这里写目录标题
- RNN的引入
- RNN的类别
- 两种Network
- 两边同时进行RNN
- LSTM
- LSTM流程
- 深入LSTM结构
- RNN带来的梯度消失和梯度爆炸
- 解决梯度消失的方法:LSTM
- RNN的应用
RNN的引入
RNN:具有记忆的神经网络。
一个词汇表示成一个Vector
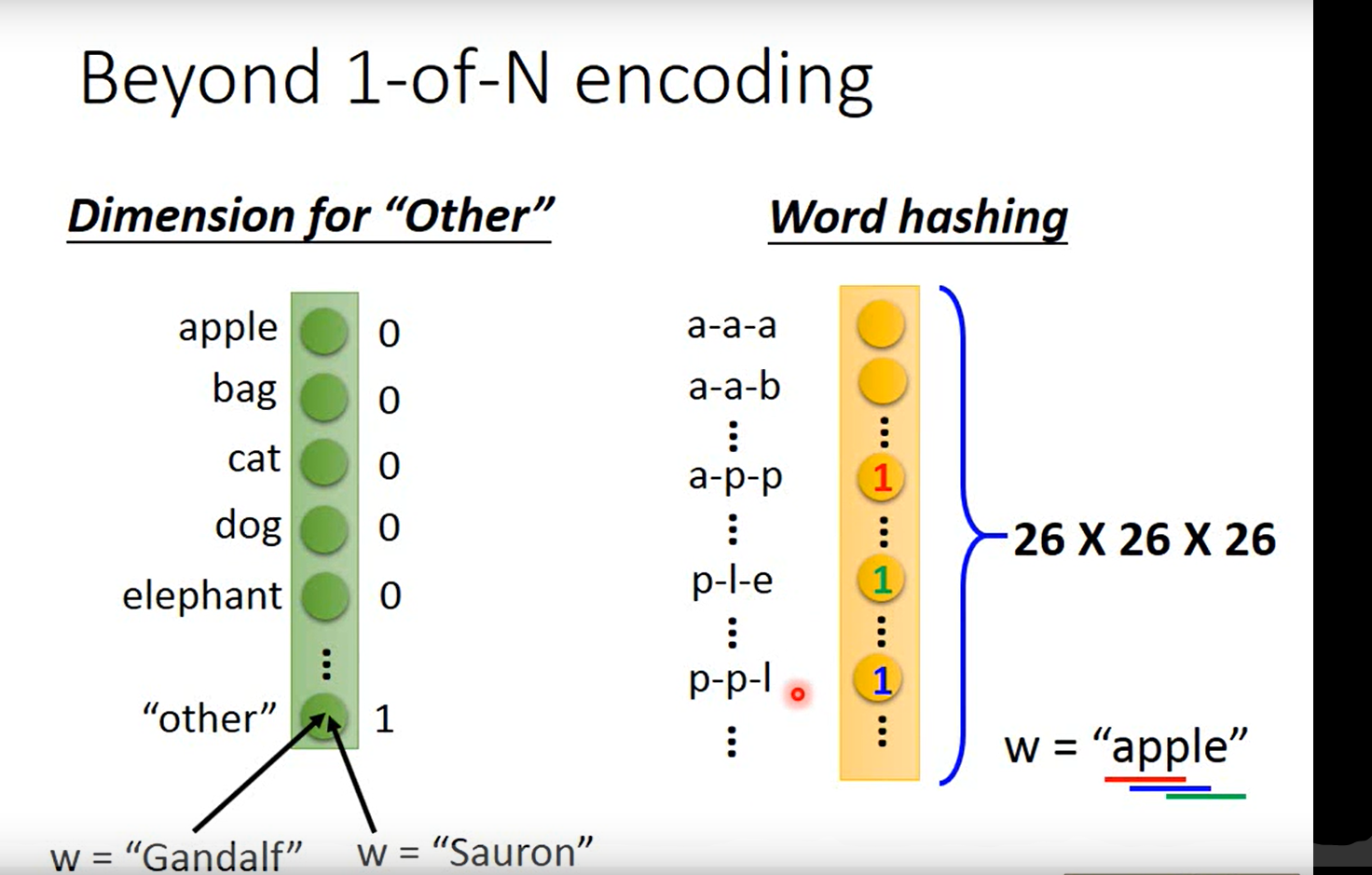
输入一个向量,第n个词的输入和第n-1个词的输出相加,然后生成第n个词的概率
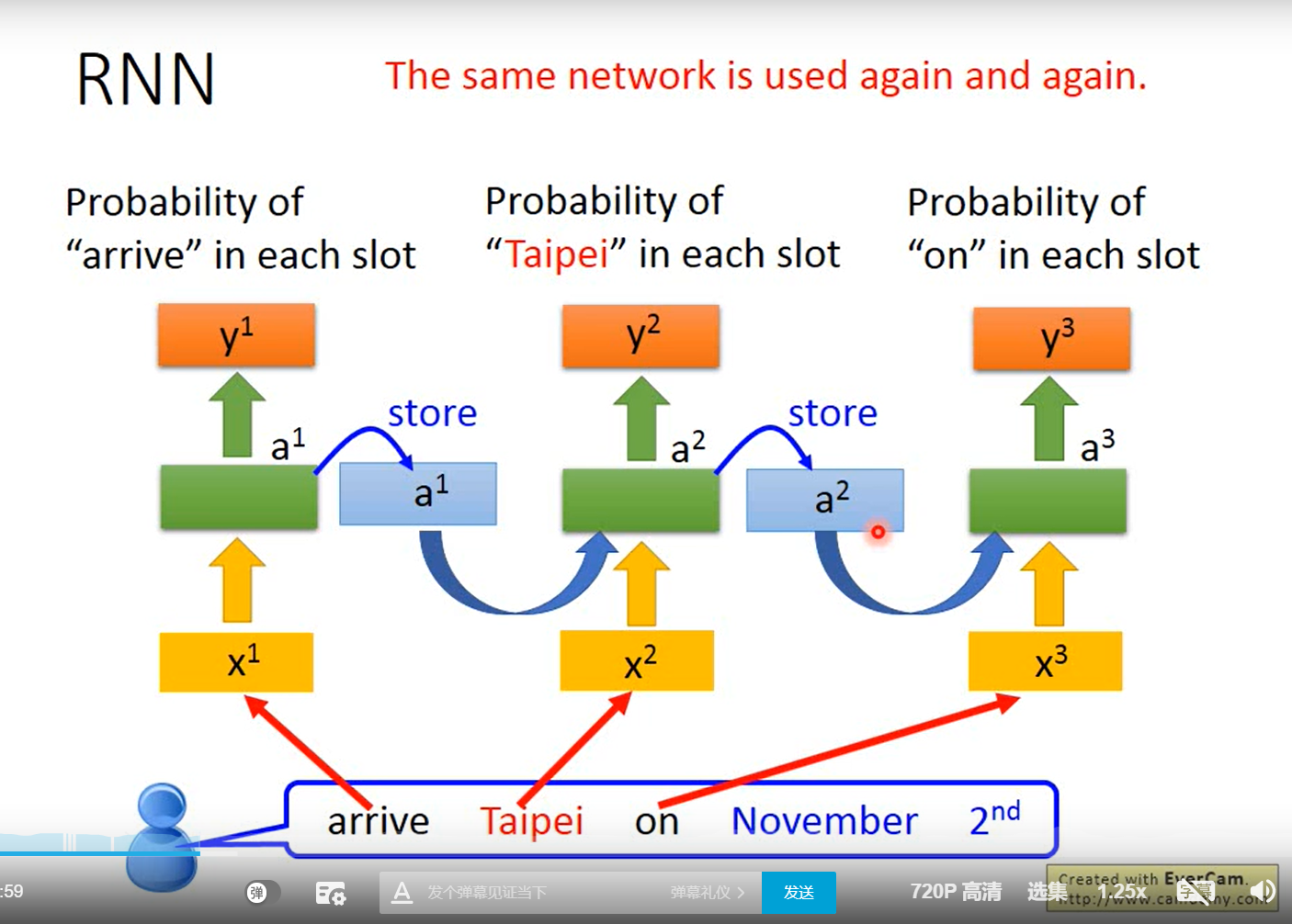
