1.什么是Redis

Redis是一个完全免费开源的 NoSQL数据库 是由意大利人开发的一款内存高速缓存数据库 该软件由C语言编写,数据模型为
Key Value 它支持丰富的数据结构(类型),比如String list hash set sorted.可持久化,保证了数据安全。
用处:
经常用在 热点数据 经常会被查询,但是不经常被修改删除的数据
官方测试数据
- 读的速度 110000次/s
- 写的速度 80000次/s
- 不会存在线程安全的问题
- 默认支持16个数据库

缺点:
太耗内存
NoSQL 非关系型数据库
NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL"。
在现代的计算系统上每天网络上都会产生庞大的数据量。
这些数据有很大一部分是由关系数据库管理系统(RDBMS)来处理。 1970年 E.F.Codd’s提出的关系模型的论文 “A relational model of data for large shared data banks”,这使得数据建模和应用程序编程更加简单。
使用需求:
- 支持大量并发用户(数万,甚至数百万量级)
- 为全球范围内的用户提供高质量的交互体验
- 高可用性 高并发
- 支持处理半结构化数据和非结构化数据
- 快速适应不断变化的需求
(DBMS)关系型数据库
MySQL SQLServer Oracle 等等
(NoSQL)非关系型数据库
MongoDB Redis 等等
安装Redis数据库
- 连接互联网 更新软件包
sudo apt-get update
- 输入 执行后
sudo apt-get install -y redis-server
-
出现错误时尝试解决apt依赖
-
默认安装路径为 /usr/bin里 可使用
ls redis*查看 -
输入redis-cli 启动redis客户端
# 启动Redis客户端
redis-cli
# 客户端命令
# help 查看Redis版本信息等
help
# 退出Redis客户端
quit 或 exit
- 输入
ping测试是否成功 - 出现PONG表示畅通
ping
- 通过启动命令检查Redis服务器状态默认端口号6379
netstat -nlt|grep 6379
- 配置文件默认在
/etc/redis/redis.conf
修改配置文件 配置文件较为长 可以使用 vi、vim 的搜索功能进行查找
vi、vim 的搜索功能教程地址
1 .用vi打开Redis服务器的配置文件redis.conf
# 进入Redis配置文件
vi /etc/redis/redis.conf
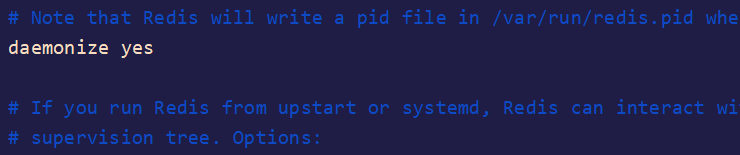
Redis以守护进程运行
- 如果以守护进程运行,则不会在命令行阻塞,类似于服务
- 如果以非守护进程运行,则当前终端被阻塞,无法使用
- 推荐改为yes,以守护进程运行
- 进入配置文件找到这一行 修改为以下配置
daemonize yes
2 .修改访问Redis的密码
使用Java连接Redis必须添加密码!!!!
#取消注释requirepass 添加你的密码
requirepass your_password

3 .让Redis服务器被远程访问
默认情况下,Redis服务器不允许远程访问,只允许本机访问,所以我们需要设置打开远程访问的功能。
配置文件中有好几处 类似的地方 不要找错了
配置文件里有好几处bind 127.0.0.1 不要找错了!!!!!!
