Redis
文章目录
- Redis
- NOSQL
- NOSQL数据库类型
- Redis简介
- Redis使用
- 启动Redis服务端
- 启动Redis客户端
- 设置开机自启动
- 设置密码登录
- 停止Redis
- 数据类型
- 1 字符串类型Map<String,String>
- 2 List数据类型Map<String,List<String>>
- 3 hash数据类型Map<String,Map<String,String>>
- 4 set数据类型Map<String,Set<String,String>>
- 5 zset(sortset)数据类型
- Redis相关命令
- 常用命令
- String类型命令
- List :集合数组
- hash:<key,value>
- set:无序且唯一
- zset:排序和隐藏分数
- 地理坐标
- Hyperloglog
- Bitmap
- Redis配置文件解析
- Redis持久化
- 持久化方案一: RDB
- 验证RDB的持久化
- 持久化方案二: AOF
- 验证AOF的持久化
- 持久化方案的选择
- 事务
- Redis 删除策略
- 惰性删除
- 定时删除
- 最终方案:定期删除+惰性删除
- Redis的复制
- 复制流程
- 复制的原理
- 哨兵模式
- 哨兵模式使用步骤
- Redis高可用高并发集群配置
- 中心化
- 去中心化
- redis集群的流程分析
- 集群的搭建
- SpringBoot整合redis
- 相关注解的使用
- 整合步骤
- 自定义序列化
- SpringBoot操作redis的api
- 针对所有数据类型
- String类型 opsForValue
- List类型 opsForList
- hash类型 opsForHash
- set类型 opsForSet
- zset类型 opsForZSet
- 缓存穿透
- 缓存雪崩
- 缓存击穿
NOSQL
NoSQL 是 Not Only SQL 的缩写,意即"不仅仅是SQL"的意思,泛指非关系型的数据库。强调Key-Value Stores和文档数据库的优点。
NOSQL数据库类型
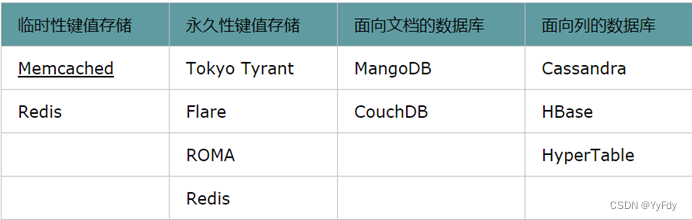
键值(Key-Value) 数据库[Redis/Memcached]
面向文档(Document-Oriented) 数据库[MongoDB] ES
列存储(Wide Column Store/Column-Family) 数据库[HBASE]
图(Graph-Oriented) 数据库[Neo4J,infoGird]
Redis简介
Redis:Remote Dictionary Server(远程字典服务器)
特点:
1、读取速度快 #读取的速度是110000次/s,写的速度是81000次/s
2、原子性
3、支持多种数据结构
4、持久化、主从复制(集群)
5、支持过期时间、支持事务、消息订阅
4、数据的读取都内在内存当中
Redis使用
启动Redis服务端
#默认情况下,redis不是在后台启动,在redis.conf下修改 daemonize =yes然后在bin目录下启动
./redis-server
#通过配置文件启动
./redis-server /usr/local/redis/conf/redis.conf
#查看进程
ps -ef|grep redis
启动Redis客户端
cd /usr/local/redis/bin
./redis-cli #默认是-h 127.0.0.1 -p 6379
#使用ping 如果出现PONG则表示连接成功
设置开机自启动
#编辑rc.local文件
vim /etc/rc.local
#加入 redis的绝对路径
/usr/local/redis/redis5.0/bin/redis-server /usr/local/redis/redis5.0/conf/redis.conf
设置密码登录
#在redis.conf配置文件中,找到# requirepass foobared,
#将密码设置成自己需要的密码,重新启动redis服务,连接客户端时便要输入密码。
requirepass 123456
停止Redis
#1、通过客户端停止
cd /usr/local/redis/bin
./redis-cli shutdown
#2、通过查询进程id号杀死
ps -ef|grep redis
kill -9 进程号
数据类型
注意:redis存放数据是以key-value的形式存放的,在redis中key永远是String类型,我们所谓的多个数据类型是针对于value的,如果value是集合类型,则该集合的元素也一定是String。
1 字符串类型Map<String,String>
最常用得数据类型,Redis中所有键都必须是字符串
2 List数据类型Map<String,List>
列表,Redis中的列表更像是数据结构中的双向链表。
3 hash数据类型Map<String,Map<String,String>>
哈希表示字段和值之间的映射关系,像Java中的Map结构
4 set数据类型Map<String,Set<String,String>>
