系列文章目录
服务器开发系列(一)——计算机硬件
服务器开发系列(二)——Jetson Xavier NX
服务器开发系列(三)——Linux与Windows操作系统基础功能对比
服务器开发系列(四)——网络基础
文章目录
- 系列文章目录
- 前言
- 一、服务器运维概述
- (1)用户权限管理
- (2)磁盘存储管理
- (3)文件系统管理
- (4)进程管理与监控
- 二、运维常用命令
- (1)性能监控类命令
- (2)查询当前整个系统每个进程的线程数
- (3)检测系统中的僵尸进程并将其kill
- (4)查看当前占用CPU或内存最多的几个进程
- (5)服务器状态监控脚本
- 三、Linux系统性能优化
- (1)进程指标:
- (2)内存指标:
- (3)文件系统指标:
- (4)磁盘I/O指标:
- (5)网络指标:
- (1)CPU性能瓶颈的特征
- (2)内存性能瓶颈的特征
- (3)磁盘性能瓶颈的特征
- (4)网络性能瓶颈的特征
- (1)内存资源(物理内存/虚拟内存)性能调优
- (2)磁盘I/O性能调优
- (3)网络性能调优
- (4)其他性能调优
- 四、系统运维常用工具
- 总结
- 参考资料
前言
服务器搭建非常简单,但服务器运维却相对复杂,还需要更多的时间,其是网络系统的重要组成部分。这里基于Linux相关书籍中的运维实操体系,对Linux系统的系统运维进行了梳理。
这里使用的Linux系统是Ubuntu18.04。
一、服务器运维概述
运维工作通常是用来维护网站,系统,硬件等正常运作。运维工程师简单来讲,简单来说,类似网吧网管,专业来说,运维工程师是集合网络、系统、数据库、开发、安全工作于一身的“复合性人才”。
Linux系统的用户权限管理、磁盘存储管理、文件系统管理、进程监控与管理,这4个方面是Linux运维的核心内容,很多问题的排查和故障解决都依赖于此。
(1)用户权限管理
系统运维人员有时候可能会遇到通过root用户都不能修改或者删除某个文件的情况,产生这种情况的大部分原因是这个问题被锁定了。在Linux下锁定文件的命令是chattr,通过这个命令可以修改EXT2、EXT3、EXT4文件系统下的文件属性,但这个命令必须由超级用户root来执行。命令lsattr则用来查询文件属性。
①对一些重要的目录和文件可以加上i属性,用来设定文件不能被修改、删除、重命名、设定链接等,同时不能写入或新增内容。
常见的文件和目录有:
$ chattr +i /etc/sudoers
②对一些重要的日志文件可以加上a属性,设定该参数后,只能向文件中添加数据,而不能删除。此选项常用于服务器日志文件安全,只有root用户才能设置这个属性。
$ chattr +a /var/log/messages
(2)磁盘存储管理
fdisk是Linux下一款功能强大的磁盘分区管理工具,可以观察硬盘的使用情况,也可以对磁盘进行分割。fdisk的使用分为两个部分,查询部分和交互操作部分。通过fdisk device即可进入命令交互操作界面,输入m显示交互操作下所有可使用命令:
$ fdisk /dev/sdb
①d:删除一个分区;
②l:查看指定分区的分区表信息;
③n:增加一个新分区;
④p:显示分区信息;
⑤q:退出交互操作,不保存操作内容;
⑥w:写分区表信息到硬盘,保存操作并退出。
关于磁盘的常见运维操作有以下几类:
①创建磁盘分区:
假设现有Linux系统增加了一块硬盘,设备名为/dev/sdb:
$ fdisk /dev/sdb
>>> Command (m for help): n # 创建一个新的磁盘分区
...
>>> primary partition: p # 创建主分区
>>> Partition number (1-4): 1 # 主分区编号从1-4 这里输入1
>>> First cylinder (1-1044, default 1): # 这里指定分区的起始值 这里使用默认值
>>> Last cylinder or +size or +sizeM or + sizeK (1-1044, default 1044): +1024M # 这里指定分区大小 直接输入需要的分区大小即可
>>> Command (m for help): p # 这里查询显示分区情况
>>> Command (m for help): n # 继续创建一个分区
>>> primary partition: p
>>> Partition number (1-4): 2
>>> Last cylinder or +size or +sizeM or + sizeK (126-1044, default 1044): +1024M
>>> Command (m for help): p
>>> Command (m for help): n
>>> primary partition: e # 创建一个扩展分区
>>> Partition number (1-4): 3
>>> Last cylinder or +size or +sizeM or + sizeK (251-1044, default 1044): # 根据磁盘分区的划分标准 如果要建立扩展分区 最好将磁盘所有剩余空间都分给扩展分区 这里直接Enter 使用默认的全部剩余空间
>>> Command (m for help): p
>>> Command (m for help): n
>>> primary partition: l # 创建一个逻辑分区
>>> First cylinder (251-1044, default 251): # 这里直接Enter 使用默认值
>>> Last cylinder or +size or +sizeM or + sizeK (251-1044, default 1044): +1024M # 创建逻辑分区大小
>>> Command (m for help): p
>>> Command (m for help): n
>>> primary partition: l # 再创建一个逻辑分区
>>> First cylinder (376-1044, default 376):
>>> Last cylinder or +size or +sizeM or + sizeK (376-1044, default 1044): # 使用默认值 将剩余空间都划入此逻辑分区
>>> Command (m for help): p
②修改磁盘分区类型:
Linux下根据ID值区分不同的磁盘分区类型。fdisk默认创建的主分区和逻辑分区类型为Linux,对应的ID为83,扩展分区默认为Extended,对应的ID为5。如果想要修改分区类型或者创建一个非默认的分区类型,可以用fdisk的交互参数t来指定:
$ fdisk /dev/sdb
>>> Command (m for help): p
>>> Device Boot Start End Blocks Id System
>>> /dev/sdb1 1 125 1004031 83 Linux
>>> /dev/sdb2 126 250 1004062+ 83 Linux
>>> /dev/sdb3 251 1044 6377805 5 Extended
>>> /dev/sdb5 251 375 1004031 83 Linux
>>> /dev/sdb6 376 1044 5373711 83 Linux
>>> Command (m for help): t # 输入t改变磁盘分区的类型
>>> Partition number (1-6): 5 # 要改变的磁盘分区对应的分区号 这里输入5代表/dev/sdb5
>>> Hex code (type L to list codes): L # 通过L可以查看分区类型对应的ID值
>>> Hex code (type L to list codes): 7 # 7对应的分区类型为HPFS/NTFS
>>> Command (m for help): p
③分区的删除:
$ fdisk /dev/sdb
>>> Command (m for help): p
>>> Device Boot Start End Blocks Id System
>>> /dev/sdb1 1 125 1004031 83 Linux
>>> /dev/sdb2 126 250 1004062+ 83 Linux
>>> /dev/sdb3 251 1044 6377805 5 Extended
>>> /dev/sdb5 251 375 1004031 7 HPFS/NTFS
>>> /dev/sdb6 376 1044 5373711 83 Linux
>>> Command (m for help): d # 这里输入删除分区的指令
>>> Partition number (1-6): 6 # 这里输入6代表/dev/sdb6
>>> Command (m for help): p
④保存分区设置:
$ fdisk /dev/sdb
>>> Command (m for help): w # 保存分区设置退出
到此磁盘分区划分完毕,但这些分区还不能使用,还需要将分区格式化为需要的文件系统类型。这里将分区格式化为EXT4:
$ mkfs.ext4 /dev/sdb1
格式化完毕后,最后一步是挂载mount设备:
$ mkdir /data
$ mount /dev/sdb1 /data
$ df | grep /data
(3)文件系统管理
Linux下常见的有DOS文件系统类型MS-DOS,Windows下的FAT系列和NTFS文件系统,单一文件系统EXT2,日志文件系统EXT3、EXT4、XFS,集群文件系统GFS,分布式文件系统HDFS,虚拟文件系统(如/proc),网络文件系统NFS等。
①对于读操作频繁同时小文件众多的应用,使用EXT4;
②写操作频繁的应用,使用XFS;
③对性能和数据安全要求不高的应用,使用EXT2(由于没有日志记录功能,不建议使用)。
网络文件系统NFS主要实现的功能是让网络上的不同操作系统之间共享数据。NFS首先在远程服务端(共享数据的操作系统)共享出文件或目录,然后远端共享出来的文件或目录就可以通过挂载的方式挂接到本地的不同操作系统上,最后本地系统就可以很方便地使用远端提供的文件服务,操作起来像在本地操作一样,从而实现数据的共享。
几乎所有的Linux发行版都在安装系统时默认安装了NFS服务,首先查看NFS服务是否安装:
$ rpm -qa | grep nfs
>>> nfs-utils-1.3.0-0.61.e17.x86_64
如果有类似输出就表示NFS软件包已经安装。
EXT4文件系统的日志功能就是在牺牲一定性能的情况下增强稳定性的一种手段,关闭日志功能的命令为:
$ tune2fs -O ^has_journal /dev/sda7
$ dumpe2fs /dev/sda7 | grep ‘Filesystem features’ | grep ‘has_journal’
打开日志功能的命令为:
$ tune2fs -O has_journal /dev/sda7
在动态关闭和打开日志功能后,可能需要对文件系统进行fsck检查,避免出错,其命令为:
$ fsck.ext4 -f /dev/sda7
禁用EXT4的日志功能后,文件系统写入性能会有不少提升。
有时候文件系统日志功能不能关闭,EXT4文件系统有3种日志模式,分别是:journal、ordered、writeback,其中writeback是EXT4提供的性能最好的模式。
$ mount -t ext4 -o data=writeback /dev/sda7 /mnt
(4)进程管理与监控
按照进程的功能和运行程序,进程可划分为两大类:
①系统进程:可以执行内存资源分配和进程切换等管理工作,而且该进程的运行不受用户的干预,即使是root用户也不能干预系统进程的运行;
②用户进程:通过执行用户程序、应用程序或内核之外的系统程序而产生的进程,此类进程可以在用户控制下运行或关闭。
