我是靠谱客的博主 迷人心情,这篇文章主要介绍Spark递归遍历HDFS并筛选文件,Spark集群模式记录自己的调试日志一、递归遍历HDFS并筛选文件二、Spark集群模式记录自己的调试日志参考,现在分享给大家,希望可以做个参考。
文章目录
- 一、递归遍历HDFS并筛选文件
- 1-1、对于本地文件系统
- 1-2、对于HDFS文件系统
- 二、Spark集群模式记录自己的调试日志
- 2-1、Spark默认log4j配置
- 2-2、Yarn运行时,使用自定义配置文件的几种方式
- 2-3、自定义log4j.properties
- 2-4、应用自定义配置
- 参考
一、递归遍历HDFS并筛选文件
1-1、对于本地文件系统
public static boolean logFilter(Path path){
return path.toString().toLowerCase().endsWith(".log");
}
public static Set<Path> listLogs(String path) throws IOException {
Set<Path> logFiles = Files.walk(Paths.get(path))
.filter(Utils::logFilter).collect(Collectors.toSet());
// logFiles.forEach(System.out::println);
return logFiles;
}
1-2、对于HDFS文件系统
def traverseDir(hdconf: Configuration, path: String, recursive: Boolean, filePaths: StringBuffer) {
val files = FileSystem.get(hdconf).listStatus(new Path(path))
files.foreach { fStatus => {
if (!fStatus.isDirectory && fStatus.getPath.getName.endsWith(".xml")) {
filePaths.append("," + fStatus.getPath.toString)
}
else if (fStatus.isDirectory) {
traverseDir(hdconf, fStatus.getPath.toString, recursive, filePaths)
}
}
}
}
有人说需要配置sc.hadoopConfiguration.get("mapreduce.input.fileinputformat.input.dir.recursive")
不需要
sc.textfile()中可传入逗号隔开的多个字符串文件路径
二、Spark集群模式记录自己的调试日志
2-1、Spark默认log4j配置
cat /etc/spark/conf.cloudera.spark_on_yarn/log4j.properties
log4j.rootLogger=${root.logger}
root.logger=INFO,console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
shell.log.level=WARN
log4j.logger.org.spark-project.jetty=WARN
log4j.logger.org.spark-project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
log4j.logger.org.apache.spark.repl.Main=${shell.log.level}
log4j.logger.org.apache.spark.api.python.PythonGatewayServer=${shell.log.level}
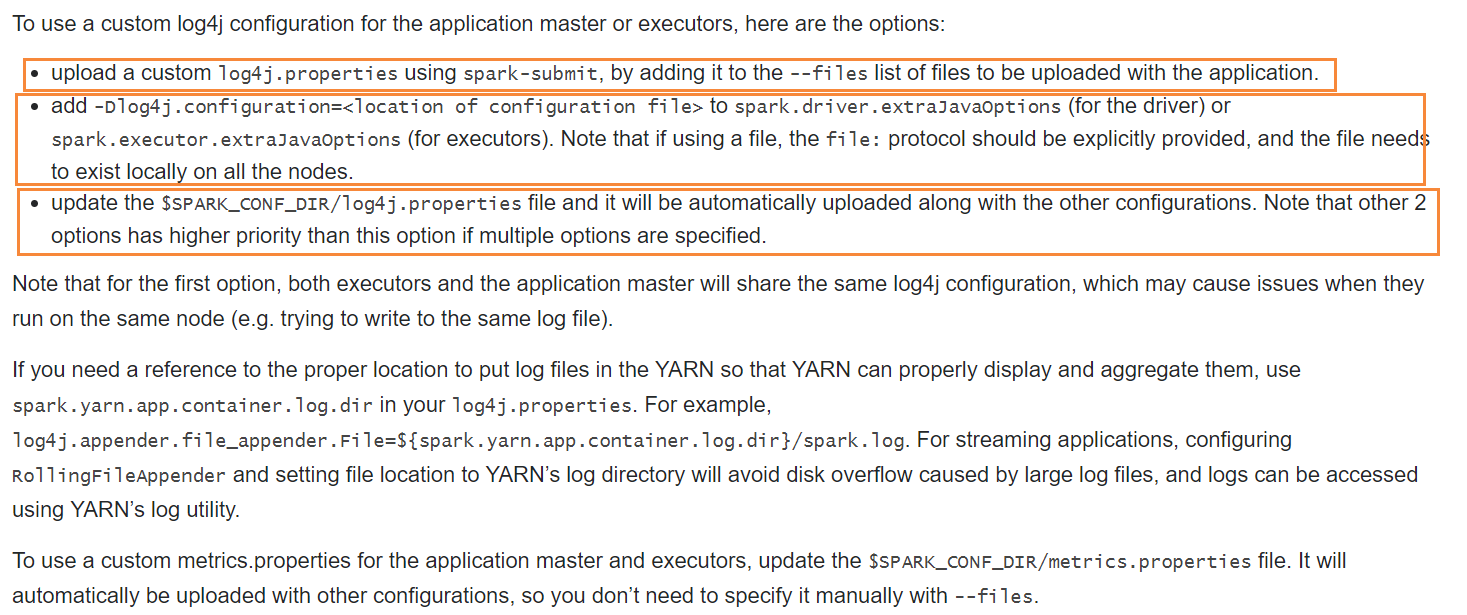
2-2、Yarn运行时,使用自定义配置文件的几种方式
2-3、自定义log4j.properties
# 默认情况下,所有log显示到console并追加到file
log4j.rootLogger=INFO, RollingAppender, console
# 程序中自己打的log写到其他file
log4j.logger.myLogger=INFO, MyRollingAppender
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
log4j.appender.RollingAppender=org.apache.log4j.DailyRollingFileAppender
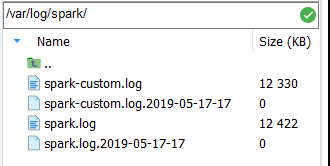
log4j.appender.RollingAppender.File=/var/log/spark/spark.log
