一 ,内核管理内存的方式
(1)内核把物理页作为内存管理的基本单位,内存管理单元通常以页为单位进行处理,所以,从虚拟内存角度来看,页就是最小单位。
大多数32位系统支持4kb的页,64位系统支持8kb的页。
(2)内核用这个结构体表示并管理系统中每个物理页。

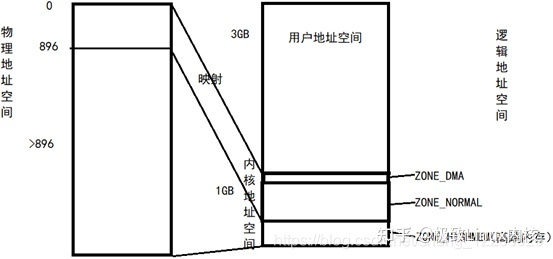
(3)由于硬件的限制,内核需要把页划分为不同的区,形成不同的内存池,根据用途进行分配。

其中ZONE_DMA 物理内存 <16MB
ZONE_NORMAL 物理内存16-896MB
ZONE_HIGHMEM 物理内存>896MB
二,内核分配和释放内存
获得页。
Struct page * alloc_pages(unsigned int gfp_mask,unsigned int order);
这个函数可以分配2的order次方个连续的物理页,并返回一个指向第一个页的page结构体的指针,如果出错,返回NULL。
如果想得到逻辑地址,使用 void *page_address(struct page *page);
返回一个指向给定物理页当前所在的逻辑地址的指针。
(2)释放页

三,Slab分配器
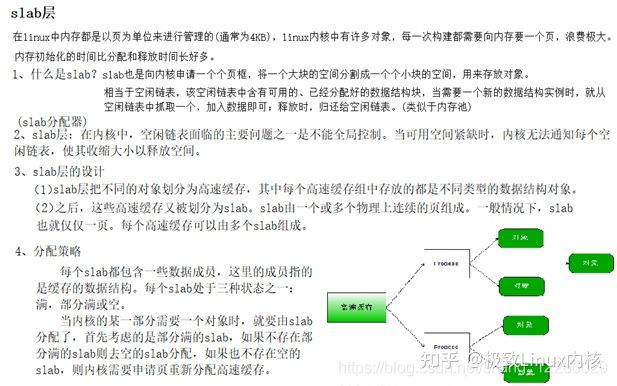
(1)什么是slab分配器
Linux内核中基于伙伴算法实现的分区页框分配器 为避免产生内部碎片
slab分配器中用到了对象这个概念,所谓对象就是内核中的数据结构以及对该数据结构进行创建和撤销的操作。它的基本思想是将内核中经常使用的对象 放到高速缓存中,并且由系统保持为初始的可利用状态。比如进程描述符,内核中会频繁对此数据进行申请和释放。当一个新进程创建时,内核会直接从slab分配器的高速缓存中获取一个已经初始化了的对象;当进程结束时,该结构所占的页框并不被释放,而是重新返回slab分配器中。如果没有基于对象的slab分 配器,内核将花费更多的时间去分配、初始化以及释放一个对象。
(2)slab分配器作用:
将频繁使用的对象缓存起来,减少分配、初始化和释放对象的时间开销。
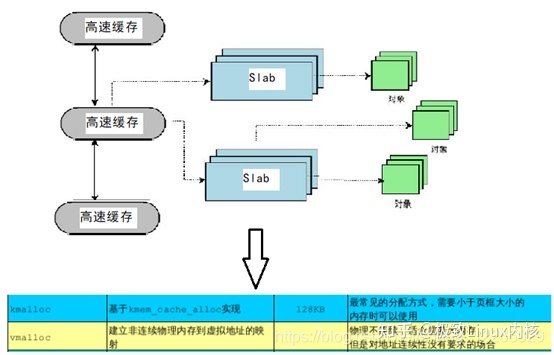
vmalloc kmalloc 基于Slab 实现
vmalloc 在ZONE_HIGHMEM区,分配大内存块,物理地址不连续,适合对地址连续无要求的场合 因为虚拟地址更新页表,故效率较低
kmalloc 通常在ZONE_NORMOL 适合分配内存大小小于页框的场合 不会触发页表更新,分配效率高
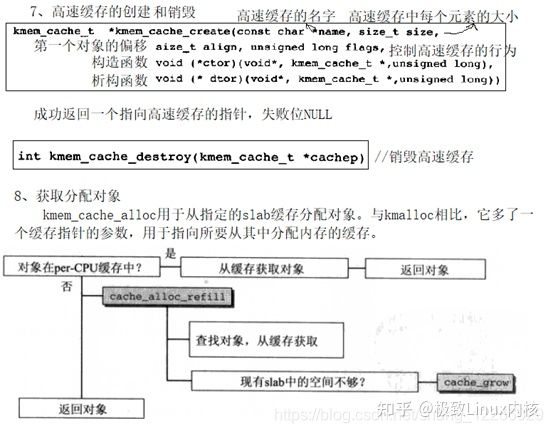
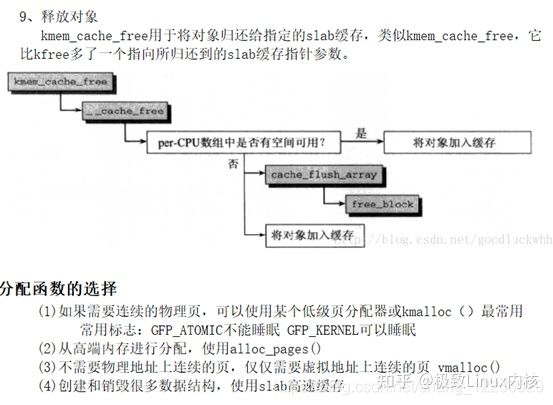
(3)slab层

