电脑城一楼杀马特造型的装机小子对着你一顿电脑型号专有名词狂射,RTX2070 WF3,i7-9700K,ASUS B360M PIXIU…,你就跟他去了吗?其实,他们什么也不懂,他们背诵的那些东西,给你两个小时你就能背诵。
缘起
马上就要放假了,又是一年结束了。对自己2018年底关于IPv6的工作还算满意,殊不知早在2012年自己就已经接触并开始Hack关于IPv6的问题了。
早上上班的班车由于要走14公里多的紫之隧道,漆黑一片无法看书,无奈只能看手机,搜到了自己的一篇关于IPv6的文章,遂分享到了朋友圈,但细读之,发现意犹未尽,于是想深入拓展一下,便成此文。
正文
本文是接着前面一篇2012年文章写的:
闲谈IPv6-聚类和浪费:https://blog.csdn.net/dog250/article/details/8172678
在RFC791(https://tools.ietf.org/html/rfc791)定义了IP协议的那个年代,人们对于IP地址将来会被如何使用是没有概念的,当时的人们是完全想不到 地址不够用 这件事的。
在全球只有几十几百台计算机需要互联的年代,万级别的计算机互联网络规模都是天文数字了。但即便如此, “富有前瞻性” 的IETF团队还是定义了32位的IPv4地址空间,没错,43亿多个地址!
RFC791定义于1981年,1981年初,世界总人口为44亿左右,这意味着IPv4可以为几乎每一个地球人提供一个IP地址以接入全世界规模的网络,这在乔布斯他们还躲在车库里接线焊板子的年代是无法想象的!
有了IPv4地址空间,分配地址以及寻址就是接下来的事了。
鉴于美国在当时计算机网络领域压倒性的技术优势和政策优势,IPv4协议几乎就是美国人自己为自己设计的网络互联协议。