针对用户进程,又可以分为三类:
①交互进程:由一个shell终端启动的进程,在执行过程中,需要与用户进行交互操作,可以运行于前台,也可以运行在后台;
②批处理进程:该进程是一个进程集合,负责按顺序启动其他进程;
③守护进程:其是一直运行的一种进程,经常在Linux系统启动时启动,在系统关闭时终止。它们独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。
常用命令有:
①通过ps命令监控系统进程:
$ ps -ef | head -n 1; ps -ef | grep httpd
其中UID是用户的ID标识号,PID是进程的标识号,PPID表示父进程,STIME表示进程的启动时间,TTY表示进程所属的终端控制台,TIME表示进程启动后累计使用的CPU总时间,CMD表示正在执行的命令。
也可以通过下面命令查看子进程与父进程的对应关系:
$ ps -auxf | head -n 1; ps -auxf | grep httpd
其中,%CPU表示进程占用的CPU百分比;%MEM表示进程占用内存的百分比;VSZ表示进程虚拟内存大小;RSS表示进程的实际内存(驻留集)大小(单位是页);STAT表示进程的状态,R表示正在运行中的进程,S表示处于休眠状态的进程,Z表示僵尸进程,<表示优先级高的进程,N表示优先级低的进程,s表示父进程,+表示位于后台的进程,START表示启动进程的时间。
②通过top命令监控系统进程:
与ps命令相比,top命令动态、实时地显示进程状态,而ps只能显示进程某一时刻的信息。top命令提供了一个交互界面,用户可以根据需要,人性化地定制自己的输出,更清楚地了解进程的实时状态。
$ top
其中PID表示进程,PR表示优先级,VIRT表示虚拟内存总量,RES表示未被换出的物理内存,SHR表示共享内存。
③通过lsof命令监控系统进程与程序:
lsof命令是列举系统中已经被打开的文件,通过lsof可以根据文件找到对应的进程信息,也可以根据进程信息找到进程打开的文件。
<1>显示使用filename文件的进程:
$ lsof <filename>
<2>显示nfs进程现在打开的文件:
$ lsof -c nfs
其中FD表示文件描述符,TYPE表示文件的类型,SIZE表示文件的大小,NODE表示本地文件的node码,NAME表示文件的全路径或挂载点。
<3>显示指定进程组打开的文件情况:
$ lsof -g 3626
<4>通过进程号显示程序打开的所有文件及相关进程:
$ lsof -p <PID>
<5>通过监听指定的协议、端口、主机等信息,显示符合条件的进程信息:
$ lsof -i tcp:25
④通过pgrep命令查询进程ID:
pgrep是通过程序的名字来查询进程PID的工具,它通过检查程序在系统中活动的进程,输出进程属性匹配命令行上指定条件的进程ID。这对于判断程序是否正在运行,或者要迅速知道进程PID的需求来说,非常有用。
<1>查看httpd进程的起始ID:
$ pgrep -lo httpd
<2>查看httpd进程的终止ID:
$ pgrep -ln httpd
<3>查看sshd进程对应的所有ID:
$ pgrep -f sshd
查看www_data组启动的相关进程的PID:
$ pgrep -G www_data
关闭进程:
①用kill终止一个进程:
kill命令的执行原理为:首先向操作系统内核发送一个终止信号和终止进程的PID,然后系统内核根据发送的终止信号类型,对进程进行相应的终止操作。
$ kill <信号类型> <进程PID>
其中:kill -9表示强制结束进程;kill -2表示结束进程但不是强制性的,Ctrl+C就是kill -2信号;kill -15表示正常结束进程,不写明信号类型时就是15。
在正常关闭进程的操作中,父进程在自己终止时,会同时调用资源关闭子进程,释放内存。而在强制关闭进程操作中,由于忽略了进程之间的依赖关系,父进程直接关闭,不去理会子进程,因而子进程将变成孤儿进程。
②用killall终止一个进程:
与kill不同的是,killall后面跟的是进程的名字,而不是进程PID,因而killall可以终止一组进程。
$ killall <信号类型> <进程名称>
通过pidof命令可查找正在运行的进程PID:
$ pidof sshd # 查找sshd进程的PID
>>> 13276 12942 4284
进入内存目录,查看对应PID目录下exe文件的信息:
$ ls -al /proc/13276/exe
>>> lrwxrwxrwx 1 root root 0 Oct 4 22:09 /proc/13276/exe -> /usr/sbin/sshd
这样就找到了进程对应的完整执行路径,如果还要查看文件的句柄,可查看如下目录:
$ ls -al /proc/13276/fd
通过这种方式基本可以找到任何进程的完整执行信息。
还可以通过指定端口或者TCP、UDP协议找到进程PID,进而找到相关进程:
$ fuser -n tcp 25
>>> 25/tcp: 2037
$ ps -ef | grep 2037
>>> root 2037 1 0 Sep 23 ? 00:00:05 /usr/libexec/postfix/master
>>> postfix 2046 2037 0 Sep 23 ? 00:00:01 qmgr -l -t fifo -u
>>> postfix 9612 2037 0 20:34 ? 00:00:00 pickup -l -t fifo -u
>>> root 14927 12944 0 21:11 pts/1 00:00:00 grep 2037
二、运维常用命令
(1)性能监控类命令
vmstat是virtual memory statistics的缩写,它能实时输出系统的各种资源的使用情况,例如进程信息、内存使用、CPU使用率以及I/O使用情况。vmstat的每条输出都包含6个字段,它们的含义分别是:
①procs,进程信息。r表示等待运行的进程数目,b表示处于不可中断睡眠状态的进程数目;
②memory,内存信息,各项的单位都是KB。swpd表示虚拟内存的使用数量,free表示空闲内存的数量,buff表示作为buffer cache的内存数量。从磁盘读入的数据可能被保持在buffer cache中,以便下一次快速访问。cache表示作为page cache的内存数量,待写入磁盘的数据将首先被放到page cache中,然后由磁盘中断程序写入磁盘;
③swap,交换分区(虚拟内存)的使用信息,各项的单位都是KB/s。si表示数据由磁盘交换至内存的速率,so表示数据由内存交换至磁盘的速率。如果这两个值经常发生变化,则说明内存不足。
④io,块设备的使用信息,单位是block/s。bi表示从块设备读入块的速率,bo表示向块设备写入块的速率。
⑤system,系统信息。in表示每秒发生的中断次数,cs表示每秒发生的上下文切换(进程切换)次数。
⑥cpu,CPU使用信息。us表示系统所有进程运行在用户空间的时间占CPU总运行时间的比例,sy表示系统所有进程运行在内核空间的时间占CPU总运行时间的比例,id表示CPU处于空闲状态的时间占CPU总运行时间的比例,wa表示CPU等待I/O事件的时间占CPU总运行时间的比例。
不过我们可以使用iostat命令获得磁盘使用情况的更多信息,vmstat命令主要用于查看系统内存的使用情况。ifstat是interface statistics的缩写,它是一个简单的网络流量监测工具。ifstat的每条输出都以KB/s为单位显示各网卡接口上接收和发送数据的速率。因此,使用ifstat命令就可以大概估计各个时段服务器的总输入、输出流量。
也可以使用mpstat获得CPU使用情况的更多信息。mpstat是multi-processor statistics的缩写,它能实时监测多处理系统上每个CPU的使用情况。mpstat命令和iostat命令通常都集成在包sysstat中,安装sysstat即可获得这两个命令。与vmstat命令一样,mpstat命令输出的第一次结果是自系统启动以来的平均结果,而后面(count-1)次输出结果则是采样间隔内的平均结果。每次采样的输出都包含3条信息,每条信息都包含如下几个字段:
①CPU,指示该条信息是哪个CPU的数据。0表示是第1个CPU的数据,1表示是第2个CPU的数据,all表示是这两个CPU数据的平均值;
②%usr,除了nice值为负的进程,系统上其他进程运行在用户空间的时间占CPU总运行时间的比例;
③%nice,nice值为负的进程运行在用户空间的时间占CPU总运行时间的比例;
④%sys,系统上所有进程运行在内核空间的时间占CPU总运行时间的比例,但不包括硬件和软件中断消耗的CPU时间;
⑤%iowait,CPU等待磁盘操作的时间占CPU总运行时间的比例;
⑥%irq,CPU用于处理硬件中断的时间占CPU总运行时间的比例;
⑦%soft,CPU用于处理软件中断的时间占CPU总运行时间的比例;
⑧%steal,一个物理CPU可以包含一对虚拟CPU,这一对虚拟CPU由超级管理程序管理。当超级管理程序在处理某个虚拟CPU时,另外一个虚拟CPU则必须等待它处理完成才能运行,这部分等待时间就是所谓的steal时间。该字段表示steal时间占CPU总运行时间的比例;
⑨%guest,运行虚拟CPU的时间占CPU总运行时间的比例;
⑩%idle,系统空闲的时间占CPU总运行时间的比例。
在所有这些输出字段中,我们最关心的是%user、%sys和%idle,它们基本上反映了我们的代码中业务逻辑代码和系统调用所占的比例,以及系统还能承受多大的负载。
(2)查询当前整个系统每个进程的线程数
工作中经常遇到这样的问题:某台服务器的CPU使用率飙升,通过top命令查看是某个程序(如Java)占用的CPU比较大,现在需要查询Java各个进程下的线程数情况:
$ for pid in $(ps -ef | grep -v grep|grep “java”|awk ‘{print $2}’); do echo ${pid} > /tmp/a.txt; cat /proc/${pid}/status|grep Threads > /tmp/b.txt; paste /tmp/a.txt /tmp/b.txt; done|sort -k3 -rn
(3)检测系统中的僵尸进程并将其kill
探测僵尸进程:
$ ps -e -o stat,ppid,pid,cmd | egrep ‘^[Zz]’
批量删除僵尸进程:
$ ps -e -o stat,ppid,pid,cmd | egrep ‘^[Zz]’ | awk ‘{print $2}’ | xargs kill -9
其实这个命令组合是将僵尸进程的父进程kill掉,进而关闭僵尸进程。这是因为僵尸进程很难直接kill掉,因为僵尸进程已经是死掉的进程,它不能再接收任何信号,所以需要kill僵尸进程的父进程,这样父进程被kill掉后,僵尸进程就成了孤儿进程,而所有的孤儿进程都会交给系统的1号进程(init或systemd)收养,1号进程会周期性地去调用wait来清除这些僵尸进程。
(4)查看当前占用CPU或内存最多的几个进程
这个应用需求在服务器问题排查和故障处理上使用率非常高。
获取当前系统占用CPU最高的前10个进程:
$ ps aux|head -1; ps aux|sourt -rn -k3|head -10
获取当前系统占用内存最高的前10个进程:
$ ps aux|head -1; ps aux|sort -rn -k4|head -10
(5)服务器状态监控脚本
<1>根据PID过滤进程所有信息(给出进程状态和占用资源信息):
#!/bin/bash
read -p “请输入要查询的PID:” P
n=`ps aux | awk ‘$2~/^’$P’$/{print $11}’ | wc -1`
if [ $n -eq 0 ]; then
echo “该PID不存在!”
