对于大文件数据进行排序,一般都是采用外排序进行处理,其处理步骤大致为:
1、从大文件中读取一部分数据,进行内存排序,将排序后的结果生产中间文件。
2、将已经排序的中间文件进行归并,最终获得整个大文件的排序结果。
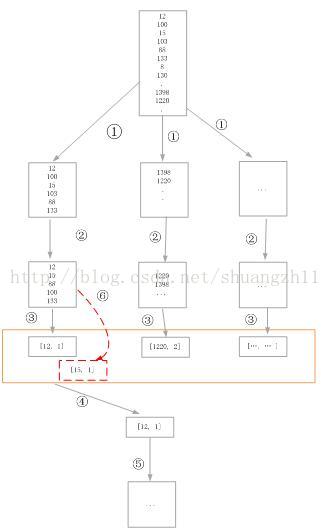
采用Groovy 实现代码如下:
static guibin() {
def datafile = "dat.txt" //输入文件名
int per = 10, no = 0, count = 0 //per:每次取出来的数字个数, no:生成的中间文件序号, count:行数记数
def wfiles = [], wfreads = [], wlist = [] //wfiles:中间文件名, wlist:临时数组
new File(datafile).eachLine { line ->
count++
if (line) {
wlist << line.toInteger() //读取数据,存储到wlist数组中
if (count % per == 0) {
wfiles << ("out" + no) //将wlist中的数据排序,并写入到中间文件中。
new File("out" + no).withPrintWriter { p ->
wlist.sort().each { it -> p.println(it) }
}
no++ //中间文件序号增加
wlist.clear()
}
}
}
//处理末尾数据
if (wlist) {
wfiles << ("out" + no)
new File("out" + no).withPrintWriter { p ->
wlist.sort().each { it -> p.println(it)}
}
}
// 打开所有中间文件
wfiles.each { it -> wfreads << new File(it).newReader() }
def sels = [] //比较数组
//将每个中间文件的第一个数组读入到sels数组中
wfreads.eachWithIndex { it, i ->
def l = it.readLine()
if (l) {
sels << [l.toInteger(), i]
}
}
//打开结果文件
def pout = new File("result").newPrintWriter()
while (sels) { //选出最小的数字写入结果文件,并读入新的数据。循环执行,进行数据归并。
def min = sels.min { a, b ->
if (a[0] - b[0] > 0)
return 1
if (a[0] == b[0])
return 0
return -1
}
sels.remove(min)
pout.println(min[0])
def nl = wfreads[min[1]].readLine()
if (nl) {
min[0] = nl.toInteger()
sels << min
}
}
pout.close()
wfreads.each { it.close() }
}借助Groovy的数组和文件处理能力, 整个代码不到60行,非常简单就实现了大文件的外排序。
最后
以上就是迅速小蜜蜂最近收集整理的关于使用groovy进行大文件外排序的全部内容,更多相关使用groovy进行大文件外排序内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复