最初,IPv4的整个地址空间被 平坦划分为了A,B,C,D,E这五类 ,而美国则牢牢掌握着A类地址全部以及B类地址大部分的分配权限,以至于海量的A类,B类地址被分配在美国,留给亚太地区的则只剩下少数的B类地址和C类地址。
再看路由原则,在基于五个类别的IP编址年代,路由查找也是严格基于类别来的,至于说最长前缀匹配算法,那是CIDR之后的事情了,并非IP协议与生俱来的。也就是说,如果一个机构被分配一个A类地址空间段,那么这个空间段里的所有地址必须全部由一个路由项指向,下面的情况是不被允许的:
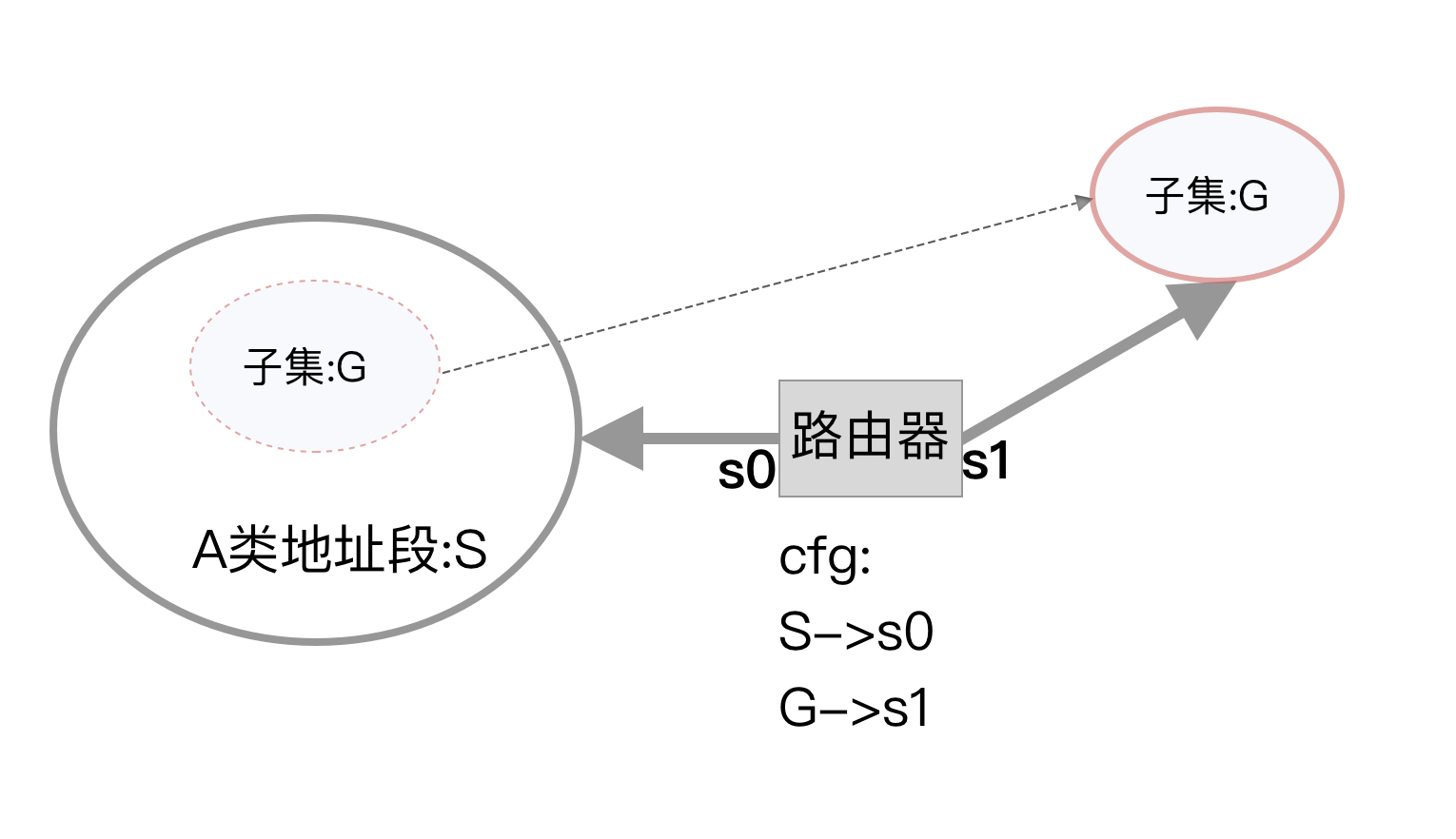
关于有类寻址的一些内容,可以看看这篇:
彻底理解Cisco/Linux/Windows的IP路由: https://blog.csdn.net/dog250/article/details/10780281
现在,问题出现了,A类地址的地址空间非常大,几乎没有几个美国的机构可以用完其每一个IP地址,这将会造成巨大的IP地址浪费,鉴于此,CIDR就被提出来了,也就是无类寻址方案,在VLSM下的最长前缀匹配算法就成了此后路由查找的标准算法,一直延续到了现在。
CIDR在某种程度上解决了IPv4地址浪费的问题,但是无法解决其地址空间只有43亿个地址的问题…
只有43亿?这难道是问题吗?43亿不够吗?
后面的故事大家就都知道了,43亿远远不够,如果每人一部手机,现在世界人口已经60亿了,地址不够,如果每部车再来个IP,如果有人有两部手机…好吧,IPv6能彻底解决地址不够用的问题。
但是只是故事的前半章,在进入IPv6编址和寻址之前,我们再来看看故事的下半章。
在分类寻址年代,上面那幅图是不被允许的,然而到了CIDR年代,它就被允许了,这种CIDR机制助长了IP地址随意售卖行为。于是,美国一些当初获得A类地址段的机构或者运营商,作为Tier 1 top机构,会把自己用不完的地址从巨大的A类空间段中抠出来一小段一小段的,卖给地理上距离遥远的大洋彼岸的需要IP地址的国家,机构或者个人,完全是一种商业行为。