exit
fi
echo “--------------------------------------”
echo “进程PID:$P”
echo “进程命令:`ps aux | awk ‘$2~/^’$P’$/{print $11}’`”
echo “进程所属用户:`ps aux | awk ‘$2~/^’$P’$/{print $1}’`”
echo “CPU占用率:`ps aux | awk ‘$2~/^’$P’$/{print $3}’`%”
echo “内存占用率:`ps aux | awk ‘$2~/^’$P’$/{print $4}’`%”
echo “进程开始运行的时间:`ps aux | awk ‘$2~/^’$P’$/{print $9}’`”
echo “进程运行的持续时间:`ps aux | awk ‘$2~/^’$P’$/{print $10}’`”
echo “进程状态:`ps aux | awk ‘$2~/^’$P’$/{print $8}’`”
echo “进程虚拟内存:`ps aux | awk ‘$2~/^’$P’$/{print $5}’`”
echo “进程共享内存:`ps aux | awk ‘$2~/^’$P’$/{print $6}’`”
echo “--------------------------------------”
<2>根据进程名查看进程状态:
#!/bin/bash
read -p “输入查询的进程名:” NAME
N=`ps aux | grep $NAME | grep -v grep | wc -l` # 统计进程总数
if [ $N -le 0 ]; then
echo “该进程名没有运行!”
fi
i=1
while [ $N -gt 0 ]
do
echo “进程PID:`ps aux | grep $NAME | grep -v grep | awk ‘NR==’$i’{print $0}’ | awk ‘{print $2}’`”
echo “进程命令:`ps aux | grep $NAME | grep -v grep | awk ‘NR==’$i’{print $0}’ | awk ‘{print $11}’`”
echo “进程所属用户:`ps aux | grep $NAME | grep -v grep | awk ‘NR==’$i’{print $0}’ | awk ‘{print $1}’`”
echo “CPU占用率:`ps aux | grep $NAME | grep -v grep | awk ‘NR==’$i’{print $0}’ | awk ‘{print $3}’`%”
echo “内存占用率:`ps aux | grep $NAME | grep -v grep | awk ‘NR==’$i’{print $0}’ | awk ‘{print $4}’`%”
echo “进程开始运行的时刻:`ps aux | grep $NAME | grep -v grep | awk ‘NR==’$i’{print $0}’ | awk ‘{print $9}’`”
echo “进程运行的时间:`ps aux | grep $NAME | grep -v grep | awk ‘NR==’$i’{print $0}’ | awk ‘{print $11}’`”
echo “进程状态:`ps aux | grep $NAME | grep -v grep | awk ‘NR==’$i’{print $0}’ | awk ‘{print $8}’`”
echo “进程虚拟内存:`ps aux | grep $NAME | grep -v grep | awk ‘NR==’$i’{print $0}’ | awk ‘{print $5}’`”
echo “进程共享内存:`ps aux | grep $NAME | grep -v grep | awk ‘NR==’$i’{print $0}’ | awk ‘{print $6}’`”
echo “****************************************”
let N-- i++
done
echo “已设置禁止root用户远程登录!”
sed -i ‘/PermitRootLogin/cPermitRootLogin no’ /etc/ssh/sshd_config
三、Linux系统性能优化
Linux系统的性能指标有:
(1)进程指标:
进程管理在任何操作系统上都是最重要的事情,高效的进程管理能够确保应用高效稳定地运行。Linux的进程管理方式包括:
①进程调度;
②中断处理;
③信号;
④进程优先级;
⑤进程切换;
⑥进程状态;
⑦进程的内存。
程序和进程的关系为:
程序和进程是有区别的,进程虽然由程序产生,但它并不是程序。程序是一个进程指令的集合,它可以启用一个或多个进程。程序只占用磁盘空间,而不占用系统运行资源。进程仅仅占用系统内存空间,是动态、可变的,关闭进程占用的内存资源随之释放。
进程和线程的关系为:
①一个线程只能属于一个进程,而一个进程可以有多个(至少一个)线程;
②进程作为资源分配的最小单位,资源是分配给进程的,同一进程的所有线程共享该进程的所有资源;
③真正在处理机上运行的是线程;
④线程作为调度和分配的基本单位,进程则作为拥有资源的基本单位;
⑤不仅进程之间可以并发执行,同一个进程的多个线程之间也可并发执行;
⑥进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以访问隶属于进程的资源;
⑦在创建或撤销进程时,由于系统都要为之分配和回收资源,导致系统的开销明显大于创建或撤销线程时的开销。
每个进程都有自己的状态,显示进程中当前发生的事情,进程执行时其状态会发生改变:
①运行状态:进程正在CPU中执行,或在运行队列run queue中等待运行;
②停止状态:进程由于特定的信号(如SIGINT、SIGSTOP)而挂起就会处于这个状态,等待恢复信号如SINCONT;
③可中断的等待状态:这类进程处于阻塞状态,一旦达到某种条件,就会变为运行状态,同时该状态的进程也会由于接收到信号而被提前唤醒进入到运行状态;
④不中断的等待状态:与可中断的等待状态类似,只是该状态进程对信号不做响应。其典型例子是进程等待磁盘I/O操作;
⑤僵尸状态:每个进程在结束后都会处于僵尸状态,等待父进程调用进而释放资源,处于该状态的进程已经结束,但其父进程还没有释放其系统资源。
(2)内存指标:
在进程执行过程中,Linux内核会根据需要给进程分配一块内存区域,进程就把这片区域作为工作区,按要求执行操作。但系统上运行的进程经常是成千上万的,但内存却是有限的,因此Linux必须高效动态的处理内存资源。
在Linux系统中,无论是内核还是应用程序,都不能直接使用物理内存和swap硬盘的逻辑内存。要使用内存需要通过一个映射机制来实现。也就是说,Linux系统会把所有内存(包括物理内存和逻辑内存)都映射成虚拟内存,这样应用程序在使用内存时,就需要向Linux内核请求一个特定大小的内存映射,并且收到一个虚拟内存的映射。申请得到的虚拟内存有部分可能是逻辑内存!
