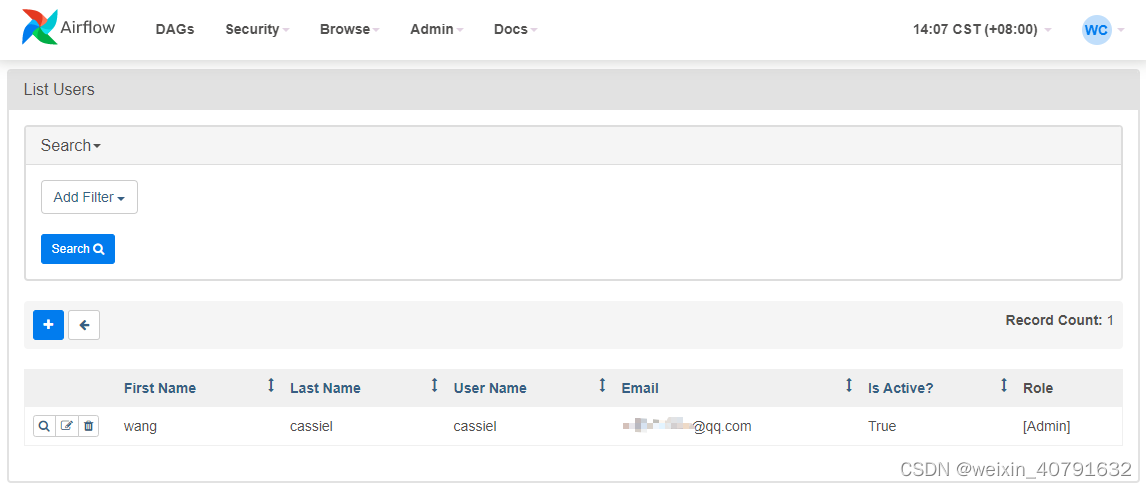
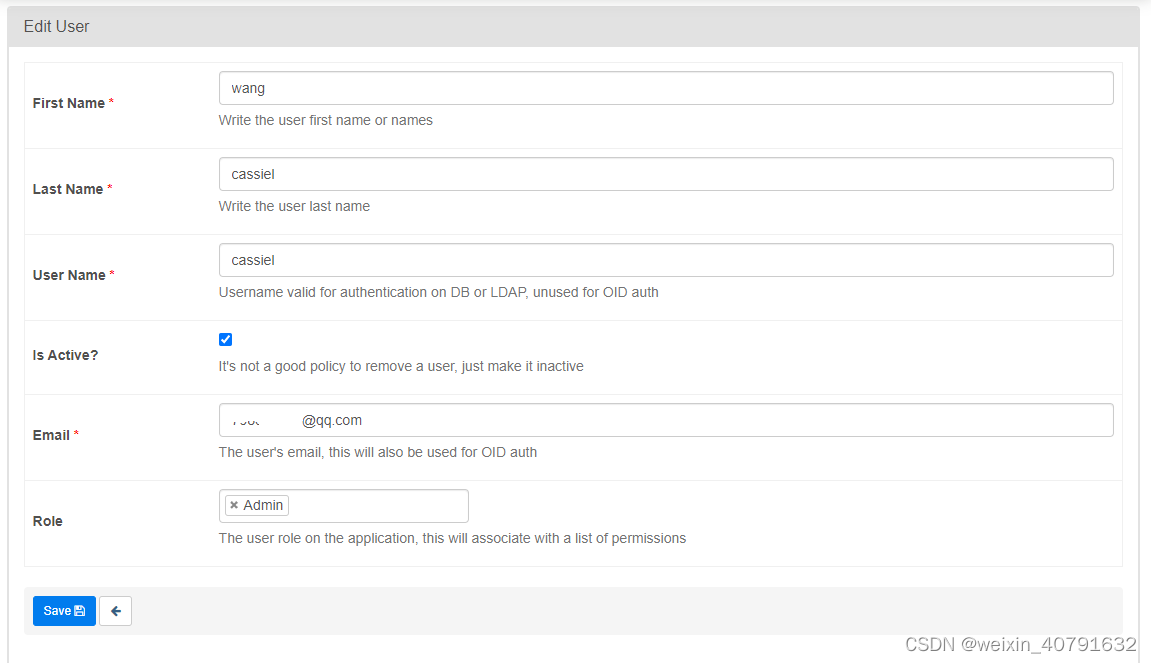
编辑用户信息
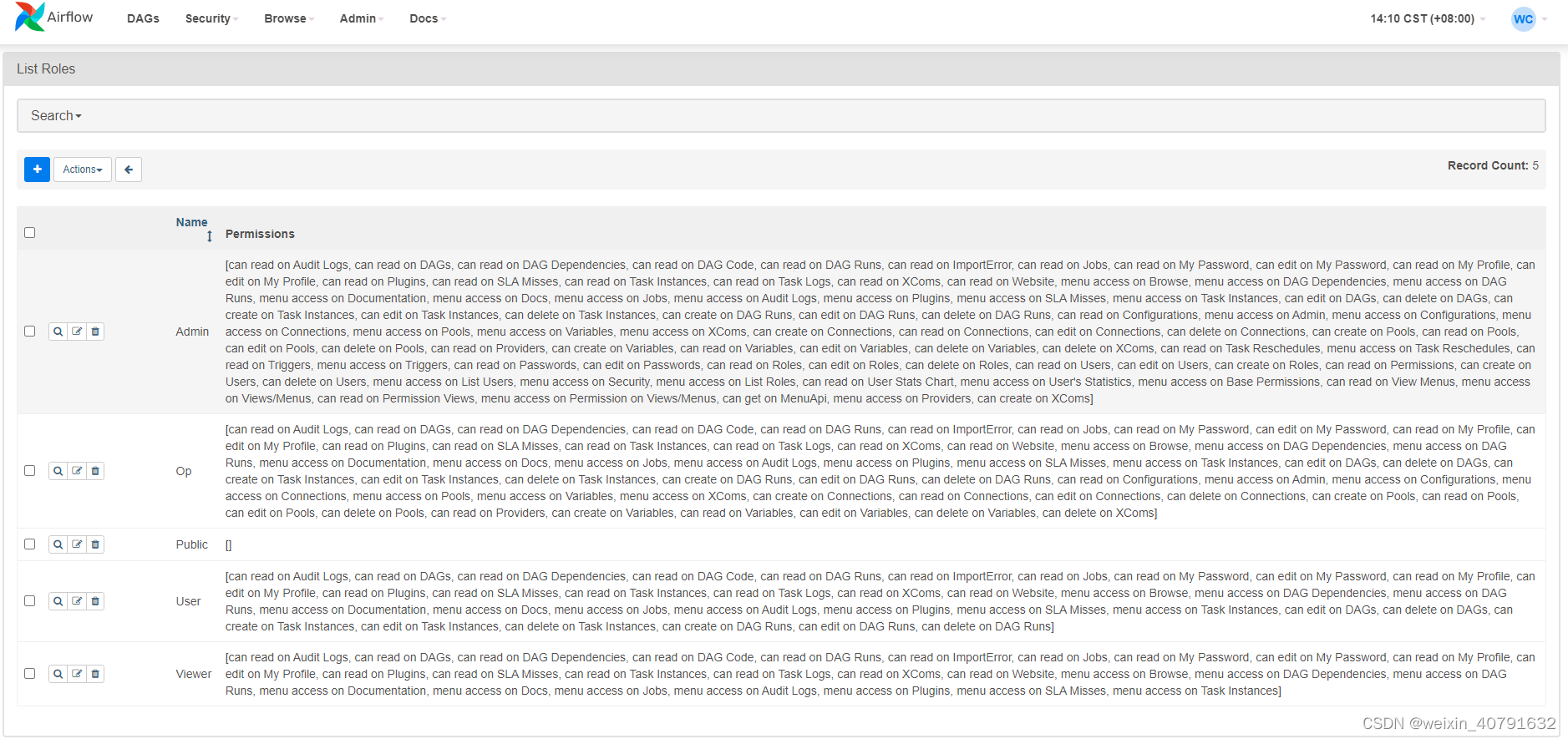
3.2.List Roles
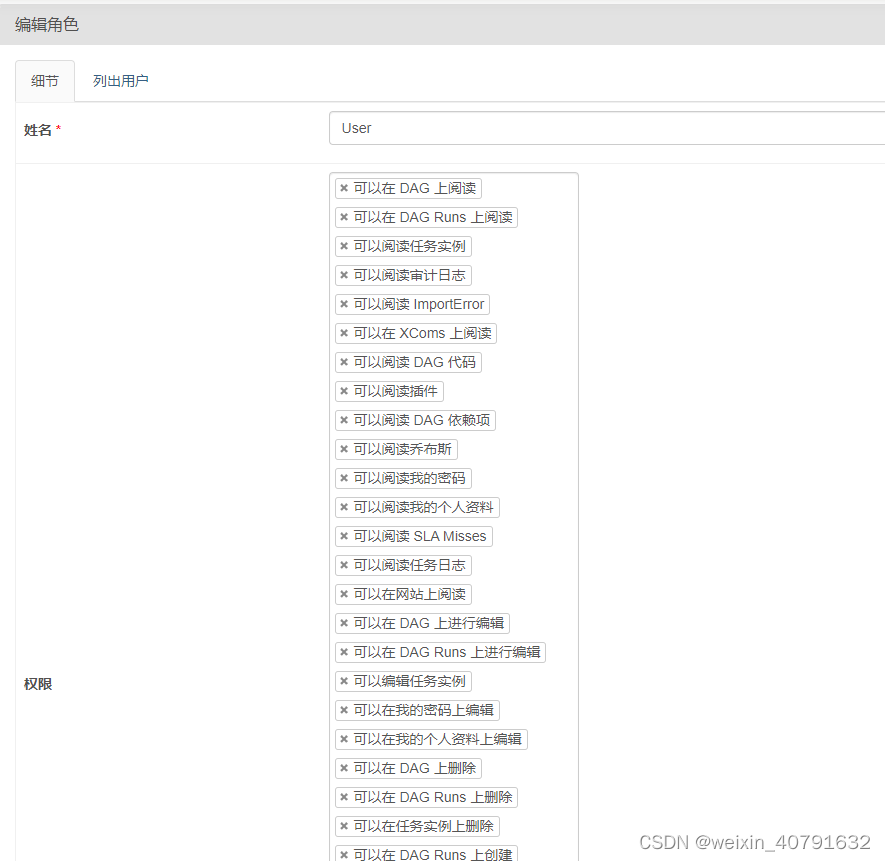
编辑角色
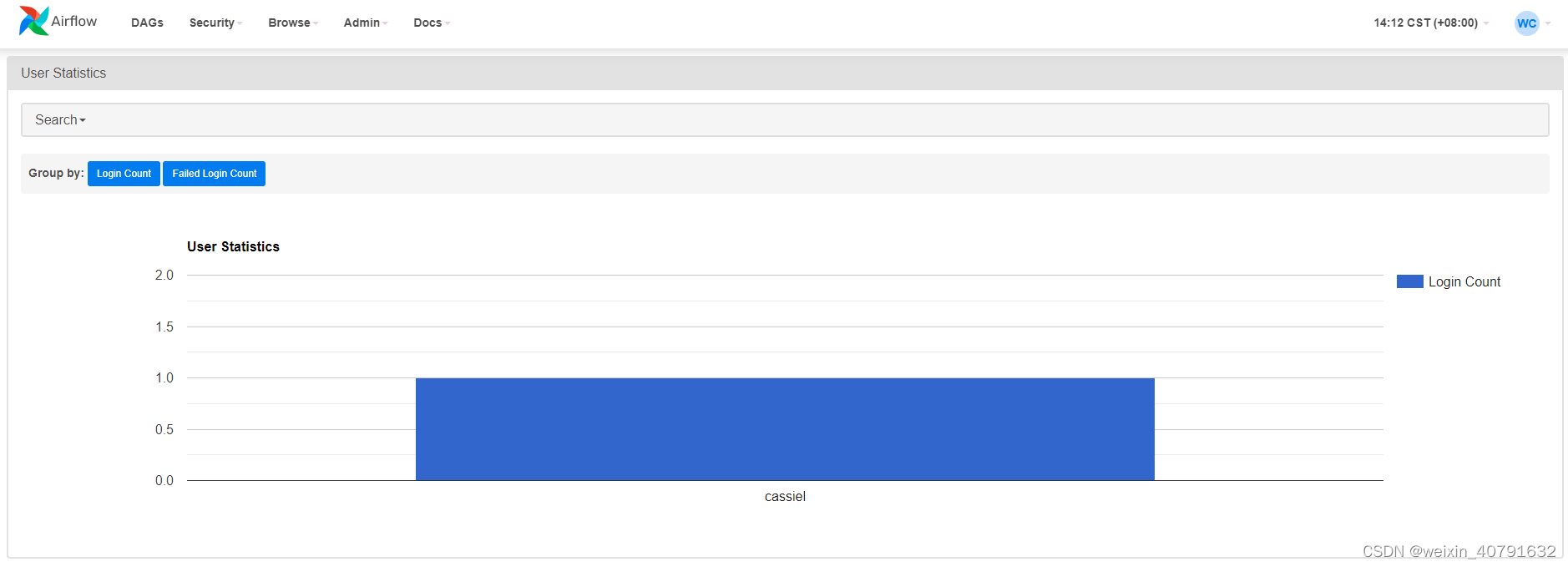
3.3.User’s Statistics
3.4.Base Permissions
4.页面菜单-Browse
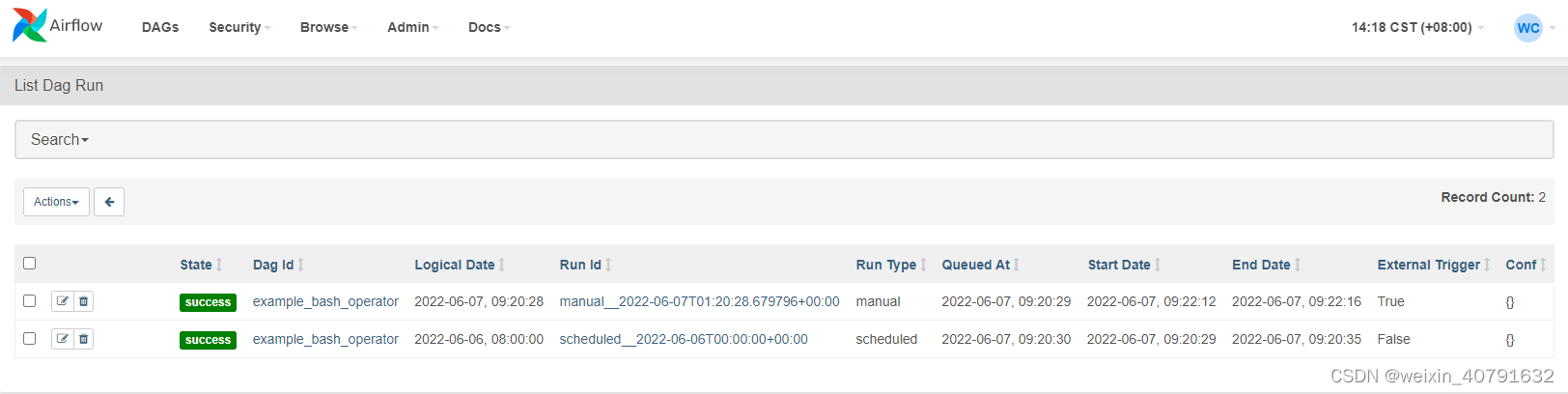
4.1.DAG Runs
列出所有的DAG执行记录和状态,包括开始时间,结束时间,手动还是周期调度等等。默认只显示活动的DAG执行记录。
5.页面菜单-Admin
在Admin标签下可以定义Airflow变量、配置Airflow、配置外部连接等。
5.1.Configurations
若在airflow.cfg中如下配置,页面上无法直接查看参数
[webserver]
# 设置web端Configuration不显示配置信息
expose_config = False

[webserver]
# 设置web端Configuration不显示配置信息
expose_config = True
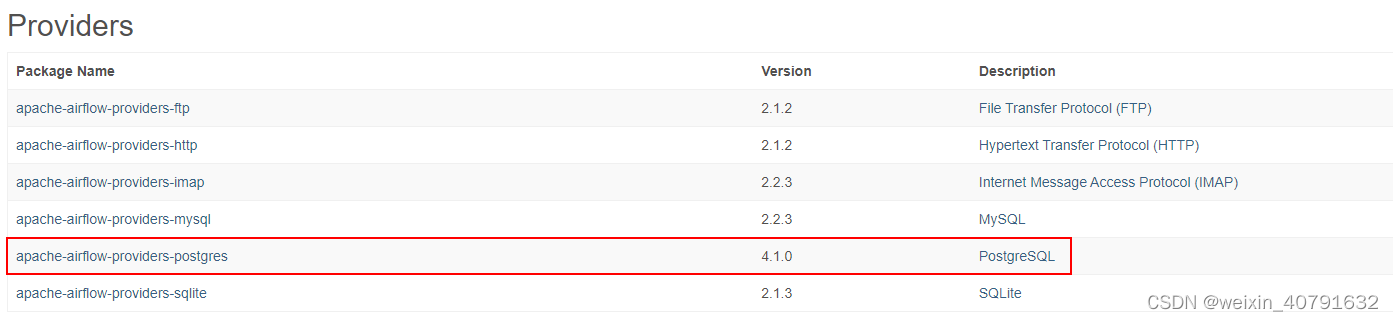
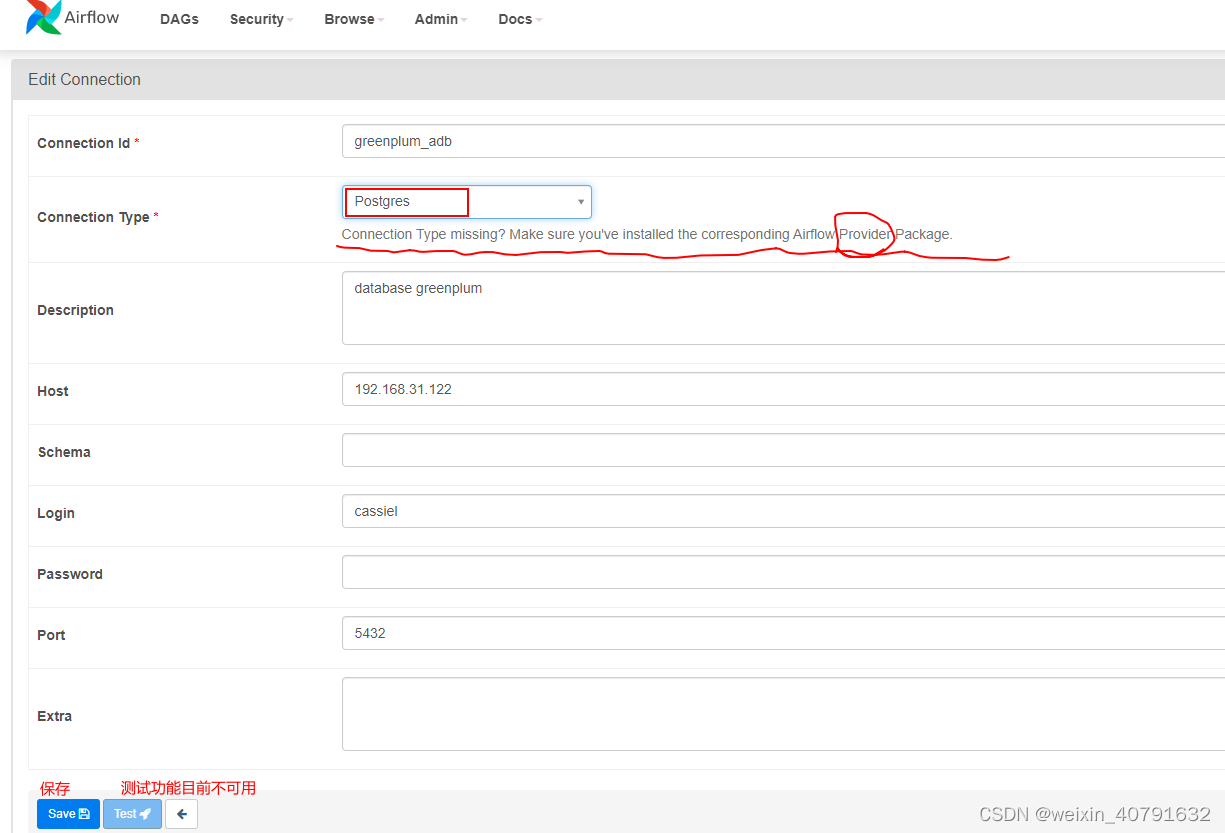
5.2.Connections
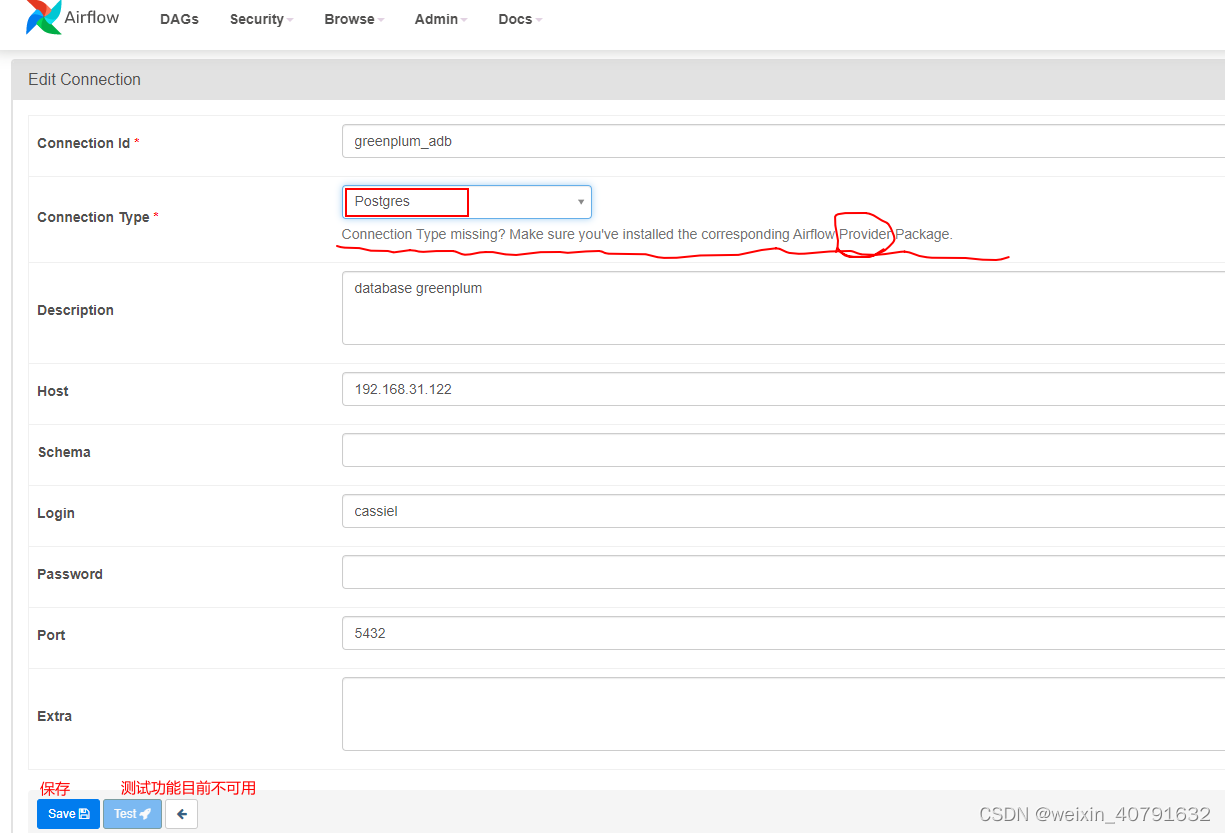
添加connection,若所添加的connection中conn type类型没有需要增加依赖
安装依赖
pip3 install apache-airflow[postgres]
依赖安装完毕后在 Admin --> Providers 中就可以查到安装的依赖版本和描述信息
再新增connection时type就可以选择了
5.3.Pools
6.页面菜单-Docs
Docs中关于用户使用的官方文档或官方页面的地址链接
四、Airflow开发详解
1.Airflow DAG作业
1.1.创建一个dag文件
Airflow的核心是DAG,而DAG在airflow中是以python脚本形式存在的,一个将DAG的结构指定为代码的脚本文件。
现在开始创建一个py文件:first_dag.py, 若一个py文件中只有一个dag,则最好py命名和dag_id命名一致。
1.1.1.第一步: 导包
python3.x 不需要指定 # -*- coding: utf-8 -*-, 因为python3.x默认使用utf-8
python脚本在开始之前需要导入依赖库,从依赖库中导出需要的类或命令。
注释是一个程序员编码的好习惯,但是airflow的dag文件中不支持中文,需要格外的注意,写的中文后面全要改写成英文。
# pyhton-note :第一个DAG,主要做演示
# created-by :cassiel
# created-date :2022-05-09 14:15:32
# updated-by :cassiel
# cassiel
# updated-date :2022-06-07 10:22:42
# 2022-06-08 14:23:51
# updated-notes:添加参数
# 修改参数
#########################################################################################
import airflow
from airflow import DAG
from airflow.operators.bash_operator import BashOperator # 有很多Operator,这里用BashOperator,因此导入这个
from datetime import datetime, datetime
1.1.2.第二步: 设置DAG默认参数
通常,DAG 中的许多运算符需要相同的一组默认参数(例如它们的retries)。您可以在创建 DAG 时将其传递给 DAG,而不必为每个 Operator 单独指定default_args它,它会自动将它们应用于与其关联的任何 Operator
显式地将一组参数传递给每个任务的构造函数作为默认参数, 这些参数都可以在DAG实例或任务配置时进行覆盖
-
owner : DAG的属主
-
depends_on_past : 是否依赖上游任务,当设置为 true 时,任务实例将按顺序运行,并且仅当前一个实例成功或已被跳过时。start_date 的任务实例被允许运行
-
start_date :DAG的开始日期,可以在DAG实例中予以覆盖
-
email : 告警通知邮箱地址,多个邮件用逗号分隔
-
email_on_failure : 是否dag失败了发送邮件
-
email_on_retry : 是否dag重试发送邮件
-
retries : 失败重试次数
-
retry_delay : 失败重试间隔
-
queue : 队列,celeryExecutor的队列可以是redis或rabbitMQ,选择对应的mq
-
pool : 选择对应的pool,给与对应的slots,避免在一个DAG中同时刻运行的task过多,造成资源不够用,出现卡顿的现象,结合着优先级权重一起使用,确定同时运行的task中水先跑谁后跑
-
priority_weight : 优先级权重
-
end_date : DAG的结束时间,注释掉就会一直执行下去
-
wait_for_downstream : 等待下游完成
-
dag : 对任务附加到的 dag 的引用(如果有)
-
adhoc : 是否点对点模式
-
sla : 预计作业成功的时间
-
execution_timeout : 执行超时,如果设置了超时,超过这个时间范围仍未完成,该DAG将会被kill掉
-
on_failure_callback : 一个Python函数,失败的时候执行。
-
on_success_callback : 一个Python函数,成功的时候执行
-
on_retry_callback : 一个Python函数,重试的时候执行
-
trigger_rule : 触发规则
-
all_success: (default) 所有的父任务都成功。
-
all_failed: 所有的父任务或上游任务都失败。
-
all_done: 所有的父任务都完成。
-
one_failed: 一旦至少一个父任务失败了就会被触发,它不会等待所有父任务完成。
-
one_success: 一旦至少有一个父任务成功了就会被触发,它不会等待所有父任务完成。
-
dummy: 依赖只是为了展示,任意触发。
-
-
catchup :意为 “追赶” ,在实现DAG具体逻辑后,如果将catchup设置为True(默认就为True), Airflow将 “回填” 所有过去的DAG run,如果将catchup设置为False, Airflow将从最新的DAG run时刻前一时刻开始执行 DAG run,忽略之前所有的记录。
-
tags:[‘example’, ‘example2’]
例如:
现在某个DAG每隔1分钟执行一次,调度开始时间为2021-01-01 ,当前日期为2022-06-01 15:23:21,如果catchup设置为True,那么DAG将从2021-01-01 00:00:00 开始每分钟都会运行当前DAG。如果catchup 设置为False,那么DAG将从2021-06-01 15:22:20(当前2021-06-01 15:23:21前一时刻)开始执行DAG run。
# pyhton-note :第一个DAG,主要做演示
# created-by :cassiel
# created-date :2022-05-09 14:15:32
# updated-by :cassiel
# cassiel
# updated-date :2022-06-07 10:22:42
# 2022-06-08 14:23:51
# updated-notes:添加参数
# 修改参数
#########################################################################################
import airflow
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2020, 6, 1, 3, 0),
'email': ['airflow1@example.com','airflow2@example.com'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 3,
'retry_delay': timedelta(seconds=20)
# 'catchup': False,
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
# 'wait_for_downstream': False,
# 'dag': dag,
# 'adhoc':False,
# 'sla': timedelta(hours=2),
# 'execution_timeout': timedelta(seconds=300),
# 'on_failure_callback': some_function,
# 'on_success_callback': some_other_function,
# 'on_retry_callback': another_function,
# 'trigger_rule': 'all_success'
}
1.1.3.第三步: 创建一个DAG实例
需要一个DAG对象来嵌入所有任务中。 这里就需要传递一个定义dag_id的字符串,它用作DAG的唯一标识符。 然后传递DAG默认参数,并为DAG定义一个schedule_interval。
-
dag_id :dag名称或者dag的id,唯一不重复
-
default_args :指定DAG的默认参数
-
description :对于定义的DAG的描述性说明文字
-
schedule_interval :schedule_interval的设置有三种方法
-
使用python的datetime库中的timeDelta类完成
schedule_interval=timedelta(minutes=1) # 执行周期,表示每分钟执行一次 schedule_interval=timedelta(seconds=40) # 执行周期,表示每40秒执行一次 schedule_interval=timedelta(hours=4) # 执行周期,表示每4小时执行一次 schedule_interval=timedelta(days=4) # 执行周期,表示每4天执行一次 -
