声明:本人非阿里员工,只是震撼于阿里在双十一处理高并发的能力,在网上查看一些双十一的技术进行总结。我是大自然的搬运工。
2013年双十一,阿里还是用的mysql数据库,服务器主要技术如下
双“11”最热门的话题是TB ,最近正好和阿里的一个朋友聊淘宝的技术架构,发现很多有意思的地方,分享一下他们的解析资料:
淘宝海量数据产品技术架构
数据产品的一个最大特点是数据的非实时写入,正因为如此,我们可以认为,在一定的时间段内,整个系统的数据是只读的。这为我们设计缓存奠定了非常重要的基础。
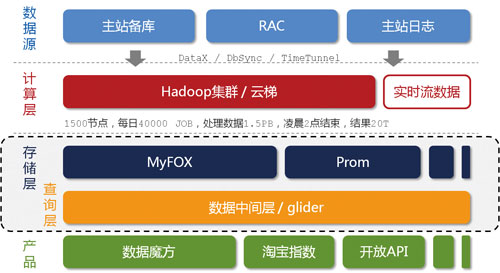
图1 淘宝海量数据产品技术架构
按照数据的流向来划分,我们把淘宝数据产品的技术架构分为五层(如图1所示),分别是数据源、计算层、存储层、查询层和产品层。位于架构顶端的是我们的数据来源层,这里有淘宝主站的用户、店铺、商品和交易等数据库,还有用户的浏览、搜索等行为日志等。这一系列的数据是数据产品最原始的生命力所在。
在数据源层实时产生的数据,通过淘宝自主研发的数据传输组件DataX、DbSync和Timetunnel准实时地传输到一个有1500个节点的Hadoop集群上,这个集群我们称之为“云梯”,是计算层的主要组成部分。在“云梯”上,我们每天有大约40000个作业对1.5PB的原始数据按照产品需求进行不同的MapReduce计算。这一计算过程通常都能在凌晨两点之前完成。相对于前端产品看到的数据,这里的计算结果很可能是一个处于中间状态的结果,这往往是在数据冗余与前端计算之间做了适当平衡的结果。
不得不提的是,一些对实效性要求很高的数据,例如针对搜索词的统计数据,我们希望能尽快推送到数据产品前端。这种需求再采用“云梯”来计算效率将是比较低的,为此我们做了流式数据的实时计算平台,称之为“银河”。“银河”也是一个分布式系统,它接收来自TimeTunnel的实时消息,在内存中做实时计算,并把计算结果在尽可能短的时间内刷新到NoSQL存储设备中,供前端产品调用。
容易理解,“云梯”或者“银河”并不适合直接向产品提供实时的数据查询服务。这是因为,对于“云梯”来说,它的定位只是做离线计算的,无法支持较高的性能和并发需求;而对于“银河”而言,尽管所有的代码都掌握在我们手中,但要完整地将数据接收、实时计算、存储和查询等功能集成在一个分布式系统中,避免不了分层,最终仍然落到了目前的架构上。
为此,我们针对前端产品设计了专门的存储层。在这一层,我们有基于MySQL的分布式关系型数据库集群MyFOX和基于HBase的NoSQL存储集群Prom,在后面的文字中,我将重点介绍这两个集群的实现原理。除此之外,其他第三方的模块也被我们纳入存储层的范畴。
存储层异构模块的增多,对前端产品的使用带来了挑战。为此,我们设计了通用的数据中间层——glider——来屏蔽这个影响。glider以HTTP协议对外提供restful方式的接口。数据产品可以通过一个唯一的URL获取到它想要的数据。
以上是淘宝海量数据产品在技术架构方面的一个概括性的介绍,接下来我将重点从四个方面阐述数据魔方设计上的特点。
关系型数据库仍然是王道
关系型数据库(RDBMS)自20世纪70年代提出以来,在工业生产中得到了广泛的使用。经过三十多年的长足发展,诞生了一批优秀的数据库软件,例如Oracle、MySQL、DB2、Sybase和SQL Server等。
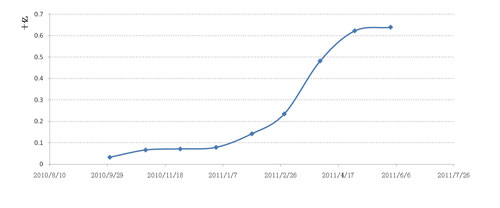
图2 MyFOX中的数据增长曲线