集合类型
5 zset(sortset)数据类型
有序集合
Redis相关命令
学习网站:http://www.redis.net.cn/order/、http://redisdoc.com/、http://doc.redisfans.com/index.html
常用命令
不针对某种特定的数据类型
#以下的key都表示自己设置的key名字
keys * -- 获取当前库所有的key
select index -- 选择某个数据库
flushdb --清空当前库
del key --删除指定的key
expire key 10 --设置key的过期时间单位是秒 放在session设置过期时间
pexpire key 1 --设置key的过期时间单位是毫秒
persist key --删除过期时间
ttl key --查看还有多少秒过期 -1表示永不过期 -2表示已过期
move key 1 --将当前的数据库key移动到第二个数据库,目标库有,则不能移动
randomkey --从当前数据库中随机返回key
exists key --判断是否存在指定key
type key --返回key类型
String类型命令
#创建String类型
set key value --存放key-vulue
get key --获取key对应的value值
--
getset name newname --设置新的value值,返回旧的value值
mset key1 v1 key2 v2 --批量设置
mget key1 key2 --批量获取
setnx key value --不存在对应的key就插入(set if not exists) 分布式锁
incr key 递增值 --注意:value的内容必须是整数
incrbyfloat key 浮点数值 --增减浮点数
decr key 数值 --递减数值
strlen key --获取对应key的长度
getrange name beginIndex endIndex --字符串分段 -1就表示最后一个元素的索引
setrange key index value --从index开始替换value
append --追加
object encoding key --得到指定key对应的value 的类型
String有三种编码格式
embstr 用于长度小于或等于44字节
Redis3.x中是39字节,这种类型的编码在内存使用
raw 用于长度大于44字节的
List :集合数组
#创建List类型
lpush key values --l=left
rpush key values --r =rigth
--
lrange key 0 -1 --取出List集合中的所有数据 0 -1是取出所有 0 1取第一个和第二个
lpop key --弹出集合中最左边的元素
rpop key --弹出集合中最右边的元素 元素弹出之后就没有了
lrem key count value --删除集合中的元素
根据count选择删除的方式: 上是头下是尾 ,上是左下是右
count > 0 : 从表头开始向表尾搜索,移除与 VALUE 相等的元素,数量为 COUNT
count < 0 : 从表尾开始向表头搜索,移除与 VALUE 相等的元素,数量为 COUNT 的绝对值
count = 0 : 移除表中所有与 VALUE 相等的值。
lindex key index --获取指定索引的值
llen key --长度
lset key a b --设置索引a的值为b
ltrim key 0 4 --剪切0-4索引的内容(其余的删掉)
linsert key before a --在a元素之前插入
linsert key after a --在a元素之后插入
rpoplpush key1 key2 --将key1中最右边的数据保存到key2中最左边
hash:<key,value>
#创建hash语法格式
hset key field value field value
其中,key指的是redis的key。hash指得是value的数据类型,hset又类似Map的<key,value>的类型,所以这里使用field代指value的key
hmset key field value --也可以批量插入
hget key field --取指定的key集合中的field对应的value值
hgetall key --获取所有对应的key和value值
hexists key field --判断key中对应的field是否存在
hdel key field --删除key中对应的field值
hsetnx key field value --设置key中对应的field对应的value值
hincrby key field increment --设置对应的value值增加指定的数值,被增加的类型必须是整数型
hkeys key --只取key
hvals key --只取value
hlen key --取长度
set:无序且唯一
#创建set类型
sadd key value1 value2... --向集合中添加元素
smembers key --获取集合中所有数元素
