1 爬虫简介
网络爬虫(又被称作网络蜘蛛、网络机器人,在某些社区中也经常被称为网页追逐者)可以按照指定的规则(网络爬虫的算法)自动浏览或抓取网络中的信息。
1.1 Web网页存在方式
- 表层网页指的是不需要提交表单,使用静态的超链接就可以直接访问的静态页面。
- 深层网页指的是需要用户提交一些关键词才能获得的Wb页面。深层页面需要访问的信息数量是表层页面信息数量的几百倍,所以深层页面是主要的爬取对象。
1.2 网络爬虫的分类
1.2.1通用网络爬虫/全网爬虫
- 通用网络爬虫的爬行范围和数量巨大,对爬行速度和存储空间要求较高,通常采用并行工作方式,需要较长时间才可以刷新一次页面,所以存在着一定的缺陷。
- 主要应用于大型搜索引擎中,有非常高的应用价值。通用网络爬虫主要由初始URL(统一资源定位符)集合、UL队列、页面爬行模块,页面分析模块、页面数据库、链接过滤模块等构成。
1.2.2 聚焦网络爬虫/主题网络爬虫
- 主要指按照预先定义好的主题,有选择地进行相关网页爬取的一种网络爬虫,将爬取的目标网页定位在与主题相关的页面中,极大地节省了硬件和网络资源,保存的页面也由于数量少而更快了。
- 主要应用在对特定信息的爬取,为某一类特定的人群提供服务。
1.2.3 深层网络爬虫
深层网络爬虫主要通过六个基本功能的模块(爬行控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表、LVS表)等部分构成。其中,LVS表示标签、数值集合,用来表示填充表单的数据源。
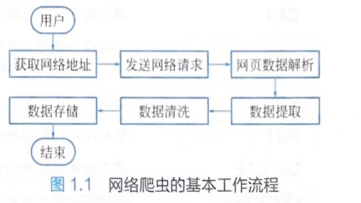
1.3 爬虫的原理
①获取初始的网络地址,该地址是用户自己制定的初始爬取的网页。
②通过爬虫代码向网页服务器发送网络请求。
③实现网页中数据的解析,确认数据在网页代码中的位置。
④在服务器响应数据中,提取数据内容。
⑤实现数据的清洗,将无用数据筛选。
⑥将清洗后的数据保存至本地或数据库当中。
2 HTTP原理