尽管相对于非关系型数据库而言,关系型数据库在分区容忍性(Tolerance to Network Partitions)方面存在劣势,但由于它强大的语义表达能力以及数据之间的关系表达能力,在数据产品中仍然占据着不可替代的作用。
淘宝数据产品选择MySQL的MyISAM引擎作为底层的数据存储引擎。在此基础上,为了应对海量数据,我们设计了分布式MySQL集群的查询代理层——MyFOX,使得分区对前端应用透明。
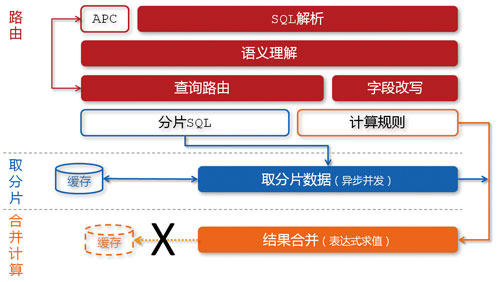
图3 MyFOX的数据查询过程
目前,存储在MyFOX中的统计结果数据已经达到10TB,占据着数据魔方总数据量的95%以上,并且正在以每天超过6亿的增量增长着(如图2所示)。这些数据被我们近似均匀地分布到20个MySQL节点上,在查询时,经由MyFOX透明地对外服务(如图3所示)。
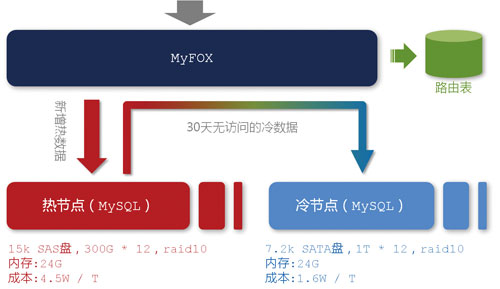
图4 MyFOX节点结构
值得一提的是,在MyFOX现有的20个节点中,并不是所有节点都是“平等”的。一般而言,数据产品的用户更多地只关心“最近几天”的数据,越早的数据,越容易被冷落。为此,出于硬件成本考虑,我们在这20个节点中分出了“热节点”和“冷节点”(如图4所示)。
顾名思义,“热节点”存放最新的、被访问频率较高的数据。对于这部分数据,我们希望能给用户提供尽可能快的查询速度,所以在硬盘方面,我们选择了每分钟15000转的SAS硬盘,按照一个节点两台机器来计算,单位数据的存储成本约为4.5W/TB。相对应地,“冷数据”我们选择了每分钟7500转的SATA硬盘,单碟上能够存放更多的数据,存储成本约为1.6W/TB。
将冷热数据进行分离的另外一个好处是可以有效提高内存磁盘比。从图4可以看出,“热节点”上单机只有24GB内存,而磁盘装满大约有1.8TB(300 * 12 * 0.5 / 1024),内存磁盘比约为4:300,远远低于MySQL服务器的一个合理值。内存磁盘比过低导致的后果是,总有一天,即使所有内存用完也存不下数据的索引了——这个时候,大量的查询请求都需要从磁盘中读取索引,效率大打折扣。
NoSQL是SQL的有益补充
在MyFOX出现之后,一切都看起来那么完美,开发人员甚至不会意识到MyFOX的存在,一条不用任何特殊修饰的SQL语句就可以满足需求。这个状态持续了很长一段时间,直到有一天,我们碰到了传统的关系型数据库无法解决的问题——全属性选择器(如图5所示)。
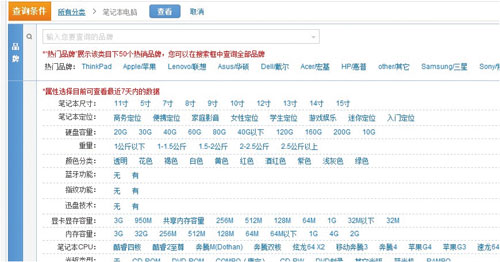
图5 全属性选择器
这是一个非常典型的例子。为了说明问题,我们仍然以关系型数据库的思路来描述。对于笔记本电脑这个类目,用户某一次查询所选择的过滤条件可能包括“笔记本尺寸”、“笔记本定位”、“硬盘容量”等一系列属性(字段),并且在每个可能用在过滤条件的属性上,属性值的分布是极不均匀的。在图5中我们可以看到,笔记本电脑的尺寸这一属性有着10个枚举值,而“蓝牙功能”这个属性值是个布尔值,数据的筛选性非常差。
在用户所选择的过滤条件不确定的情况下,解决全属性问题的思路有两个:一个是穷举所有可能的过滤条件组合,在“云梯”上进行预先计算,存入数据库供查询;另一个是存储原始数据,在用户查询时根据过滤条件筛选出相应的记录进行现场计算。很明显,由于过滤条件的排列组合几乎是无法穷举的,第一种方案在现实中是不可取的;而第二种方案中,原始数据存储在什么地方?如果仍然用关系型数据库,那么你打算怎样为这个表建立索引?