但是,这种随意分配地址的方式,会对路由器的路由表造成巨大的压力,路由表项会激增。只要你从路由器的一边抠出一段地址,分配给了路由器的另一边,就需要增加一个路由表项:
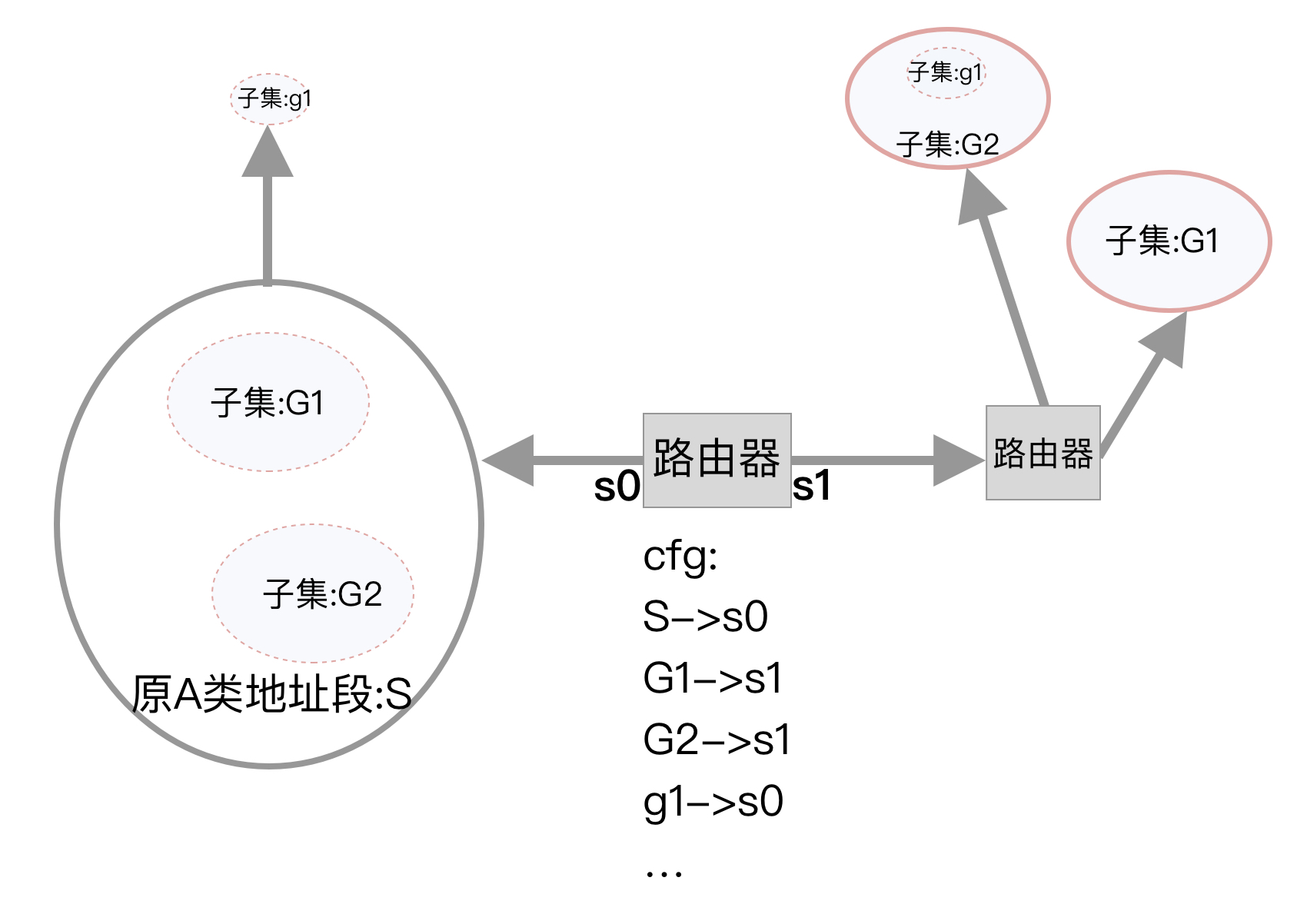
随着这种随意分配地址行为的进行,核心路由器上表项达到了50万+,这压力最终落到了路由查找算法上。
遍历50万+条路由表项并执行match,需要的是秒级的时间,这对于数据包转发而言是绝对不可忍受的,因此必须采用更加高效的数据结构,比如hash,比如查找树等等。
说到这里,我想再说一个事,那就是全球网络拓扑,路由表,路由查找算法的关系。
先从上图说起,如果我们不想增加路由项怎么办?其实还是有办法的,那就是把地址抠出来的同时,顺便拉一条专线:
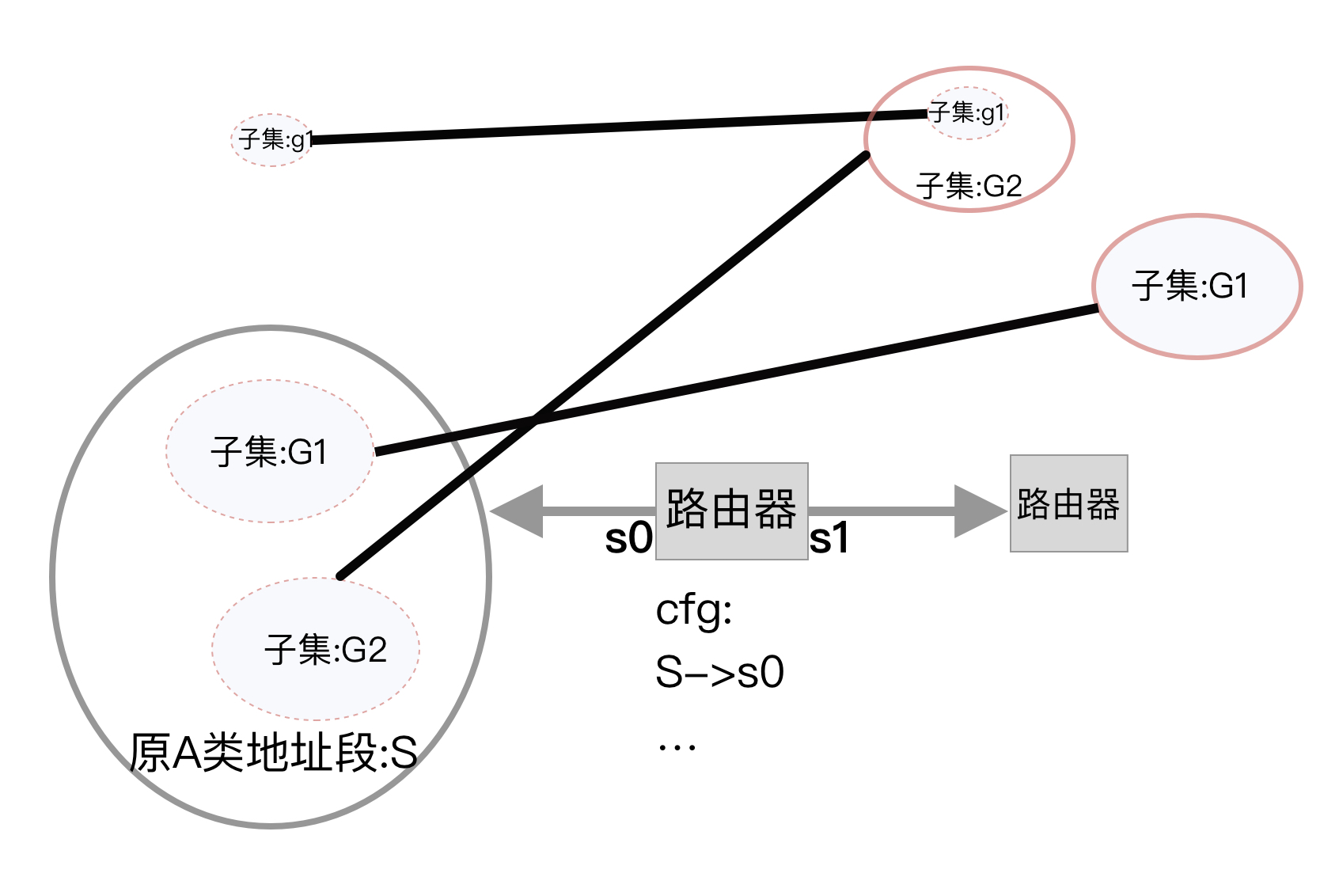
但这种方法设计重资产投资,即便不考虑投资问题,这也违背的 最短路径选路 原则。
幸亏CIDR执行的是最长前缀匹配,否则如果执行平坦精确匹配的话,抠出去一个洞,就要至少分裂出三条路由,这更是对路由查找算法的严峻考验!
本质上,上述的矛盾在于, IP地址的分布和路由分布之间的矛盾。
IP地址的连续性分布和路由的连续性分布必须一致 ,才能使得 在路由表项最少的情况下执行最短路径算法 成为可能,而这里路由的连续性,体现在 目标地址在地理上的连续性分布 。
以Linux内核路由表数据结构Trie树为例,事实上,如果IP地址在全球的分布是 地理连续 的,那么任何一台路由器中的路由表数据结构将成为全球网络拓扑的一个缩影,即, 这一棵Trie树表示的就是全球的网络拓扑,中间节点表示路由器,叶子节点表示拥有独立IP地址的端主机 。