大概在69行左右
#注释bind
#bind 127.0.0.1

修改后,重启Redis服务器。
service redis-server restart
未使用密码登陆Redis服务器
他会告诉你 没有权限不能访问
redis-cli
redis 127.0.0.1:6379> keys *
(error) ERR operation not permitted
**登陆Redis服务器,输入密码 **
这时候就能正常的访问了
redis-cli -a your_password
redis 127.0.0.1:6379> keys *
1) "name"
2)....你的所有key
配置完成后重新启动服务器
# 重启redis-server 的三个命令 任选其一即可
sudo service redis-server restart
sudo /etc/init.d/redis-server restart
sudo redis-server /etc/redis/redis.conf
Redis关闭
./redis-cli shutdown 正常方式关闭 Redis 会进行持久化操作
kill -9 进程号 强制关闭Redis服务端 不会进行持久化操作 容易造成数据丢失
ps -ef | grep -i redis 查看当前Redis运行的进程号
如果想要保证数据不造成丢失可以修改Redis配置文件的save 持久化时间
Ubuntu中使用Redis客户端
服务端设置密码后 客户端的连接方法必须带参数 ./redis-cli -h host -p port -a password
redis-cli -h 192.168.0.100 -p 6379 -a 123456
- host代表 连接的IP地址
- port 连接的端口号
- password 密码
本机(虚拟机本机)访问可以忽略IP地址 port忽略的话默认是6379
Redis客户端常用命令 String
| 命令 | 作用 | 示例 |
|---|---|---|
| del key | 根据key删除 | del userName 或 del key1 key2 … |
| keys pattern | 通配符 *代表所有 user? 开头为user的key | key * 或 key user? |
| exists key | 判断一个key是否存在 | 返回值0或1 |
| expire key seconds | 给一个key设置过期时间 单位:秒 | |
| ttl key | 查询 kye的生命周期 | 返回值 -1:永久 -2:无效 |
| persist key | 移除key的过期时间设置为永久有效 | |
| select index | 切换到第index个数据库 | select 1 切换到第一个数据库 |
| rename key newName | 修改key的名字 | rename key1 user1 |
| move key index | 把key移动到下标为index的数据库里去 | move user1 1 把user1移动到下标为1的数据库里 |
| type key | 查看key是什么类型 | |
| FLUSHALL | 删除所有数据库中所有的key | 用于辞职时 删库跑路 |
| FLUSHDB | 删除当前数据库中所有的key |
Key的命名规范
key区分大小写 命令不区分大小写
- 单个Key可以支持512M的大小
- key不要太长尽量不能超过1024字节 不仅降低内存 还增长查询时间
- key也不要太短,太短的话key的可读性会降低
- 在一个项目中key的命名规范尽量使用统一的命名格式 列如:user12
- 对应到表上就是 user表有 id,name,age…属性 命名格式就可以是
- user:1:name 或 user:2:name 中间的数字为用户的id 用于区分数据
- : 号 为程序员的统一规范 其他的符号也可以用
Redis的数据类型
- string 是redis的最基本的数据类型 是二进制安全的 一个key对一个value 单个key可以最大存储512M的数据
- 二进制安全特点
- 编码 解码在客户端进行 执行效率高
- 不需要频繁编码解码,不会出现乱码
string类型常用命令
| 命令 | 作用 | 示例 |
|---|---|---|
| set Key | 创建一个Key | set key1 |
| set Key value | 创建一个Key且赋值 | set key1 123 |
| mset k1 v1 k2 v2… | 存多个key value | |
| mget k1 k2 | 取多个key | |
| setnx key value | 当key不存在时才创建 | key存在时返回0 |
| setex key seconds value | 将键 key 的值设置为 value , 并将键 key 的生存时间设置为 seconds 秒钟。如果键 key 已经存在, 那么 SETEX 命令将覆盖已有的值。 | |
| getrange key start end | 根据下标取值 | getrange key 0 3 返回下标0到3的值 |
| strlen key | 查看字符串长度 | |
| incr key | 每次自增key的值+1 | decr key 自减 |
| incrby key 增量值 | 每次自增key的增量值 | decyby key 减值 |
| get keys | 根据Key获取Value | get userName 返回nil 就是null |
-
应用场景
- 保存单个字符或字符串或JSON格式的数据
- 计数器 点击量 粉丝数等等
