索引
- 中文乱码问题的由来(个人理解)
- 常用字符集
- ASCII
- ISO8859-1
- GB2312和GBK
- Unicode
- UTF-8
- Unicode和UTF-8转换的规则
- java平台乱码分析
- 查看本地字符集
- 查看“中”的Unicode编码转换为GBK编码
- GB2312—Unicode—GBK
- Web系统各个组件的默认字符集
- Web请求响应的字符集转换
- POST乱码的解决方案
- 对于JSP页面
- GET乱码的解决方案
- 数据库中存储和读取中文乱码的解决方案
- java程序在不同平台下中文输出乱码的解决方案
中文乱码问题的由来(个人理解)
计算机中,只有二进制数。不同字符对应二进制的规则,就是字符的编码。字符编码的集合成为字符集。
举例:
字符 ’宋‘ 字,在A字符集下对应 二进制 002552 ,在B字符集下对应 二进制 5533544,
在发送端 , '宋’ 被映射成 002552,然后通过网络或其他方式传输二进制比特流。
在接收端 ,接受比特流 002552,但是接收端不知道 A字符集,而直接以本地 B字符集 进行映射,002552在 B字符集中 可能并不是 字符 ‘宋’
正确的处理方式
1 发送端和接收端使用相同的字符集
2 在接收端 进行发送端字符集到接收端字符集的编码转换
常用字符集
ASCII
特点
- 8位二进制数表示字符
- 最到位是0
- 相应的十进制数 0-127 ,表示128个字符
- 另有128个扩展的ASCII码,最高位是1,由一些图形和划线符组成。
比如,字符‘0’ 的编码用十进制表示 48
ISO8859-1
特点
- 0-127与ASCII相同
- 一个字节表示
- 总共有 15个版本, ISO8859-1、 ISO8859-2,···, ISO8859-15
其中最常用的是, ISO8859-1,通常叫做 Latin-1,包括了书写所有西方欧洲语言不可缺少的附加字符。
GB2312和GBK
特点(GB2312)
- 国家标准
- 两字节表示一个字符
- 和ASCII区别,中文字符的每一个字节的最高位是1
- 编码范围,高位0xa1-0xf1,低位0xa1-0xfe,汉字从0xb0a1,结束于0xf7fe
GBK完全兼容GB2312,编码范围0x8140-0xfefe,包含20902个汉字。
Unicode
特点
- 使用 0-65535 的双字节无符号数对每一个字符进行编码
- 0-255与ISO8859-1 的一致
- 对英文字符采取前面加‘0’字节的策略实现等长兼容,如 a ,ASCII码为 0x61 ,unicode码就为0x00 0x61。
目前已经定义了40000多个,剩余25000个空缺留待将来扩展,其中,汉字大约20000个字符,韩语字节11000左右
UTF-8
对于unicode所有字符采用双字节编码,在网络上,大量字符都是英文,如果采用unicode,数据量太大。
特点
- 全称:Eight-bit UCS Transformation Format(UCS,Universal Character Set,通用字符集,UCS是所有其他字符集标准的一个超集)
- 通用字符,如0-127的ASCII码,UTF-8使用一个字节,和ASCII完全一致。
| Unicode | UTF-8 |
|---|---|
| 0x0000-0x007f | 0x00-0x7f |
| 0x0080-0x007f | 两个字节 |
| 0x0800-0xffff | 三个字节 |
中文字符在0x0800-0xffff之间,对用utf-·8是三个字节,数据量增大50%。
Unicode和UTF-8转换的规则
| Unicode(16 bit) | UTF-8 |
|---|---|
| 前 9 位是0,正好是ASCII码中的 | 一个字节 首位 0 剩下 7位相同 |
| 前 5 位是0 , | 两个字节,110+去5个0的高5位+10+低6位 |
| 不符合上面情况 | 三个字节,1110+高4位+10+中间6位+10+低六位 |
java平台乱码分析

查看本地字符集
String charSet=System.getProperty("sun.jnu.encoding");
System.out.println(charSet);
//我的机子输出GBK
查看“中”的Unicode编码转换为GBK编码
String str = "中";
byte[] b=null;
try {
b = str.getBytes(charSet);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
System.out.println("出错了");
}
for (int i = 0; i < b.length; i++) {
System.out.printf("%x ",b[i]);
}
//我的机子输出 d6d0
GB2312—Unicode—GBK
byte[] buf={(byte)0x81,(byte)0x40,(byte)0xb0,(byte)0xa1};
String str2;
try {
// GB2312编码转换为Unicode编码
str2 = new String(buf, "GB2312");
for (int i = 0; i < str2.length(); i++) {
char ch=str2.charAt(i);
//获得每个字符的Unicode编码
String hex=Integer.toHexString((int)ch);
System.out.print(hex);
System.out.print("==");
//Unicode编码转换为GBK(本地字符集) 没有就出现 ?
