队列你真的懂了吗?队列用来干嘛?什么场景用队列有优势?
一、循环队列
颜色说明如下:

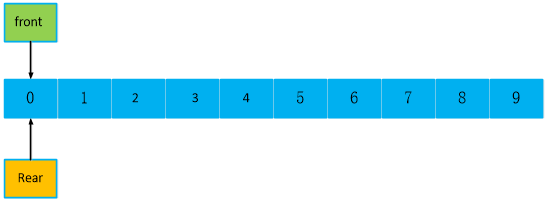
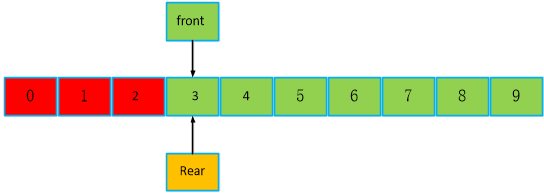
假设有一个空队列,长度为len = 10 fornt对头,rear队尾初始化时,指向0位置。
注意,这里指向可不是指针的意思,就是front = =rear == 0。
向队列写入1个数据,rear队尾向后移动一个位置,此时,front == 0,rear = rear + 1,也就是 rear == 1。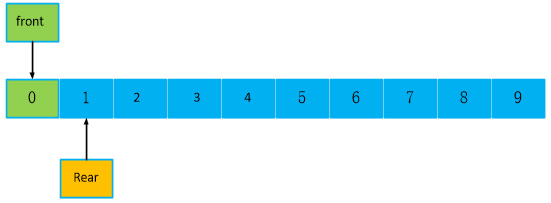
继续向队列写入9个数据,rear队尾向后移动一个位置,此时,front = 0,rear = 9。如果是传统队列,此时是不能再写入数据了,rear 不能等于10。
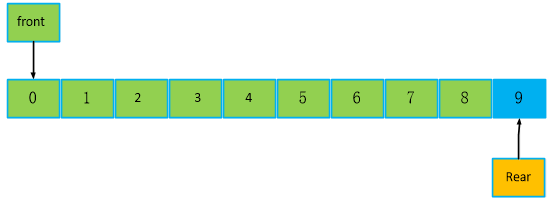
队列里有9个数据,此时为非空,读走5个数据,此时,front == 5,rear == 9, rear - front == 4。如果是顺序队列,再写数据,此时是从5位置写入数据,前面5个就浪费了。
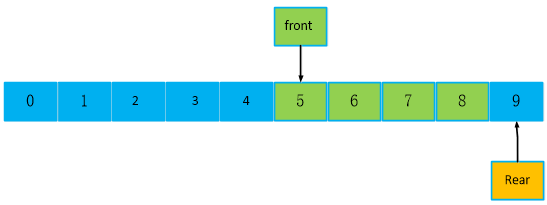
队列里有4个数据,此时为非空,再写入1个数据,此时,front == 5,rear =rear + 1, rear == 0。如果是传统顺序队列,
rear - front 是 < 0,不可操作的,不允许再写入,但是本文研究设计的循环队列,是可以写入的,如下。
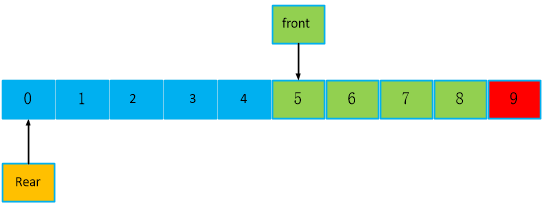
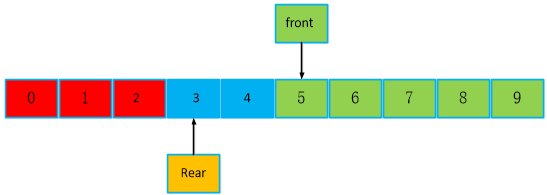
再继续看下面。继续写入3个数据,红色为队列满之后写入的数据,此时,front== 5不变,rear == 3,没啥问题啊,为啥前人,会发明顺序队列,是因为不可判断队列数据个数吗,rear - front < 0,是不可以判断的,但是,可不可以增加一种判读机制呢,引入一个count,记录数据个数,每次增加一个数,就加1,读走一个数,就减1。上面步骤最开始是写1个数,count == 1,再写入8个数,就是是9个数,再读走5个数,就还剩4个数,再写入一个数,就是5个,最后,下面步骤,写入3个数,就是8个数,下图,红色和绿色都是代表有数据,刚好是8个数。
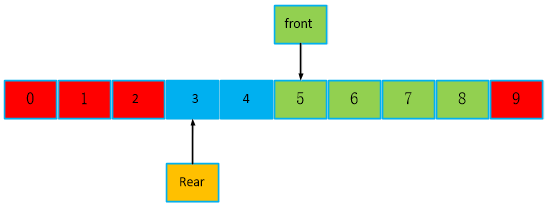
再继续分析如下,读走一个数,front队头向后移动一个位置,还剩7个数。
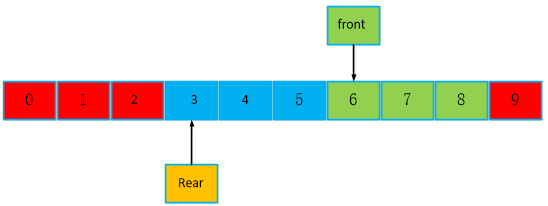
再继续读走3个数到最后一个位置,此时,还剩4个数,继续读,会怎么样?