- incr等指令本身具有原子性操作的特性所有完全可以用redis的 自增自减操作实现计数的效果 假如有5个用户同时点击那么 就要排队最后的值一定是5
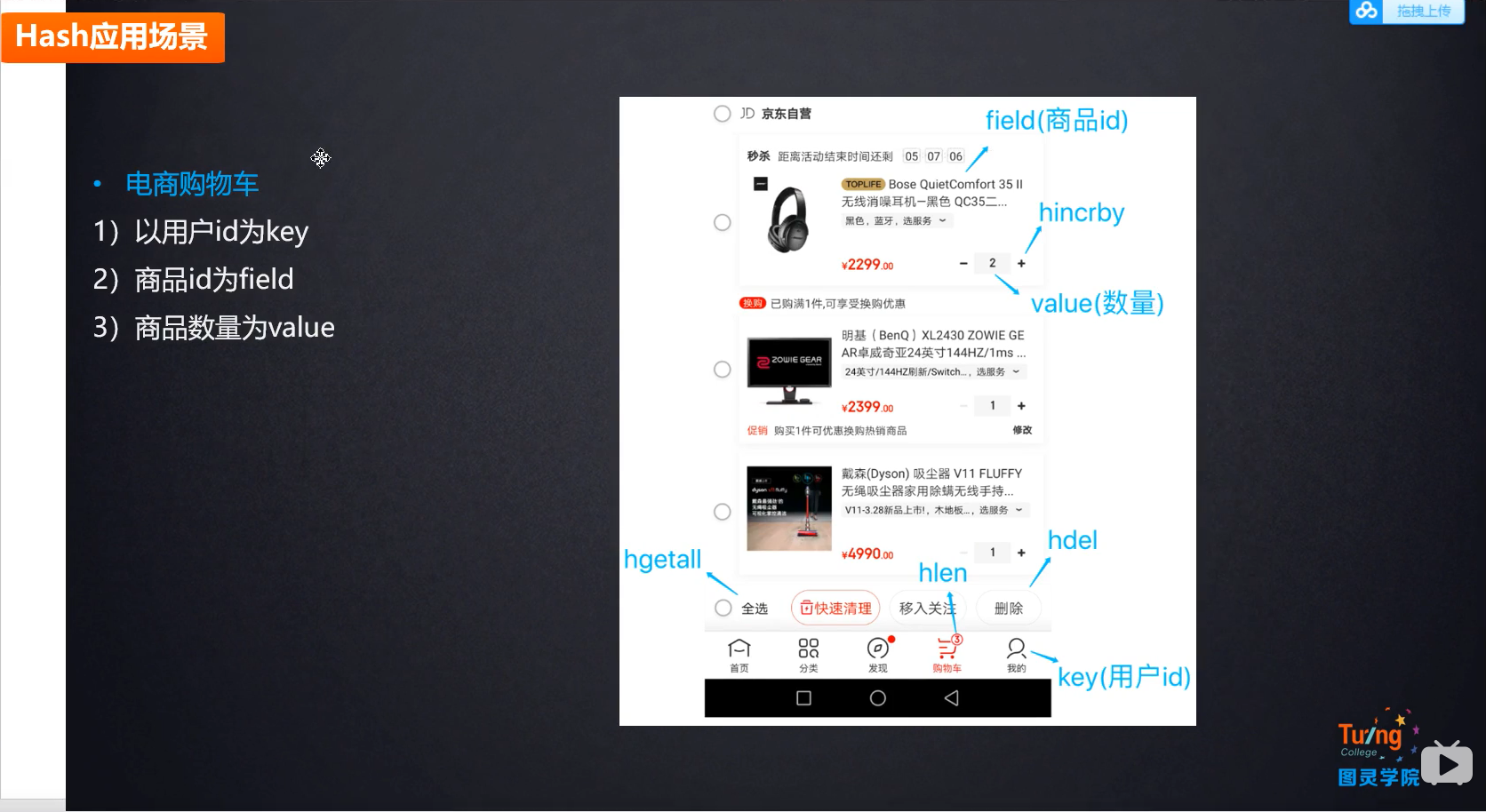
Hash类型
简介:RedisHash是一个string类型的field 和value的影视表,特别适合存储对象。每个hash可以存储(40多亿)个键值对,而且占用很少磁盘空间
常用命令
| 命令 | 作用 | 示例 |
|---|---|---|
| hset key field value 赋值语法 | 为指定的key设置fild和value | hset users:1 uname 张三 |
| hmset key field value field value… 赋值语法 | 为指定的key设置fild和value | hmset users:1 uname 张三 uage 24 … 此命令会覆盖哈希表中已存在的域。 |
| hget key field 取值语法 | 指定key 根据field取得value | hget users:1 uname |
| hmget key field1 field2 … 取多值语法 | 指定多个field获取多个value | hmget users:1 uname age … |
| hgetall key | 指定key获取key中所有的value | hgetall users:1 |
| hkeys key | 指定key获取key中所有的 field名称 | hkeys users:1 |
| hlen key | 获取key中的一共有多少个filed | |
| hlen key | 获取key中有多少个field | |
| hdel key1 key2 | 删除指定的key | |
| hincrby key field increment | 给key中为数值的field增量 | hincrby users:1 age 10 |
| hincrbyfloat key filed increment | 给key中为浮点数的field增量 | hincrby users:1 money 10.1 |
| hexists key field | 查看key中的field是否存在 | 返回1或0 |
| hsetnx key field | 当field 尚未存在于哈希表的情况下, 将它的值设置为 value | 如果哈希表 hash 不存在, 那么一个新的哈希表将被创建并执行 hsetnx 命令。 |
| hstrlen key field | 返回哈希表 key 中,field 值的字符串长度。 | hstrlen myhash f1 |
-
应用场景
- 存储对象 Hash是最接近关系型数据库的类型
- 不允许没有field为空的数据存在 如果一个key的field被删完了那么这个key就会被redis回收
list列表常用命令
| 命令 | 作用 | 示例 |
|---|---|---|
| lpush key value [value…] | 将一个或多个值 value 插入到列表 key 的表头 | LPUSH a b c 先进后出 返回的就是 c b a值可以重复 |
| lpushx key value [value…] | 当key存在时才添加否则什么都不做 | 功能与lpush一致 |
| rpush key value[value…] | 往表尾部添加数据 | 与lpush刚好相反 插入a b c 返回 a b c |
| rpushx key value [value…] | 当key存在时才添加否则什么都不做 | 功能与lpushx刚好相反 |
| lpop key | 移除头元素第一个元素 | |
| rpop key | 与上相反 | |
| lrem key count value | 根据位置移除key | lrem greet 2 morning移除从表头到表尾,最先发现的2个 morning 元素被移除 |
| llen key | 查询key的长度 | |
| lindex key index | 返回下表时index的元素 | 没找到返回nil |
| lset key index value | 把下表为index的key赋值 | 用该命令操作空列表(报错)索引超出列表长度(报错) |
| lrange key start end | 区间查询 | LRANGE fp-language 0 1 0 -1代表查询所有 |
| ltrim key start end | 区间删除 | LTRIM alpha 1 -1删除下标为1到-1之间的key(下标0) |
| BLPOP key [key …] timeout | 阻塞查询 | |
| BLPOP job command 300 | 当key不存在时会被阻塞,直到另一客户端进行添加操作300为等待秒数 如果超时还没有查到那么返回nil | |
| RPOPLPUSH 集合1 集合2 | 把第一个集合的第一个元素(RPOP)移除 并且添加到第二个集合里边(lpush添加) | 也可以把当前集合的最后一个元素换位到当前集合第一个位置(rpoplpush 集合1 集合1) |
应用场景
- 实现消息队列的功能 不必用MySQL的order by排序
- 分页
- 任务队列
set集合常用命令 无序
| 命令 | 作用 | 示例 |
|---|---|---|
| sadd key value [value…] | 将一个或多个元素添加到集合中 | 当key不是集合类型的时候则会报错当key不存在则新创建包含value的集合 |
| sismember key value | 判断key中是否包含该value | |
