一.全连接层、CNN、RNN三种网络结构的分析
- 对于全连接网络:理论上全连接网络可以处理所有的问题,但是对于有些问题,全连接网络的效率非常差,所以对于一些特定的问题要使用更加有效的网络结构。
- 对于图片这样的2维信息处理,毫无疑问CNN会更有优势。
- 对于有着明显的前后关系的序列数据,比如说随着时间变化的数据,当使用RNN对其进行处理的时候,也会有着巨大的优势。
1.CNN应用举例
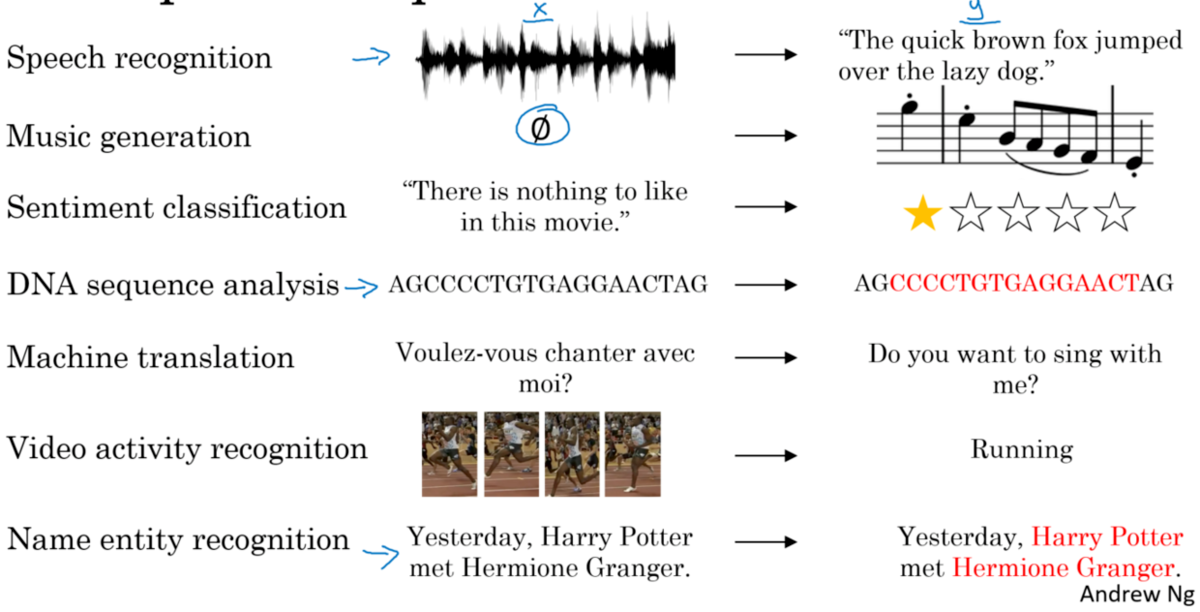
现实生活中这样的数据和应用比比皆是:
-
说话时的语音处理,可以用序列模型进行语音识别
-
听的音乐,可以用序列模型进行音乐生成
-
我们的语言信息,可以用序列模型进行机器翻译、情感分析等等
-
还有感兴趣的金融市场波动,可以用序列模型进行预测
-
当然此外还有诸如DNA序列,视频动作识别等等
二.循环神经网络–RNN
1.首先来看看,为什么普通的全连接网络并不适用于序列数据处理。
- 第一,如果使用全连接网络,那么输入输出的长度就被固定了,而往往序列数据的输入和输出长度是变化的
- 在学习序列关系的时候,RNN可以分享学到的关系特征,节省参数,而全连接网络不行。这里有点像CNN在不同的区域共享参数一样。
2.来看看RNN到底是什么样子
首先假设输入是长度为t的序列x,(就比如说是一个句子x有t个单词)。
于是对于RNN单元,我们从左到右每次输入一个时序单位的数据
x
t
x_t
xt,也就是一个单词。
那么RNN会对它进行一些运算,获得一个隐藏状态
s
t
s_t
st(
h
t
h_t
ht),传往下一个时序,同时再根据
s
t
s_t
st(短期记忆,会不断的更新(擦除和重写))计算出
o
t
o_t
ot(这里要是经过一个线性处理的话就叫做
0
t
0_t
0t,要是不经过线性处理也可以直接作为输出,那样的话就直接是
s
t
s_t
st了)。(对于Simple RNN,来说没有长期的记忆)
s
t
=
f
(
W
s
s
s
t
−
1
+
W
s
x
x
t
+
b
s
)
s_{t}=f left(W_{ss} s_{t-1}+W_{sx} x_{t} + b_sright)