使用Airflow预置的Cron调度周期
预设 意义 cron None 不要安排,仅用于“外部触发”的 DAG @once 安排一次且仅一次 @hourly 每小时开始时运行一次 0 * * * * @daily 每天午夜跑一次 0 0 * * * @weekly 每周在周日早上的午夜运行一次 0 0 * * 0 @monthly 每月第一天午夜运行一次 0 0 1 * * @quarterly 第一天午夜每季度跑一次 0 0 1 */3 * @yearly 每年 1 月 1 日午夜运行一次 0 0 1 1 * -
使用crontab表达式
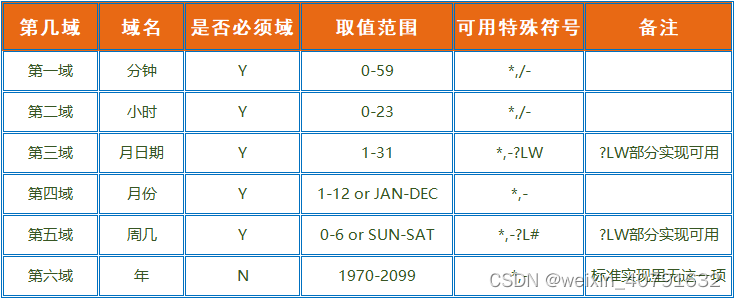
┌───────────── 分钟 (0 - 59) │ ┌───────────── 小时 (0 - 23) │ │ ┌───────────── 每月日期 (1 - 31) │ │ │ ┌───────────── 月份 (1 - 12) │ │ │ │ ┌───────────── 周几 (0 - 6) (周日 ~ 周六; 7、在某些系统里则是周日) │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ * * * * * bash xxxxaabbxx.sh args1 args2 逗号(,) * 3,10,14,18,22 * * * // 表示在3点、10点、14点、18点、22点整的时候执行一次 连字符(-) * 3-10 * * * //表示在3点到10点每小时执行一次 斜线(/) */5 * * * * //表示每5分钟执行一次 井号(#) */5 3,10,18 * * 5#3 //表示在第三周的星期五的3点、10点和18点中,每五分钟运行一次 L(last) * * * * L5 //表示在当年中的最后一个星期五的凌晨零点整执行一次 W(weekday)和 ?一般较少使用,可以不做详解
-
-
start_date :覆盖掉默认DAG参数
-
max_active_runs:设置dag中最多跑几个dag_run,当多天一起执行时会出现一天在跑,其他全部是死锁,可以将值设成1
# pyhton-note :第一个DAG,主要做演示
# created-by :cassiel
# created-date :2022-05-09 14:15:32
# updated-by :cassiel
# cassiel
# updated-date :2022-06-07 10:22:42
# 2022-06-08 14:23:51
# updated-notes:添加参数
# 修改参数
#########################################################################################
import airflow
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedelta
# Dag默认参数设置
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2020, 6, 1, 3, 0),
'email': ['airflow1@example.com','airflow2@example.com'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 3,
'retry_delay': timedelta(seconds=20)
}
# Dag一个定义
dag = DAG(
dag_id='first_dag',
default_args=default_args,
description='my first DAG',
schedule_interval='*/10 * * * *',
start_date=datetime(2022, 5, 28),
catchup=False
)
1.1.4.第四步: 设置任务
设置所有的任务,任务名自定义,没有具体要求
# pyhton-note :第一个DAG,主要做演示
# created-by :cassiel
# created-date :2022-05-09 14:15:32
# updated-by :cassiel
# cassiel
# updated-date :2022-06-07 10:22:42
# 2022-06-08 14:23:51
# updated-notes:添加参数
# 修改参数
#########################################################################################
import airflow
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedelta
# Dag默认参数设置
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2020, 6, 1, 3, 0),
'email': ['airflow1@example.com','airflow2@example.com'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 3,
'retry_delay': timedelta(seconds=20)
}
# Dag一个定义
dag = DAG(
dag_id='first_dag',
default_args=default_args,
description='my first DAG',
schedule_interval='*/10 * * * *',
start_date=datetime(2022, 5, 28),
catchup=False
)
# 设置任务
first_1_task = BashOperator(
task_id='first_1_task',
bash_command='echo `date` >> /home/airflow/test.txt',
dag=dag
)
first_2_task = BashOperator(
task_id='first_2_task',
bash_command='echo "hello" >> /home/airflow/test.txt',
dag=dag
)
second_task = BashOperator(
task_id='second_task',
bash_command='echo "hello world!" >> /home/airflow/test.txt',
dag=dag
)
1.1.5.第五步: 设置任务依赖关系
注意: 上传的DAG文件中不能出现任何中文,一旦有中文出现,就会报错。如果写py文件时注释使用了中文,样么删除,样么改成英文
设置依赖关系有两种方法:
-
推荐的一种是使用
>>and<<运算符a >> b # b依赖a a << b # a依赖b a >> b >> c # 依赖可以串起来 [a,b] >> c # 可以依赖多个 -
也可以使用更明确的
set_upstream和set_downstream方法first_task.set_downstream(second_task, third_task) third_task.set_upstream(fourth_task)
# pyhton-note : fist dag, use to test
# created-by : cassiel
# created-date : 2022-05-09 14:15:32
# updated-by : cassiel
# cassiel
# updated-date : 2022-06-07 10:22:42
# 2022-06-08 14:23:51
# updated-notes: add args
# update args
#########################################################################################
import airflow
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedelta
# Dag default args
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2020, 6, 1, 3, 0),
'email': ['airflow1@example.com','airflow2@example.com'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 3,
'retry_delay': timedelta(seconds=20)
}
# Defined a dag
dag = DAG(
dag_id='hello_world',
default_args=default_args,
description='my first DAG',
schedule_interval='0 3 * * *',
start_date=datetime(2022, 6, 11),
catchup=False
)
# set tasks
first_1_task = BashOperator(
task_id='first_1_task',
bash_command='echo `date` >> /home/airflow/test.txt',
dag=dag
)
first_2_task = BashOperator(
task_id='first_2_task',
bash_command='echo "hello" >> /home/airflow/test.txt',
dag=dag
)
second_task = BashOperator(
task_id='second_task',
bash_command='echo "hello world!" >> /home/airflow/test.txt',
dag=dag
)
# set dependences
[first_1_task,first_2_task] >> second_task
1.2.创建DAG的三种方式
1.2.1. 匿名构造函数声明
with DAG(
"my_dag_name", start_date=datetime(2022, 1, 1),
schedule_interval="@daily", catchup=False
) as dag:
task1=XXOperator(task_id="task1")
run_after_loop = BashOperator(