srem key value --移除集合中的一个或者多个元素
scard key --获取当前集合下的元素个数
spop key --随机弹出集合中的一个元素,弹出即删除
sismember key value --判断该集合中是否还存在该元素
sidff |sinter | sunion key1 key2
sdiff --判断两个集合的差集 以key1为标准,看key2中没有的元素
sinter --判断两个集合中的交集
sunion --判断两个集合中的并集
srandmember --随机获取集合中的元素
zset:排序和隐藏分数
#创建zset类型
zadd key score value --创建元素,设置分数
zrange key 0 -1 --返回集合中所有的元素 按照分数从小到大排序
zrevrange key 0 -1 --返回集合中所有的元素 按照分数从大到小排序
zcard key --获取元素个数
zrem key value1 value2 --删除一个或者多个元素
zincrby key value score --给指定元素增加分数
zscore key value --获取指定元素的分数
zrangebyscore key 10 25 --获取指定区间分数的元素
--获取指定分数区间的元素并且分页
zrangebyscore key min max [WITHSCORES] [LIMIT offset count]
--翻转
zrevrangebyscore myzset max min [WITHSCORES] [LIMIT offset count]
zcount key min max --获取指定分数区间的个数
地理坐标
geoadd key longitude latitude member --添加指定key的经度、纬度 member--表示城市名
geopos key member --获取指定key中的城市经纬度
geodist key member1 member2 [unit] --获取两个城市之间的直线距离
unit参数 --表示单位为米。
--km 表示单位为千米。
--mi 表示单位为英里。
--ft 表示单位为英尺。
--以给定的经纬度为中心, 找出某一半径内的元素
georadius key longitude latitude radius m|km|ft|mi [参数]
参数:WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回
WITHCOORD: 将位置元素的经度和维度也一并返回。
WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。
ASC: 根据中心的位置, 按照从近到远的方式返回位置元素。
DESC: 根据中心的位置, 按照从远到近的方式返回位置元素。
--找出位于指定范围内的元素,中心点是由给定的位置元素决定
georadiusbymember key member radius m|km|ft|mi
geo命令底层就是采用的zset封装的,所以我们可以使用zset命令来操作geo命令
Hyperloglog
基数:不重复的元素
#使用Hyperloglog来做基数统计
pfadd key element --添加元素
Pfcount key -统计key中的元素个数
pfmerge destkey sourcekey1 sourcekey2 --合并不同key中的元素个数,并集。
Bitmap
#可以使用bitmap来做位图
setbit key offset value --给指定的key设置值
getbit key offset --取得对应key的value值
bitcount key [start end] --取出对应key中的1
#需求:统计每周的打卡天数
#使用1表示打卡 使用0表示未打卡 下标使用0-6
setbit sign 0 1
setbit sign 1 0
...
bitcount sign
Redis配置文件解析
save #保存数据到磁盘。save 20 5 #当数据发生5次修改时,每20秒保存一次。
daemonize; #如需要在后台运行,把该项的值改为yes
bind; #指定redis只接收来自该IP的请求,如果不设置,那么将处理所有请求,在生产环节中最好设置该项
port; #监听端口,默认为6379
timeout; #当客户端闲置多少秒后关闭连接,如果设置为0表示关闭该功能。
Redis持久化
持久化:将数据写入到磁盘文件中
redis持久化的意义:容灾
持久化方案一: RDB
RDB:每隔一段时间就将当前redis中的数据写入到磁盘文件中一次
RDB保存的是dump.rdb文件,压缩的了,不能查看
优点:
写的频率不高,写的是真实数据,内容可以压缩
缺点:
容易造成数据的丢失
在配置文件中可以配置RDB写数据的频率
save 900 1 --写入一条数据,每间隔900秒持久化一次
save 300 10 --写入10条数据,每隔300秒持久化一次
RDB的关闭
在配置文件中修改为 save ""
验证RDB的持久化
1、首先将配置文件中rdb持久化频率修改,重新加载配置文件 save 20 5