st=f(Wssst−1+Wsxxt+bs)
y
^
t
=
f
(
W
s
y
s
t
+
b
y
)
widehat{y}_{t}=fleft(W_{s y} s_{t}+b_{y}right)
y
t=f(Wsyst+by)
式子中w是权重矩阵,f是一个非线性激活函数。因此对于每一个时序,RNN都是输入当前时序的的
x
t
x_t
xt,和来自之前时序的状态
s
t
−
1
s_{t-1}
st−1,
x
t
x_t
xt可以理解为当前的信息,而
s
t
−
1
s_{t-1}
st−1可以理解为对之前信息的总结。
循环网络之所以称之为循环,是因为实际上一个单层的RNN网络只有一个单元,每次输入一个时序的数据,总结信息然后再传给自己,进入下一个时序。
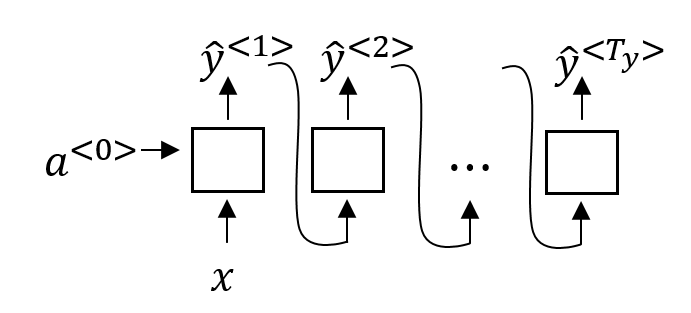
一般RNN的表示方式有两种,一种是像上图左端一样,一个单元加一个循环的符号,便于理解RNN的原理;还有一种是,把它展开,将不同时序的运算过程都表示出来,便于理解RNN的运算过程
3.RNN的不同的架构
为了处理有着不同输入输出组合的各类任务,RNN可以分为以下几种不同的架构。
以下图中所有的
a
<
?
>
a^{<?>}
a<?>均为
s
?
s_?
s?
- 一对一:
其实就是普通的神经网络。
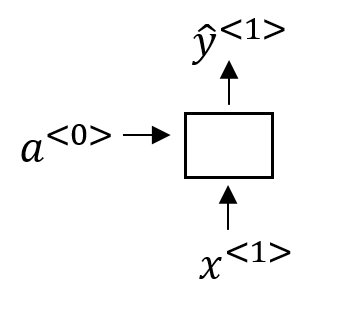
- 多对一:
多个时序的输入,得出一个时序的输出。比如说情感分析里面,看完一句评论,然后输出这句话是正面还是负面(对一句评论里边的每一个字的信息进行综合以后,得到一个总的判别)。这种结构又叫做Acceptor(接受器),可以看作接受一段输入,然后输出结论。
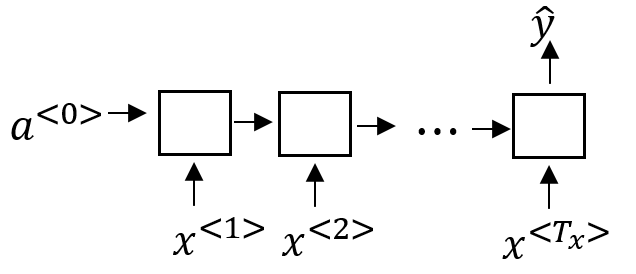
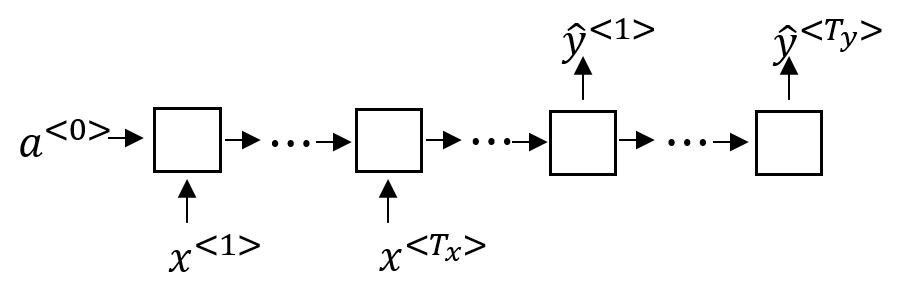
- 多对多:
多个时序输入对多个时序的输出。最经常的应用就是Tagging(标记),比如说判断一句话中每一个词的词性,输入包含多个词的句子,然后输出对应的词性,这种结构又叫做Transducer(变换器),可以看作将一段输入转换成另一种表示。
