文章目录
- 前言
- ❤️Redis缓存的常见问题
- ????缓存穿透
- ????缓存击穿
- ????缓存雪崩
- ????数据不一致
- ❤️使用Redis作为分布式锁
- ????Redis实现分布式锁
- ????普通代码实现
- ????Redisson实现
- ????Redis分布式锁与Zookeeper分布式锁的比较
前言
前面简单的讲解了下Redis的入门知识,我们使用缓存数据库的目的是让一些查询可以直接走缓存从而减轻数据库压力,但是框架中每增加一个中间件就会产生一些对应的问题,这些问题要怎么解决呢?本篇文章对Redis的一些常见问题及解决方案做一下简单的介绍,这也是面试的时候经常会被问到的题。
❤️Redis缓存的常见问题
????缓存穿透
缓存穿透指的是Redis没有存放对应的数据,从而导致查询直接走的数据库,在高并发的情况下如果缓存穿透的情况较多会导致数据库压力过大而宕机,数据库宕机了整个系统就不能用了,我们肯定不想看到这种问题的产生,那么怎么解决这种问题呢?
我们知道什么是缓存穿透了,同样需要知道缓存穿透是怎么产生的,一般情况下我们认为Redis缓存了大部分数据库数据的,但是如果用户请求的数据在数据库中都没有呢?那缓存中肯定是不存在的,这时候肯定会缓存穿透。
????解决方案
首先我们肯定要进行缓存的,那么我们是不是也考虑下查询结果没有的情况进行缓存呢?例如查询的id为1024的数据,查询为空,我们同样把空的结果缓存起来,下次查询的时候直接根据缓存返回,如果后面真的插入id为1024的数据这时候要更新缓存的,否则就会出现BUG了。当然这种情况是有一个弊端的,如果真的有大量请求为空的查询,那么Redis中就会保存大量的空值,占用太多的空间了。
还有一个方案就是采用布隆过滤器,对于布隆过滤器我们都比较了解,可以记录大批量的Key,通过布隆过滤器来查看Key是否存在。所以我们可以在Redis的上层增加一个布隆过滤器,提前使用布隆过滤器记录数据库中的ID,在执行查询请求的时候先去布隆过滤器查询,如果当前ID存在,执行查询先走Redis再走数据库,如果布隆过滤器返回当前ID不存在,那直接返回请求结果不存在给客户端。
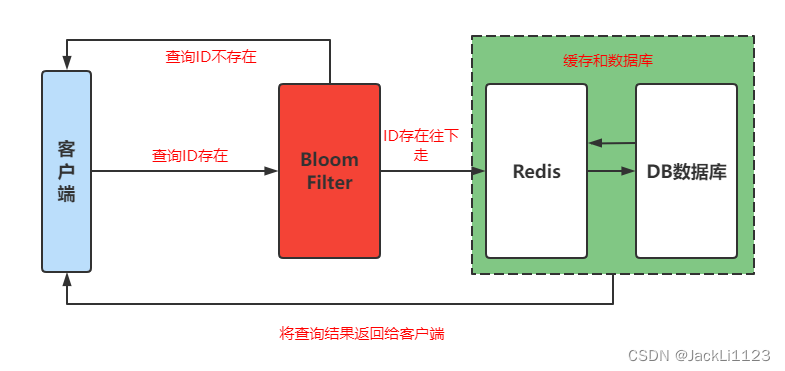
????缓存击穿
缓存击穿和缓存穿透的概念差不多,但是他们之间有一个区别就是缓存穿透指的是请求数据库中不存在的数据,缓存击穿指的是访问的数据在数据库中存在,但是缓存中不存在。如果这个数据是个热点数据(例如又有某明星结婚了)的话可能会大批量用户同时搜索该热点,这时候就会导致数据库压力过大宕机。
????解决方案
针对缓存穿透我们要思考缓存穿透产生的原因,可能热点数据在Redis中过期了,这种情况我们需要将热点数据的失效时间设置为永不过期。当然这种情况下需要注意数据的更新问题,否则某明星又离婚了你这还告诉人家刚结婚呢????。
还有种方案就是增加分布式锁,对热点数据的请求加锁,如果第一个用户请求的时候发现缓存中没有,那么直接查询数据库并且更新到缓存中,后面的用户都在排队等待,当后面的用户查询的时候缓存中已经存在了数据,这时候就直接从缓存中取数据就可以了。
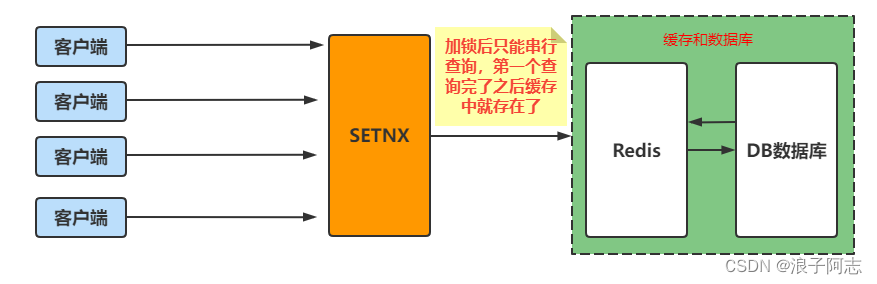
还有一种缓存击穿是服务刚开始启动,缓存中没有加载数据库的数据,这种情况下可以使用缓存预热,提前将部分数据加载到缓存中,防止刚开始启动的时候Redis是干净的导致缓存击穿数据库压力太大而宕机。
