前几篇博客详细解析了Spark的Job触发机制、Spark的DAGScheduler调度机制、Spark的TaskScheduler调度机制、Spark调度器的终端通信SchedulerBackend和Spark的Executor启动,在对这些源码进行分析之后,头脑中十分混乱,对于各个机制的具体执行过程不是十分了解。网上的各种分析博客也写得不是十分清晰,于是就开始了Spark任务提交流程的分析。本博客的Spark版本为2.12,是以Standalone Cluster部署模式为基础进行分析。
Spark的任务提交过程
- 1. 总览
- 2. 申请创建Driver
- 3. 创建Driver
1. 总览
本节主要从整体上对Spark提交任务的流程。spark应用程序可以以Client模式和Cluster启动,区别在于Client模式下的Driver是在执行spark-submit命令节点上启动的,而Cluster模式下是Master随机选择的一台Worker通过DriverWrapper来启动Driver的。
整个任务提交的流程大致如下所示:
- 通过spark-submit提交会调用SparkSubmit类,SparkSubmit类里通过反射调用Client,Client与Master通信来SubmitDriver,收到成功回复后退出JVM(SparkSubmit进程退出)。
- Master收到SubmitDriver后会随机选择一台能满足driver资源需求的Worker,然后与对应Worker通信发送启动driver的消息。Worker收到消息后根据driver的信息等来拼接成linux命令来启动DriverWrapper,在该类里面再启动driver,最后将Driver执行状态返回给Master。
- driver启动后接下来就是注册APP,在SparkContext启动过程中会通过创建AppClient并与Master通信要求注册application。
- Master收到消息后会去调度执行这个application,通过调度算法获取该application需要在哪些Worker上启动executor,接着与对应的Worker通信发送启动Executor的消息。
- Worker收到消息后通过拼接linux命令,启动了CoarseGrainedExecutorBackend进程,接着向Driver通信进行Executor的注册,成功注册后会在CoarseGrainedExecutorBackend中创建Executor对象。接着就是job的执行。
2. 申请创建Driver
我们通常会通过shell执行spark-submit 命令来提交spark应用程序,该脚本的运行命令如下所示:
./bin/spark-submit
--class <main-class>
--master <master-url>
--deploy-mode <deploy-mode>
--conf <key>=<value>
... # other options
<application-jar>
[application-arguments]
一些常用的选项是:
–class:应用程序的入口点,main函数所在的类(例如org.apache.spark.examples.SparkPi)
–master:群集的主网址(例如spark://23.195.26.187:7077)
–deploy-mode:是否将驱动程序部署在工作节点(cluster)上,或作为外部客户机(client)本地部署(默认值:client)
–conf:Key = value格式的任意Spark配置属性。对于包含空格的值,用引号括起“key = value”(参见示例)。
application-jar:包含应用程序和所有依赖关系的捆绑jar的路径。该URL必须在集群内全局可见,例如hdfs://路径或所有节点上存在的file://路径。
application-arguments:参数传递给主类的main方法(如果有的话)常见的部署策略是从与您的工作机器物理上位于的网关机器提交应用程序(例如,独立的EC2集群中的主节点)。在此设置中,client模式是适当的。在client模式下,驱动程序直接在spark-submit过程中启动,该过程充当集群的客户端。应用程序的输入和输出连接到控制台。因此,该模式特别适用于涉及REPL(例如Spark shell)的应用。
通过查看spark-submit脚本可以发现,其实际是使用自定义的参数运行Spark中的org.apache.spark.deploy.SparkSubmit类,下面我们从SparkSubmit的main函数开始分析,其主要源代码如下所示:
override def main(args: Array[String]): Unit = {
val submit = new SparkSubmit() {
self =>..........