这一系列问题把我们引到了“创建定制化的存储、现场计算并提供查询服务的引擎”的思路上来,这就是Prometheus(如图6所示)。
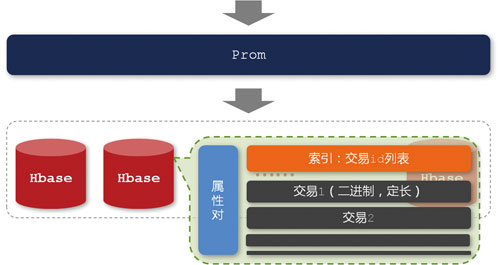
图6 Prom的存储结构
从图6可以看出,我们选择了HBase作为Prom的底层存储引擎。之所以选择HBase,主要是因为它是建立在HDFS之上的,并且对于MapReduce有良好的编程接口。尽管Prom是一个通用的、解决共性问题的服务框架,但在这里,我们仍然以全属性选择为例,来说明Prom的工作原理。这里的原始数据是前一天在淘宝上的交易明细,在HBase集群中,我们以属性对(属性与属性值的组合)作为row-key进行存储。而row-key对应的值,我们设计了两个column-family,即存放交易ID列表的index字段和原始交易明细的data字段。在存储的时候,我们有意识地让每个字段中的每一个元素都是定长的,这是为了支持通过偏移量快速地找到相应记录,避免复杂的查找算法和磁盘的大量随机读取请求。
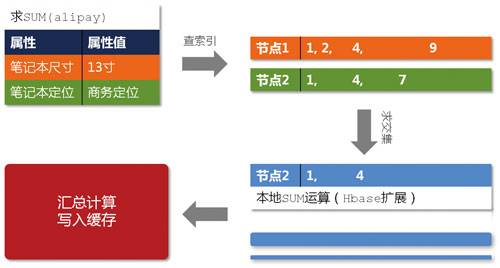
图7 Prom查询过程
图7用一个典型的例子描述的Prom在提供查询服务时的工作原理,限于篇幅,这里不做详细描述。值得一提的是,Prom支持的计算并不仅限于求和SUM运算,统计意义上的常用计算都是支持的。在现场计算方面,我们对HBase进行了扩展,Prom要求每个节点返回的数据是已经经过“本地计算”的局部最优解,最终的全局最优解只是各个节点返回的局部最优解的一个简单汇总。很显然,这样的设计思路是要充分利用各个节点的并行计算能力,并且避免大量明细数据的网络传输开销。
用中间层隔离前后端
上文提到过,MyFOX和Prom为数据产品的不同需求提供了数据存储和底层查询的解决方案,但随之而来的问题是,各种异构的存储模块给前端产品的使用带来了很大的挑战。并且,前端产品的一个请求所需要的数据往往不可能只从一个模块获取。
举个例子,我们要在数据魔方中看昨天做热销的商品,首先从MyFOX中拿到一个热销排行榜的数据,但这里的“商品”只是一个ID,并没有ID所对应的商品描述、图片等数据。这个时候我们要从淘宝主站提供的接口中去获取这些数据,然后一一对应到热销排行榜中,最终呈现给用户。
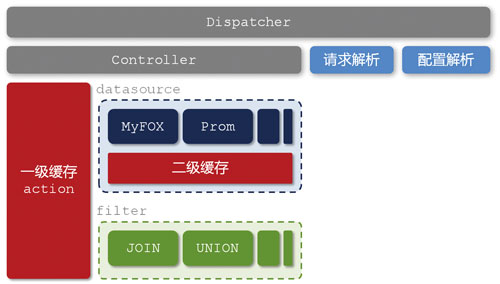
图8 glider的技术架构
有经验的读者一定可以想到,从本质上来讲,这就是广义上的异构“表”之间的JOIN操作。那么,谁来负责这个事情呢?很容易想到,在存储层与前端产品之间增加一个中间层,它负责各个异构“表”之间的数据JOIN和UNION等计算,并且隔离前端产品和后端存储,提供统一的数据查询服务。这个中间层就是glider(如图8所示)。
缓存是系统化的工程
除了起到隔离前后端以及异构“表”之间的数据整合的作用之外,glider的另外一个不容忽视的作用便是缓存管理。上文提到过,在特定的时间段内,我们认为数据产品中的数据是只读的,这是利用缓存来提高性能的理论基础。
在图8中我们看到,glider中存在两层缓存,分别是基于各个异构“表”(datasource)的二级缓存和整合之后基于独立请求的一级缓存。除此之外,各个异构“表”内部可能还存在自己的缓存机制。细心的读者一定注意到了图3中MyFOX的缓存设计,我们没有选择对汇总计算后的最终结果进行缓存,而是针对每个分片进行缓存,其目的在于提高缓存的命中率,并且降低数据的冗余度。