????缓存雪崩
缓存雪崩指的是大量的缓存数据可能同时失效了,所以查询走缓存的时候数据不存在所以直接请求数据库了,这时候可能会对数据库造成很大的压力,如果高并发情况下可能会导致数据库宕机。
????解决方案
这种情况下我们可以对缓存设置不同的失效时间,只要缓存中的数据不同时失效就好了。当然Redis挂掉了,正在恢复的时候另算,Redis搭建了集群,只要不全部挂掉就行。
????数据不一致
使用缓存数据库就会导致系统中出现多个数据存储读取的位置,那么就肯定会产生一个问题:数据不一致。两个数据库的更新时间肯定不一样,无论我们是先更新数据库还是先更新缓存,在这个时间过程中的数据肯定是不一致的。
针对这个情况我们需要考虑的是当前开发的系统属于什么类型的,需要数据一致性达到什么要求,如果我们做的系统是一个普通的系统,可能实现最终一致性就可以了,如果做的是金融业务的模块,这可能需要强一致性,当然如果想要强一致性就需要加锁了,把数据库和缓存通过加锁当成一个原子操作。
????关于缓存和数据库谁先操作的问题
????更新缓存问题
一般情况下缓存中的数据我们是直接删的,而不是更新。因为如果在不加锁的情况下,高并发的修改某些东西肯定会出现并发问题的。因为数据库的更新和缓存的更新不是原子操作,所以两个请求数据库的更新顺序和缓存的更新数据可能不一致,这样就导致数据库和缓存的数据不一致了。
举个例子:假设两个请求同时发送过来,请求1要把ID为1024的用户名修改为张三,请求2要把ID为1024的用户修改为李四,因为没有加锁数据库的执行顺序不一定,缓存的执行顺序也不一定。那就会存在一种情况,数据库按照请求1 -> 请求2的顺序执行的,而缓存按照请求2 -> 请求1的顺序更新的,那么数据库最终保存的结果是用户名为李四,缓存中保存的结果是用户名为张三。两者不一致。
????先删缓存再更数据库
既然更新缓存不能用,那么我们直接删除缓存吧,那先删除缓存的情况讨论一下是否会有问题,问题严重不严重。经过逻辑思考(baidu)发现一个漏洞,就是删除缓存和更新数据库是两步操作,在操作的中间是有一个时间间隙的。咱举个例子说明一下:
举个例子:假设还是高并发同时请求,现在不是两个更新操作了,而是一个更新一个读取,那么就会出现这种情况,先执行的是更新操作,删除了缓存中的数据,但是此时CPU时间片切换到了读取那边,然后读取数据又把数据库中的数据保存到了缓存中,这时候才更新数据库,那么缓存中与数据库中的数据就不一致了。
????先更数据库再删缓存
先删缓存再更新数据库存在问题,那么咱再讨论一下先更新数据库再删除缓存吧,不会也存在问题吧。????恭喜你,这样操作也是会出现缓存和数据库不一致的:还是上面的情况,咱再讨论一个CPU时间片抢占的一个特殊情况。
举个例子:假设还是上面的例子,一个更新一个读取,这次先执行的读取,读取完了数据还没有加载到缓存,CPU时间片被抢过去了,数据库更新了,缓存也删除了,但是这时候读操作的回写缓存才抢回来时间片,数据不一致的问题就又出来了。当然这个情况出现的理论概率比较低,但是也出现了不是。
????解决方案
针对上面的几种情况的讨论,数据不一致问题肯定会出现的,但是咱的业务系统不需要强一致性,假设我们允许其在10秒的时间内存在数据不一致问题,上面的三种情况肯定需要选择一种,首先更新不能选择,这个问题无法避免,除非将Redis的过期时间设置为10秒,那还有啥意义吗?