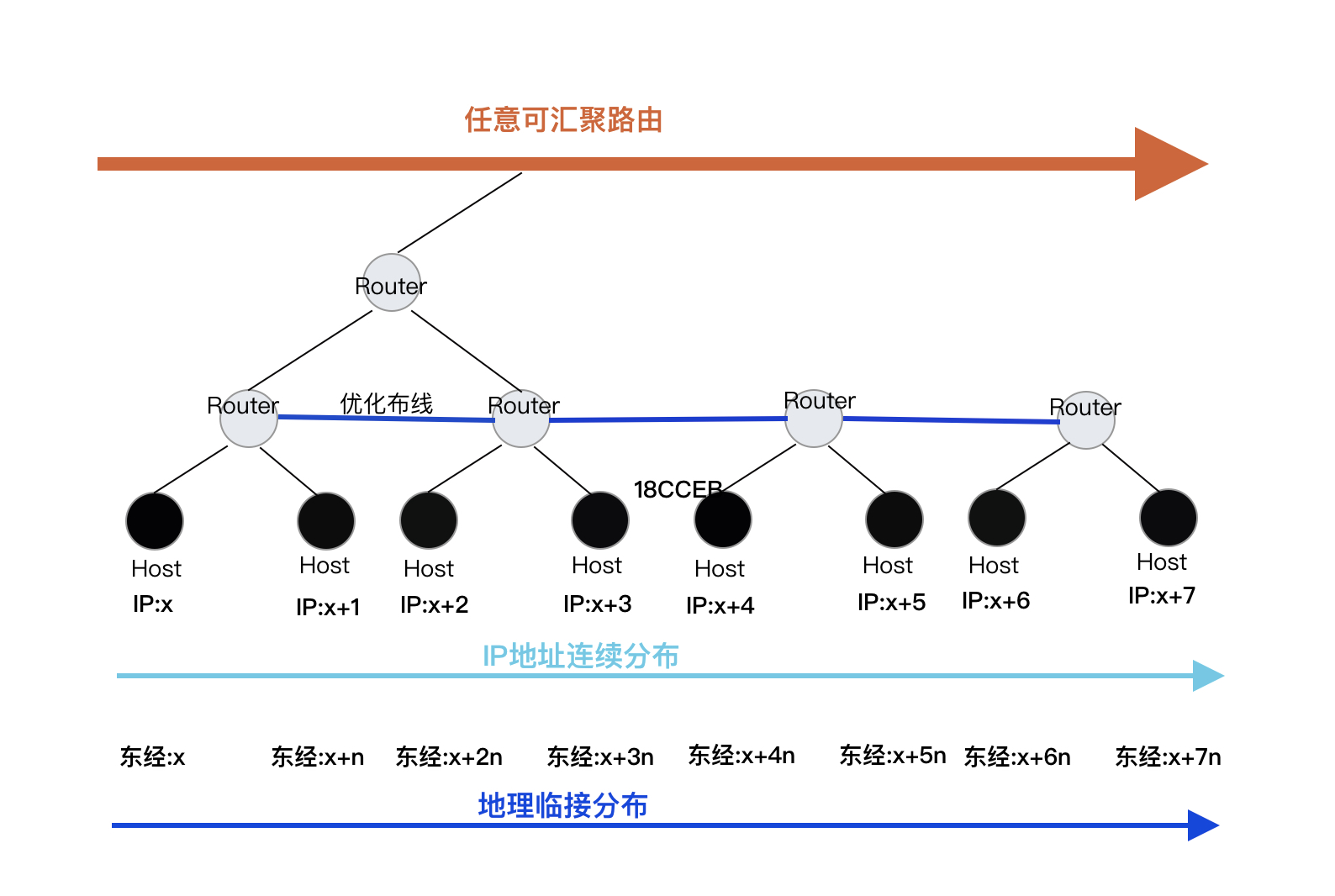
每台路由上只需要部署三条路由即可:
ip route add $this_bit_0 via $left_child
ip route add $this_bit_1 via $right_child
ip route add 0.0.0.0/0 via $parent
当然,为了更优化的执行最短路径算法,如果同层的路由器节点之间有布线,那么便可以 以增加一条路由为代价,执行bypass,不必回溯到parent。
但事实上全球的IP地址分配并没有在地理上邻接。当我们了解了 链路状态路由协议 算法之后,我们就会明白,其实 路由表项的激增和IP地址的随意分配是一回事!
我们回忆一下OSPF这种链路状态路由协议的生成过程算法,其实就是企图将全球的网络拓扑转化为自己内存中的一张路由表:
- 所有路由器交换自己的链路状态信息;
- 所有的路由器将获得一致的全局链路信息,生成相同的全局网络拓扑;
- 该全局网络拓扑上执行SPF算法,即类似Dijkstra算法的东东;
- 将算法执行结果经过预处理存入路由表数据结构。
当然,在OSPF实际运作的时候,并没有基于全球网络拓扑生成路由表,而是在AS内的路由域范围内运作,但这并不妨碍我们对整个过程和问题根源的理解。
- 路由要执行最短路径算法
- 路由器的路由表项要少
在地址随意分配的前提下,这个鱼与熊掌不可兼得,同时无法取舍,重新规划IP编址是不可能的了,只能从头设计一个新的协议,这就是IPv6。
小Tip
为什么Linux最终采用了Trie树作为路由表的数据结构,而不是Hash?
Trie树更能体现路由表和全球网络拓扑的同一性,因为在 正确的 地址规划下,全球的网络拓扑本就应该是一棵和路由器内路由表一模一样的Trie树。
