Computational limitations(计算局限性)
在RNN中,attention的加入到底能解决什么问题呢。就是计算局限性的问题。
计算局限性主要表现在计算机视觉中。比如在目标检测方面,采用滑动窗口模式可以地毯式的提取图片信息,但是成本过高,内存占用很大。
计算局限性目前的解决方式及优缺点
减少分类器窗口数量
很多工作致力于降低滑动窗口模式的成本,具体包括减少那些已经被评估完整的分类器的窗口数量。尽管这些工作可以获得实质性的加速,但它们仍然牢牢植根于用于目标检测的窗口分类器设计,并且只能利用过去的信息以非常有限的方式通知未来的图像处理。
特征检测器
特征检测器同样用来解决计算局限性的问题。它优先处理可能感兴趣的或者突出的图像区域,方法是测量一些局部低水平特征对比度,靠测量值来识别图像的突出区域或者感兴趣区域。但这种方法也有缺点,按文章的原说法就是不跨固定点集成信息,必须在硬连线上完成特征检测。另外他们仅基于低级图像特性,通常忽略诸如信号,场景和任务需求等其他因素。
Attention
是什么?
把视觉作为一个连续的决策任务。有关图像的信息按照顺序收集,下一步的决定是基于图像的先前固定。
将attention看作是*目标导向’agent’*与视觉环境交互作用的顺序决策过程。这里边agent我理解就是一个我们想要达成的目的的代理人。在每个时间点,agent只通过带宽有限的传感器观察环境,即它从不完全感知环境。它只能在局部区域或窄带内提取信息。但是,agent可以主动控制如何部署其传感器资源(例如,选择传感器位置)。agent还可以通过执行操作来影响环境的真实状态。
如何实现?
*采用**政策梯度公式**的学习框架。与深度学习框架中实现注意力处理的其他实验相似。
不同的是,使用RNN来整合视觉信息并决定如何行动的公式更为普遍,我们的学习过程允许对顺序决策过程进行端到端优化,而不是依赖贪婪的行动选择。进一步演示了如何在静止图像中使用相同的通用体系结构来进行有效的对象识别,以及如何与静止图像中的动态视觉环境进行交互。
由于只对环境进行了部分观察,因此agent需要随着时间的推移集成信息,以确定如何操作以及如何最有效地部署其传感器。在每个步骤中,agent都会收到一个标量回馈(这取决于agent已执行的操作,并且可以延迟),agent的目标是大化这些奖励的总和。
具体操作与公式
在介绍具体的操作与公式之前,介绍一下这个agent(个人理解可以把这个agent理解成时间t,或者是计算机操作时间迭代的方式)如何围绕一个循坏脑神经网络构建的。
在每个时间步骤中,它处理传感器数据,随着时间的推移集成信息,并选择怎样操作以及如何在下一个时间步骤部署传感器。
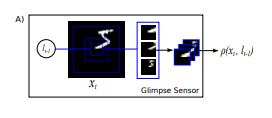
视景传感器:直译的话叫窥视传感器。
它以高分辨率对L周围的区域进行编码,但对距离L更远的像素使用逐渐降低的分辨率,从而导致比原始图像X维数低得多的矢量。我们将此低分辨率表示作为一种视景。其实很好懂,输入一个坐标l,分别以这个l为重心切下来三个大小不同的矩形patch。
在每个步骤t,agent都以图像xt的形式接收(部分)对环境的观察。agent,也就是t,无法完全访问此图像,而是可以通过其带宽受限的传感器ρ从xt中提取信息,方法是通过将传感器聚焦到感兴趣的某个区域或频段。
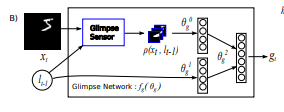
视景网络:给定位置(lt-1)和输入图像(xt),使用视景传感器提取视网膜表征ρ(xt,lt-1)。
视景传感器用于我们称为窥视网络fg的内部,以产生窥视特征向量gt=fg(xt,lt−1;θg),其中θg=θ0g,θ1g,θ2g(图1b)。给定视景坐标和输入图像,传感器提取以l为中心的视网膜样的表现形式ρ(xt,lt−1),该表现形式包含多个分辨率补丁。
然后,利用由θg0和θg1分别参数化的独立线性层,使用校正单元和另一个线性层θ2gt将视网膜表示和视景位置映射到隐藏空间,以合并来自两个组件的信息。视景网络fg(.; {θ0g, θ1g, θ2g}) 为生成了视景表现gt的attention网络定义了一个可训练带宽限制的传感器。
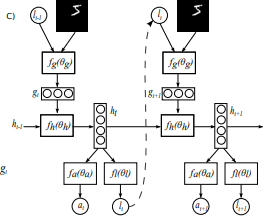
fh(.;θh)模型的核心网络将视景表现gt作为输入,并与前一时间步骤ht-1中的内部表示相结合,生成模型ht的新内部状态。**位置网络fl(;θl)和行动网络fa(;θa)**使用模型的内部状态ht来生成下一个位置,分别处理lt和行动/分类。这个基本的RNN迭代对于不同数量的步骤开始迭代。
此时agent保持了一种内部状态,这种状态总结了从过去的观察历史中提取的信息,它编码代理对环境的了解,并有助于决定如何行动和在何处部署传感器。这种内部状态由循环神经网络的隐藏单元ht形成,并随着时间的推移由核心网络更新:ht=fh(ht-1,gt;θh)。网络的外部输入是视景特征向量gt。
在每次迭代中,agent行两个操作,它决定如何通过传感器控制lt部署其传感器,以及可能影响环境状态的环境操作。环境操作的性质取决于任务。在这项工作中,**定位操作是随机从位置网络fl(ht;θl)在时间t:lt~p(·fl(ht;θl))**参数化的分布中选择的。同样地,环境操作at也是从第二个网络输出at~p(·fa(ht;θa))条件下的分布中得出的。动作网络,也就是环境操作所使用的网络,经过固定的时间步长后,使用h_t核心网络的内部状态来产生最终的输出分类y。
分类使用softmax分类器。动态环境的精确操作公式取决于为特定环境定义的动作集(也就是外部环境)。
这里按照本人理解这个特定环境定义的动作集指的是外部环境对attention网络如果影响明显,就应该加上。
agent接收到一个新的视觉环境观察xt+1和奖励信号rt+1。agent的目标是最大化奖励信号1的总和,奖励信号1通常非常稀疏和延迟:
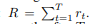
在目标识别的情况下,例如,如果对象在t步之后被正确分类,则rt=1,否则为0。
最后
以上就是难过小伙最近收集整理的关于对RNN中attention机制的一点理解Computational limitations(计算局限性)Attention的全部内容,更多相关对RNN中attention机制的一点理解Computational内容请搜索靠谱客的其他文章。








发表评论 取消回复