task_id='run_after_loop',
bash_command='echo 1'
)
task1 >> run_after_loop
1.2.2.标准构造函数声明
这是目前主流使用方式
my_dag = DAG(task_id="my_dag_name", catchup=False)
task1 = XXOperator(task_id="task1", dag=my_dag)
task2 = XXOperator(task_id="task2", dag=my_dag)
task1 >> task2
1.2.3.装饰器函数转换声明
这种方式是在2.x版本之后出现的
@dag(start_date=days_ago(2), catchup=False)
def generate_dag():
task1 = XXOperator(task_id="task1")
dag = generate_dag()
1.3.上传DAG文件
DAGs的存放目录一般是在airflow.cfg中配置的
[core]
# 存放dag的目录,需要使用绝对路径
dags_folder = /appcom/modules/airflow/dags
将写的 first_dag.py 上传到制定的存储目录中 /appcom/modules/airflow/dags
注意: 上传的DAG文件中不能出现任何中文,一旦有中文出现,就会报错。如果写py文件时注释使用了中文,样么删除,样么改成英文
(base) [airflow@centos003 dags]$ pwd
/appcom/modules/airflow/dags
(base) [airflow@centos003 dags]$ ll
总用量 4
-rwxr-xr-x 1 airflow airflow 1499 5月 28 15:44 first_dag.py
(base) [airflow@centos003 dags]$
dag.py文件也可以放在git或svn等文件管理系统中,后面需要写自动部署脚本,可以使用Jekins进行。
2.运行DAG任务
2.1.手动执行
上传好了之后,在页面上操作
- 点击最左边的激活按钮,激活这个dag,不激活,是不会呗scheduler调度的。
- 点击右侧的执行按钮手动执行;不点击执行按钮则按照Scheduler设置的crontab自动周期调度执行
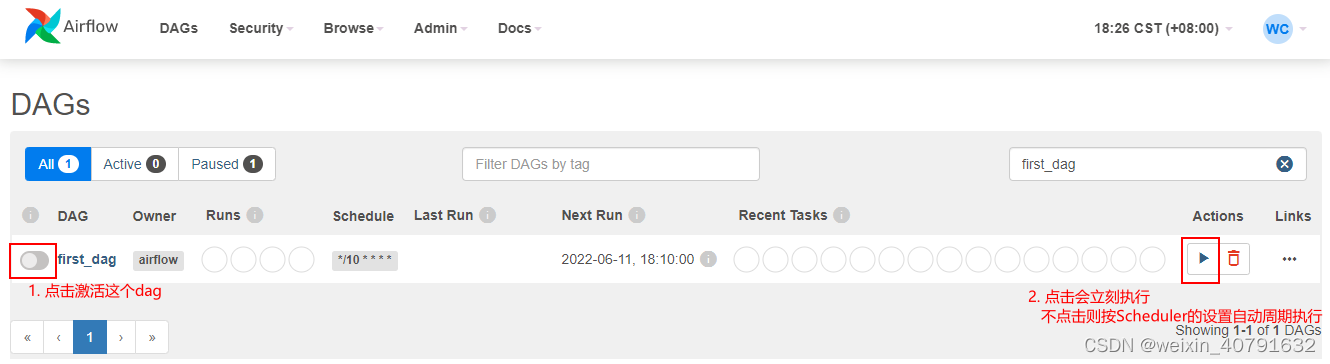
手动执行,dag会再queue中延迟约1分钟才会执行。
2.2使用命令执行
2.2.1.命令行执行
# 激活dag,会根据配置的Scheduler周期调度的
airflow dags unpause execute_shell_sh
# 关闭dag激活
airflow dags pause execute_shell_sh
# 手动命令执行dag
# airflow dags trigger [-c CONF] [-e EXEC_DATE] [-r RUN_ID] [-S SUBDIR] dag_id
airflow dags trigger execute_shell_sh
2.2.2.调用Rest API执行
参考 [六、Airflow的API使用](# 六、Airflow的API使用) :按住ctrl键再点击鼠标左键就可以跳转了
2.3.传递参数
2.3.1.Jinja模板
2.3.1.1.airflow的Jinja模板
Airflow充分利用了Jinja Templating的强大功能,并提供了一组内置参数和宏。 Airflow还支持自定义参数、宏和模板的钩子。
# {{ }} 就是Jinja模板的轮廓
{{ ds }} # 这是airflow中内置的基于Jinja模板的变量参数
模板替换发生在pre_execute你的操作符函数被调用之前,会将整个Jinja模板全部替换成对应的变量参数值。
2.3.1.2.Jinja模板和自定义变量
除了内置的变量还可以Jinja模板配合自定义变量使用,自定义参数的value需要是json类型,key必须是“params”,不能是别的,否则报错
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
default_args = {
'owner': 'airflow',
'params' : {'name': 'zhangsan'}
}
dag = DAG(
dag_id = 'execute_jinja_seft_var',
default_args=default_args,
schedule_interval=timedelta(minutes=1),
catchup = False,
start_date = datetime(2022, 6, 11)
)
shell_task=BashOperator(
task_id='shell_task',
bash_command='echo {{ params.name }}',
dag = dag
)
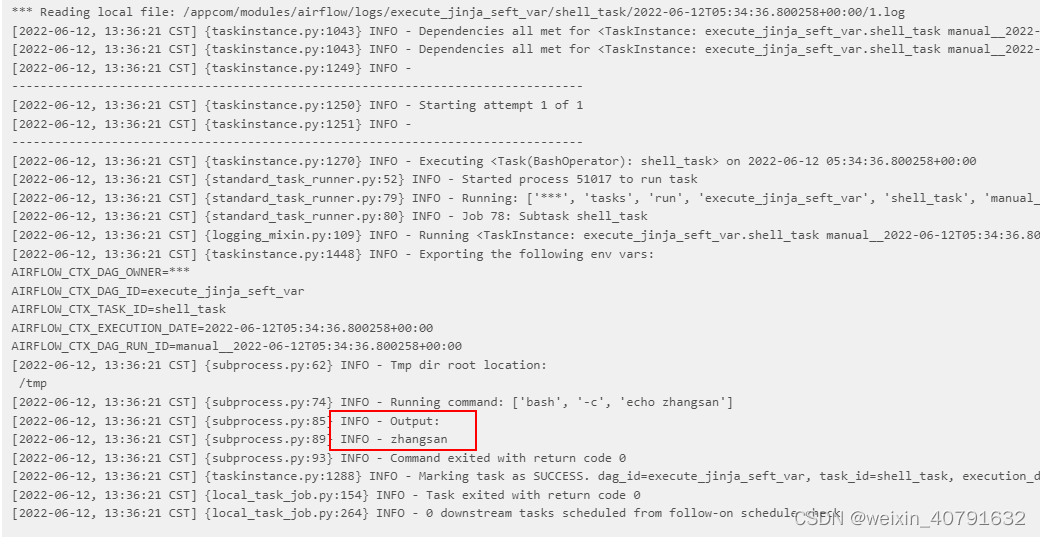
2.3.1.3.Airflow内置的Jinja变量
Airflow 引擎默认传递一些变量,这些变量在所有模板中都可以访问
| Jinja模板内置变量 | 说明描述 |
|---|---|
{{ data_interval_start }} | 数据间隔的开始(pendulum.DateTime) |
{{ data_interval_end }} | 数据间隔结束 ( pendulum.DateTime ) |
{{ ds }} | DAG 运行的逻辑日期为YYYY-MM-DD. 等价于`{{ dag_run.logical_date |
{{ ds_nodash }} | 等价于`{{ dag_run.logical_date |
{{ ts }} | 等价于`{{ dag_run.logical_date |
{{ ts_nodash_with_tz }} | 等价于`{{ dag_run.logical_date |
{{ ts_nodash }} | 等价于`{{ dag_run.logical_date |
{{ prev_data_interval_start_success }} | 从先前成功的 DAG 运行开始的数据间隔 |
{{ prev_data_interval_end_success }} | 从先前成功的 DAG 运行开始的数据间隔结束 |
{{ prev_start_date_success }} | 从先前成功的 dag 运行开始日期 |
{{ dag }} | DAG 对象。 |
{{ task }} | 任务对象。 |
{{ macros }} | 对宏包的引用 |
{{ task_instance }} | task_instance 对象。 |
{{ ti }} | 等价于{{ task_instance }} |
{{ params }} | 对用户定义的 params 字典的引用 |
{{ var.value.my_var }} | 表示为字典的全局定义变量。 |
{{ var.json.my_var.path }} | 表示为字典的全局定义变量。使用反序列化的 JSON 对象,将路径附加到 JSON 对象中的键。 |
{{ conn.my_conn_id }} | 表示为字典的连接。 |
{{ task_instance_key_str }} | 任务实例的唯一、人类可读的密钥,格式为 {dag_id}__{task_id}__{ds_nodash}. |
{{ conf }} | airflow.configuration.conf代表您的内容的完整配置对象 airflow.cfg。 |
{{ run_id }} | 当前run_idDAG 运行的。 |
{{ dag_run }} | 对 DagRun 对象的引用。 |
2.3.1.4.过滤器
Airflow 定义了一些可用于格式化值的 Jinja 过滤器
# 语法
{{ 内置变量名 | 过滤器 }}
| 过滤器 | 对应库 | 描述 |
|---|---|---|
ds | datetime | 将日期时间格式化为YYYY-MM-DD |
ds_nodash | datetime | 将日期时间格式化为YYYYMMDD |
ts | datetime | 与 .isoformat()相同,示例:2018-01-01T00:00:00+00:00` |
ts_nodash | datetime | 与没有,或 TimeZone 信息的ts过滤器相同。例子:-``:``20180101T000000 |
ts_nodash_with_tz | datetime | 作为没有or的ts过滤器。例子 20180101T000000+0000 |
2.3.1.5.宏-Macros
宏是一种向模板公开对象并存在于模板中的 macros命名空间下的方法
用的不算多,了解请自行官网访问:https://airflow.apache.org/docs/apache-airflow/2.2.5/templates-ref.html
2.3.2.Variables
变量是将任意内容或配置作为一个key/value简单键值存储的通用方法, 这种存储时作为全局变量来使用的。这种全局变量尽可能少用,影响性能,因为全局标量是存在数据库中,对于所有DAG都有效,增加了访问数据库的次数,增加了后端压力。
可以在UI界面录入全局变量(Admin - > Variables)
- 编辑变量
- list变量
- 创建变量
- 更新变量
- 删除变量
注意:不能出现中文!!!!!挺恶心的玩意
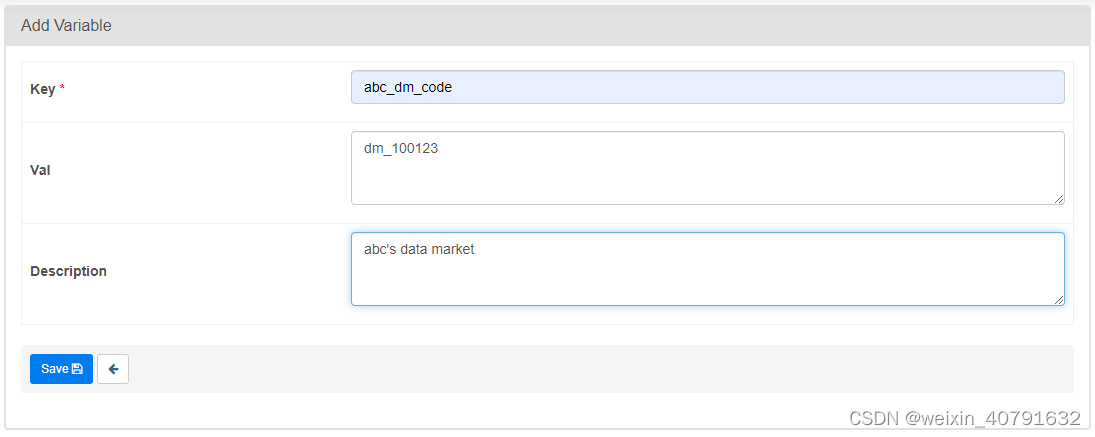
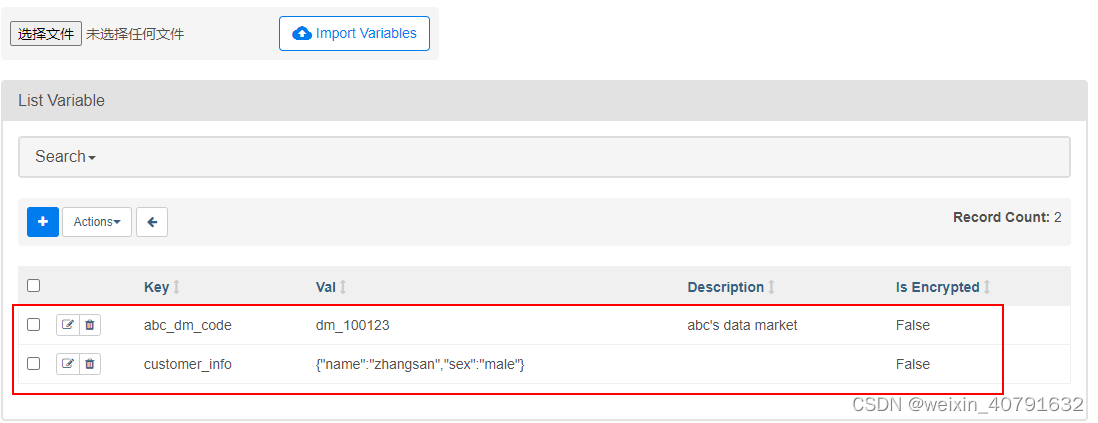
json配置文件可以通过UI批量上传。 虽然pipeline代码定义和大多数常量和变量应该在代码中定义并存储在源代码控制中,但是通过UI可以访问和修改某些变量或配置项会很有用。
from airflow.models import Variable
dm_code = Variable.get("abc_dm_code")
bar = Variable.get("customer_info", deserialize_json=True)
第二个调用假设是json内容,并将其反序列化。 请注意Variable是sqlalchemy模型,可以这样使用。
你可以在jinja模板中按下面方法引用变量:
echo {{ var.value.customer_info }}
或者如果需要从变量反序列化json对象:
echo {{ var.json.customer_info }}
2.3.3.Xcoms
XComs 是一种让任务相互交流的机制,因为默认情况下,任务是相互隔离开的当试图在某个DAG中获取之前的任务输出时,XComs会非常有用。
就算是一种让任务交流的机制为什么一定需要Xcoms呢?