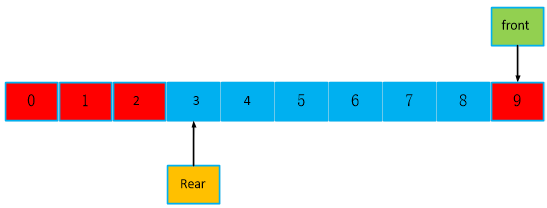
继续读,如下,队头又回到队尾前面了,此时count == 2。front == 0,rear == 3。
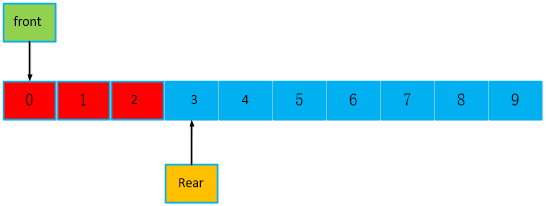
读走最后两个,此时,front == rear == 3,空队列。
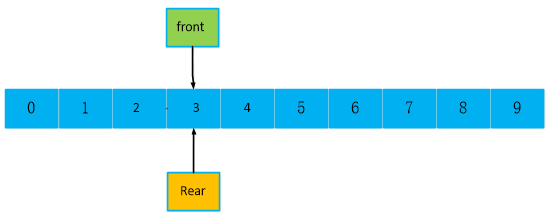
再来分析,和我们最开始的队列,front == rear == 0,有啥区别?也是空对列,好像是 front == rear,,只是位置在0和3,但是都是队头队尾相等,没有数据的空队列。,此时可以根据front == rear来判断空队列下结论吗?
继续看,如果把队列都写满,此时,front == rear,为满队列,和上面的空队列一样的情况,所以,不能只靠这个条件进行判读,我们可以加入一个判断条件,count
如果count == 0,且front == rear,则为空队列,如果count != 0,front == rear,为满队列。
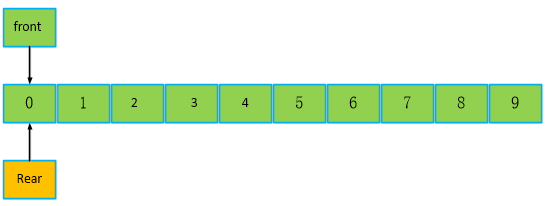
到这里结束了?但是有个毛病,满之后,再继续写,会怎么样?如下图,再写入3个数据,原来是10个,加3个,本来是10+ 3 == 13,现在是把10个满队列的数,前面3个覆盖掉,那不是丢失数据了,就算不考虑丢失的问题,此时要去读取数据时,front == 0,读第0个数,现在读出来的是第11个位置数据,也就是第11个位置的数,而不是被覆盖之前的第0个位置数据,这显然不符合先进先出的思想,因为最现在被覆盖后,最新的数据应该是从第3个数据开始的后面一段数据。
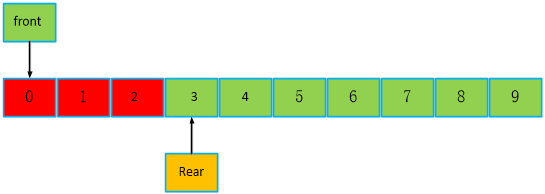
所以,我们要做一个改进,当队列已满时,不再允许写入数据,只有再次为空时,才允许写入数据。
如果我们希望,可以覆盖,真正实现循环,就需要做如下改进,把队头移动到队尾,front == rear,不关心数据丢失的问题,只希望数据是最新的数据。
如下,验证设计的正确性,读取2个数据,此时front = front + 2,front == 5。完全正确,为了验证安全性,可以写代码
增加长度,和轮询次数,本文没有验证过,只是理论研究。
**总结;
1、传统的循环队列其实没有实现真正的循环队列,只是队头队尾可以循环移动,此时可以只根据
front == rear 来判断空。
front== ( rear + 1)% len 来判断满队列。
但是本文真正实现了数据循环覆盖,循环队列。列外判断机制加入了count,与别人有所区别。
1、满队列时,如果希望不覆盖前面的数据,防止数据丢失,可以加判断,满队列将不被允许写入,直到不满。
2、满队列时,如果希望,实现循环写入,将可以通过移动队头到队尾,将数据覆盖。
以上设计,各有各的用处场景,不能说哪个好,场景不同,就要选用不同的方式。**
demo代码:
#include"queue_cmd.h"
PT_QUEUE_CMD QUEUE_CMD_Open(SX_S32 depth)
{
PT_QUEUE_CMD handle = (PT_QUEUE_CMD)xine_xmalloc(sizeof(T_QUEUE_CMD));
if( handle == NULL )
{
TRACE(DL_ERROR, "DL_ERRORn");
return NULL;
}
if (pthread_mutex_init( &handle->mutex, NULL ) != 0)
{
TRACE(DL_ERROR, "DL_ERRORn");
QUEUE_CMD_Close( handle );
return NULL;
}
if( pthread_cond_init(&handle->cond, NULL) != 0 )
{
TRACE(DL_ERROR, "DL_ERRORn");
QUEUE_CMD_Close( handle );
return NULL;
}
handle->ptCmd = (PT_NET_Pkt)xine_xmalloc(sizeof(T_NET_Pkt) * depth);
if( handle->ptCmd == NULL )
{
TRACE(DL_ERROR, "DL_ERRORn");
QUEUE_CMD_Close( handle );
return NULL;
}
handle->s32QueueDepth = depth;
handle->s32IndexR = 0;
handle->s32IndexW = 0;
handle->s32Count = 0;
handle->bAbortRequest = SX_FALSE;
return handle;
}
void QUEUE_CMD_Close( PT_QUEUE_CMD handle )
{
if( handle )
{
if( handle->ptCmd )
{
xine_freep( (void *)&(handle->ptCmd) );
}
pthread_mutex_destroy( &handle->mutex );
