版本配置:
Ubuntu 16.04 (事实上centos我配过也是这么配的,一样的)
Mysql 5.7.28
Hive 2.3.6
1.前言
hive和hbase的安装配置是我目前配置遇到问题最多两个个组件。。真的十分的坑,又或者是我菜吧。所以我决定写下来,hbase我写下来了,如果大家有兴趣的话,可以去翻一下。
hbase: centos7下hbase配置及解决错误: 找不到或无法加载主类 org.apache.hadoop.hbase.util.GetJavaProperty等三个问题.
遇到的报错在这里总结一下(解决的办法,在文章中,可以ctrl+F找一下):
1、使用hive的时候报错。Caused by: MetaException(message:Hive Schema version 1.2.0 does not match metastore’s schema version x.x.x Metastore is not upgraded or corrupt)_2
2、使用spark sql对hive进行操作,数据不能连接同步
3、启动pyspark或者spark-shell报很多 WARN conf.HiveConf: HiveConf of name hive.xxxx.xxxx.xxxx does not exist 的警告
4、启动hive警告 SLF4J: Class path contains multiple SLF4J bindings.
2.Hive安装配置
在安装Hive之前是需要先装好mysql的,但是因为我很早之前就配好了(其实就是懒得写),所以就配置mysql的方法你们可以参考这篇文章: https://www.cnblogs.com/opsprobe/p/9126864.html.,我按他的装没出现问题,大家可以试一下。
2.1 Hive下载安装配置
官网下载链接: https://hive.apache.org/.
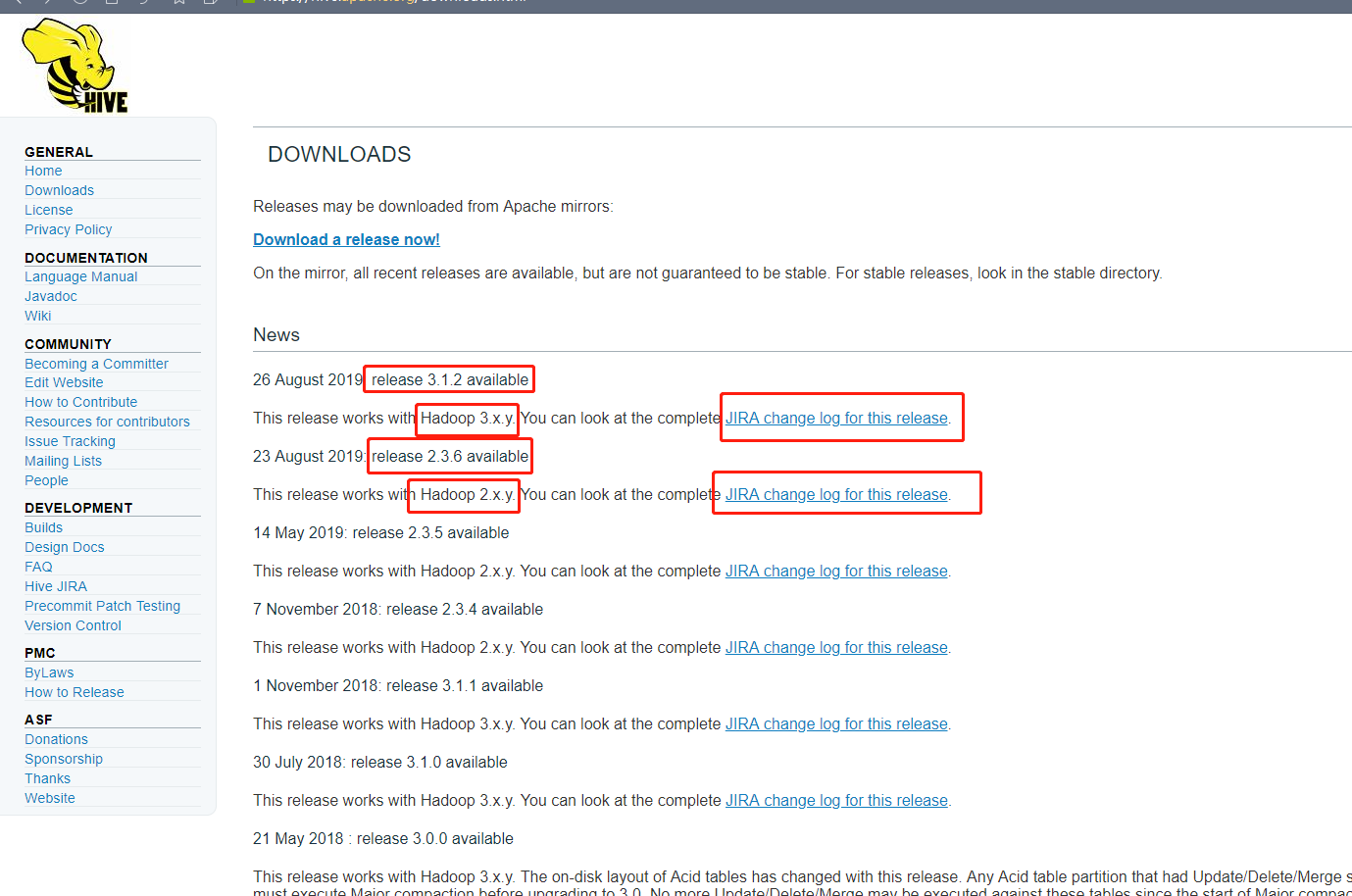
文章写道这里我才发现一个问题。。原来我的版本配置错了。。。。。日
红框的意思是,如果你的hadoop 是3字头的版本(3.x.y–例如3.1.1)那么你就应该选择第一个3.1.2的版本,那下面的2.3.6版本就应该是2字头的hadoop应该要选的版本。
我的hadoop是3.1.2版本的,然而我没看清楚选了2.3.6版本。
所以在启动的时候报了以下这个错(由于我当时忘记把错误提示拷贝下来了,所以找了一下历史记录把网上差不多的错拷贝过来了):
Caused by: MetaException(message:Hive Schema version 1.2.0 does not match metastore’s schema version x.x.x Metastore is not upgraded or corrupt)_2
大概意思反正就是版本不匹配,我觉得就是因为这个原因,我选错了版本,应该选hive3.1.2那个版本的。