2、在redis中写入5条数据,等待20秒后,通过另一个客户端kill杀死该redis服务端,重后重启服务端,查看数据是否还存在。
持久化方案二: AOF
AOF (Append Only File) 持久化默认是关闭的,通过修改redis配置文件 appendonly no改为yes启动AOF持久化功能,如果说开启了AOF持久化功能,
那么会优先加载AOF持久化。以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,
redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
AOF保存的是appendonly.aof文件,可以使用vim查看
优点
数据丢失的几率更小,可以将文件当做日志使用
缺点
文件比较大,写的频率也比较高
AOF配置持久化频率
# appendfsync always --一直持久化
appendfsync everysec --每一秒持久化一次
# appendfsync no --关闭AOF持久化
验证AOF的持久化
1--修改配置文件,启动AOF持久化功能,重新加载配置文件 appendonly yes
2--在redis中 修改数据,通过另一个终端杀死服务端,重新启动服务端,查看数据是否还在存在。
如果持久化的文件发生了损坏,AOF会自动帮我们修复文件。
修复文件的方式:将不能识别的内容删除掉。
持久化方案的选择
只做缓存(RDB)
做用户登录保存session会话(RDB+AOF)
极致追求性能(关闭RDB,开启副本)
极致追求安全性(RDB+AOF (appendfsync always))
事务
redis事务的本质:一组命令的集合!
redis单条命令是保存原子性的,但是事务不保证原子性!
事务的步骤
1--开启事务
multi
2--其他命入队令
set..get,,
3-提交事务
exec
--如果要取消事务
discard
如果在事务中发生了异常,
编译时异常:代码有问题,命令有错 --事务中的命令都不会被执行
运行时异常:(1/0) 如果事务队列中存在语法性,异常的命令不会被执行,其他正常的命令会被执行。
所以redis事务不保证原子性。
Redis 删除策略
惰性删除
所有设置了过期时间的数据,都只会在取出该数据时才检查是否过期,如果过期了就删除
优点:检查的频率变低 节省了系统资源
缺点:浪费内存资源
/*
惰性删除策略
每取一个值 就判断有没有过期 过期就删除
*/
public class test01 {
//模拟redis
private static Map<String, Object> redis = new HashMap<>();
//设置一个集合存放设置了过期时间数据的key 以及对应的过期时间
private static Map<String, Long> ttl = new HashMap();
/*
向redis中添加数据
*/
public static void set(String key,Object value,Long time){
redis.put(key, value);
if (time != null){
//说明设置了过期时间 保存过期时间
ttl.put(key,System.currentTimeMillis()+time);
}
}
/*
取数据
*/
public static Object get(String key) {
if(ttl.containsKey(key)){//判断是否设置了过期时间
if(System.currentTimeMillis() > ttl.get(key)){//判断是否过期
//如果过期 则从redis中删除该数据 同时也从ttl中删除
ttl.remove(key);
redis.remove(key);
}
}
return redis.get(key);
}
/*
测试
*/
public static void main(String[] args) {
test01.set("name", "jay", 5000L);
while(true){
System.out.println(test01.get("name"));
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
定时删除
每添加一个设置了过期时间的数据,就为该数据指定一个线程,线程一启动就直接休眠,休眠的时间就相当于设置的过期时间,休眠时间一到,就直接将数据删除。
优点:每一个数据都能及时的删除
缺点:线程数量太多了,浪费系统资源
/*
定时删除
*/
public class test02 {
//模拟redis
private static Map<String, Object> redis = new HashMap<>();
//准备一个线程池
private static ExecutorService executorService =
new ThreadPoolExecutor(
10,
20,
3, TimeUnit.SECONDS, new LinkedBlockingDeque<Runnable>());
/*
设置值
*/