- 在生产上一般都是分布式或者容器式的部署,一个DAG中的不同任务可能会在不同的worker上运行,woker之间具有隔离性,直接是无法获取对方的返回值的,而Xcoms则提供了这种交流方式。
XComs允许任务间交换消息,允许更细微的控制形式和共享状态。 该名称是“cross-communication”的缩写。 XComs主要由一个key, value和timestamp所定义,但也跟踪创建XCom的task/DAG,以及何时应该可见的属性。 任何可以被pickled的对象都可以用作XCom值,因此用户应该确保使用适当大小的对象。
XComs支持“推”(发送)或“拉”(接收)的方式处理消息。 当任务推送XCom时,它通常可用于其他任务。 任务可以通过调用xcom_push()方法随时推送XComs。 此外,如果任务返回一个值(来自其Operator的execute()方法,或者来自PythonOperator的python_callable函数),则会自动推送包含该值的XCom。
Tasks可以调用xcom_pull()来检索XComs,可选地根据key、source task_ids和source dag_id等条件应用过滤器。 默认情况下,xcom_pull()会过滤出从执行函数返回时被自动赋予XCom的键(与手动推送的XCom相反)。
如果为task_ids传递xcom_pull单个字符串,则返回该任务的最新XCom值; 如果传递了task_ids列表,则返回相应的XCom值列表。
# 在名为“pushing_task”的PythonOperator中使用了def push_function()
return value
#另一个任务接受传过来的对象时,获取对象的某个值
value = context['task_instance'].xcom_pull(task_ids='pushing_task')
也可以直接在模板中pull XCom,这是一个示例:
SELECT * FROM {{ task_instance.xcom_pull(task_ids='foo', key='table_name') }}
请注意,XCom与变量类似,但专门用于任务间通信而非全局设置。
举例:
import airflow
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.operators.python_operator import PythonOperator
from datetime import timedelta
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(1),
'email': ['user@qq.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(seconds=3),
}
dag = DAG(
'bash_get_param_2',
default_args=default_args,
description='bash get param job',
schedule_interval=timedelta(days=1))
# 通过模板的方式来获取xcom传递的参数值。
# 注意:return_value这个变量名是固定的,表示从任务:first_task,过来的变量名
bash_prit_param='echo "I get: {{ ti.xcom_pull(task_ids="first_task", key="return_value") }}"'
print_param_task = BashOperator(
task_id='print_param_task',
do_xcom_push=True,
bash_command=bash_prit_param,
dag=dag)
# 接收REST API的参数,并通过返回参数值来使用xcom保存参数
# 注意:可能有多个参数,可以把这些参数合并到一个变量中,然后返回。若以元组方式返回,则是一个列表。
def receive_param(**context):
# 此句用来接收rest接口的参数,参数名为:push_key
stock_list = context["dag_run"].conf.get("push_key")
print("returned tickers: %s" % str(stock_list))
return stock_list
# 接收来自rest api的参数和值
first_operator = PythonOperator(
task_id='first_task',
python_callable=receive_param,
dag=dag)
print_param_task << first_operator
2.3.4.执行时传参
以bash_operator为例
在大多数的情况下,task中不会直接使用shell命令,而是执行一个shell脚本。在脚本内 “批处理日期” 一般不会写死,那么执行该脚本时需要给它指定这么一个 “批处理日期”,大多数时候是传一个昨天的日期。
创建一个shell脚本如下:
batch_date的值通过formate_date_str得来,而formate_date_str是执行脚本时给的第二个参数
#!/bin/bash
source ~/.bash_profile
job_rootpath=/appcom/data-mark-apps
#initialize tool-function
source ${job_rootpath}/shell-common-config/common_shell_function.properties
#Workflow paramters
shell_name=$0
wf_name=$1
formate_date_str=$2
output_path=$3
#Data defined
batch_date=`date -d "${formate_date_str}" +"%Y-%m-%d"`
batchDateStr=`date -d "${formate_date_str}" +"%Y%m%d"`
timestr=`date +"%s%N"`
#db paramters
out_db_name=file
out_table=mid_hr_tongdun_dq
input_table=tb_interface_log
orcle_pwd=`get_db_password edmp`
mysql_pwd=`get_db_password rds`
oracle_url=`get_db_url edmp`
mysql_url=`get_db_url rds`
#job paramters
interface_id=hx_lihapu_dq
outputpath=/app/bk/parseFile/${interface_id}
selectSql="select a.* from kb.${input_table} a where request_date=date'${batch_date}' and inteface_id = '${interface_id}' and iscached = 'F'"
echo $selectSql
jsonParse_jarpath=${job_rootpath}/json-parse-jars/janalyzer-2.0.0.jar
########################################################################################
#shell-note : java程序解析ods层到mid层
#create-by : cassiel
#create-date : 2022-06-08 14:30:45
#updated-by :
#updated-date :
#updated-notes :
#jsonParse execution start
func_mysql_insert
echo "========================================================"
echo `date +"%Y-%m-%d %X"` "#INFO : Script execution start!"
echo "========================================================"
java -jar
${jsonParse_jarpath}
"${batch_date}"
"${outputpath}"
"${selectSql}" "${orcle_pwd}" "${mysql_pwd}" "${oracle_url}" "${mysql_url}" 1> ~/appcom/logs/exec_result_${timestr}.log 2>&1
exitCodeCheck $?
echo `date +"%Y-%m-%d %X"` "#INFO : Data insert into file ok!"
#get execution reault data
cat ~/appcom/logs/exec_result_${timestr}.log
exe_result=`cat ~/appcom/logs/exec_result_${timestr}.log`
insert_data_cnt=`tail -4 ~/appcom/logs/exec_result_${timestr}.log | grep "已解析" | awk -F'已解析' '{print $2}'`
#shell execute ends
func_mysql_update
rm -rf ~/appcom/logs/exec_result_${timestr}.log
echo "========================================================"
echo `date +"%Y-%m-%d %X"` "#INFO : Script execution complete!"
echo "========================================================"
DAG文件中如此传值 :
可以使用Jinja模板的airflow内置参数方式进行
# pyhton-note : test shell script
# created-by : cassiel
# created-date : 2022-06-11 14:15:32
# updated-by :
# updated-date :
# updated-notes:
#########################################################################################
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
default_args = {
'owner':'airflow',
'start_date':datetime(2022, 6, 1),
'retries': 3,
'retry_delay': timedelta(minutes=1)
}
dag = DAG(
dag_id = 'execute_shell_sh',
default_args=default_args,
schedule_interval=timedelta(minutes=1),
catchup = False,
start_date = datetime(2022, 6, 11)
)
shell_task=BashOperator(
task_id='shell_task',
bash_command='sh /home/airflow/ods_java_parse_json.sh abcd {{ yesterday_ds }}',
dag = dag
)
可以使用Jinja模板的自定义参数的方式进行
# pyhton-note : test shell script
# created-by : cassiel
# created-date : 2022-06-11 14:15:32
# updated-by :
# updated-date :
# updated-notes:
#########################################################################################
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
default_args = {
'owner':'airflow',
'start_date':datetime(2022, 6, 1),
'retries': 3,
'retry_delay': timedelta(minutes=1),
'params': {'yesterday': '2022-06-11'}
}
dag = DAG(
dag_id = 'execute_shell_sh',
default_args=default_args,
schedule_interval=timedelta(minutes=1),
catchup = False,
start_date = datetime(2022, 6, 11)
)
shell_task=BashOperator(
task_id='shell_task',
bash_command='sh /home/airflow/ods_java_parse_json.sh abcd {{ params.yesterday }}',
dag = dag
)
可以使用Python的datetime库的方式进行
# pyhton-note : test shell script
# created-by : cassiel
# created-date : 2022-06-11 14:15:32
# updated-by :
# updated-date :
# updated-notes:
#########################################################################################
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
default_args = {
'owner':'airflow',
'start_date':datetime(2022, 6, 1),
'retries': 3,
'retry_delay': timedelta(minutes=1)
}
dag = DAG(
dag_id = 'execute_shell_sh',
default_args=default_args,
schedule_interval=timedelta(minutes=1),
catchup = False,
start_date = datetime(2022, 6, 11)
)
shell_task=BashOperator(
task_id='shell_task',
bash_command='sh /home/airflow/ods_java_parse_json.sh abcd %s'%(datetime.now()-timedelta(days=1)).strftime('%Y-%m-%d'),
dag = dag
)
2.4.配置自动部署脚本
多数情况下,dags和任务的脚本都存放在代码版本管理平台上,例如git、gitlab、gitee、svn上等等。
- 将开发的需求(包含了任务脚本和dag文件)测试OK后上传到分支
- 在上线前请求合并到主分支
- 合并后的主分支,点击发布按钮后,将会将最新的代码脚本和dag文件部署到airflow集群中,并对其进行激活和执行
那这种部署到生产集群的操作并非人工手动在命令行上的操作,而是在点击发布的时候调用了 “自动部署的脚本” ;
具体的操作参考 “七、Airflow集成Jekins自动部署”
3.Airflow系统自带operator
airflow默认的op目前有一下几种operator:
- BashOperator :执行一个bash命令或者脚本
- PythonOperator :调用一个python函数执行
- EmailOperator :发送一条邮件
- HTTPOperator :发送HTTP请求
- SqlOperator :执行一个SQL语句,若是使用对应数据库的需要安装依赖(mysql、postgresql等等),并在connections中配置
- Sensor : waits for a certain time, file, database row, S3 key, etc…
3.1.PythonOperator
PythonOperator是默认op,不需要指定conn_id
pythonOperator常用属性
- python_callable(python callable):调用的python函数
- op_kwargs(dict):调用python函数对应的 **args 参数,dict格式,使用参照案例。
- op_args(list):调用python函数对应的 *args 参数,多个封装到一个tuple中,list格式,使用参照案例。
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
# 定义默认参数
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2022, 5, 15, 10, 0),
'email': ['airflow1@example.com'],
'email_on_failure': True,
'email_on_retry': True,
'retries': 3,
'retry_delay': timedelta(seconds=5)
# 'end_date': datetime(2032, 1, 1), # 结束时间,注释掉就会一直执行下去
}
# 定义一个DAG
dag = DAG(
dag_id='hello_world',
default_args=default_args,
# schedule_interval="00 * * * *"
schedule_interval=timedelta(minutes=1)
)
"""
1.通过PythonOperator定义执行python函数的任务
"""
# Python函数1
def hello_world_1():
current_time = str(datetime.today())
with open('/root/tmp/hello_world_1.txt', 'a') as f:
f.write('%sn' % current_time)
assert 1 == 1 # 可以在函数中使用assert断言来判断执行是否正常,也可以直接抛出异常
# Python函数2
def hello_world_2():
current_time = str(datetime.today())
with open('/root/tmp/hello_world_2.txt', 'a') as f:
f.write('%sn' % current_time)
# 定义要执行的task 1
hello_world_1 = PythonOperator(
task_id='hello_world_1', # task_id
python_callable=hello_world_1, # 指定要执行的函数
dag=dag, # 指定归属的dag
retries=2, # 重写失败重试次数,如果不写,则默认使用dag类中指定的default_args中的设置
)
# 定义要执行的task 2
hello_world_2 = PythonOperator(
task_id='hello_world_2', # task_id
python_callable=hello_world_2, # 指定要执行的函数
dag=dag, # 指定归属的dag
)
hello_world_1 >> hello_world_2
3.2.BashOperator
BashOperator是默认op,不需要指定conn_id
3.2.1.执行shell命令
# pyhton-note : test shell command. not shell script
# created-by : cassiel
# created-date : 2022-06-10 10:34:26
# updated-by :
# updated-date :
# updated-notes:
#########################################################################################
from datetime import timedelta
import airflow
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(2),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5)
}
dag = DAG(
dag_id='hello_airflow',
default_args=default_args,
description='first DAG',
schedule_interval=timedelta(days=1)
)
t1 = BashOperator(
task_id='print_date',
bash_command='date',
dag=dag
)
t2 = BashOperator(
task_id='sleep',
depends_on_past=False,
bash_command='sleep 5',
dag=dag
)
# 这里使用了jinja模板,具体参考 “四、Airflow开发详解”中的“4.Airflow附加功能”的“2.10.Jiaja模板”
templated_command = """
{% for i in range(5) %}
echo "{{ ds }}"
echo "{{ macros.ds_add(ds, 7)}}"
echo "{{ params.print_value }}"
{% endfor %}
"""
t3 = BashOperator(
task_id='templated',
depends_on_past=False,
bash_command=templated_command,
params={'print_value': 'hello world! hello airflow!'},
dag=dag,
)
t1 >> [t2, t3]
3.2.1.执行shell脚本
准备如下两个shell脚本,将以下两个脚本放在$AIRFLOW_HOME/dags目录下,
BashOperator默认执行脚本时,默认从/tmp/airflow**临时目录查找对应脚本,由于临时目录名称不定,这里建议执行脚本时,在“bash_command”中写上绝对路径。如果要写相对路径,可以将脚本放在/tmp目录下,在“bash_command”中执行命令写上“sh …/xxx.sh”也可以。
first_shell.sh
#!/bin/bash
dt=$1
echo "==== execute first shell ===="
echo "---- first : time is ${dt}" >> ~/test1.txt
second_shell.sh
#!/bin/bash
dt=$1
echo "==== execute second shell ===="
echo "---- second : time is ${dt}" >> ~/test1.txt
编写execute_shell_sh.py 配置:
# pyhton-note : test shell script
# created-by : cassiel
# created-date : 2022-06-11 14:15:32
# updated-by :
# updated-date :
# updated-notes:
#########################################################################################
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
default_args = {
'owner':'airflow',
'start_date':datetime(2022, 6, 1),
'retries': 3,
'retry_delay': timedelta(minutes=1)
}
dag = DAG(
dag_id = 'execute_shell_sh',
default_args=default_args,
schedule_interval=timedelta(minutes=1),
catchup = False,
start_date = datetime(2022, 6, 11)
)
first=BashOperator(
task_id='first',
bash_command='sh /home/airflow/first_shell.sh %s'%datetime.now().strftime("%Y-%m-%d"),
dag = dag
)
second=BashOperator(
task_id='second',
bash_command='sh /home/airflow/second_shell.sh %s'%datetime.now().strftime("%Y-%m-%d"),
dag=dag
)
first >> second
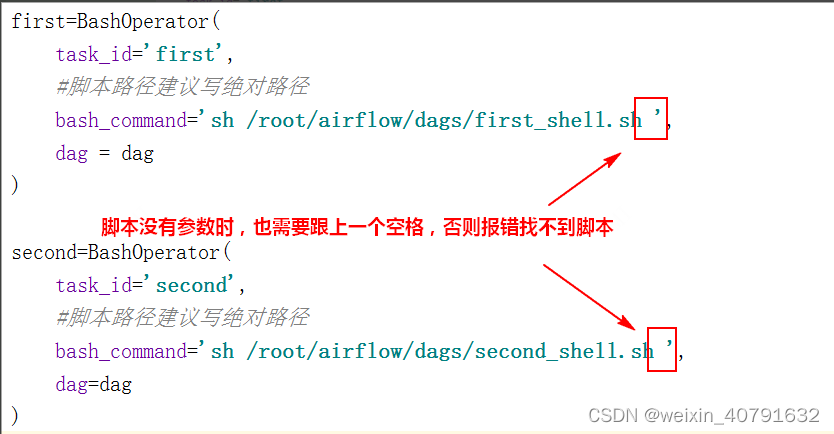
**特别注意:**在“bash_command”中写执行脚本时,一定要在脚本后跟上空格,有没有参数都要跟上空格,否则会找不到对应的脚本。如下:

# pyhton-note : extract province,city and area infomations
# created-by : cassiel
# created-date : 2022-06-11 17:15:32
# updated-by :
# updated-date :
# updated-notes:
#########################################################################################
from datetime import datetime, timedelta
import airflow
from airflow import DAG
from airflow.models import Variable
from airflow.operators.bash_operator import BashOperator
from airflow.operators.dummy_operator import DummyOperator
dags_folder_path = Variable.get("dags_folder_path")
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(2),
'email': ['798320307@qq.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 3,
'retry_delay': timedelta(minutes=1)
}
dag = DAG(
dag_id='sqoop_ods_sys_province_city_area',
description='抽取全国省份、城市、区域数据',
default_args=default_args,
schedule_interval='30 4 * * *',
dagrun_timeout=timedelta(minutes=60)
)
# extract province info
extract_sys_province = BashOperator(
task_id='extract_sys_province',
bash_command='%s/sqoop/ods/shell/sys_province.sh '%(dags_folder_path),
dag=dag
)
# extract city info
extract_sys_city = BashOperator(
task_id='extract_sys_city',
bash_command='%s/sqoop/ods/shell/sys_city.sh '%(dags_folder_path),
dag=dag,
)
# extract area info
extract_sys_area = BashOperator(
task_id='extract_sys_area',
bash_command='%s/sqoop/ods/shell/sys_area.sh '%(dags_folder_path),
dag=dag,
)
extract_sys_province >> extract_sys_city >> extract_sys_area
3.3.EmailOperator
参考官网的说明
3.4.HTTPOperator
参考官网的说明
3.5.SqlOperator
参考官网的说明
3.6.Sensor
3.6.1.airflow.sensors.external_task_sensor
说明:在当前DAG文件中指定一个非本DAG文件中的DAG对应的某个task在完成之后,再执行该DAG的某个Task。
- task_id : 该sensor的task id
- external_dag_id : 外部依赖的一个dag id
- external_task_id : 外部依赖的dag某一个task id,若不指定task,则给None
- external_task_ids : 外部依赖的dag某几个task id [‘task1’,‘task2’,‘task3’]
- allowed_states : 列出task允许的状态,default是success [‘success’]
- execution_dalte : 与执行的external任务的时间差,即往前推多少个小时内有一个成功的记录
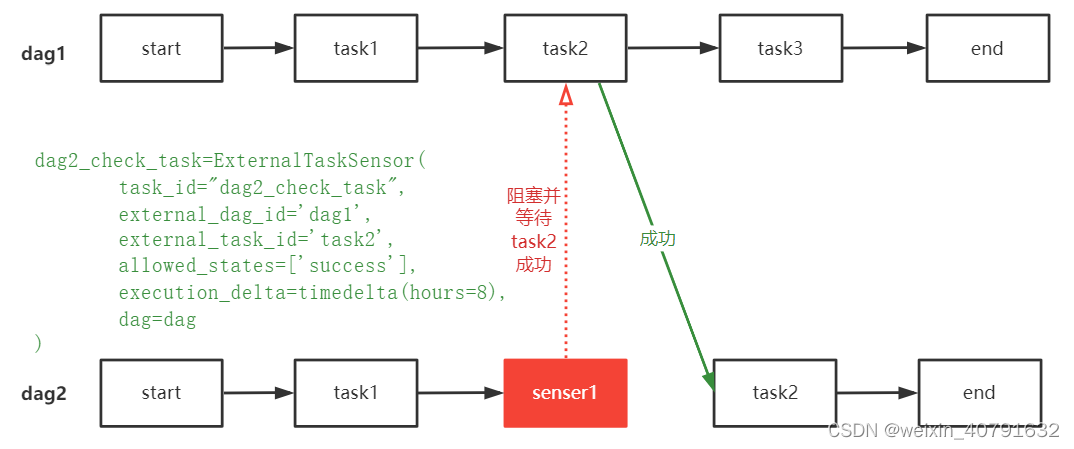
import airflow
from airflow.models import DAG
from airflow.operators.bash import BashOperator
from airflow.sensors.external_task_sensor import ExternalTaskSensor
from datetime import datatime, timedelta
default_args = {
'owner':'airflow',
'start_date':datetime(2022, 6, 1),
'retries': 1,
'retry_delay': timedelta(minutes=1)
}
dag = DAG(
dag_id= dag2,
default_args=default_args,
.......
