系统环境
Linux Ubuntu 16.04
jdk-7u75-linux-x64
hive-1.1.0-cdh5.4.5
hadoop-2.6.0-cdh5.4.5
mysql-5.7.24
相关知识
Hive查询操作过程严格遵守Hadoop MapReduce的作业执行模型,Hive将用户的HQL语句通过解释器转换为MapReduce作业提交到Hadoop集群上,Hadoop监控作业执行过程,然后返回作业执行结果给用户。
如下图Hive执行流程大致步骤为:
(1)用户提交查询等任务给Driver。
(2)编译器获得该用户的任务Plan。
(3)编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
(4)编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce),最后选择最佳的策略。
(5)将最终的计划提交给Driver。
(6)Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作。
(7)获取执行的结果。
(8)取得并返回执行结果。
Hive的入口是Driver,执行的SQL语句首先提交到Driver驱动,然后调用Compiler解释驱动,最终解释成MapReduce任务执行,最后将结果返回。
(编译流程)
一条SQL进入Hive经过上述过程,使得一个编译过程变成了一个作业。
(1)首先,Driver会输入一个字符串SQL,然后经过Parser变成AST,这个变成AST的过程是通过Antlr来完成的,也就是Anltr根据语法文件来将SQL变成AST。
(2)AST进入Semantic Analyzer(核心)变成QB(QueryBlock)。一个最简的查询块,通常来讲,一个From子句会生成一个QB,生成QB是一个递归过程,生成的QB经过GenLogical Plan过程,变成了一个有向无环图。
(3)OP DAG经过逻辑优化器,对这个图上的边或者结点进行调整,顺序修订,变成了一个优化后的有向无环图。这些优化过程包括谓词下推(Predicate Push Down),分区剪裁(Partition Prunner),关联排序(Join Reorder)等等。
(4)经过了逻辑优化,这个有向无环图还要能够执行。所以有了生成物理执行计划的过程。Gen Tasks。Hive的作法通常是碰到需要分发的地方,切上一刀,生成一道MapReduce作业。如Group By切一刀,Join切一刀,Distribute By切一刀,Distinct切一刀。这么很多刀砍下去之后,这个逻辑有向无环图就被切成了很多个子图,每个子图构成一个结点。这些结点又连成了一个执行计划图,也就是Task Tree。
