真是“千呼万唤使出来”,NameNode结点出现真的不容易啊!!!
搞了两天,终于出现了,可开心了,以图为鉴
第一天下载了centos7,并安装了一下
准备材料 jdk1.8和hadoop2.7
在usr目录下新建apps和data文件夹
data文件夹用于存放压缩包

apps文件夹用于安装文件

详细步骤:
第一步:确定虚拟机的IP地址(命令ipconfig),设置IP地址与主机的映射关系
主机名可以修改的
vim /etc/hosts
第二步:关闭防火墙并查看防火墙的状态
systemctl stop firewalld.service #关闭防火墙
firewall-cmd --state #查看防火墙状态第三步:配置java环境
可参考https://blog.csdn.net/lylg_ban/article/details/109676369?spm=1001.2014.3001.5501 不在赘述
第四步:解压hadoop文件,进入/etc/hadoop,修改hadoop-env.sh,导入JAVA_HOME的路径
第五步:修改四个配置文件
core-site.xml
<!--指定namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!--用来指定使用hadoop时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/apps/hadoop-2.7.0/data</value>
</property>
hdfs-site.xml
<!--指定hdfs保存数据的副本数量-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>mapred-site.xml
<!--告诉hadoop以后MR(Map/Reduce)运行在YARN上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
第六步:修改、etc/profile 导入hadoop路径,之后记得source /etc/profile(至此已快成功)
#set java_home
export JAVA_HOME=/usr/apps/jdk1.8.0_281
export PATH=$PATH:$JAVA_HOME/bin
#set hadoop_home
export HADOOP_HOME=/usr/apps/hadoop-2.7.0
export PATH=$PATH:$HADOOP_HOME/bin
第七步:切换到hadoop主目录,格式化namenode
[root@master hadoop-2.7.0]# hadoop namenode -format
第八步:启动dfs.sh
[root@master hadoop-2.7.0]# sbin/start-dfs.sh
第九步:查看结点的启动情况
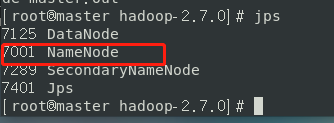
结果namenode并没有启动成功
第二天重点解决这个问题
一开始不知道查看logs文件,浪费了很长时间去搜索,然而并没有很大的作用
一般的操作:删除logs文件的内容,还有临时文件的内容,然后重新格式化,在开启dfs.sh,最后就好了,对我而言,好像并没有作用。
知道下午才发现了logs文件,并找到了错误所在
[root@master hadoop-2.7.0]# cd logs
[root@master logs]# vim hadoop-root-namenode-master.log 
错误说的很清楚,存储目录不存在或者权限不够,经查看data/dfs目录下确实没有name目录
在网上由搜索了一番,最后发现是我的hdfs-site.xml配置文件的问题
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/apps/hadoop-2.7.0/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/apps/hadoop-2.7.0/data/dfs/data</value>
</property>
在hdfs-site.xml文件中指定namenode和datanode的目录地址,否则的话,容易出现结点不启动的问题。
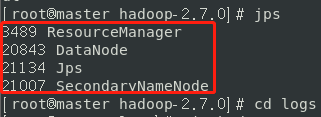
修改hdfs-site.xml文件之后,重新格式化namenode,在开启dfs.sh结果成功出现各个结点。
还有一点需要配置ssh免密登录,详情请见https://blog.csdn.net/lylg_ban/article/details/115383625
最后
以上就是醉熏帽子最近收集整理的关于Namenode:Failed to start namenode(伪分布式环境配置)准备材料 jdk1.8和hadoop2.7第一步:确定虚拟机的IP地址(命令ipconfig),设置IP地址与主机的映射关系第二步:关闭防火墙并查看防火墙的状态第三步:配置java环境第四步:解压hadoop文件,进入/etc/hadoop,修改hadoop-env.sh,导入JAVA_HOME的路径第五步:修改四个配置文件第六步:修改、etc/profile 导入hadoop路径,之后记得source /et的全部内容,更多相关Namenode:Failed内容请搜索靠谱客的其他文章。








发表评论 取消回复