)
dag1_check_task=ExternalTaskSensor(
# 指定该dag的名称,在airflow列表页面显示的就是这个任务的id名称
task_id="dag1_check_task",
# 指定依赖哪一个dag的id
external_dag_id='dag1',
# 指定依赖dag的哪一个task任务
external_task_id='task2',
# 列出允许的states,default是success
allowed_states=['success'],
# 与执行的external任务的时间差,即往前推8个小时内有一个成功的dag1的记录
execution_delta=timedelta(hours=8),
dag=dag
)
dg2_task_1=BashOperator(
task_id='dg2_task_1',
...
)
dg2_task_2=BashOperator(
task_id='dg2_task_2',
...
)
dg2_task_1 >> dag1_check_task >> dag2_task_2
3.6.2.airflow.sensors.hive_partition_sensor
说明:用于检查hive表的分区是否存在
from airflow.sensors.hive_partition_sensor import HivePartitionSensor
# 用于检查hive分区是否生成
check_hive_partition= HivePartitionSensor(
task_id='check_hive_artition_task', # 当前sensor任务ID
metastore_conn_id='hive-conn', # hive的hive_metastore连接,可点击ariflow web界面的Connection进行配置
schema='default', # 如果是default,那么table里要加上库名
table='库名.表名', # 需要检查的hive表名
poke_interval=300, # 两次检查的间隔时间,单位秒。建议该值不小于60。
partition="ds='{{ ds }}'" # 需要检测的分区,分区格式需要实际情况
)
3.6.2.airflow.sensors.hive_partition_sensor
说明:通过连接hive元数据所在的mysql数据库,来检查hive表的分区是否存在,是airflow.sensors.hive_partition_sensor的体待方案,这个远比查询hive要快的多
from airflow.sensors.hive_partition_sensor.MetastorePartitionSensor
# 用于检查hive分区是否生成
check_hive_partition= MetastorePartitionSensor(
task_id='check_hive_artition_task', # 当前sensor任务ID
mysql_conn_id='mysql-conn', # hive的元数据库连接,可点击ariflow web界面的Connection进行配置
schema='default', # 如果是default,那么table里要加上库名
table='库名.表名', # 需要检查的hive表名
partition="ds='{{ ds }}'" # 需要检测的分区,分区格式需要实际情况
)
3.6.3.airflow.providers.apache.hive.sensors.named_hive_partition
说明:用法基本和airflow.sensors.hive_partition_sensor一致
3.6.4.多个sensor模块
参考官网:https://airflow.apache.org/docs/apache-airflow/2.2.5/_api/airflow/sensors/index.html
4.Airflow自定义Operator
正常情况下shell脚本或python脚本可以涵盖所有的开发模式,对于operator不需要过多的进行自定义,下面是几种可能比较常用的Operator.
自定义的operator都有自己一套参数,具体需要哪些参数可以参考官网描述
https://airflow.apache.org/docs/apache-airflow/stable/_api/airflow/operators
4.1.SSHOperator
SSHOperator不是默认op,需要安装connection,并在dag中单独指定conn_id
在实际的调度任务中,任务脚本大多分布在不同的机器上,可以使用SSHOperator来调用远程机器上的脚本任务。SSHOperator使用ssh协议与远程主机通信,需要注意的是SSHOperator调用脚本时并不会读取用户的配置文件,最好在脚本中加入以下代码以便脚本被调用时会自动读取当前用户的配置信息
#Ubuntu系统
source ~/.profile
#CentoOS或者RedHat系统
source ~/.bashrc
4.1.1.安装ssh的依赖
若是分布式,每台服务器都需要安装
# 登录虚拟miniconda
[airflow@centos003 ~]# su - airflow
# 进入airflow的虚拟环境
(base) [airflow@centos003 ~]# source activate airflow
# 安装ssh的hook依赖
(airflow) [airflow@centos003 ~]# pip3 install "apache-airflow[ssh]~=2.2.5"
# v2.2.5不需要重启airflow
4.1.2.配置SSH Connection连接
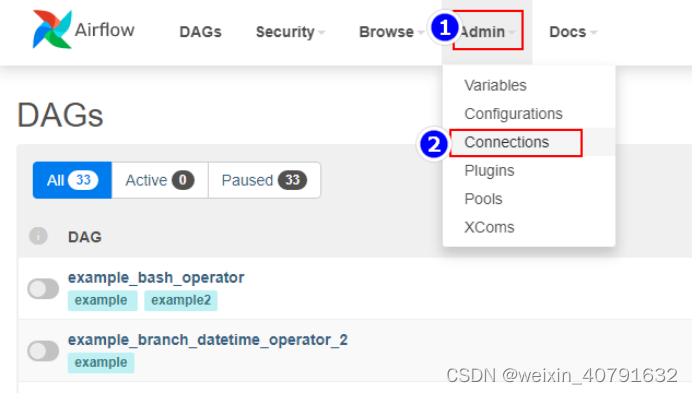
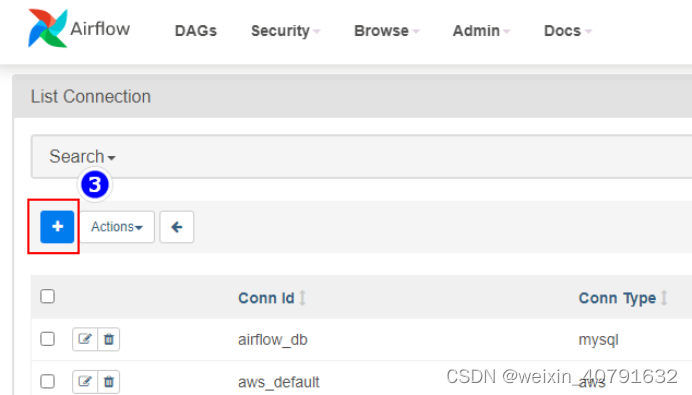
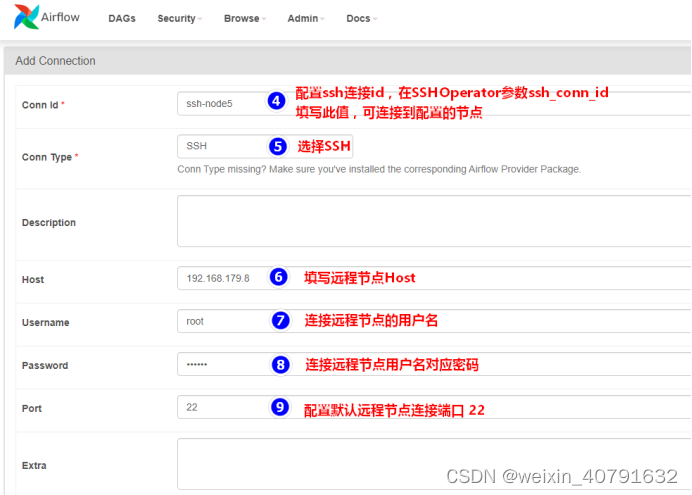
点击“+”添加连接,这里的host是在airflow集群意外的节点
- Conn id可以随便填写,但不能和其他的重复,要保持唯一
- Description中不可以填写中文,会报错的
4.1.3.准备远程执行脚本
在远程节点1(192.168.179.8)的/root路径下创建first_shell.sh ,内容如下:
#!/bin/bash
echo "==== execute first shell ===="
在远程节点2(192.168.179.6)的/root路径下创建second_shell.sh,内容如下:
#!/bin/bash
echo "==== execute second shell ===="
4.1.4.SSHOperator的常用属性
| 属性 | 数据类型 | 说明 |
|---|---|---|
| ssh_conn_id | string | ssh连接id,名称自取,需要在airflow webserver界面配置,具体配置参照案例。 |
| remote_host | string | 远程连接节点host,如果配置,可替换ssh_conn_id中配置的远程host,可选。 |
| command | string | 在远程主机上执行的命令或脚本。 |
4.1.5.编写DAG python配置文件
execute_remote_shell.py
# pyhton-note : Test remote execution shell script with SSHOperator
# created-by : cassiel
# created-date : 2022-06-11 17:15:32
# updated-by :
# updated-date :
# updated-notes:
#########################################################################################
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.providers.ssh.operators.ssh import SSHOperator
default_args = {
'owner':'airflow',
'start_date':datetime(2026, 6, 1),
'retries': 3,
'retry_delay': timedelta(minutes=1)
}
dag = DAG(
dag_id = 'execute_remote_shell',
default_args=default_args,
schedule_interval=timedelta(minutes=1)
catchup = False
)
first=SSHOperator(
task_id='first',
ssh_conn_id='ssh-node5',
command='sh /root/first_shell.sh ',
dag = dag
)
second=SSHOperator(
task_id='second',
ssh_conn_id='ssh-node5',
command='sh /root/second_shell.sh ',
remote_host="192.168.179.6", #if you sets remote_host, will replace Connection's SSH setting
dag=dag
)
first >> second
4.2.PostgresOperator
4.2.1.安装Postgres的依赖
若是分布式,每台服务器都需要安装
# 登录虚拟miniconda
[airflow@centos003 ~]# su - airflow
# 进入airflow的虚拟环境
(base) [airflow@centos003 ~]# source activate airflow
# 安装ssh的hook依赖
(airflow) [airflow@centos003 ~]# pip3 install "apache-airflow[postgres]~=2.2.5"
# v2.2.5不需要重启airflow
4.2.2.配置Postgres Connection连接
依赖安装完毕后在 Admin --> Providers 中就可以查到安装的依赖版本和描述信息
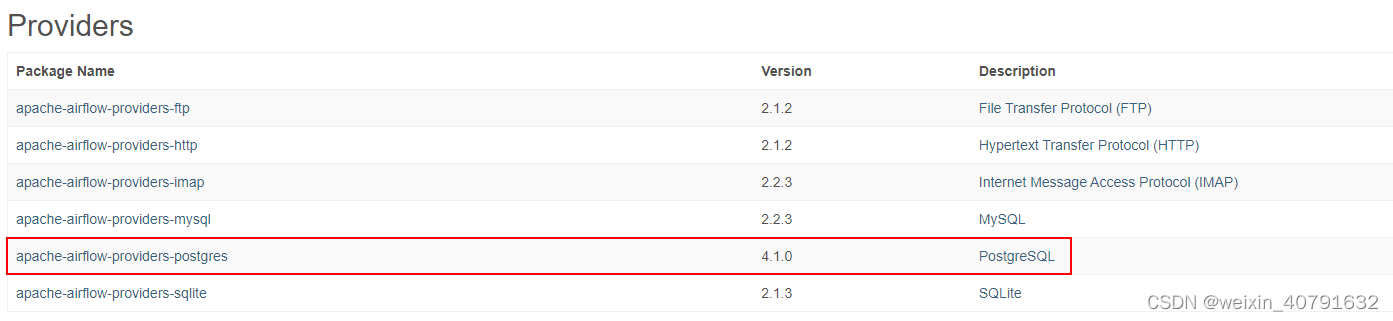
再新增connection时type就可以选择了
4.2.3.PostgresOperator的常用属性
| 属性 | 数据类型 | 说明 |
|---|---|---|
| postgres_conn_id | string | postgresql、ali adb、grennplum的连接id名 |
| sql | string | 可以是sql命令,也可以是sql脚本(sql脚本需要以 .sql 结尾) |
| autocommit | boolean | 如果为 True,则自动提交每个命令。(默认值:假) |
| database | string | 覆盖连接中定义的数据库的名称 |
4.2.4.编写DAG python配置文件
execute_greenplum_sql_script.py
# pyhton-note : Test PostgresOperator
# created-by : cassiel
# created-date : 2022-06-11 17:15:32
# updated-by :
# updated-date :
# updated-notes:
#########################################################################################
from airflow import DAG
from airflow.providers.ssh.operators.ssh import PostgresOperator
from datetime import datetime, timedelta
default_args = {
'owner':'airflow',
'start_date':datetime(2026, 6, 1),
'retries': 3,
'retry_delay': timedelta(minutes=1)
}
dag = DAG(
dag_id = 'execute_greenplum_sql_script',
default_args=default_args,
schedule_interval=timedelta(minutes=1)
catchup = False
)
first = PostgresOperator(
task_id='pt_360_zx_indv_cust_cont_tel_h',
postgres_conn_id='greenplum_adb',
sql='/apps/fds/sql/pt_360_zx_indv_cust_cont_tel_h.sql',
dag=dag
)
second = PostgresOperator(
task_id='pt_360_zx_indv_cust_phys_addr_h',
postgres_conn_id='greenplum_adb',
sql='/apps/fds/sql/pt_360_zx_indv_cust_phys_addr_h.sql',
dag=dag
)
first >> second
4.3.HiveOperator
由于Airflow 使用HiveOperator时需要在Airflow安装节点上有Hive客户端,所以要确保airflow的集群中都需要有hive客户端
4.3.1.安装Hive的依赖
若是分布式,每台服务器都需要安装
# 登录虚拟miniconda
[airflow@centos003 ~]# su - airflow
# 进入airflow的虚拟环境
(base) [airflow@centos003 ~]# source activate airflow
# 安装ssh的hook依赖
(airflow) [airflow@centos003 ~]# pip3 install "apache-airflow[hive]~=2.2.5"
# v2.2.5不需要重启airflow
4.3.2.配置Hive Connection连接
点击“+”添加连接,这里的host是在airflow集群意外的节点
- Conn id可以随便填写,但不能和其他的重复,要保持唯一
- Description中不可以填写中文,会报错的
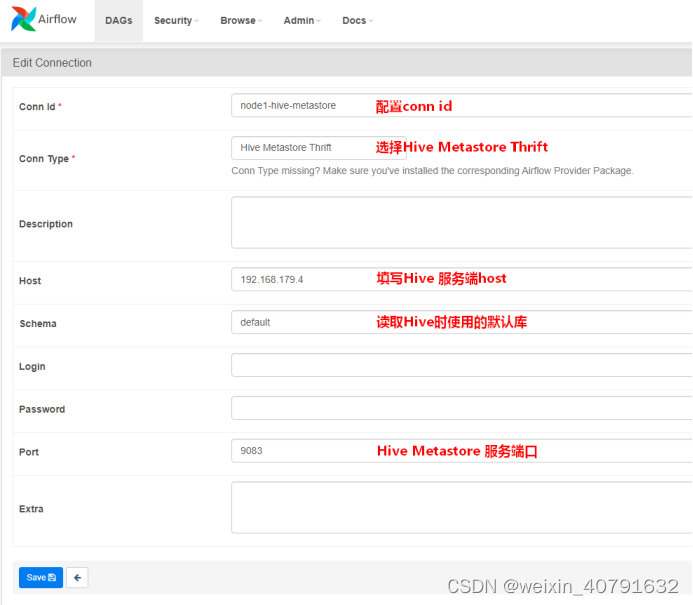
4.3.3.HiveOperator的常用属性
更多参数仓靠官网:https://airflow.apache.org/docs/apache-airflow-providers-apache-hive/stable/_api/airflow/providers/apache/hive/operators/hive/index.html#module-airflow.providers.apache.hive.operators.hive
| 属性 | 数据类型 | 说明 |
|---|---|---|
| hive_cli_conn_id | string | 连接Hive的conn_id,在airflow webui connection中配置的 |
| hql | string | 需要执行的Hive SQL |
4.3.4.编写DAG python配置文件
execute_hive_sql.py
# pyhton-note : Test hive sql command
# created-by : cassiel
# created-date : 2022-06-11 17:15:32
# updated-by :
# updated-date :
# updated-notes:
#########################################################################################
from datetime import datetime, timedelta
from airflow import DAG
from airflow.providers.apache.hive.operators.hive import HiveOperator
default_args = {
'owner':'airflow',
'start_date':datetime(2022, 6, 1),
'retries': 3,
'retry_delay': timedelta(minutes=1)
}
dag = DAG(
dag_id = 'execute_hive_sql',
default_args=default_args,
schedule_interval=timedelta(minutes=1),
catchup = False
)
first=HiveOperator(
task_id='person_info',
hive_cli_conn_id="node1-hive-metastore",
hql='select id,name,age from person_info',
dag = dag
)
second=HiveOperator(
task_id='score_info',
hive_cli_conn_id="node1-hive-metastore",
hql='select id,name,score from score_info',
dag=dag
)
third=HiveOperator(
task_id='join_info',
hive_cli_conn_id="node1-hive-metastore",
hql='select a.id,a.name,a.age,b.score from person_info a join score_info b on a.id = b.id',
dag=dag
)
first >> second >>third