(5)对于Task Tree的优化,比如基于输入选择执行路径,增加备份作业等。可以由Physical Optimizer来完成。经过Physical Optimizer,每一个结点就是一个MapReduce作业或者本地作业,就可以执行了。
这就是一个SQL如何变成MapReduce作业的过程。
任务内容
1.掌握Hive的普通查询、别名查询、限定查询与多表联合查询。
2.掌握Hive的多表插入、多目录输出以及使用Shell脚本查看Hive中的表。
任务步骤
1.首先检查Hadoop相关进程,是否已经启动。若未启动,切换到/apps/hadoop/sbin目录下,启动Hadoop。
jps
cd /apps/hadoop/sbin
./start-all.sh
然后执行启动以下命令,开启Mysql库,用于存放Hive的元数据。(密码:zhangyu)
sudo service mysql start
启动Mysql后,在终端命令行界面,直接输入Hive命令,启动Hive命令行。
hive
2.打开一个新的命令行,切换到/data/hive3目录下,如不存在需提前创建hive3文件夹。
mkdir -p /data/hive3
cd /data/hive3
使用wget命令,下载http://192.168.1.100:60000/allfiles/hive3中的文件。
wget http://192.168.1.100:60000/allfiles/hive3/buyer_log
wget http://192.168.1.100:60000/allfiles/hive3/buyer_favorite
3.在hive命令行,创建买家行为日志表,名为buyer_log,包含ID(id) 、用户ID(buyer_id) 、时间(dt) 、 地点(ip) 、操作类型(opt_type)5个字段,字符类型为string,以’t’为分隔符。
create table buyer_log(id string,buyer_id string,dt string,ip string,opt_type string)
row format delimited fields terminated by 't' stored as textfile;

创建买家收藏表,名为buyer_favorite,用户ID(buyer_id) 、商品ID(goods_id)、时间(dt)3个字段,字符类型为string,以’t’为分隔符。
create table buyer_favorite(buyer_id string,goods_id string,dt string)
row format delimited fields terminated by 't' stored as textfile;
