
注:图片如果损坏,点击文章链接:https://www.toutiao.com/i6815920501530034696/
承接上一篇文档《Spark词频前十的统计练习》
Spark on standalone
类似于yarn的一个集群资源管理框架,spark自带的
yarn
ResourceManager(进程)
管理和调度集群资源,主要包括:申请、调度、监控
NodeManager(进程)
管理当前节点的资源,以及启动container资源:CPU和内存(CPU决定快慢,内存决定生死)
注意:一台机器只允许有一个NodeManager
standalone
Master:(进程)
管理集群资源,主要包括:申请、调度、监控
Worker:(进程)
当前进程允许分配的资源进行管理,包括资源的管理以及executor的启动资源:CPU和内存(CPU决定快慢,内存决定生死)
注意:一台机器允许有多个Worker进程
Standalone集群的配置
前提:spark的本地执行环境已经配置好了
- 修改${SPARK_HOME}/conf/spark-env.sh
SPARK_MASTER_HOST=域名和ip
SPARK_MASTER_PORT=7070
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=2//指定当前机器上的每个worker进程允许分配的逻辑CPU核数
SPARK_WORKER_MEMORY=2g//指定当前机器上的每个worker允许分配的内存大小(可以认为是逻辑内存)
SPARK_WORKER_PORT=7071
SPARK_WORKER_WEBUI_PORT=8081
SPARK_WORKER_INSTANCES=2//指定当前机器上的Worker的数量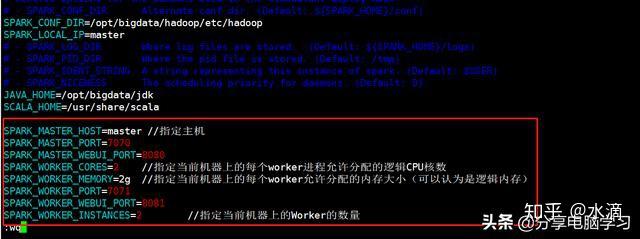
2. 配置Worker节点所在机器,在conf目录中
cp slaves.template slaves
修改slaves
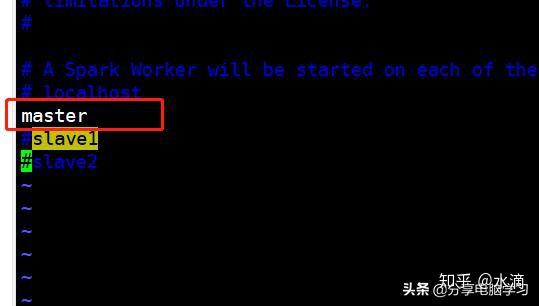
备注:一行一个机器的主机名(Worker进程所在的机器的hostname)
3. 额外:完全分布式配置(此处可不配置了解即可)
只需要在slaves文件中添加slave从节点的hostname即可(前提是ssh、hostname和ip映射等hadoop的依赖环境均已完成),然后将修改好的spark的安装包copy到其他的slave机器上即可完成分布式的安装
4. 启动服务
4.1 启动主节点
./sbin/start-master.sh访问WEBUI:http://master:8080/
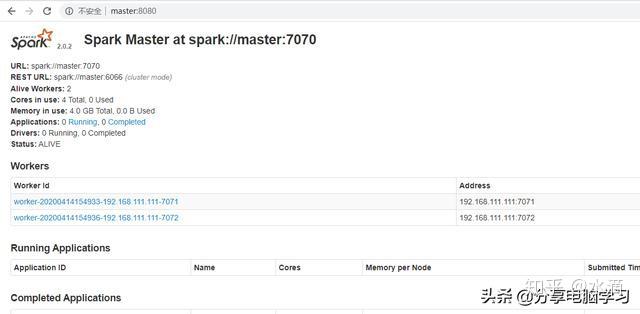
4.2 启动从节点(Worker)
./sbin/start-slave.sh spark://master:7070
4.3 关闭所有服务
./sbin/stop-all.sh4.5 启动所有服务
./sbin/start-all.sh注意:启动和关闭所有服务的前提是由ssh免秘钥登录
5. 简单查看/测试
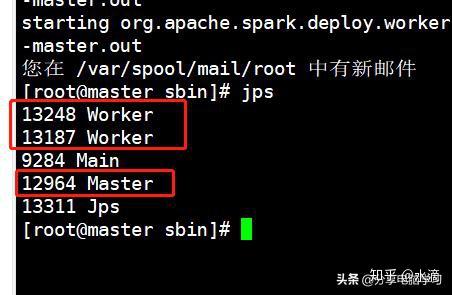
5.1 jps查看Master和Worker进程
5.2 查看WEBUI界面:http://master:8080/
5.3 ./bin/spark-shell --help--》查看帮助命令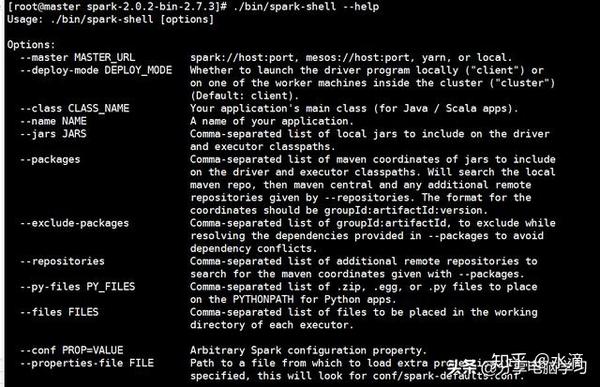
./bin/spark-shell --master spark://master:7070val result1 = sc.textFile("file:///opt/modules/spark/README.md").flatMap(_.split(" ")).filter(_.nonEmpty).map((_,1)).reduceByKey(_+_).collect如果看到collect有结果,表示我们的standalone搭建完成