log4j.appender.RollingAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.RollingAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.RollingAppender.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
log4j.appender.MyRollingAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.MyRollingAppender.File=/var/log/spark/spark-custom.log
log4j.appender.MyRollingAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.MyRollingAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.MyRollingAppender.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
# 以下log不打印到console
log4j.logger.spark.storage=INFO, RollingAppender
log4j.additivity.spark.storage=false
log4j.logger.spark.scheduler=INFO, RollingAppender
log4j.additivity.spark.scheduler=false
log4j.logger.spark.CacheTracker=INFO, RollingAppender
log4j.additivity.spark.CacheTracker=false
log4j.logger.spark.CacheTrackerActor=INFO, RollingAppender
log4j.additivity.spark.CacheTrackerActor=false
log4j.logger.spark.MapOutputTrackerActor=INFO, RollingAppender
log4j.additivity.spark.MapOutputTrackerActor=false
log4j.logger.spark.MapOutputTracker=INFO, RollingAppender
log4j.additivty.spark.MapOutputTracker=false
# 其他配置
shell.log.level=WARN
log4j.logger.org.spark-project.jetty=WARN
log4j.logger.org.spark-project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
log4j.logger.org.apache.spark.repl.Main=${shell.log.level}
log4j.logger.org.apache.spark.api.python.PythonGatewayServer=${shell.log.level}
2-4、应用自定义配置
- 仅配置- -files,发觉不可行
- 加上
--conf "spark.driver.extraJavaOptions=${log4j_setting}"
--conf "spark.executor.extraJavaOptions=${log4j_setting}"
也不行
- 修改权限,不行
- 最终可行的:
- 覆盖${SPARK-HOME}/conf/log4j.properties
- chown spark:spark -R /var/log/spark
- (之前的–files以及–conf "spark.driver.extraJavaOption、spark.executor.extraJavaOptions"都不再需要设置)
参考
- How to list all files in a directory and its subdirectories in hadoop hdfs
- spark yarn log4j.properties
- spark-submit, how to specify log4j.properties
- How to log in Apache Spark
最后
以上就是迷人心情最近收集整理的关于Spark递归遍历HDFS并筛选文件,Spark集群模式记录自己的调试日志一、递归遍历HDFS并筛选文件二、Spark集群模式记录自己的调试日志参考的全部内容,更多相关Spark递归遍历HDFS并筛选文件,Spark集群模式记录自己内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复