如何处理训练集
在神经网络的计算中,通常先有一个前向传播(前向暂停 forward pause),接着有一个反向传播(反向暂停 backward pause)的步骤。
逻辑回归:一个用于二分类的算法
以猫的识别为例
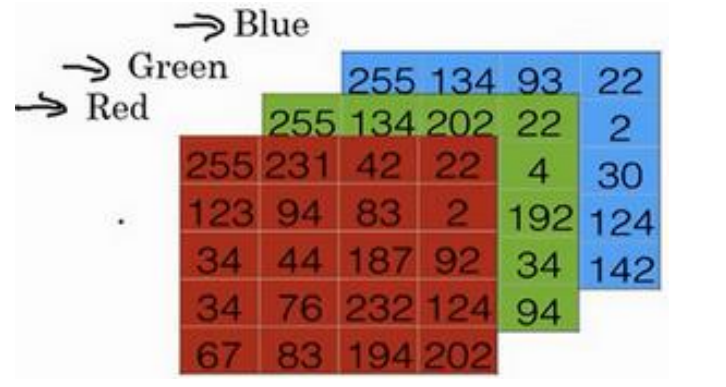
图片(64X64像素)在计算机中的保存:三个64X64的
矩阵,对应R,G,B三种像素的强度值。定义一个特征向量,线性存储所有像素值,总维度是64X64X3。
输入是X(mXnx),输出Y(取值为0或1)
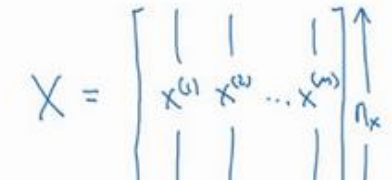
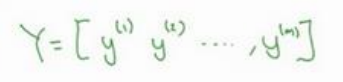
列堆叠要比行堆叠在进行神经网络训练时容易得多
- 假设函数(Hypothesis Function)
- w:逻辑回归的参数(也是一个nx维的向量),
特征权重 - b:
偏差(实数)
- w:逻辑回归的参数(也是一个nx维的向量),
这在
线性回归时可用到,但在进行二分类时,无法保证取值范围在输出值的值域中
采用sigmoid函数
以逻辑回归的假设函数为自变量z
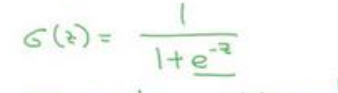
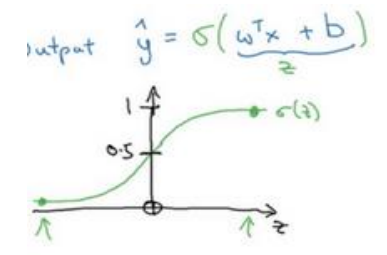
如果z趋于正无穷,sigmoid函数结果近似等于1,如果z趋于负无穷,sigmoid函数结果近似于0,保证了输出y在(0,1)之间

注意,因为想将?</sup>=w<sup>T</sup>X+b`转换`为?<sup>= ?(?
?X),因为?增加一个偏差b,那么X也应增加一维x0=1,即转换成功
逻辑回归的代价函数(Logistic Regression Cost Function)
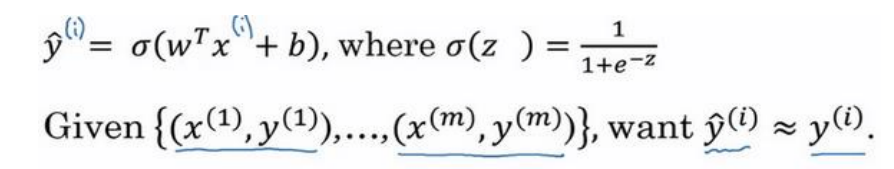
损失函数:用来
衡量算法的运行情况(预测值和实际值有多接近),Loss function:L(y^,y),一般我们用预测值和实际值的平方差或者平方差的一半,但在逻辑回归中我们不这么做(因为优化目标不是凸优化(可行域及目标函数均凸),只能找到多个局部最优值,梯度下降法很可能找不到全局最优值),采用
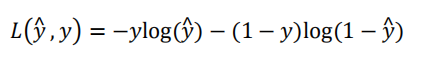
- 非凸优化
- 凸优化
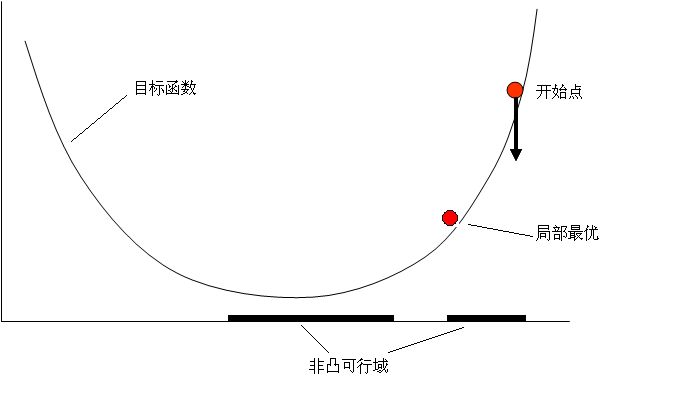
- 为什么采用此损失函数呢?