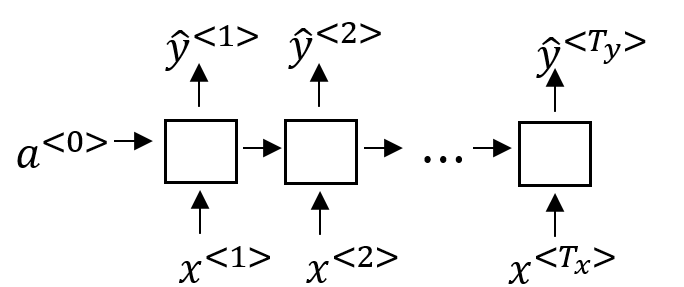
- 一对多:
给出一个时序的输入,获得多个时序的输出。比如说音乐生成和语言生成,给定第一个音符或字,生成一段旋律或者一句话。这个可以算是Transducer里的一种特殊情况
- 多对多(特):
还有最后一种比较特殊的情况,也是多对多,但不是Transducer,而是被叫做seq2seq(序列到序列)编码器解码器模型,主要用于像机器翻译这样的任务。(前期先输入过个输入序列,后期再输出多个输出序列)
4.语言模型于序列生成
因为语言天生的序列性,于是理所当然的RNN在自然语言处理中得到了广泛的应用。虽然自然语言处理也使用到CNN,但并不多。
语言模型
先来看看RNN如何解决自然语言处理中,一个很基础同时也很重要的问题:语言模型。之前在机器翻译中也提到过,语言模型就是判断你说的是不是人话。
科学一点讲就是,语言模型判断这句话出现的概率。一句人话“我吃饭。”的概率显然比一句乱七八糟的“吃,饭我”的概率要高。
所以语言模型就是求一句话的概率,根据概率论可以把求长度为t的句子的概率,分成对前t-1个词求概率,然后用这个概率乘以第t个单词出现在这样的t-1个词后面的概率;而对t-1个词求概率,可以分成对前t-2个词求概率,乘上…以此类推。
而用RNN可以很好的模拟这个过程。
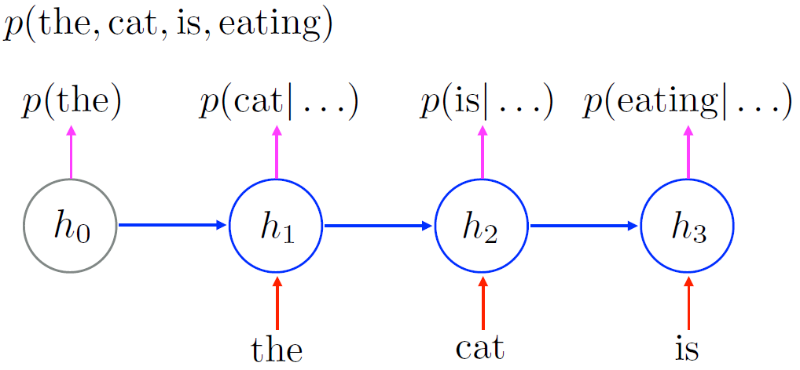
我们只需要拿着RNN在一般的语言数据上训练,让它们记住这些概率就可以了。
语言模型的应用有很多,比方说可以辅助机器翻译。而这里吴教授提到它的一个不能算是应用的应用,序列生成。
序列生成
就是先随便输入一个词,然后RNN输出对下一个词的预测,这里的输出是通过softmax得到的概率列表,表示每一个词的预测概率。之后根据这些概率,采样出一个词,作为下一个时序的输入。然后重复之前的过程,最后就可以获得该语言模型生成的句子。
输给模型 出战,不胜必斩!”庞 生成: 出战,不胜必斩!”庞德有张,而来。二人与言!”二绍急闻将骑去了了,不可护弟如开策一十,各兵当夺。,入荆州,皆口而奉,金密有奉罪...