public static void set(final String key, Object value, final Long time){
redis.put(key, value);
//如果指定的过期时间 则时间一到就自动删除该数据
if(time != null){
executorService.submit(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
redis.remove(key);
}
});
}
}
/*
取值
*/
public static Object get(String key){
return redis.get(key);
}
/*
测试
*/
public static void main(String[] args) {
test02.set("name", "jay", 5000L);
while(true){
System.out.println(test02.get("name"));
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
最终方案:定期删除+惰性删除
单独指派一个线程,每隔一段时间就检查一遍:设置了过期时间的数据是否到期,如果到期了就删除
优点:会尽量及时的将过期的数据删除,并且额外的线程数量只有一个
缺点:不能绝对及时的删除过期数据
所以最终的选择方案就是使用定期删除+惰性删除:
每隔一段就去扫描一次,当取出的值在下一次扫描才会过期的时候,这次扫描不会删除,但是下次取出这个值的时候,惰性删除判断时间已经过期,就不用等到下次扫描删除了。
public class Test3 {
private static Map<String, Object> redis = new HashMap<>();
private static Map<String, Long> ttl = new HashMap();
static{
new Thread(new Runnable() {
@Override
public void run() {
//每隔5秒检查一遍
while(true){
//检查是否过期
Set<Entry<String, Long>> entrySet = ttl.entrySet();
for (Entry<String, Long> entry: entrySet) {
//如果过期则删除
if(entry.getValue() < System.currentTimeMillis()){
ttl.remove(entry.getKey());
redis.remove(entry.getKey());
}
try {
//每隔5秒检查一遍
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
}
public static void set(String key, Object value, Long time){
redis.put(key, value);
if(time != null){
ttl.put(key, System.currentTimeMillis() + time);
}
}
public static Object get(String key){
return redis.get(key);
}
public static void main(String[] args) throws InterruptedException {
Test3.set("name", "jay", 6000L);
while(true){
System.out.println(Test3.get("name"));
Thread.sleep(1000);
}
}
}
Redis的复制
主从复制是为了达成高可用
为了避免单点Redis服务器故障,准备多台服务器,互相连通。将数据复制多个副本保存在不同的服务器上,连接在一起,并保证数据是同步的。
主机:写数据
从机:复制主机的数据 只能读数据
复制流程
1--首先拷贝多个redis.conf配置文件 修改主机的配置文件 从机的配置文件
2--在从机的配置文件中slaveof指定自己的master
主机配置文件
port 6379
daemonize yes
dbfilename dump6379.rdb
dir ./
pidfile /var/run/redis_6379.pid
从机的配置文件(存在多个从机的时候,修改从机自身的端口号就可以)
port 6380
daemonize yes
dbfilename dump6380.rdb
dir ./
pidfile /var/run/redis_6380.pid
//SLAVEOF 主库IP 主库端口
slaveof 127.0.0.1 6379 #挂载主机的ip地址 端口号
测试
主机中添加数据,通过从机查看,通过role命令查看身份信息。
复制的原理
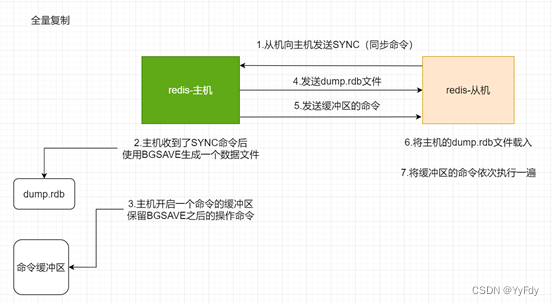
哨兵模式
反客为主的自动版,能够在后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。
