2019独角兽企业重金招聘Python工程师标准>>> 
1. Hibernate创建过程
l 引入jar包
l 加入配置文件hibernate.cfg.xml
l 创建数据
l 创建实体,配置映射:1、xml;2、jpa(推荐)
l 测试:1、加载配置文件;2、创建SessionFactory;3、openSession;4、beginTransaction;5、save;6、commit;7、close
2. HelloWorld
l Xml配置方式:实体对应hbm.xml
l Annotation配置方式:类名用@Entity注解
3. Hibernate模拟实现
l 创建数据库
l 与表建立映射关系
l 提供保存对象方法
l 将对象转换为sql语句
l 执行sql
l 关闭链接
4. 常见OR框架
l jFinal
l MyBatis
5. hbm2ddl
l create:每次启动都会删除表后重建。数据会丢失
l update:根据最新实体对数据表进行同步修改。强烈推荐。
6. 先建表还是先建类
l best practise:先建表,方便对数据库进行优化
7. 搭建Logback日志环境
l 引入slf4j-api.jar,代码以slf4j-api为标准开发,方便切换日志实现
l 引入logback-core.jar、logback-classic、logback-access。logback-classic实现了slf4j-api,不用再引入转换包
l 配置logback.xml日志等级、格式
8. 搭建Junit日志环境
l @Test:执行的测试单元
l @BeforeClass:执行测试单元前执行,定义为static
l @AfterClass:执行测试单元后执行,定义为static
l 测试驱动开发(Test-Driven Development):不可运行/可运行/重构
9. BaseConfig
l showsql:显示hibernate执行的sql语句
l formatsql:将sql语句格式化后输出
10. Annotation字段映射
l Xml:某属性不需要映射,则不配置对应属性
l Annotation:某属性不需要映射,则配置@Transient,@Transient只有放在get方法上才有效(测试的4.3.5版本)。
l 强烈推荐使用Annotation方式,配置简便。
l 默认配置@Basic注解
l Enum类型属性:使用@Enumerated注解:value可选EnumType.STRING、EnumType.ORDINAL,数据库根据类型创建对应类型
l Date类型:使用@Temporal注解:value可选TemporalType.DATE、TemporalType.TIME、TemporalType.TIMESTAMP,数据库根据类型创建对应类型
l Best practise:注解放在get方法上面,因为放在属性上面暴露的是private的属性,那样就破坏了面向对象的封装性
11. ID的生成策略
l Xml:常用native、uuid、identity、sequence:native会根据数据库自动映射,mysql下为identity(auto_increment);oracle下为sequence
l Annotation:jpa只支持4种:GenerationType.AUTO、GenerationType.IDENTITY、GenerationType.SEQUENCE、GenerationType.TABLE,默认GenerationType.AUTO,类似xml中native
l Sequence:默认只生成一个名为hibernate_seq的序列,所有的表共用一个序列。也可以使用@GeneratedValue(strategy = GenerationType.SEQUENCE, generator="teacherSEQ")指定序列,并且可以在class上面用@SequenceGenerator(name = "teacherSEQ", sequenceName = "teacher_SEQ")指定序列别名
l TableGenerator:使用场景,真正提供跨数据库平台id的生成策略(使用AUTO无法完美解决跨平台,例:Oracle数据库与Mysql数据库id的生成策略不一致,Oracle使用AUTO只能生成一个sequence,无法每个表自增)。使用较少,了解即可。
l 复合/联合主键:xml中使用composite-id指定;annotation有三种方式实现,从2、3选择一种即可:
1. @Id @Embeddable
2. @EmbeddedId
3. @Id @IdClass
12. SessionFactory
l 由hibernate.cfg.xml配置文件决定生成规则
l configure()可加载指定配置文件
l 通常情况每个应用只需要一个SessionFactory。访问多个数据库时每个数据库对应一个。
l getCurrentSession、openSession均可获得session,区别如下:
1. openSession每次打开一个新连接,提交后手动close
2. getCurrentSession根据配置(current_session_context_class)策略从上下文获取已经打开的session,如果没有则新增一个,不需要手动关闭session
3. getCurrentSession主要用于界定事务边界