大量使用缓存的最大问题就是数据一致性问题。如何保证底层数据的变化在尽可能短的时间内体现给最终用户呢?这一定是一个系统化的工程,尤其对于分层较多的系统来说。
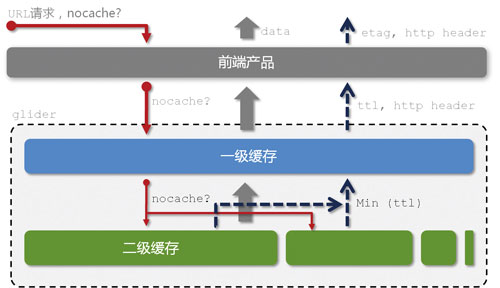
图9 缓存控制体系
图9向我们展示了数据魔方在缓存控制方面的设计思路。用户的请求中一定是带了缓存控制的“命令”的,这包括URL中的query string,和HTTP头中的“If-None-Match”信息。并且,这个缓存控制“命令”一定会经过层层传递,最终传递到底层存储的异构“表”模块。各异构“表”除了返回各自的数据之外,还会返回各自的数据缓存过期时间(ttl),而glider最终输出的过期时间是各个异构“表”过期时间的最小值。这一过期时间也一定是从底层存储层层传递,最终通过HTTP头返回给用户浏览器的。
缓存系统不得不考虑的另一个问题是缓存穿透与失效时的雪崩效应。缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。在数据魔方里,我们采用了一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存失效时的雪崩效应对底层系统的冲击非常可怕。遗憾的是,这个问题目前并没有很完美的解决方案。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。在数据魔方中,我们设计的缓存过期机制理论上能够将各个客户端的数据失效时间均匀地分布在时间轴上,一定程度上能够避免缓存同时失效带来的雪崩效应。
2015年双十一,阿里还是用的自研OceanBase数据库1秒14万单!阿里云支撑“双11”912.17亿商业奇迹
2015天猫双11全球狂欢节再次刷新一系列世界纪录。912.17亿元的天量交易背后,是中国计算能力的登顶全球。11日,阿里巴巴集团披露,当天系统交易创建峰值达到每秒钟14万笔,支付峰值达到每秒钟8.59万笔。相比2009年首届双11,订单创建峰值增长了350倍,支付峰值增长了430倍。
为了支撑这一天量的高并发交易,阿里巴巴今年实现了多项世界级技术创新:全球最大规模混合云架构;全球首个核心交易系统上云;1000公里外交易支付“异地多活”;全球首个应用在金融业务的分布式关系数据库OceanBase。
“这些世界顶尖的技术,正在通过阿里云加速向外输出。我们希望将这些技术变成普惠科技,以此催生1万个阿里巴巴”,阿里云总裁胡晓明说。
全球最大规模混合云架构实践
胡晓明介绍,今年双11淘宝天猫核心交易链条和支付宝核心支付链条的部分流量,直接切换到阿里云的公共云计算平台上。通过将公共云和专有云无缝连接的模式,全面支撑双11。
因此,如果从技术层面来看,今年双11成为了一场全球最大规模的混合云弹性架构实践。阿里巴巴成为全球大型互联网公司中,首个将核心交易系统放在云上的企业。阿里云成为全球第一家有能力支撑核心交易系统的云服务商。
“将淘宝、天猫、支付宝这么庞大、复杂、跟钱紧密关联的系统搬到云上,除了我们全世界还没有第二家,这包括全球互联网巨头和云计算公司。”胡晓明说,阿里巴巴希望在自身最重要商业实践中,验证云计算的安全性、可靠性,向世界证明云计算的优势。
胡晓明强调:“这一混合云架构完全基于阿里云官网在售的标准化产品搭建的。也就是说,你通过这些标准化的产品,也可以搭建这样一个像淘宝、天猫这样万亿级的企业应用,满足任何极端的业务挑战。”
