1. 前言
本文详解Embedding、Simple RNN原理,并使用飞桨(PaddlePaddle)基于IMDB电影评论数据集实现电影评论情感分析。
本人全部文章请参见:博客文章导航目录
本文归属于:自然语言处理系列
本系列实践代码请参见:我的GitHub
后文:长短期记忆网络(LSTM)原理与实战
2. 类别特征数值化方法
机器学习的数据通常有类别特征(categorical feature),训练机器学习模型之前,需要把类别特征转化成机器学习模型能理解的数值特征(numerical feature)。
在自然语言处理任务中,数据都是文本,文本可以分割成许多字符或者词语,每一个字符或者每一个词语就是一个类别特征。将类别特征数值化,主要有两种方式:独热编码(One-hot Encoding)与嵌入(Embedding)。
2.1 独热编码(One-hot Encoding)
独热向量(One-hot Vector)是指只有一个元素为1,其余元素均为0的向量。独热编码是指将类别特征转换为独热向量。
假设训练集文本中包含10000个不同的单词,每一个单词即可视为一个不同的类别特征,即有10000个类别特征。可以使用一个维度为10000的独热向量表示一个单词,不同单词对应的独热向量不同。
在实际处理文本时,会统计文本中单词出现的次数,进行去掉低频词(出现次数较少)、去除停用词(the、a、of等无意义单词)等等数据处理操作,因为低频词往往是命名实体、拼写错误词汇等无意义的单词。这方面的内容不在本文讲解范围。
但是使用独热编码存在如下问题:
- 向量维数等于单词数,单词越多,向量维度越高,表示一个独热单词的向量非常稀疏;
- 任意两个单词对应的向量之间的距离均相等,无法捕捉到单词与单词之间的相关性;
- 单词对应的独热向量只能表示一个类别,无法表示单词的语义。
此外,在RNN等自然语言处理模型中,模型RNN层参数正比于输入的向量的维度。使用独热编码,会使得RNN层参数数量过多。比独热编码更好的选择是Embedding。
2.2 嵌入(Embedding)
在自然语言处理领域,词语/单词级别的Embedding称为词嵌入(Word Embedding),字/字符级别的Embedding被称为字嵌入(Char Embedding)。
词嵌入是将单词映射到低维的连续向量空间中,即单词被表示成实数域上的低维向量。其中向量的长度是超参数,必须人为设定。向量中每一个元素的值,是模型的参数,必须从训练数据中学习获得,即通过大量数据训练,模型自动获得每一个单词该被表示成一个怎样的向量。词嵌入维度的设定并没有精确的理论可以指导,设定的原则是:Embedding表示的对象包含的信息越多(不同语言词汇信息熵不一致),则词嵌入维度应该越高;训练数据集越大,词嵌入维度可以设置得更高。一般词嵌入是8维(对于小型数据集)到1024维(对于超大型数据集)。更高维度的Embedding可以捕获单词之间更细的关系,但是需要更多数据去学习,否则模型非常容易过拟合。
使用词嵌入的优点如下:
- 能捕捉到单词之间的联系,比如通过计算两个词嵌入的距离,可以得到两个单词的相关程度(如图一所示);
- 词嵌入维度较独热向量低的多得多,运算速度较快;
- 实践证明,使用Embedding能够提高情感分析、机器翻译等众多自然语言处理问题的效果。
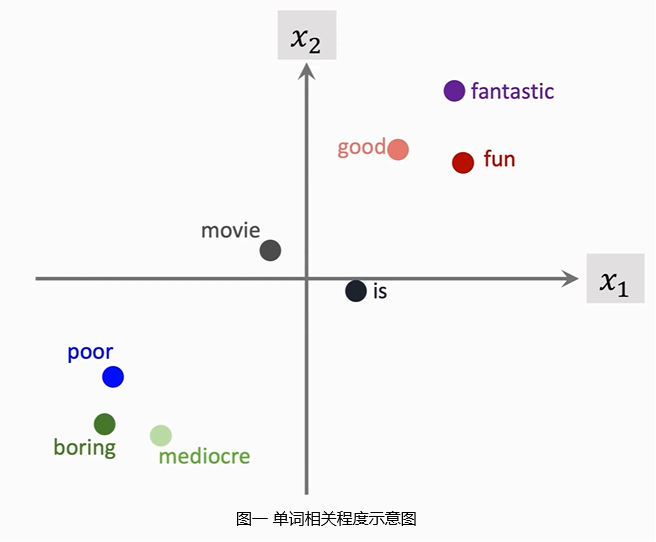
Deep Learning is all about “Embedding Everything”.