4. 两种方式生成的session不能混用,即openSession打开了一个链接,则getCurrentSession无法获取到该链接
l current_session_context_class可配置为:JTA、thread
1. thread依赖与connection事务
2. JTA:java transaction api,用于多个数据库分布式事务
13. Session的核心API
l save,保存对象操作,对象有三种状态:
1. transient:内存有、缓存没有、数据库没有——ID没有
2. persistent:内存有、缓存有、数据库有——ID有
3. detached:内存有、缓存没有、数据库有——ID有
l delete,只要对象的id有值,就能删除
l load、get:获取数据对象,差别:
1. load返回的是代理对象,延迟加载,在具体使用对象内容时才推送sql语句。(测试中发现:超时也会执行,具体超时时间不定)
2. get即时加载,不会延迟
3. 数据不存在:load报错;get不报错,返回null
l Update
1. 用来更新detached对象,更新后转为persistent状态
2. 更新transient对象会报错
3. 可以更新自己设定id的transient对象(前提《==数据库有对应记录)
4. persistent状态的对象只要设定值就会发生更新(特别注意:不需要save就会执行更新)
5. 更新部分更改的字段
1. 对于单个属性:xml设定property的update属性,annotation采用@Column(updatable = false)注解实现,这种情况很少用,不灵活
2. 整个对象:xml使用dynamic-update="true"实现,JPA无对应实现。hibernate扩展annotation注解@DynamicUpdate(true)可以实现。同一个session可以,跨session不行,不过可以用merge实现。
3. 使用HQL(EJBQL)(推荐使用)
l saveOrUpdate:不存在id时save,存在id时update
l clear:
1. 无论是get还是load,都会首先查找缓存(一级缓存),如果没有,才会去数据库查找
2. 调用clear方法可以强制清除session缓存
l Flush
1. 强制缓存与数据库同步(强制推送sql语句)
2. Flushmode,知道即可,不重要
l find:已经过时
l SchemaExport:主要用来显示sql脚本,方便保留数据库脚本信息
14. 表间关系映射
l 一对一单向外键关联
1. Annotation:@OneToOne实现,@JoinColumn指定外键名称
2. Xml:采用many-to-one标签指定,设置unique="true"表示唯一
l 一对一双向外键关联
1. Annotation:@OneToOne,mappedBy。强烈推荐
2. Xml:<many-to-one unique,<one-to-one property-ref,不好理解
3. 实际应用中,采用双向关联,都会使用mappedBy减少外键个数
4. 单向、双向生成的数据库都一样,但是双向模式在任一对象上面都能拿到关联的数据对象
l 一对一单向主键关联(不重要)
l 一对一双向主键关联(不重要)
l 联合主键
1. @JoinColumns来关联
l 组件映射
1. 使用@Embedded指定嵌入的组件
2. 组件中的属性不能重复,可采用改名或者指定@Column(name = 指定列表
l 多对一单向:在多方向增加@ManyToOne
l 一对多单向:在少方加@OneToMany @JoinColumn指定关联外键
l 一对多、多对一双向关联:
1. Annotation:无法指定列名?
2. Xml:one的key必须与many的column一致,否则生成多个外键
l 多对多单向关联:
@ManyToMany
@JoinTable(name = "t_s", // 关联中间表名
joinColumns = @JoinColumn(name = "teacher_id", referencedColumnName = "id"), // 中间表,关联当前表(teacher)的字段信息
inverseJoinColumns = @JoinColumn(name = "student_id", referencedColumnName = "id") // 中间表,关联引用的字段(student)信息
l 多对多双向关联:极少用
15. 表关联操作
l 一对多关联操作:
1. CUD操作通过cascade = CascadeType.ALL实现级联
1. 设置在哪个对象,就对操作的那个对象有作用
2. 技巧:尽量操作关系为多(many)的表,操作方便
2. R(Retrieve)操作通过fetch = FetchType.EAGER控制加载规则
1. OneToMany对象默认是FetchType.LAZY,即不关联加载many数据
2. ManyToOne对象默认是FetchType. EAGER,即关联加载one数据
3. best practice:OneToMany只在many数据量很少的情况下设置为EAGER。
l 多对多关联操作:
1. 保存设置@JoinTable注解的对象才能保存成功,最佳实践——进行双向设置
l 集合映射:
1. Set:无顺序
2. List:有顺序,通过@OrderBy("name ASC")指定排序规则
