第一步:使用vim编写一个简单的C程序helloworld.c
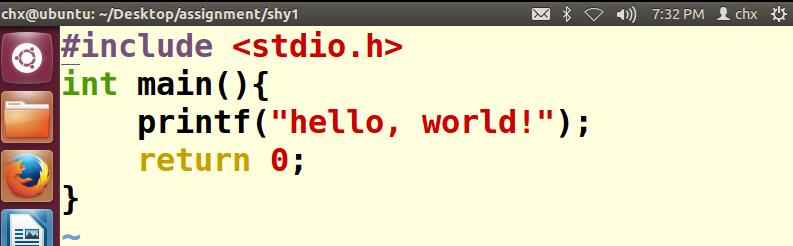
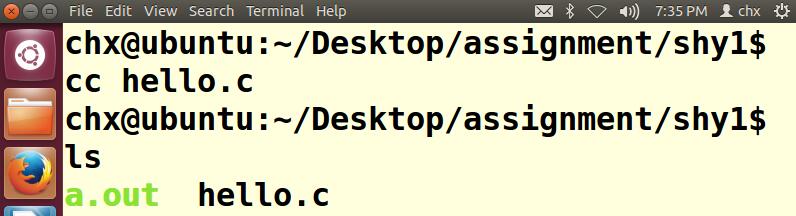
第二步:使用gcc命令编译文件
这里可以使用cc helloworld.c生成一个默认的a.out文件
(若要自定义生成文件名称,使用gcc -o filename helloworld.c,如下图,其他操作完全相同)
我们运行一下a.out文件,看一下效果

第三步:开始调试
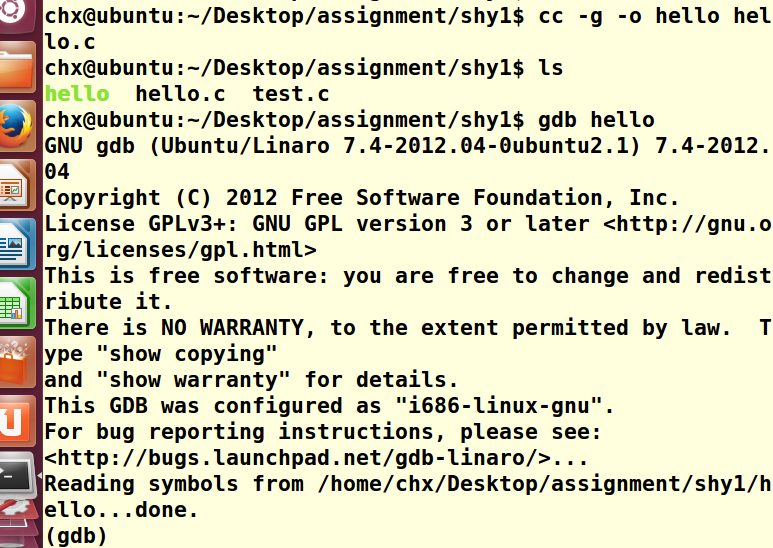
1>在编译选项中加入-g属性重新编译,使生成的a.out文件能够支持调试

2>执行gdb(GDB, the GNU Project debugger, allows you to see what is going on `inside' another program while it executes)
执行完后会有一段提示:

显示(gdb)开头就说明进入了调试模式
生词:warranty(a written guarantee, issued to the purchaser of an article by its manufacturer, promising to repair or replace it if necessary within a specified period of time.)
3>设置断点:
有两种写法
写法1:对函数进行调试
这里又有两种格式:
格式1: break function_name
格式2: break filename : function_name
写法2:对某一行进行调试(需要在vim中的命令模式下设置set nu命令显示行号)
这里也有两种格式:
格式1: break line_number
格式2: break filename : line_number
这里采用使用行号的方式添加断点:
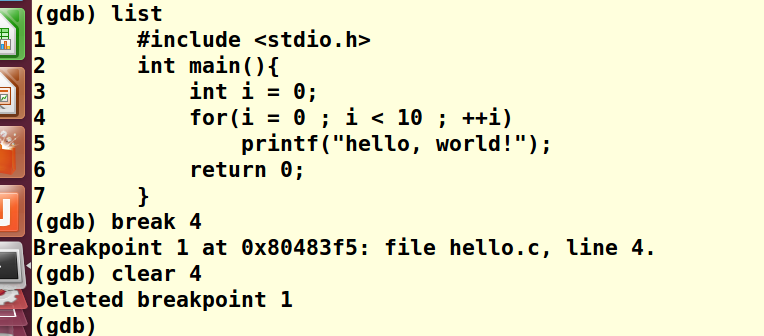
首先退出调试模式,进入hello.c查看行号

