alertmanager-----告警处理源码剖析
alertmanager整体处理流程
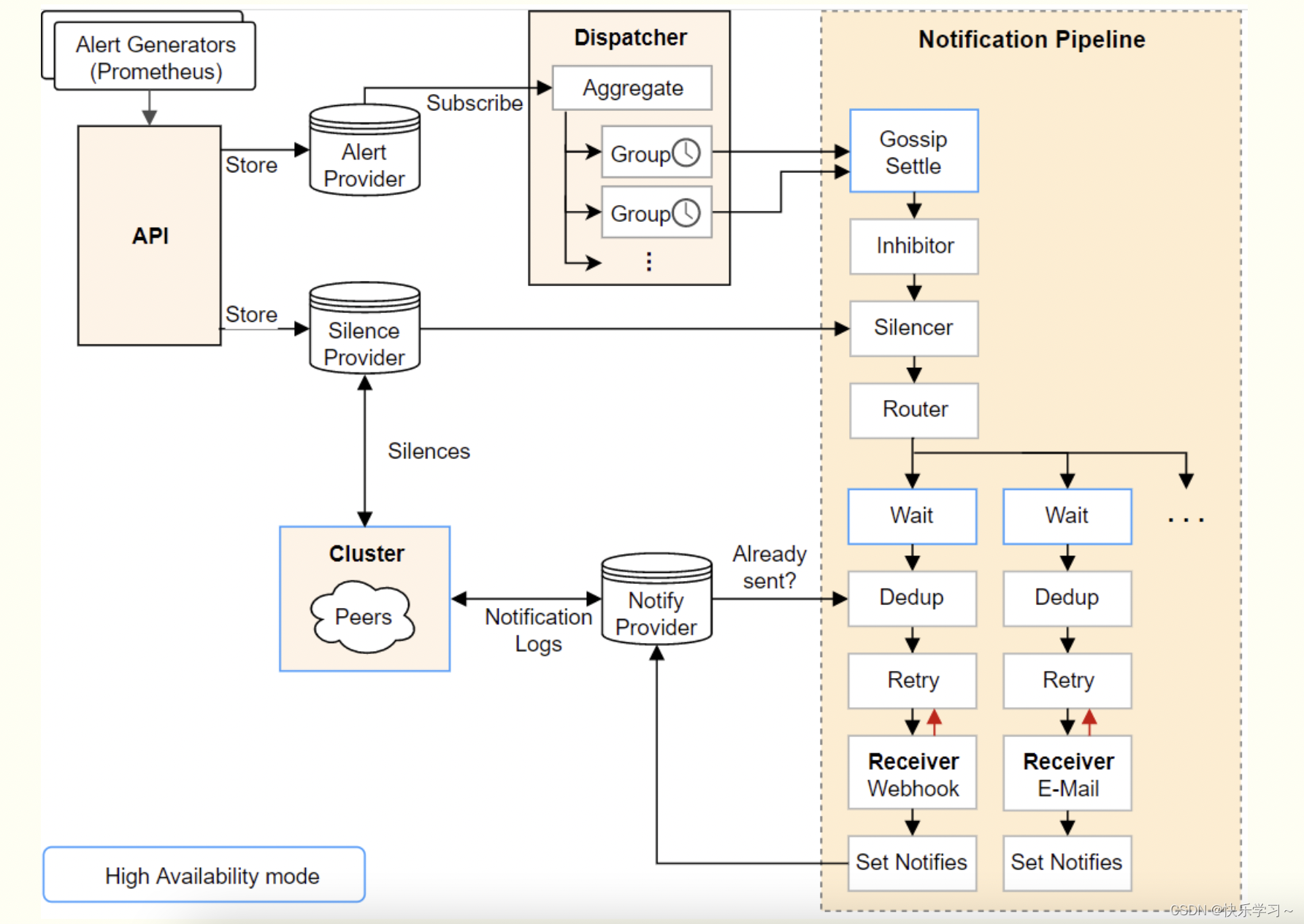
本文重点讲Dedup(去重)和Wait(等待同步)
Dedup:保证一条告警在正常情况下只会由集群内的一个节点发出,不会重复发送
Wait:保证了正常情况下,在集群有节点发送告警后,在同步给其它节点的期间,其它节点又把告警重复发了一次
Dedup(去重)
Wait(等待同步)
WaitStage
顾名思义,WaitStage表示向其他实例发送Notification Log的时间间隔,只是单纯的时间等待。
官方源码解释:
clusterWait returns a function that inspects the current peer state and returns
a duration of one base timeout for each peer with a higher ID than ourselves.