多层的
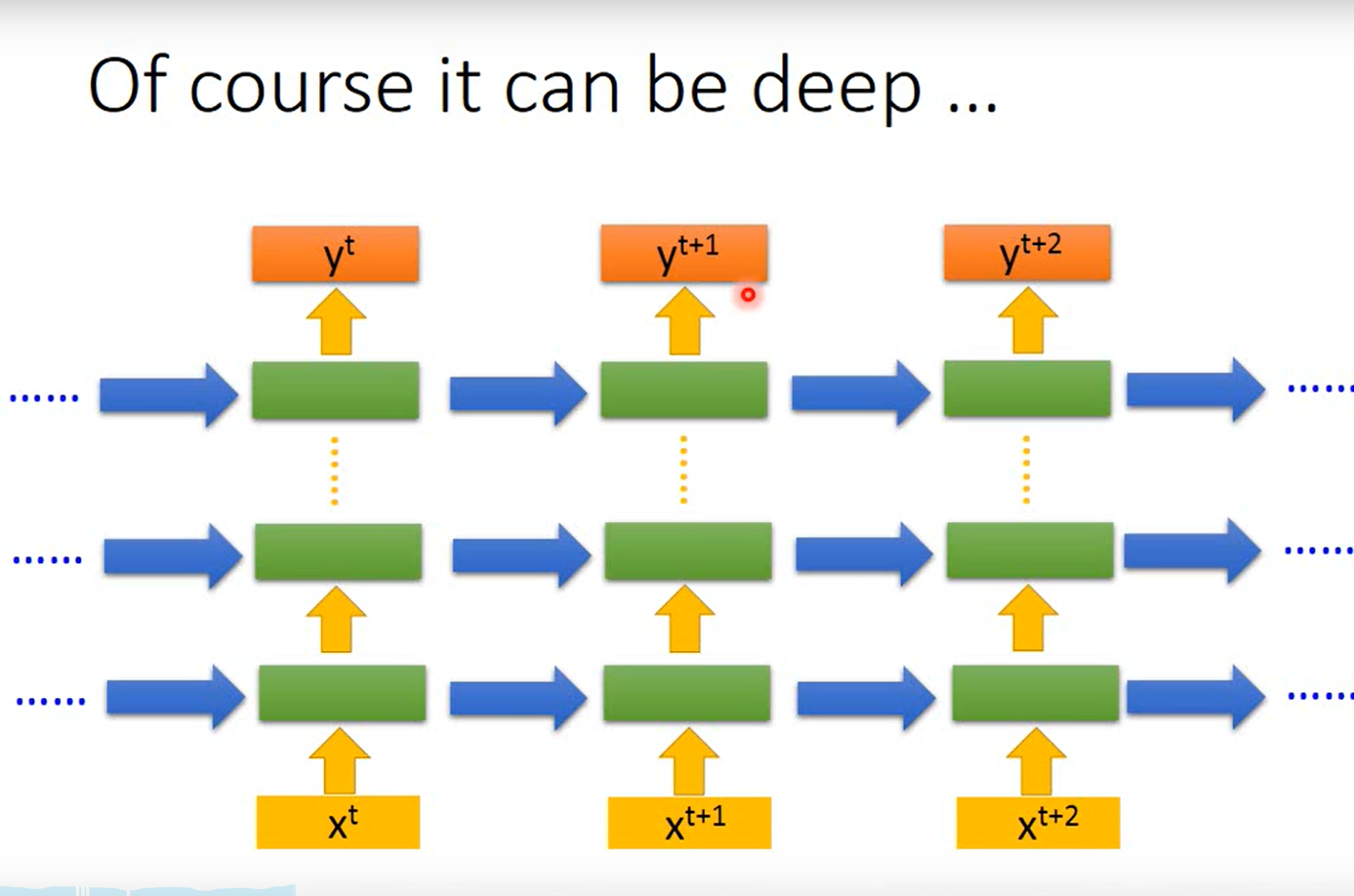
RNN的类别
两种Network
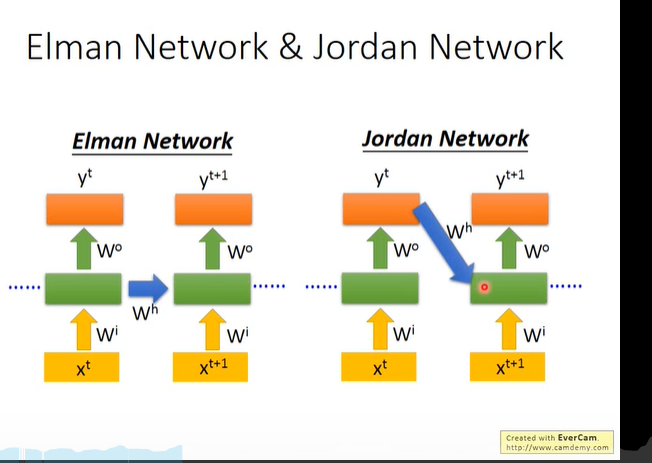
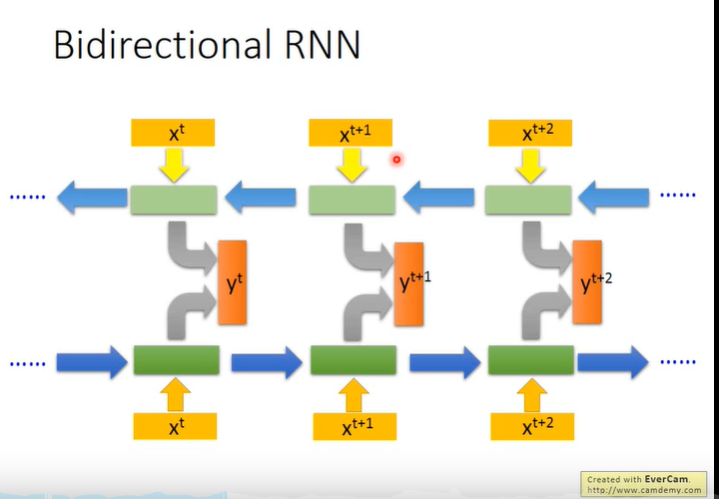
两边同时进行RNN
除了可以获取从头到尾的信息,还能获取从尾到头的信息。
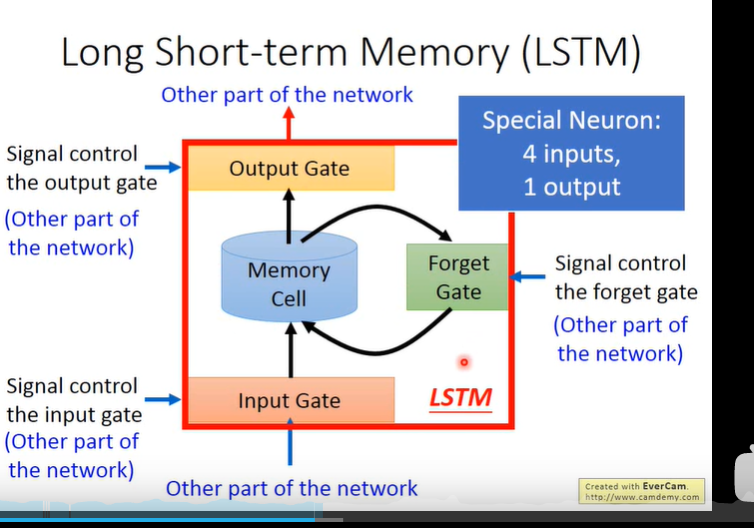
LSTM
LSTM流程