解决办法则是直接把 hive/conf/ 目录下的 hive-site.xml 文件修改以下这个配置(把true改成false):
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
有些网上的说法是要在mysql那里改一下配置的设置,那个我没试过,不清楚,但是上面这个方法我改了之后就不报错了。但是如果你如果文章看到这里,你只是刚下载完,如果版本有我这个问题建议还是重新下载吧。
下载好之后,我是解压放在 /usr/local/ 目录下的具体位置自己选择
tar -zxvf apache-hive-2.3.6-bin.tar.gz -C /usr/local/hive
添加环境变量
vim ~/.bashrc
# 加入以下配置
export HIVE_HOME=/usr/local/hive
export HCAT_HOME=$HIVE_HOME/hcatalog
export HIVE_CONF=$HIVE_HOME/conf
export PATH=$PATH:$HIVE_HOME/bin
# source一下
source ~/.bashrc
然后进入到hive目录下的conf目录下修改配置文件 hive-site.xml
# 拷贝一份原始文件进行修改
cp conf/hive-default.xml.template conf/hive-site.xml
vim hive-site.xml
# 修改以下内容,在VIM中使用 / 可以搜索,按N是下一个
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://Commit-Master:3306/hive?createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>1qaz@WSXcomit</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
然后将hvie-site.xml中的${system:java.io.tmpdir}全部替换为/usr/local/hive/tmp,将${system:user.name}全部替换为${user.name}。这个tmp目录没有的话则自行创建。
还需要下载与mysql的连接器mysql-connector-java-8.0.17.jar把连接器放在hive的目录的lib目录下。
并且复制一份mysql-connector-java-8.0.17.jar到spark/jars目录中,然后把hive-site.xml 复制一份到spark目录的conf中,并且spark那里的hive-site.xml只保留以下配置:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://Commit-Master:3306/hive?createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>1qaz@WSXcomit</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
