1.背景介绍
今天在公司接到一个需求,大概是这样的.我们ERP系统数据库有张customer(客户)表,其中有个字段是小区名称(plotName),当初在录入数据时没有对这一字段做界定和规范,由人工手动录入,这就导致两位客户本是一个小区,而录入的小区名可能不是完全一样的结果.例如张三和李四都住在武林邸,而张三录入的数据是"武林邸",李四录入的数据的"杭州市西湖区武林邸",又或是舞林邸等.由于业务需要,现需要对这些小区名进行名称规整,如上述例子都规整为"杭州市西湖区武林邸".
2.解决方案如下
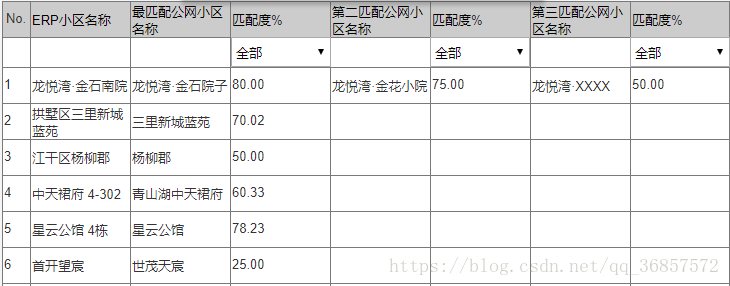
既然要规整,就要有统一的名称规范,最终决定从安居客,租房网等爬出杭州市各小区的标准名称.再用数据库现有数据与之对比.列出最相似的前三个名称,然后泽其一修数据库数据.
如下图所示:匹配度及为相似度算法计算所得结果.
3.难点
难点就是字符串相似度对比算法的设计,网上查阅大量资料,如字符串最小编辑距离匹配算法此处不适用,因为对比的字符串与目标字符串长度不一样,会导致对比结果不是正确的.用代码和数据验证如下:
对比的三个字符串如下: 目标字符串为:"龙悦湾金石院子"
- "浙江省杭州市拱墅区龙悦湾金石院子"
- "金石院子十六幢二单元302"
- "金子"
public static void main(String[] args){
LinkedList list=new LinkedList();
String source = "龙悦湾金石院子";//目标字符串
String target1 = "浙江省杭州市拱墅区龙悦湾金石院子";
String target2="金石院子十六幢二单元302";
String target3="金子";
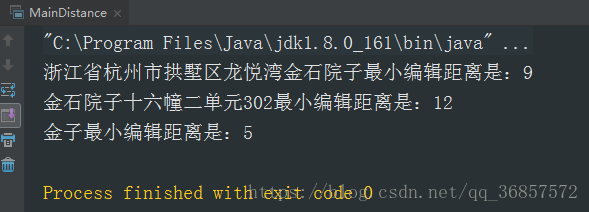
System.out.println(target1+"最小编辑距离是:"+minEdit_distance(source,target1));
System.out.println(target2+"最小编辑距离是:"+minEdit_distance(source,target2));
System.out.println(target3+"最小编辑距离是:"+minEdit_distance(source,target3));
}其中minEdit_distance()方法是最小编辑距离算法,根据此算法的思想,如果最小编辑距离值越小,则说明两个字符串越相似.而此处打印结果为9,12,5.即"金子"与"龙悦湾金石院子"最相似,"浙江省杭州市拱墅区龙悦湾金石院子"第二,"金石院子十六幢二单元302"第三,而实际应该是"金子"与"龙悦湾金石院子"最不相似,是不期望得到的结果.
打印结果:
4.最终解决方案
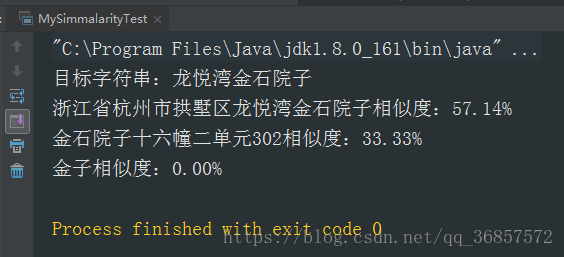
将字符串和目标字符串去空格后转为单字符集,定义一个变量intersection,自定义算法计算让intersection值增加,相似度百分比值=intersection*2/unionLength(两个字符串长度和)*100.
代码如下:
public static String compareStrings(String str1, String str2) {
DecimalFormat df = new DecimalFormat("0.00");//格式化小数
ArrayList pairs1 = wordLetterPairs(str1.toUpperCase());
ArrayList pairs2 = wordLetterPairs(str2.toUpperCase());
int intersection = 0;
int union = pairs1.size() + pairs2.size();
for (int i=0; i<pairs1.size(); i++) {
Object pair1=pairs1.get(i);
for(int j=0; j<pairs2.size(); j++) {
Object pair2=pairs2.get(j);
if (pair1.equals(pair2)) {
intersection++;
pairs2.remove(j);
break;
}
}
}
return df.format((2.0*intersection)/union*100)+"%";
}
private static String[] letterPairs(String str) {
int numPairs = str.length()-1;
String[] pairs = new String[numPairs];
for (int i=0; i<numPairs; i++) {
pairs[i] = str.substring(i,i+2);
}
return pairs;
}
private static ArrayList wordLetterPairs(String str) {
ArrayList allPairs = new ArrayList();
String[] words = str.split("\s");
for (int w=0; w < words.length; w++) {
String[] pairsInWord = letterPairs(words[w]);
for (int p=0; p < pairsInWord.length; p++) {
allPairs.add(pairsInWord[p]);
}
}
return allPairs;
}运行结果:正确
最后
以上就是受伤短靴最近收集整理的关于不同长度的字符串/中文串相似度对比算法的全部内容,更多相关不同长度内容请搜索靠谱客的其他文章。








发表评论 取消回复