页是物理内存或虚拟内存中一组连续的线性地址,Linux内核以页为单位处理内存,页的大小通常是4KB。当一个进程请求一定数量的页时,如果有可用的页,内核会直接把这些页分配给该进程,否则内核会从其他进程或页缓存中拿出一部分给这个进程用。
如果在进程请求指定数量的内存页时没有可用的页,内核就会尝试释放特定的内存页给新的请求使用,这个过程称为内存回收。kswapd内核线程负责页回收。操作系统每隔一定时间就会唤醒kswapd,它基于最近最少使用原则LRU在活动页中寻找可回收的页。即使没有什么事情需要内存,Linux也会交换出暂时不用的内存页。
Linux在负载比较大(内存紧张)时一般会看到两个进程:kswapd0和kswapd1。如果这些进程占用系统资源很多,尤其是在负载很大的业务系统中,可能引起系统宕机。如果这些进程占用资源非常高,就要考虑优化系统,或添加硬件资源。
如果虚拟内存中没有足够空间来存储交换页时,最终会导致Linux出现假死机、服务异常等问题。Linux虽然可以在一段时间内自行恢复,但恢复后的系统已经基本不可用了。
(3)文件系统指标:
消除文件系统瓶颈的主要方法有:
①如果程序访问磁盘的方式是顺序访问,那就换一个更好的磁盘控制器;如果是随机访问,就增加更多的磁盘控制器;
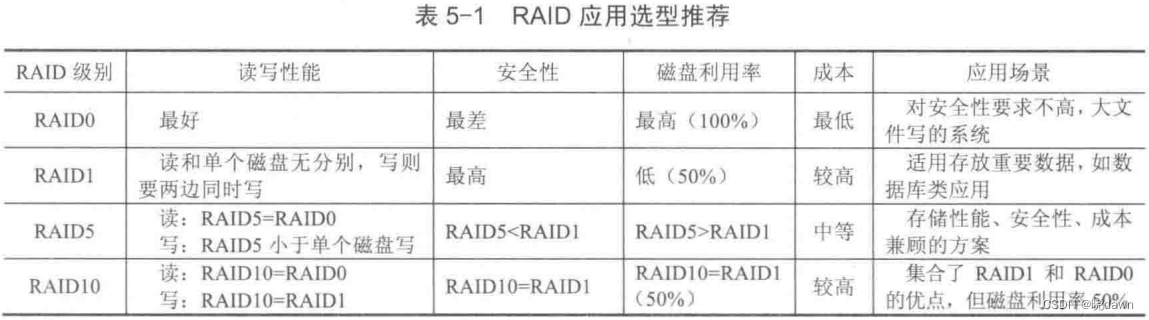
②磁盘存储一定要使用RAID技术。根据不同的使用需求,选择不同的RAID级别。例如写频繁、数据安全性要求一般,可采用RAID0;对数据安全性要求很高,可采用RAID1或RAID10。RAID有软硬之分,优先使用基于硬件实现的RAID;
③给磁盘合理分区也有助于提高文件系统性能。例如将写频繁的应用放到不同的磁盘中,这样可以最大限度地提高写入性能;
④选择合适的文件系统。
(4)磁盘I/O指标:
I/O调度器的总体目标是希望让磁头能够总是往一个方向移动,移动到底再往反方向移动。这恰恰是现实生活中的电梯模型。这对于目前已广泛使用的固态硬盘并不重要。
硬件发展到现在,处理器性能得到了飞速提升,但RAM和磁盘并没有质的飞跃,这导致了系统整体性能并没有因为处理器速度的提升而提升。为解决CPU处理速度快而磁盘存取速度慢的问题,需要用到缓存技术。把常用数据放入到更快速度的内存中,通过缓存机制解决处理器和磁盘之间速度的不平衡。现代计算机系统在几乎所有的I/O组件中都使用了这项技术,例如磁盘缓存、磁盘控制器缓存以及文件系统缓存。缓存技术通过L1 Cache、L2 Cache、RAM等多级缓存来消除CPU和磁盘之间存储速度的差异。
Linux通过独立的磁盘缓存机制——页高速缓存,来解决CPU和磁盘的这种读取差异:进程从磁盘中读数据时,数据被复制到内存中。该进程和其他进程都可以在内存缓存中读取同样的数据副本。当进程尝试改变数据时,会首先修改内存中的数据,这时磁盘和内存中的数据就不一致了,内存中的数据称为脏缓存dirty buffer。脏缓存应尽快同步到磁盘上,否则如果突然崩溃,内存中的数据就会丢失。同步脏缓存是由内核中的一个线程(flusher线程)来完成的。
(5)网络指标:
网络调优涉及很多组件,例如交换机、路由器、网关、防火墙等。尽管这些组件不受Linux系统的控制,但它们对系统的整体性能有很大影响。因此调优过程必须要和维护网络系统的人员紧密联系。在实际的网络调优中,需重点关注以下性能指标:
①网络拓扑结构是否合理:网络中的接入交换机、核心交换机背板带宽是否足够,网络结构是否有冗余,以确保网络设备出故障时可以不影响网络运行。同时还要考虑网络配置是否正确,配置参数是否合理,是否能发挥最大的网络性能。
②服务器硬件要根据应用需求使用更快的网卡:使用速度更快、更稳定的网卡可以最大限度保障网络性能。例如可采用千兆光纤、万兆光纤接口,并通过多网卡绑定实现冗余功能,可最大程度保障网络稳定性和可靠性。
③调整操作系统内核网络参数:Linux系统中关于网络的内核参数有很多,例如设置接收和发送缓冲区的大小、设置传输窗口、设置网络等待时间等参数,以确保网络在操作系统下以最优性能运行。
Linux上运行的程序都会受到资源限制的影响,例如物理设备限制(CPU数量、内存数量等)、系统策略限制(CPU时间等),以及具体实现的限制(例如文件名的最大长度)。Linux系统资源限制可以通过以下函数来读取和设置:
# include <sys/resource.h>
int getrlimit(int resource, struct rlimit *rlim);
int setrlimit(int resource, const struct rlimit *rlim);
rlim参数是rlimit结构体类型的指针,rlimit结构体定义为:
struct rlimit {
rlim_t rlim_cur;
rlim_t rlim_max;
}
rlim_t是一个整数类型,它描述资源级别。rlim_cur成员指定资源的软限制,rlim_max成员指定资源的硬限制。软限制是一个建议性的、最好不要超越的限制,如果超越的话,系统可能向进程发送信号以终止其运行。例如,当进程CPU时间超过其软限制时,系统将向进程发送SIGXCPU信号;当文件尺寸超过其软限制时,系统将向进程发送SIGXFSZ信号。硬限制一般是软限制的上限,普通程序可以减小硬限制,而只有以root身份运行的程序才能增加硬限制。此外,我们可以使用ulimit命令修改当前shell环境下的资源限制(软限制或/和硬限制),这种修改将对该shell启动的所有后续程序有效。我们也可以通过修改配置文件来改变系统软限制和硬限制,而且这种修改是永久的。

(1)CPU性能瓶颈的特征
CPU是十分关键的资源,也常常是性能瓶颈的源头。注意:高的CPU利用率并不总是意味着CPU正在繁忙地工作,也可能是正在等着其他子系统完成工作。要正确判断,需要把整个系统作为一个整体,并且观察到每一个子系统,因为子系统之间存在着各种千丝万缕的关联。
注意:不要一次运行太多性能工具,以避免增加CPU资源利用率。因为一次运行太多不同的监控工具,可能导致CPU负载飙升。
如果CPU资源持续满负荷运转,而应用系统仍然缓慢甚至无响应,但在重新启动应用服务后,CPU负载又马上耗尽,此时基本就能判断CPU出现了瓶颈。出现CPU瓶颈有两种原因:一种是应用程序bug导致CPU资源耗尽;另一种是CPU资源确实不足。实际应用中,第一种情况更常见,此时需要从应用程序角度来排查问题。而如果出现的是第二种情况,就要考虑增加CPU资源了。
可以采用以下方法来增强CPU性能:
①通过Linux系统命令查看耗费CPU资源的进程,如果找到无用的进程在消耗大量CPU资源,那么就必须关掉它,也就是让没必要的进程或任务关闭,减少对CPU的资源消耗;
②如果应用程序或软件支持,可以尝试将进程或线程绑定到CPU上,避免进程在多个处理器之间切换,引起缓存刷新;
③要根据应用系统的特点,确认应用是否能够利用多CPU,或尽量把应用系统设计成可以并行利用多CPU机制,这样就能够充分利用CPU资源,同时要知道CPU瓶颈出在哪里,例如单线程应用,需要更快的CPU才能提高性能,而增加CPU个数是没有用的。
(2)内存性能瓶颈的特征
要优化内存性能,就是让数据存放到最快的存储器中。CPU寄存器离CPU最近,读取速度最快,但是存放数据有限,所以更多的数据要存放到Cache中。而Linux的内存管理机制中Cache是RAM映射出来的,要提高内存性能,最好的方式就是数据都存入Cache。而事实上,内存是有限的,不可能所有数据都存入Cache,此时部分数据还是要在硬盘上存取,因此提升性能的关键是提高缓存命中率,让活动数据尽可能都通过Cache存取。
要知道内存是否出现了瓶颈,可综合多个系统指标查看,不能仅仅看到空闲内存很少就认为内存不足了。此时要对Linux内存管理机制有深入了解,通过内存监控工具free、top、smem等获取内存指标。如果发现可用内存available持续减少,系统进程中kswapd进程频繁出现,同时swap交换空间占用率持续增高,那么基本可以判断是系统内存资源不足了。出现内存资源不足也有两种原因:一种是应用程序bug导致内存资源耗尽;另一种是确实内存资源不足。实际应用中,两种情况都比较常见,针对第一种情况,需要从应用程序角度来排查问题。如果出现第二种情况,就要考虑增加内存资源了。
可以采用以下方法来提升内存使用效率:
①关掉操作系统上用不到的服务,腾出内存资源;
②调整swap使用机制,调整page-out使用率,尽量使用物理内存,而不去用swap交换空间;
③使用bigpages、hugetlb和共享内存调优;
④增加或者减少页大小;
⑤优化操作系统虚拟内存参数,如/proc/sys/vm。
有时还会出现系统内存资源非常充足,但应用系统却运行缓慢,这除了应用程序本身问题外,很大一部分原因可能是系统内存资源参数设置不合理,所以对操作系统下内存参数的调优也非常重要。
(3)磁盘性能瓶颈的特征
磁盘I/O通常是体现服务器性能的最重要方面之一,是瓶颈问题的高发区。但磁盘问题有时表现得不是那么直接,例如由于磁盘I/O性能低,会导致CPU使用率过高,因为CPU都花费在等待I/O任务完成上了,此时在操作系统上看到的CPU负载就会很大,而根本原因是磁盘I/O慢导致的。
如果服务器表现以下情况,可能就是磁盘出现瓶颈了:
①通过磁盘I/O监控命令,如iostat、iotop等,发现%iowait持续超过80%,并且CPU的I/O等待也非常高;
