上一篇介绍过数据差距与数据岛的背景,这里不再赘述,请翻阅上一文。此篇在Sqlserver上给大家演示1000万条记录的计算性能。
测试电脑软硬件说明
一般般的笔记本电脑,2017年7月,价格:4500+。
电脑配置
数据构造
1000万行数据,由10万个用户+每用户100条记录组成,同样使用书中所提及的构造序列的表值函数轻松构造完成。
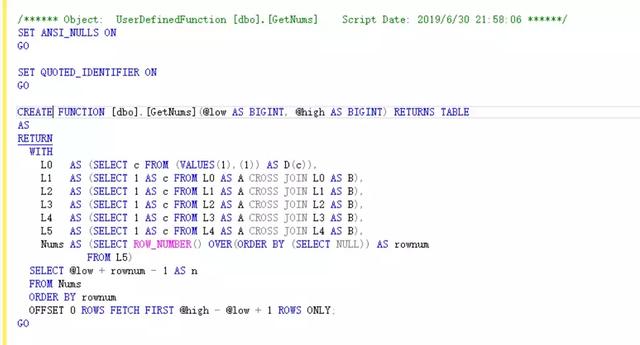
同样使用窗口函数完成的表值函数

生成1000万条数据记录
数据源结构
使用循环和随机函数,实现删除10万条数据,因测试时先建了索引再删除数据,慢得一塌糊涂,最终中途中止了,没有实际删除这么多数据。