在栈上的静态分配
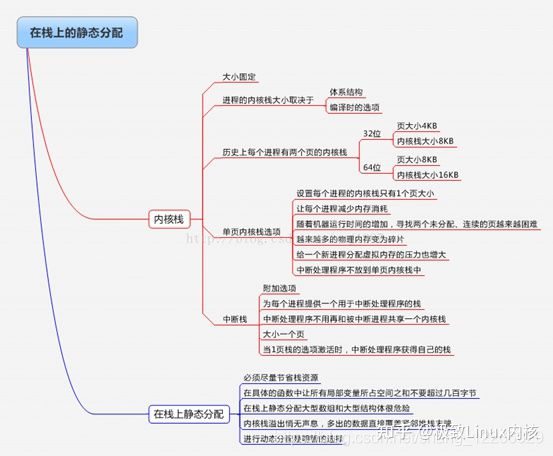
在任何情况下,无限制的递归和alloca()是不允许的。
任意函数必须尽量节省栈资源,方法就是所有函数让局部变量所占空间之和不要超过几百字节。如果栈溢出,可能会对连着内核栈末端的thread_info结构产生很大的影响。
进行动态分配是明智的选择。
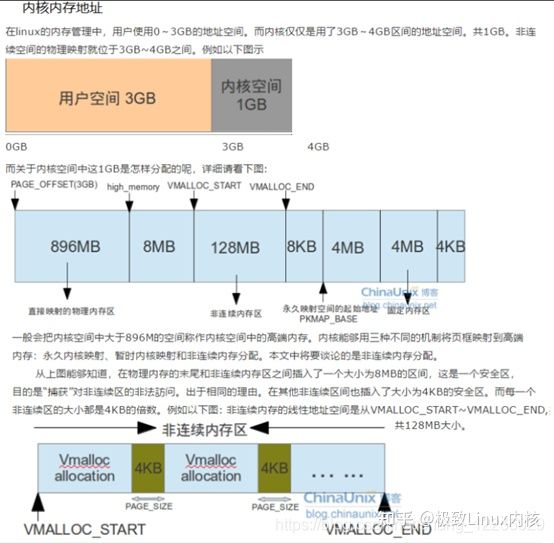
高端内存的映射
什么是高端内存?Linux把内存地址空间分为三部分:ZONE_DMA ZONE_NORMAL ZONE_HIGHMEM 高端内存的地址范围是0xf80000000~0xffffffff,他不会永久的自动的映射到内核地址空间。
永久映射
这个函数在高端内存或低端内存上都可以使用。
如果page结构对应的是低端内存中的一页,返回的是虚拟地址;如果是高端内存,则会建立一个永久映射。
注意:永久映射的数量是有限的,当不需要的时候,需要归还,应解除映射。