5.DAG和子DAG
SubDAG非常适合重复模式。 在使用Airflow时,定义一个返回DAG对象的函数是一个很好的设计模式。
Airbnb在加载数据时使用stage-check-exchange模式。 数据在临时表中暂存,然后对该表执行数据质量检查。 一旦检查全部通过,分区就会移动到生产表中。
再举一个例子,考虑以下DAG:
我们可以将所有并行task-* operators组合到一个SubDAG中,生成的DAG类似于以下内容:

请注意,SubDAG operators应包含返回DAG对象的工厂方法。 这将阻止SubDAG在main UI中被视为单独的DAG。
例如:
#dags/subdag.py
from airflow.models import DAG
from airflow.operators.dummy_operator import DummyOperator
# Dag is returned by a factory method
def sub_dag(parent_dag_name, child_dag_name, start_date, schedule_interval):
dag = DAG(
'%s.%s' % (parent_dag_name, child_dag_name),
schedule_interval=schedule_interval,
start_date=start_date,
)
dummy_operator = DummyOperator(
task_id='dummy_task',
dag=dag,
)
return dag
然后可以在主DAG文件中引用此SubDAG:
# main_dag.pyfrom datetime import datetime, timedeltafrom airflow.models import DAGfrom airflow.operators.subdag_operator import SubDagOperatorfrom dags.subdag import sub_dag
PARENT_DAG_NAME = 'parent_dag'CHILD_DAG_NAME = 'child_dag'
main_dag = DAG(
dag_id=PARENT_DAG_NAME,
schedule_interval=timedelta(hours=1),
start_date=datetime(2016, 1, 1))
sub_dag = SubDagOperator(
subdag=sub_dag(PARENT_DAG_NAME, CHILD_DAG_NAME, main_dag.start_date,
main_dag.schedule_interval),
task_id=CHILD_DAG_NAME,
dag=main_dag,)
使用SubDAG时的一些其他提示:
- 按照惯例,SubDAG的dag_id应以其父级和点为前缀。 和在parent.child中一样。
- 通过将参数传递给SubDAG operator来共享主DAG和SubDAG之间的参数(如上所示)。
- SubDAG必须有一个计划并启用。 如果SubDAG的时间表设置为None或@once,SubDAG将成功完成而不做任何事情。
- 清除SubDagOperator也会清除其中的任务状态。
- 在SubDagOperator上标记成功不会影响其中的任务状态。
- 避免在SubDAG中的任务中使用depends_on_past=True,因为这可能会造成混淆。
- 可以为SubDAG指定执行程序。 如果要在进程中运行SubDAG并有效地将其并行性限制为1,则通常使用SequentialExecutor。 使用LocalExecutor可能会有问
- 题,因为它可能会过度订阅你的worker,在单个插槽中运行多个任务。
6.Airflow附加功能
6.1.Hooks
挂钩(Hooks)是一个外部平台的高级接口,可让你无需编写访问API /使用特殊库的代码,就能快速轻松地与这些平台沟通挂钩(Hooks)与连接(Connections)集成,共同收集凭证你可以在 Airflow 的 API 文档中查看Airflow挂钩的完整列表
钩子是外部平台和数据库的接口,如Hive,S3,MySQL,Postgres,HDFS和Pig。 Hooks尽可能实现通用接口,并充当operator的构建块。 他们使用airflow.models.Connection模型来获取主机名和身份验证信息。 钩子将身份验证代码和信息保存在pipeline之外,集中在元数据数据库中。
钩子在Python脚本,Airflow airflow.operators.PythonOperator以及iPython或Jupyter Notebook等交互式环境中使用它们也非常有用。
6.2.Pools
当有太多进程同时需要执行时,某些系统可能会被淹没。 Airflow pools可用于限制任意任务集上的并发执行。 要以在UI(菜单 - > Admin- >pools)中管理pools列表,通过为pools命名并为其分配多个worker slots。 然后在创建任务时(即实例化operators),可以通过使用pools参数将task与现有pools之一相关联。
aggregate_db_message_job = BashOperator(
task_id='aggregate_db_message_job',
execution_timeout=timedelta(hours=3),
pool='ep_data_pipeline_db_msg_agg',
bash_command=aggregate_db_message_job_cmd,
dag=dag)aggregate_db_message_job.set_upstream(wait_for_empty_queue)
pool参数可以与priority_weight结合使用,以定义队列中的优先级,以及在pool中打开的slot时首先执行哪些任务。 默认的priority_weight是1,可以使用任何数字。 在对队列进行排序以评估接下来应该执行哪个任务时,我们使用priority_weight,与来自此任务下游任务的所有priority_weight值相加。 您可以使用它来执行特定的重要任务,并相应地优先处理该任务的整个路径。
当slot被填满时,任务将照常安排。 达到容量后,可运行的任务将排队,其状态将在UI中显示。 当插槽空闲时,排队的任务将根据priority_weight(任务及其后代)开始运行。
请注意,默认情况下,任务不会分配给任何池,并且它们的执行的并行性仅限于执行程序的设置。
6.4.Queues
使用CeleryExecutor时,可以指定发送任务的celery队列。 queue是BaseOperator的一个属性,因此任何任务都可以分配给任何队列。 环境的默认队列在airflow.cfg的celery - > default_queue中定义。 这定义了未指定任务时分配给的队列,以及Airflow工作程序在启动时侦听的队列。
Workers可以监听一个或多个任务队列。 当工作程序启动时(使用airflow worker命令),可以指定一组由逗号分隔的队列名称(例如,airflow worker -q spark)。 然后,该工作人员将仅接收连接到指定队列的任务。
如果您需要专用的workers,从资源角度来看(例如,一个worker可以毫无问题地执行数千个任务)或者从环境角度(比如您希望worker从Spark群集中运行,这可能非常有用 本身,因为它需要一个非常具体的环境和安全权限)。
6.5.Xcoms
请参考 “四、Airflow开发详解 -> 2.运行DAG任务 -> 2.3.传递参数 -> 2.3.3.Xcoms”
6.6.Variables
请参考 “四、Airflow开发详解 -> 2.运行DAG任务 -> 2.3.传递参数 -> 2.3.2.Variables”
6.7.Branching
有时需要一个工作流分支,或者只根据任意条件走下某条路径,这通常与上游任务中发生的事情有关。 一种方法是使用BranchPythonOperator。
BranchPythonOperator与PythonOperator非常相似,只是它需要一个返回task_id的python_callable。 返回task_id,并跳过所有其他路径。 Python函数返回的task_id必须直接引用BranchPythonOperator任务下游的任务。
请注意,在BranchPythonOperator的下游任务中使用depends_on_past = True,这在逻辑上是不合理的,因为skipped状态将总是
因为他们过去的successes而造成task的堵塞。
如果你想跳过一些任务,请记住你不能有一个空路径,如果是这样,那就做一个虚设任务。
像这样,跳过虚拟任务“branch_false”
6.8.SubDags
参考 “四、Airflow开发详解 -> 6.DAG和子DAG ”
6.9.SLAs
服务级别协议或任务/DAG应该成功的时间可以在任务级别设置为timedelta。 如果此时一个或多个实例未成功,则会发送警报电子邮件,详细说明错过其SLA的任务列表。 该事件也记录在数据库中,并可在Web UI中浏览,其中可以分析和记录事件。
6.10.Jinja模板
{% start %} {% end %}
{{ variable }}
{{}}使用请参考 “四、Airflow开发详解 -> 2.运行DAG任务 -> 2.3.传递参数 -> 2.3.1.Jinja模板”
7.Airflow的回调函数
airflow默认使用email来进行报警通知,但实际各个公司通信方式不仅仅有邮件,还有钉钉、企微、飞书等等,而且邮件的时效性不太好,通知可能无法达到指定管理人员。
airflow提供了回调功能,在回调功能里可以定义通知方式的operator
- on_failure_callback : 一个Python函数,失败的时候执行。
- on_success_callback : 一个Python函数,成功的时候执行
- on_retry_callback : 一个Python函数,重试的时候执行
7.1.使用钉钉最为报警通知方式
7.1.1.设置DingdingOperator
使用钉钉作为airflow报警通知方法, 后台 admin -> connections 去配置DingdingOperator,然后引用conn_id即可。
- 将自定义机器人添加到您要发送钉钉消息的钉钉组。
- 从钉钉定制机器人获取 webhook 令牌。
- 将钉钉自定义机器人令牌放入
dingding_defaultConnection的密码字段中。请注意,您只需要令牌而不是整个 webhook 字符串。
第一步:在钉钉页面(电脑端或手机端均可)获取自定义机器人Webhook
- 建立一个接受信息的群组(必须满足三个人才可以建群)
- 在群组中点击
群设置->智能群助手->添加机器人
完成安全设置后,复制出机器人的Webhook地址,可用于向这个群发送消息,格式如下
```http
https://oapi.dingtalk.com/robot/send?access_token=8923d7e1fa9d5b1904326f9b22a689ea78562070a535c7b0e3b8fe97daa5fded
```
第二步:在airflow的connections中设置connection
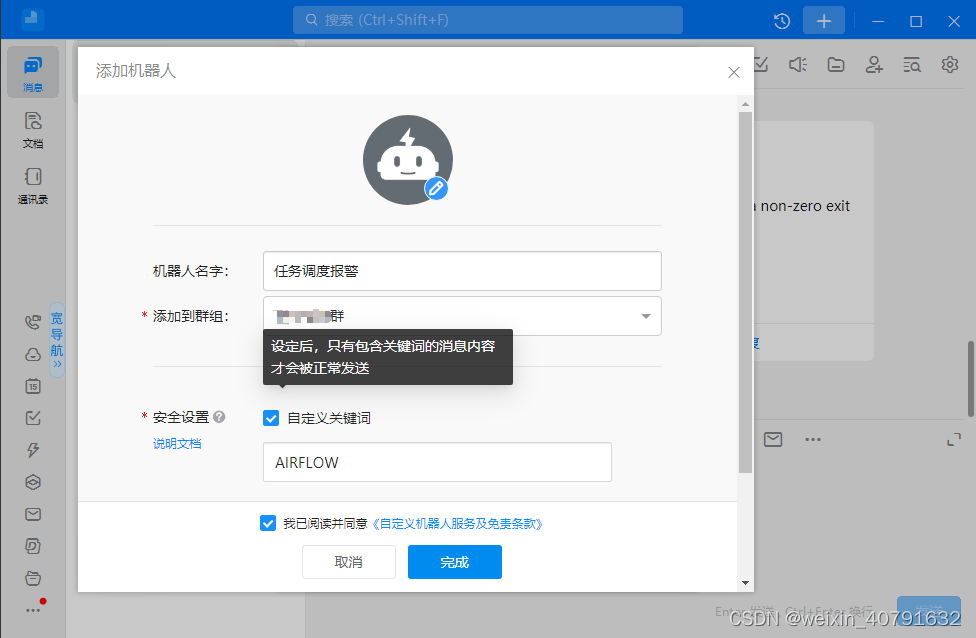
安装钉钉python依赖
# 安装了最新的3.0.0的dingding prociders
pip3 install apache-airflow-providers-dingding
7.1.2.编写钉钉回调函数
发送消息时使用参数at_mobiles和at_all提醒特定用户, at_mobiles将被忽略当at_all设置为True
# pyhton-note : Send alert message to Dingding on failure.
# created-by : cassiel
# created-date : 2022-06-12 12:33:46
# updated-by :
# updated-date :
# updated-notes:
#########################################################################################
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.providers.dingding.operators.dingding import DingdingOperator
# dingding
def failure_callback(context):
message = (
f"AIRFLOW TASK FAILURE TIPS:n"
f"DAG: {context['task_instance'].dag_id}n"
f"TASKS: {context['task_instance'].task_id}n"
f"Reason: {context['exception']}n"
)
return DingdingOperator(
task_id='failure_dingding_callback',
dingding_conn_id='dingding_default',
message_type='text',
message=message,
at_all=False, # at_mobiles will be ignored when at_all is set to True.
at_mobiles=['18551812179','18939797615']
).execute(context)
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2022, 5, 1),
'email': ['798320308o@qq.com'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=1),
'on_failure_callback': failure_callback,
# 'on_success_callback':failure_callback
}
dag = DAG(
dag_id = 'dingding_test',
default_args=default_args,
schedule_interval=timedelta(minutes=1),
catchup = False,
start_date = datetime(2022, 6, 11)
)
first=BashOperator(
task_id='first',
bash_command='sh /home/airflow/first_shell.sh %s'%(datetime.now()-timedelta(days=1)).strftime('%Y-%m-%d'),
dag = dag
)
second=BashOperator(
task_id='second',
bash_command='sh /home/airflow/second_shell.sh {{ ds }}',
dag=dag
)
first >> second
在first_shell.sh或second_shell.sh脚本中制造一些报错,例如分母为0的情况,一旦报错就会警报了
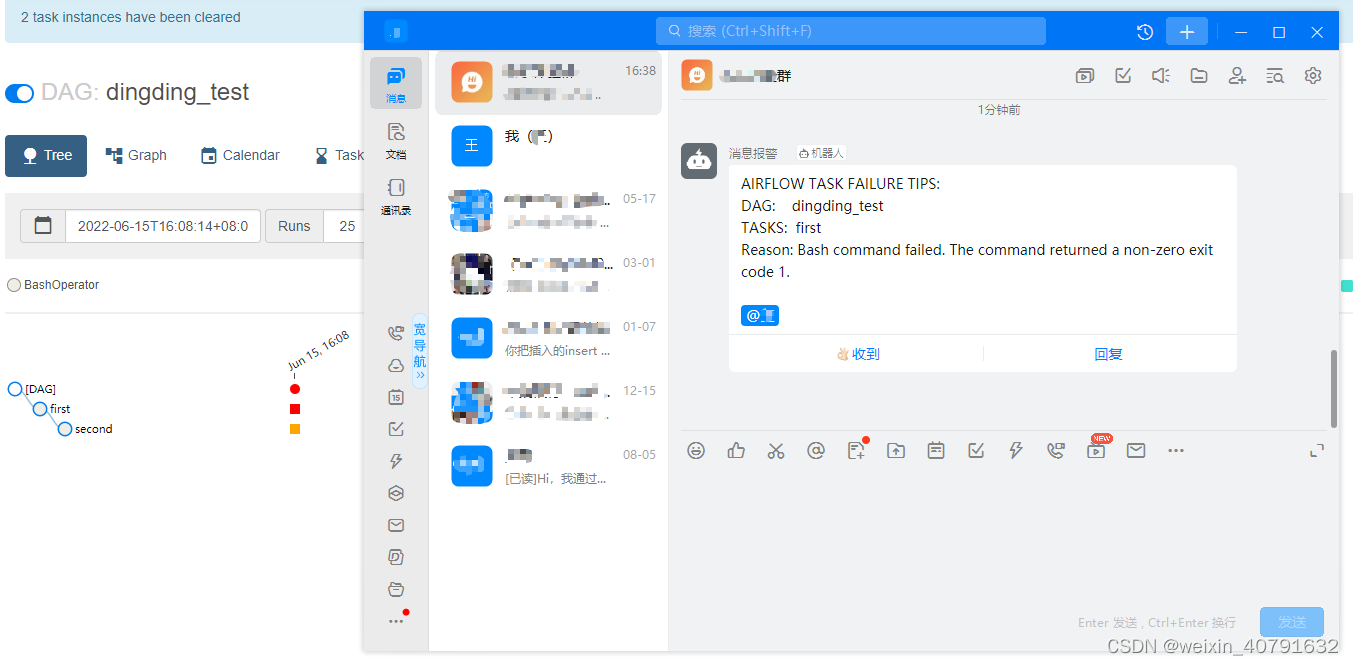
7.2.使用企微作为报警通知方式
7.2.1.设置WeixinOperator
下面的两个python文件要放到 dags 目录,也就是和dag的py文件放在一起才会有效果,这个wechat的hook和operater是根据官方的dingding.py v3.0.0版本改动而来的。
wechat_hook.py
import json
from typing import List, Optional, Union
import requests
from requests import Session
from airflow.exceptions import AirflowException
from airflow.providers.http.hooks.http import HttpHook
class WechatHook(HttpHook):
conn_name_attr = 'wechat_conn_id'
default_conn_name = 'wechat_default'
conn_type = 'http'
hook_name = 'Wechat'
def __init__(
self,
wechat_conn_id='wechat_default',
message_type: str = 'text',
message: Optional[Union[str, dict]] = None,
at_mobiles: Optional[List[str]] = None,
at_all: bool = False,
*args,
**kwargs,
) -> None:
super().__init__(http_conn_id=wechat_conn_id, *args, **kwargs) # type: ignore[misc]
self.message_type = message_type
self.message = message
self.at_mobiles = at_mobiles
self.at_all = at_all
def _get_endpoint(self) -> str:
"""Get WeChat endpoint for sending message."""
conn = self.get_connection(self.http_conn_id)
token = conn.password
if not token:
raise AirflowException(
'WeChat token is requests but get nothing, check you conn_id configuration.'