实际上,不仅仅在自然语言处理领域可以将字/词等类别特征通过Embedding方式数值化,任意类别特征均可尝试通过Embedding方式数值化;
处理中文文本时,可以将一个“字”视为一个类别特征,也可以将一个“词语”视为一个类别特征。如果将“字”视为类别特征,则需较多数据才能学习出比较好的Char Embedding。如果将“词语”视为类别特征,则分词效果将会直接影响到最终输出效果。一般建议在相对较小的数据集上使用词嵌入,在大数据集或者网络用语等新词频出的数据集上使用字嵌入。
3. 电影评论情感分析(一)
电影评论情感分析的本质是一个分类问题,给定一段自然语言文本,判断其情感是正向还是负向。
IMDB数据集是PaddlePaddle内置的NLP领域常见的一个对电影评论标注为正向评论与负向评论的数据集,共有25000条文本数据作为训练集,25000条文本数据作为测试集。使用PaddlePaddle基于IMDB电影评论数据集实现电影评论情感分析,首先须对数据进行处理。神经网络模型接受的输入是张量(Tensor),其长度是固定的。数据处理须将文本数据截断或填充,使得不同长度的原始文本经过处理后长度一致。
电影评论情感分析(一)使用浅层网络模型分析电影评论情感,设计如下:
- 模型结构:一层Embedding+softmax分类器
- 词嵌入维度:16
softmax分类器:由一个全连接层,再最后加上softmax激活函数组成。
softmax:max函数使得一个向量中最大值变成1,其余值变成0。softmax函数使得一个向量中最大值变大,其余值变小,但是不会像max函数那么极端,比max函数更soft。关键在于softmax函数可导,max函数不可导。
3.1 数据处理
定义get_data_loader函数,设置文本最大长度为200,加载IMDB数据集,处理数据,然后封装成paddle.io.Dataset对象,再进一步封装成paddle.io.DataLoader对象。代码如下:
# -*- coding: utf-8 -*-
# @Time : 2021/6/16 22:17
# @Author : He Ruizhi
# @File : emb_softmax.py
# @Software: PyCharm
import paddle
import numpy as np
import random
import warnings
warnings.filterwarnings('ignore')
print(paddle.__version__) # 2.1.0
class IMDBDataset(paddle.io.Dataset):
"""继承paddle.io.Dataset类,创建自定义数据集类"""
def __init__(self, sents, labels):
super(IMDBDataset, self).__init__()
assert len(sents) == len(labels)
self.sents = sents
self.labels = labels
def __getitem__(self, index):
data = self.sents[index]
label = self.labels[index]
return data, label
def __len__(self):
return len(self.sents)
def get_data_loader(mode, seq_len=200, batch_size=128, pad_token='<pad>', data_show=None):
""" 加载训练/测试数据
:param mode: 加载数据模式 train/test
:param seq_len: 文本数据中,每一句话的长度都是不一样的,为了方便后续的神经网络的计算,须通过阶段或填充方式统一输入序列长度
:param batch_size: 批次大小
:param pad_token: 当一条文本长度小于seq_len时的填充符号
:param data_show: 如果不为None,则展示数据集中随机data_show条数据
:return: paddle.io.DataLoader对象
"""
imdb_data = paddle.text.Imdb(mode=mode)
# 获取词表字典
word_dict = imdb_data.word_idx
# 将pad_token加入最后一个位置
word_dict[pad_token] = len(word_dict)
# 获取pad_token的id
pad_id = word_dict[pad_token]
# 将数据处理成同样长度
def create_padded_dataset(dataset):
# 处理后的句子
padded_sents = []
# 对应标签
labels = []
for batch_id, data in enumerate(dataset):
sent, label = data[0], data[1]
padded_sent = np.concatenate([sent[:seq_len], [pad_id] * (seq_len - len(sent))])
padded_sents.append(padded_sent)
labels.append(label)
return np.array(padded_sents, dtype='int64'), np.array(labels, dtype='int64')
