我是靠谱客的博主 悲凉早晨,这篇文章主要介绍lambda表达式:Collector解析,方法使用Collector(重要)CollectorsCollectors 方法解析,现在分享给大家,希望可以做个参考。
Collector(重要)
- collect:收集器
- Collector:收集器的方法
- Collector:是一个接口,一种可变的汇聚操作,它将输入元素累积到可变结果容器中。在处理完所有输入元素后,可以选择将累积的结果转换为最终形式(这是一种可选操作),支持串行,并行操作
- Collectors本身提供了关于Collector的常见汇聚实现,Collectors本身实际上是一个工厂(辅助类)
- 为了确保串行与并行操作结果的的等价性,Collector函数需要满足两个条件:identity(同一性)与associativity(结合性)
- identity(同一性指中间容器类型)约束表示,对于任何部分累积的结果,将其与空的结果容器组合必须生成等效的结果。也就是说,对于任何一系列累加器和组合器调用的部分累加结果a 这时的a必须满足 a=combiner.apply(a, supplier.get()),【也就是说a数据类型跟一个空结果数据数据类型相同时 两者执行的合并结果等于本身a】
/*
combiner.apply 调用的是BinaryOperator函数 输入两个相同参数返回 相同值
a, supplier.get() 就相当于 list1,list2 执行a.addAll(supplier.get()); 当, supplier.get()(返回的结果容器)为空时
a 就等于combiner.apply(a, supplier.get())
*/
(List<String> list1, List<String> list2) -> list1.addAll(list2);
- finisher(结合性指返回结果类型)关联性约束表示,串行和并行计算必须产生等效的结果。也就是说,对于任何输入元素t1和t2,下面计算中的结果r1和r2必须相等:
A a1 = supplier.get();//得到结果容器
accumulator.accept(a1, t1); //a1执行累加中间值,t1 是流中要处理的下一个元素
accumulator.accept(a1, t2);//此时a1已经加过t1
R r1 = finisher.apply(a1); // 串行操作
A a2 = supplier.get();
accumulator.accept(a2, t1);
A a3 = supplier.get();
accumulator.accept(a3, t2);
R r2 = finisher.apply(combiner.apply(a2, a3));//各自并行操作 结果汇总
函数式编程的的最大特点:表示做什么,而不是如何做

重要方法
/**
创建并返回新的可变结果容器的函数。
A:中间可变容器储存类型
*/
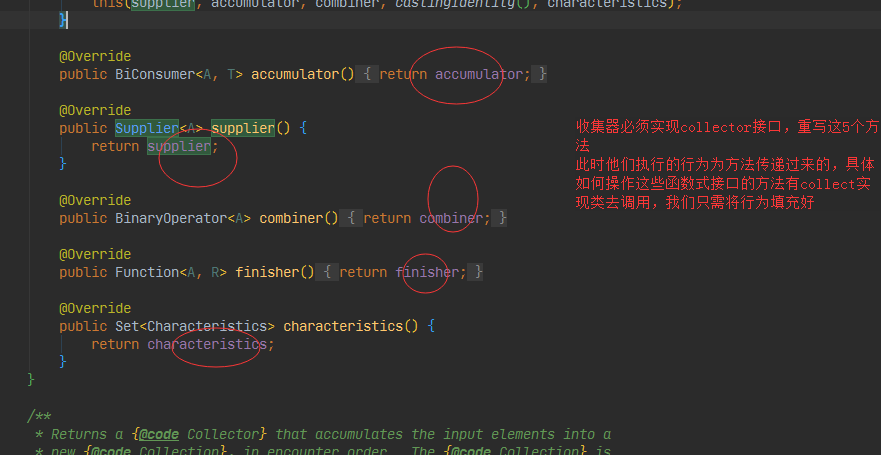
Supplier<A> supplier();
/**
将值(流元素)折叠(放到类似集合add)到可变结果容器中的函数,将新数据元素合并到结果容器中
将T 初类型放到 新A类型
(如果是串行流不会掉combiner方法)
*/
BiConsumer<A, T> accumulator();
/** 并行(多线程)
接受两个部分结果并将其合并的函数。组合器函数可以将状态从一个参数折叠(放到类似集合add)到另一个参数并返回该参数将,
或者返回一个新的结果容器(例如生成新的集合)。
A:中间可变容器储存类型
如果并行流去操作收集器此时未设置Characteristics.CONCURRENT特性时 此时会被调用(需收集多线程结果)返回行为(返回行为才算被调用)
如果设置了改特性 依然不会被调用 (此时多线程操作一个中间容器,结果都在一个中间容器中)
*/
BinaryOperator<A> combiner();
/**
执行从中间累积类型A到最终结果类型R的最终转换。
返回汇聚结果类型R
如果设置了特征IDENTITY_TRANSFORM,
则该函数可以被假定为具有从A到R的未经检查的转换的IDENTITY TRANSFORM
*/
Function<A, R> finisher();
/*
设置收集器的特性 内置枚举类型
*/
Set<Characteristics> characteristics();
/*
返回由给定的供应商(Supplier)、累加器(BiConsumer)和组合器函数(BinaryOperator)描述的新收集器。结 果收集器具有集热器特性标识饰面特点。
*/
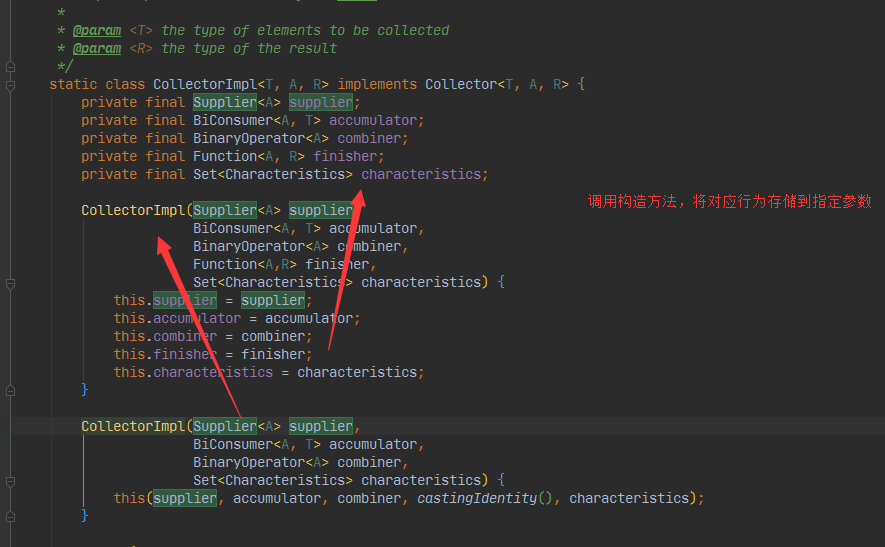
public static<T, R> Collector<T, R, R> of(Supplier<R> supplier,
BiConsumer<R, T> accumulator,
BinaryOperator<R> combiner,
Characteristics... characteristics) {
Objects.requireNonNull(supplier);
Objects.requireNonNull(accumulator);
Objects.requireNonNull(combiner);
Objects.requireNonNull(characteristics);
Set<Characteristics> cs = (characteristics.length == 0)
? Collectors.CH_ID
: Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH,
characteristics));
return new Collectors.CollectorImpl<>(supplier, accumulator, combiner, cs);
}
/*
Collectors.collectingAndThen 中间转换
将Collector<T,A,R> 收集器的到数据在进行Function<R,RR>转换,返回转换后的值
*/