就是看起来好像挺通,但是读完发现完全不知所云。
想更深入了解语言模型可以看看这篇文章:浅谈NLP中条件语言模型(Conditioned Language Models)的生成和评估
5.NLP 的问题
问题探究: 梯度消失/梯度爆炸、过拟合/欠拟合
随着时序的长度变长,RNN的深度也就不断增加这样就无法避免深度学习中的两个典型问题,梯度爆炸和梯度消失,具体可参考这篇文章 《神经网络训练中的梯度消失与梯度爆炸》
梯度爆炸还好解决,只需要每一次更新前,检查梯度的大小,太大的话就进行修剪(clip)(具体的修剪的方法还需要进一步的考虑)
梯度消失的问题就不好办了,因此提出了更加强大的RNN结构来避免梯度消失的问题。
二.循环神经网络–LSTM、GRU
更强大的RNN结构里边,最著名的两个结构,一个是1997年由四大天王之一的 Jurgen Schmidhuber提出的老牌大哥LSTM,另一个是后起之秀GRU,两者都属于门控结构。而前边提到的RNN单元因为简单,就叫做简单RNN(Simple RNN),也叫作埃尔曼(Elman)RNN.
回到主题,相对来说,GRU因为简单,也更加简单容易理解一些,所以吴教授先解说了GRU。但是根据我的学习经验,我更推崇 Yoav Goldberg 的 Neural Network Methods for Natural Language Processing 书中的讲解步骤。
首先来说为什么需要门控机制。首先简单的RNN每次更新时是对记忆全体进行擦除和重写,这样导致不能捕捉长期关系(这里为什么这样讲?不是每一次都是上一次的状态和这一次的输入经过激活函数得到新的状态码?)。而有的时候需要长期保留一些记忆来捕捉长期关系。正如人一样,有长期的记忆,同时根据新的信息对局部进行更新。
因此也可以让RNN有这样的结构,在每个时序根据输入,选择哪些记忆保留,哪些记忆忘掉且用新的信息更新。
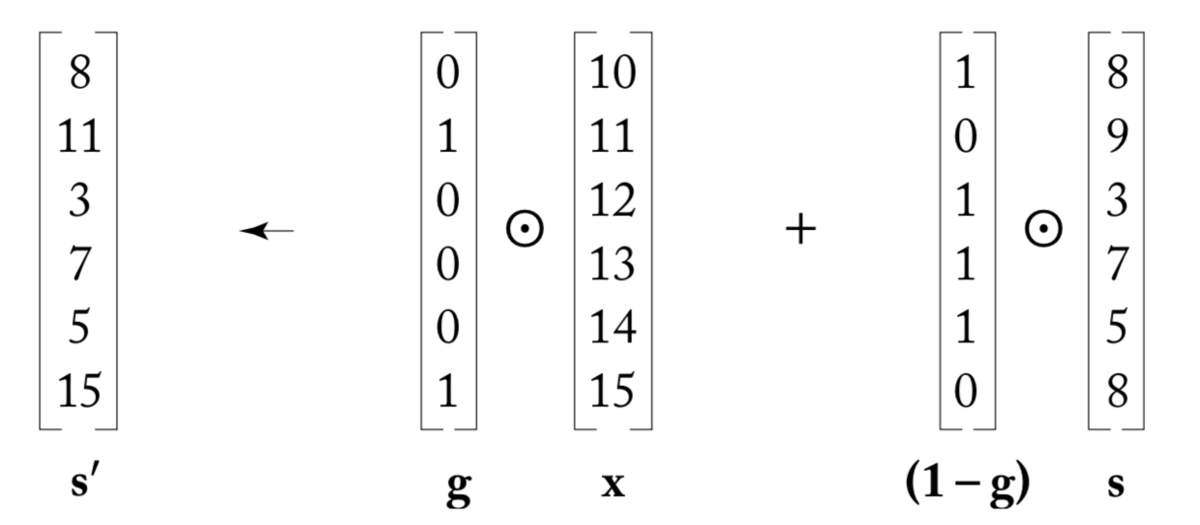
如上图所示,s是之前时序传递过来的状态,x是当前时序的输入,g则是门(gate)。门中数值位置是1的部分表示保留记忆的部分,而其他不保留的则直接用当前的输入相应位置更新代替(这也就是为什么强调那一部分和那一部分的形状是一样的)
这就是门结构RNN里边的基本模型了。而GRU和LSTM则是对着里面的门结构进行更细致的设计,因为像这样子的直接 全部擦除和更新的方式,太过于简单粗暴了,有的时候可能希望,保留一部分记忆,更新一部分记忆。
先是一个简化版本的GRU,公式如下,和上边讲到的记忆更新公式对比一下就很好理解了。
GRU 里边只有一个状态
c
/
s
c/s
c/s(用c和s都行,都表示长期的记忆)
c
~
t
=
tanh
(
W
c
[
c
t
−
1
,
x
t
]
+
b
c
)
Γ
u
=
σ
(
W
u
[
c
t
−
1
,
x
t
]
+
b
u
)
c
t
=
Γ