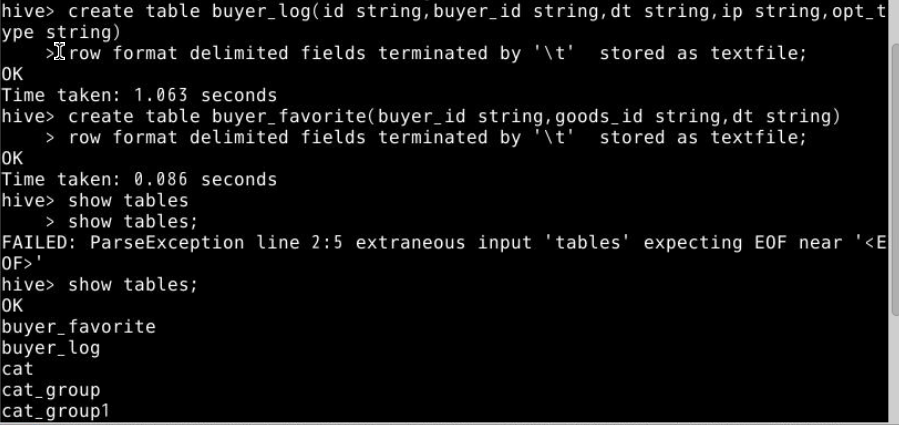
4.将本地/data/hive3/下的表buyer_log中数据导入到Hive中的buyer_log表中,表buyer_favorite中数据导入到Hive中的buyer_favorite表中。
load data local inpath '/data/hive3/buyer_log' into table buyer_log;
load data local inpath '/data/hive3/buyer_favorite' into table buyer_favorite;
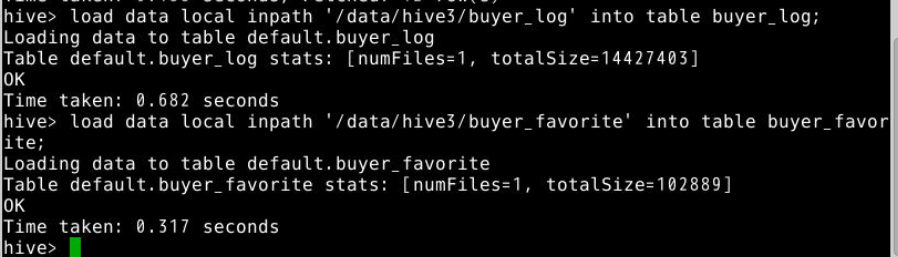
5.普通查询,例如查询buyer_log表中全部字段,数据量大时应避免查询全部数据。(limit 10为限制查询10条数据)
select * from buyer_log limit 10;
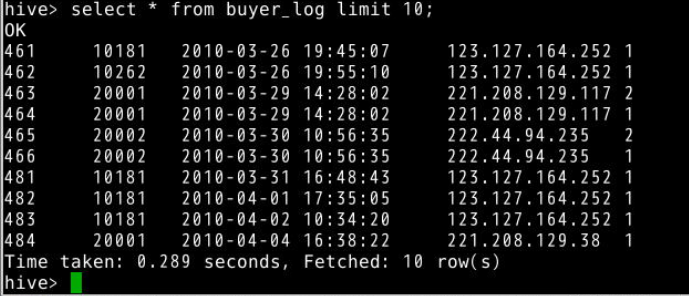
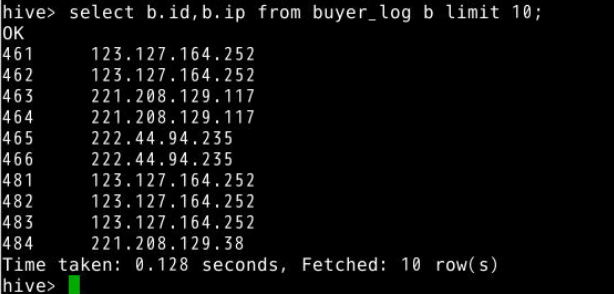
6.别名查询,例如查询表buyer_log中id和ip字段,当多表连接字段较多时,常常使用别名。(limit 10为限制查询10条数据)
select b.id,b.ip from buyer_log b limit 10;
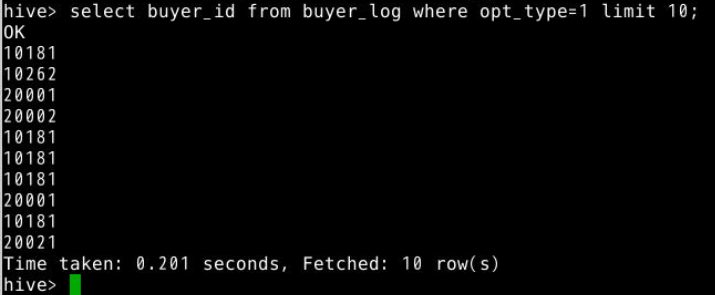
7.限定查询(where),例如查询buyer_log表中opt_type=1的用户ID(buyer_id)。(limit 10为限制查询10条数据)
select buyer_id from buyer_log where opt_type=1 limit 10;
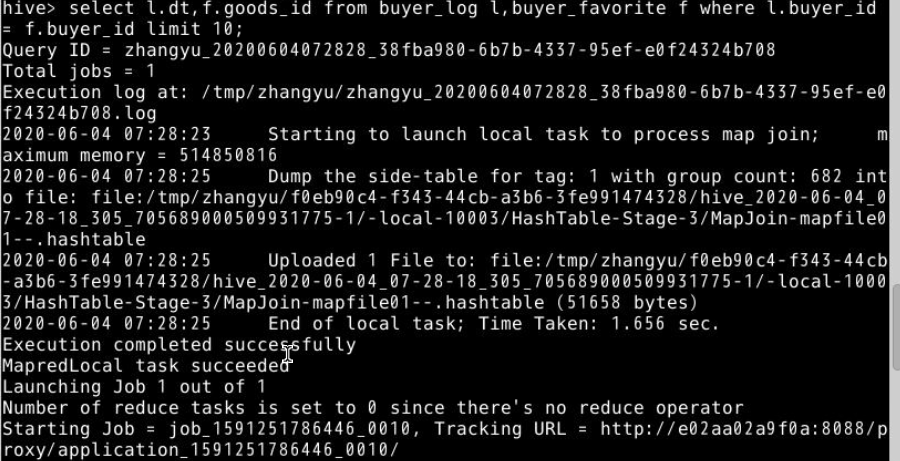
8.两表或多表联合查询,例如通过用户ID(buyer_id)连接表buyer_log和表buyer_favorite,查询表buyer_log的dt字段和表buyer_favorite的goods_id字段,多表联合查询可以按需求查询多个表中不同字段,生产中常用limit 10为限制查询10条数据。
select l.dt,f.goods_id from buyer_log l,buyer_favorite f where l.buyer_id = f.buyer_id limit 10;
9.多表插入,多表插入指的是在同一条语句中,把读取的同一份数据插入到不同的表中。只需要扫描一遍数据即可完成所有表的插入操作, 效率很高。
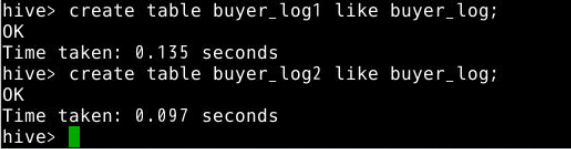