| spop key | 移除key中随机一个元素并返回 | |
| srandmember key count | 随机移除count个元素并返回 | 当count没有指定就移除一个元素并返回 |
| srem key value | 移除key中指定的value | 当key不是集合类型报错 |
| smove key newkey value | 把一个key中的指定value移动到新的key中 | |
| scard key | 返回key中元素的数量 | |
| smembers key | 返回可以中所有的成员 | |
| sinter key [key…] | 返回多个集合中的交集 | key1 1 2 3 key2 2 3 4 返回值 2 3 交集 |
| sinterstore newKey[key…] | 把多个key中的交集保存到新的key中 | |
| sunion key [key…] | 返回多个集合中的并集 | 返回两个集合中所有的value |
| SUNIONSTORE newKey [key…] | 把多个集合的并集保存到新的集合 | |
| sdiff key [key…] | 返回多个集合中的差集 | SDIFF peter’s_movies joe’s_movies 左边的为主集合以主集合为基准返回值就是 主集合中有的 副集合里没有的数据 |
| SDIFFSTORE newKey [key…] | 把多个集合的差集保存到新集合中 | 交并差集解释 |
set集合常用命令 有序
| 命令 | 作用 | 示例 |
|---|---|---|
SpringBoot整合Redis
- 在pom.xml中添加依赖
# 此依赖被Spring官方收录在spring-boot-starter-parent中有版本号
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--lettuce pool连接池-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
- 在application.yml中添加配置
spring:
redis:
host: 192.168.244.102 # Redis服务器地址
port: 6379 # Redis服务器连接端口
password: root # Redis服务器连接密码
database: 0 # Redis数据库索引(默认为0)
lettuce:
shutdown-timeout: 0
pool:
max-active: 8 # 连接池最大连接数(使用负值表示没有限制) 默认 8
max-wait: -1 #连接池最大阻塞等待时间(使用负值表示没有限制) 默认 -1
max-idle: 8 # 连接池中的最大空闲连接 默认 8
min-idle: 0 # 连接池中的最小空闲连接 默认 0
-
上文配置的 jedis 和 lettuce是两种不同的Redis客户端
-
Jedis 是直连模式,在多个线程间共享一个 Jedis 实例时是线程不安全的,每个线程都去拿自己的 Jedis 实例,当连接数量增多时,物理连接成本就较高了。
-
2、Lettuce的连接是基于Netty的,连接实例可以在多个线程间共享,如果你不知道Netty也没事,大致意思就是一个多线程的应用可以使用同一个连接实例,而不用担心并发线程的数量。通过异步的方式可以让我们更好地利用系统资源。
编写RedisConfig
- 完整的配置类
package cn.yufire.redis.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.connection.jedis.JedisConnectionFactory;
import org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import org.springframework.data.redis.support.collections.RedisCollectionFactoryBean;
/**
*
* <p>
* Description:
* </p>
* RedisConfig的配置类
* @author yufire
* @version v1.0.0
* @since 2020-02-21 21:37:46
* @see cn.yufire.redis.config
*
*/
@Configuration
public class RedisConfig {
/**
* 使用 LettuceConnectionFactory连接池
* 也可以使用 JedisConnectionFactory 需要引入依赖和配置
* 也可以使用 RedisConnectionFactory Redis默认的连接池
* @param factory
* @return
*/
@Bean
public RedisTemplate<String,Object> redisTemplate(LettuceConnectionFactory factory){
RedisTemplate<String,Object> template = new RedisTemplate<String,Object>();
template.setConnectionFactory(factory);
return template;
}
}
//使用Jackson2JsonRedisSerializer来序列化和反序列化redis的value值(默认使用JDK的序列化方式)
Jackson2JsonRedisSerializer jacksonSeial = new Jackson2JsonRedisSerializer(Object.class);