u
∗
c
~
t
+
(
1
−
Γ
u
)
∗
c
t
−
1
begin{array}{l}{tilde{c}_{t}=tanh left(W_{c}left[c_{t-1}, x_{t}right]+b_{c}right)} \ \ {Gamma_{u}=sigmaleft(W_{u}left[c_{t-1}, x_{t}right]+b_{u}right)} \ \ {c_{t}=Gamma_{u} * tilde{c}_{t}+left(1-Gamma_{u}right) * c_{t-1}}end{array}
c~t=tanh(Wc[ct−1,xt]+bc)Γu=σ(Wu[ct−1,xt]+bu)ct=Γu∗c~t+(1−Γu)∗ct−1
中间的公式 Γ Gamma Γ(希腊字母G,gate)就是计算出一个门函数(u表示update更新),负责长期记忆的 c t c_t ct的更新,而用来更新的信息比直接输入x,中间增加了一些处理 c ~ t tilde{c}_{t} c~t,是利用前边传过来的 c t − 1 c_{t-1} ct−1和当前输入 x t x_t xt计算得到的。(这里本来新的状态 c t c_t ct是由之前的状态 c t − 1 c_{t-1} ct−1和新的输入 x t x_t xt经过门函数直接得到的,这里就是通过这样的方式中间增加了一些处理,将这个时序输入信息转变成 c ~ t tilde{c}_{t} c~t,再与之前的状态通过门函数结合起来得到新的状态 c t c_t ct)
那么完整的GRU是什么样子的呢?介个样子。
对于GRU来说,只有长期记忆,对输入信息
x
t
x_t
xt增加了一个处理的步骤
s
~
t
tilde{s}_{t}
s~t(对于上边的简单版本就是
c
~
t
tilde{c}_{t}
c~t),同时GRU只有两个门控,r和z
s
t
=
R
G
R
U
(
s
t
−
1
,
x
t
)
=
(
1
−
z
)
⊙
s
t
−
1
+
z
⊙
s
t
~
z
=
σ
(
x
t
W
x
z
+
s
t
−
1
W
s
z
)
r
=
σ
(
x
t
W
x
r
+
s
t
−
1
W
s
r
)
s
t
~
=
tanh
(
x
t
W
x
s
+
(
r
⊙
s
t
−
1
)
W
s
g
)
begin{aligned} s_{t}=R_{mathrm{GRU}}left(s_{t-1}, x_{t}right) &=(1-z) odot s_{t-1}+z odot tilde{s_{t}} \ z &=sigmaleft(x_{t} W_{x z}+s_{t-1} W_{s z}right) \ r &=sigmaleft(x_{t} W_{x r}+s_{t-1} W_{s r}right) \ tilde{s_{t}} &=tanh left(x_{t} W_{x s}+left(r odot s_{t-1}right) W_{s g}right) end{aligned}
