/** Spark SQL源码分析系列文章*/
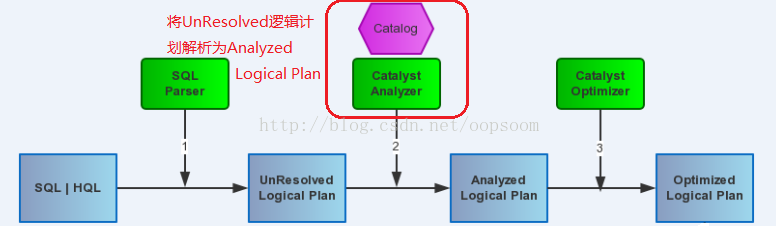
前面几篇文章讲解了Spark SQL的核心执行流程和Spark SQL的Catalyst框架的Sql Parser是怎样接受用户输入sql,经过解析生成Unresolved Logical Plan的。我们记得Spark SQL的执行流程中另一个核心的组件式Analyzer,本文将会介绍Analyzer在Spark SQL里起到了什么作用。
Analyzer位于Catalyst的analysis package下,主要职责是将Sql Parser 未能Resolved的Logical Plan 给Resolved掉。
一、Analyzer构造
Analyzer会使用Catalog和FunctionRegistry将UnresolvedAttribute和UnresolvedRelation转换为catalyst里全类型的对象。
Analyzer里面有fixedPoint对象,一个Seq[Batch].
-
class Analyzer(catalog: Catalog, registry: FunctionRegistry, caseSensitive: Boolean) -
extends RuleExecutor[LogicalPlan] with HiveTypeCoercion { -
// TODO: pass this in as a parameter. -
val fixedPoint = FixedPoint(100) -
val batches: Seq[Batch] = Seq( -
Batch("MultiInstanceRelations", Once, -
NewRelationInstances), -
Batch("CaseInsensitiveAttributeReferences", Once, -
(if (caseSensitive) Nil else LowercaseAttributeReferences :: Nil) : _*), -
Batch("Resolution", fixedPoint, -
ResolveReferences :: -
ResolveRelations :: -
NewRelationInstances :: -
ImplicitGenerate :: -
StarExpansion :: -
ResolveFunctions :: -
GlobalAggregates :: -
typeCoercionRules :_*), -
Batch("AnalysisOperators", fixedPoint, -
EliminateAnalysisOperators) -
)
Analyzer里的一些对象解释:
FixedPoint:相当于迭代次数的上限。
-
/** A strategy that runs until fix point or maxIterations times, whichever comes first. */ -
case class FixedPoint(maxIterations: Int) extends Strategy
Batch: 批次,这个对象是由一系列Rule组成的,采用一个策略(策略其实是迭代几次的别名吧,eg:Once)
-
/** A batch of rules. */, -
protected case class Batch(name: String, strategy: Strategy, rules: Rule[TreeType]*)
Rule:理解为一种规则,这种规则会应用到Logical Plan 从而将UnResolved 转变为Resolved
-
abstract class Rule[TreeType <: TreeNode[_]] extends Logging { -
/** Name for this rule, automatically inferred based on class name. */ -
val ruleName: String = { -
val className = getClass.getName -
if (className endsWith "$") className.dropRight(1) else className -
} -
def apply(plan: TreeType): TreeType -
}
Strategy:最大的执行次数,如果执行次数在最大迭代次数之前就达到了fix point,策略就会停止,不再应用了。
-
/** -
* An execution strategy for rules that indicates the maximum number of executions. If the -
* execution reaches fix point (i.e. converge) before maxIterations, it will stop. -
*/ -
abstract class Strategy { def maxIterations: Int }
Analyzer解析主要是根据这些Batch里面定义的策略和Rule来对Unresolved的逻辑计划进行解析的。
这里Analyzer类本身并没有定义执行的方法,而是要从它的父类RuleExecutor[LogicalPlan]寻找,Analyzer也实现了HiveTypeCosercion,这个类是参考Hive的类型自动兼容转换的原理。如图:
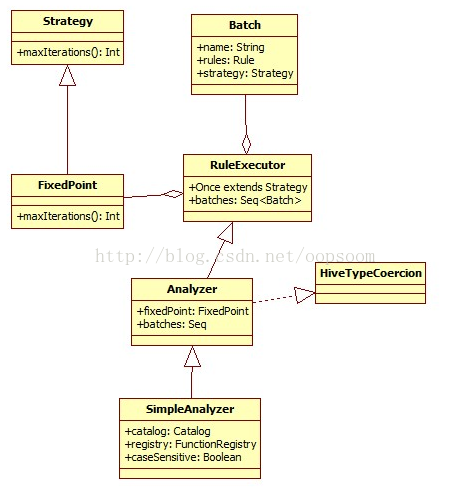
RuleExecutor:执行Rule的执行环境,它会将包含了一系列的Rule的Batch进行执行,这个过程都是串行的。
具体的执行方法定义在apply里:
可以看到这里是一个while循环,每个batch下的rules都对当前的plan进行作用,这个过程是迭代的,直到达到Fix Point或者最大迭代次数。
-
def apply(plan: TreeType): TreeType = { -
var curPlan = plan -
batches.foreach { batch => -
val batchStartPlan = curPlan -
var iteration = 1 -
var lastPlan = curPlan -
var continue = true -
// Run until fix point (or the max number of iterations as specified in the strategy. -
while (continue) { -
curPlan = batch.rules.foldLeft(curPlan) { -
case (plan, rule) => -
val result = rule(plan) //这里将调用各个不同Rule的apply方法,将UnResolved Relations,Attrubute和Function进行Resolve -