简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。现在的所说的RNN就是LSTM。
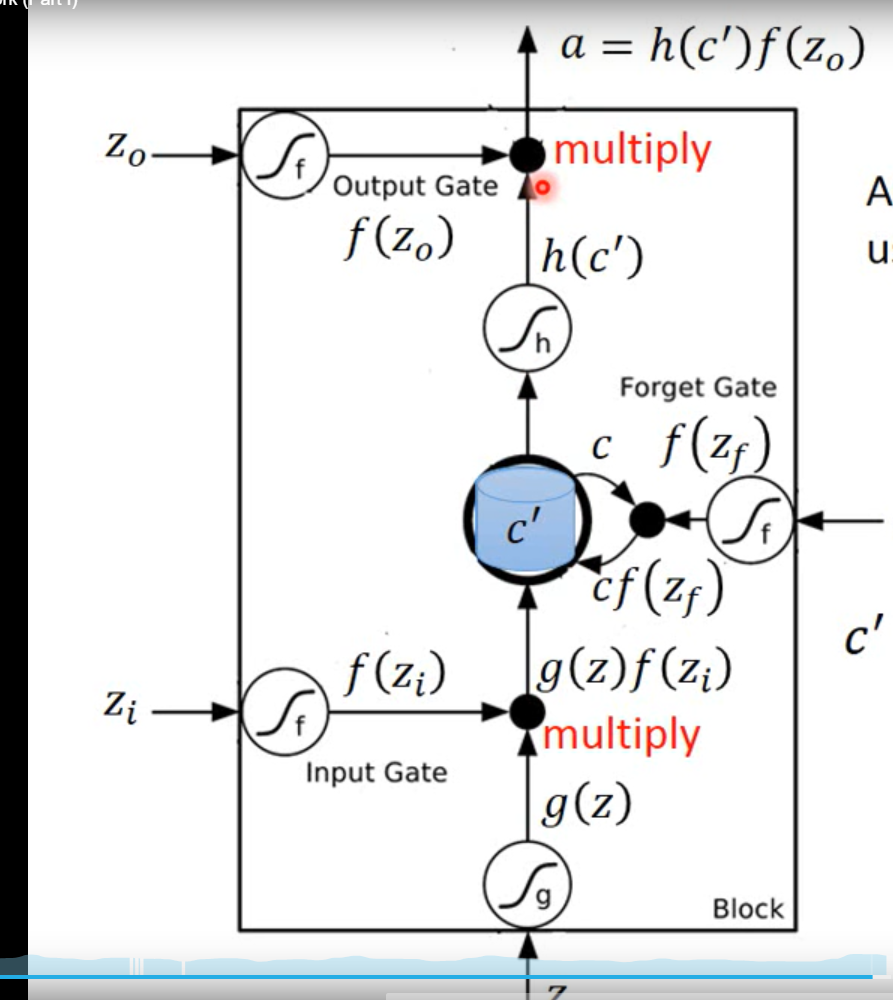
**一个局部LSTM:**每个f(x)函数都是用的sigmoid函数,就是生成0~1的值来表示这个阀门的打开程度大小。
流程:输入向量,输入门(Input Gate)以一定概率控制输入输入,遗忘门(Forget Gata)一一定概率记住这个值,然后输出门(Output Gate)以一定概率输出。
LSTM的参数是普通神经网络的四倍