“在双11中应用的关键技术都将变成阿里云上的标准化产品向外输出。”胡晓明说,我们希望把验证过的技术尽快分享给全球的创新创业者。
据悉,经此次双11验证并计划输出的技术包括:应用于异地多活的数据传输产品DataTransmission、实时计算系统StreamSQL、数据可视化引擎dataV等。
全球首秀1000公里异地多活能力
如果阿里巴巴的数据中心出现故障会怎样?“异地多活”正是为了应对这一突发情况。通过“异地多活”技术,系统可以迅速的把流量全部切换到另外的数据中心。整个过程不会对业务造成任何影响,用户也几乎没有感知。
据阿里巴巴技术保障部研究员毕玄介绍,早在去年“双11”,阿里巴巴就已经实现了交易系统的“异地双活”。和去年“双活”相比,今年最大的变化有两点:一是同时实现了交易和支付的“多活”;二是异地数据中心的最远距离超过1000公里,这意味着阿里巴巴具备了在全国任意节点部署交易系统的能力。
“这就像为1000公里外空中飞行的飞机更换引擎。不仅不能影响飞行,飞机上的乘客也不能有感觉。”毕玄表示,尤其在支付宝这样高度复杂与严谨的金融系统中,实现1000公里以上的“异地多活”能力,在全球也绝无先例,完全颠覆了传统金融的灾备概念。
公开资料显示,全球能够做到异地多活的只有少数几家互联网巨头如Google、Facebook,但无论是搜索还是社交场景,对数据同步性、一致性的要求远不如电商场景苛刻。
中国自研数据库支撑全球最强支付平台
双11当天,蚂蚁金服旗下的支付宝平稳支撑起了8.59万笔/秒的交易峰值,是去年双十一峰值3.85万笔/秒的2.23倍。
这一数字大幅超越了Visa和MasterCard的实际处理能力,甚至比二者的实验室数据都要高出一大截。这意味着经历了双十一大考的中国支付系统,在技术上已大幅领先全球。
支撑支付宝实现这一超越的秘密武器,是阿里巴巴与蚂蚁金服自主研发的分布式关系数据库Oceanbase。 OceanBase是中国首个具有自主知识产权的数据库,也是全球首个应用在金融业务的分布式关系数据库。
蚂蚁金服首席技术官程立介绍,今年双11的核心交易流100%由金融级海量数据库OceanBase承载。和常用的商业数据库相比,OceanBase成本不到其一半。分布式的系统可以更好地应对双11这类大流量冲击。
OceanBase 2010年诞生,2014年支撑了10%的双11交易流量。今年6月,网商银行开业,底层数据库全部采用OceanBase,是第一家完全摆脱商业数据库的金融机构。而PayPal等美国金融机构,仍然主要依靠Oracle等。
ODPS-StreamSQL:让未来实时计算更顺畅
开放数据处理服务(Open Data Processing Service, 简称ODPS)是由阿里云自主研发,提供针对TB/PB级数据、实时性要求不高的分布式处理能力,应用于数据分析、挖掘、商业智能等领域。阿里巴巴的离线数据业务都运行在ODPS上。其“海量运算””开箱即用”、“安全防护到位”、“按量付费”等特点,使得其保证了阿里云用户可以轻松实现大数据的顺利运行,一劳永逸的解决数据烦恼。
今年双11,淘宝、天猫、支付宝、菜鸟等所有大数据处理工作,都将由阿里云ODPS来完成。在刚刚结束的2015世界Sort Benchmark排序比赛中,阿里云ODPS用377秒完成了100TB的数据排序,打破了此前Apache Spark创造的1406秒纪录,一举创造4项世界纪录。ODPS根据用户实际的存储和计算消耗收费,最大化的降低用户的数据使用成本。目前,国内首家将核心系统放在云上的基金公司-天弘基金与首家互联网保险公司-众安保险都是阿里云ODPS的用户。