Spark StandAlone集群的HA配置
1. Single-Node Recovery with Local File System --基于文件系统的单节点恢复
在spark-env.sh配置
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/user/spark/tmp"spark.deploy.recoveryDirectory --> 保存恢复状态的一个目录
2. Standby Masters with ZooKeeper --基于Zookeeper的Master的HA机制
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop01:2181,hadoop02:2181,hadoop03:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"
假设有三台机器
hadoop01MasterSPARK_MASTER_HOST=hadoop01
hadoop02Master(standby) SPARK_MASTER_HOST=hadoop02
hadoop03SPARK_MASTER_HOST=hadoop02启动Master,在hadoop01上用 start-all.sh(hadoop01:8080)
再在hadoop02上面单独启动Master start-master.sh (自动成为StandBy的状态hadoop02:8080)
Spark应用的监控
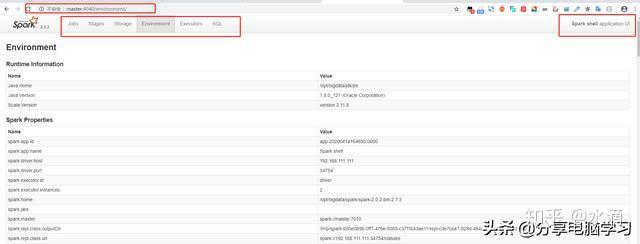
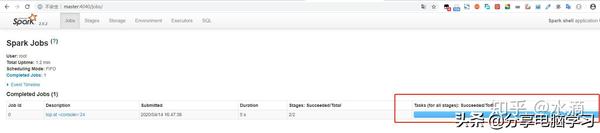
如果运行

页面就会变化
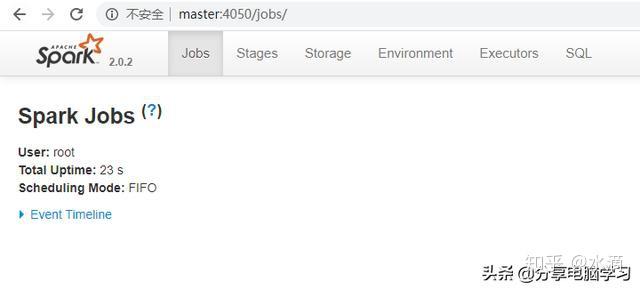
如果关掉shell,页面就不存在了


官网:http://spark.apache.org/docs/2.0.2/monitoring.html给了监控方法
- 针对我们正在运行的Spark应用,可以通过WEB界面监控,默认端口号是4040,如果4040被占用,就会依次进行端口递增(也是有次数限制的),
spark.ui.port=4050 --4051 4052
2. 如果应用已经执行完成了,那可以spark的job history server服务来看
MapReduce的job history server
(1). 开启日志聚集功能
(2). 日志上传到HDFS的文件夹路径
(3). 启动mr的job history服务(读取HDFS的日志文件,并进行展示)
Spark的job history server
(1). 在HDFS上创建spark应用日志存储路径
./bin/hdfs dfs -mkdir -p /spark/history
(2). 修改配置文件spark-default.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:8020/spark /history(3). 配置Spark的job history server
spark-env.sh
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://master:8020/spark/history-Dspark.history.ui.port=18080"
(4). 启动spark的job history server
http:/master:18080/api/v1/applications
查看Jps