pthread_cond_destroy(&handle->cond);
xine_freep( (void *)&handle);
}
return;
}
SX_S32 QUEUE_CMD_Send( PT_QUEUE_CMD handle, PT_NET_Pkt cmd)
{
if( handle == NULL || cmd == NULL )
{
TRACE(DL_ERROR, "DL_ERRORn");
return -1;
}
pthread_mutex_lock( &(handle->mutex) );
if( (handle->s32IndexW + 1) % handle->s32QueueDepth == handle->s32IndexR) //&& (count> 0) )
{
pthread_mutex_unlock( &(handle->mutex) );
//TRACE(DL_WARNING, "queue fulln"); //tx bus_send_cmd fifo is always full in working phase
return 0;
}
PT_NET_Pkt ptCmd = handle->ptCmd + handle->s32IndexW;
#if 1
*ptCmd = *cmd;
#else
memcpy( ptCmd->szSync, cmd->szSync, sizeof(ptCmd->szSync) );
ptCmd->s8ChNo = cmd->s8ChNo;
ptCmd->s8CmdIndex = cmd->s8CmdIndex;
ptCmd->s16CmdPeriod = cmd->s16CmdPeriod;
ptCmd->s8LibIndex = cmd->s8LibIndex;
ptCmd->u8CmdLength = cmd->u8CmdLength;
ptCmd->s8CmdFormat = cmd->s8CmdFormat;
memcpy( ptCmd->szReserved1, cmd->szReserved1, sizeof(cmd->szReserved1) );
memcpy( ptCmd->szCmd, cmd->szCmd, MIN(ptCmd->u8CmdLength, sizeof(ptCmd->szCmd)) );
ptCmd->s32StatusLength = cmd->s32StatusLength;
memcpy( ptCmd->szStatus, cmd->szStatus, MIN(ptCmd->s32StatusLength, sizeof(ptCmd->szStatus)) );
ptCmd->s32LastTime = cmd->s32LastTime;
ptCmd->s32Sn = cmd->s32Sn;
ptCmd->ptBk = cmd->ptBk;
ptCmd->ptCh = cmd->ptCh;
ptCmd->ptCmd_Myself = cmd->ptCmd_Myself;
ptCmd->next = cmd->next;
#endif
handle->s32IndexW = (handle->s32IndexW+1) % handle->s32QueueDepth;
handle->s32Count++;
pthread_cond_signal( &handle->cond );
pthread_mutex_unlock( &handle->mutex );
return 1;
}
SX_S32 QUEUE_CMD_Receive(PT_QUEUE_CMD handle, PT_NET_Pkt cmd, SX_BOOL block)
{
if( handle == NULL || cmd == NULL )
{
TRACE(DL_ERROR, "DL_ERRORn");
return -1;
}
SX_S32 ret;
pthread_mutex_lock( &(handle->mutex) );
for (;;)
{
if (handle->bAbortRequest)
{
ret = -1; // 异常
break;
}
if(( handle->s32IndexW == handle->s32IndexR) //&& ( _s32Count == 0 )) //empty
{
if ( !block) // 阻塞标记,1(阻塞模式),0(非阻塞模式)
{
ret = 0; // 非阻塞模式,没东西直接返回0
break;
}
else
{
pthread_cond_wait(&handle->cond, &handle->mutex);
}
}
else
{
PT_NET_Pkt ptCmd = handle->ptCmd + handle->s32IndexR; //指针 == 队头,加索引,
#if 1
*cmd = *ptCmd;
#else
memcpy( cmd->szSync, ptCmd->szSync, sizeof(cmd->szSync) );
cmd->s8ChNo = ptCmd->s8ChNo;