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// key采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
// hash的key也采用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
// value序列化方式采用jackson
template.setValueSerializer(jacksonSeial);
// hash的value序列化方式采用jackson
template.setHashValueSerializer(jacksonSeial);
template.afterPropertiesSet();
可以去网上找一个完整的RedisUtil工具类 也可以使用redisTemplate进行操作
使用redisTemplate操作Redis
//注入RedisTemplate模板
@Autowired
private RedisTemplate<String,String > redisTemplate;
//测试插入一个对象到Redis
@Test
public void userAddToRedis() throws JsonProcessingException {
User user = new User();
user.setId(1);
user.setName("张三");
user.setPassword("123456");
user.setAge(18);
ObjectMapper mapper = new ObjectMapper();
//使用Jackosn把user对象转成json类型存入Redis
String userJson = mapper.writeValueAsString(user);
//存入Redis
redisTemplate.opsForValue().set("user",userJson);
//从Redis取出User的json串
String redisGetUserJson = redisTemplate.opsForValue().get("user");
//使用Jackson把json字符串转换为User对象
User redisGetUser = mapper.readValue(redisGetUserJson, User.class);
//打印
System.out.println(redisGetUser);
}
- 控制台输出
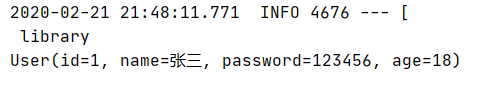
- redisTemplate方法说明
redisTemplate.opsForValue(); //操作字符串类型
redisTemplate.opsForHash(); //操作hash类型
redisTemplate.opsForList(); //操作List类型
redisTemplate.opsForSet(); //操作Set类型
redisTemplate.opsForZSet(); //操作有序set类型
具体使用的时候,你可以根据自己的数据类型选择相应的方法即可,网上有各种RedisUtil工具类。
普通Java项目连接Redis
添加Maven依赖
<!--Redis客户端的 使用连接池需要添加commons-pool2的jar redis客户端提供依赖所以不用写-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.8.1</version>
</dependency>
<!--spring-data-redis Spring提供的RedisTemplate模板-->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
<version>1.6.4.RELEASE</version>
</dependency>
<!--与spring整合的spring核心包-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>4.3.20.RELEASE</version>
</dependency>
单实例连接Redis
Jedis jedis = new Jedis("192.168.189.132",6379);//ip 和 端口号
jedis.auth("123456");//密码 Redis服务器必须设置密码
/**
* 测试是否连接成功成功返回 PONG
* 如果显示连接超时 检查linux服务器是否开放6379端口
*/
System.out.println(jedis.ping());
连接池连接Redis
/**
* 连接池连接 帮助我们管理连接
*/
//获取连接池配置对象设置配置信息
JedisPoolConfig config = new JedisPoolConfig();
//设置最大连接数
config.setMaxTotal(30);
//最大空闲数
config.setMaxIdle(10);
//获得连接池
JedisPool jedisPool = new JedisPool(config,"192.168.189.132",6379);
//获得核心对象
Jedis jedis2 = null;
try {
jedis2 = jedisPool.getResource();
jedis2.auth("123456"); //指定密码
/**
* get set 操作
* jedis2.get(key);....
