KafkaProducer 的实现是线程安全的,所以我们可以在多线程的环境下,安全的使用 KafkaProducer 的实例。
1.创建主题concurrent-test
./kafka-topics.sh --zookeeper localhost:2181 --create --topic concurrent-test --replication-factor 1 --partitions 8

2.添加常量
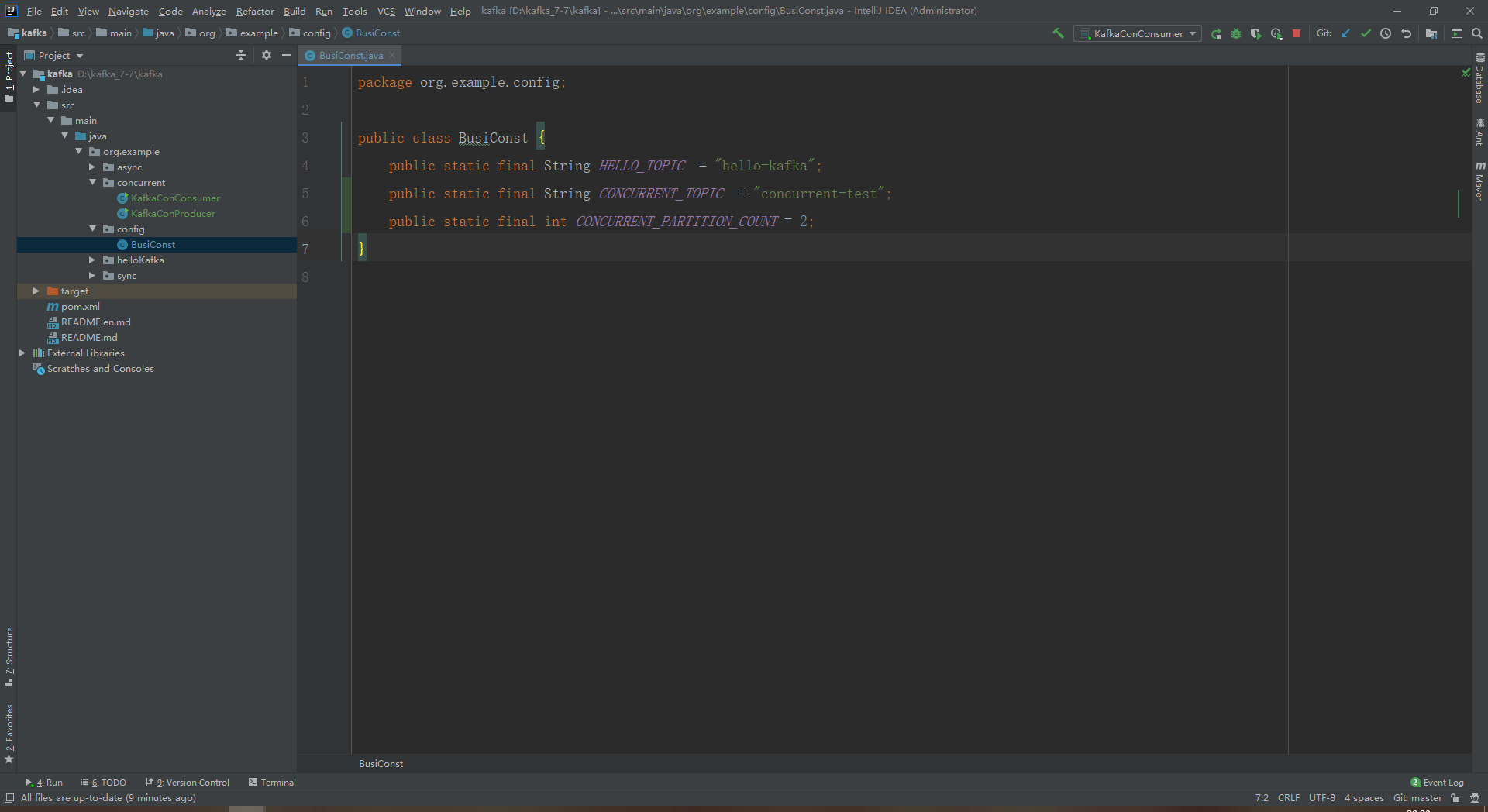
package org.example.config;
public class BusiConst {
public static final String HELLO_TOPIC = "hello-kafka";
public static final String CONCURRENT_TOPIC = "concurrent-test";
public static final int CONCURRENT_PARTITION_COUNT = 2;
}
3.创建生产者KafkaConProducer
package org.example.concurrent;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import org.example.config.BusiConst;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 多线程下生产者
**/
public class KafkaConProducer {
//发送消息个数
private static final int MSG_SIZE = 1000;
//负责发送消息的线程池
private static ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
private static CountDownLatch countDownLatch = new CountDownLatch(MSG_SIZE);
private static class ProducerWorker implements Runnable {
private ProducerRecord<String, String> record;
private KafkaProducer<String, String> producer;
public ProducerWorker(ProducerRecord<String, String> record, KafkaProducer<String, String> producer) {
this.record = record;
this.producer = producer;
}
@Override
public void run() {