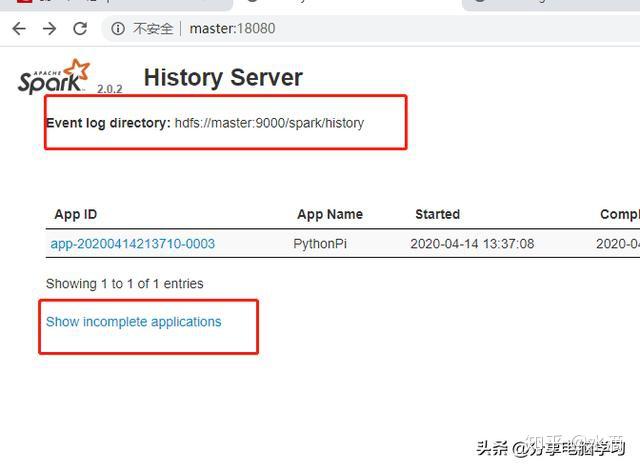
Web的地址查看,注意18080
这里出现了一个错误18080可以访问但没有内容
先检查Hadoop是否创建了这个目录

检查路径是否有问题
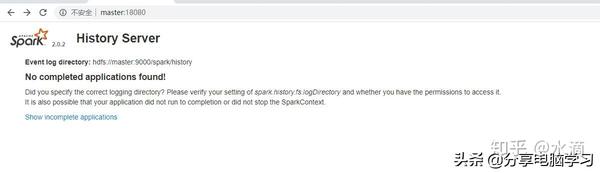
检查配置文件发现问题所在
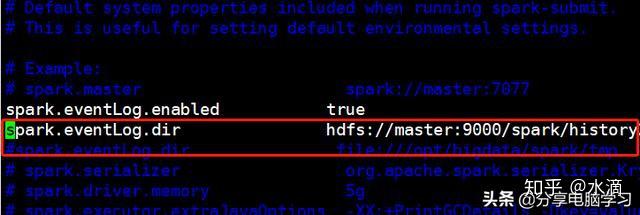
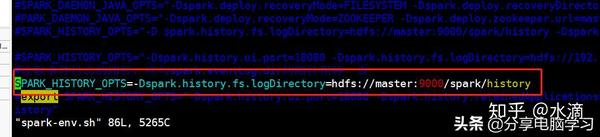
经测试后发现:
spark.eventLog.dir:Application在运行过程中所有的信息均记录在该属性指定的路径下;
spark.history.fs.logDirectory:Spark History Server页面只展示该指定路径下的信息;
比如:spark.eventLog.dir刚开始时指定的是hdfs://hadoop000:8020/directory,而后修改成hdfs://hadoop000:8020/directory2那么spark.history.fs.logDirectory如果指定的是hdfs://hadoop000:8020/directory,就只能显示出该目录下的所有Application运行的日志信息;反之亦然。
所有这里修改spark.eventLog.dir为
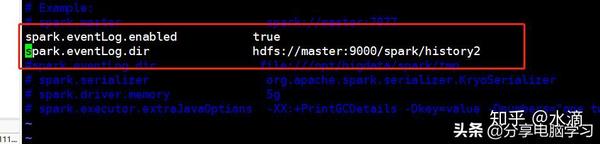
重启服务即可访问

在页面里可以查看很多信息,比如日志配置路径,未完成的应用等等
Api查询应用
RESTAPI:
http://master:18080/api/v1/applications/local-1533452143143/jobs/0
最后
以上就是超级书包最近收集整理的关于spark启动的worker节点是localhost_Standalone集群搭建和Spark应用监控的全部内容,更多相关spark启动内容请搜索靠谱客的其他文章。








发表评论 取消回复