)
return f'cgi-bin/webhook/send?key={token}'
def _build_message(self) -> str:
"""
Build different type of WeChat message
As most commonly used type, text message just need post message content
rather than a dict like ``{'content': 'message'}``
"""
if self.message_type in ['text', 'markdown']:
data = {
'msgtype': self.message_type,
self.message_type: {'content': self.message} if self.message_type == 'text' else self.message,
'at': {'atMobiles': self.at_mobiles, 'isAtAll': self.at_all},
}
else:
data = {'msgtype': self.message_type, self.message_type: self.message}
return json.dumps(data)
def get_conn(self, headers: Optional[dict] = None) -> Session:
"""
Overwrite HttpHook get_conn because just need base_url and headers and
not don't need generic params
:param headers: additional headers to be passed through as a dictionary
"""
conn = self.get_connection(self.http_conn_id)
self.base_url = conn.host if conn.host else 'https://qyapi.weixin.qq.com'
session = requests.Session()
if headers:
session.headers.update(headers)
return session
def send(self) -> None:
"""Send WeChat message"""
support_type = ['text', 'link', 'markdown', 'actionCard', 'feedCard']
if self.message_type not in support_type:
raise ValueError(
f'WeChatWebhookHook only support {support_type} so far, but receive {self.message_type}'
)
data = self._build_message()
self.log.info('Sending WeChat type %s message %s', self.message_type, data)
resp = self.run(
endpoint=self._get_endpoint(), data=data, headers={'Content-Type': 'application/json'}
)
# WeChat success send message will with errcode equal to 0
if int(resp.json().get('StatusCode')) != 0:
raise AirflowException(f'Send WeChat message failed, receive error message {resp.text}')
self.log.info('Success Send WeChat message')
wechat_operator.py
from typing import TYPE_CHECKING, List, Optional, Sequence, Union
from airflow.models import BaseOperator
from wechat_hook import WechatHook
if TYPE_CHECKING:
from airflow.utils.context import Context
class WechatOperator(BaseOperator):
template_fields: Sequence[str] = ('message',)
ui_color = '#4ea4d4' # Wechat icon color
def __init__(
self,
*,
wechat_conn_id: str = 'wechat_default',
message_type: str = 'text',
message: Union[str, dict, None] = None,
at_mobiles: Optional[List[str]] = None,
at_all: bool = False,
**kwargs,
) -> None:
super().__init__(**kwargs)
self.wechat_conn_id = wechat_conn_id
self.message_type = message_type
self.message = message
self.at_mobiles = at_mobiles
self.at_all = at_all
def execute(self, context: 'Context') -> None:
self.log.info('Sending WeChat message.')
hook = WechatHook(
self.wechat_conn_id,
self.message_type,
self.message,
self.at_mobiles,
self.at_all
)
hook.send()
在企业微信群中创建机器人
-
企业微信右上角点击省略号
-
选择 [群机器人],进入之后点击 [添加机器人]
-
点击新建,输入机器人名字。 比如:任务调度报警
-
点击完成以后会得到一个Webhook地址
# 这个key的值就是机器人的ID https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=4797fda8-9319-53f4-ab3c-e19b4224206c -
在airflow中创建企业微信的连接:[主菜单] -> [Admin] -> [Connections],配置
Conn Id: wechat_default Conn Type: HTTP Host: https://qyapi.weixin.qq.com Password: 机器人的ID(key)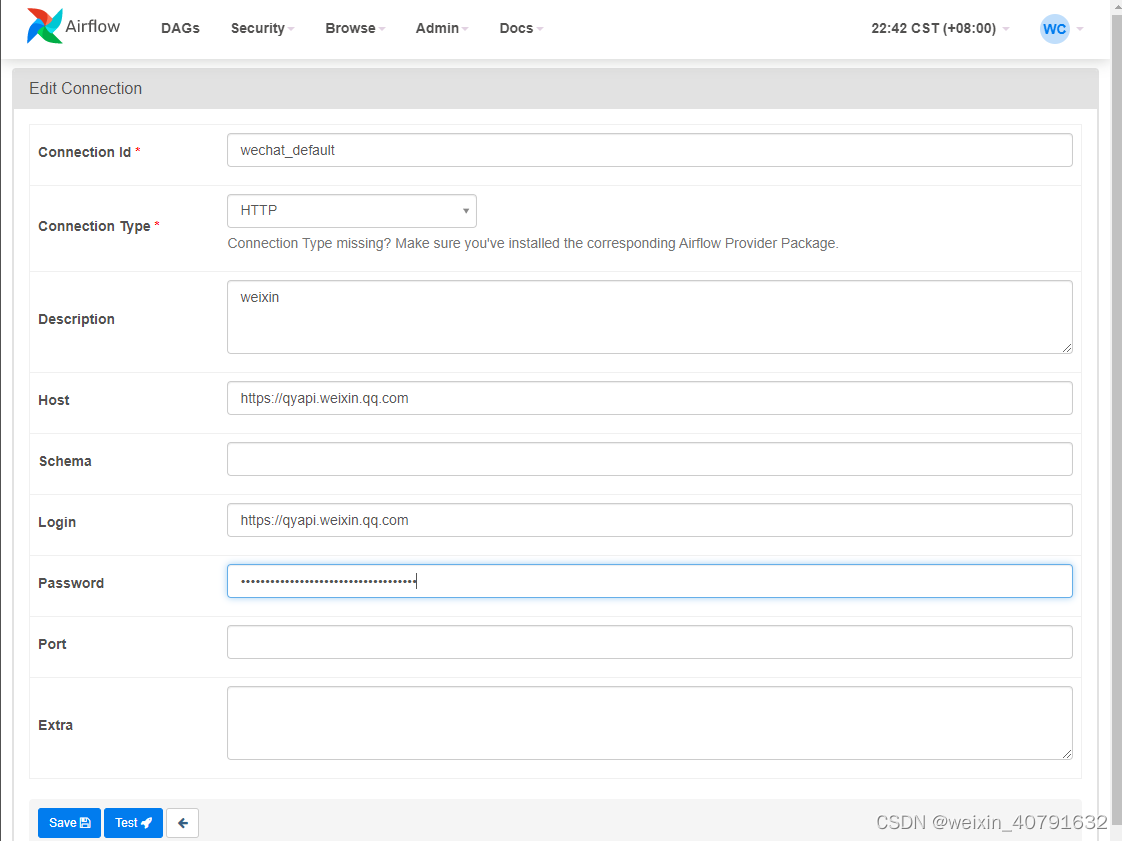
7.2.2.编写回调函数
weixin_failure_msg_test.py
# pyhton-note : Send alert message to Wechat on failure.
# created-by : cassiel
# created-date : 2022-06-12 12:33:46
# updated-by :
# updated-date :
# updated-notes:
#########################################################################################
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from wechat_operator import WechatOperator
# wechat
def failure_callback(context):
message = 'AIRFLOW TASK FAILURE TIPS:n'
'DAG: {}n'
'TASKS: {}n'
'Reason: {}n'
.format(context['task_instance'].dag_id,
context['task_instance'].task_id,
context['exception'])
return WechatOperator(
task_id='wechat_task',
wechat_conn_id='wechat_default',
message_type='text',
message=message,
at_all=True,
).execute(context)
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2022, 6, 11),
'email': ['798320308@qq.com'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=1),
'on_failure_callback': failure_callback,
# 'on_success_callback':failure_callback
}
dag = DAG(
dag_id = 'weixin_failure_msg_test',
default_args=default_args,
schedule_interval='*/1 * * * *',
catchup = False,
start_date = datetime(2022, 6, 14)
)
first=BashOperator(
task_id='first',
bash_command='sh /home/airflow/first_shell.sh %s'%(datetime.now()-timedelta(days=1)).strftime('%Y-%m-%d'),
dag=dag
)
second=BashOperator(
task_id='second',
bash_command='sh /home/airflow/second_shell.sh {{ ds }}',
dag=dag
)
first >> second
在first_shell.sh或second_shell.sh脚本中制造一些报错,例如分母为0的情况,一旦报错就会警报了
7.3.使用飞书作为报警通知方式
7.3.1.设置FeishuOperator
下面的两个python文件要放到 dags 目录,也就是和dag的py文件放在一起才会有效果,这个feishu的hook和operater是根据官方的dingding.py v3.0.0版本改动而来的。
feishu_hook.py
import json
from typing import List, Optional, Union
import requests
from requests import Session
from airflow.exceptions import AirflowException
from airflow.providers.http.hooks.http import HttpHook
class FeishuHook(HttpHook):
conn_name_attr = 'feishu_conn_id'
default_conn_name = 'feishu_default'
conn_type = 'http'
hook_name = 'Feishu'
def __init__(
self,
feishu_conn_id='feishu_default',
message_type: str = 'text',
message: Optional[Union[str, dict]] = None,
at_mobiles: Optional[List[str]] = None,
at_all: bool = False,
*args,
**kwargs,
) -> None:
super().__init__(http_conn_id=feishu_conn_id, *args, **kwargs) # type: ignore[misc]
self.message_type = message_type
self.message = message
self.at_mobiles = at_mobiles
self.at_all = at_all
def _get_endpoint(self) -> str:
"""Get Feishu endpoint for sending message."""
conn = self.get_connection(self.http_conn_id)
token = conn.password
if not token:
raise AirflowException(
'Feishu token is requests but get nothing, check you conn_id configuration.'
)
return f'open-apis/bot/v2/hook/{token}'
def _build_message(self) -> str:
"""
Build different type of Feishu message
As most commonly used type, text message just need post message content
rather than a dict like ``{'content': 'message'}``
"""
if self.message_type in ['text', 'markdown']:
data = {
'msg_type': self.message_type,
'content': {self.message_type: self.message} if self.message_type == 'text' else self.message,
}
else:
data = {'msg_type': self.message_type, self.message_type: self.message}
return json.dumps(data)
def get_conn(self, headers: Optional[dict] = None) -> Session:
"""
Overwrite HttpHook get_conn because just need base_url and headers and
not don't need generic params
:param headers: additional headers to be passed through as a dictionary
"""
conn = self.get_connection(self.http_conn_id)
self.base_url = conn.host if conn.host else 'https://open.feishu.cn'
session = requests.Session()
if headers:
session.headers.update(headers)
return session
def send(self) -> None:
"""Send Feishu message"""
support_type = ['text', 'link', 'markdown', 'actionCard', 'feedCard']
if self.message_type not in support_type:
raise ValueError(
f'FeishuWebhookHook only support {support_type} so far, but receive {self.message_type}'
)
data = self._build_message()
self.log.info('Sending Feishu type %s message %s', self.message_type, data)
resp = self.run(
endpoint=self._get_endpoint(), data=data, headers={'Content-Type': 'application/json'}
)
# Feishu success send message will with errcode equal to 0
if resp.json().get('StatusMessage') != 'success':
raise AirflowException(f'Send Feishu message failed, receive error message {resp.text}')
self.log.info('Success Send Feishu message')
feishu_operator.py
from typing import TYPE_CHECKING, List, Optional, Sequence, Union
from airflow.models import BaseOperator
from feishu_hook import FeishuHook
if TYPE_CHECKING:
from airflow.utils.context import Context
class FeishuOperator(BaseOperator):
template_fields: Sequence[str] = ('message',)
ui_color = '#4ea4d4' # Feishu icon color
def __init__(
self,
*,
feishu_conn_id: str = 'feishu_default',
message_type: str = 'text',
message: Union[str, dict, None] = None,
at_mobiles: Optional[List[str]] = None,
at_all: bool = False,
**kwargs,
) -> None:
super().__init__(**kwargs)
self.feishu_conn_id = feishu_conn_id
self.message_type = message_type
self.message = message
self.at_mobiles = at_mobiles
self.at_all = at_all
def execute(self, context: 'Context') -> None:
self.log.info('Sending feishu message.')
hook = FeishuHook(
self.feishu_conn_id,
self.message_type,
self.message,
self.at_mobiles,
self.at_all
)
hook.send()
在飞书群中创建机器人
-
进入群,点击设置按钮
-
选择 [群机器人],进入之后点击 [添加机器人]
-
点击新建,新建【自定义机器人】,输入机器人名字。 比如:Airflow任务调度报警
-
点击完成以后会得到一个Webhook地址
# 这个key的值就是机器人的ID https://open.feishu.cn/open-apis/bot/v2/hook/090da27f-a7e9-494c-8de5-6d5ff2a9205d -
在airflow中创建企业微信的连接:[主菜单] -> [Admin] -> [Connections],配置
Conn Id: feishu_default Conn Type: HTTP Host: https://open.feishu.cn Password: 机器人的ID(key)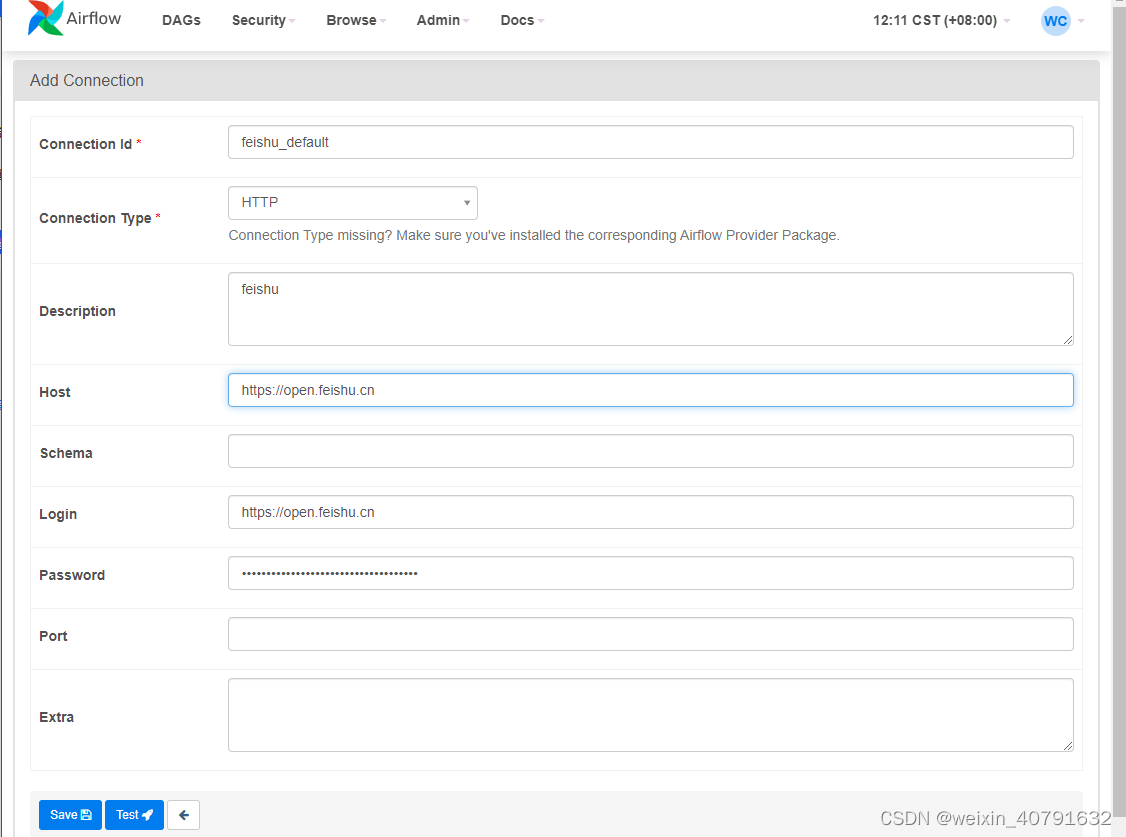
7.3.2.编写回调函数
feishu_failure_msg_test.py
# pyhton-note : Send alert message to feishu on failure.
# created-by : cassiel
# created-date : 2022-06-12 12:33:46
# updated-by :
# updated-date :
# updated-notes:
#########################################################################################
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from feishu_operator import FeishuOperator
# feishu
def failure_callback(context):
message = 'AIRFLOW TASK FAILURE TIPS:n'
'DAG: {}n'
'TASKS: {}n'
'Reason: {}n'
.format(context['task_instance'].dag_id,
context['task_instance'].task_id,
context['exception'])
return FeishuOperator(
task_id='feishu_task',
feishu_conn_id='feishu_default',
message_type='text',
message=message,
at_all=True,
).execute(context)
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2022, 6, 11),
'email': ['798320307@qq.com'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(secondss=10),
'on_failure_callback': failure_callback,
# 'on_success_callback':failure_callback
}
dag = DAG(
dag_id = 'feishu_failure_msg_test',
default_args=default_args,
schedule_interval='*/1 * * * *',
catchup = False,
start_date = datetime(2022, 6, 14)
)
first=BashOperator(
task_id='first',
bash_command='sh /home/airflow/first_shell.sh %s'%(datetime.now()-timedelta(days=1)).strftime('%Y-%m-%d'),
dag=dag
)
second=BashOperator(
task_id='second',
bash_command='sh /home/airflow/second_shell.sh {{ ds }}',
dag=dag
)
first >> second
在first_shell.sh或second_shell.sh脚本中制造一些报错,例如分母为0的情况,一旦报错就会警报了
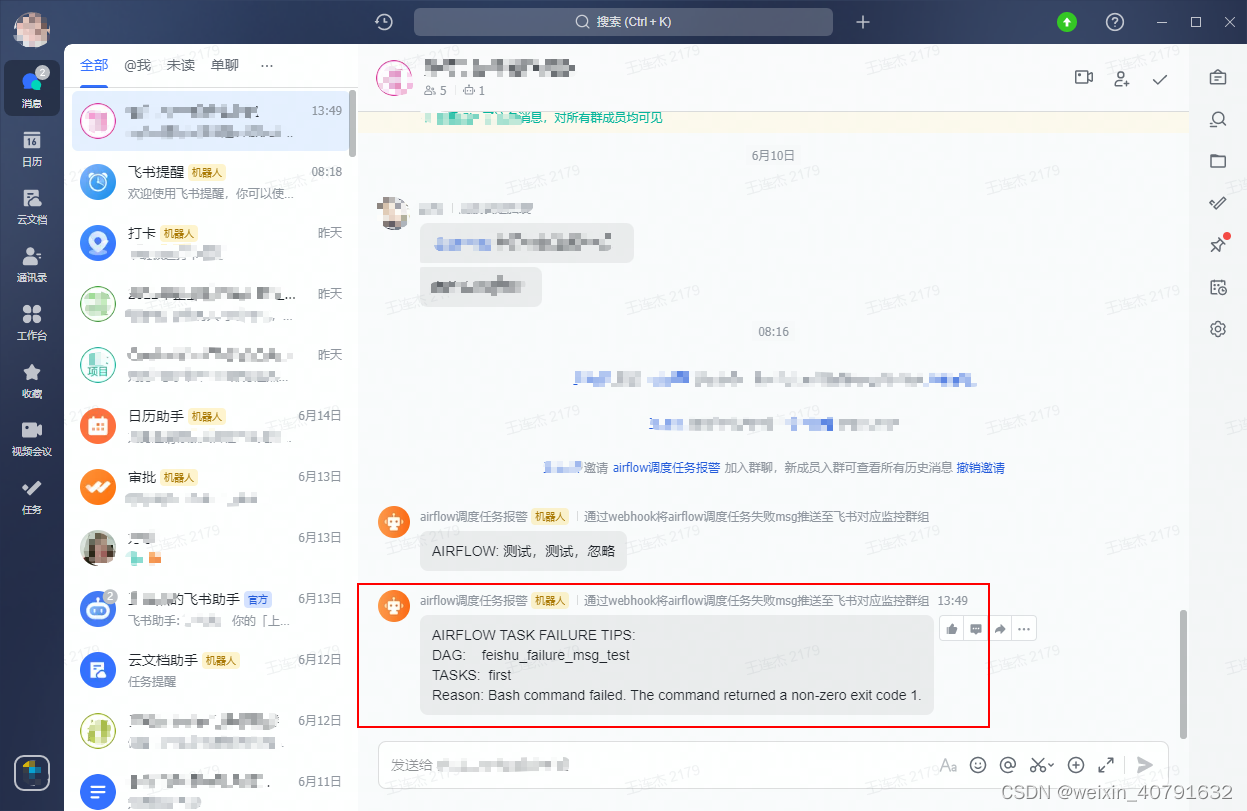
五、Airflow的Client命令
1.客户端命令概览
(airflow) [airflow@centos003 ~]$ airflow -h
usage: airflow [-h] GROUP_OR_COMMAND ...