}
submit.doSubmit(args)
}
从代码中可以看出,其首先创建SparkSubmit类的实例,并调用doSubmit方法,传入我们设置的一些参数。doSubmit的相关代码如下所示:
def doSubmit(args: Array[String]): Unit = {
// 初始化日志(如果尚未完成。跟踪应用程序启动之前是否需要重置日志记录。
val uninitLog = initializeLogIfNecessary(true, silent = true)
//解析传入的参数并封装成SparkSubmitArguments对象
val appArgs = parseArguments(args)
if (appArgs.verbose) {
logInfo(appArgs.toString)
}
appArgs.action match {//匹配提交的任务类型
case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
case SparkSubmitAction.PRINT_VERSION => printVersion()
}
}
上述代码中关键部分在于针对不同的任务类型,来执行不同操作,在这里我们是提交任务,所以匹配的是SparkSubmitAction.SUBMIT,那么将会调用submit方法,其关键代码如下:
private def submit(args: SparkSubmitArguments, uninitLog: Boolean): Unit = {
def doRunMain(): Unit = {
if (args.proxyUser != null) {//查看是否设置用户权限??
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {//使用当前用户来运行程序,可能会权限不够
override def run(): Unit = {
runMain(args, uninitLog)
}
})
} catch {
..........
}
} else {
runMain(args, uninitLog)
}
}
if (args.isStandaloneCluster && args.useRest) {//判断是否是StandaloneCluster部署模式,并且使用基于REST的方式
try {
logInfo("Running Spark using the REST application submission protocol.")
doRunMain()
} catch {
................
}
// 在所有其他模式下,只需按准备好的方式运行主类
} else {
doRunMain()
}
}
从上述代码中可以看出,在submit方法中首先对部署模式进行判断,但其最终都是调用内部的doRunMain方法,在doRunMain方法中首先会考虑用户权限的问题,如果设置了权限,则按照给定的权限执行任务,否则按照普通方式执行。两者都调用了runMain方法,其关键代码如下所示:
private def runMain(args: SparkSubmitArguments, uninitLog: Boolean): Unit = {
//准备提交应用程序的环境,根据传递的参数获取参数
val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
...................
val loader = getSubmitClassLoader(sparkConf)
//添加jar包
for (jar <- childClasspath) {
addJarToClasspath(jar, loader)
}
var mainClass: Class[_] = null
try {
//通过反射来获取应用程序子类
mainClass = Utils.classForName(childMainClass)
} catch {
.............
}
//根据刚才获取的类来创建实例。不同的部署模式具体实例不同,但是都是SparkApplication的子类
val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
mainClass.getConstructor().newInstance().asInstanceOf[SparkApplication]
} else {
new JavaMainApplication(mainClass)
}
................
try {
//调用start方法,来启动应用程序
app.start(childArgs.toArray, sparkConf)
} catch {
.............
}
}
runMain方法中首先会调用prepareSubmitEnvironment方法来获取提交应用程序需要的一些参数,其中childMainClass是应用程序主类,部署模式不同加载的主类不同。由于本篇博客是基于Standalone Cluster部署模式的,下面给出prepareSubmitEnvironment方法中关于该部署模式的childMainClass赋值语句:
private[deploy] val REST_CLUSTER_SUBMIT_CLASS = classOf[RestSubmissionClientApp].getName()
private[deploy] val STANDALONE_CLUSTER_SUBMIT_CLASS = classOf[ClientApp].getName()
if (args.isStandaloneCluster) {
if (args.useRest) {
childMainClass = REST_CLUSTER_SUBMIT_CLASS
childArgs += (args.primaryResource, args.mainClass)
} else {
// In legacy standalone cluster mode, use Client as a wrapper around the user class
childMainClass = STANDALONE_CLUSTER_SUBMIT_CLASS
if (args.supervise) { childArgs += "--supervise" }
Option(args.driverMemory).foreach { m => childArgs += ("--memory", m) }
Option(args.driverCores).foreach { c => childArgs += ("--cores", c) }
childArgs += "launch"
childArgs += (args.master, args.primaryResource, args.mainClass)
}
if (args.childArgs != null) {
childArgs ++= args.childArgs
}
}
从上述代码中可以看出,StandaloneCluster集群模式也会分为两种情况,分别是使用Rest和不使用Rest,本博客中以不使用Rest为例进行介绍。我们可以看出,当不使用Rest时,childMainClass所指定的主类为ClientApp。回到runMain方法中,当获取提交应用程序需要的配置之后,首先通过反射来获取应用程序子类,然后创建该类的实例对象,并且调用start方法启动应用程序。下面给出ClientApp中start方法的源代码:
override def start(args: Array[String], conf: SparkConf): Unit = {
//将参数封装为ClientArguments对象
val driverArgs = new ClientArguments(args)
//设置RPC请求等待时间(过期时间)
if (!conf.contains(RPC_ASK_TIMEOUT)) {
conf.set(RPC_ASK_TIMEOUT, "10s")
}
//日志级别
Logger.getRootLogger.setLevel(driverArgs.logLevel)
//创建RPC运行环境
val rpcEnv =
RpcEnv.create("driverClient", Utils.localHostName(), 0, conf, new SecurityManager(conf))
//设置并获取Master端的RPC通信端点
val masterEndpoints = driverArgs.masters.map(RpcAddress.fromSparkURL).