ODPS的实时计算系统StreamSQL在今年的双11技术支撑过程表现抢眼,据阿里内部对外宣布,双11当天通过StreamSQL系统,交易系统预计日消息处理量将达上万亿条。据了解,阿里云StreamSQL系统是一款秒级实时流计算产品,用户可以直接在SQL编程里使用。在今年7月北京举办的“阿里云分享日X云栖大会”上,阿里云资深总监李津正式发布了这款产品,作为分析型数据库,它可以完成海量数据的实时多维分析,实现海量数据多维比对和碰撞。而这一产品在刚刚过去的双11过程中得到了充分的检验,并且成绩优异,而这一能力,正在通过阿里云逐步开放出来。
dataV:让数据分析也进入“读图”时代
在阿里巴巴每天海量的交易面前,如何精准把握由数据脉搏带来的趋势也成为极大的挑战。
对此,阿里巴巴自主研发了dataV数据可视化引擎,该引擎完全基于Web 技术 ,可快速、低成本的部署。用于内部的商品、交易、支付、数据中心等的可视化呈现和管理,帮助实现更精准的调控。
自2013年起,双11交易数据大屏成为对外直播狂欢节的重要窗口,而在2015年的全球狂欢节上,这一树立在水立方的巨型数据大屏,以实时动态可视图的方式向全球用户直播了双11的数据魅力。
据悉,水立方数据大屏上,该数据可视化引擎既可以利用3D webgl技术从宏观角度展示双十一平台总体交易订单实时流向的全量展示,也可以通过便捷的交互手段,深入到城市级别进行微观的人群画像分析。
目前,这一技术已计划通过阿里云向外输出,很快将会有标准化产品推出。
OceanBase:中国自研数据库正式崛起
双11当天,刘振飞在接受媒体采访时的一段话触动了很多人:“我上大学的时候,我的导师跟我说,中国有三个IT技术没有办法突破,一个是操作系统,第二是数据库,第三是芯片,今天可以非常自豪地说,在阿里起码把数据库这个问题解决掉了,我们终于有了完全自主可控的数据库。”
没错,五年前阿里巴巴就开始打造自主可控的数据库产品OceanBase,2014年其支撑了10%的双11交易流量,而今年双11的核心交易流量,100%都由OceanBase来承载。很明显,阿里这一举动将对全球IT业的格局产生深远影响。
由于对硬件设备能力和软件许可的弱需求,通过OceanBase可以比采用传统商业数据库节约50%的成本。同时,分布式的系统,可以更好地应对双11这类大流量冲击:弹性能力可保证大促之前完成一键扩容、大促之后实现一键缩容,并且性能方面已经完全符合金融级海量数据库标准。
据阿里内部数据显示,双11当天,蚂蚁金服旗下的支付宝平稳支撑起了8.59万笔/秒的交易峰值,是去年双十一峰值3.85万笔/秒的2.23倍。这一数字大幅超越了Visa和MasterCard的实际处理能力,甚至比二者的实验室数据都要高出一大截。这意味着经历了双十一大考的中国支付系统,在技术上已大幅领先全球。而后台起到关键支撑作用的秘密武器就是 Oceanbase。
作为中国首个具有自主知识产权的数据库,也是全球首个应用在金融业务的分布式关系数据库。OceanBase计划明年可以通过阿里云的公共计算平台对外界开放。
最后
以上就是笑点低蜻蜓最近收集整理的关于2013-2015阿里双十一技术网络文章总结的全部内容,更多相关2013-2015阿里双十一技术网络文章总结内容请搜索靠谱客的其他文章。








发表评论 取消回复