在前面的博客中谈到了不使用分布式系统如何做并行计算。其中需要利用scp命令手动拷贝数据的地方有如下三处:
(1)手动将待处理的数据从Server1拷贝到各个计算节点;
(2)手动将可执行文件topN从Server1拷贝到各个计算节点;
(3)手动将各节点的中间计算结果从每个节点拷贝到Node10。
如何避免这种频繁的基于手动的数据移动,我们需要这样一个工具,它具有如下特点:集群中每一个节点都能看到相同的目录树和文件路径,某一节点对目录树的修改(如增加或删除数据),任何其它节点都可以同步感知这个变化。HDFS(Hadoop Distributed File System 即为这样的工具)。
一、HDFS 如何为计算任务提供存储空间
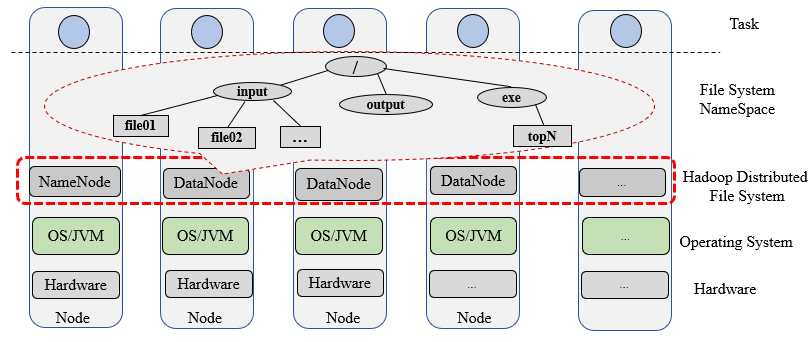
图1-1 HDFS为不同节点的计算任务提供统一的存储路径
如图1-1所示,HDFS提供了全局统一的文件系统命名空间,任何一个节点都可以看到相同的目录树,在任何节点启动程序并指定输入输出路径,就像使用本地路径一样。HDFS通过软件方式(每个节点都有守护进程)聚合了每个节点的存储空间,向上层的任务(每个节点上的数据处理程序)提供统一的存储系统。通过HDFS,源数据和可执行文件只需要上传一次,每个节点均可以使用。各节点的计算任务执行完毕,数据都保存到HDFS的/output目录,不需要手动汇聚中间计算结果。
二、HDFS 的角色与交互
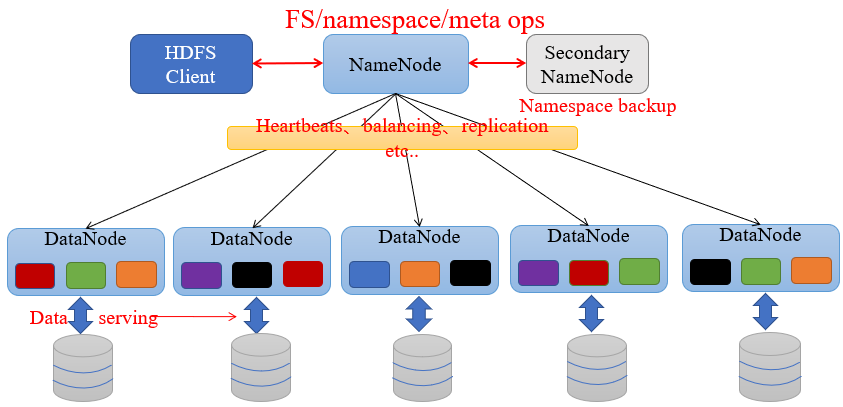
图1-2 HDFS的角色与交互
图1-2描述了HDFS涉及的四个角色,分别是NameNode,DataNode,Client,SecondaryNameNode。其中NameNode保存着整个文件系统的目录树和元数据(常驻内存),DataNode负责实际的数据存储。四个角色的具体功能如下:
NameNode:Master节点,在hadoop1.X中只有一个,管理HDFS的名称空间和数据块映射 信息,配置副本策略,处理客户端请求。
DataNode:Slave节点,存储实际的数据,汇报存储信息给NameNode。
Secondary NameNode:辅助NameNode,分担其工作量;定期合并fsimage和fsedits, 推送给NameNode;紧急情况下,可辅助恢复NameNode,但Secondary NameNode并非NameNode的热备。
Client:切分文件;访问HDFS;与NameNode交互,获取文件位置信息;与DataNode交互,读取和写入数据。