这有利于实施基于 局部性 的缓存优化。因为网络连接中,同一连接的数据包总是密集Burst到来,Trie树便于缓存命中节点在cache line,而Hash算法会将结果散列在一个比较大的内存地址空间,不利于局部性缓存的实施。
现在让我们总结一下:
- 20世纪80年代初
计算机网络通信伊始,TCP/IP呱呱坠地,前途未知。
分类协议体现了IETF的一种原始探索,编址,分配,路由原则,简单直接,至少,TCP/IP跑起来了! - 20世纪90年代初
遭遇地址浪费的问题,使用VLSM/CIDR以增加路由表项为代价化解之,同时单列私有IP地址+NAT的方式弥补地址浪费,虽然争议不断,但直至今日,它依然在工作并将继续工作。
IPv6吸取了IPv4的教训,从一开始设计时就将IPv4从分类编址,CIDR/VLSM,NAT等等一并考虑。
IPv6的意义到底是什么?
一说起这个问题,在网上一搜,很多喷子开始扯到什么XX-Wall,Great or Dis,我了解这个,但我不会多说,我站在IPv6的本质的立场来评价IPv6本身,无关人们如何使用它,甚至无关人们想不想使用它。
首先,一个问题,IPv6有128bit那么长,可是真的需要那么长吗?
如果你只是考虑 够不够用 这个层面,那就有点Low了。IPv4当初就是这么考虑的,32bit足够了,除了这个之外,并没有对任何bit留下任何解释的空间,换句话说,32bit的IPv4地址,除了类别中用于指示网络和主机的明确bit数量要求外,全部都解释成IP地址本身,后来CIDR时代,连这个约束也没有了,所以现在,随便一个32bit的数字,都可以解释成一个IP地址并且分配给主机(当然,组播这种除外)。
我们来考虑一下我们的 身份证。 身份证目前有18位10进制数,用我们问IPv6的问题问身份证,用的了那么多位数吗?
11位十进制数就能编址百亿级别的人口了,而我们国家的人口才十几亿,并且可能会减少…用18位编址人口,用得完吗?