</configuration>
这里是解决上面写的第二和第三个问题因为使用spark sql的时候,是连接hive的,如果不这么配置,那么使用spark sql的时候,与hive的数据就不能同步了。并且,如果整个配置复制过来,打开pyspark或者spark-shell就会出现一堆下面这个警告(看着真吓人):
WARN conf.HiveConf: HiveConf of name hive.xxxx.xxxx.xxxx does not exist
WARN conf.HiveConf: HiveConf of name hive.xxxx.xxxx.xxxx does not exist
WARN conf.HiveConf: HiveConf of name hive.xxxx.xxxx.xxxx does not exist
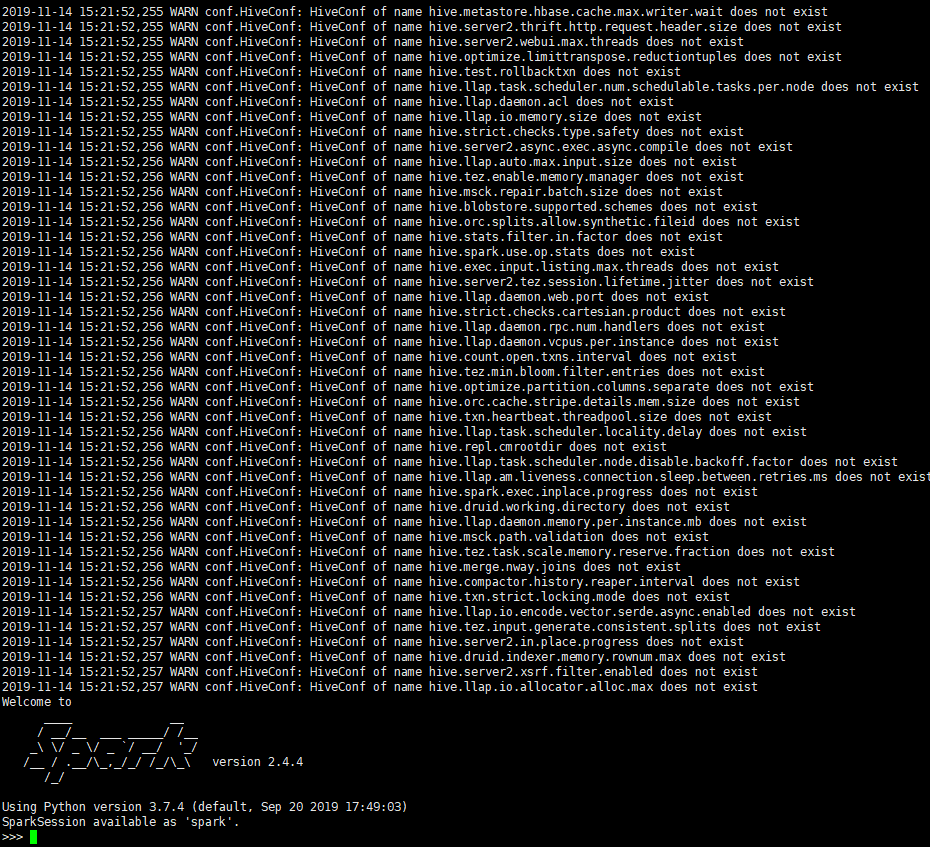
我真的想去问问那些在网上写文章说整个配置文件复制过去spark的人????,难道你们不报这些警告的吗?还是他们的是旧版的hive,配置文件里面就几个关键配置而已。。
简单来讲我觉得出现这些警告是因为spark启动的时候会检查对hive的配置,他只关注几个关键的配置,其他无关的配置他会识别不了,所以一通警告说找不到,那么你只要保留关键的配置就行了。
# 保存好之后初始化一下
schematool -dbType mysql -initSchema
hive --service metastore &
初始化没报错的话,在终端直接输入hive就可以打开hive了。
这时当你打开hive的时候,应该是这样的:

# warn
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hive/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/usr/local/hive/lib/hive-common-2.3.6.jar!/hive-log4j2.properties Async: true
这里的第一行其实是个警告,看下面的提示简单来讲就是hive的一个jar包与hadoop的一个jar包冲突了,其实你不去理他其实应该也是能用的,但是我有点强迫症,所以我还是搞了一下????
直接把上面提到的/usr/local/hive/lib/ 下的log4j-slf4j-impl-2.6.2.jarjar包删掉,就可以了,然后你重新启动一下hive就会变成下图这样:

到这里就已经完成配置了,如果大家对文章有什么建议或者问题,欢迎评论区交流和指点,谢谢????。
最后
以上就是坚强诺言最近收集整理的关于ubuntu16.04 Hive安装配置的全部内容,更多相关ubuntu16.04内容请搜索靠谱客的其他文章。








发表评论 取消回复