*/
} catch (Exception e) {
e.printStackTrace();
}finally{
if (jedis2!=null) {
jedis2.close();
}
//虚拟机 Redis服务器关闭时 释放pool资源
if (jedisPool !=null) {
jedisPool.close();
}
}
整合Spring后使用RedisTemplate模板连接Redis
整合Spring的配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx.xsd">
<!--开启注解扫描-->
<context:component-scan base-package="com.sjy.redis"/>
<!-- 配置Redis配置 -->
<bean id="jedisConfig" class="redis.clients.jedis.JedisPoolConfig">
<!-- 最大连接数 -->
<property name="maxTotal" value="50"/>
<!-- 最大空闲数 -->
<property name="maxIdle" value="5"/>
<!-- 最大等待时间 -->
<property name="maxWaitMillis" value="300" />
</bean>
<!-- Spring整合Redis -->
<bean id="jedisConnectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory">
<!-- IP地址 -->
<property name="hostName" value="192.168.189.132" />
<!-- 端口号 -->
<property name="port" value="6379" />
<property name="password" value="123456" />
<!-- 连接池配置引用 -->
<property name="poolConfig" ref="jedisConfig" />
<!-- 超时时间 默认2000-->
<property name="timeout" value="2000" />
<!-- usePool:是否使用连接池 -->
<property name="usePool" value="true"/>
</bean>
<bean id="redisTemplate" class="org.springframework.data.redis.core.RedisTemplate">
<property name="ConnectionFactory" ref="jedisConnectionFactory"/>
<!--不让Jdk进行序列化操作-->
<property name="keySerializer">
<bean class="org.springframework.data.redis.serializer.StringRedisSerializer" />
</property>
<property name="valueSerializer">
<bean class="org.springframework.data.redis.serializer.StringRedisSerializer" />
</property>
<property name="hashKeySerializer">
<bean class="org.springframework.data.redis.serializer.StringRedisSerializer" />
</property>
<property name="hashValueSerializer">
<bean class="org.springframework.data.redis.serializer.StringRedisSerializer" />
</property>
</bean>
</beans>
测试Spring整合Redis