几乎随便一个人都知道,身份证并不是连续编址的,而是分层次的。前面6位代表省市区,然后中间8位代表出生年月日,最后4位代表你自己的唯一ID,这样看到一个身份证号,就能快速定位到这个人出生时的归属地。所以说,18位身份证并不是让你去编址10亿亿人口的。
IPv6的编址机制非常类似于身份证的编址机制。
如果换一种类似IPv4的编址方案,不用18位,而用12位十进制数编址。我们随意对人们的身份证号连续编址,比如按照出生顺序简单递增数值,那么看到一个人想定位它出生时的归属地,就必须对每一个人建立一个映射!所有这些映射的集合就是 中国人口路由表。这种情况下,试问谁还敢去查身份证???
这顺便回答了另一个问题,即 为什么采用更多位数的分层编址方案,路由表项反而小于更短位数的平坦编址方案?
好了,既然128位IPv6地址和身份证一样是分层的,那么我们来看看它的每部分bits到底是干什么的。不过在此之前,我们实际来推敲一下IPv6坊间常说的那个段子,即 IPv6可以为地球上每一粒沙子分配一个IP地址。
我们先来进行一个简单的计算,看看如果IPv6编址方案也是平坦的,它到底能不能为地球上每一粒沙子分配一个IP地址。
我们假设沙子的直径是0.25mm,开始我们的计算。
1
k
m
=
1000000
m
m
1km= 1000000mm
1km=1000000mm
所以,
1
k
m
2
1km^2
1km2的沙子数量为:
4000000
×
4000000
=
16
×
1
0
12
4000000times 4000000=16times 10^{12}
4000000×4000000=16×1012(个)
而地球表面积为:
510
,
100
,
000
k
m
2
510,100,000 km^2
510,100,000km2
那么,假设地球表面积全部铺了一层沙子,那么一共会有多少沙子呢?
5101
×
16
×
1
0
17
≈
8
×
1
0
21
5101times 16times 10^{17}approx8times 10^{21}
5101×16×1017≈8×1021(个)
而IPv6的地址数量为
3.4
×
1
0
38
3.4times 10^{38}
3.4×1038个,…我们假设地球表面铺了
10
k
m
10km
10km全是沙子,那么沙子的数量为
3.2
×
1
0
29
3.2times 10^{29}
3.2×1029个…再用沙子堆个珠峰?再填满马里亚纳海沟?上天遁地,九天揽月,五洋捉鳖,自己算吧!
看来, “为地球上每一粒沙子分配一个IP地址” 并不是传言,它是真的!不光如此,整个地球就算全部用沙子组成,IPv6地址也够用!
但是,我们并不是用这 3.4 × 1 0 38 3.4times 10^{38} 3.4×1038个IPv6地址全部用于 平坦 编址,这点和我们并非用18位身份证号全部平坦编址10亿亿个人是一样的道理。IPv6采用了分层的编址设计,而不是平坦的编址设计。
并不是说 将全部128bits的地址空间用于分层编址有多么多么炫酷, 而是说 如果将128bits的地址空间用于平坦编址必然导致万劫不复的悲哀!
既然都可以为每一粒沙子分配一个IPv6地址,那么应对物联网(IoT)就是小菜一碟了,如果真的每一粒沙子都有了IP地址,如果真的还像IPv4地址那样乱分一通,128bits地址空间的IPv6将会产生多少离散的路由条目,这将使得任意强大的路由器彻底溢出,罢工而歇菜!
所以说,分层设计IPv6地址,是刚需,而不是优化! 是不这么做就不行,而不是这么做了会更好!
现在看IPv6的可全球被路由的128bits的地址都代表了什么,懒得画图,网图侵删:
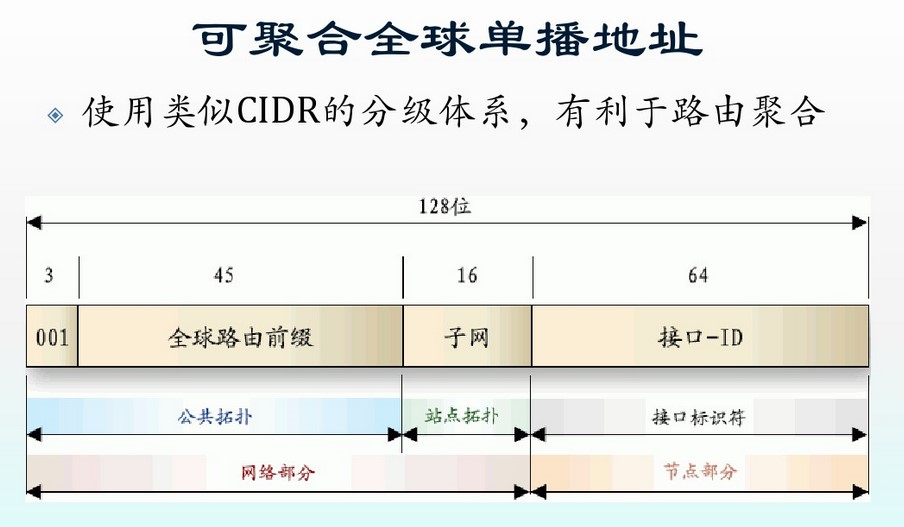
我们看到,IPv6地址高3位为 001 001 001,这3bits代表的含义是 该地址是全局可路由的地址, 其次的45bits为前缀,类似身份证号的省市,接下来的16bit为子网ID,类似于身份证号的区县,最后的低64bits为EUI-64映射,即将自身的 唯一ID(比如以太网全球唯一的MAC地址)映射到64bits的空间内 。
这个编址规则和我们身份证的编址规则简直太像了!