map(rpcEnv.setupEndpointRef(_, Master.ENDPOINT_NAME))
//创建并设置client的通信端点ClientEndpoint
rpcEnv.setupEndpoint("client", new ClientEndpoint(rpcEnv, driverArgs, masterEndpoints, conf))
//等待终止
rpcEnv.awaitTermination()
}
从上面代码中可以看出,ClientApp的start方法首先将参数封装成ClientArguments,然后创建RPC运行环境并设置Master的RPC通信端点,最后创建并设置Client端的通信端点ClientEndpoint。创建ClientEndpoint之后会首先调用其onStart方法,具体代码如下:
override def onStart(): Unit = {
driverArgs.cmd match {
case "launch" =>
//执行主类
val mainClass = "org.apache.spark.deploy.worker.DriverWrapper"
//获取并封装Driver启动时所需要的参数配置
val classPathConf = config.DRIVER_CLASS_PATH.key
val classPathEntries = getProperty(classPathConf, conf).toSeq.flatMap { cp =>
cp.split(java.io.File.pathSeparator)
}
val libraryPathConf = config.DRIVER_LIBRARY_PATH.key
val libraryPathEntries = getProperty(libraryPathConf, conf).toSeq.flatMap { cp =>
cp.split(java.io.File.pathSeparator)
}
val extraJavaOptsConf = config.DRIVER_JAVA_OPTIONS.key
val extraJavaOpts = getProperty(extraJavaOptsConf, conf)
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val sparkJavaOpts = Utils.sparkJavaOpts(conf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
//获取并封装Command命令,用于后续启动Driver
val command = new Command(mainClass,
Seq("{{WORKER_URL}}", "{{USER_JAR}}", driverArgs.mainClass) ++ driverArgs.driverOptions,
sys.env, classPathEntries, libraryPathEntries, javaOpts)
val driverResourceReqs = ResourceUtils.parseResourceRequirements(conf,
config.SPARK_DRIVER_PREFIX)
//将参数配置封装成DriverDescription对象
val driverDescription = new DriverDescription(
driverArgs.jarUrl,
driverArgs.memory,
driverArgs.cores,
driverArgs.supervise,
command,
driverResourceReqs)
//发送消息给Master并且将返回结果异步转发给自己
asyncSendToMasterAndForwardReply[SubmitDriverResponse](
//向Master提交请求提交Driver
RequestSubmitDriver(driverDescription))
case "kill" =>
val driverId = driverArgs.driverId
asyncSendToMasterAndForwardReply[KillDriverResponse](RequestKillDriver(driverId))
}
}
从上述代码中可以看出,onStart方法中配置了Driver启动时的主类以及一些参数配置,然后利用RPC通信方式向Master发送启动Driver的消息RequestSubmitDriver,到此也就完成了申请创建Driver过程,将上述部分过程总结一下可以画出下面的时序图。其中Maser端的代码在下一节分析。
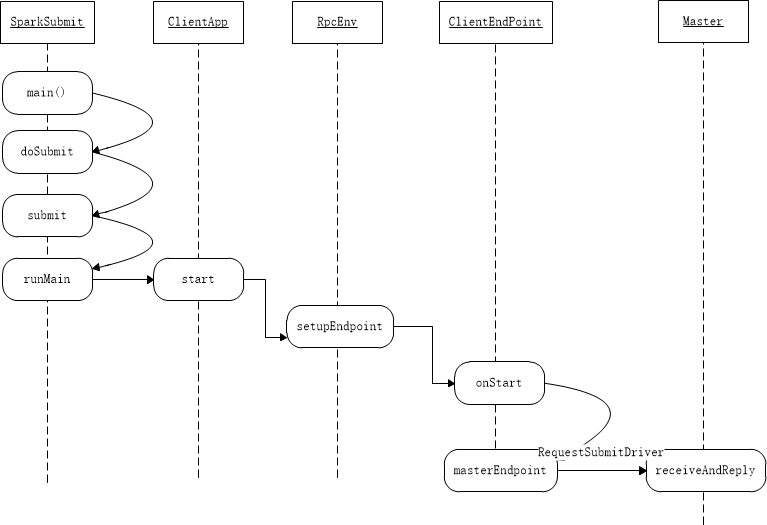
3. 创建Driver
在第1部分我们分析了从shell命令提交任务到向Master申请创建Driver的过程,在本节中我们详细分析Driver的创建过程,首先master端收到RequestSubmitDriver消息之后的会具体创建Driver,其关键代码如下所示:
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case RequestSubmitDriver(description) =>
if (state != RecoveryState.ALIVE) {//判断当前Master状态,不处于活跃状态则不能启动
val msg = s"${Utils.BACKUP_STANDALONE_MASTER_PREFIX}: $state. " +
"Can only accept driver submissions in ALIVE state."