②应用系统读、写操作响应时间很长,或网络利用率(网络正常情况下)非常低;
③磁盘请求队列(/sys/block/sda/queue/nr_requessts)变满,处理请求时间变长。
要优化磁盘I/O,还需要了解磁盘接口速度、磁盘容量、磁盘负载,访问磁盘是随机还是顺序的,I/O是大还是小,这些都是优化磁盘I/O性能的关键。
可以采用以下方法来优化磁盘性能:
①不要划分过大的磁盘分区,考虑使用Linux逻辑卷分区;
②使用RAID技术在RAID阵列中添加更多的磁盘,把数据分散到多块物理磁盘,可以同时增强读和写的性能。增加磁盘会提升每秒的读写I/O数;
③如果应用系统是随机读写磁盘,那么瓶颈可能在磁盘上,增加更多的磁盘可以提升I/O性能。如果是顺序读写磁盘,那么压力是在控制器带宽上,办法就是添加更快的磁盘控制器;
④添加RAM。添加内存会提升系统磁盘缓冲,增强磁盘响应速度;
⑤修改磁盘的默认请求队列数可以大幅提升磁盘的吞吐量,缺点就是要牺牲一定的内存。
(4)网络性能瓶颈的特征
网络的性能问题会导致很多其他问题,在系统安装的时候,就需要考虑对其进行优化。CPU、内存、磁盘、网络间可能导致相互的影响,例如网络问题可以影响到CPU利用率,尤其当包大小特别小的时候;当TCP连接数太多的时候,内存使用率会变高。
网络瓶颈表现得比较直接,例如连接服务器变慢但服务器正常,大部分连接请求超时,网络传输带宽上不去等,服务器的CPU、内存、磁盘I/O都表现正常,但是操作系统上面的业务系统访问却很缓慢,这都是典型的网络带宽瓶颈。
要查找带宽瓶颈的原因,可以通过ping、mtr等工具获取延时、丢包、路由等信息。
可以采用以下方法来优化网络性能:
①确保网卡带宽和交换机配置相匹配。不能一个千兆网卡连接在一个百兆网口交换机上;
②网卡带宽无法满足需求时,可通过双网卡绑定提供吞吐量,或者用光纤网络解决;
③适当调整IPv4的TCP内核参数(/proc/sys/net),可以在一定程度上提升网络性能。
网络方面的性能问题一般比较好解决,只要判断出是网络方面的问题,就可以通过增加网络带宽或者调整系统相关网络设置等参数来迅速解决。
要从系统的角度来优化、改进服务器需要包括3方面的内容:系统调制、服务器调试和压力测试。Linux平台的一个优秀特性是内核微调,即我们可以通过修改文件的方式来调整内核参数。这些内核参数中,系统或进程能打开的最大文件描述符数尤其重要。
文件描述符是服务器程序的宝贵资源,几乎所有的系统调用都是和文件描述符打交道。系统分配给应用程序的文件描述符数量是有限制的,所以我们必须总是关闭那些已经不再使用的文件描述符,以释放它们占用的资源。例如作为守护进程运行的服务器程序就应该总是关闭标准输入、标准输出和标准错误这3个文件描述符。
Linux对应用程序能打开的最大文件描述符数量有两个层次的限制:用户级限制和系统级限制。用户级限制是指目标用户运行的所有进程总共能打开的文件描述符数;系统级的限制是指所有用户总共能打开的文件描述符数。
下面这个命令是最常用的查看用户级文件描述符数限制的方法:
$ ulimit -n
可以通过如下方式将用户级文件描述符数限制设定为max-file-number:
$ ulimit -SHn max-file-number
不过这种设置是临时的,只在当前的session中有效。为永久修改用户级文件描述符数限制,可以在/etc/security/limits.conf文件中加入如下两项:
* hard nofile max-file-number
* soft nofile max-file-number
第一行是指系统的硬限制,第二行是软限制。
如果要修改系统级文件描述符数限制,则可以使用如下命令:
$ sysctl -w fs.file-max=max-file-number
不过该命令也是临时更改系统限制。要永久更改系统级文件描述符数限制,则需要在/etc/sysctl.conf文件中添加如下一项:
$ fs.file-max=max-file-number
然后通过执行sysctl -p命令使更改生效。
理想情况下,Linux系统的性能调优是从安装操作系统开始的,需要针对操作系统的用途和具体特点,进行有针对性地系统设计和安装配置。例如将Linux作为一个服务器来使用的话,只需要安装一个精简的内核和必要的软件支持即可。还有很多类似设置,例如系统盘要做RAID1、软件要做更新、系统资源参数优化、系统基本安全设置等,这些必要的安装和配置是服务器上线前必须要考虑的因素,因为合理的安装和系统定制可以为以后的优化节省大量的时间。
因此根据实际应用需要,在部署线上服务器的时候,最好配置两组RAID,一组是系统盘RAID,对系统盘(安装操作系统的磁盘)推荐配置为RAID1,另一组是数据盘RAID,对数据盘(存放应用程序、各种数据)推荐采用RAID1、RAID5或者RAID10。
Linux服务器的远程维护管理都是通过SSH服务完成的,默认使用22端口监听。这些默认的配置已经成为黑客扫描的常用方式,所以对SSH服务的配置需要做一些安全加固和优化。SSH服务的配置文件为/etc/ssh/sshd_config,常用的优化选项有:
①修改默认22端口为1万以上端口号,避免被扫描和攻击:Port 22221
②不使用DNS反查,可提高SSH连接速度:UseDNS no
③关闭GSSAPI验证,可提高SSH连接速度:GSSAPIAuthentication no
④禁止root账号SSH登录:PermitRootLogin no
线上服务器对时间的要求是非常严格的,为了避免服务器时间因长时间运行而导致时间偏差,进行时间同步synchronize是非常必要的。Linux系统下,一般使用NTP服务来同步不同机器的时间。
Linux内核参数调优:
要观察当前内核参数的配置,例如要查看/proc/sys/目录中某个内核参数文件,可以使用cat命令查看内容。
运维人员应该使用sysctl来修改内核参数,而sysctl使用/proc/sys目录树中的文件名作为参数。
系统内核参数优化:
①/proc/sys/kernel/panic,其用来设置如果发生“内核严重错误Kernel panic”,内核在重新引导之前等待的时间(以s为单位)。默认值为0,表示在发生内核严重错误时将禁止重新引导。
②/proc/sys/kernel/pid_max,其用来设置Linux下进程数量的最大值。
③/proc/sys/kernel/ctrl-alt-del,其文件中有一个二进制值,该值控制系统在接收到Ctrl+Alt+Delete组合键时如何反应。
④/proc/sys/kernel/core_pattern,其用来设置core文件保存位置或文件名,只有文件名时,则保存在应用程序运行的目录下。
内存内核参数优化:
①/proc/sys/vm/dirty_background_ratio,其指定了当文件系统缓存脏数据数量达到系统内存百分之多少时(如10%)就会触发pdflush/flush.kdmflush等后台回写进程运行,将一定缓存的脏页异步地刷入磁盘。
②/proc/sys/vm/dirty_ratio,其指定了当文件系统缓存脏数据数量达到系统内存百分之多少时(如15%),系统不得不开始处理缓存脏页(因为此时脏数据数量已经比较多,为了避免数据丢失需要将一定脏数据刷入磁盘)。如果触发了这个设置,那么新的I/O请求将会被阻挡,直到脏数据被写进磁盘。这是造成I/O卡顿的重要原因,但这也是保证内存中不会存在过量脏数据的保护机制。
在磁盘写入不是很频繁的场景,适当增大此值可以极大提高文件系统的写性能。但如果是持续、恒定的写入场合,应该降低其数值。
③/proc/sys/vm/dirty_expire_centisecs,其表示如果脏数据在内存中驻留时间超过该值,pdflush进程在下一次将把这些数据写回磁盘。这个参数声明Linux内核写缓冲区里面的数据多久之后,pdflush进程就开始考虑写到磁盘中去。
④/proc/sys/vm/dirty_writeback_centisecs,其控制内核的脏数据刷新进程pdflush的运行间隔。
⑤/proc/sys/vm/vfs_cache_pressure,其表示内核回收用于directory和inode cache内存的倾向。
⑥/proc/sys/vm/min_free_kbytes,其表示强制Linux VM最低保留多少空闲内存(Kbytes)。
⑦/proc/sys/vm/nr_pdflush_threads,表示当前正在运行的pdflush进程数量,在I/O负载高的情况下,内核会自动增加更多的pdflush进程。
⑧/proc/sys/vm/overcommit_memory,其指定了内核针对内存分配的策略,其值可以是0、1、2。其中0表示内核将检查是否有足够的可用内存供应用进程使用,如果有足够的可用内存,内存申请允许,否则内存申请失败,并把错误返回给应用进程;1表示内核允许分配所有的物理内存,而不管当前的内存状态如何;2表示内核允许分配超过所有物理内存和交换空间总和的内存。
⑨/proc/sys/vm/panic_on_oom,其表示内存不够时内核是否直接panic(恐慌)。Linux Kernel panic表示Linux Kernel不知道如何运行,此时它会尽可能把此时能获取的全部信息都打印出来,有时为了不让系统自动kill掉进程,需要设置此值为1。
