目录
一.引用
1.引用的概念:
2.引用的格式:
3.引用的特性
4.取别名原则:
难点:隐式类型转换的引用
5.引用的使用场景:
【1】做参数:
【2】做返回值
(1)int& Count() 的讲解
(2)传值、传引用效率比较
6.引用和指针的不同点:
二.内联函数
1.概念:
2.写法和作用:
3.如何通过汇编查看内联后的结果?
4.为什么要有内联函数:
5.特性
6.内联函替换后指令变多真的提高效率了吗?——确实提高了
一.引用
1.引用的概念:
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
2.引用的格式:
举例如下:
 注意:引用类型必须和引用实体是同种类型的
注意:引用类型必须和引用实体是同种类型的
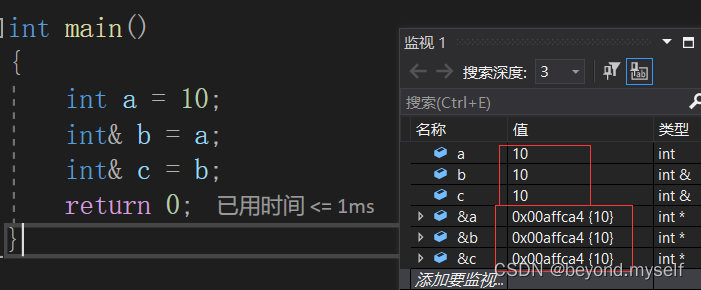
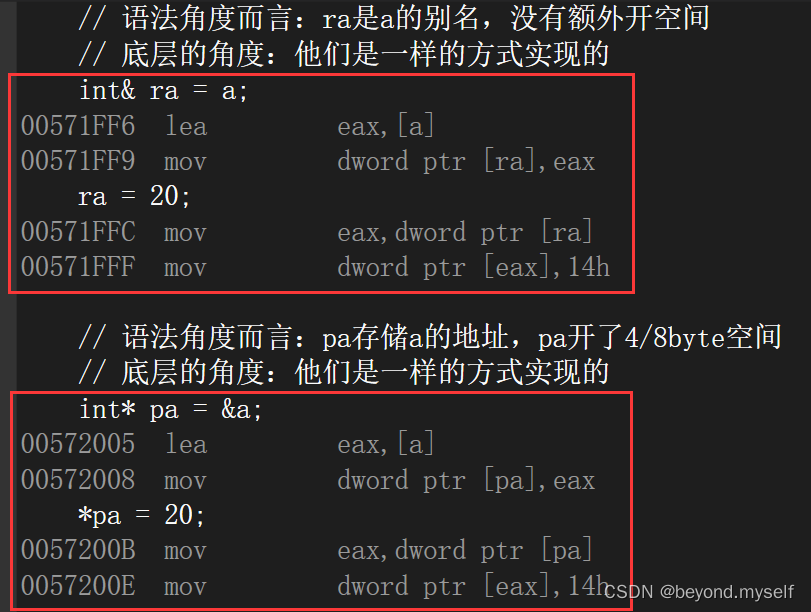
3.引用的特性
int a = 10;
int& b = a;
int& c = b;
int* p = &b; //p是指针(3). 引用一旦引用一个实体,再不能引用其他实体
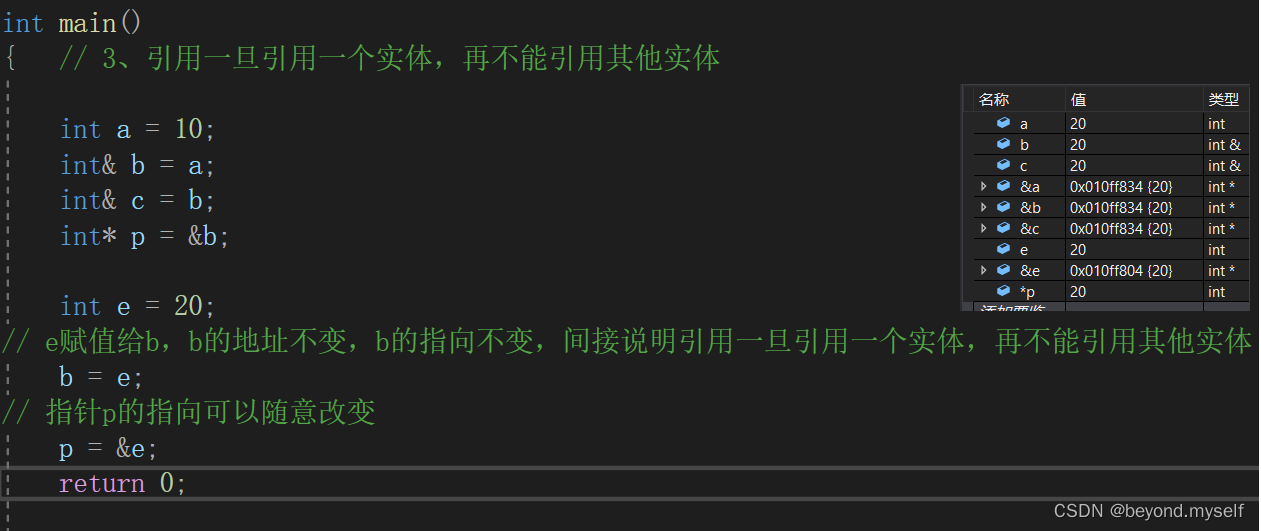
4.取别名原则:
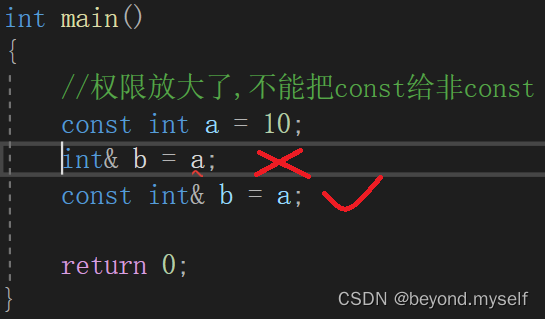
对原引用变量,权限只能缩小,即 可读可写(普通类型) 可以改成 只读(const);不能放大:,即 只读 不能改成 可读可写的
例子1:权限的放大,不能把const给非const
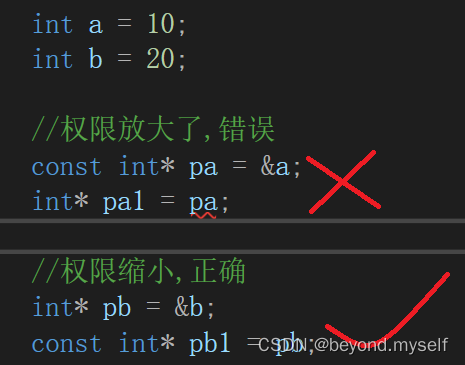
例子2:权限的缩小 非const 既可以给非const,也可以给const:

例子3: 权限缩小和放大规则:适用于引用和指针间
例子4: 权限不适用于普通赋值:

难点:隐式类型转换的引用
整形e能否做双精度浮点型d的别名呢?
直接赋值是不行的,需要加上const才正确。即:const int& e = d; 正确

解释:隐式类型转换的普通赋值的情况,上面的例子:int f=d;从语法上看把8字节的d不能直接给4字节的f,因为浮点数和整形的存储形式就不一样,没办法直接截取,所以d需要先把整数部分给一个4字节的临时变量,再把临时变量给f
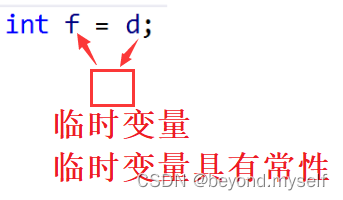
再看引用:int& e=d; 临时变量具有常性,所以这里把临时变量给引用e的时候,相当于是把自带const的临时变量赋值给非const的e,把只读的给可读可写的是放大了权限,所以错误;必须改成const int& e=d; 才正确!