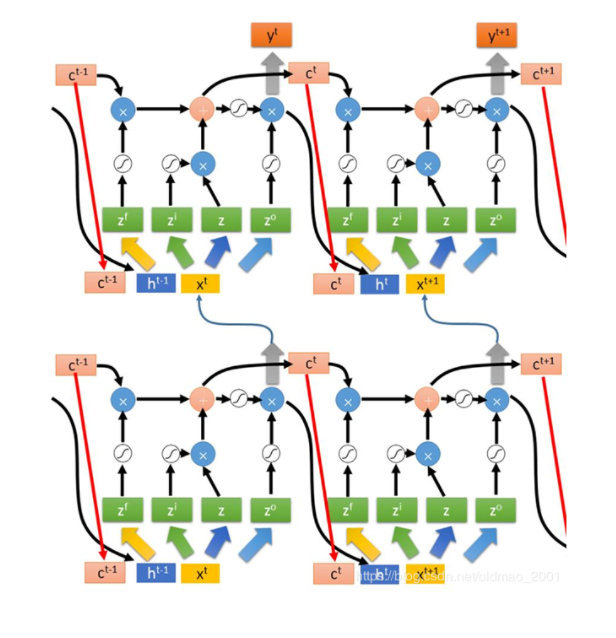
深入LSTM结构
1、首先使用LSTM的当前输入
x
t
x^t
xt和上一个状态传递下来的
h
(
t
−
1
)
h^(t-1)
h(t−1)拼接经过线性激活函数训练得到四个状态。
RNN带来的梯度消失和梯度爆炸
RNN不好训练,因为梯度容易爆炸或者消失。
首先得明白RNN中梯度消失和平常的梯度消失不是一个概念。
RNN 所谓梯度消失的真正含义是,梯度被近距离梯度主导,导致模型难以学到远距离的依赖关系。
原因: 因为每次记忆都会覆盖上一次的值,长久的记忆下去,梯度被近距离梯度主导,远距离梯度很小,导致模型难以学到远距离的信息。