if (!result.fastEquals(plan)) { -
logger.trace( -
s""" -
|=== Applying Rule ${rule.ruleName} === -
|${sideBySide(plan.treeString, result.treeString).mkString("n")} -
""".stripMargin) -
} -
result //返回作用后的result plan -
} -
iteration += 1 -
if (iteration > batch.strategy.maxIterations) { //如果迭代次数已经大于该策略的最大迭代次数,就停止循环 -
logger.info(s"Max iterations ($iteration) reached for batch ${batch.name}") -
continue = false -
} -
if (curPlan.fastEquals(lastPlan)) { //如果在多次迭代中不再变化,因为plan有个unique id,就停止循环。 -
logger.trace(s"Fixed point reached for batch ${batch.name} after $iteration iterations.") -
continue = false -
} -
lastPlan = curPlan -
} -
if (!batchStartPlan.fastEquals(curPlan)) { -
logger.debug( -
s""" -
|=== Result of Batch ${batch.name} === -
|${sideBySide(plan.treeString, curPlan.treeString).mkString("n")} -
""".stripMargin) -
} else { -
logger.trace(s"Batch ${batch.name} has no effect.") -
} -
} -
curPlan //返回Resolved的Logical Plan -
}
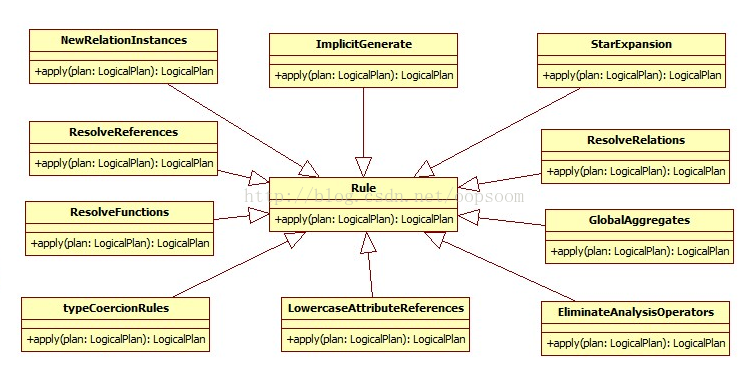
二、Rules介绍
目前Spark SQL 1.0.0的Rule都定义在了Analyzer.scala的内部类。
在batches里面定义了4个Batch。
MultiInstanceRelations、CaseInsensitiveAttributeReferences、Resolution、AnalysisOperators 四个。
这4个Batch是将不同的Rule进行归类,每种类别采用不同的策略来进行Resolve。
2.1、MultiInstanceRelation
如果一个实例在Logical Plan里出现了多次,则会应用NewRelationInstances这儿Rule
-
Batch("MultiInstanceRelations", Once, -
NewRelationInstances)
-
trait MultiInstanceRelation { -
def newInstance: this.type -
}
-
object NewRelationInstances extends Rule[LogicalPlan] { -
def apply(plan: LogicalPlan): LogicalPlan = { -
val localRelations = plan collect { case l: MultiInstanceRelation => l} //将logical plan应用partial function得到所有MultiInstanceRelation的plan的集合 -
val multiAppearance = localRelations -
.groupBy(identity[MultiInstanceRelation]) //group by操作 -
.filter { case (_, ls) => ls.size > 1 } //如果只取size大于1的进行后续操作 -
.map(_._1) -
.toSet -
//更新plan,使得每个实例的expId是唯一的。 -
plan transform { -
case l: MultiInstanceRelation if multiAppearance contains l => l.newInstance -
} -
} -
}
2.2、LowercaseAttributeReferences
同样是partital function,对当前plan应用,将所有匹配的如UnresolvedRelation的别名alise转换为小写,将Subquery的别名也转换为小写。
总结:这是一个使属性名大小写不敏感的Rule,因为它将所有属性都to lower case了。
-
object LowercaseAttributeReferences extends Rule[LogicalPlan] { -
def apply(plan: LogicalPlan): LogicalPlan = plan transform { -
case UnresolvedRelation(databaseName, name, alias) => -
UnresolvedRelation(databaseName, name, alias.map(_.toLowerCase)) -
case Subquery(alias, child) => Subquery(alias.toLowerCase, child) -
case q: LogicalPlan => q transformExpressions { -
case s: Star => s.copy(table = s.table.map(_.toLowerCase)) -
case UnresolvedAttribute(name) => UnresolvedAttribute(name.toLowerCase) -
case Alias(c, name) => Alias(c, name.toLowerCase)() -
case GetField(c, name) => GetField(c, name.toLowerCase) -
} -
} -
}
2.3、ResolveReferences
将Sql parser解析出来的UnresolvedAttribute全部都转为对应的实际的catalyst.expressions.AttributeReference AttributeReferences
这里调用了logical plan 的resolve方法,将属性转为NamedExepression。
-
object ResolveReferences extends Rule[LogicalPlan] { -
def apply(plan: LogicalPlan): LogicalPlan = plan transformUp { -