# 获取处理后的数据
sents_padded, labels_padded = create_padded_dataset(imdb_data)
# 使用自定义paddle.io.Dataset类封装
dataset_obj = IMDBDataset(sents_padded, labels_padded)
shuffle = True if mode == 'train' else False
data_loader = paddle.io.DataLoader(dataset_obj, shuffle=shuffle, batch_size=batch_size, drop_last=True)
if data_show is not None:
# 定义ids转word方法
def ids_to_str(ids):
words = []
for k in ids:
w = list(word_dict)[k]
words.append(w if isinstance(w, str) else w.decode('utf-8'))
return ' '.join(words)
show_ids = random.sample(range(len(imdb_data)), data_show)
for i in show_ids:
show_sent = imdb_data.docs[i]
show_label = imdb_data.labels[i]
print('the {}-th sentence list id is:{}'.format(i+1, show_sent))
print('the {}-th sentence list is:{}'.format(i+1, ids_to_str(show_sent)))
print('the {}-th sentence label id is:{}'.format(i+1, show_label))
print('--------------------------------------------------------')
return data_loader
3.2 模型搭建
搭建神经网络模型,定义emb_softmax_classifier_model函数,使用paddle.nn.Sequential创建序列容器,并依次添加paddle.nn.Embedding、paddle.nn.Flatten、paddle.nn.Linear层。将对象用paddle.Model封装并返回。代码如下:
def emb_softmax_classifier_model(emb_size=16, seq_len=200):
""" 创建emb层+softmax分类器层 模型
其中num_embeddings=5149为事先查看数据集中的单词数
out_features=2因为情感分类,输出为两类
:param emb_size: emb大小
:param seq_len: 单个seq长度
:return: paddle.Model对象
"""
net = paddle.nn.Sequential(
paddle.nn.Embedding(num_embeddings=5149, embedding_dim=emb_size),
paddle.nn.Flatten(),
paddle.nn.Linear(in_features=seq_len * emb_size, out_features=2)
)
return paddle.Model(net)
3.3 模型训练
设置超参数seq_len = 200、emb_size = 16,调用get_data_loader函数加载训练和测试数据,调用emb_softmax_classifier_model函数获得模型实例。使用model.summary获得模型信息如下:
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Embedding-1 [[1, 200]] [1, 200, 16] 82,384
Flatten-1 [[1, 200, 16]] [1, 3200] 0
Linear-1 [[1, 3200]] [1, 2] 6,402
===========================================================================
Total params: 88,786
Trainable params: 88,786
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.05
Params size (MB): 0.34
Estimated Total Size (MB): 0.39
---------------------------------------------------------------------------
使用model.prepare进行模型配置,使用paddle.optimizer.Adam优化器、paddle.nn.CrossEntropyLoss损失函数,并添加paddle.metric.Accuracy作为衡量指标。使用model.fit开启模型训练,设置eopchs=5。训练过程信息如下:
The loss value printed in the log is the current step, and the metric is the average value of previous steps.