即:clusterWait 返回一个检查当前对等体状态的函数并返回对于 ID 比我们自己高的每个对等点,
一个基本超时的持续时间。
// Exec implements the Stage interface.
func (ws *WaitStage) Exec(ctx context.Context, _ log.Logger, alerts ...*types.Alert) (context.Context, []*types.Alert, error) {
select {
case <-time.After(ws.wait()):
case <-ctx.Done():
return ctx, nil, ctx.Err()
}
return ctx, alerts, nil
}
// clusterWait returns a function that inspects the current peer state and returns
// a duration of one base timeout for each peer with a higher ID than ourselves.
func clusterWait(p *cluster.Peer, timeout time.Duration) func() time.Duration {
return func() time.Duration {
return time.Duration(p.Position()) * timeout
}
}
// Position returns the position of the peer in the cluster.
func (p *Peer) Position() int {
all := p.mlist.Members()
sort.Slice(all, func(i, j int) bool {
return all[i].Name < all[j].Name
})
k := 0
for _, n := range all {
if n.Name == p.Self().Name {
break
}
k++
}
return k
}
解析:
各个实例发送Notification Log的时长并不一样,它与p.Position()的返回值有关,timeout默认是15s。
p.Position()返回的是当前的alertmanager实例的编号,每个alertmanager等待的时间:
编号 * timeout(默认是15s)
Dedup(去重)
DedupStage目的就是根据告警的哈希值来判断本实例的告警是否已经被发送,如果已经被发送,则本实例不再继续发送
哈希算法如下,主要是对告警的标签进行哈希:
func hashAlert(a *types.Alert) uint64 {
const sep = 'xff'
hb := hashBuffers.Get().(*hashBuffer)
defer hashBuffers.Put(hb)
b := hb.buf[:0]
names := make(model.LabelNames, 0, len(a.Labels))
for ln := range a.Labels {
names = append(names, ln)
}
sort.Sort(names)
for _, ln := range names {
b = append(b, string(ln)...)
b = append(b, sep)
b = append(b, string(a.Labels[ln])...)
b = append(b, sep)
}
hash := xxhash.Sum64(b)
return hash
}
通过上述哈希算法,可以知道:
alertmanager判断两条告警是否是同一条的标志是根据告警的标签集合来判断的,跟告警的值,发生的时间等是没有关系的
SetNotifiesStage:
该阶段就是使用Notification Log向其他节点发送告警通知的过程。
func (n SetNotifiesStage) Exec(ctx context.Context, l log.Logger, alerts ...*types.Alert) (context.Context, []*types.Alert, error) {
gkey, ok := GroupKey(ctx)
if !ok {
return ctx, nil, errors.New("group key missing")
}
firing, ok := FiringAlerts(ctx)
if !ok {
return ctx, nil, errors.New("firing alerts missing")
}
resolved, ok := ResolvedAlerts(ctx)
if !ok {
return ctx, nil, errors.New("resolved alerts missing")
}
// 通知其他实例
return ctx, alerts, n.nflog.Log(n.recv, gkey, firing, resolved)
}
首先通过FiringAlerts获取告警消息,通过ResolvedAlerts获取告警恢复消息,然后通过n.nflog.Log将这些消息发送给其他实例。可以看到FiringAlerts和ResolvedAlerts获取到的是[]uint64类型的数据,这些数据实际内容是什么?
func FiringAlerts(ctx context.Context) ([]uint64, bool) {
v, ok := ctx.Value(keyFiringAlerts).([]uint64)
return v, ok
}
func ResolvedAlerts(ctx context.Context) ([]uint64, bool) {
v, ok := ctx.Value(keyResolvedAlerts).([]uint64)
return v, ok
}
答案是,SetNotifiesStage中用到的FiringAlerts和ResolvedAlerts是在DedupStage阶段生成的,因此SetNotifiesStage阶段发送给其他实例的信息实际是告警的哈希值!
DedupStage处理如下:
func (n *DedupStage) Exec(ctx context.Context, _ log.Logger, alerts ...*types.Alert) (context.Context, []*types.Alert, error) {
...