case q: LogicalPlan if q.childrenResolved => -
logger.trace(s"Attempting to resolve ${q.simpleString}") -
q transformExpressions { -
case u @ UnresolvedAttribute(name) => -
// Leave unchanged if resolution fails. Hopefully will be resolved next round. -
val result = q.resolve(name).getOrElse(u)//转化为NamedExpression -
logger.debug(s"Resolving $u to $result") -
result -
} -
} -
}
2.4、 ResolveRelations
这个比较好理解,还记得前面Sql parser吗,比如select * from src,这个src表parse后就是一个UnresolvedRelation节点。
这一步ResolveRelations调用了catalog这个对象。Catalog对象里面维护了一个tableName,Logical Plan的HashMap结果。
通过这个Catalog目录来寻找当前表的结构,从而从中解析出这个表的字段,如UnResolvedRelations 会得到一个tableWithQualifiers。(即表和字段)
这也解释了为什么流程图那,我会画一个catalog在上面,因为它是Analyzer工作时需要的meta data。
-
object ResolveRelations extends Rule[LogicalPlan] { -
def apply(plan: LogicalPlan): LogicalPlan = plan transform { -
case UnresolvedRelation(databaseName, name, alias) => -
catalog.lookupRelation(databaseName, name, alias) -
} -
}
2.5、ImplicitGenerate
如果在select语句里只有一个表达式,而且这个表达式是一个Generator(Generator是一个1条记录生成到N条记录的映射)
当在解析逻辑计划时,遇到Project节点的时候,就可以将它转换为Generate类(Generate类是将输入流应用一个函数,从而生成一个新的流)。
-
object ImplicitGenerate extends Rule[LogicalPlan] { -
def apply(plan: LogicalPlan): LogicalPlan = plan transform { -
case Project(Seq(Alias(g: Generator, _)), child) => -
Generate(g, join = false, outer = false, None, child) -
} -
}
2.6 StarExpansion
在Project操作符里,如果是*符号,即select * 语句,可以将所有的references都展开,即将select * 中的*展开成实际的字段。
-
object StarExpansion extends Rule[LogicalPlan] { -
def apply(plan: LogicalPlan): LogicalPlan = plan transform { -
// Wait until children are resolved -
case p: LogicalPlan if !p.childrenResolved => p -
// If the projection list contains Stars, expand it. -
case p @ Project(projectList, child) if containsStar(projectList) => -
Project( -
projectList.flatMap { -
case s: Star => s.expand(child.output) //展开,将输入的Attributeexpand(input: Seq[Attribute]) 转化为Seq[NamedExpression] -
case o => o :: Nil -
}, -
child) -
case t: ScriptTransformation if containsStar(t.input) => -
t.copy( -
input = t.input.flatMap { -
case s: Star => s.expand(t.child.output) -
case o => o :: Nil -
} -
) -
// If the aggregate function argument contains Stars, expand it. -
case a: Aggregate if containsStar(a.aggregateExpressions) => -
a.copy( -
aggregateExpressions = a.aggregateExpressions.flatMap { -
case s: Star => s.expand(a.child.output) -
case o => o :: Nil -
} -
) -
} -
/** -
* Returns true if `exprs` contains a [[Star]]. -
*/ -
protected def containsStar(exprs: Seq[Expression]): Boolean = -
exprs.collect { case _: Star => true }.nonEmpty -
} -
}
2.7 ResolveFunctions
这个和ResolveReferences差不多,这里主要是对udf进行resolve。
将这些UDF都在FunctionRegistry里进行查找。
-
object ResolveFunctions extends Rule[LogicalPlan] { -
def apply(plan: LogicalPlan): LogicalPlan = plan transform { -
case q: LogicalPlan => -
q transformExpressions { -
case u @ UnresolvedFunction(name, children) if u.childrenResolved => -
registry.lookupFunction(name, children) //看是否注册了当前udf -
} -
} -
}
2.8 GlobalAggregates
全局的聚合,如果遇到了Project就返回一个Aggregate.