例:我们使用买家行为日志buyer_log表作为插入表,创建buyer_log1和buyer_log2两表作为被插入表。
创建buyer_log1和buyer_log2。
create table buyer_log1 like buyer_log;
create table buyer_log2 like buyer_log;
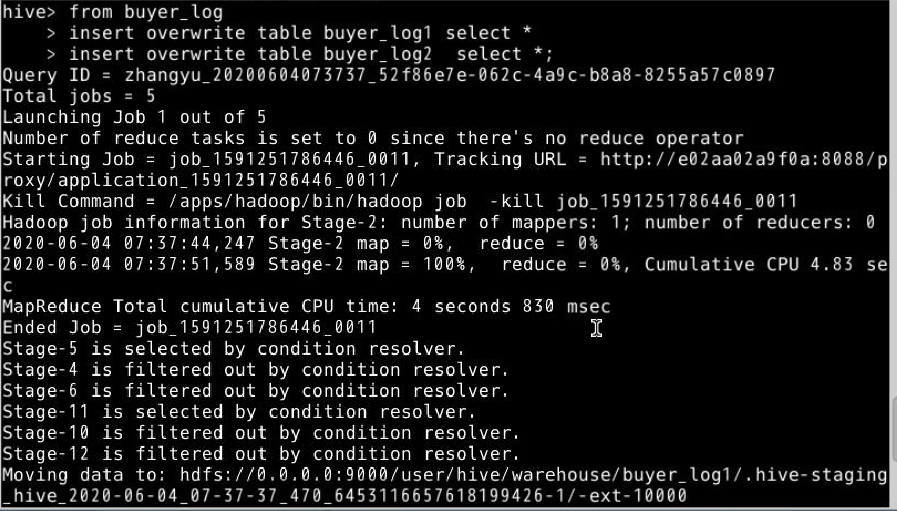
10.将buyer_log表中数据插入到buyer_log1和buyer_log2。
from buyer_log
insert overwrite table buyer_log1 select *
insert overwrite table buyer_log2 select *;
11.多目录输出文件,将同一文件输出到本地不同文件夹中,提高效率,可以避免重复操作from ,将买家行为日志buyer_log表导入到本地‘/data/hive3/out’和‘data/hive3/out1’中
from buyer_log
insert overwrite local directory '/data/hive3/out' select *
insert overwrite local directory '/data/hive3/out1' select *;
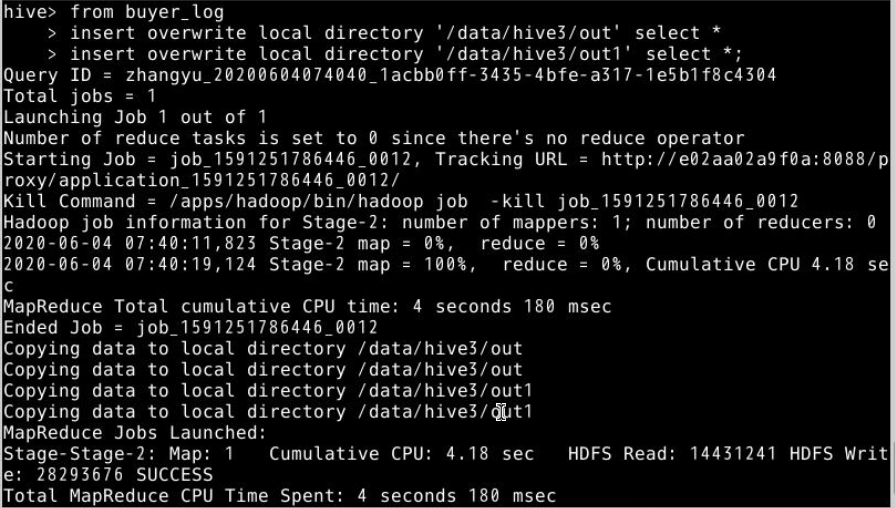
在本地切换到/data/hive3中,查询输出文件。
cd /data/hive3
ls out
ls out1
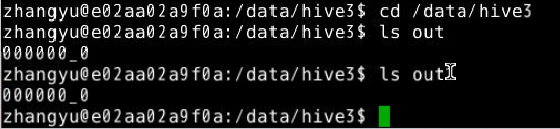
12.使用shell脚本调用Hive查询语句。
切换目录到本地目录’/data/hive3‘下,使用vim编写一个shell脚本,名为sh1,使其功能实现查询Hive中所有表。
cd /data/hive3
vim sh1
在sh1中,输入以下脚本,并保存退出
#!/bin/bash
cd /apps/hive/bin;
hive -e 'show tables;'
13.编写完成,赋予其执行权限。
chmod +x sh1
14.执行shell脚本 。
./sh1
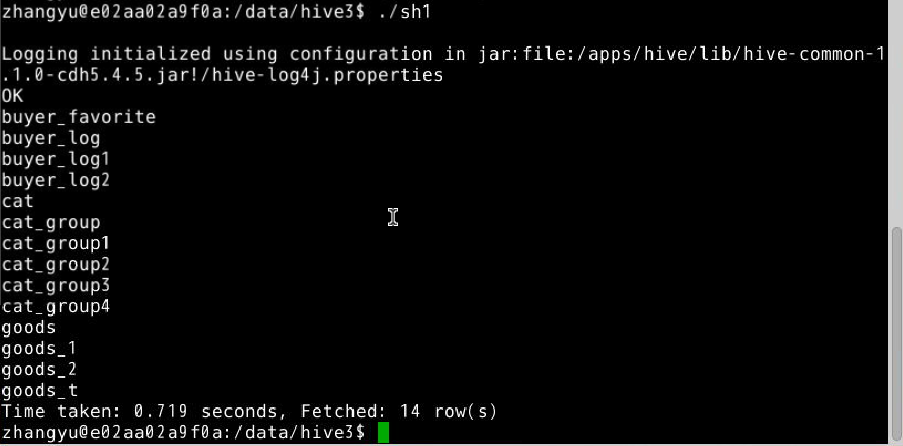
采用shell脚本来执行一些Hive查询语句可以简化很多的开发工作,可以利用Linux自身的一些工具,实现定时的job任务。
最后
以上就是饱满猫咪最近收集整理的关于Hive查询系统环境相关知识任务内容任务步骤的全部内容,更多相关Hive查询系统环境相关知识任务内容任务步骤内容请搜索靠谱客的其他文章。








发表评论 取消回复