context.reply(SubmitDriverResponse(self, false, None, msg))
} else {
logInfo("Driver submitted " + description.command.mainClass)
//将创建Driver所需要的配置封装成DriverInfo(逻辑上创建Driver)
val driver = createDriver(description)
//持久化存储该Driver
persistenceEngine.addDriver(driver)
//将新创建的Driver加入待分配资源队列
waitingDrivers += driver
drivers.add(driver)
//实际分配资源
schedule()
//向Client端返回消息
context.reply(SubmitDriverResponse(self, true, Some(driver.id),
s"Driver successfully submitted as ${driver.id}"))
}
}
Master端收到RequestSubmitDriver消息之后,首先判断Master的状态,只有处于活跃状态才可以创建Driver。然后将创建Driver所需要的配置封装成DriverInfo,这其实逻辑上创建Driver。之后持久化存储该Driver,以便于出错之后重新创建。将新创建的Driver加入待分配资源队列等待后续分配资源。最后调用schedule方法来进行资源分配,分配完资源后会将结果返回给Client端。下面分析schedule方法中资源分配的关键代码:
private def schedule(): Unit = {
//Master状态不为Alive直接返回
if (state != RecoveryState.ALIVE) {
return
}
//随机打乱works,防止在同一个works上启动太多的app,与此同时过滤出Alive状态的works
val shuffledAliveWorkers = Random.shuffle(workers.toSeq.filter(_.state == WorkerState.ALIVE))
val numWorkersAlive = shuffledAliveWorkers.size
//当前最后一个分配的work下标
var curPos = 0
/**
* 我们以轮循方式为每个等待的Driver分配work。 对于每个Driver,我们从分配给Driver的最后一个work开始,
* 然后继续进行,直到我们遍历所有处于活跃状态的work。
* */
var launched = false
var isClusterIdle = true
var numWorkersVisited = 0
while (numWorkersVisited < numWorkersAlive && !launched) {//遍历所有的work,直到driver启动
val worker = shuffledAliveWorkers(curPos)
//该work上没有启动driver和executor
isClusterIdle = worker.drivers.isEmpty && worker.executors.isEmpty
numWorkersVisited += 1
//判断当前work资源能否启动该driver
if (canLaunchDriver(worker, driver.desc)) {
//向该work请求driver启动需要的资源
val allocated = worker.acquireResources(driver.desc.resourceReqs)
//给driver分配申请好的资源
driver.withResources(allocated)
//启动driver
launchDriver(worker, driver)
//从等待队列中删除该driver
waitingDrivers -= driver
//标识启动成功
launched = true
}
//更新下标,如同一个循环列表
curPos = (curPos + 1) % numWorkersAlive
}
if (!launched && isClusterIdle) {
logWarning(s"Driver ${driver.id} requires more resource than any of Workers could have.")