final String id = Thread.currentThread().getId() + "-" + System.identityHashCode(producer);
try {
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {
e.printStackTrace();
}
if (recordMetadata != null) {
System.out.println("offset:" + recordMetadata.offset() + ";partition:" + recordMetadata.partition());
}
}
});
System.out.println(id + ":数据[" + record + "]已发送。");
countDownLatch.countDown();
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.42.111:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
try {
for (int i = 0; i < MSG_SIZE; i++) {
ProducerRecord<String, String> record = new ProducerRecord<String, String>(
BusiConst.CONCURRENT_TOPIC, null, System.currentTimeMillis(), String.valueOf(i), "Fisher" + i);
executorService.submit(new ProducerWorker(record, producer));
}
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
producer.close();
executorService.shutdown();
}
}
}
4.创建消费者KafkaConConsumer,为了保证线程安全, 使用KafkaConsumer的实例要小心,应该每个消费数据的线程拥有自己的KafkaConsumer实例
package org.example.concurrent;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.example.config.BusiConst;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 多线程下使用消费者,需要一个线程一个消费者
**/
public class KafkaConConsumer {
private static ExecutorService executorService = Executors.newFixedThreadPool(BusiConst.CONCURRENT_PARTITION_COUNT);
private static class ConsumerWorker implements Runnable{
private KafkaConsumer<String, String> consumer;
//使用KafkaConsumer的实例要小心,应该每个消费数据的线程拥有自己的KafkaConsumer实例
public ConsumerWorker(Properties properties, String topic) {
this.consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Collections.singletonList(topic));
}
@Override
public void run() {
final String id = Thread.currentThread().getId() + "-" + System.identityHashCode(consumer);
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(5000));
for (ConsumerRecord record : records) {
System.out.println("do something");
System.out.println(id+"|主题"+record.topic()+",分区"+record.partition()+
",偏移量"+record.offset()+",key:"+record.key()+",value:"+record.value());
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
}
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.42.111:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "concurrent");
for (int i = 0; i < BusiConst.CONCURRENT_PARTITION_COUNT; i++) {
executorService.submit(new ConsumerWorker(properties, BusiConst.CONCURRENT_TOPIC));
}
}
}
5.先启动消费者,再启动生产者
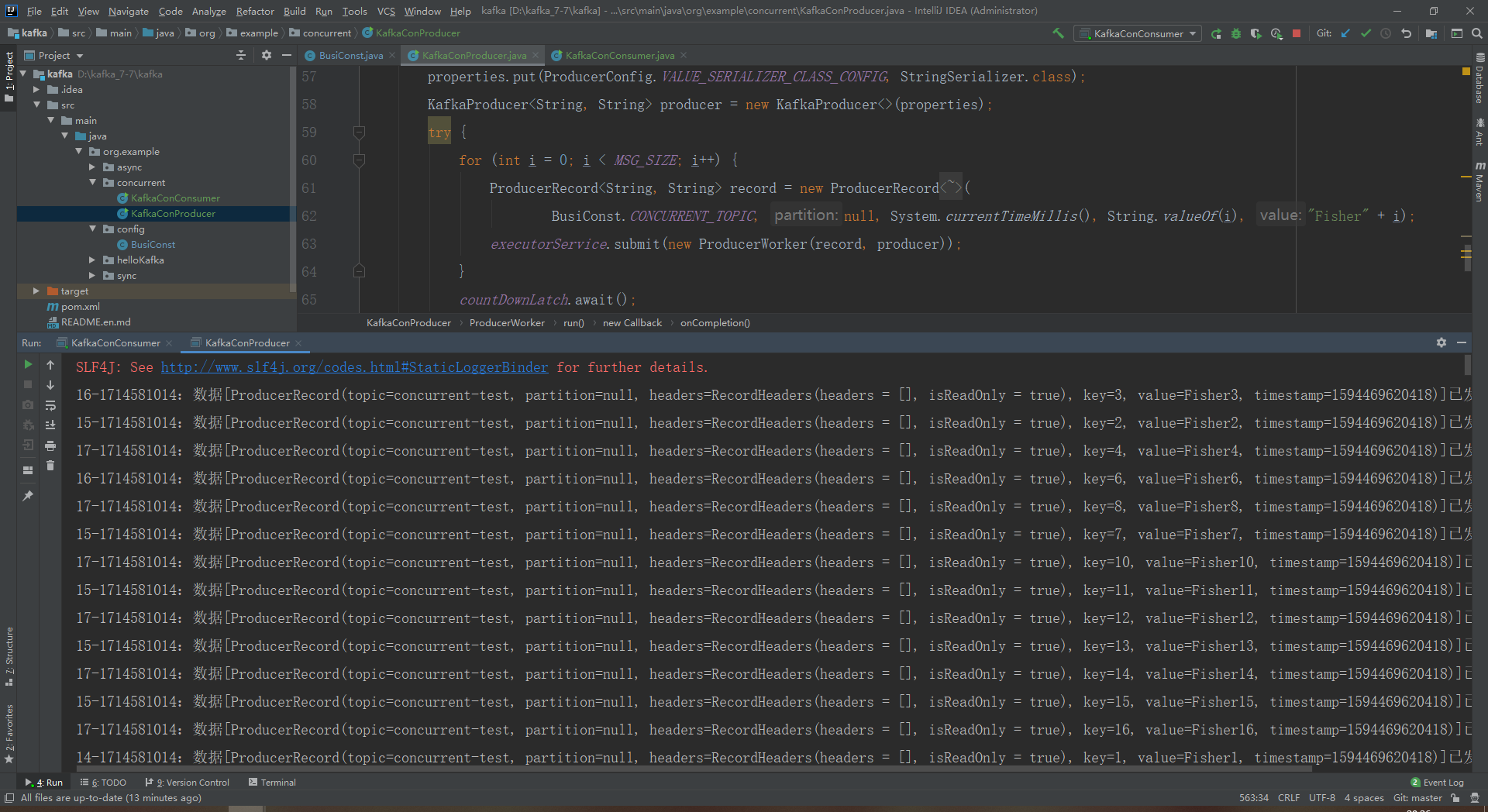
6.查看消费者打印
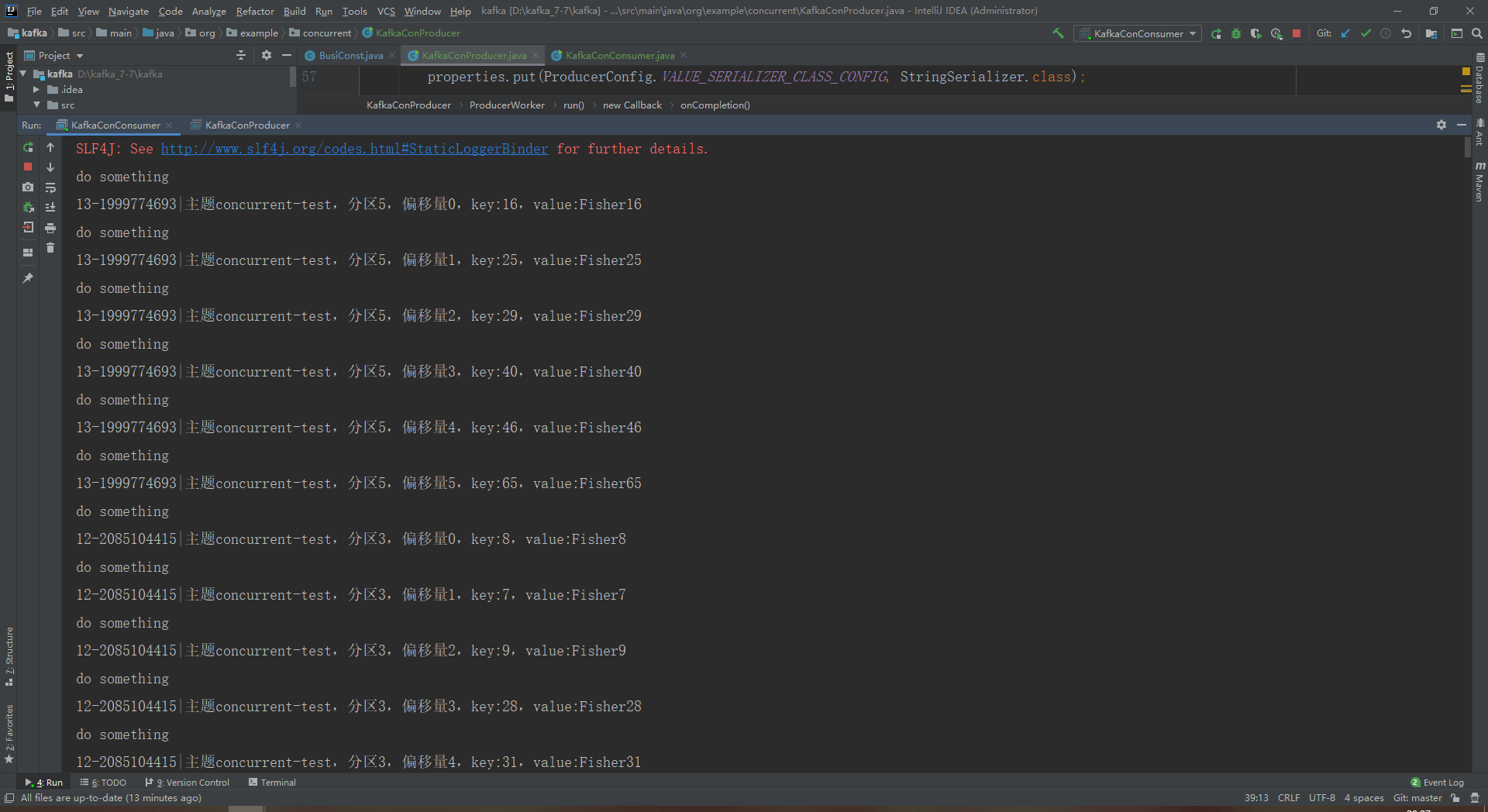
最后
以上就是温婉毛豆最近收集整理的关于Kafka 4:多线程下的生产者的全部内容,更多相关Kafka内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复