st=RGRU(st−1,xt)zrst~=(1−z)⊙st−1+z⊙st~=σ(xtWxz+st−1Wsz)=σ(xtWxr+st−1Wsr)=tanh(xtWxs+(r⊙st−1)Wsg)
这里多了一个r门,其实就是在获得更新信息的时候,进行了更加复杂的处理。
比起GRU,LSTM则要更加的复杂,具体的方程是这样的。
s
t
=
R
LSTM
(
s
t
−
1
,
x
t
)
=
[
c
t
;
h
t
]
c
t
=
f
⊙
c
t
−
1
+
i
⊙
z
h
t
=
o
⊙
tanh
(
c
t
)
i
=
σ
(
x
t
W
x
i
+
h
t
−
1
W
h
i
)
f
=
σ
(
x
t
W
x
f
+
h
t
−
1
W
h
f
)
o
=
σ
(
x
t
W
x
o
+
h
t
−
1
W
h
o
)
z
=
tanh
(
x
t
W
x
z
+
h
t
−
1
W
h
z
)
y
t
=
O
LSTM
(
s
t
)
=
h
t
begin{aligned} s_{t}=R_{text {LSTM}}left(s_{t-1}, x_{t}right) &=left[c_{t} ; h_{t}right] \ c_{t} &=f odot c_{t-1}+i odot z \ h_{t} &=o odot tanh left(c_{t}right) \ i &=sigmaleft(x_{t} W_{x i}+h_{t-1} W_{h i}right) \ f &=sigmaleft(x_{t} W_{x f}+h_{t-1} W_{h f}right) \ o &=sigmaleft(x_{t} W_{x o}+h_{t-1} W_{h o}right) \ z &=tanh left(x_{t} W_{x z}+h_{t-1} W_{h z}right) \ y_{t}=O_{text {LSTM}}left(s_{t}right) &=h_{t} end{aligned}
st=RLSTM(st−1,xt)cthtifozyt=OLSTM(st)=[ct;ht]=f⊙ct−1+i⊙z=o⊙tanh(ct)=σ(xtWxi+ht−1Whi)=σ(xtWxf+ht−1Whf)=σ(xtWxo+ht−1Who)=tanh(xtWxz+ht−1Whz)=ht
LSTM里边有两个状态,一个是c,一个是h。c可以理解为长期记忆,h可以理解为短期记忆。c会通过每个时序输入的信息对自身进行更新,同时一直传递下去。如下图中,c在上边的轴线上不断的向下传递
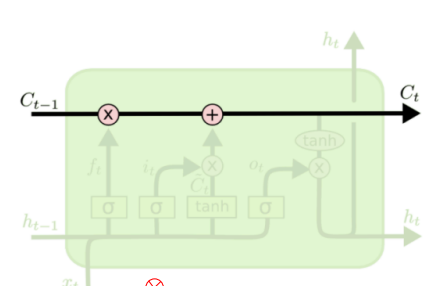
而h则是在每一个时序里边,提取需要提取的短期记忆。这也是LSTM为什么叫做LSTM的原因,Long Short Term Memory(长短期记忆)。