}
}
//启动Executor,在这里不进行介绍
startExecutorsOnWorkers()
}
上述一段代码与应用程序分配资源相同,在前面的博客中有详细介绍,代码中也给出了具体注释,就不进行具体分析。在给Driver分配完资源后会调用launchDriver方法来启动Driver,下面我们分析launchDriver中的关键代码:
private def launchDriver(worker: WorkerInfo, driver: DriverInfo): Unit = {
logInfo("Launching driver " + driver.id + " on worker " + worker.id)
//在该work中添加driver
worker.addDriver(driver)
//设置driver的worker
driver.worker = Some(worker)
//向worker端发送启动driver请求
worker.endpoint.send(LaunchDriver(driver.id, driver.desc, driver.resources))
//设置friver状态
driver.state = DriverState.RUNNING
}
launchDriver方法中并没有实际完成Driver的启动,其仅仅设置driver启动的worker和driver状态,然后会向具体分配资源的worker发送启动Driver消息launchDriver,下面就来看看Worker端的处理过程,首先看Worker接受消息之后的处理步骤:
case LaunchDriver(driverId, driverDesc, resources_) =>
logInfo(s"Asked to launch driver $driverId")
//创建DriverRunner实例
val driver = new DriverRunner(
conf,
driverId,
workDir,
sparkHome,
driverDesc.copy(command = Worker.maybeUpdateSSLSettings(driverDesc.command, conf)),
self,
workerUri,
securityMgr,
resources_)
//添加映射关系
drivers(driverId) = driver
//启动driver
driver.start()
//更新本work使用的资源
coresUsed += driverDesc.cores
memoryUsed += driverDesc.mem
addResourcesUsed(resources_)
worker接收到LaunchDriver消息之后,首先会创建一个DriverRunner对象用于启动driver,然后调用其start方法启动driver,启动完成之后会更新本worker的资源信息。下面就具体看看DriverRunner的start方法。
private[worker] def start() = {
//启动线程用于创建和管理driver
new Thread("DriverRunner for " + driverId) {
override def run(): Unit = {
var shutdownHook: AnyRef = null
try {
//用于杀死Driver
shutdownHook = ShutdownHookManager.addShutdownHook { () =>
logInfo(s"Worker shutting down, killing driver $driverId")
kill()
}
//准备driver需要的jar包并运行driver
val exitCode = prepareAndRunDriver()
//根据是否被强制终止并设置退出代码来设置最终状态
finalState = if (exitCode == 0) {
Some(DriverState.FINISHED)
} else if (killed) {
Some(DriverState.KILLED)
} else {
Some(DriverState.FAILED)
}
} catch {
case e: Exception =>
kill()
finalState = Some(DriverState.ERROR)
finalException = Some(e)
} finally {
if (shutdownHook != null) {
ShutdownHookManager.removeShutdownHook(shutdownHook)
}
}
//通知worker最终driver状态和可能出现异常
worker.send(DriverStateChanged(driverId, finalState.get, finalException))
}
}.start()//启动线程
}
DriverRunner的start方法会创建一个线程来创建和管理driver,在线程的run方法中会设置driver关机引用,然后调用prepareAndRunDriver方法准备driver所需要的jar包并且运行driver,下面来看看prepareAndRunDriver方法:
private[worker] def prepareAndRunDriver(): Int = {
//准备driver创建所需要的资源
val driverDir = createWorkingDirectory()
val localJarFilename = downloadUserJar(driverDir)
val resourceFileOpt = prepareResourcesFile(SPARK_DRIVER_PREFIX, resources, driverDir)
def substituteVariables(argument: String): String = argument match {
case "{{WORKER_URL}}" => workerUrl
case "{{USER_JAR}}" => localJarFilename
case other => other
}
//driver的配置资源文件,该文件将在driver启动时用于加载资源
val javaOpts = driverDesc.command.javaOpts ++ resourceFileOpt.map(f =>
Seq(s"-D${DRIVER_RESOURCES_FILE.key}=${f.getAbsolutePath}")).getOrElse(Seq.empty)
//构建用于启动driver进程命令
val builder = CommandUtils.buildProcessBuilder(driverDesc.command.copy(javaOpts = javaOpts),
securityManager, driverDesc.mem, sparkHome.getAbsolutePath, substituteVariables)
runDriver(builder, driverDir, driverDesc.supervise)
}
private def runDriver(builder: ProcessBuilder, baseDir: File, supervise: Boolean): Int = {
builder.directory(baseDir)
def initialize(process: Process): Unit = {
// Redirect stdout and stderr to files
//将stdout和stderr重定向到文件
val stdout = new File(baseDir, "stdout")
CommandUtils.redirectStream(process.getInputStream, stdout)
val stderr = new File(baseDir, "stderr")
val redactedCommand = Utils.redactCommandLineArgs(conf, builder.command.asScala)
.mkString(""", "" "", """)
val header = "Launch Command: %sn%snn".format(redactedCommand, "=" * 40)
Files.append(header, stderr, StandardCharsets.UTF_8)
CommandUtils.redirectStream(process.getErrorStream, stderr)
}
runCommandWithRetry(ProcessBuilderLike(builder), initialize, supervise)
}
private[worker] def runCommandWithRetry(
command: ProcessBuilderLike, initialize: Process => Unit, supervise: Boolean): Int = {
var exitCode = -1
// Time to wait between submission retries.