public static<T,A,R,RR> Collector<T,A,RR> collectingAndThen(Collector<T,A,R> downstream,
Function<R,RR> finisher) {
Set<Collector.Characteristics> characteristics = downstream.characteristics();
if (characteristics.contains(Collector.Characteristics.IDENTITY_FINISH)) {
if (characteristics.size() == 1)
characteristics = Collectors.CH_NOID;
else {
characteristics = EnumSet.copyOf(characteristics);
characteristics.remove(Collector.Characteristics.IDENTITY_FINISH);
characteristics = Collections.unmodifiableSet(characteristics);
}
}
return new CollectorImpl<>(downstream.supplier(),
downstream.accumulator(),
downstream.combiner(),
downstream.finisher().andThen(finisher),
characteristics);
}
enum Characteristics {
/**
指示此收集器是并发的,这意味着结果容器可以支持与来自多个线程的同一中间结果容器同时调用的累加器函数。
如果并发收集器也不是无序的,则仅当应用于无序数据源时,才应并发计算该收集器。
(并行,多个线程操作唯一一个中间结果容器)
*/
CONCURRENT,
/**
* 指示集合操作不承诺保留输入元素的相遇顺序。
* (如果结果容器没有内在顺序(如集合),则可能是这样。(不排序)
*/
UNORDERED,
/**
表示finisher函数就是identity函数,可以省略。
如果设置了该枚举参数 就是告诉间容器类型和返回类型一致
底层源码从A到R的未检查强制转换是否合理,也就是说设置这个参数必须中间容器类型和返回类型
必须一致
*/
IDENTITY_FINISH
}
例:of方法如何创建
/*
Widget 元素类型,?:中间类型,TreeSet<Widget> 返回结果类型
TreeSet::new 新生成的类型容器
TreeSet::add 每个元素累积 最终容器
(left, right) -> { left.addAll(right); return left; }
将累加的每个中间集合合并一起 合并完返回
*/
Collector<Widget, ?, TreeSet<Widget>> intoSet =
Collector.of(TreeSet::new, TreeSet::add,
(left, right) -> { left.addAll(right); return left; });
等于 toCollection(Supplier)
等价
R container = collector.supplier().get();//执行TreeSet::new 行为
* for (T t : data)
* collector.accumulator().accept(container, t);//执行TreeSet::add行为
* return collector.finisher().apply(container);//执行(left, right) -> { left.addAll(right); return left; } 行为
Collectors
实现各种有用的汇聚操作的收集器Collector的实现,如将元素累加到集合中、根据各种条件汇总元素等。
public class Student {
private String username;
private int score;
public Student(String username, int score) {
this.username = username;
this.score = score;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public String toString() {
return "Student{" +
"username='" + username + ''' +
", score=" + score +
'}';
}
}
示例
public class StreamTest1 {
public static void main(String[] args) {
Student student1 = new Student("zhangsan", 80);
Student student2 = new Student("lisi", 90);
Student student3 = new Student("wangwu", 100);
Student student4 = new Student("zhaoliu", 90);
Student student5 = new Student("zhaoliu", 90);
List<Student> list = Arrays.asList(student1, student2, student3, student4, student5);
// List<Student> collect = list.stream().collect(toList());
// collect.forEach(System.out::println);
//
// System.out.println("count=" + list.stream().collect(counting()));
// System.out.println("count=" + list.stream().count());
//
// list.stream().min(Comparator.comparingInt(Student::getScore)).ifPresent(x -> System.out.println(x.getScore()));