vim hello.c进入源文件,使用set nu命令显示行号,找到我们要调试的某一行
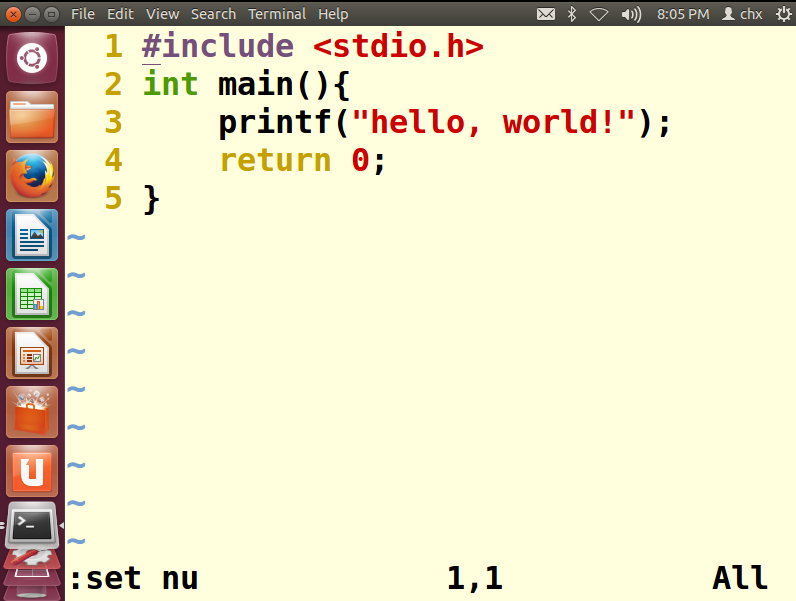
4>设置断点,在这里,尝试在第2,3行设置断点
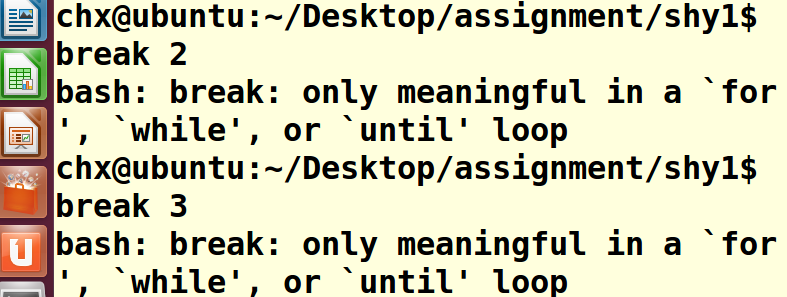
发现提示只有在for,while,utill循环中,break设置断点才有意义
vim打卡hello.c,加一个for循环
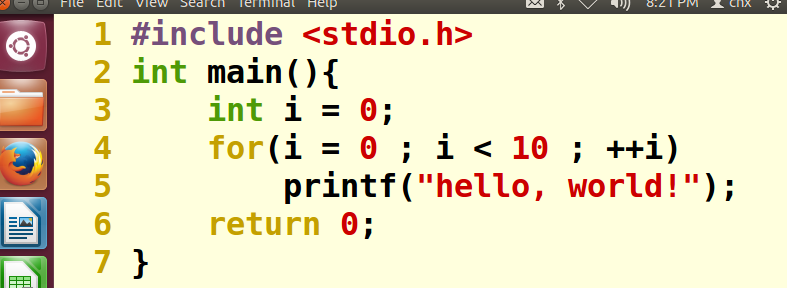
之后使用cc -g指令重新编译hello.c(重复步骤1-4)
再经过以上重复步骤之后,可以设置断点在第4行处