//运行spring配置文件 启动spring
ApplicationContext ac = new ClassPathXmlApplicationContext("spring_redis.xml");
RedisTemplate<String ,String> template = (RedisTemplate<String, String>) ac.getBean("redisTemplate");
//string类型的操作
ValueOperations<String, String> string = template.opsForValue();
//还有其他类型 //Hash类型的 opsForHash()
//list类型的 opsForList()
Spring整合Redis需要指定是否序列化key value 否则会出现新增key时key的前边出现序列化的字符串导致出现问题
Redis发送订阅
Redis多数据库
常用命令
- Redis下数据库是由一个整数索引标识,
- 而不是一个数据库名称。
- 默认情况下连接到表示为0的数据库
- redis配置文件redis.conf 中datebases 16 来控制数据库总数
| 命令 | 作用 | 示例 |
|---|---|---|
| select index | 切换到第index个数据库 | select 1 切换到第一个数据库 |
| move key db | 把指定的key移动到指定的数据库中 | move user 2 |
Redis事务
- redis事务可以一次执行多个命令(按顺序的串行化执行,执行中不会被其他命令插入,不能加塞)
- 当事务块中的某个命令出错时只有出错的命令不会执行,其他的命令继续执行,不会回滚
- 如果编辑事务块的时候出现了语法错误提交时整个事务快将执行失败Redis进行回滚
Redis事务执行的三个阶段
| 事务命令 | 作用 | 示例 |
|---|---|---|
| DISCARD | 取消事务,放弃执行事务块中所有的指令 | |
| EXEC | 执行所有事务块中的命令 | |
| MULTI | 标记一个事务的开始 | |
| UNWATCH | 取消WATCH命令对所有key的监视 | |
| WATCH key [key…] | 监视一个或多个key如果在事务在执行前这个key被其他命令改动的话,事务将被打断 | |
| 图片示例 | 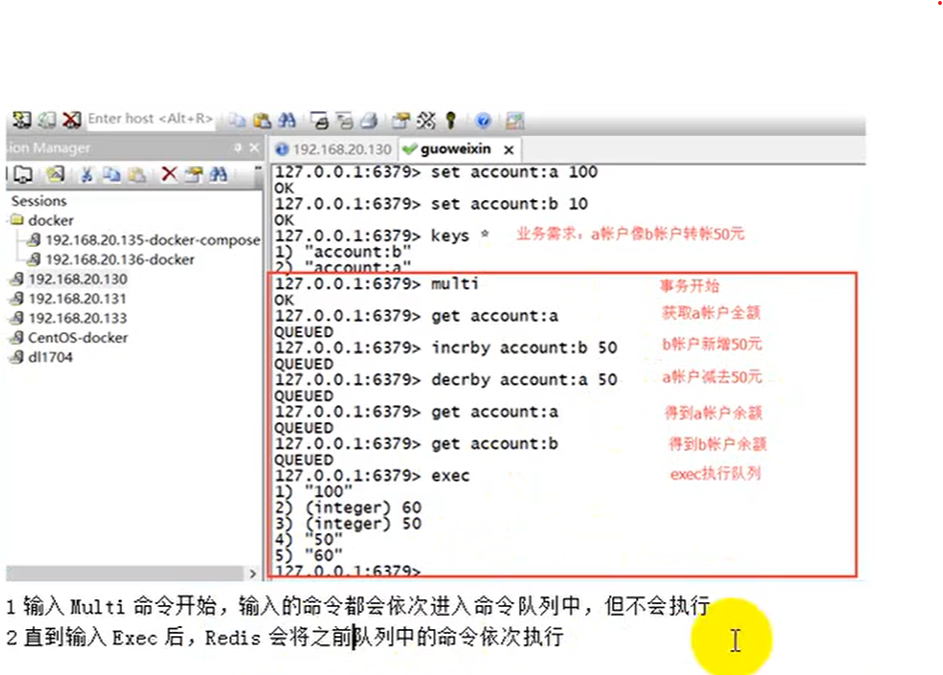 |
Redis数据淘汰策略
- 当内存不足时Redis会根据redis-conf配置文件中的缓存淘汰策略进行淘汰部分key,以保证写入成功
- 如果无法淘汰key时,Redis将返回out of memory内存溢出的错误

Redis持久化
- 方式一 RDB(默认)
- RDB相当于快照,保存的一种状态。把几十G的数据创建一个几kb的快照
- 默认的文件名叫 dump.rdb
- 优点
- 保存数据块 还原数据速度极快 他是以二进制的格式写的dump.rdb
- 适用于灾难备份
- 缺点
- 不适合小内存的机器使用
- 快照条件
- Redis-cli服务正常关闭的时候
- key满足配置文件中的持久化策略的时候
- 优点
- 方式二 AOF

Redis的与mysql的一致性
最后
以上就是谦让篮球最近收集整理的关于Redis缓存数据库使用以及命令1.什么是Redis安装Redis数据库Redis关闭Redis客户端常用命令 StringKey的命名规范Redis的数据类型string类型常用命令Hash类型list列表常用命令set集合常用命令 无序set集合常用命令 有序SpringBoot整合Redis普通Java项目连接RedisRedis发送订阅Redis多数据库Redis事务Redis数据淘汰策略Redis持久化Redis的与mysql的一致性的全部内容,更多相关Redis缓存数据库使用以及命令1.什么是Redis安装Redis数据库Redis关闭Redis客户端常用命令内容请搜索靠谱客的其他文章。








发表评论 取消回复