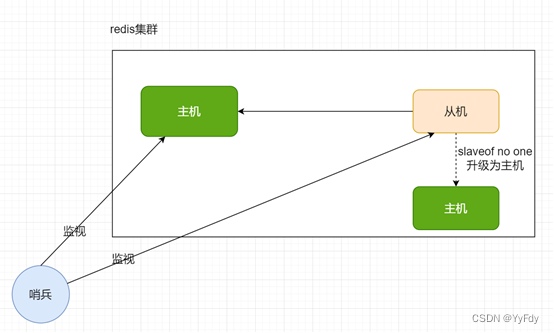
哨兵模式使用步骤
1-- 自定义新建sentinel.conf文件,名字必须是这个!!填写配置文件
sentinel monitor 被监控主机名字z(自定义1) 被监控主机ip 被监控主机端口号 1
2--启动哨兵
./redis-sentinel ../conf/sentinel.conf
最后的数字1表示当主机宕机之后,如果有超过多少个哨兵认为主机挂掉,主机才会真的挂掉,才会从从机中选择一个作为新的主机
注意:
如果原有的主机宕机之后,哨兵会重新选出一个从机变成主机,如果之前宕机掉的主机重新启动回来,是会变成新选出来的主机的从机,哨兵会帮我们修改配置文件。
Redis高可用高并发集群配置
高可用:24小时对外提供服务
高并发:同一时间段能处理的请求数 QPS
中心化
意思是所有的节点都要有一个主节点
缺点:中心挂了,服务就挂了,中心处理数据的能力有限,不能把节点性能发挥到最大
特点:就是一个路由作用
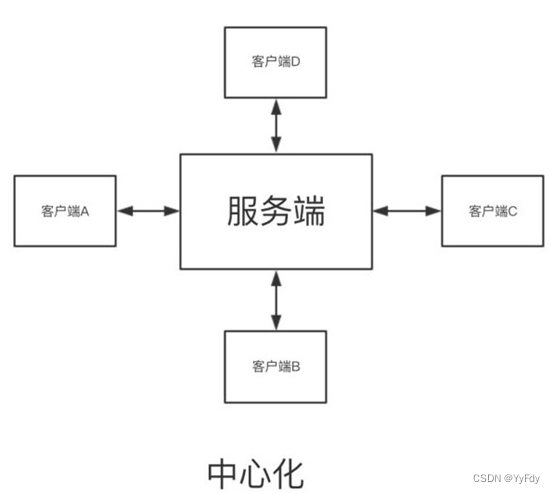
去中心化
特点:去掉路由,我自己来路由
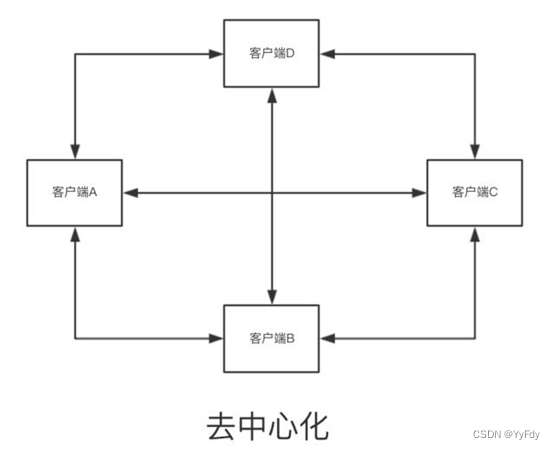
redis集群的流程分析
原理:去中心化
只要连接上了集群中任意一个主机,就相当于连接上了集群
向集群中添加数据的流程:
1--连接上集群中的任意一个主机,填写要增加的数据(key,value)
2--拿到key的值,通过某种哈希算法得到一个随机数
3--通过这个随机数就可以匹配到集群中的某个redis
redis中内置了16384个哈希槽,redis会将哈希槽大约平均分配给redis的主机
将随机数对16384取余,得到的一定是0-16383之间的数值,然后将得到的余数与哈希槽的数值进行匹配,匹配上哪一个就存放在哪一个redis
集群的搭建
案例展示搭建三个集群:三个主机,三个从机
步骤
1--准备6个配置文件
2--启动所有的redis服务 通过配置文件启动
3--使用docker下载redis-trib的镜像运行
4--通过-p指定端口连接集群
注意:搭建集群的所有redis不能存放数据,要保证集群中的每一个数据都有哈希槽。
1 配置文件
bind 0.0.0.0
port 7000 #修改其他文件的端口号即可
daemonize yes
# 打开aof 持久化
appendonly yes
# 开启集群
cluster-enabled yes
# 集群的配置文件,该文件自动生成
cluster-config-file nodes-7000.conf
# 集群的超时时间
cluster-node-timeout 5000
2 启动redis服务
3 通过docker下载镜像
#启动docker
systemctl start docker
#下载镜像
docker pull inem0o/redis-trib
#使用交互命令 连接集群
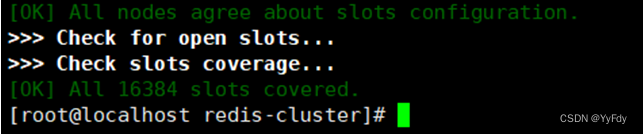
docker run -it --net host inem0o/redis-trib create --replicas 1 47.108.135.180:7000 47.108.135.180:7001 47.108.135.180:7002 47.108.135.180:7003 47.108.135.180:7004 47.108.135.180:7005
出现以下画面表示集群创建成功
4 测试
#-c 表示连接集群
./redis-cli -c -h 127.0.0.1 -p 7000
添加数据会发现,会将我们添加的元素随机存放在某个redis中。
SpringBoot整合redis
相关注解的使用
| 配置注解 | 作用 |
|---|---|
| @EnableCaching | 在启动类上加上注解启动缓存 |
| @CacheConfig | 设置当前方法中所有缓存数据的缓存名称 |
| 缓存注解 | 作用 |
|---|---|
| @CachePut | 会自动的将返回值添加到redis中,如果返回值是java对象,会自动的将该对象进行解析作为value存放 注意:我们需要指定存放的key,使用当前注解的key属性:#参数名称—>使用参数对象 一定会操作数据库的 执行添加操作的时候 会将添加的结果返回给redis |
| @CacheEvict | 删除缓存中指定key的数据 |
| @Cacheable | 先查redis,查到了就直接返回 ,查不到再查询数据库 |
| @Caching | 如果要使用多个注解,必须使用Caching来包含这多个注解 |
注意:使用注解的方式本质上是springboot使用RedisTemplate帮我们在向redis中添加数据,使用的是默认的jdk序列化工具
整合步骤
1搭建项目环境、导入连接池的依赖、配置yml配置文件
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.9.0</version>
</dependency>
mybatis-plus:
mapper-locations: classpath:mapper/*.xml