当系统物理内存和交换空间都被用完时,如果还有进程来申请内存,内核将触发OOM killer。
⑩/proc/sys/vm/swappiness,表示使用swap分区的概率,swappiness=0时表示最大限度使用物理内存,然后才使用swap空间;swappiness=100时表示积极使用swap分区,并且把内存上的数据及时搬运到swap空间里面。Linux默认设置为60,表示物理内存在使用到40%(100-60)的时候,就开始使用交换分区。
文件系统内核参数优化:
①/proc/sys/fs/file-max,其指定了可以分配的文件句柄的最大数目。如果用户得到的错误消息声明由于打开文件数已经达到了最大值而不能打开更多文件,则可能需要增加该值。
②/proc/sys/fs/inotify/max_user_watches,Linux下rsync+inotify-tools实现数据实时同步中有一个重要的配置就是设置inotify的max_user_watches值,如果不设置,当遇到大量文件的时候就会出现出错的情况。
要将设置好的内核参数永久生效,需要修改/etc/sysctl.conf文件。首先检查sysctl.conf文件,如果已经包含需要修改的参数,则修改该参数的值,如果没有包含需要修改的参数,在/etc/sysctl.conf文件中添加该参数即可。
(1)内存资源(物理内存/虚拟内存)性能调优
Cache名为缓存,Buffer名为缓冲,二者都是和内存相关的。Cache就是为了弥补高速设备和低速设备之间的矛盾而设立的一个中间层。因为在现实里经常出现高速设备要和低速设备打交道,结果被低速设备拖后腿的情况。Buffer是根据磁盘的读写设计的,它把分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道,从而提高系统性能。
Cache和Buffer的区别有:
①Cache是CPU与内存间的,Buffer是内存与磁盘间的,都是为了解决速度不对等的问题;
②Cache是把读取过的数据保存起来,重新读取时若命中(找到需要的数据)就不要去读硬盘了,若没有命中再读硬盘。其中的数据会根据读取频率进行组织,把最频繁读取的内容放在最容易找到的位置,把不再读的内容不断往后排,直至从中删除;
③Buffer是即将要被写入磁盘的,而Cache是被从磁盘中读出来的;
④在应用场景上,Buffer是由各种进程分配的,被用在如输入队列等方面。Cache经常被用在磁盘的I/O请求上,如果有多个进程都要访问某个文件,于是该文件便被做出Cache以方便下次被访问,这样可提高系统性能。
Linux系统中有一个守护进程定期清空缓冲内容(即写入磁盘),也可以通过sync命令手动清空缓冲。
虽然Linux内核有自动释放Cache的机制,但有时急需要内存资源或者看着Cache占用不爽的话,也可以手动释放Cache资源。要释放Cache的命令为:
$ echo <1, 2, 3> > /proc/sys/vm/drop_caches
Linux下目前主流的文件是EXT4和XFS,这两个都是日志文件系统Journal File System。日志文件系统解决了掉电或系统崩溃造成元数据不一致的问题。
在进行写操作之前,把即将进行的各个步骤(称为transaction)事先记录下来,这些步骤包括:在inode中添加指向数据块的指针、从data block bitmap中分配一个数据块、把用户数据写入数据块等。这些transaction保存在文件系统单独开辟的一块空间上,称为日志journal,日志保存成功之后才进行真正的写操作。把文件系统的元数据和用户数据写进硬盘(称为checkpoint),通过这种机制,万一写操作的过程中掉电,下次挂载文件系统之前把保存好的日志重新执行一遍即可(称为replay),这样就保证了文件系统的一致性。
执行journal replay所需的时间很短,可以通过fsck或者mount命令完成。mount就是挂载文件系统,如果能够正常挂载,那么执行journal replay就算完成了。fsck进行full check(为文件系统进行彻底的检查,扫描所有的inode、目录、superblock和allocation bitmap等),所需时间很长,而且文件系统越大,所需的时间也越长。所以fsck更多用来修复磁盘故障,而不是执行journal replay。
(2)磁盘I/O性能调优
固态硬盘SSD被划分成很多block,而block又被划分成很多page。SSD的读和写都以page为单位的,而清除数据erase是以block为单位的。只不过SSD只能写到空的page上,不能像传统机械磁盘那样直接覆盖去写,因此SSD磁盘在修改数据时,操作流程为:read-modify-write。也就是首先读取原有page的内容,然后在Cache中修改,最后写入新的空page中,还要修改逻辑地址到新的page,而原有的page会标记为stale,但并不清零。
Linux文件系统下对于删除操作,只标记为未使用,而实际并没有清零,这样底层存储如SSD和传统机械磁盘并不知道哪些数据块可用,哪些数据块可以清除。所以对于非空的page,SSD在写入前必须先进行一次清除,这种情况下,SSD写入过程变为:read-erase-modify-write。
(3)网络性能调优
内核中网络模块的相关参数都位于/proc/sys/net目录下,其中和TCP/IP协议相关的参数主要位于以下三个子目录中:core、ipv4和ipv6。
①/proc/sys/net/core/somaxconn,指定listen监听队列里,能够建立完整连接从而进入ESTABLISHED状态的socket的最大数目。
②/proc/sys/net/ipv4/tcp_max_syn_backlog,指定listen监听队列里,能够转移至ESTABLISHED或者SYN_RCVD状态的socket的最大数目。
③/proc/sys/net/ipv4/tcp_wmem,它包含3个值,分别指定一个socket的TCP写缓冲区的最小值、默认值和最大值。
④/proc/sys/net/ipv4/tcp_rmem,它包含3个值,分别指定一个socket的TCP读缓冲区的最小值、默认值和最大值。我们正是通过修改这个参数来改变接收通告窗口大小的。
⑤/proc/sys/net/ipv4/tcp_syncookies,指定是否打开TCP同步标签syncookie。同步标签通过启动cookie来防止一个监听socket因不停地重复接收来自同一个地址的连接请求(同步报文段),而导致listen监听队列溢出(所谓的SYN风暴)。
除了通过直接修改文件的方式来修改这些系统参数外,我们也可以使用sysctl命令来修改它们。这两种修改方式都是临时的,永久的修改方法是在/etc/sysctl.conf文件中加入相应网络参数及其数值,并执行sysctl -p使之生效,就像修改系统最大允许打开的文件描述符数那样。
系统安全与防护机制:
①设定TCP_Wrappers防火墙:
②合理使用shell历史命令记录功能:在Linux下可通过history命令查看用户所有的历史操作记录,同时shell命令操作记录默认保存在用户目录下的.bash_history文件中。
为了确保服务器的安全,保留shell命令的执行历史是非常有用的。shell虽然有历史功能,但这个功能并非针对审计目的而设计,因此很容易被黑客篡改或丢失。
但其可以实现详细记录登录过系统的用户、IP地址、shell命令以及详细操作时间等,并将这些信息以文件的形式保存在一个安全的地方,以供系统审计和故障排查。
(4)其他性能调优
可以通过命令来修改设备名称(用于区分多台设备):
$ sudo nano /etc/hosts
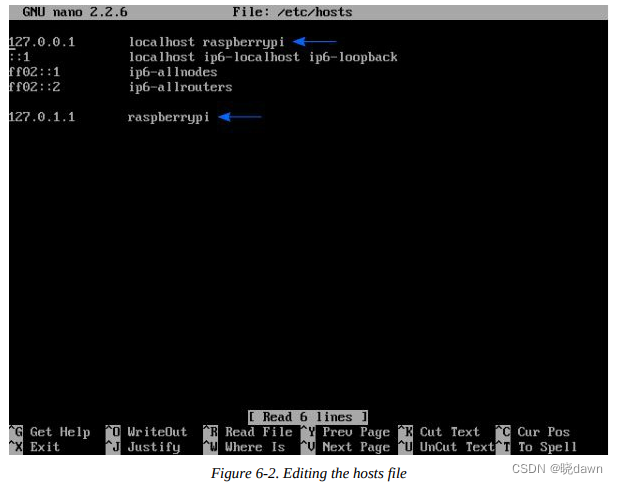
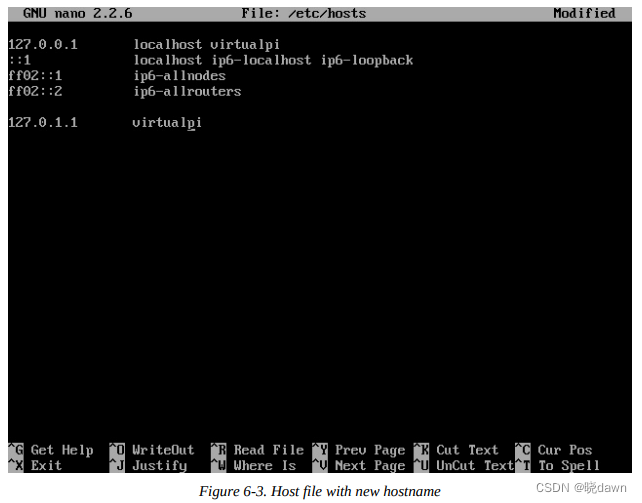
然后修改主机名:
$ sudo nano /etc/hostname
virtualpi
服务器的调试和维护都需要一个专业的日志系统,Linux提供一个守护进程来处理系统日志syslog,现在的Linux系统上使用的都是它的升级版rsyslogd。rsyslogd守护进程既能接收用户进程输出的日志,也能接收内核日志。用户进程是通过调用syslog函数生成系统日志的,该函数将日志输出到一个UNIX本地域socket类型(AF_UNIX)的文件/dev/log中,rsyslogd则监听该文件以获取用户进程的输出。内核日志由printk等函数打印至内核的环状缓存(ring buffer)中。环状缓存的内容直接映射到/proc/kmsg文件中,rsyslogd则通过读取该文件获得内核日志。
rsyslogd守护进程在接收到用户进程或内核输入的日志后,会把它们输出至某些特定的日志文件。默认情况下,调试信息会保存至/var/log/debug文件,普通信息保存至/var/log/messages文件,内核消息则保存至/var/log/kern.log文件。不过日志信息具体如何分发,可以在rsyslogd的配置文件中配置。rsyslogd的主配置文件是/etc/rsyslog.conf,其中主要可以设置的项包括:
①内核日志输入路径;