firingSet := map[uint64]struct{}{}
resolvedSet := map[uint64]struct{}{}
firing := []uint64{}
resolved := []uint64{}
var hash uint64
for _, a := range alerts {
hash = n.hash(a)
if a.Resolved() {
resolved = append(resolved, hash)
resolvedSet[hash] = struct{}{}
} else {
firing = append(firing, hash)
firingSet[hash] = struct{}{}
}
}
//生成SetNotifiesStage使用的 FiringAlerts
ctx = WithFiringAlerts(ctx, firing)
//生成SetNotifiesStage使用的 ResolvedAlerts
ctx = WithResolvedAlerts(ctx, resolved)
entries, err := n.nflog.Query(nflog.QGroupKey(gkey), nflog.QReceiver(n.recv))
if err != nil && err != nflog.ErrNotFound {
return ctx, nil, err
}
var entry *nflogpb.Entry
switch len(entries) {
case 0:
case 1:
entry = entries[0]
default:
return ctx, nil, errors.Errorf("unexpected entry result size %d", len(entries))
}
if n.needsUpdate(entry, firingSet, resolvedSet, repeatInterval) {
return ctx, alerts, nil
}
return ctx, nil, nil
}
DedupStage阶段会使用和SetNotifiesStage阶段相同的哈希算法来计算本实例的告警的哈希值,然后与接收到的其他实例发送的告警哈希值进行对比,如果needsUpdate返回true,则会继续发送告警,如果返回false,则可以认为这部分告警已经被其他实例发送,本实例不再发送。
needsUpdate的函数如下,入参entry为接收到的其他实例发送的告警哈希值,firing和resolved为本实例所拥有的告警哈希值,因此,如果要让本地不发送告警恢复,则满足如下条件之一即可:
1、本实例的firing哈希是entry.FiringAlerts的子集,即本实例的所有告警都已经被发送过
2、不启用发送告警恢复功能或本实例的resolved哈希是entry.ResolvedAlerts的子集
即本实例的所有告警恢复都已经被发送过
如果本实例的告警哈希与接收到的告警哈希存在交叉或完全不相同的情况时,则不会对告警消息和告警恢复消息产生抑制效果。
判断是否需要发送:
func (n *DedupStage) needsUpdate(entry *nflogpb.Entry, firing, resolved map[uint64]struct{}, repeat time.Duration) bool {
// If we haven't notified about the alert group before, notify right away
// unless we only have resolved alerts.
if entry == nil {
return len(firing) > 0
}
// 如果本实例的fitring告警不是peer通知的他已经发送出去的告警的子集合,那么需要发送
if !entry.IsFiringSubset(firing) {
return true
}
// Notify about all alerts being resolved.
// This is done irrespective of the send_resolved flag to make sure that
// the firing alerts are cleared from the notification log.
if len(firing) == 0 {
// If the current alert group and last notification contain no firing
// alert, it means that some alerts have been fired and resolved during the
// last interval. In this case, there is no need to notify the receiver
// since it doesn't know about them.
return len(entry.FiringAlerts) > 0
}
// 如果本实例的resolved告警不是peer通知的他已经发送出去的告警的子集合,那么需要发送
if n.rs.SendResolved() && !entry.IsResolvedSubset(resolved) {
return true
}
// Nothing changed, only notify if the repeat interval has passed.
return entry.Timestamp.Before(n.now().Add(-repeat))
}
判断是否是子集的方法:
// IsFiringSubset returns whether the given subset is a subset of the alerts
// that were firing at the time of the last notification.
func (m *Entry) IsFiringSubset(subset map[uint64]struct{}) bool {
set := map[uint64]struct{}{}
for i := range m.FiringAlerts {
set[m.FiringAlerts[i]] = struct{}{}
}
return isSubset(set, subset)
}
// IsResolvedSubset returns whether the given subset is a subset of the alerts
// that were resolved at the time of the last notification.
func (m *Entry) IsResolvedSubset(subset map[uint64]struct{}) bool {
set := map[uint64]struct{}{}
for i := range m.ResolvedAlerts {
set[m.ResolvedAlerts[i]] = struct{}{}
}
return isSubset(set, subset)
}
总结:
判断是否需要发送就是看本实例的告警条例是不是其他peer通知的他们已经发送的告警实例的子集:
如果是,则不需要告警;
如果不是,则需要告警,同时发出告警的间隔要满足repeat_interval,不满足也是不能发的
对startsAt和endsAt的处理