System.out.println("==========");
list.stream().collect(Collectors.minBy(Comparator.comparingInt(Student::getScore))).ifPresent(x -> System.out.println(x.getScore()));
list.stream().collect(Collectors.maxBy(Comparator.comparingInt(Student::getScore))).ifPresent(x -> System.out.println(x.getScore()));
System.out.println(list.stream().collect(Collectors.averagingDouble(x -> x.getScore())));
System.out.println(list.stream().collect(Collectors.summingInt(x -> x.getScore())));
System.out.println(list.stream().collect(Collectors.summarizingInt(x -> x.getScore())));
System.out.println("=====");
System.out.println(list.stream().map(Student::getUsername).collect(Collectors.joining()));
System.out.println(list.stream().map(Student::getUsername).collect(Collectors.joining(",")));
System.out.println(list.stream().map(Student::getUsername).collect(Collectors.joining(",", "开始", "结束")));
System.out.println("=====");
/*
先根据分数进行分组,分组完的的数据在通过名字进行分组
*/
Map<Integer, Map<String, List<Student>>> collect = list.stream()
.collect(Collectors.groupingBy(Student::getScore, Collectors.groupingBy(Student::getUsername)));
System.out.println(collect);
System.out.println("=====");
//分区
Map<Boolean, List<Student>> collect1 = list.stream().collect(Collectors.partitioningBy(x -> x.getScore() > 80));
System.out.println(collect1);
Map<Boolean, Map<Boolean, List<Student>>> collect2 = list.stream().collect(Collectors.partitioningBy(x -> x.getScore() > 80, Collectors.partitioningBy(y -> y.getScore() > 90)));
System.out.println(collect2);
System.out.println("=========");
/*
统计分数》80的学生 通过分数进行分组 取出来每个分组总个数
*/
Map<Integer, Long> collect3 = list.stream().filter(x -> x.getScore() > 80).collect(Collectors.groupingBy(Student::getScore, Collectors.counting()));
System.out.println(collect3);//{100=1, 90=3}
System.out.println("==========");
/*
根据名字进行分组,在去得到学生最小分数
minBy 返回的数据是Optional 类型 流中数值可能为空
Collectors.collectingAndThen 中间转换 将收集器的到数据在进行转换,返回转换后的值
*/
list.stream().
collect(Collectors.groupingBy(Student::getUsername, Collectors.minBy(Comparator.comparingInt(Student::getScore))));
Map<String, Student> collect4 = list.stream().
collect(Collectors.groupingBy(Student::getUsername,
Collectors.collectingAndThen(Collectors.minBy(Comparator.comparingInt(Student::getScore)), Optional::get)));
System.out.println(collect4);
}
}
Collectors 方法解析
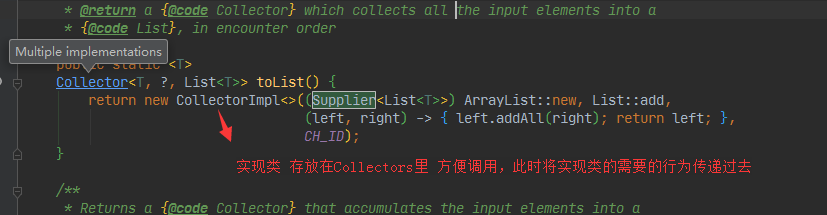
例如toList,其他方法大同小异
public static <T>
Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add,
(left, right) -> { left.addAll(right); return left; },
CH_ID);
}
最后
以上就是悲凉早晨最近收集整理的关于lambda表达式:Collector解析,方法使用Collector(重要)CollectorsCollectors 方法解析的全部内容,更多相关lambda表达式:Collector解析,方法使用Collector(重要)CollectorsCollectors内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复