5.引用的使用场景:
【1】做参数:
void Swap(int& x, int& y)
{
int tmp = x;
x = y;
y = tmp;
}
void Swap(double& x, double& y)
{
double tmp = x;
x = y;
y = tmp;
}
int main()
{
int a = 0, b = 1;
swap(a, b);
double c = 1.1, d = 2.2;
swap(c, d);
return 0;
}(2)作输出型参数:
leetcode上的题往往有输出型参数,在c++中就可以用引用代替更加方便
【2】做返回值
(1)int& Count() 的讲解
传值返回:会有一个拷贝
传引用返回:没有这个拷贝了,函数返回的直接就是返回变量的别名
int& Count()
{
int n = 0;
n++;
return n;
}
int main()
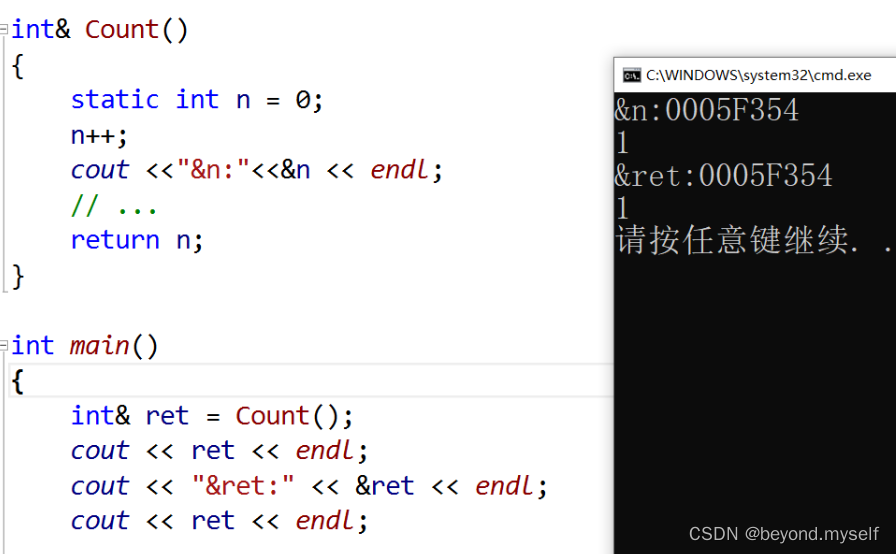
{
int ret = Count();
return 0;
}——————————————————————————————————手动分割
首先我们来看普通的传值返回:普通的传值返回需要把返回值n给一个函数类型int的临时变量(函数类型就是返回值类型),再把临时变量给ret。
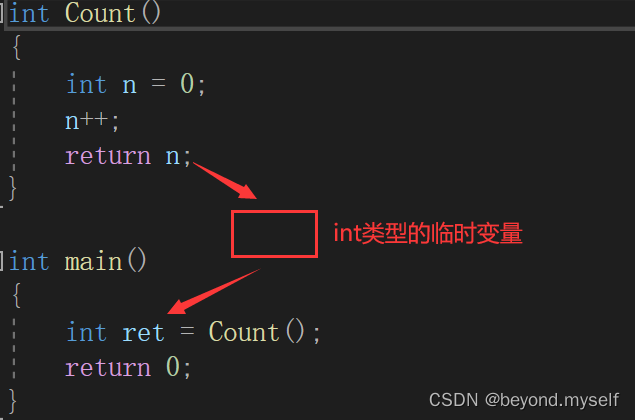
为什么设计一个临时变量,直接把n给ret不行吗?