随机删除10万条记录,用于实现数据差距和数据岛效果
关系型数据库,性能优化的核心是适当的索引,此次肯定要加上索引才能客观地表现出该有的合理效果。

增加聚集索引
算法代码演示
数据差距范围
此部分计算的逻辑是将每个用户分组下本来连续的序号中,缺失了某些记录,这些缺失的部分对应的区间范围,若缺失的为连续的,返回连续的区间,若缺失为单个记录,返回首尾相同的序号。
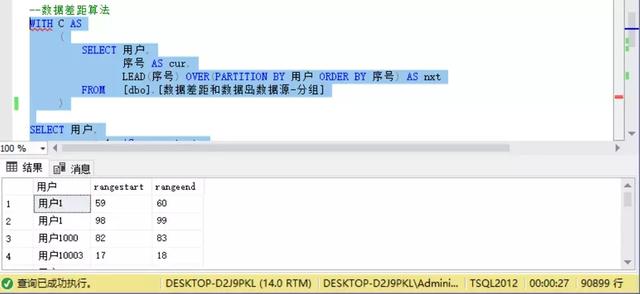
数据差距的SQL代码及结果
原理:关键思路是使用LEAD函数,使用“用户”列作分区,按序号的升序排列,取当前用户组的当前行序号为cur列,其下一行内容作为nxt列,最终构造结构表是,将当前行的cur列值+1构造出差距的首范围,当前行的nxt列值-1作为结束范围。
而最终的结果只会取nxt和cur之差大于1的记录,即开始有缺失产生差距的行记录。
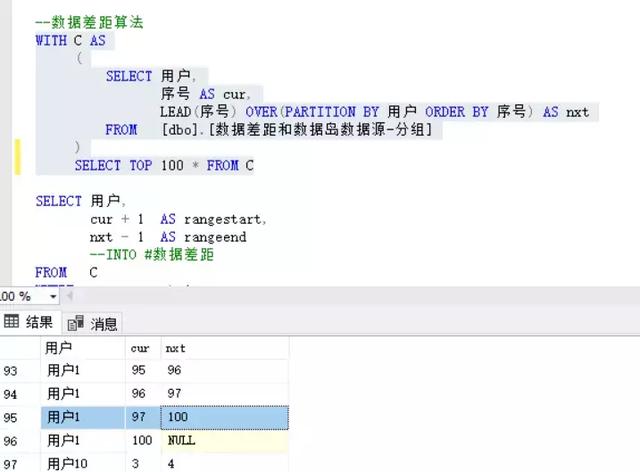
总记录1000万条,10万个用户,分组计算后,返回数据产距90899条记录,用时27秒
分解下步骤,将CTE虚拟表C给大家看下效果,可以看到97和100之间是缺失了98、99两值,最终在97序号上,cur为97、nxt为100,此行记录是我们后面where条件要筛选出来的记录行(模拟删除数据过程中,尽量删除连续的两条记录,让差距结果更清晰)。
将cur+1,nxt-1后,就拿到98-99这样的差距区间。
分步骤演示
数据岛范围
这个就是一般来说连续记录的区间,如现实场景中的用户连续打卡天区间。10万个用户测试,100天打卡天数,足够满足一般互联网中等规模的活动场景使用。
数据岛范围的SQL代码及结果
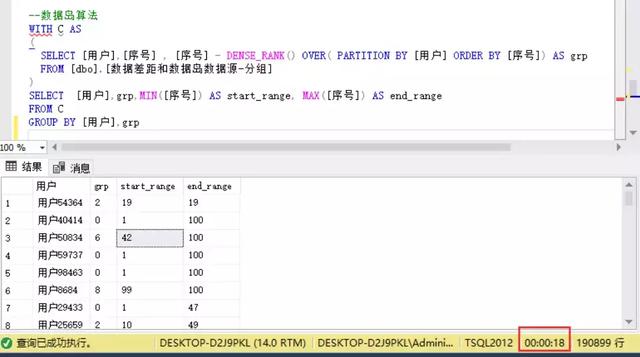
原理:使用排名窗口函数,对用户进行分组计算。若有数据缺失时,排名的序号和正常序号之差会有跳跃性的差距(正常无缺失时序号和排名是相同,且差异为0)。
下一步对排名产生的相同的数值进行分组汇总,连同用户字段,最终可统计出某用户在某个差异值grp下的连续区间。
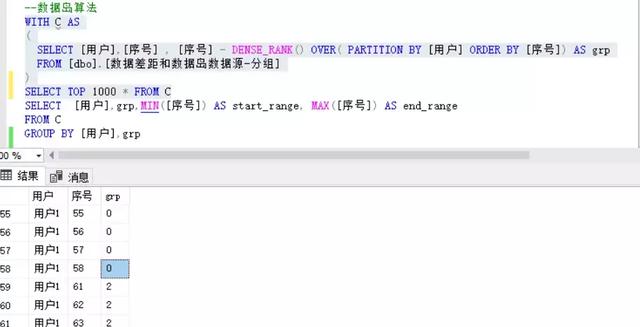
分解步骤后可知,在用户1中,58后缺失了59、60两个值,最终在61的排名与序号差grp为2,直到下一次有缺失时,此2的值再更新为下一个缺失的值区间长度2+2=4。
分步骤演示
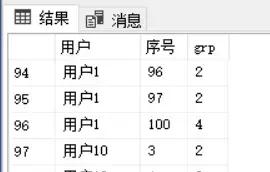
下一个缺失值为98和99两值
结语
Sqlserver的窗口函数,非常多的应用场景,对传统的SQL的查询进行了极大的简化,在PowerBI的DAX查询语言中,暂时还缺少其在集合的基础上进行窗口的处理,致使同样都是对数据集合进行运算,但因为缺失窗口函数特性支持,性能上仍然和SQL中的窗口函数处理有非常大的差距。
想必有人好奇地问,这些内容在其他数据库中是否同样可以?窗口函数在其他关系型数据库中是否也一样支持?
据笔者知识范围所知,MySQL和Sqlite是没有的,Oracle是有的,并且比Sqlserver更强大(为何不推荐,因为笔者是微软系的信徒呗,Oracle人家是法务团队强大,你懂得)。
最后
以上就是慈祥西装最近收集整理的关于1万条数据大概占多大空间_「数据分析」Sqlserver的窗口函数的精彩应用之数据差距与数据岛...的全部内容,更多相关1万条数据大概占多大空间_「数据分析」Sqlserver内容请搜索靠谱客的其他文章。








发表评论 取消回复