②是否接收UDP日志及其监听端口(默认是514,见/etc/services文件);
③是否接收TCP日志及其监听端口;
④日志文件的权限;
⑤包含哪些子配置文件(例如/etc/rsyslog.d/*.conf)。
rsyslogd的子配置文件则指定各类日志的目标存储文件。
图7-1总结了Linux的系统日志体系:
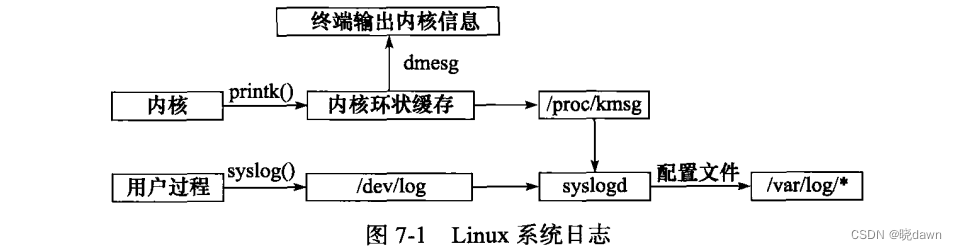
应用程序使用syslog函数与rsyslogd守护进程通信。
# include <syslog.h>
void syslog(int priority, const char *message, ...);
该函数采用可变参数(第二个参数message和第三个参数…)来结构化输出;priority参数是所谓的设施值与日志级别的按位或;设施值的默认值是LOG_USER。日志级别有以下几个:

下面函数可以改变syslog的默认输出方式,进一步结构化日志内容:
# include <syslog.h>
void openlog(const char *ident, int logopt, int facility);
其中,ident参数指定的字符串将被添加到日志消息的日期和时间之后,它通常被设置为程序的名字;logopt参数对后续syslog调用的行为进行配置,它可取下列值的按位或:

facility参数用来修改syslog函数中的默认设施值。
此外,日志的过滤很重要。程序在开发阶段可能需要输出很多调试信息,而发布之后我们又需要将这些调试信息关闭。解决这个问题的方法并不是在程序发布之后删除调试代码(因为日后可能还需要用到),而是简单地设置日志掩码,使日志级别大于日志掩码的日志信息被系统忽略。下面函数用于设置syslog的日志掩码:
# include <syslog.h>
int setlogmask(int maskpri);
其中,maskpri参数指定日志掩码值。该函数始终会成功,它返回调用进程先前的日志掩码值。不要忘了使用下面函数关闭日志功能:
# include <syslog.h>
void closelog();
需要在服务器重点检查的日志有以下几个:
①/var/log/messages:公共日志文件,记录Linux内核消息及各种应用程序的公共日志信息,包括启动、I/O错误、网络错误、程序故障等。对于未使用独立日志文件的应用程序或服务,一般都可以从该文件获得相关的事件记录信息;
②/var/log/cron:记录crond计划任务产生的事件消息;
③/var/log/dmesg:包含内核缓存信息(kernel ring buffer)。在系统启动时,会在屏幕上显示许多与硬件有关的信息。此文件记录的信息是系统上次启动时的信息。而用dmesg命令可查看本次系统启动时与硬件有关的信息,以及内核缓存信息;
④/var/log/secure:记录用户远程登录、认证过程中的事件信息;
⑤/var/log/wtmp:记录系统所有登录进入和退出信息。可执行last命令查看;
⑥/var/log/btmp:记录错误登录进入系统的日志信息。可执行lastb命令查看;
⑦/var/log/lastlog:记录最近成功登录的事件和最后一次不成功的登录事件。可执行lastlog命令查看。
其中,系统日志/var/log/messages和/var/log/secure一定要仔细检查,这两个日志文件可以记录软件的运行状态以及远程用户的登录状态,还可以查看每个用户目录下的.bash_history文件,特别是/root目录下的.bash_history文件,这个文件中记录着用户执行的所有历史命令。
守护进程用于在系统后台执行特定的系统任务,可进一步提高系统运行程序的稳定性,其编写遵循一定步骤,通过代码,让一个进程以守护进程的方式运行的示例:
bool daemonize() {
// 创建子进程 关闭父进程 这样可以使程序在后台运行
pid_t pid = fork();
if (pid < 0) {
return false;
} else if (pid > 0) {
exit(0);
}
// 设置文件权限掩码
// 当进程创建新文件(使用open()系统调用)时 文件的权限将是mode & 0777
umask(0);
// 创建新的会话 设置本进程为进程组的首领
pid_t sid = setsid();
if (sid < 0) {
return false;
}
// 切换工作目录
if ((chdir(“/”)) < 0) {
return false;
}
// 关闭标准输入设备 标准输出设备和标准错误输出设备
close(STDIN_FILENO);
close(STDOUT_FILENO);
close(STDERR_FILENO);
// 关闭其他已经打开的文件描述符
...
// 将标准输入 标准输出和标准错误输出都定向到/dev/null文件
open(“/dev/null”, O_RDONLY);
open(“/dev/null”, O_RDWR);
open(“/dev/null”, O_RDWR);
return true;
}
Linux提供了完成同样功能的库函数:
# include <unistd.h>
int daemon(int nochdir, int noclose);
其中,nochdir参数用于指定是否改变工作目录,如果给它传递0,则工作目录将被设置为“/”(根目录),否则继续使用当前工作目录;noclose参数为0时,标准输入、标准输出和标准错误输出都被重定向到/dev/null文件,否则依然使用原来的设备。
定时器是根据系统时钟计算时间的外围设备。它可以被编程为以给定的间隔定期“触发”,或者在一次性间隔之后。当定时器“触发”时,它会引发中断请求。计时器特别重要,因为它是操作系统用来跟踪时间进度并允许它安排任务的主要机制。
定时是指在一段时间之后触发某段代码的机制,我们可以在这段代码中依次处理所有到期的定时器。换言之,定时机制是定时器得以被处理的原动力。Linux提供了三种定时方法:
①socket选项SO_RCVTIMEO和SO_SNDTIMEO;
②SIGALRM信号;
③I/O复用系统调用的超时参数。
socket选项SO_RCVTIMEO和SO_SNDTIMEO,它们分别用来设置socket接收数据超时时间和发送数据超时时间。因此,这两个选项仅对与数据接收和发送相关的socket专用系统调用有效,这些系统调用包括send、sendmsg、recv、recvmsg、accept、connect。

由alarm和setitimer函数设置的实时闹钟一旦超时,将触发SIGALRM信号。因此我们可以利用该信号的信号处理函数来处理定时任务。但是,如果要处理多个定时任务,我们就需要不断地触发SIGALRM信号,并在其信号处理函数中执行到期的任务。一般而言,SIGALRM信号按照固定的频率生成,即由alarm或setitimer函数设置的定时周期T保持不变。如果某个定时任务的超时时间不是T的整数倍,那么它实际被执行的时间和预期的时间将略有偏差。因此定时周期T反映了定时的精度。
四、系统运维常用工具
CPU性能评估的常用工具有vmstat、uptime、mpstat等。
①通过vmstat命令可以对操作系统的CPU活动、内存信息、进程状态进行监视,不足之处是无法对某个进程进行深入分析。例如,每3s更新一次输出信息,统计5次后停止输出:
$ vmstat 3 5
其中,procs显示队列和等待状态,memory显示物理内存状态,swap显示交换分区的使用状态,io显示磁盘读写状况,system显示采集间隔内发生的中断数,cpu显示CPU的使用状态。
②uptime是监控系统性能最常用的一个命令,主要用来统计系统当前的运行状况。输出的信息依次为:系统现在的时间,系统从上次开机到现在运行了多长时间,系统目前有多少登录用户,系统在1min内、5min内、15min内的平均负载。
③mpstat是Multiprocessor Statistics的缩写,其是一个CPU实时状态监控工具。它与vmstat命令类似,mpstat是通过/proc/stat里面的状态信息来进行统计的。使用mpstat最大的好处是,它可以查看多核CPU中每个计算核的统计数据,而vmstat只能查看系统整体的CPU情况。
其输出中每列的含义为:CPU为处理器ID,多处理器时会显示每个处理器ID号;%usr显示了用户进程消耗的CPU时间百分比;%nice显示了运行正常进程所消耗的CPU时间百分比;%sys显示了系统进程消耗的CPU时间百分比;%iowait显示了I/O等待所占用的CPU时间百分比;%irq显示了硬中断时间占用的CPU时间百分比;%soft显示了软中断时间占用的CPU时间百分比;%steal显示了在内存相对紧张的环境下page in强制对不同的页面进行的steal操作;%guest显示了运行虚拟处理器时CPU花费时间的百分比;%gnice显示了运行带有nice优先级的虚拟CPU(宿主机角度)所花费的时间百分比;%idle显示了CPU处在空闲状态的时间百分比。
具体调试过程中,可以通过两个命令的结合来综合判断CPU是否有性能问题。例如当通过两个命令都发现较低的%idle数值时,可以判断应该是CPU不足的问题。而当看到较高的%iowait数值时,就应该马上知道在当前负载下I/O子系统出现了某些问题。