cmd->s8CmdIndex = ptCmd->s8CmdIndex;
cmd->s16CmdPeriod = ptCmd->s16CmdPeriod;
cmd->s8LibIndex = ptCmd->s8LibIndex;
cmd->u8CmdLength = ptCmd->u8CmdLength;
cmd->s8CmdFormat = ptCmd->s8CmdFormat;
memcpy( cmd->szReserved1, ptCmd->szReserved1, sizeof(ptCmd->szReserved1) );
memcpy( cmd->szCmd, ptCmd->szCmd, MIN(cmd->u8CmdLength, sizeof(cmd->szCmd)) );
cmd->s32StatusLength = ptCmd->s32StatusLength;
memcpy( cmd->szStatus, ptCmd->szStatus, MIN(cmd->s32StatusLength, sizeof(cmd->szStatus)) );
cmd->s32LastTime = ptCmd->s32LastTime;
cmd->s32Sn = ptCmd->s32Sn;
cmd->ptBk = ptCmd->ptBk;
cmd->ptCh = ptCmd->ptCh;
cmd->ptCmd_Myself = ptCmd->ptCmd_Myself;
cmd->next = ptCmd->next;
#endif
handle->s32IndexR = (handle->s32IndexR + 1) % handle->s32QueueDepth;
if( handle->s32Count > 0 )
{
handle->s32Count--;
}
ret = 1;
break;
}
}
pthread_mutex_unlock( &(handle->mutex) );
return ret;
}
void QUEUE_CMD_Abort(PT_QUEUE_CMD handle)
{
if( handle == NULL )
{
TRACE(DL_ERROR, "DL_ERRORn");
return;
}
pthread_mutex_lock( &(handle->mutex) );
handle->bAbortRequest = SX_TRUE;
pthread_cond_signal(&handle->cond);
pthread_mutex_unlock( &handle->mutex);
return;
}
void QUEUE_CMD_Flush(PT_QUEUE_CMD handle)
{
if( handle == NULL )
{
TRACE(DL_ERROR, "DL_ERRORn");
return;
}
pthread_mutex_lock( &(handle->mutex) );
handle->s32IndexR = 0;
handle->s32IndexW = 0;
handle->s32Count = 0;
handle->bAbortRequest = 0;
pthread_mutex_unlock( &(handle->mutex) );
return;
}
//queue_cmd.h
#ifndef QUEUE_CMD_H_
#define QUEUE_CMD_H_
#include "global.h"
#pragma pack(1)
typedef struct UART_Pkt
{
SX_U16 u16SyncHead; //EB90/AABB
SX_U8 u8Cmd;
SX_U8 data[120]; //
} T_UART_Pkt, *PT_UART_Pkt;
#pragma pack()
#pragma pack(1)
typedef struct NET_Pkt
{
//net head
SX_U8 u8Ch;
SX_U8 u8Reserved1;
SX_U8 u8Reserved2;
SX_U8 u8Reserved3;
SX_U32 u32TimeStamp;
//uart pkt
T_UART_Pkt tUartPkt;
} T_NET_Pkt, *PT_NET_Pkt;
#pragma pack()
typedef struct QUEUE_CMD{
PT_NET_Pkt ptCmd;
SX_S32 s32QueueDepth;
SX_S32 s32IndexR;
SX_S32 s32IndexW;
SX_S32 s32Count;
SX_BOOL bAbortRequest;
pthread_mutex_t mutex;
pthread_cond_t cond;
}T_QUEUE_CMD, *PT_QUEUE_CMD;
extern PT_QUEUE_CMD QUEUE_CMD_Open( SX_S32 depth );
extern void QUEUE_CMD_Close( PT_QUEUE_CMD handle );
extern SX_S32 QUEUE_CMD_Receive(PT_QUEUE_CMD handle, PT_NET_Pkt cmd, SX_BOOL block);