Epoch 1/5
step 195/195 [==============================] - loss: 0.4092 - acc: 0.6625 - 5ms/step
Epoch 2/5
step 195/195 [==============================] - loss: 0.2929 - acc: 0.8648 - 4ms/step
Epoch 3/5
step 195/195 [==============================] - loss: 0.2057 - acc: 0.9011 - 4ms/step
Epoch 4/5
step 195/195 [==============================] - loss: 0.2373 - acc: 0.9239 - 4ms/step
Epoch 5/5
step 195/195 [==============================] - loss: 0.1361 - acc: 0.9466 - 4ms/step
使用model.evaluate在测试集上评估模型,得到测试信息如下:
测试结果: {'loss': [0.4164989], 'acc': 0.8514423076923077}
测试集中正样本数为12500,负样本数为12500,瞎猜正确率为50%。使用简单浅层网络,经过训练后测试准确率为:85.14%。模型训练部分代码如下:
if __name__ == '__main__':
# 设置超参数
seq_len = 200 # 每条文本的长度
emb_size = 16 # 词嵌入(word embedding大小)
# 加载和处理数据
train_data_loader = get_data_loader('train', seq_len=seq_len, data_show=1)
test_data_loader = get_data_loader('test', seq_len=seq_len)
model = emb_softmax_classifier_model(emb_size=emb_size, seq_len=seq_len)
# 打印模型结构信息
model.summary(input_size=(None, seq_len), dtype='int64')
# 配置模型
model.prepare(optimizer=paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(use_softmax=True), metrics=paddle.metric.Accuracy())
model.fit(train_data_loader, epochs=5, verbose=1)
print('测试结果:', model.evaluate(test_data_loader, verbose=0))
训练此模型并没有经过精细的调参,很明显,模型出现了比较严重的过拟合现象;
模型最后没有softmax层,是因为paddle.nn.CrossEntropyLoss()将softmax操作和计算损失操作合并了;
之所以采用两个输出节点+softmax+cross_entropy而不是采用二分类问题中使用更广泛的一个输出节点+sigmoid+binary_cross_entropy,是因为如果在PaddlePaddle中使用后一种方式,貌似在使用高阶API训练模型时,accuracy计算机制存在BUG。这一点我向官方提出来过,也和官方人员讨论过,具体可查看链接。
4. Simple RNN
第3部分直接将文本整体输入模型,对文本进行二分类,所述模型属于一对一(one to one)模型,即一个输入对应一个输出。但是人脑并不使用one to one模型处理时序数据,人类在阅读文章时,并不会把一整段文字全部直接输入大脑。在阅读时,人类通常逐字逐句阅读文章,并逐渐在大脑里积累信息。当整篇文章阅读完毕,大脑里就积累了整篇文章的大意。
One to one模型要求一个输入对应一个输出,比如输入一张图片,输出每一类的概率值。One to one模型非常适合图片处理问题,但不适合文本等时序数据(sequential data)处理问题。对于文本等时序数据处理问题,输入和输出的长度都不固定,更适合时序数据处理问题的模型是多对一(many to one)或者多对多(many to many)模型。
RNN(Recurrent Neural Network)即是这种多对多模型,虽然现在RNN没有以前那么流行,在自然语言处理领域,已经有些过时。如果训练数据足够多,RNN的效果不如Transformer模型。但是在较小规模数据集上,RNN效果仍然比较出色。RNN非常适合处理文本、语音等时序数据,其输入和输出长度均无须固定。RNN处理时序数据的过程与人脑非常类似,人类阅读文本时,每次看一个字,逐渐在大脑里积累信息。RNN每次接受一个输入,用状态向量
h
h
h积累输入信息。如图二所示,一段文本中的单词,经过Embedding层后从左至右依次输入RNN,状态向量
h
0
h_0
h0包含了第一个词
x
0
x_0
x0的信息,
h
1
h_1
h1包含了前两个词
x
0
x_0
x0和
x
1
x_1
x1的信息,以此类推,
h
t
h_t
ht包含了
x
0
x_0
x0到
x
t
x_t