IPv6和IPv4的不同在于,IPv6为每一个bit赋予了特殊的含义,使得寻址操作更加规整规则,而IPv4的CIDR则是平坦化编址。具有讽刺意义的是,起初的分类编址(A,B,C…类地址)倒是使用了 规则 ,只不过这些规则最终被证实是起副作用的,造成可地址浪费,所以最终VLSM/CIDR取消了约束,将IPv4地址空间彻底变成了平坦的地址空间!
这里不得不提到的是,IPv6地址低64位的EUI-64映射的64bits才是真正标识IPv6地址唯一性的,前面64bits只是描述了该IPv6地址的属性,包括但不限于:
- 该IPv6地址属于哪个机构或者运营商分配的
- 该IPv6弟子属于哪个子网,其子网ID是什么
- …
抛开IPv6的其它地址不说,仅仅考虑全球可被公网路由的地址,其范围是:
- start:2000:0000:0000:0000:0000:0000:0000:0000
- end:3FFF:FFFF:FFFF:FFFF:FFFF:FFFF:FFFF:FFFF
仅就全球可任意被路由的地址段来讲,它占据了1/8的IPv6地址空间,也就是总共有 3.4 × 1 0 38 8 dfrac{3.4times 10^{38}}{8} 83.4×1038个IPv6地址,你算算看,即便是这个 缩小了8倍的数值 ,照样可以为地球上的每一颗沙子分配一个IP地址。
关于IPv6 unicast地址每一部分bits的结构,有一篇比较不错的资源,来自Microsoft:
Unicast IPv6 addresses: https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-server-2003/cc759208(v=ws.10)
考虑到网络上东西并不持久(所以我从不信任网络,我一般都会把自己的思路写到纸上收藏起来),我还是硬拷贝一些资源:

TLA ID
The TLA ID field indicates the Top Level Aggregation Identifier (TLA ID) for the address. The size of this field is 13 bits. The TLA identifies the highest level in the routing hierarchy. TLAs are administered by IANA and allocated to local Internet registries that, in turn, allocate individual TLA IDs to large, global Internet service providers (ISPs). A 13-bit field allows up to 8,192 different TLA IDs. Routers in the highest level of the IPv6 Internet routing hierarchy (called default-free routers) do not have a default route–only routes with 16-bit prefixes that correspond to the allocated TLAs.
Res
The Res field is reserved for future use in expanding the size of either the TLA ID or the NLA ID. The size of this field is 8 bits.
NLA ID
The NLA ID field indicates the Next Level Aggregation Identifier (NLA ) for the address. The NLA ID is used to identify a specific customer site. The size of this field is 24 bits. The NLA ID allows an ISP to create multiple levels of addressing hierarchy to organize addressing and routing and to identify sites. The structure of the ISP’s network is not visible to the default-free routers.
SLA ID
The SLA ID field indicates the Site Level Aggregation Identifier (SLA ID) for the address. The SLA ID is used by an individual organization to identify subnets within its site. The size of this field is 16 bits. The organization can use these 16 bits within its site to create 65,536 subnets or multiple levels of addressing hierarchy and an efficient routing infrastructure. With 16 bits of subnetting flexibility, an aggregatable global unicast prefix assigned to an organization is equivalent to that organization being allocated an IPv4 Class A network ID (assuming that the last octet is used for identifying nodes on subnets). The structure of the customer’s network is not visible to the ISP.
Interface ID
The Interface ID field indicates the interface of a node on a specific subnet. The size of this field is 64 bits.
看看上述对精确划分其含义的地址bits的描述,就能理解这就是所谓的 IPv6在设计之初就考虑到了地址聚合 的真实含义。这个就和身份证一般,在一个IPv6地址被分配的时候,就必须要综合考虑其 地理位置, 所属机构, 所属AS, 等等一系列的属性。
按照标准的规程来看,其实IPv6地址中有一半的bits,即64bits是完全自动生成的,这就是EUI-64机制。EUI-64映射是将网卡48bit的MAC地址按照一定的规则映射成了64bit的IPv6地址的主机部分,这解放了管理员或者DHCPv6的配置工作。
这个EUI-64映射不可小觑,它直接将链路层的逻辑提升到了IP层统一处理,使得 自动配置 成为了可能,并大大简化了对IP地址的管理之难度。
只要MAC地址不冲突, IPv6链路本地地址 就不冲突,这就使得自动配置可以开启,然后一切都不需要人工干预!IPv6甚至不需要DHCPv6协议做额外的支撑,其本身就能完成从0到1,从1到100的完整配置过程。
以上,我们可以看到,IPv6地址中128bits中的每一个bit都被赋予了意义,这一点是和IPv4编址最大的不同。这不仅仅是一个地址空间扩大的问题,这还是地址可扩展性的问题。
我们可以想象一下IPv6地址是如何被分配的。
它肯定不是交钱就能给IP的,它一定是要综合考虑地址数量需求,地理位置分布等因素,来决定如何分配IPv6地址。
TLA所示众的地址段原则上是不允许被抠洞的,想划分子网,那就在NLA上做文章。机构或者运营商自行决定具体的分配策略,而上级机构或者运营商仅仅规定分配哪些TLA段。
IPv6地址结构有点像 优化版本的平等性分类地址结构, 和IPv4分类地址中A类地址规模远远大于B类,C类地址不同,IPv6只有一类,所有的地址段都是地位均等的!