一般情况下都是选择先更新数据库再删除缓存的,因为更新数据库的时间比较长,就让它先执行了。出现了数据不一致,允许10秒内数据不一致,那么咱就定时10秒,10秒之后在删除一次缓存。我们不认为同时操作会操作了10秒钟。
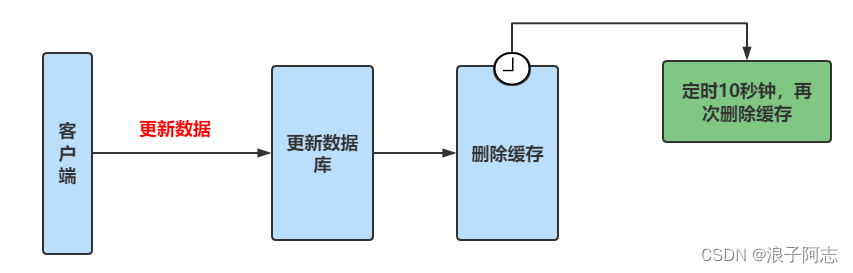
❤️使用Redis作为分布式锁
分布式锁大家都比较了解了,就是分布式多台服务器之间加锁,我们以前多线程的时候加锁是一台服务器的Java代码加锁,如果多台服务器那就是多个JVM环境之间加锁。
常见的分布式锁的实现方式Redis和Zookeeper,咱这次主要讲一下使用Redis怎么实现分布式锁的。
????Redis实现分布式锁
????普通代码实现
看一下加锁的代码:
/**
* @param lockKey 锁的Key
* @param requestId 请求ID,一般使用UUID+ThreadId
* @param expireTime 过期时间
* @return
*/
public boolean getLock(String lockKey, String requestId, int expireTime) {
String result = jedis.set(lockKey, requestId, "NX", "EX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;
}
再看一下解锁的代码:
/**
* @param lockKey 锁的Key
* @param requestId 请求ID,一般使用UUID+ThreadId
*/
public static boolean releaseLock(String lockKey, String requestId) {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId));
if (result.equals(1L)) {
return true;
}
return false;
}
????上面的实现方式是手写的存在一定的漏洞,咱先分析一下可能会存在什么问题
问题一: 首先我们使用的Redis肯定是个集群的,是集群就可能发生这么一个问题,Redis中的一台节点宕机了,如果宕机的是从节点是没有问题的,但是如果宕机的是主节点呢?
主节点SETNX完成了,但是从节点还没有复制过来的时候主节点挂了,那么这个锁其实是无效的,但是返回给程序的状态是有效的。这时候检测到主节点挂了,其中一个从节点升级为主节点,因为从节点还没有复制SETNX,所以从节点不知道已经加锁了,其他请求发送过来SETNX结果返回了1,这样就会同时有两个代码在使用同一把锁执行。
问题二: 这种方式实现的分布式锁是不能续租的,假设过期时间到了代码还没有执行完成可能锁就到期了,当然你也可以设置过期时间大一点,但是这样会死锁代码卡住好长一段时间。
怎么解决上面的问题呢?我们可以使用对应的框架Redisson
????Redisson实现
代码咱就不讲解了,代码很简单,网上有一大堆,咱看一下Redisson实现的原理过程:
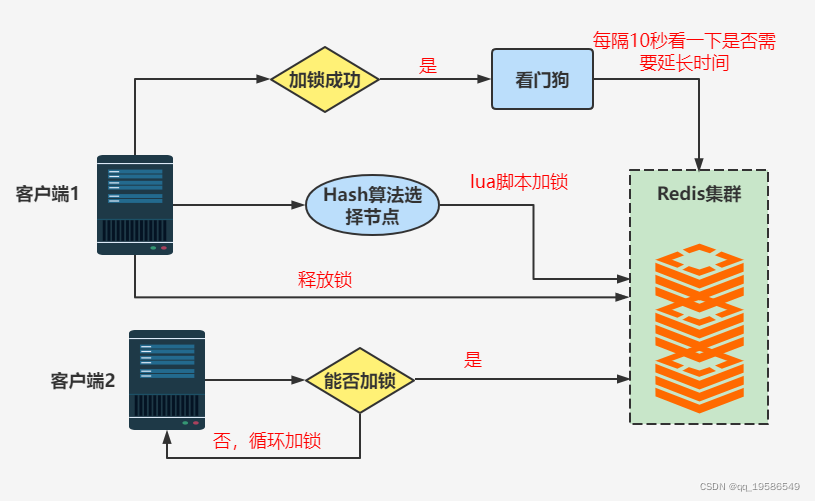
Redisson实现的分布式锁比普通的Redis实现分布式锁多加了两个功能:
锁的续租: 锁的续租好说,看上面的原理图,在加锁成功后客户端会建立起看门狗(第一次听到看门狗还是学单片机的时候呢),每隔10秒都会检查一下锁是否过期,是否需要续租,需要的话会延长锁的时间,当然不是一直延长,是一个递减的延长。
锁的重入: Redisson实现的分布式锁是可以实现重入锁的,我们知道Redis有个自增操作的,如果锁重入了Redisson里面的记录数会自增,释放的时候会自减,直到为0完全释放锁。
Redisson也是没有解决集群情况下多个客户端获取锁的情况的,因为Redisson的集群使用的CAP理论中的AP理论,如果需要解决这个问题可以考虑使用Zookeeper实现分布式锁,Zookeeper的分布式锁是CP理论的。
????Redis分布式锁与Zookeeper分布式锁的比较
| # | Redis | Zookeeper |
|---|---|---|
| 一致性算法 | 无 | ZAB |
| CAP理论 | AP | CP |
| 高可用 | 主从集群 | n+1 |
| 实现方式 | SETNX | createEphemeral |
最后
以上就是背后翅膀最近收集整理的关于Redis常见问题及解决方案前言❤️Redis缓存的常见问题❤️使用Redis作为分布式锁的全部内容,更多相关Redis常见问题及解决方案前言❤️Redis缓存内容请搜索靠谱客的其他文章。








发表评论 取消回复