三、NameNode的目录树与块映射
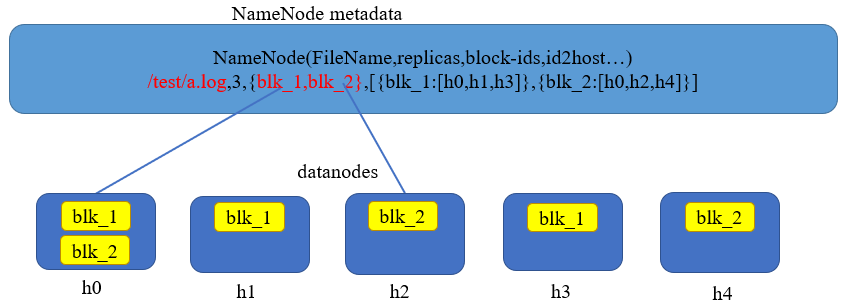
图1-3 NameNode的目录树与块映射
图1-3描述了常驻NameNode内存的目录树和元数据信息。与本地文件系统例如linux下的ext3等格式的文件系统相比,除了文件路径,权限等属性以外,HDFS的文件属性还具有一些额外特征。例如,数据的备份数,文件与分块的映射,块与存储节点的映射关系。其中blk_i代表某个数据块的id,hi代表存储数据的DataNode。
四、HDFS 客户端的形式
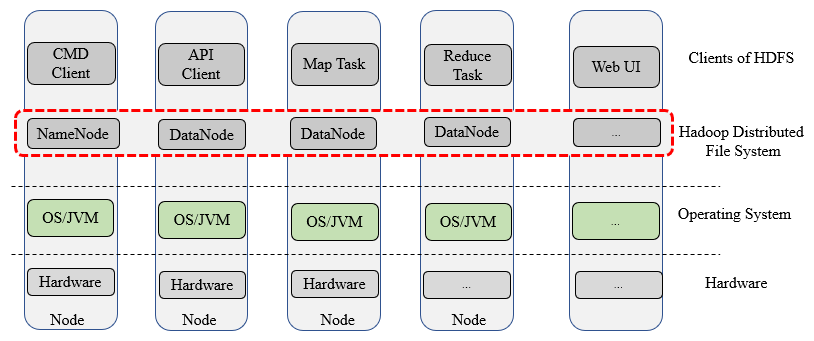
图1-4 HDFS客户端的几种形式
图1-4描述了HDFS客户端的几种形式。一方面,我们可以通过命令行,写程序和Web浏览器操作HDFS,例如上传下载删除文件。另外一方面,HDFS为MapReduce和Spark等并行计算框架提供存储服务,以MR为例,Map Task和Reduce Task均为HDFS客户端的形式。
五、思考题-什么叫Master和Slave?
谈到Hadoop平台或其它流行的大数据组件时,经常会出现以下一些概念,如Master,Slave,NameNode,DataNode,JobTracker、TaskTraker,ResourceManager,NodeManager,HMaster,RegionServer,Master,Worker等名词。初学者经常无法准确理解。
一般来讲,Master负责组织和协调工作,称为主节点;Slave负责具体的执行工作,称为从节点。更进一步, Master和Slave要结合具体的大数据组件来确定。
在HDFS中,NameNode是主节点,DataNode是从节点;
在YARN中,RedourceManager是主节点,NodeManeger是从节点;
在SparK中,Master是主节点,Worker是从节点;
在HBase中,HMaster是主节点,RegionServer是从节点。
最后
以上就是重要跳跳糖最近收集整理的关于spark 显示hdfs 路径_Hadoop基础HDFS介绍(一)的全部内容,更多相关spark内容请搜索靠谱客的其他文章。

![[Spark][Python]对HDFS 上的文件,采用绝对路径,来读取获得 RDD](https://www.shuijiaxian.com/files_image/reation/bcimg5.png)






发表评论 取消回复