内存性能评估的常用工具有free、smem等。
①free是监控Linux内存使用状况最常用的指令。其输出信息依次为:used物理内存中已使用的内存;free空闲内存;shared共享内存;buff/cache系统缓存;available目前可使用内存。
其中used+free+buff/cache=total。
若要查看内存是否充足,只需要关注available一列即可。一般有这样一个经验:available内存>70%时,表示系统内存资源非常充足,不影响系统性能;available内存<20%时,表示系统内存资源紧缺,需要增加系统内存;20%<available内存<70%时,表示系统内存资源基本能满足应用需求,暂时不影响系统性能。
②smem是一款命令行下的内存使用情况报告工具,它能够给用户提供Linux系统下内存使用的多种报告。和其他传统的内存报告工具不同的是,它有个独特的功能,可以报告PSS。Linux使用虚拟内存,因此要准确计算一个进程实际使用的物理内存就不那么简单了。只知道进程的虚拟内存大小也并没有多大用处,因为还是无法获取到实际分配的物理内存大小。PSS是所有使用某共享库的程序均分该共享库占用的内存。显然所有进程的PSS之和就是系统的内存使用量。它会更准确一些,它将共享内存的大小进行平均后,再分摊到各进程上去。
smem支持查看某个进程占用内存的大小:
$ smem -k -P prometheus
通过这种方式,用户可以马上知道每个进程占用了多少内存资源,以及占用是否合理。
磁盘性能评估的常用工具有iotop、iostat等。
①iotop是一个用来监视磁盘I/O使用状况的top类工具,可监测到某一个程序使用的磁盘I/O的实时信息。这对于线上业务系统来说非常有用。
②iostat是I/O statistics(输入/输出统计),主要的功能是对系统的磁盘I/O操作进行监视。它的输出主要显示磁盘读写操作的统计信息。其输出信息依次为:KB_read/s表示每秒读取的数据块数;KB_wrtn/s表示每秒写入的数据块数;KB_read表示读取的所有块数;KB_wrtn表示写入的所有块数。
如果KB_wrtn/s值很大,表示磁盘的写操作很频繁,可以考虑优化磁盘或者优化程序;如果KB_read/s值很大,表示磁盘直接读取操作很多,可以将读取的数据放入内存中进行操作。长期的、超大的数据读写,肯定是不正常的,这种情况一定会影响系统性能。
网络性能评估的常用工具有ping、traceroute和mtr等。
如果发现网络反应缓慢,或者连接中断,可以通过ping来测试网络的连通情况。time值显示了两台主机之间的网络延时情况,如果此值很大,则表示网络的延时很大,单位为ms。packet loss表示网络的丢包率,此值越小表示网络的质量越高。
traceroute命令可以用来显示网络数据包传输到指定主机的路由信息,追踪数据传输路由状况,这对于网络性能调优非常有帮助。traceroute命令会对经过的所有路由节点做ICMP的回应时间测试,每个路由节点做3次时间测试。通过这种网络跟踪,可以测试数据传输在哪个部分出现问题,以便及时解决。如果在指定的时间内(本例设置为10s),traceroute检测不到某个路由节点的回应信息,就在屏幕输出*,表示此节点无法通过。由于traceroute是利用ICMP连接的,有些网络设备(如防火墙)可能会屏蔽ICMP通过的权限,因此也会出现节点没有回应的状态。这些都是分析网络问题时需要知道的。
mtr命令是一个更好的网络连通性调优工具,它结合了ping、nslookup、traceroute这3个命令的特性来判断网络的相关状态。
可用来全面监控Linux系统性能的常用工具有:top和htop。
htop是Linux系统中的一个互动的进程查看器,与Linux传统的top相比,htop更加人性化,它可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。
其总共分了5个展示区,分别是CPU状态区、内存展示区、整体状态区、进程状态区和管理控制台。输出的信息依次为:PID进程标识号;USER进程所有者的用户名;PRI进程的优先级别;NI进程的优先级别数值;VIRT进程占用的虚拟内存值;RES进程占用的物理内存值;SHR进程使用的共享内存值;S进程的状态;CPU%进程占用的CPU使用率;MEM%进程占用的物理内存和总内存的百分比;TIME+进程启动后占用的总CPU时间;Command进程启动的命令名称。
tcpdump是一款经典的网络抓包工具。即使在今天,我们拥有像Wireshark这样更易于使用和掌握的抓包工具,tcpdump仍然是网络程序员的必备利器。tcpdump给使用者提供了大量的选项,用以过滤数据包或者定制输出格式。除了使用选项外,tcpdump还支持用表达式来进一步过滤数据包。tcpdump表达式的操作数分为3种:类型type、方向dir和协议proto。
lsof(list open file)是一个列出当前系统打开的文件描述符的工具。通过它我们可以了解感兴趣的进程打开了哪些文件描述符,或者感兴趣的文件描述符被哪些进程打开了。
nc(netcat)命令短小精干、功能强大,有着瑞士军刀的美誉。它主要被用来快速构建网络连接。我们可以让它以服务器方式运行,监听某个端口并接收客户连接,因此它可用来调试客户端程序。我们也可以使之以客户端方式运行,向服务器发起连接并收发数据,因此它可以用来调试服务器程序,此时它有点像telent程序。
strace是测试服务器性能的重要工具,它跟踪程序运行过程中执行的系统调用和接收到的信号,并将系统调用名、参数、返回值及信号名输出到标准输出或者指定的文件。strace命令的每一行输出都包含这些字段:系统调用名称、参数和返回值,例如:
$ strace cat /dev/null
>>> open(“/dev/null”, O_RDONLY | O_LARGEFILE) = 3
当系统调用发生错误时,strace命令将输出错误标识和描述,例如:
$ strace cat /foo/bar
>>> open(“/foo/bar”, O_RDONLY | O_LARGEFILE) = -1 ENOENT (No such file or directory)
netstat是一个功能强大的网络信息统计工具,它可以打印本地网卡接口上的全部连接、路由表信息、网卡接口信息等。我们主要利用的是上述功能中的第一个,即显示TCP连接及其状态信息,毕竟要获得路由表信息和网卡接口信息,我们可以使用输出内容更丰富的route和ifconfig命令。在服务器程序开发过程中,我们一定要确保每个连接在任一时刻都处于我们期望的状态,因此我们应该习惯于使用netstat命令。
Zabbix是一个基于Web界面的提供分布式系统监视以及网络监视功能的企业级开源解决方案。Zabbix能监视各种网络参数,保证服务器系统的安全运营;并提供强大的通知机制以让系统运维人员快速定位/解决存在的各种问题。
Ganglia是一款HPC(高性能计算)集群而设计的可扩展的分布式监控系统。Ganglia可以监视和显示集群中节点的各种状态信息,由运行在各个节点上的gmond守护进程来采集CPU、内存、硬盘利用率、I/O负载、网络流量情况等方面的数据,然后汇总到gmetad守护进程下,使用rrdtool存储数据,最后将历史数据以曲线方式通过PHP页面呈现。
Prometheus是一套开源的系统监控告警框架,它既适用于面向服务器等硬件指标的监控,也适用于高动态的面向服务架构的监控。对于现在流行的微服务,Prometheus的多维度数据收集和数据筛选查询语言也非常强大。Prometheus是为服务的可靠性而设计的,当服务出现故障时,它可以使运维人员快速定位和诊断问题。
Grafana是一个开源的度量分析与可视化套件。通俗地说,Grafana就是一个图形可视化展示平台,它通过各种炫酷的界面效果展示监控数据。如果觉得Zabbix的出图界面不够好看,不够高端大气上档次,就可以使用Grafana的可视化展示。Grafana支持许多不同的数据源,Graphite、InfluxDB、OpenTSDB、Prometheus、Elasticsearch、CloudWatch和KairosDB都可以完美支持。
总结
以上就是关于Linux系统服务器运维基本操作要讲的内容,欢迎大家对本文章进行补充和指正。
参考资料
《鸟哥的Linux私房菜 基础学习篇》,人民邮电出版社出版
《鸟哥的Linux私房菜 服务器架设篇》,人民邮电出版社出版
《Operating Systems Foundations with Linux on the Raspberry Pi》,Arm Education Media
《高性能Linux服务器运维实战》,机械工业出版社
《Linux高性能服务器编程》,机械工业出版社
最后
以上就是执着香菇最近收集整理的关于服务器开发系列(五)——服务器运维系列文章目录前言一、服务器运维概述二、运维常用命令三、Linux系统性能优化四、系统运维常用工具总结参考资料的全部内容,更多相关服务器开发系列(五)——服务器运维系列文章目录前言一、服务器运维概述二、运维常用命令三、Linux系统性能优化四、系统运维常用工具总结参考资料内容请搜索靠谱客的其他文章。








发表评论 取消回复