var waitSeconds = 1
// A run of this many seconds resets the exponential back-off.
val successfulRunDuration = 5
var keepTrying = !killed
val redactedCommand = Utils.redactCommandLineArgs(conf, command.command)
.mkString(""", "" "", """)
while (keepTrying) {
logInfo("Launch Command: " + redactedCommand)
synchronized {
if (killed) { return exitCode }
//启动进程,也就是执行命令
process = Some(command.start())
initialize(process.get)
}
val processStart = clock.getTimeMillis()
//获取状态
exitCode = process.get.waitFor()
// check if attempting another run
............
}
exitCode
}
}
prepareAndRunDriver方法中首先会准备driver创建所需要的资源,包括创建目录、加载jar包和准备资源,然后会创建启动应用程序的命令。利用准备好的资源和执行命令调用runDriver方法,runDriver方法中主要设置了driver初始化的操作,然后调用runCommandWithRetry方法执行启动命令。从前面代码可以知道,这里命令所执行的主类为"org.apache.spark.deploy.worker.DriverWrapper",下面就来看看该类的Main方法:
def main(args: Array[String]): Unit = {
args.toList match {
case workerUrl :: userJar :: mainClass :: extraArgs =>
//创建SparkConf
val conf = new SparkConf()
val host: String = Utils.localHostName()
val port: Int = sys.props.getOrElse(config.DRIVER_PORT.key, "0").toInt
//创建RPC环境
val rpcEnv = RpcEnv.create("Driver", host, port, conf, new SecurityManager(conf))
logInfo(s"Driver address: ${rpcEnv.address}")
//设置WorkerWatcher
rpcEnv.setupEndpoint("workerWatcher", new WorkerWatcher(rpcEnv, workerUrl))
.................
// 通过反射来获取应用程序主类
val clazz = Utils.classForName(mainClass)
//获取应用程序main方法
val mainMethod = clazz.getMethod("main", classOf[Array[String]])
//使用参数来执行main方法
mainMethod.invoke(null, extraArgs.toArray[String])
rpcEnv.shutdown()
..........................
}
}
在DriverWrapper的main方法中,首先创建Spark的配置文件,然后创建RPC环境并且设置WorkerWatcher。之后会通过反射技术获取应用程序主类,并且执行其main方法。在我们的应用程序中会首先创建SparkContext,在SparkContext中就会创建DAGScheduler、TaskScheduler以及SchedulerBackend。当遇到Action操作时就会触发Job。这些部分在前面的博客中已经详细讲解过,在这里就不再叙述。
在整个源码阅读过程中遇到很多问题,有部分已经理解了,但是还是有一部分没有理解。例如:
- 为什么会有两次RPC环境创建?一次名字为DriverClient,一次为Driver,两者有什么区别?
- WorkerWatcher具体作用是什么也还没有仔细查看
如果喜欢的话希望点赞收藏,关注我,将不间断更新博客。
希望热爱技术的小伙伴私聊,一起学习进步
来自于热爱编程的小白
最后
以上就是自信冥王星最近收集整理的关于你真的懂Spark吗?手把手带你解析Spark-Submit提交应用程序过程(Spark2.12)1. 总览2. 申请创建Driver3. 创建Driver的全部内容,更多相关你真的懂Spark吗?手把手带你解析Spark-Submit提交应用程序过程(Spark2.12)1.内容请搜索靠谱客的其他文章。








发表评论 取消回复