答:不行,因为当函数Count里执行完各种代码后,返回n,等出了Count函数的作用域后n就会销毁,所以不能直接把n给ret,需要一个临时变量。
如何证明返回时存在临时变量呢?:如果你用int& ret 接收,写成int& ret = Count(); 发现无法运行,因为临时变量有常性,所以需要写成const int& ret = Count(); 才能通过。
——————————————————————————————————手动分割
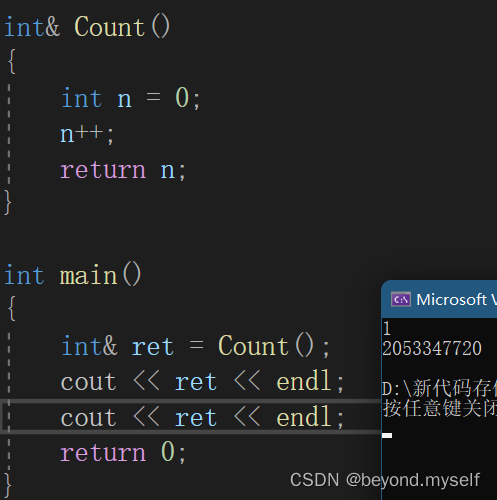
此时再看传引用返回:

当用引用接收引用返回时:这里ret和n的地址一样,也就意味着ret其实就是n的别名。但是因为n出作用域不会立即被覆盖,所以第一次通过ret可以打印是1,当打印第二次时,因为前面已经调用过一次打印函数,已 "销毁" 的Count函数栈帧在此时被打印函数覆盖,再打印ret就会是随机数了!
用static修饰n后:用static静态变量使n只初始化一次且改变其生命周期,把n放进了静态区,这样n就一直存在,就可以通过ret找到n了,再怎么打印ret都是1.
(2)传值、传引用效率比较
6.引用和指针的不同点:
这就好比保时捷的卡宴和大众的途锐汽车,他们的三大件底盘,发动机,变速箱都是一样的,但是他们的品牌不一样,价格不同

二.内联函数
1.概念:
2.写法和作用:
在函数定义前加个 " inline ",就会在调用此函数的时候展开这个函数,通过汇编指令我们能清晰看到原本调用此函数的地方应是call Add,加上inline后他就会直接把Add函数的指令放到ret = Add(1, 2); 的位置了,即:如果在函数前增加inline关键字将其改成内联函数,在编译期间编译器会用函数体替换函数的调用。 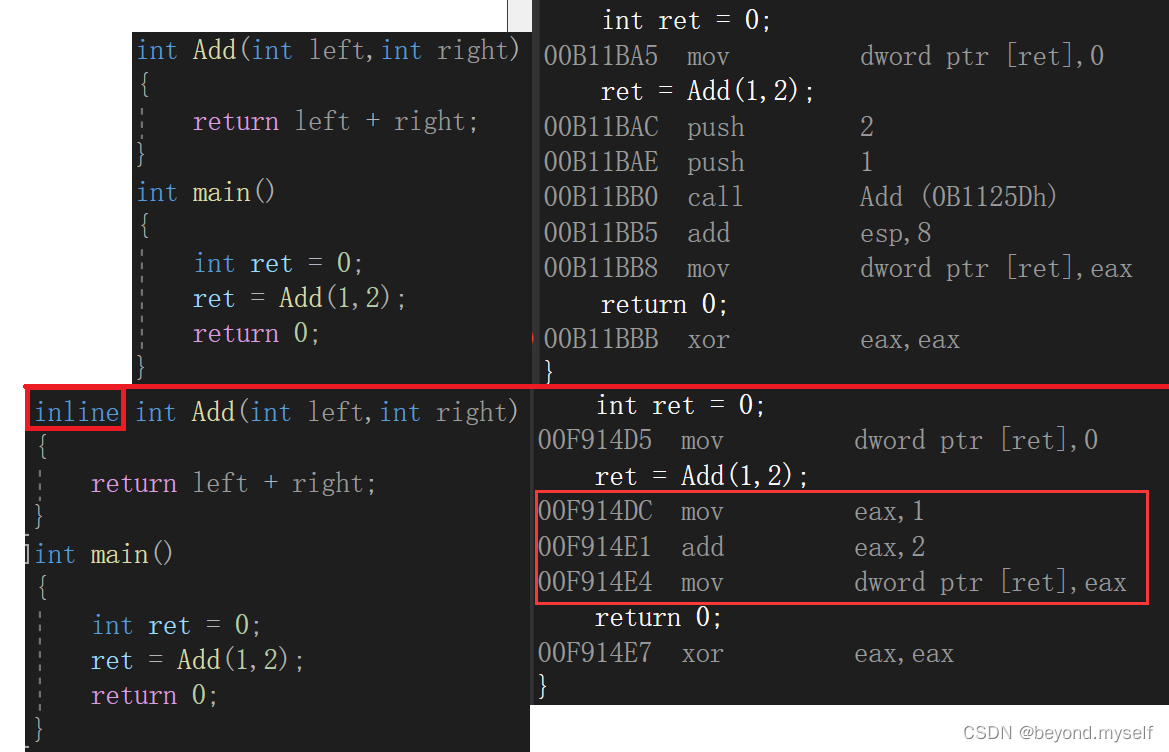
3.如何通过汇编查看内联后的结果?