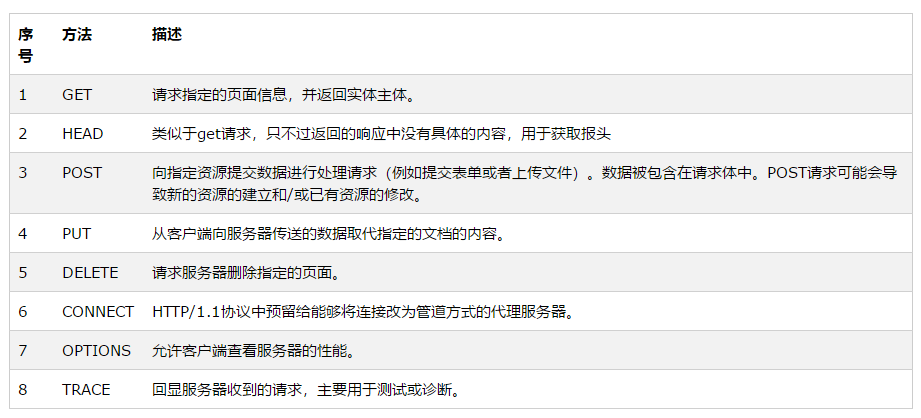
2.1 URL
使用浏览器访问网页时,需要在浏览器地址栏处填写目标网页的URL地址,统一资源定位符。
2.2 HTTP协议
HTTP(hypertext transfer protocol),即超文本传输协议,是互联网上应用最为厂厂泛的一种网络),主要利用TCP(传输控制协议)在web服务器和客户端之间传输信息的协议。客户端使用器发起HTTP请求给Web服务器,Web服务器发送被请求的信息给客户端。
2.2.1 HTTP与Web服务器
当在浏览器输人URL地址后,浏览器会先请求DNS域名系统服务器,获得请求站点的P地址(根据URL地址www.aliyun.com获取其对应的P地址,如101.201.120.85),然后发送一个HTTP请求(request)给拥有该IP的主机(阿里云服务器),接着就会接收到服务器返回的HTTP响应(response),浏览器经过渲染后,以一种较好的效果呈现给用户。
2.2.2 Web服务器工作原理
①建立连接:客户端通过TCP/IP(传输控制协议、网际协议)协议建立到服务器的TCP连接。
②请求过程:客户端向服务器发送HTTP协议请求包,请求服务器里的资源文档。
③应答过程:服务器向客户端发送HTTP协议应答包,如果请求的资源包含动态语言的内容,那么服务器会调用动态语言的解释引擎处理动态语言部分,并将处理后得到的数据返回给客户端。由客户端HTML(超文本标记语言)文档,并在客户端屏幕上渲染图形结果。服务器返回给客户端的状态码可分为5种类型,由它们的第一位数字表示。

④关闭连接:客户端与服务器断开连接。
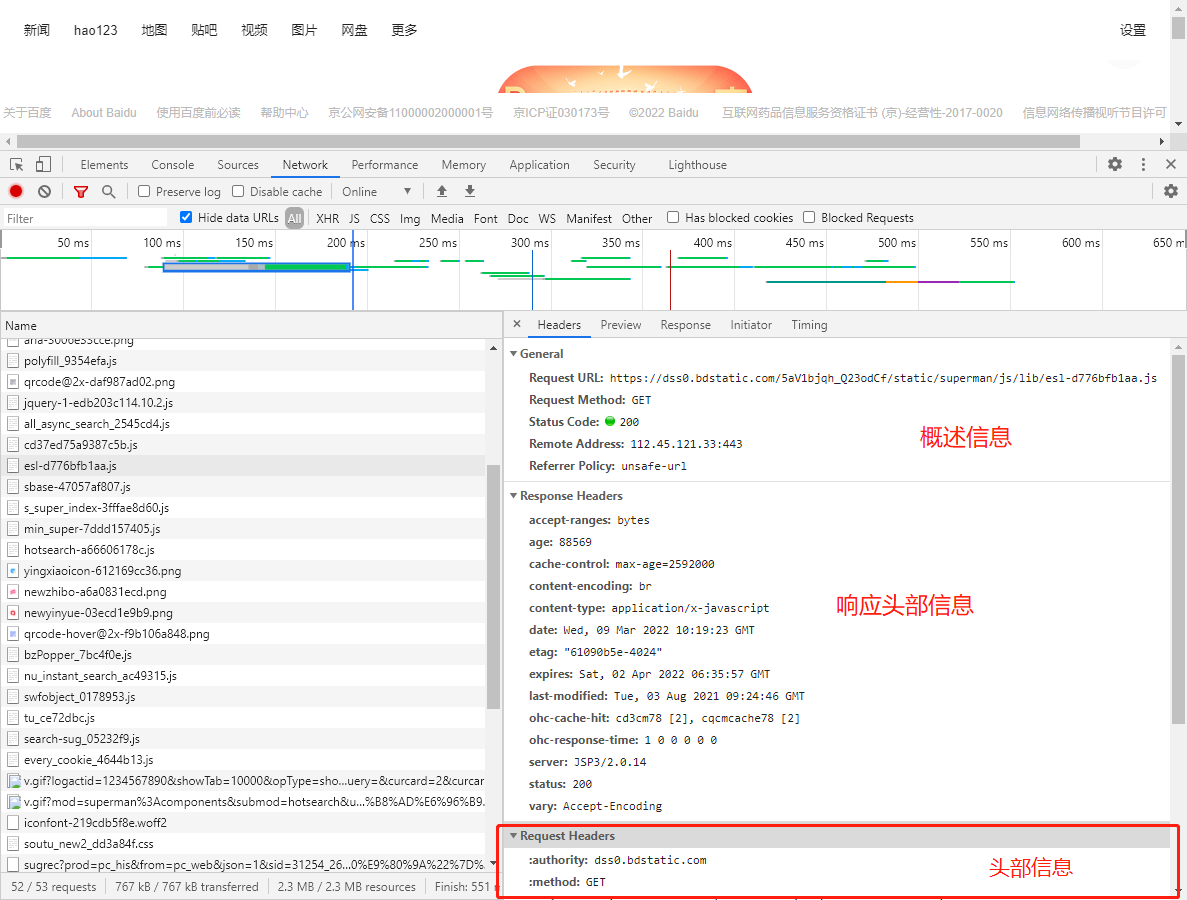
2.2.3 浏览器中的请求与响应
最后
以上就是无奈大侠最近收集整理的关于爬虫实战学习笔记_1 爬虫基础+HTTP原理1 爬虫简介1.3 爬虫的原理2 HTTP原理的全部内容,更多相关爬虫实战学习笔记_1内容请搜索靠谱客的其他文章。








发表评论 取消回复