System.out.println(ch);
}
System.out.println();
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//我的机子输出
//fffd==�
//40==@
//554a==啊
原因:比如GBK的编码值0x8140,从GBK小Unicode转换,由于0x8140不在GB2312字符集的编码范围(0xa1a1-0xfefe),当然没有对应的字符,转换后会得到0xfffd.
Web系统各个组件的默认字符集
- 浏览器往往使用本地默认字符集提交数据
- Web容器默认采用ISO-8859-1的编码方式解析POST数据,可能产生乱码
- 大多数数据库的JDBC驱动程序默认使用ISO-8859-1的编码方式在Java程序和数据库之间传递数据,我们向数据库中存储包括中文的数据时,Unicode编码转换为ISO-8859-1编码,可能乱码。
- 目前流行的数据库系统都支持数据库编码,所以也可能发生字符集的转换。
Web请求响应的字符集转换
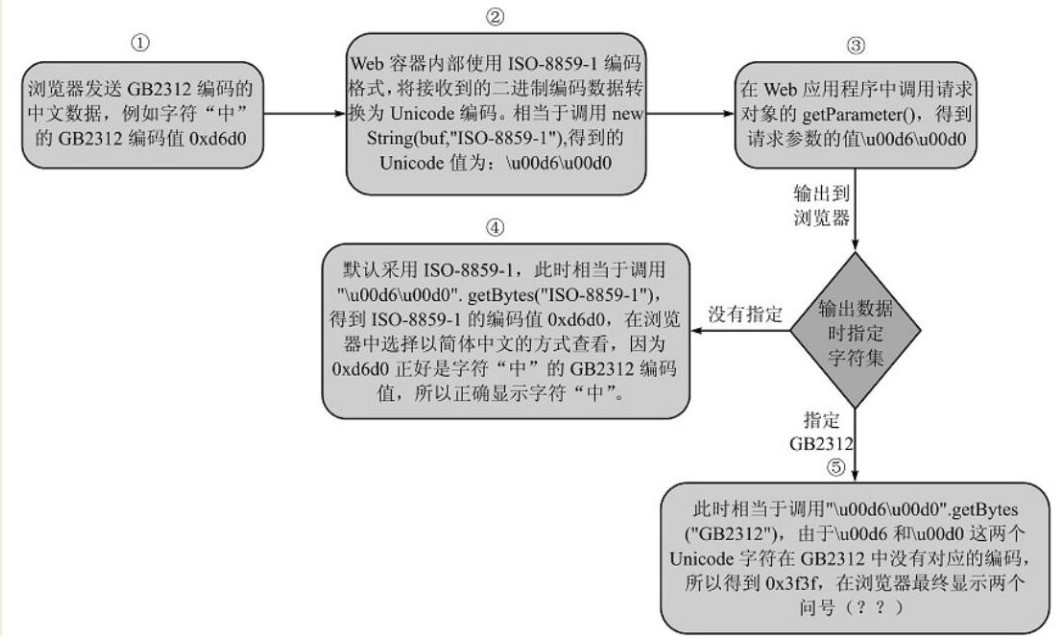
POST乱码的解决方案
request.setCharacterEncoding("GBK");
response.setContentType("text/html;charset=GBK");
对于JSP页面
<% request.setCharacterEncoding("GBK");%>
<% page contentType="text/html;charset=GBK" %>
GET乱码的解决方案
String name=request.getParameter("name");
name=new String(name.getBytes("ISO-8859-1"),"GBK"); //转换到传送过程中的比特流,在用正确的字符集转换。
数据库中存储和读取中文乱码的解决方案
利用JDBC存储数据是,首先Unicode编码变换为ISO-8859-1编码,然后把二进制编码存到数据库中。但是数据库也有自身的字符集,因此就出现了中文乱码。
解决方法:把数据库的字符集改为GBK或GB2312即可。
java程序在不同平台下中文输出乱码的解决方案
如果Java源文件没有指定编码方式,那么当在其他平台运行时,就是使用本地默认字符集输出中文。
在英文平台下,默认编码格式为ISO-8859-1,所以在执行输出时,会出现中文乱码。
解决方法:
javac -encoding GBK Hello.java
最后
以上就是饱满缘分最近收集整理的关于字符集与编码格式总结的全部内容,更多相关字符集与编码格式总结内容请搜索靠谱客的其他文章。








发表评论 取消回复