extern SX_S32 QUEUE_CMD_Send( PT_QUEUE_CMD handle, PT_NET_Pkt cmd);
extern void QUEUE_CMD_Abort( PT_QUEUE_CMD handle );
extern void QUEUE_CMD_Flush( PT_QUEUE_CMD handle );
#endif /* QUEUE_CMD_H_ */
QUEUE_Frame_Open(100);
//下面是读写对列的操作,当网络端有数据发过来时,写对列,并读队列,例外数据类型可不是int一个字节
//太low了,我是结构体套结构体的类型,把这个结构体理解成一个数据类型,使用指针指定的方式赋值,
SX_S32 Frame_Receiver_Rcv(PT_Receiver handle, void *buf, SX_S32 timeoutMs )
{
if( handle == NULL )
{
TRACE(DL_ERROR, "DL_ERRORn");
return 0;
}
SX_U8 *pDst = NULL;
SX_S32 ret, sret, retval;
SX_S64 max_fd;
fd_set readfds;
struct timeval tv;
int i = 0;
FD_ZERO(&readfds);
FD_SET( handle->sockfd, &readfds );
max_fd = handle->sockfd;
tv.tv_sec = timeoutMs/1000;
tv.tv_usec = (timeoutMs%1000)*1000;
retval = select( max_fd + 1, &readfds, NULL, NULL, &tv );
if ( retval > 0 )
{
if( buf ){
sret = recvfrom( handle->sockfd, (SX_S8 *)buf, UDP_MAX_LEN, 0, (struct sockaddr *)&(handle->cliaddr), &(handle->cliaddr_len) );
}
else{
sret = recvfrom( handle->sockfd, handle->pszRecvBuf, UDP_MAX_LEN, 0, (struct sockaddr *)&(handle->cliaddr), &(handle->cliaddr_len) );
handle->s32RecvLen = sret;
}
if ( sret > 0 )
{
ret = sret;
pDst = (SX_U8 *)&handle->FrameSendQueue.data;
memcpy( (SX_S8 *)pDst, (SX_S8 *)buf,sret);
//printf("+ recvfrom %ld +rn",sret);
if(handle->ptFrameQueue == NULL || &(handle->FrameSendQueue) == NULL)
return -1;
QUEUE_CMD_Send(handle->ptFrameQueue,&(handle->FrameSendQueue));
//tset
QUEUE_CMD_Receive(handle->ptFrameQueue,&(handle->FrameRcvQueue),1);
for(i = 0; i< sret;i++)
printf("%x",handle->FrameRcvQueue.data[i]);
printf("rn");
}
else
{
ret = 0; // no data;
}
}
else if ( retval == 0 )
{
// timeout
ret = 0;
}
else
{
// error
ret = -1;
}
return ret;
}
上面的例程,数据是不允许被覆盖的,因为本例程的数据不能被丢失,所以是按传统的写法,只移动队尾队头,实现传统循环对列。
例外判读非空,非满,也是按传统没有加入count机制,在研究了别人的写法,发现确实是多此一举。
如果要按本文上面研究,实现数据循环可覆盖的,也就是写满后,允许写入数据,可以自己改下,在判断满队列时,增加,队头 == 队尾的操作。
说明:
r + 1和w+ 1,是因为最后一个位置是len -1 ,如10个,队尾只能最大到9,
如果满队列再写入, 此时队尾位置是(9 + 1)%10 == 0,也就是0位置。
队列,在多线程通信时,是很有用的,涉及互斥,竞争,加入条件变量来约束,例外,本文例程,不是写入单个数据,而是通过指针,队头的指针,加索引,也就是队尾的索引值,每次读写取最后一个队尾的地址,指向一段存有数据的内存,实现数据的写入,读取,传统的写法是,是将所有数据复制写入,这种写法太low了,当有大数据了,很影响读写速率。
最后
以上就是呆萌手套最近收集整理的关于数据结构之.队列,循环队列,链式队列(一)的全部内容,更多相关数据结构之内容请搜索靠谱客的其他文章。








发表评论 取消回复