hive的安装依附于hadoop 首先要安装hadoop
1.导入hive压缩包 并解压缩 [分发集群]
2.更改hadoop配置文件 使其能拥有权限并连接hive
配置core-site.xml配置core-site.xml配置core-site.xml [分发集群]
<!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.atguigu.users</name>
<value>*</value>
</property>3.配置环境变量 vim /etc/profile.d/my_evn.sh ,并刷写 source /etc/profile 【分发集群】 增加
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin注意:环境变量是在root权限下的 普通用户 无权限本权限的脚本分发
建议移动到当前用户下借用sudo再进行分发配置
4.更改日志jar包文件 hive中负责日志的jar包会和hadoop的jar包冲突【不同版本,相同作用的jar包在使用时在底层代码会有不同,会冲突】
改成bak文件 文字变白 表示此文件不可执行
mv $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.bak5.初步配置完成,可以使用hive命令进行启动
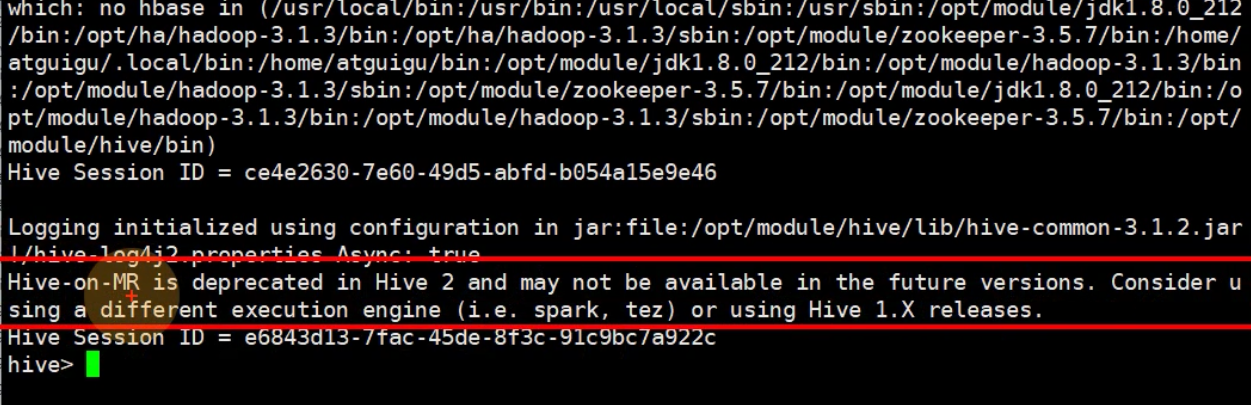 理解: 表示hive不建议mr引擎【有点慢】 建议更换引擎比如spark 建议将版本改为hive1
理解: 表示hive不建议mr引擎【有点慢】 建议更换引擎比如spark 建议将版本改为hive1
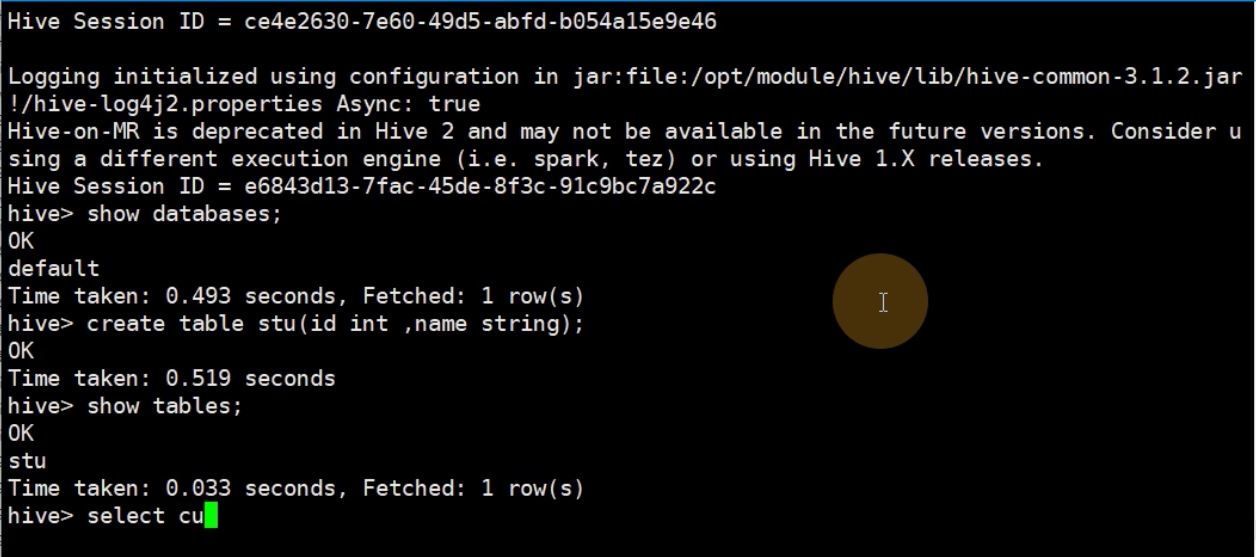
默认使用库default
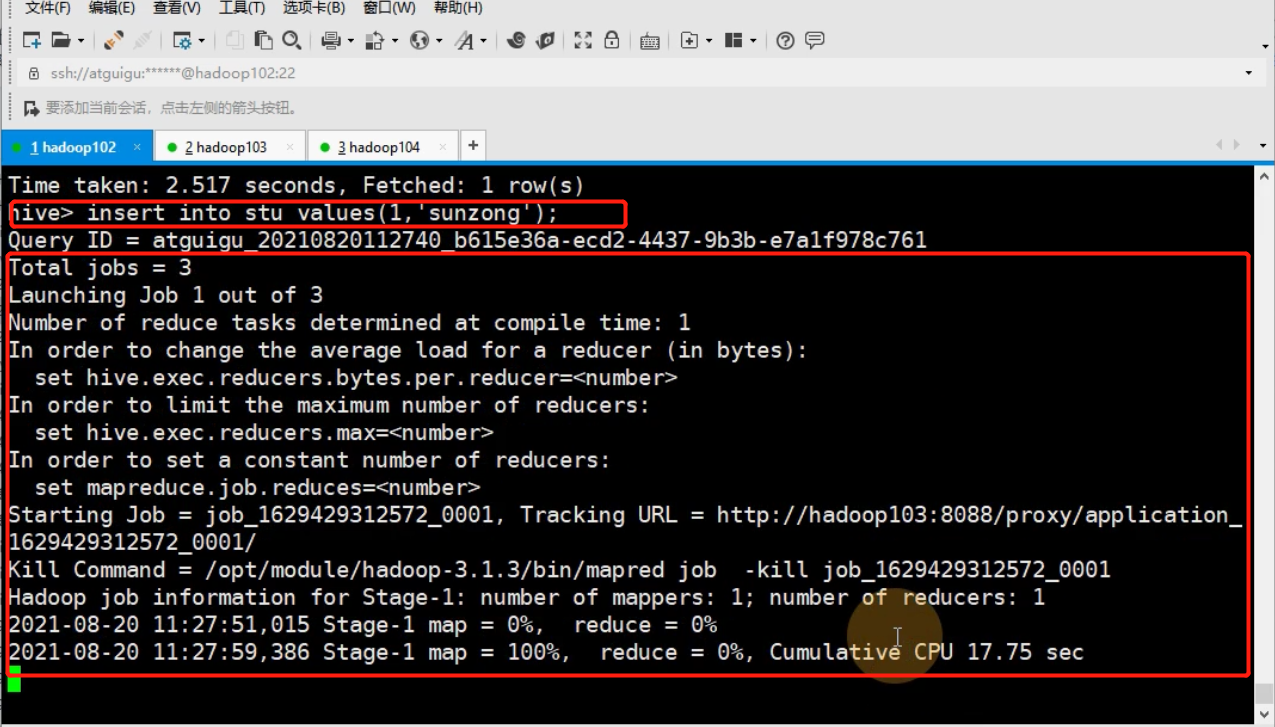
插入数据默认走mr [比较慢]
使用存储元数据的数据库是derby 不支持并发
最后
以上就是飘逸荷花最近收集整理的关于Hive的安装的全部内容,更多相关Hive内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复