xt所有词的信息,如果到
t
t
t时刻,文本中所有词均被输入RNN,则可以将
h
t
h_t
ht看做RNN从输入的文本中抽取的特征向量。
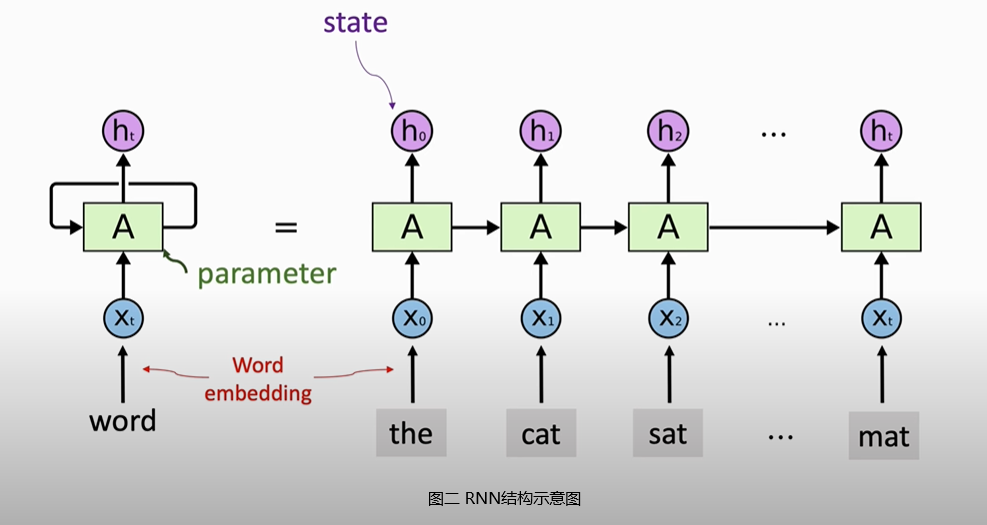
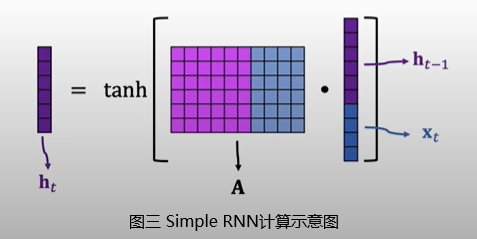
Simple RNN根据
t
t
t时刻输入
x
t
x_t
xt和
t
−
1
t-1
t−1时刻状态向量
h
t
−
1
h_{t-1}
ht−1计算
t
t
t时刻状态向量
h
t
h_{t}
ht的方法如图三所示,将
t
−
1
t-1
t−1时刻状态向量
h
t
−
1
h_{t-1}
ht−1与
t
t
t时刻输入
x
t
x_t
xt拼接(concatenation),再左乘参数矩阵
A
A
A,然后将激活函数tanh作用于得到向量的每一个元素上,最后得到
t
t
t时刻状态向量
h
t
h_t
ht。其中
A
A
A是RNN的参数矩阵,需要随机初始化后通过训练数据学习。此外,Simple RNN实际计算过程中往往会加上一个形状与状态向量一致的偏置(bias),然后再通过激活函数并输出新的状态向量,与图三所示有一点点区别,不过本质上没有差别。
Simple RNN的结构展开如图四所示,新的状态
h
t
h_t
ht是上一个时刻状态
h
t
−
1
h_{t-1}
ht−1和
t
t
t时刻输入
x
t
x_t
xt的函数,
A
A
A是Simple RNN的模型参数矩阵。不论RNN的链展开有多长,RNN中的参数矩阵只有一个,即在始终使用同一个
A
A
A乘以不同时刻的状态向量
h
t
−
1
h_{t-1}
ht−1和输入向量
x
t
x_t
xt拼接后形成的向量,从而得到新状态向量
h
t
h_t
ht。
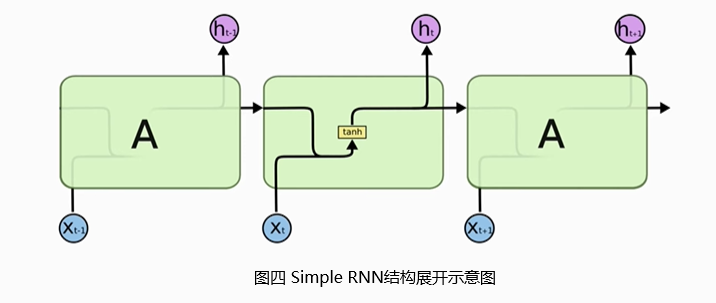
Simple RNN的模型参数数量等与参数矩阵
A
A
A中的元素个数(不考虑偏置),参数矩阵
A
A
A的行数等于状态向量
h
h
h的维度:
s
h
a
p
e
(
h
)
shape(h)
shape(h),列数等于状态向量
h
h
h的维度加上输入向量
x
x
x的维度:
s
h
a
p
e
(
h
)
+
s
h
a
p
e
(
x
)
shape(h)+shape(x)
shape(h)+shape(x)。因此Simple RNN模型的总参数个数为:
s
h
a
p
e
(
h
)
∗
[
s
h
a
p
e
(
h
)
+
s
h
a
p
e
(
x
)
]
shape(h) * [shape(h)+shape(x)]
shape(h)∗[shape(h)+shape(x)]。
4.1 遗忘问题
Simple RNN的记忆时效较短,会遗忘很久之前的输入
x
x
x。根据图三,Simple RNN状态更新公式可写作如下形式:
h
t
=
t
a
n
h
(
W
i
x
t
+
W
h
h
t
−
1
+
b
)
h_t=tanh(W_ix_t+W_hh_{t-1}+b)
ht=tanh(Wixt+Whht−1+b)
W i W_i Wi相当于图三中参数矩阵 A A A右半边蓝色部分, W h W_h Wh相当于左半边紫色部分。此外,公式中加入了偏置项。
令
z
t
=
W
i
x
t
+
W
h
h
t
−
1
+
b
则
∂
h
t
∂
x
t
=
∂
h
t
∂
z
t
W
i
,
∂
h
t
∂
h
t
−
1
=
∂
h
t
∂
z
t
W
h
因
为
h
t
是
h
t
−
1
的
函
数
,
h
t
−
1
是
x
t
−
1
的
函
数
,
则
:
∂
h
t
∂
x
t
−
1
=
∂
h
t
∂
h
t
−
1
∂
h
t
−
1
∂
x
t
−
1
同
理
,
h
t
−
1
是
h
t
−
2
的
函
数
,
h
t
−
2
是
x
t
−
2
的
函
数
,
则
:
∂
h
t
∂
x
t
−
2
=
∂
h
t
∂
h
t
−
1
∂
h
t
−
1
∂
h
t
−
2
∂
h
t
−
2
∂
x
t
−
2
以
此
类
推
,
∂
h
t
对
∂
x
t
−
k
的
偏
导
数
如
下
:
∂
h
t
∂
x
t
−
k
=
∂
h
t
∂
h
t
−
1
∂
h
t
−
1
∂
h
t
−
2
⋯
∂
h
t
−
k
+
1
∂
h
t
−
k
∂
h
t
−
k
∂
x
t
−
k
=
[
∏
j
=
t
−
k
+
1
t
∂
h
j
∂
h
j
−
1
]
∂
h
t
−
k
∂
x
t
−
k
=
{
∏
j
=
t
−
k
+
1
t
[
d
i
a
g
(
∂
h
j
∂
z
j
)
W
h
]
}
∂
h
t
−
k
∂
x
t
−
k