仔细看IPv6的结构,TLA,NLA都只有有限的bit位,并且貌似比较少,然而Res为其提供了无限可能。
有句话说 “计算机科学家能够犯的最大错误就是有些地方提供太少的数据位。” ,但是坊间民间还有一句话 “图片仅供参考,最终解释权归XX所有!”(方便面包装上常见) ,这个在IPv6看来,解释权就是Res字段了!
换句话说,Res提供了 “注释” 的功能,我们可以想象一下它未来的一个用法。Res字段可以提供一种线下的注释,比如:
- Res:00000010
将NLA和TLA拼接后,padding 8个0,作为网络ID - Res:00000001
将TLA后padding 8个0后,与NLA拼接,作为网络ID - Res作为一张255个表项的 解释表 的索引,索引解释地址的方法
- …
我想以上已经解释了为什么说 IPv6地址一开始就是自带聚合的, 本文并不解释技术细节,详情参见RFC即可。
参考之前写的文章:
闲谈IPv6-IPv6的NAT原理以及MAP66:https://blog.csdn.net/dog250/article/details/7799398
闲谈IPv6-典型特征的一些技术细节:https://blog.csdn.net/dog250/article/details/8169984
闲谈IPv6-聚类和浪费:https://blog.csdn.net/dog250/article/details/8172678
闲谈IPv6-尴尬的IPv4:https://blog.csdn.net/dog250/article/details/8169953
闲谈IPv6-现状和过渡:https://blog.csdn.net/dog250/article/details/8170010
此外,下面的资源也是必读的:
IPv6编址指南:https://www.cisco.com/c/dam/global/zh_cn/solutions/industry/segment_sol/enterprise/programs_for_large_enterprise/iba/pdf/bn_enterprise_ipv6_addressing_guide_h2cy10.pdf
后记
几年来看过N多关于IPv6的文章和各类资源,总结下来不外乎就几类:
- IPv6地址空间太大了,足以解决IPv4地址不够的问题;
- 国家未普及IPv6是因为那个什么墙尚未支持IPv6(这种最烦人,评论喷子最多);
- IPv6地址不好记,这是普及的阻力(这种也烦人,难道不懂自动配置吗?本地链路地址是干啥的?);
- IPv6不需要NAT,更容易实名制(烦人,咋就这么敏感呢?);
- …
其实,关于IPv6,很少有人从技术的层面去分析,也是是本来就很少有人去深究吧。
比如,关于NAT,在物联网时代,万物联网,每一个小玩意儿都有一个IP地址,这对IP地址的需求非常可观,IPv4是显然不够用的。但是使用NAT技术呢?
我们知道,NAT技术绝大多数需要在NAT节点维护连接Session,对于IoT设备而言,现有设备根本不足以维持海量的连接Session,即便是Stateless的NAT,也需要配置海量的静态规则,这对数据结构和算法都是严峻的考验!IPv6上来就解决了这个问题!
此外,IPv6的Stream ID意义何在?它使用一个ID号就能免除转发节点维护的海量Session,这一点很少有人注意到。其实,IPv6的Stream ID可以等同于Linux nf_conntrack机制在追踪连接时计算的五元组Hash,只是这个Hash在端到端意义上就已经被计算好了,从而解放了转发节点大量的CPU资源!另一方面,作为Stateless转发协议的IP,被Stream ID赋予了端到端的功能,这也许并不优雅,但是不然能怎样呢?
本身,分层模型到底是不是网络传输王道就没有定论,又何必纠结于模型怎么地怎么地。违背ISO/OSI~TCP/IP分层模型但是最终却做了好事的多了去了!
好吧!不说网络了,说点别的。
我倒是觉得IPv6的思路可以用在内存映射上。
类比IPv4和IPv6,其实32位系统MMU和64位系统MMU之间的差异,也可以有异曲同工之妙。时间关系,不再细说。
君不见浙江温州皮鞋?湿,下雨☔️进水不会胖,
Zhejiang Wenzhou skinshoe wet,rain flooding water will not fat!
最后
以上就是追寻外套最近收集整理的关于闲谈IPv6-编址规则以及聚类的意义的全部内容,更多相关闲谈IPv6-编址规则以及聚类内容请搜索靠谱客的其他文章。








发表评论 取消回复