代价函数(损失函数的整体形式)就是:
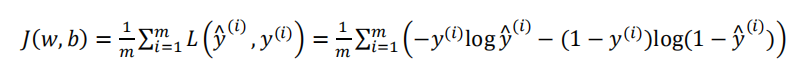
我们在训练逻辑回归模型时,就是找到合适的w和b,让代价函数J最低
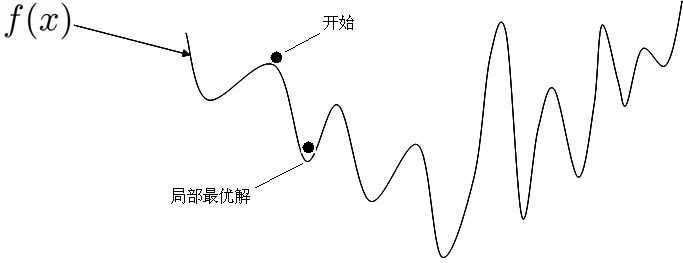
梯度下降法
目前已经选取了假设函数和代价函数
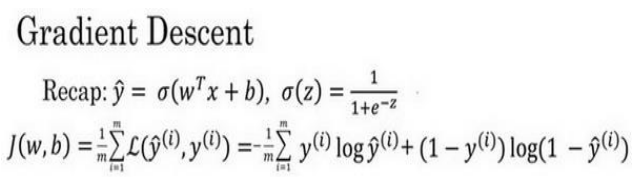
梯度下降法的形象表示
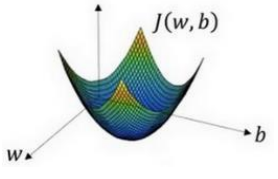
新的成本函数较使得方差形式的非凸函数成为凸函数,而后由初始点(随机初始化)开始,沿着梯度最大的方向走一定的步长,迭代此过程,最后走到全局最优点
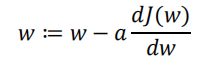
α是学习率,用来
控制步长
最后的除法公式就是一个
偏导公式
Summary Day03
今天开启了二分类这一章节,由第一节学习到了第六节,新学习到的概念有:
- 逻辑回归
- 分类与回归
- 维度
- sigmoid函数
- 假设函数
- 损失函数
- 代价函数
- 凸函数与非凸函数
- 梯度下降法
需要注意的是:
1.逻辑回归的假设函数在用于分类问题时,传统的形式往往存在值域的不匹配问题,
需要将假设函数作为sigmoid函数的自变量来解决,使函数收敛在(0,1)之间
2.特征矩阵并不是将RGB以同等形式录入,而是将每一个颜色的强度值矩阵变为
一维线性连接起来(此处存在理解错误,所以没弄明白维度)
3.?矩阵的变换导致了X输入矩阵的变化,增加了一维
4.损失函数是单个样本,代价函数是样本总体损失函数值的平均值
5.非凸函数存在局部最优解问题,由平方差的形式变换为
?(?^ , ?) = −?log(?^) − (1 − ?)log(1 − ?^)
最后
以上就是落后悟空最近收集整理的关于2.二分类模型的全部内容,更多相关2内容请搜索靠谱客的其他文章。








发表评论 取消回复