startsAt和endsAt这两个字段,这两个字段分别表示告警的起始时间和终止时间,不过两个字段都是可选的。当AlertManager收到告警实例之后,会分以下几类情况对这两个字段进行处理:
1、两者都存在:不做处理
2、两者都未指定:startsAt指定为当前时间,endsAt为当前时间加上告警持续时间,默认为5分钟
3、只指定startsAt:endsAt指定为当前时间加上默认的告警持续时间
4、只指定endsAt:将startsAt设置为endsAt
即:如果 endsAt 没有提供,则自动等于 startsAt + resolve_timeout(默认 5m)
AlertManager一般以当前时间和告警实例的endsAt字段进行比较用以判断告警的状态:
* 若当前时间位于endsAt之前,则表示告警仍然处于触发状态(firing)
* 若当前时间位于endsAt之后,则表示告警已经消除(resolved)
为什么一直触发的告警不会触发恢复,而触发的告警一旦采集不到,尽管仍是触发的,也会触发恢复
如果告警一直 Firing,那么 Prometheus 会在 resend_delay 的间隔重复发送,而 startsAt 保持不变, endsAt 跟着 ValidUntil 变,这也就是为啥一直firing的规则不会被认为恢复,而不发firting则会认为恢复。
因为一直firing的告警消息中, endsAt 跟着 ValidUntil 变,一直在后延。而如果没收到,就会导致alertmanger那边在过了告警的endAt时间后,没收到恢复或者新firing,则认为恢复
注意:Alertmanager 里必须有 Inactive 消息所对应的告警,否则是会被忽略的。换句话说如果一个告警在 Alertmanager 里已经解除了,再发同样的 Inactive 消息,Alertmanager 是不会发给 webhook 的。
Prometheus 需要 持续 地将 Firing 告警发送给 Alertmanager,遇到以下一种情况,Alertmanager 会认为告警已经解决,发送一个 resolved:
* Prometheus 发送了 Inactive 的消息给 Alertmanager,即 endsAt=当前时间
* Prometheus 在上一次消息的 endsAt 之前,一直没有发送任何消息给 Alertmanager
Alertmanager重复/缺失告警现象探究及三个关键参数group_wait和group_interval,repeat_interval的释义
group_wait和group_interval,repeat_interval
1、当alertmanager接收到一条新的alert时,会先根据group_by为其确定一个聚合组group,然后等待group_wait时间,如果在此期间接收到同一group的其他alert,则这些alert会被合并,然后再发送(alertmanager发送消息单位是group)。此参数的作用是防止短时间内出现大量告警的情况下,接收者被告警淹没。
2、在该组的alert第一次被发送后,该组会进入睡眠/唤醒周期,睡眠周期将持续group_interval时间,在睡眠状态下该group不会进行任何发送告警的操作(但会插入/更新(根据fingerprint)group中的内容),睡眠结束后进入唤醒状态,然后检查是否需要发送新的alert或者重复已发送的alert(resolved类型的alert在发送完后会从group中剔除)。这就是group_interval的作用。
聚合组在每次唤醒才会检查上一次发送alert是否已经超过repeat_interval时间,如果超过则再次发送该告警。
3、因此repeat_interval并不代表告警的实际重复间隔,因为在第一次发送告警的repeat_interval时间后,聚合组可能还处在睡眠状态,所以实际的告警间隔应该大于repeat_interval且小于repeat_interval+group_interval。因此实际生产中group_interval值不可设得太大。
出现以下四种情况的原因:
1、为什么有些的firing alert没有对应的resolved alert呢?
假设该firing消息发生在第n个睡眠周期,而在第n+1个睡眠周期内,该alert发生了resolved-firing-resolved…这样的状态变化,则其对应的resolved消息被n+1周期内的第二个resolved消息覆盖,因此表现为该firing alert没有对应的resolved消息。
2、有些resolved alert没有对应的firing alert?
因为这些firing alert发送给alertmanager时其所在的group恰好处在睡眠状态下,而其对应的resolved消息也在同一睡眠周期内被发送给alertmanager,接收到resolved消息后,group将其对应的firing消息覆盖,因此在唤醒时就只接收到了resolved消息。
3、收到多条重复的resolved alert?
这个问题又涉及到prometheus rule组件的一个特性,当一个alert由firing变成resolved后,该resolved alert不会只发送给alertmanager一次,而是会先保存在内存中15分钟,并且重复多次发送给alertmanager
并且这部分实现在prometheus中是hard code:
// resolvedRetention is the duration for which a resolved alert instance
// is kept in memory state and consequently repeatedly sent to the AlertManager.
const resolvedRetention = 15 * time.Minute
因此发送多条resolved的情况为:
在第n个睡眠周期内,alertmanager接收到第一条resolved alert并将其更新进group,紧接着在唤醒时发送该group并将resolved alert从group中剔除。但在第n+1个睡眠周期内,prometheus仍然在向alertmanager发送该resolved alert,因此下次唤醒时发送的group中又带有这条resolved alert。
4、firing alert短时间发送了多次?
这个容易理解,如上所述,alertmanager发送消息的单位是group,在该group被发送的下一个睡眠周期中,又有新的alert被insert到该group中,因此下一次唤醒时又发送了一次该group,表现为同一条firing alert短时间内发送了多次。
5、对于瞬时性的告警,firing后,虽然立即恢复,但是没有马上收到resolved
因为一条告警的firing和resolved是属于同一个group的,那么firing发送后,需要等待group_interval后这个组才能再发送,就会导致此时resolved被抑制啦,发不出去,因此实际生产中,group_interval不宜过大,否则resolved可能无法及时发送出来
最后
以上就是优雅灯泡最近收集整理的关于【博客484】alertmanager-----告警处理源码剖析alertmanager-----告警处理源码剖析的全部内容,更多相关【博客484】alertmanager-----告警处理源码剖析alertmanager-----告警处理源码剖析内容请搜索靠谱客的其他文章。








发表评论 取消回复