临时映射
当必须创建一个映射而当前的上下文不能睡眠时,内核提供临时映射。有一组保留的映射,他们可以存放新创建的临时映射。
注意:临时映射可以用在不能睡眠的地方。

参数type时面熟临时映射的目的

这个函数不会阻塞,因此可以用在中断上下文和其他不能重新调度的地方。还可以禁止内存抢占。

临时内核映射和永久内核映射相比,其最大的特点就是不会阻塞请求映射页框的进程,因此临时内核映射请求可以发生在中断和可延迟函数中。
临时映射可以在不能睡眠的地方,如中断处理程序中,因为获取映射时,绝对不会阻塞。它也禁止内核抢占,因为映射对每个处理器都是唯一的。
四,每个CPU的分配
(1)支持SMP的现代操作系统使用每个CPU上的数据,对于给定的处理器其数据是唯一的。一般来说,每个CPU的数据存放在一个数组中。数组中的每一项对应着系统上一个存在的处理器。当前处理器号确定这个数据的当前元素。像如下声明数据:
上面的代码并没有出现锁,这是因为所操作的数据对当前处理器来说是惟一的。除了当前处理器之外,没有其他处理器可以接触到这个数据,不存在并发访问的问题。
因此,内核抢占成为了唯一要关注的问题:
(2)内核抢占
1.如果你的代码被其他处理器抢占并重新调度,那么这时cpu变量就会无效,因为它指向的是错误的处理器(通常,代码获得当前处理器后是不可以睡眠的)。
2.如果别的任务抢占了你的代码,那么有可能在同一处理器上发生并发访问My_percup的情况,显然这处于一种竞争状况。
不必惊慌,应为在获取当前处理器号,即调用get_cpu()时,就已经禁止了内核抢占。相应的smp_processor_id()在调用put_cpu()时又会重新激活当前处理器号。注意,如果你使用对smp_processor_id()的调用来获得当前处理器号,只要你总是用上述方法来保护数据安全,那么内核抢占并不需要你自己去禁止。
新的每个CPU接口
2.6内核为了方便创建和操作每个CPU数据,从而引进了新的操作接口,称作percpu。该接口归纳了前面所述的操作行为,并使每个CPU数据的创建和操作得以简化。
编译时的每个CPU数据
DEFINE_PRE_CPU(type, name);
这个语句为系统中的每一个处理器都创建了一个内型为type,名字为name的变量实例,如果你需要在别处声明变量,以防范编译时警告,那么下面的宏将是你的好帮手:
DECLARE_PER_CPU(type, name);
你可以利用get_cpu_var()和put_cpu_var()例程操作变量。调用get_cpu_var()返回当前处理器上的指定变量。同时它将禁止抢占,另一方面put_cpu_var()将相应的重新激活抢占。
使用此方法要格外小心,因为per_cpu()函数既不会禁止内核抢占,也不会提供任何形式的锁保护。如果一些处理器可以接触到其他处理器的数据。那么就必须要给数据上锁。此外,如果你需要从模块中访问每个CPU数据,或者如果你需要动态创建这些数据。
(3)运行时的每个CPU数据
内核实现每个CPU数据的动态分配方法类似于kmalloc()。该例程为系统上的每个处理器创建所需内存的实例:
宏alloc_perpu()给系统中的每个处理器分配一个指定类型对象的实例。它其实是宏__alloc_percpu的一个封装,这个原始的宏接收的参数有两个:一个是要分配的实际字节数,一个是分配时要按多少字节对齐。而封装后的_alloc_percpu()按照单字节对齐——按照给定类型的自然边界对齐,比如:
_alignof_结构是gcc的一个功能,它会返回指定的类型或lvalue所需的对齐节数。它的语意和sizeof一样,比如:
_alignof_(unsigned long)
在x86体系中将返回4。如果指定一个lvalud,那么将返回lvalud的最大对齐字节数。比如一个结构中的lvalue相比结构外的lvalue可能有更大的对齐字节数需求,这是结构本身的对齐要求的缘故。
调用函数 free_percpu() 将释放所有处理器上指定的每个CPU数据。
无论是alloc_percpu()还是__alloc_percpu都会返回一个指针,用来间接引用动态创建的每个CPU数据,内核提供了两个宏来利用指针获取每个CPU数据:
get_cpu_ptr()宏返回了一个指向当前处理器数据的特殊实例。它同时会禁止内核抢占,而在put_cpu_ptr()宏中会重新激活内核抢占。
(4)使用每个CPU数据的原因
使用每个CPU数据好处如下:
1.减少了数据锁定,因为按照每个处理器访问每个CPU数据的逻辑,你可以不在需要任何锁。
2.可以大大的减少缓存失效,失效发生在处理器视图使他们的缓存保持同步时,如果一个处理器操作某个数据,而该数据又存放在其他处理器缓存中,那么存放该数据的那个处理器必须清理或刷新它自己的缓存。持续不断的缓存失效称为缓存抖动,这样对系统性能影响颇大。
它唯一的安全要求就是禁止内核抢占。
以上内容是小组一同完成的。
博主已将这些基础知识汇总成了一个视频版的C语言基础知识大全加博主的QQ号1625358265 备注【GGG】不备注不通过哦 加上QQ后即可获取!更多C/C++(Linux内核)入门、进阶教程也可以添加博主QQ 号备注【GGG】即可获取!!!
学习直通车
资料免费领

最后
以上就是羞涩抽屉最近收集整理的关于Linux内核中的内存管理(图例解析)的全部内容,更多相关Linux内核中内容请搜索靠谱客的其他文章。








发表评论 取消回复