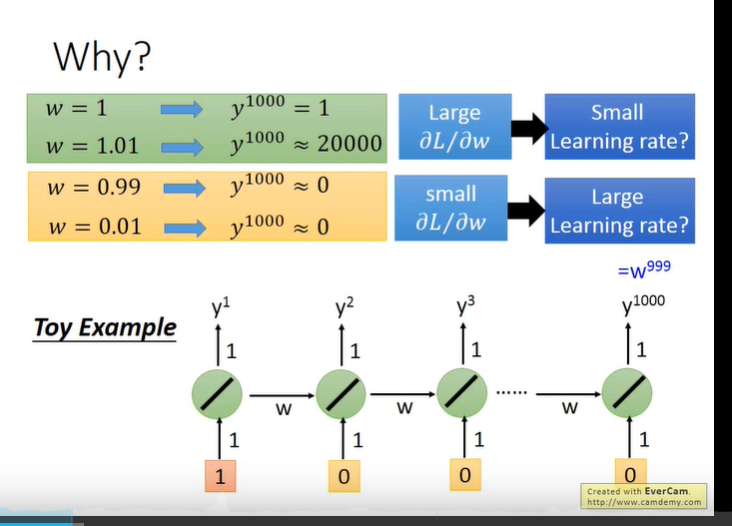
解决梯度消失的方法:LSTM
**原因:**一开始的LSTM没有遗忘门,也就是类似一个残差网络(ResNet),上一次的数据完整的传给了下一次。后面产生遗忘门,每次都选择上次记忆的部分+这次的新值,不是直接覆盖。可以解决RNN中梯度消失的问题。
RNN的应用
最后
以上就是烂漫紫菜最近收集整理的关于从RNN到LSTM的全部内容,更多相关从RNN到LSTM内容请搜索靠谱客的其他文章。








发表评论 取消回复