positional arguments:
GROUP_OR_COMMAND
Groups:
celery Celery components
config View configuration
connections Manage connections
dags Manage DAGs
db Database operations
jobs Manage jobs
kubernetes Tools to help run the KubernetesExecutor
pools Manage pools
providers Display providers
roles Manage roles
tasks Manage tasks
users Manage users
variables Manage variables
Commands:
cheat-sheet Display cheat sheet
info Show information about current Airflow and environment
kerberos Start a kerberos ticket renewer
plugins Dump information about loaded plugins
rotate-fernet-key
Rotate encrypted connection credentials and variables
scheduler Start a scheduler instance
standalone Run an all-in-one copy of Airflow
sync-perm Update permissions for existing roles and optionally DAGs
triggerer Start a triggerer instance
version Show the version
webserver Start a Airflow webserver instance
optional arguments:
-h, --help show this help message and exit
2.Client命令使用案例
略,一切参考官网吧,命令变化有点频繁。
六、Airflow的REST API使用
所有REST API详解参考官网:https://airflow.apache.org/docs/apache-airflow/2.0.0/stable-rest-api-ref.html#tag/TaskInstance
1.授权REST API使用
在Airflow的配置文件Airflow.cfg中对于API访问权限是"拒绝所有请求"
[api]
# 默认是deny_all(拒绝所有请求)
auth_backend = airflow.api.auth.backend.deny_all
给其授权
[api]
# 如果想让rest api有授权,使用basic_auth,若是想使用kerberos认证需要参考Airflow官网配置
auth_backend = airflow.api.auth.backend.basic_auth
授权后,REST API即可使用
2.DAG相关API操作
2.1.开启DAG
批量开启使用循环操作
curl -X PATCH "http://${host}:${port}/api/v1/dags/${dag_id}?update_mask=is_paused"
-H 'Content-Type: application/json'
--user "${账号}:${密码}"
-d '{
"is_paused": false
}'
2.2.暂停DAG
批量暂停使用循环操作
curl -X PATCH "http://${host}:${port}/api/v1/dags/${dag_id}?update_mask=is_paused"
-H 'Content-Type: application/json'
--user "${账号}:${密码}"
-d '{
"is_paused": true
}'
2.3.手动触发DAG执行
触发某个dag执行时,需要填写参数,其中execution_date参数是必须要填写的,而且该参数不能和以前提交的任务参数相同。
curl -X POST "http://${host}:${port}/api/v1/dags/${dag_id}/dagRuns"
-H 'content-type: application/json'
--user "${账号}:${密码}"
-d "{
'execution_date': '${EXE_DATE}',
'conf': {}
}"
2.4.获取DAG运行状态
可以通过触发任务时,获取到的dag_run_id的值,来获取运行时任务的状态信息。
curl -X GET "http://${host}:${port}/api/v1/dags/${dag_id}/dagRuns/${dag_run_id}"
-H 'content-type: application/json'
--user "${账号}:${密码}"
七、Gitlab集成Airflow自动部署
1.自动部署方案
3.1.部署方案一
- 只开发任务脚本,不开发DAG文件
- 在数据库中创建两张表,一张是任务清单表,一张是任务依赖表
- 开发生成DAG脚本任务,每次生产发布时通过脚本任务生成一个大的DAG文件,只定义一个DAG实例,从数据库中获取所有任务清单和任务依赖放入DAG文件中
- 生成的DAG通过gitlab的webhook部署到airflow的DAGs存储目录中
- 执行自动部署脚本(unpause or execute)
3.2.部署方案二
- 开发任务脚本和DAG文件,一个文件一个DAG,DAG文件名和DAG的dag_id保持一致;任务脚本采用ssh远程运行shell方式
- 将DAG通过gitlab的webhook部署到airflow的DAGs存储目录中
- 执行自动部署脚本(unpause or execute)
2.自动部署流程
采用 “部署方案二”
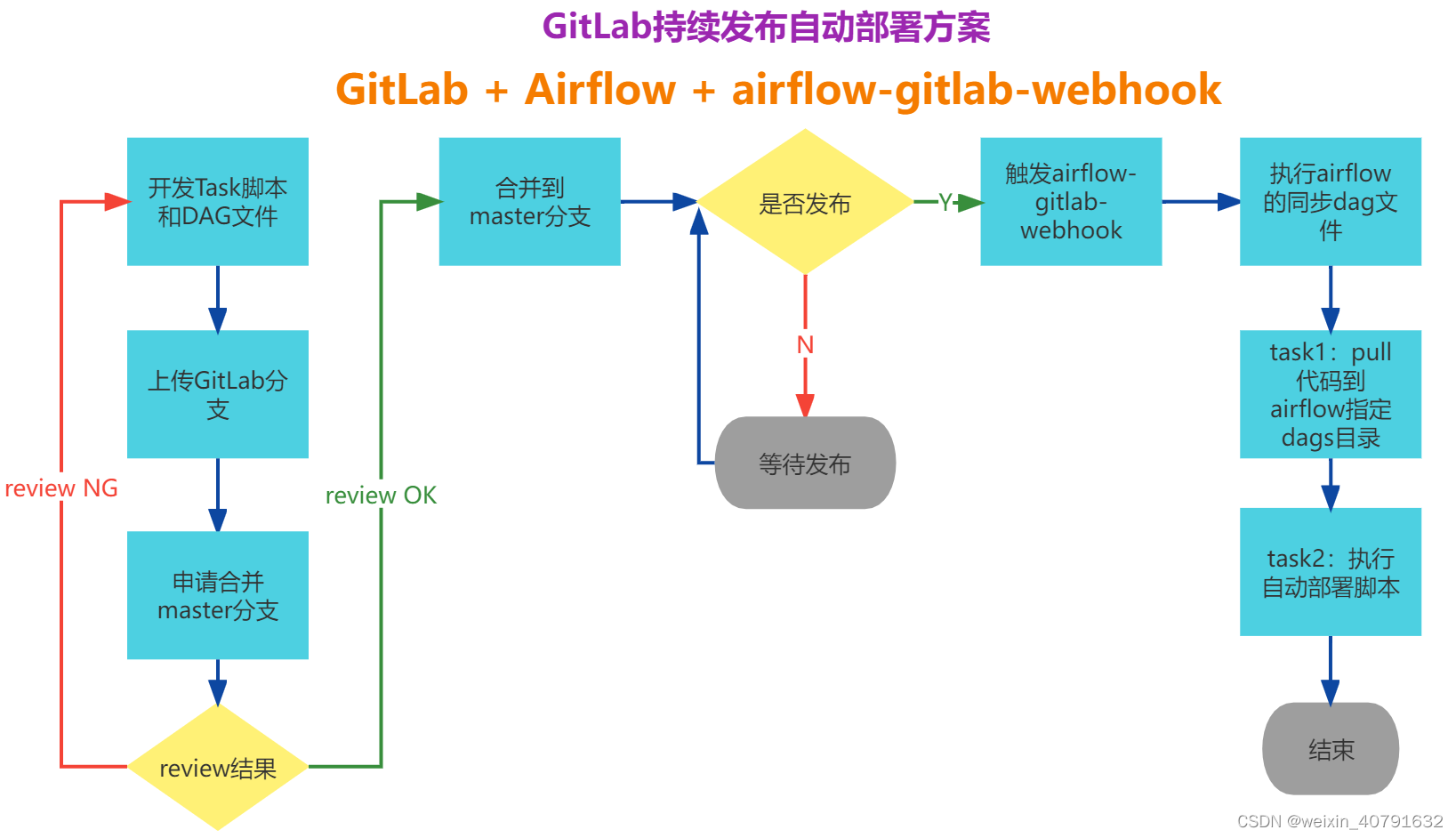
3.自动部署实施细节
3.1.Airflow集群准备动作
-
Airflow集群需要ssh互信,使用 ssh-keygen -t rsa
-
Airflow的webserver节点(HA的备用master也需要)安装airflow-gitlab-webhook插件
#下载airflow-gitlab-webhook插件。地址:https://github.com/andreax79/airflow-gitlab-webhook pip3 install airflow-gitlab-webhook# 增加配置,所有的airflow集群节点都要增加 vim /appcom/mudules/airflow/airflow.cfg #添加如下内容 [gitlab_plugin] # 项目url。${git_host}、${port}和${project_name}需要修改成自己的 repository_url = ssh://git@${git_host}:${port}/${project_name}.git # webhook触发dag的dag_id,这个dag需要开发并在airflow上已激活,dag中设置自动部署脚本的任务 dag = data_warehouse_sync -
更改dags的目录路径
原来的
[core] # 存放dag的目录,需要使用绝对路径 dags_folder = /appcom/modules/airflow/dags更改后
[core] # 存放dag的目录,需要使用绝对路径 dags_folder = /appcom/apps/data_warehouse/airflow/dags -
重启webserver
3.2.在gitlab上配置 webhook
在对应的项目中进行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EYzjjd6l-1655365483245)(D:bigdata_softwareTyporaimagesimage-20220613112330738.png)]](https://www.shuijiaxian.com/files_image/2023061019/44424e26e2d24e27981669042912209a.png)
- 点击Integrations进入 webhook配置页面
- 添加 airflow webhook的url链接 如: http://192.168.31.122:8787/webhooks/gitlab/push
- 选择push events添加仓库分支信息,执行需要发布的分支
- 点击webhook即可 添加成功
- 完成后可以点击Test -> Push events,若成功会返回200
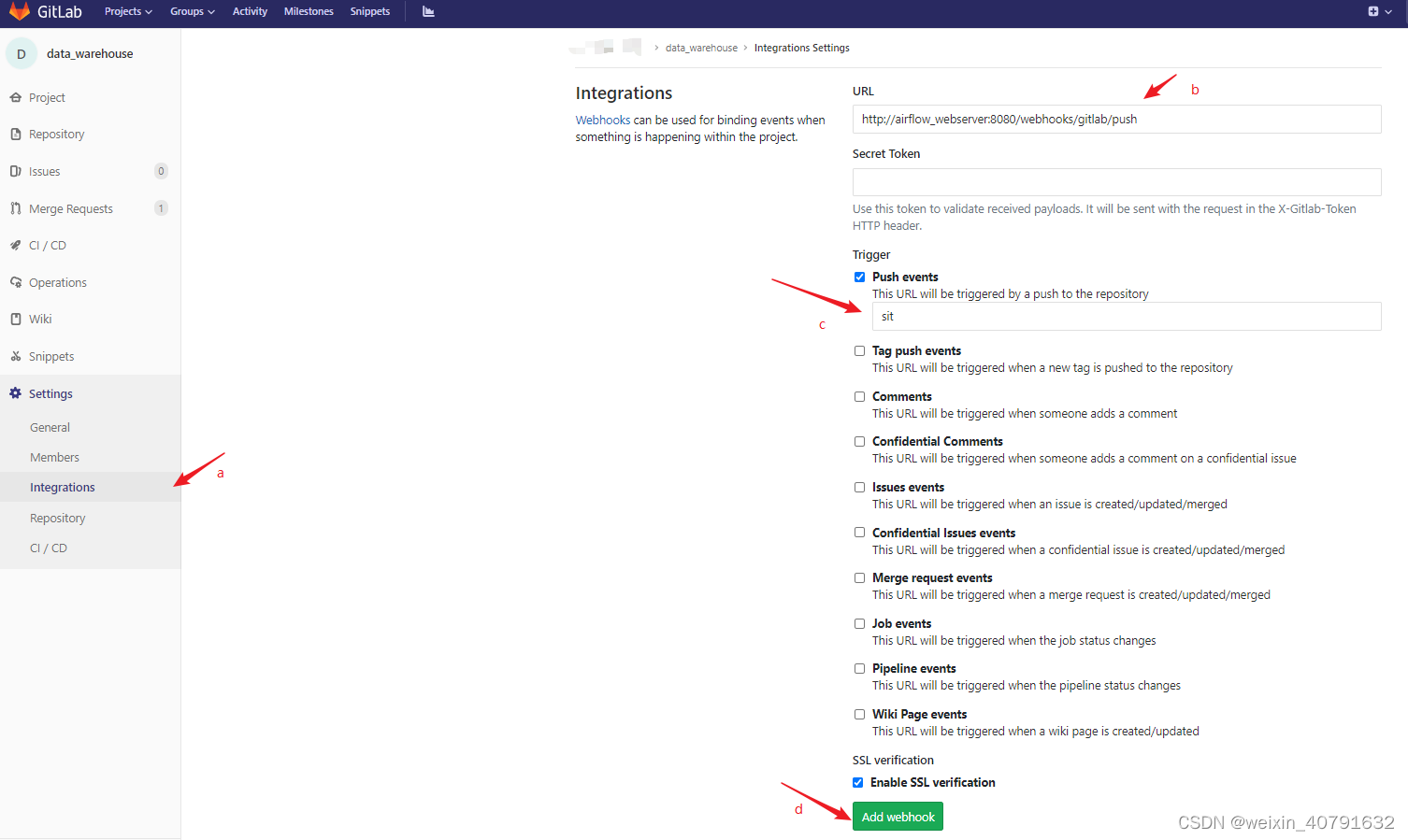
3.3.触发Dag文件编写
这个dag文件主要用来被gitlab的webhook触发的,不需要有schedule_interval
data_warehouse_sync.py
# pyhton-note : Gitlab trigger to execute DAG file with Airflow-gitlab-webhook.
# created-by : cassiel
# created-date : 2022-06-13 14:15:32
# updated-by :
# updated-date :
# updated-notes:
#########################################################################################
import airflow
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedelta
# Dag default args
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2022, 6, 1),
'email': ['798320308@qq.com','113672635@qq.com'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 2,
'retry_delay': timedelta(minitues=5),
'params': {'urls': 'centos003 centos004 centos005 centos006'}
}
# Defined a dag
sync_dag = DAG(
dag_id='data_warehouse_sync',
default_args=default_args,
description='dag files sync',
schedule_interval=None,
max_active_runs=1,
catchup=False
)
# set pull task
pull_gitlab_task = BashOperator(
task_id='pull_all_into_apps',
bash_command="for url in `echo {{ params.urls }}`; do ssh airflow@${url} 'cd /appcom/apps/data_warehouse; git pull' ; done",
dag=sync_dag
)
# set auto deploy tasks
auto_deploy_task = BashOperator(
task_id='auto_deploy_task',
bash_command='sh /appcom/apps/data_warehouse/bin/auto_deploy/start_exec.sh ',
dag=sync_dag
)
# set dependences
pull_gitlab_task >> auto_deploy_task
3.4.自动部署脚本
auto_deploy_code.sh
#!/bin/bash
source ~/.bashrc
job_rootpath=/appcom/apps/data_warehouse
#initialize tool-function
source ${job_rootpath}/config/common_shell_function.properties
#Data defined
batch_date=`date +"%Y-%m-%d"`
#paramters
web=airflow
role=admin
host=`get_web_url ${web}_${role}`
port=`get_web_port ${web}_${role}`
user=`get_web_user ${web}_${role}`
pwd=`get_web_password ${web}_${role}`
########################################################################################
#shell-note : 自动部署脚本
#create-by : cassiel
#create-date : 2022-06-13 14:30:45
#updated-by :
#updated-date :
#updated-notes :
#execution start
echo "========================================================"
echo `date +"%Y-%m-%d %X"` "#INFO : Script execution start!"
echo "========================================================"
line_num=`cat ${job_rootpath}/build/build.properties | grep -v ^'#' | wc -l`
for (( i=1; i<=${line_num}; i++ ))
do
# 获取dag_id
dag_id=`sed -n "$(( ${i}+2 ))p" ${job_rootpath}/build/build.properties | awk -F'|' '{print $1}'`
# 获取操作信息
op_info=`sed -n "$(( ${i}+2 ))p" ${job_rootpath}/build/build.properties | awk -F'|' '{print $2}'`
#执行操作
if [[ ${op_info} = 'add' ]];
then
# upause dags
curl -X PATCH "http://${host}:${port}/api/v1/dags/${dag_id}?update_mask=is_paused"
-H 'Content-Type: application/json'
--user "${user}:${pwd}"
-d '{"is_paused": false}'
elif [[ ${op_info} = 'update' ]];
then
# TODO
elif [[ ${op_info} = 'delete' ]];
then
# TODO
else
# TODO
fi
done
echo "========================================================"
echo `date +"%Y-%m-%d %X"` "#INFO : Script execution complete!"
echo "========================================================"
3.5.生产目录结构

最后
以上就是烂漫绿茶最近收集整理的关于Airflow2.2.5任务调度工具Airflow2.2.5任务调度工具一、Airflow介绍二、Airflow安装配置三、Airflow页面介绍四、Airflow开发详解五、Airflow的Client命令六、Airflow的REST API使用七、Gitlab集成Airflow自动部署的全部内容,更多相关Airflow2.2.5任务调度工具Airflow2.2.5任务调度工具一、Airflow介绍二、Airflow安装配置三、Airflow页面介绍四、Airflow开发详解五、Airflow的Client命令六、Airflow的REST内容请搜索靠谱客的其他文章。



![[IM] [Webhook] Webhook实现IM平台机器人简介方法 / 步骤参考资料 & 致谢](https://www.shuijiaxian.com/files_image/reation/bcimg23.png)




发表评论 取消回复