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
spring:
redis:
host: 47.108.135.180
port: 6379
lettuce: #配置连接池
pool:
max-active: 10
min-idle: 2
datasource:
driver-class-name: com.mysql.jdbc.Driver
username: root
data-password: 123456
url: jdbc:mysql://localhost:3306/db08?serverTimezone=UTC&useSSL=false&charaterEncoding=utf-8
2、在启动类上使用注解,启用缓存
@SpringBootApplication
@MapperScan("com.bjpowernode.demo02.mapper")
@EnableCaching //开启使用缓存的注解
public class Demo02Application {
public static void main(String[] args) {
SpringApplication.run(Demo02Application.class, args);
}
}
3在业务层添加相关的注解 实现缓存
//设置命令空间
@CacheConfig(cacheNames = "com.bjpowernode.demo02.service.impl.UserServiceImpl")
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User>
implements UserService{
@Autowired
private UserMapper userMapper;
/*
增加操作
需要操作数据库 操作redis缓存
*/
@Caching(
put = @CachePut(key = "#user.id"), //如果执行的是插入操作 直接操作数据库 将新插入的数据返回给redis
evict = @CacheEvict(key = "'userAll'") //每次添加成功之后 应该将缓存中的数据删除
)
@Override
public User saveUser(User user) {
userMapper.insert(user);
return user;
}
/*
删除
删除缓存中key的数据 通过id删除数据
*/
@Caching(
evict = {
@CacheEvict(key = "#id"),
@CacheEvict(key = "'userAll'")
}
)
@Override
public int removeUser(Integer id) {
return userMapper.deleteById(id);
}
/*
修改
修改之后 我们应该将更新的用户向redis中添加一次
*/
@Caching(
evict = {
@CacheEvict(key = "#user.id"),
@CacheEvict(key = "'userAll'")
}
)
@Override
public User updateUser(User user) {
userMapper.updateById(user);
return user;
}
/*
查询单个用户
*/
@Cacheable(key = "#id")
@Override
public User findByid(Integer id) {
User user = userMapper.selectById(id);
return user;
}
/*
与查询单个用户一致 只不过存入redis中的是一个集合
注意:如果指定的key为字符串常量,则需要添加单引号或者双引号进行表示
*/
@Cacheable(key = "'userAll'")
@Override
public List<User> findAll() {
return userMapper.selectList(Wrappers.emptyWrapper());
}
}
自定义序列化
若不设置序列化规则,它将使用JDK自动的序列化将对象转换为字节,存到Redis 里面
如果对象没有序列化,那么默认使用的JDK的序列化方式
1首先导入json依赖文件
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-json</artifactId>
</dependency>
2自定义类重写方法 需要注意的是,javaBean必须实现序列化接口
@Configuration
public class RedisConfig {
@Bean
public RedisCacheConfiguration redisCacheConfiguration(){
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig();
// 设置序列化的方式