令~~z_t=W_ix_t+W_hh_{t-1}+b\ 则~~frac{partial h_t}{partial x_t}=frac{partial h_t}{partial z_t}W_i,~~~~frac{partial h_t}{partial h_{t-1}}=frac{partial h_t}{partial z_t}W_h\ 因为h_t是h_{t-1}的函数,h_{t-1}是x_{t-1}的函数,则:\ frac{partial h_t}{partial x_{t-1}}=frac{partial h_t}{partial h_{t-1}}frac{partial h_{t-1}}{partial x_{t-1}}\ 同理,h_{t-1}是h_{t-2}的函数,h_{t-2}是x_{t-2}的函数,则:\ frac{partial h_t}{partial x_{t-2}}=frac{partial h_t}{partial h_{t-1}}frac{partial h_{t-1}}{partial h_{t-2}}frac{partial h_{t-2}}{partial x_{t-2}}\ 以此类推,partial h_t对partial x_{t-k}的偏导数如下:\ frac{partial h_t}{partial x_{t-k}}=frac{partial h_t}{partial h_{t-1}}frac{partial h_{t-1}}{partial h_{t-2}}cdotsfrac{partial h_{t-k+1}}{partial h_{t-k}} frac{partial h_{t-k}}{partial x_{t-k}}\ =[prod_{j=t-k+1}^tfrac{partial h_j}{partial h_{j-1}}]frac{partial h_{t-k}}{partial x_{t-k}}\ ={prod_{j=t-k+1}^t[diag(frac{partial h_j}{partial z_j})W_h]}frac{partial h_{t-k}}{partial x_{t-k}}
令 zt=Wixt+Whht−1+b则 ∂xt∂ht=∂zt∂htWi, ∂ht−1∂ht=∂zt∂htWh因为ht是ht−1的函数,ht−1是xt−1的函数,则:∂xt−1∂ht=∂ht−1∂ht∂xt−1∂ht−1同理,ht−1是ht−2的函数,ht−2是xt−2的函数,则:∂xt−2∂ht=∂ht−1∂ht∂ht−2∂ht−1∂xt−2∂ht−2以此类推,∂ht对∂xt−k的偏导数如下:∂xt−k∂ht=∂ht−1∂ht∂ht−2∂ht−1⋯∂ht−k∂ht−k+1∂xt−k∂ht−k=[j=t−k+1∏t∂hj−1∂hj]∂xt−k∂ht−k={j=t−k+1∏t[diag(∂zj∂hj)Wh]}∂xt−k∂ht−k
因为激活函数为tanh,
h
j
=
t
a
n
h
(
z
j
)
h_j=tanh(z_j)
hj=tanh(zj),因此
∂
h
j
∂
z
j
≤
1
frac{partial h_j}{partial z_j}le1
∂zj∂hj≤1。若
W
h
W_h
Wh较大,则
k
k
k较大时
∂
h
t
∂
x
t
−
k
frac{partial h_t}{partial x_{t-k}}
∂xt−k∂ht非常大,出现梯度爆炸情况;若
W
h
W_h
Wh较小,则当
k
k
k较大时,
∂
h
t
∂
x
t
−
k
frac{partial h_t}{partial x_{t-k}}
∂xt−k∂ht基本等于0,即
x
t
−
k
x_{t-k}
xt−k发生改变时,状态向量
h
t
h_t
ht基本不变,
h
t
h_t
ht与
x
t
−
k
x_{t-k}
xt−k基本不存在相关关系,Simple RNN遗忘了很久之前的输入信息。
5. 电影评论情感分析(二)
电影评论情感分析(二)使用Simple RNN模型分析电影评论情感,设计如下:
- 模型结构:Embedding层+SimpleRNN层+softmax分类器
- 词嵌入维度:16
- 状态向量维度:32
5.1 模型搭建
数据处理与3.1部分相同,直接介绍搭建神经网络模型。为了展示PaddlePaddle的不同模型搭建方法及高低阶API使用方法,电影评论情感分析(二)将使用不同的方式搭建及训练模型。
定义继承自paddle.nn.Layer的SimpleRNNModel类,在初始化函数__init__中定义网络各层,重写forward方法,实现前向计算流程。代码如下:
class SimpleRNNModel(paddle.nn.Layer):
def __init__(self, emb_size, hidden_size):
super(SimpleRNNModel, self).__init__()
self.emb = paddle.nn.Embedding(num_embeddings=5149, embedding_dim=emb_size)
self.simple_rnn = paddle.nn.SimpleRNN(input_size=emb_size, hidden_size=hidden_size)
self.fc = paddle.nn.Linear(in_features=hidden_size, out_features=2)
self.softmax = paddle.nn.Softmax()
def forward(self, x):
x = self.emb(x)
# SimpleRNN分别返回所有时刻状态和最后时刻状态,这里只使用最后时刻状态
_, x = self.simple_rnn(x)
# 去掉第0维,这么处理与PaddlePaddle的SimpleRNN层返回格式有关
x = paddle.squeeze(x, axis=0)
x = self.fc(x)
x = self.softmax(x)
return x
5.2 模型训练
使用PaddlePaddle低阶API训练模型,定义train函数,遍历epoch次训练样本,在每个epoch的每个batch内,依次执行前向计算、计算损失、后向传播、梯度更新,并且每个epoch遍历结束后评估测试集准确率。代码如下:
def train(model, epochs, train_loader, test_loader):
# 将模型设置为训练模式
model.train()
# 定义优化器
opt = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader):
sent = data[0]
label = data[1]
# 前向计算输出
logits = model(sent)
# 计算损失
loss = paddle.nn.functional.cross_entropy(logits, label, use_softmax=False)
if batch_id % 50 == 0:
acc = paddle.metric.accuracy(logits, label)
print("epoch: {}, batch_id: {}, loss: {}, acc:{}".format(epoch, batch_id, loss.numpy(), acc.numpy()))
# 后向传播
loss.backward()
# 参数更新
opt.step()
# 清除梯度
opt.clear_grad()
# 每个epoch数据遍历结束后评估模型
# 将模型设置为评估模式
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(test_loader):
sent = data[0]
label = data[1]
logits = model(sent)
loss = paddle.nn.functional.cross_entropy(logits, label, use_softmax=False)
acc = paddle.metric.accuracy(logits, label)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
avg_acc, avg_loss = np.mean(accuracies), np.mean(losses)
print("[validation] accuracy/loss: {}/{}".format(avg_acc, avg_loss))
# 将模型重新设置为训练模式
model.train()
设置超参数seq_len = 100、emb_size = 16、hidden_size = 32,调用get_data_loader函数加载训练和测试数据,实例化模型对象。使用paddle.summary获得模型信息如下:
---------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
=================================================================================
Embedding-1 [[1, 100]] [1, 100, 16] 82,384
SimpleRNN-1 [[1, 100, 16]] [[1, 100, 32], [1, 1, 32]] 1,600
Linear-1 [[32]] [2] 66
Softmax-1 [[2]] [2] 0
=================================================================================
Total params: 84,050
Trainable params: 84,050
Non-trainable params: 0
---------------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.04
Params size (MB): 0.32
Estimated Total Size (MB): 0.36
---------------------------------------------------------------------------------
调用train函数开启模型训练:
if __name__ == '__main__':
# 设置超参数
seq_len = 100 # 每条文本的长度
emb_size = 16 # 词嵌入(word embedding大小)
hidden_size = 32 # Simple RNN中状态向量维度
# 加载和处理数据
train_data_loader = get_data_loader('train', seq_len=seq_len, data_show=1)
test_data_loader = get_data_loader('test', seq_len=seq_len)
# 创建模型对象
model = SimpleRNNModel(emb_size, hidden_size)
# 查看模型结构信息
paddle.summary(model, input_size=(None, seq_len), dtypes='int64')
# 训练模型
train(model, 3, train_data_loader, test_data_loader)
训练过程信息及结果如下:
epoch: 0, batch_id: 0, loss: [0.6936736], acc:[0.5390625]
epoch: 0, batch_id: 50, loss: [0.6944036], acc:[0.484375]