-
object GlobalAggregates extends Rule[LogicalPlan] { -
def apply(plan: LogicalPlan): LogicalPlan = plan transform { -
case Project(projectList, child) if containsAggregates(projectList) => -
Aggregate(Nil, projectList, child) -
} -
def containsAggregates(exprs: Seq[Expression]): Boolean = { -
exprs.foreach(_.foreach { -
case agg: AggregateExpression => return true -
case _ => -
}) -
false -
} -
}
2.9 typeCoercionRules
这个是Hive里的兼容SQL语法,比如将String和Int互相转换,不需要显示的调用cast xxx as yyy了。如StringToIntegerCasts。
-
val typeCoercionRules = -
PropagateTypes :: -
ConvertNaNs :: -
WidenTypes :: -
PromoteStrings :: -
BooleanComparisons :: -
BooleanCasts :: -
StringToIntegralCasts :: -
FunctionArgumentConversion :: -
CastNulls :: -
Nil
2.10 EliminateAnalysisOperators
将分析的操作符移除,这里仅支持2种,一种是Subquery需要移除,一种是LowerCaseSchema。这些节点都会从Logical Plan里移除。
-
object EliminateAnalysisOperators extends Rule[LogicalPlan] { -
def apply(plan: LogicalPlan): LogicalPlan = plan transform { -
case Subquery(_, child) => child //遇到Subquery,不反悔本身,返回它的Child,即删除了该元素 -
case LowerCaseSchema(child) => child -
} -
}
三、实践
补充昨天DEBUG的一个例子,这个例子证实了如何将上面的规则应用到Unresolved Logical Plan:
当传递sql语句的时候,的确调用了ResolveReferences将mobile解析成NamedExpression。
可以对照这看执行流程,左边是Unresolved Logical Plan,右边是Resoveld Logical Plan。
先是执行了Batch Resolution,eg: 调用ResovelRalation这个RUle来使 Unresovled Relation 转化为 SparkLogicalPlan并通过Catalog找到了其对于的字段属性。
然后执行了Batch Analysis Operator。eg:调用EliminateAnalysisOperators来将SubQuery给remove掉了。
可能格式显示的不太好,可以向右边拖动下滚动轴看下结果。 :)
-
val exec = sqlContext.sql("select mobile as mb, sid as id, mobile*2 multi2mobile, count(1) times from (select * from temp_shengli_mobile)a where pfrom_id=0.0 group by mobile, sid, mobile*2") -
14/07/21 18:23:32 DEBUG SparkILoop$SparkILoopInterpreter: Invoking: public static java.lang.String $line47.$eval.$print() -
14/07/21 18:23:33 INFO Analyzer: Max iterations (2) reached for batch MultiInstanceRelations -
14/07/21 18:23:33 INFO Analyzer: Max iterations (2) reached for batch CaseInsensitiveAttributeReferences -
14/07/21 18:23:33 DEBUG Analyzer$ResolveReferences$: Resolving 'pfrom_id to pfrom_id#5 -
14/07/21 18:23:33 DEBUG Analyzer$ResolveReferences$: Resolving 'mobile to mobile#2 -
14/07/21 18:23:33 DEBUG Analyzer$ResolveReferences$: Resolving 'sid to sid#1 -
14/07/21 18:23:33 DEBUG Analyzer$ResolveReferences$: Resolving 'mobile to mobile#2 -
14/07/21 18:23:33 DEBUG Analyzer$ResolveReferences$: Resolving 'mobile to mobile#2 -
14/07/21 18:23:33 DEBUG Analyzer$ResolveReferences$: Resolving 'sid to sid#1 -
14/07/21 18:23:33 DEBUG Analyzer$ResolveReferences$: Resolving 'mobile to mobile#2 -