5>执行调试,输入r [args] 开始调试(args为可选参数)

6>监视变量值,使用 print variable_name 语句监视相应的变量

7>后续操作(常用)
类型 对应指令
print variable/address/register_name(打印变量/地址/寄存器名) p expression / print expression
step over(执行下一行,如果是函数,执行完该函数) n / next
step in(单步进入,进入函数体内部,一条条语句执行) s / step
continue(快进,跳转到下一个断点) c / continue
show code for 10 lines(从第1行开始,每调用一次展示10行代码) l / list
exit(退出调试) q / quit
help(显示帮助) h / help
show stack info(展示程序运行栈信息) bt / backtrack
delete breakpoint(删除断点) clear lineNumber
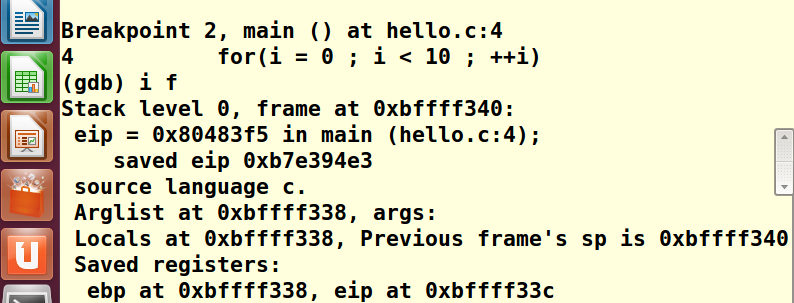
寄存器级别监视:
info register(显示寄存器信息) i f / info register (不是if 是 i f)
examine n data in format f of size s(查看内存,n条结果,f进制,每条s字节) x / nsf address (一条完整的命令, / 并不表示或)
x nfs address 命令参数说明
n : 一个正整数: 例如 1, 4, 6, 9 ...
f : 一个代表进制的符号 : 支持2/8/10/16进制 以及浮点数/字符格式
s : 一个代表每次读取几个字节的符号 : 有bwhg四种
nfs顺序问题: n必须放在前面,fs的顺序随意