redisCacheConfiguration = redisCacheConfiguration.serializeValuesWith(RedisSerializationContext
.SerializationPair
.fromSerializer(RedisSerializer.json()));
return redisCacheConfiguration;
}
}
SpringBoot操作redis的api
在springboot环境中不需要使用jedis 而是使用StringRedisTemplate/RedisTemplate进行操作本质上他们就是封装了jedis,这两个类是继承关系,而是使用StringRedisTemplate是RedisTemplate子类,所以真实开发中大多数情况就应该使用StringRedisTemplate
针对所有数据类型
public void test2(){
stringRedisTemplate.keys("*");
stringRedisTemplate.delete("a");
stringRedisTemplate.randomKey();
/*
springboot在添加值 的时候,会自动的对key与value先进行序列化然后再将序列化的结果添加到redis中
从redis中取值的时候也会自动将值反序列
意义:保证我们能添加任意类型的值
*/
stringRedisTemplate.getKeySerializer();//获取key的序列化工具
stringRedisTemplate.getValueSerializer();//获取value的序列化工具
}
String类型 opsForValue
除了String类型是opsForValue,其他都是opsForxxx
public void testString() throws InterruptedException {
//1.获取操作该类型数据的工具对象 opsForValue();
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
//2.调用响应的方法
ops.set("a", "aa", 3, TimeUnit.SECONDS);
System.out.println(ops.get("a"));
Thread.sleep(3000);
System.out.println(ops.get("a"));
}
List类型 opsForList
public void testList() throws InterruptedException {
//1.获取操作该类型数据的工具对象
ListOperations<String, String> ops = stringRedisTemplate.opsForList();
//2.调用响应的方法
ops.rightPushAll("myList", "a", "b", "c");
System.out.println(ops.range("myList", 0, -1));
}
hash类型 opsForHash
public void testHash(){
HashOperations<String, Object, Object> ops = stringRedisTemplate.opsForHash();
ops.put("myHash", "a", "aa");
System.out.println(ops.get("myHash", "a"));
}
set类型 opsForSet
public void testSet(){
SetOperations<String, String> ops = stringRedisTemplate.opsForSet();
ops.add("mySet", "a", "b", "c", "d");
System.out.println(ops.members("mySet"));
}
zset类型 opsForZSet
public void testZSet(){
ZSetOperations<String, String> ops = stringRedisTemplate.opsForZSet();
ops.add("myzset", "a", 1);
ops.add("myzset", "b", 2);
ops.add("myzset", "c", 3);
System.out.println(ops.range("myzset", 0, -1));
}
缓存穿透
缓存一直不命中 特别是恶意攻击 发一个没有值当key来查询 -1
怎么解决:做参数的校验 ,把null 或者是空串也存起来
缓存雪崩
在一段时间内 有大量的key都过期了 ,此时有大量请求进来 数据库也炸了
怎么解决:我们会均匀的设置他的过期时间,避免短时内大量过期
缓存击穿
当一个热点key 突然过期了,此时有大量请求进来 ,请求会打到数据库 ,数据库就炸了
怎么解决: 热点key 永不过期 set(k1,v2) 每次set值的时候最好给一个过期时间 避免出现淘汰策略
最后
以上就是自信小土豆最近收集整理的关于Redis基本使用Redis的全部内容,更多相关Redis基本使用Redis内容请搜索靠谱客的其他文章。








发表评论 取消回复