而和GRU一样,对c和h进行操作与更新的就是我们的门结构了。LSTM里边的门有三个, i i i, f f f, o o o,分别为输入门,遗忘门,输出门(这些门控机制的原理就是通过激活函数来控制哪些信息保留,哪些更新)。按照各自的名字,输入门负责决定记住哪些需要输入更新的信息,而遗忘门负责决定忘记哪些长期记忆中的记忆,最后输出门决定输出最后获得的长期记忆中的哪个部分最为短期记忆输出。
1.接下来从比较直观地角度理解为什么GRU还有LSTM可以避免梯度消失的问题,如下图所示:
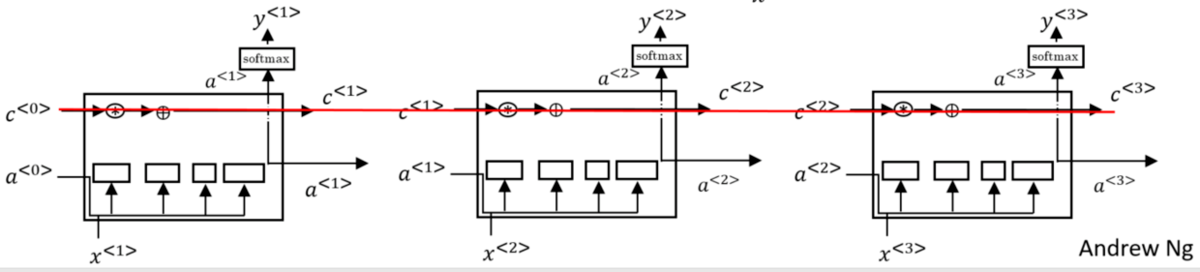
我们可以清晰的看到,在LSTM的上部,长期记忆c从头贯穿到尾,每次只有更新的时候才会对它进行修改。而又因为门函数是sigmoid函数的原因,所以可以对信息进行很好的保留(??)。
关于LSTM和GRU哪一个更好的问题,个人经验来说,目前在很多问题上还是使用经典款的LSTM要好一些,但是因为GRU有结构简单,运算量相对较少的等优势的原因,在很多问题上越来越多的人也开始尝试使用它。(是否可以将LSTM和GRU这样的可以减少梯度消失的机制移植到其他会出现梯度消失的模型上边??)
最近LSTM还出了一个挺火的Nested LSTM(嵌套LSTM),有机会可以写一写。
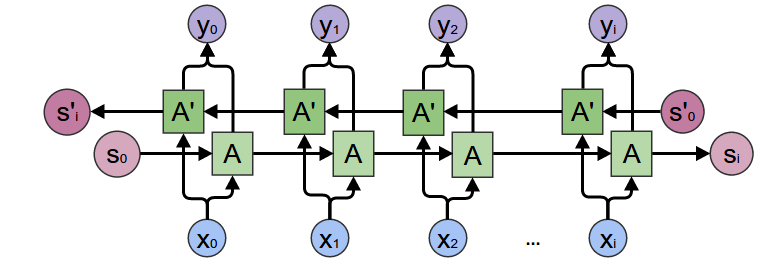
2.增强技巧:双向与加深
对于上边说的这些RNN系列,除了单纯的一个方向和单层运行,还可以对它进行扩展。
比如说,将单向变成双向,只要将输入x反向输入另一个RNN单元,之后将结果与正向拼接起来就好了,双向RNN因为可以利用两个方向的原因,所以一般能够取得更好的结果。(?)(进一步来实验实现)
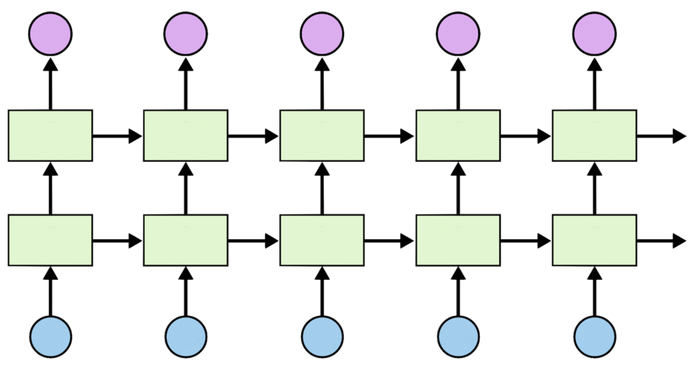
还有就是增加RNN的纵向深度,多添加几层,增加复杂度。
 参考:
参考:
Coursera DeepLearning.ai Sequence Model
Neural Network Methods for Natural Language Processing by Yoav Goldberg (邮箱留下!)
基于LSTM的语言模型
神经网络训练中的梯度消失与梯度爆炸
作者:坂本龙一
链接:https://www.jianshu.com/p/a6fac09028e4
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
最后
以上就是体贴雪碧最近收集整理的关于循环神经网络--RNN GRU LSTM 对比分析一.全连接层、CNN、RNN三种网络结构的分析二.循环神经网络–RNN二.循环神经网络–LSTM、GRU的全部内容,更多相关循环神经网络--RNN内容请搜索靠谱客的其他文章。








发表评论 取消回复