参数f(format)的详细说明 :
16进制(hex):
x/a : 16进制显示变量
u : 16进制显示无符号整型
10进制(decimal):
d : 10进制显示变量
8进制(octal):
o : 8进制格式显示变量
2进制(binary):
t : 2进制格式显示变量(个人猜测是tree的缩写,而tree最常见的就是binary tree)
字符格式(char):
c : 字符格式显示变量
浮点格式(float):
f : 浮点数格式显示变量
参数s(size)的详细说明:
s对应c语言中一个很著名的内置函数sizeof,s代表的就是字节数bytes,一个字节byte规定是8个位bit
如果不指明,则默认为4bytes
参数列表:
b : 8 bits 单字节(就是一个字节)
w : 4 bytes 四字节(刚好四根线,形象)
h : 2 bytes 双字节
g : 8 bytes 八字节
使用示例:
创建一个字符数组进行检验:
x / 4bt &charStr[0] (当然这里写成charStr效果相同)
命令解释:
x / 开始读取内存操作
参数解释:
从charStr地址[参数&charStr]开始 向后每次读取半个字节(4 bits)[参数b] 以2进制方式显示[参数t] 一共读取4次[参数4]
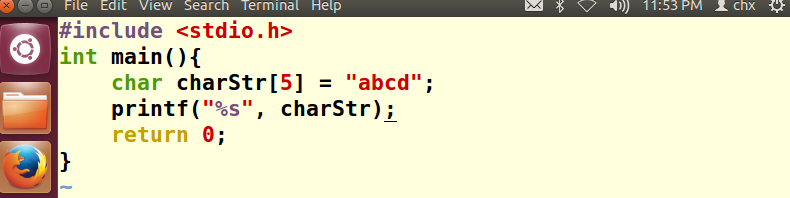
按照上面的步骤1-4进行编译,添加断点(这里发现不是循环的行也可以添加断点,不知道之前为什么报错)
编译:
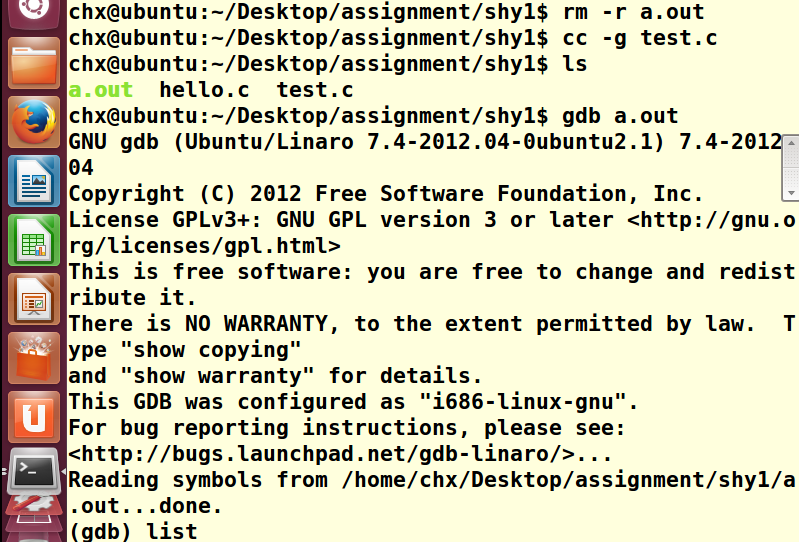
gdb命令 list显示代码 break n 在代码第n行添加断点
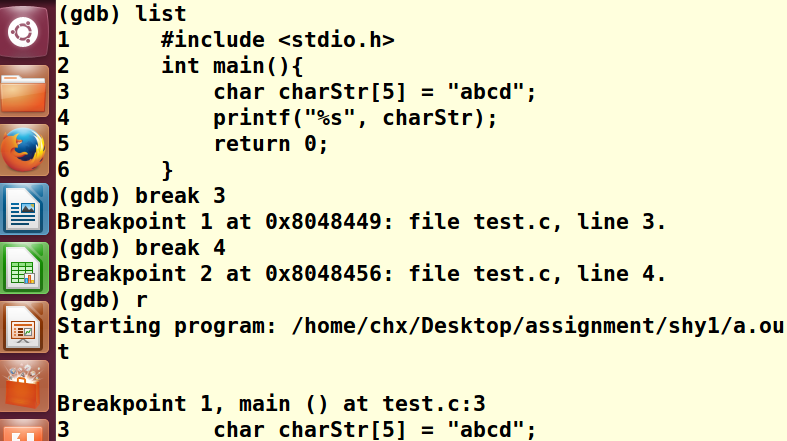
添加断点,在第3,4行,然后输入r开始Debug
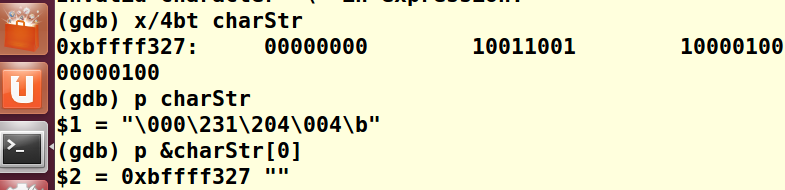
这里已经按照 x/nsf address的格式对内容进行了输出,从地址0xbffff327开始向后 读取4个单位 每个单位一个字节 以2进制输出
可以使用16进制输出,使得计算分析更加方便,即将x/4bt address 转化为 x/4bx address
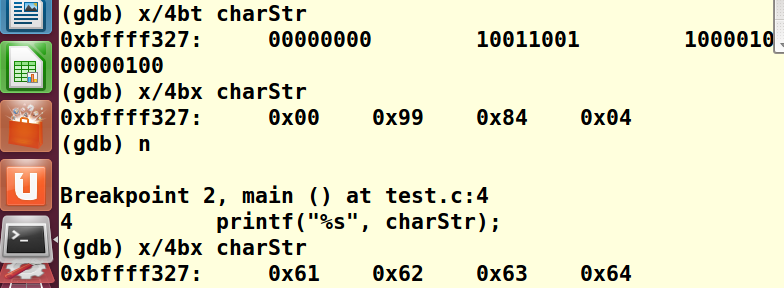
可以从上图看到四个连续字节内存对应数值分别为:
0x00 -> 0
0x99->153
0x84->132
0x04->4
这显然不符合"abcd"四个字符中的任何一个的ascii码,'a'的ascii码位97,'b'的ascii码位98,'c'的ascii码为99,'d'的ascii码位100
原因很简单,断点到这里,还没有运行,这里面的值是系统开始随机分配的值
执行(gdb) n进入下一行指令,执行当前指令,就可以完成指令
所以执行n命令之后,就可以看到赋值完成:
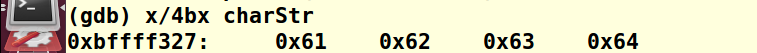
0x61->97 -->ascii 'a'
0x62->98 -->ascii 'b'
0x63->99 -->ascii 'c'
0x64->100 -->ascii 'd'
为了更直观,可以采用直接以字符的形式输出(f参数使用c)