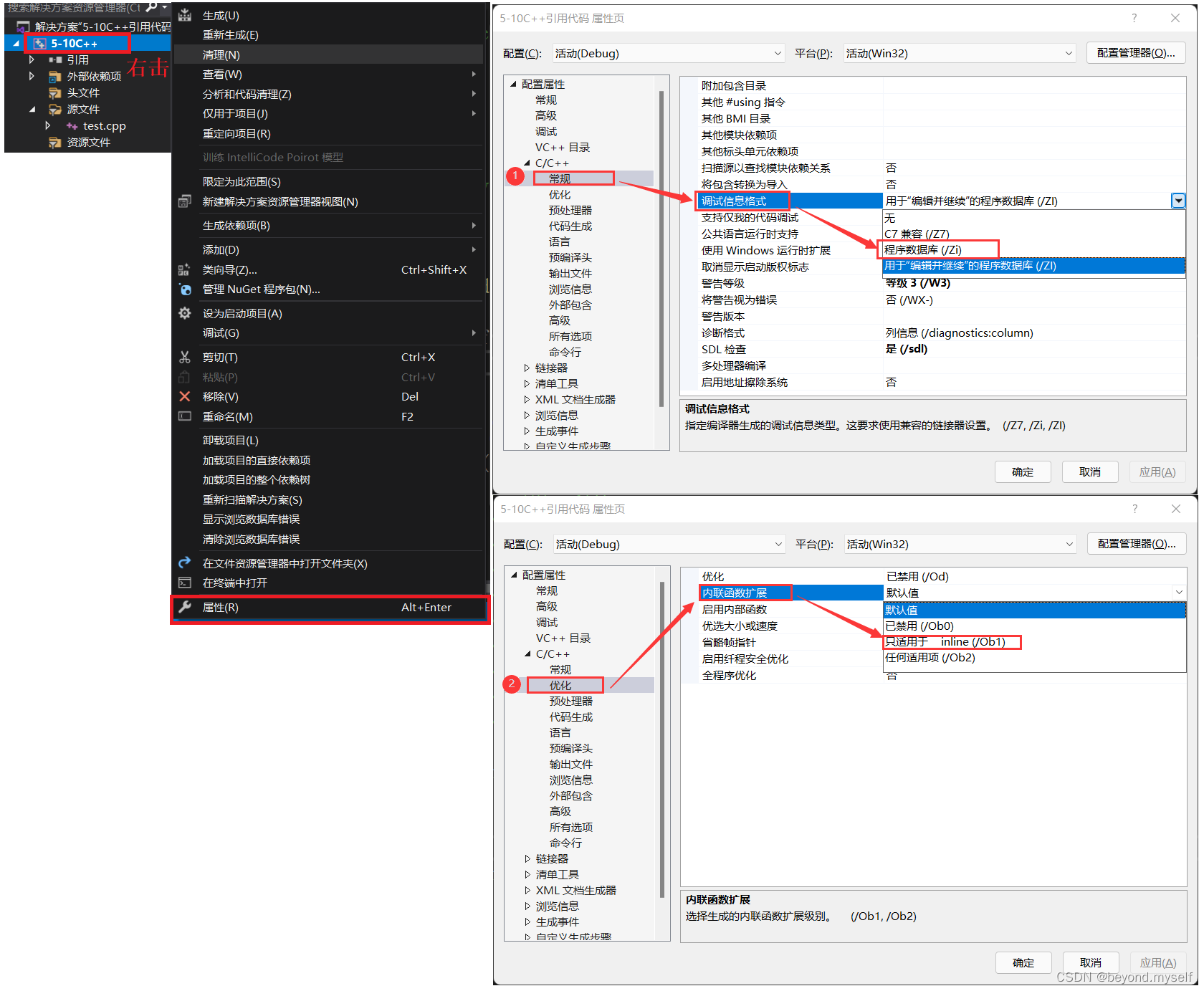
4.为什么要有内联函数:
代码少的函数频繁被调用,每次调用建立栈帧,汇编看建立栈帧里面一堆操作很浪费时间,所以干脆在调用的地方展开,虽然指令多了但是效率高了,空间换时间的做法,在c语言中是通过宏函数的方式展开的,比如#define ADD(x, y) ((x)+(y)) ( 当Add(1 & 2 , 3 | 4); 时有优先级问题,+比&和|优先级高,所以x和y也要加括号),但是大佬们发现宏函数易写错难懂,所以在c++中创造了更易懂的展开做法:内联函数——总结一句:频繁调用小函数,建议定义成inline
顺便再讨论一下宏,宏的缺点就是内联函数的优点
(1)宏
5.特性
// F.h
#include <iostream>
using namespace std;
inline void f(int i);
// F.cpp
#include "F.h"
void f(int i)
{
cout << i << endl;
}
// main.cpp
#include "F.h"
int main()
{
f(10);
return 0;
}F.h 在F.cpp中被展开,因为声明是inline,符号表不会生成函数地址,当main.cpp 中调用函数f时,call(函数名) 这个指令去符号表找函数名和地址映射关系时,找不到函数地址,则无法展开。
正确应该这么写:
最佳写法:(1)
F.h 在main.cpp中被展开,因为是内联,所以会在调用处展开,此时call指令也能找到函数地址。
// F.cpp
#include "F.h"
inline void f(int i)
{
cout << i << endl;
}