3. Map:通过@MapKey(name = "id")指定map的key
l 集成映射:
1. Single_Table:数据存储在一张表,缺点:存储数据冗余。适用于字段少,总数据较少的情况;
2. Table_Per_Class:
1. 每个类映射为一张表
2. 为保证唯一性(多态读取数据),需利用@TableGenerator生成主键
3. 缺点:查询需要将所有的表union。适用于字段多,多态(父类)查询少的情况
3. JOINED:
1. 每个类映射为一张表,子类不包含父类除id外的字段
2. 缺点:查询父类会关联所有表,查询子类都会关联父类表。
16. Hibernate查询语言
l HQL vs EJBQL
1. NativeSQL > HQL > EJBQL(JP QL 1.0) > QBC(Query By Critira)
2. 总结:QL应该和导航关系结合,共同为查询提供服务
17. 性能优化
l 注意session.clear()的运用,尤其在不断分页的循环的时候
1. 遍历大集合
2. 另外一种形式的内存泄露
18. 1+N问题
l ManyToOne对象默认是FetchType. EAGER,即关联加载one数据。当只取many的数据时,会将每条数据关联的one通过一条sql语句取出来,造成数据库的负担。解决的方案有:
1. 将fetch设置为FetchType.LAZY,在合适的时候加载数据
2. 在Entity上面加@BatchSize属性,设置size,减少执行取数据次数
3. 利用QBC语句进行查询,或者直接采用HQL加上join fetch条件查询关联数据
19. list、iterator
l 相同点:获取数据集。
l 不同点:
1. list一次性取出所有数据;iterator先取出id,在访问其他属性的时再利用ID取数据,类似延迟加载。
2. 同一个session中,list方式每次都会从数据库获取数据;iterator能利用session缓存,如果session中存在,则直接从session中返回。
20. 一级缓存、二级缓存和查询缓存
l 什么是缓存:缓存就是将数据库经常用到的数据存储到服务器内存或磁盘上面,提供快速查询能力的技术。
l 一级缓存,session缓存,存储在内存中。eg:同一个session里面,多次load同一个对象。
l 二级缓存,sessionFactory缓存。对所有session缓存统一进行缓存,故在多个session里面,load同一个对象,不用查询数据库。适合做二级缓存的特点:
1. 查询频率高
2. 数据改动小
3. 数据量不大
l 打开二级缓存:
1. hibernate.cfg.xml文件
<property name="cache.use_second_level_cache">true</property>
<property name="hibernate.cache.region.factory_class">org.hibernate.cache.EhCacheRegionFactory</property>
2. 制定需要缓存的数据实体。
1. 需要缓存的domain加注解
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
2. Best practic:在hibernate.cfg.xml中增加
<class-cache class="com.bjsxt.hibernate.Category" usage="read-write"/>
l load默认使用二级缓存,iterator默认使用二级缓存。
l list默认往二级缓存加载,但查询的时候不使用,查询每次都到数据库执行。
l 查询缓存:用来缓存相同查询语句的结果集
1. hibernate.cfg.xml文件
<property name="cache.use_query_cache">true</property>
2. 调用Query设置setCacheable(true)方法指明使用二级缓存
l 缓存算法:当缓存的容量满时
1. LRU、LFU、FIFO
1. Least Recently Used:最近很少用
2. Least Frequently Used:命中率较低
3. First In First Out:先进先出
2. memoryStoreEvictionPolicy=”LRU”(ehcache)
21. 事务隔离机制
l 事务的特征:ACID
l 事务并发可能出现的问题:


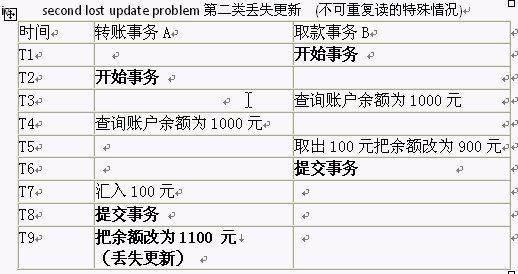

l 数据库的事务隔离机制



转载于:https://my.oschina.net/u/254813/blog/275024
最后
以上就是俊逸音响最近收集整理的关于hibernate读书笔记 1. Hibernate创建过程 2. HelloWorld 3. Hibernate模拟实现 4. 常见OR框架 5. hbm2ddl 6. 先建表还是先建类 7. 搭建Logback日志环境 8. 搭建Junit日志环境 9. BaseConfig 10. Annotation字段映射 11. ID的生成策略 12. SessionFactory 13. Session的核心API 14. 表间关系映射 1的全部内容,更多相关hibernate读书笔记内容请搜索靠谱客的其他文章。








发表评论 取消回复