比较容易弄混的是小端规则"高高低低"在这里貌似不成立,明明是从0xbffff327(低地址)开始到地址0xbffff32a(高地址),按照小端机器的"高高低低"的规则("高高低低"的解释:对于一个数据,例如0x12345 (16) => 10进制 1*16^4 + 2*16^3 + 3*16^2 + 4*16^1 + 5*16^0 认为左边权值大,所以是数据位的高位,右边的数据为低位)应该是高地址放高数据位数据(在字符数组中,数据高位应该是最左边的'a'字符),也就是应该在0xbffff32a这个地方放字符'a',但是使用gdb调试输出却可以发现内存的高位0xbffff32a处存放的确是字符'd'
有这种想法,其实是"高高低低"的规则没有真正理解,"高高低低"是对于一个基本数据类型而言的,在char字符数组中,基本的数据类型是char型,每个字符是一个独立的意群,自然不存在这个问题,但如果在一个int类型的内存中写入四个字符'a','b','c','d',就需要考虑这个问题,因为此时机器解码的时候,翻译自然以int整型这样一个数据类型来翻译,如果是个人电脑(小端机器),此时按照"高高低低",高地址放高有效位数据(如果想要输出的效果是"abcd"那么'a'对应最高有效位,'d'对应最低有效位),此时就应该将'a'字符放在高内存中,将'd'字符放在低内存中,也就是应该写成下面这样:
int arr[2] = {(('d')<<24+('c')<<16+('b')<<8+('a')),('�')}
printf("%s", arr);
生词: miscellaneous([ˌmisəˈlānēəs])(of items or people gathered or considered together) of various types or from different sources.)(eg: he picked up the miscellaneous papers)
例如进行单步调试:

例如清除断点:
例如显示寄存器信息:
8>查看汇编:
生词:annotate[ˈanəˌtāt]add notes to (a text or diagram) giving explanation or comment.
在查看汇编之前,先要对高级语言C的编译过程有一个认识:
从高级C语言到可执行二进制代码,需要如下步骤:
对于一个hello.c文件
1.预处理阶段
预处理器(cpp)将#之后的头文件(系统头文件如stdio.h和自定义头文件如myhead.h)对应的代码引入并直接插入程序文本中,得到另外一个更长的c语言程序,通常是以.i作为文件扩展名,即hello.i
2.编译阶段(assemble phase 1)
编译器(ccl)对第一阶段的.i为尾缀的文件翻译成汇编代码hello.s(依然属于文本文件),这里其实是各种高级语言的汇聚的地方,无论C,C++,swift,OC,C#,都会在编译阶段被翻译为通用的汇编代码
3.汇编阶段(assemble phase 2)
汇编器(as)将hello.s翻译为机器语言指令,并打包成一个二进制文件(不是文本文件,打开乱码),结果保存在目标文件hello.o中
4.链接阶段(link)
链接器(ld)将hello.o和C语言库预编译文件printf.o进行合并,得到名为hello的可执行文件,这种文件可以被加载到内存中,直接运行
查看汇编,其实就是在第二阶段进行查看以.s为尾缀的文件内容
.c -----> .i ----> .s ------> .o ----->.exe(也可以什么都不写,exe在这里仅表示这是一个可执行文件)
虽然有一键从.c --> .exe的方法,即cc hello.c但这却跳过了汇编的详细过程,需要更精细化的处理
下面处理到.s为尾缀的assemble环节:
gcc -g -S hello.c //S是大写,linux严格区分大小写
现在我们只需要打开hello.s文件,就可以查看和修改汇编代码
![]()
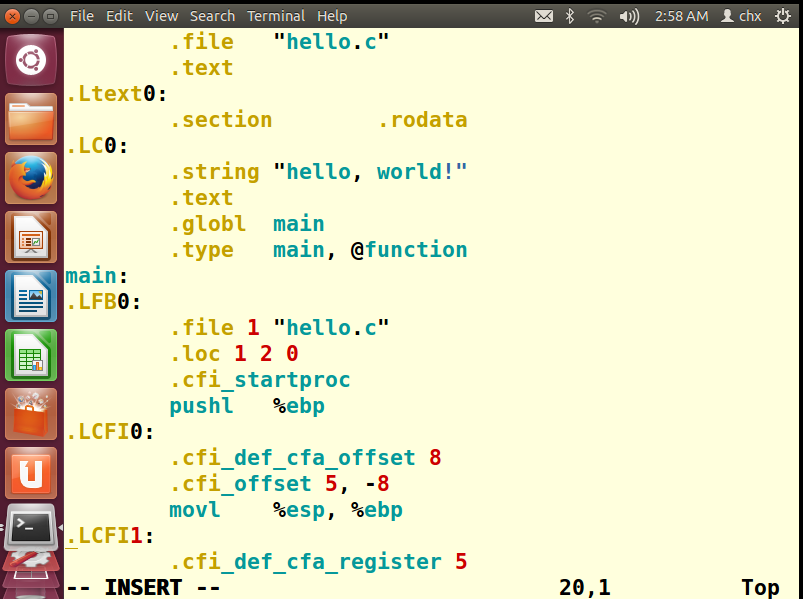
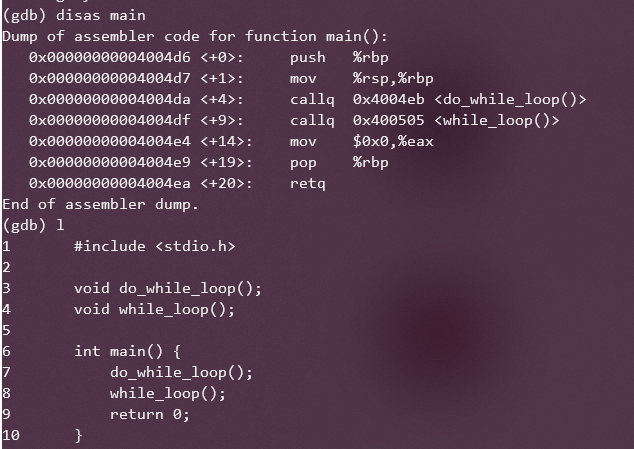
另外,可以直接在gdb中使用disas命令反汇编查看 特定的函数,使用的语法也很简单:
disas function_nameon_name例如:
通过disas main 查看main函数的反汇编代码:
__________________________________________________________________________________
本文写作过程中,参考了大量国内外书籍社区网站,以及老师的指导板书,并动手进行了实验测试,在此感谢各位前辈,恩师的付出
精力有限,错误难以避免,欢迎留言区交流指正
原创文章,转载前请咨询作者
最后
以上就是笑点低天空最近收集整理的关于[linux]linux下调试C语言程序并查看汇编代码[图文教程]的全部内容,更多相关[linux]linux下调试C语言程序并查看汇编代码[图文教程]内容请搜索靠谱客的其他文章。




![[linux]linux下调试C语言程序并查看汇编代码[图文教程]](https://www.shuijiaxian.com/files_image/reation/bcimg5.png)



发表评论 取消回复