14/07/21 18:23:33 DEBUG Analyzer: -
=== Result of Batch Resolution === -
!Aggregate ['mobile,'sid,('mobile * 2) AS c2#27], ['mobile AS mb#23,'sid AS id#24,('mobile * 2) AS multi2mobile#25,COUNT(1) AS times#26L] Aggregate [mobile#2,sid#1,(CAST(mobile#2, DoubleType) * CAST(2, DoubleType)) AS c2#27], [mobile#2 AS mb#23,sid#1 AS id#24,(CAST(mobile#2, DoubleType) * CAST(2, DoubleType)) AS multi2mobile#25,COUNT(1) AS times#26L] -
! Filter ('pfrom_id = 0.0) Filter (CAST(pfrom_id#5, DoubleType) = 0.0) -
Subquery a Subquery a -
! Project [*] Project [data_date#0,sid#1,mobile#2,pverify_type#3,create_time#4,pfrom_id#5,p_status#6,pvalidate_time#7,feffect_time#8,plastupdate_ip#9,update_time#10,status#11,preserve_int#12] -
! UnresolvedRelation None, temp_shengli_mobile, None Subquery temp_shengli_mobile -
! SparkLogicalPlan (ExistingRdd [data_date#0,sid#1,mobile#2,pverify_type#3,create_time#4,pfrom_id#5,p_status#6,pvalidate_time#7,feffect_time#8,plastupdate_ip#9,update_time#10,status#11,preserve_int#12], MapPartitionsRDD[4] at mapPartitions at basicOperators.scala:174) -
14/07/21 18:23:33 DEBUG Analyzer: -
=== Result of Batch AnalysisOperators === -
!Aggregate ['mobile,'sid,('mobile * 2) AS c2#27], ['mobile AS mb#23,'sid AS id#24,('mobile * 2) AS multi2mobile#25,COUNT(1) AS times#26L] Aggregate [mobile#2,sid#1,(CAST(mobile#2, DoubleType) * CAST(2, DoubleType)) AS c2#27], [mobile#2 AS mb#23,sid#1 AS id#24,(CAST(mobile#2, DoubleType) * CAST(2, DoubleType)) AS multi2mobile#25,COUNT(1) AS times#26L] -
! Filter ('pfrom_id = 0.0) Filter (CAST(pfrom_id#5, DoubleType) = 0.0) -
! Subquery a Project [data_date#0,sid#1,mobile#2,pverify_type#3,create_time#4,pfrom_id#5,p_status#6,pvalidate_time#7,feffect_time#8,plastupdate_ip#9,update_time#10,status#11,preserve_int#12] -
! Project [*] SparkLogicalPlan (ExistingRdd [data_date#0,sid#1,mobile#2,pverify_type#3,create_time#4,pfrom_id#5,p_status#6,pvalidate_time#7,feffect_time#8,plastupdate_ip#9,update_time#10,status#11,preserve_int#12], MapPartitionsRDD[4] at mapPartitions at basicOperators.scala:174) -
! UnresolvedRelation None, temp_shengli_mobile, None
四、总结
本文从源代码角度分析了Analyzer在对Sql Parser解析出的UnResolve Logical Plan 进行analyze的过程中,所执行的流程。
流程是实例化一个SimpleAnalyzer,定义一些Batch,然后遍历这些Batch在RuleExecutor的环境下,执行Batch里面的Rules,每个Rule会对Unresolved Logical Plan进行Resolve,有些可能不能一次解析出,需要多次迭代,直到达到max迭代次数或者达到fix point。这里Rule里比较常用的就是ResolveReferences、ResolveRelations、StarExpansion、GlobalAggregates、typeCoercionRules和EliminateAnalysisOperators。
最后
以上就是老实发夹最近收集整理的关于Spark SQL Catalyst源码分析之Analyzer的全部内容,更多相关Spark内容请搜索靠谱客的其他文章。








发表评论 取消回复