// main.cpp
#include "F.h"
int main()
{
f(10);
return 0;
}(2)声明和定义写都写在.h中也可以,但是没必要
// F.cpp
#include "F.h"
inline void f(int i);
void f(int i)
{
cout << i << endl;
}
// main.cpp
#include "F.h"
int main()
{
f(10);
return 0;
}6.内联函替换后指令变多真的提高效率了吗?——确实提高了
举例:比如把3行的swap函数调用1000次,如果用内联展开就是3000行指令,如果不展开就是1000+3=1003 行指令(1000次调用就要1000次call指令,还有3行swap函数的指令),那把小函数内联展开指令多了很多,真的比建立栈帧快吗?
答:不是说不展开指令就变少了,每次call过去,swap函数里面的3行指令还是会执行的,所以实际上一共是执行了 1000次call指令+1000*3次调用swap指令=4000次指令,所以说还是inline的3000行效率更快。
7.为什么 频繁调用小函数,建议定义成inline ?
代码很长的时候不适宜用内联函数,比如10行swap函数调用1000次,内联后指令会执行10*1000=1w次,不内联就是1000次call指令+1000*10次调用swap指令=11000次指令,虽然少走1000次,但是多消耗了很多展开的空间 不值得,所以不建议长函数用内联
最后
以上就是虚心钢铁侠最近收集整理的关于C++入门 “引用”,“内联函数” 详解一.引用二.内联函数的全部内容,更多相关C++入门内容请搜索靠谱客的其他文章。








发表评论 取消回复