epoch: 0, batch_id: 100, loss: [0.6921302], acc:[0.515625]
epoch: 0, batch_id: 150, loss: [0.69894063], acc:[0.5]
[validation] accuracy/loss: 0.532892644405365/0.6888695359230042
epoch: 1, batch_id: 0, loss: [0.68087435], acc:[0.5703125]
epoch: 1, batch_id: 50, loss: [0.64476], acc:[0.6328125]
epoch: 1, batch_id: 100, loss: [0.57881236], acc:[0.703125]
epoch: 1, batch_id: 150, loss: [0.47674033], acc:[0.8046875]
[validation] accuracy/loss: 0.7377804517745972/0.5892166495323181
epoch: 2, batch_id: 0, loss: [0.5755479], acc:[0.7421875]
epoch: 2, batch_id: 50, loss: [0.5476066], acc:[0.7421875]
epoch: 2, batch_id: 100, loss: [0.53570944], acc:[0.765625]
epoch: 2, batch_id: 150, loss: [0.4936667], acc:[0.765625]
[validation] accuracy/loss: 0.7520833611488342/0.5342828035354614
本文中实战部分,将训练集、测试集中文本数据截断或填充,使得不同长度的原始文本经过处理后长度一致采用的是保留文本数据中前面部分,截断长文本后面部分,在短文本后面部分填充的方法。由于SimpleRNN的遗忘问题,越靠近最后时刻的数据记忆越深刻。本文这种数据处理方法,使得靠近最后时刻的数据要么是一段文本中的中间部分(一般来说,一段评论更倾向于在开头和结尾表达感情。),要么是填充的无意义符号。经过训练发现在测试即上的表现基本比第3部分电影评论情感分析(一)模型差,由此可见数据处理的重要性。如果将
seq_len设置为200,实测在测试集上基本无法做出正确的预测。因为在末尾填充的无意义信息过多,而且SimpleRNN遗忘掉了最开始的输出数据。预期在数据处理时,采用保留文本数据中后面部分,截断长文本前面部分,在短文本前面部分填充的方法,测试效果将会好得多。
6. 参考资料链接
- https://www.icourse163.org/learn/ZUCC-1206146808?tid=1461395446#/learn/content?type=detail&id=1237779505&cid=1257874377
- https://www.icourse163.org/learn/ZUCC-1206146808?tid=1461395446#/learn/content?type=detail&id=1237779506&cid=1257874382
- https://www.icourse163.org/learn/ZUCC-1206146808?tid=1461395446#/learn/content?type=detail&id=1237779507&cid=1257874386
- https://www.icourse163.org/learn/ZJU-1206573810?tid=1206902211#/learn/content?type=detail&id=1235268008&cid=1255629043
- https://www.cnblogs.com/nio-nio/p/11599199.html
- https://www.paddlepaddle.org.cn/documentation/docs/zh/tutorial/nlp_case/imdb_bow_classification/imdb_bow_classification.html
- https://aistudio.baidu.com/aistudio/projectdetail/1981183
- https://www.youtube.com/watch?v=NWcShtqr8kc&list=PLvOO0btloRnuTUGN4XqO85eKPeFSZsEqK&index=1
- https://www.youtube.com/watch?v=6_2_2CPB97s&list=PLvOO0btloRnuTUGN4XqO85eKPeFSZsEqK&index=2
- https://www.youtube.com/watch?v=Cc4ENs6BHQw&list=PLvOO0btloRnuTUGN4XqO85eKPeFSZsEqK&index=3
最后
以上就是会撒娇鸭子最近收集整理的关于简单循环神经网络(Simple RNN)原理与实战1. 前言2. 类别特征数值化方法3. 电影评论情感分析(一)4. Simple RNN5. 电影评论情感分析(二)6. 参考资料链接的全部内容,更多相关简单循环神经网络(Simple内容请搜索靠谱客的其他文章。








发表评论 取消回复