在上一部分的内容中,我们已经介绍了如何建立一个detectron2的开发环境,现们就可以开始来学习其中相关的细节了。在今天的这部分内容中,我们主要会介绍detectron2中和数据加载相关的内容。
从数据加载开始,是基于以下几个考虑:
1、dataloader 模块相对比较独立,比较好理解
2、模型部分相对复杂,开坑了就没完没了...
3、老司机肯定知道,其实一般模型都是不怎么动的,学学怎么动dataloader比较实在...
本章的内容将会分成以下几个部分:
- Part1:如何设计一个数据加载模块
- 介绍在设计一个针对检测问题的dataloader时可能会遇到的问题
- 针对这些问题,应该需要哪些模块
- Part2:dataloader 相关代码介绍
- 介绍detectron2 的代码是如何实现上述模块的
- Part3:如何加载自己的数据集
- 分析如何自定义数据集加载自己的检测数据
- 分析加载文字检测数据(记录着边框的4个角点8个值的信息)的方法
这里,我不会上来就直接介绍代码,而是想从设计的角度分析detectron2需要设计成什么样,然后再介绍detectron2对每一个模块具体是怎么实现的,随后,在下一讲中,我将介绍如何加载自己的检测数据集
part1 : 如何设计一个数据加载模块
1.1 如何设计一个最简单的 dataset
我们知道,在pytorch中,一个dataset 应该需要包含两个函数:
class 注意到, 这里每个idx ,应该对应的应该是一张图而不是一个检测框。 在目标检测任务中,一张图上会对应着多个框。而在这里,样本是以图为单位的,而不是以框为单位的
很简单,对么?那么我们将从这个最简单的dataset开始,一步一步的把他变复杂,变成和detectron2中设计的dataset相近的东西
1.2 设计__getitem__模块中返回内容的细节
对应上文说,每个样本是一张图的观点,在 __getitem__ 时 ,
返回的样本信息 应该是第 idx张 图片,以及 第 idx张图对应的所有的框
对应这种想法来说,可以这样设计一个 __getitem__ 方法:
def 加载的图片一般会使用 cv2 或者 Pillow , 加载完成的图片当然是一个 ndarray , 而boxes 信息,因为是多个框,当然可以使用一个list 来存储框的信息,而每个检测框之所以设计成字典,是因为目标检测中有许多的任务,一个框中可能出了包含bbox信息,还包含了segmentation 的信息,就像下面这个样子
# boxes[0]
{"boxes" : ... , "segmentation": ...}
至此,你可以设计出如下的代码:
image_anno_info 注意到到这里,代码变成了两个部分:
- 第一部分为数据的加载,通过某种加载方式,获得了image_anno_info , 每个元素为一个图片的信息和图片对应的标注信息
- 在利用这些图片的元信息创建dataset后,可以在 __getitem__ 中完成图片的读取和 annotation 的加载
1.3 加入数据增强
在 __getitem__时,不仅需要加载图片和annotation ,还要完成数据增强
为了提升训练的效果,一般在每次训练的时候,我们都加入数据增强的操作,因此,也许你可以这么设计你的dataset:
class 在这个阶段中,我们又做了两件事情:
- 在dataset 初始化中,建立了一个类,这个类负责随机的生成transform
- 在 __getitem__ 中, 我们首先利用这个transform生成了一个变换,然后基于这个变换,更新我们的标签和图片
到这里为止,已经变得有点点复杂了,为了让程序更加简单,我们来把这个代码重新整合一下
class 注意到:
1、这里,将对数据的处理的操作封装在map_func中,则可以使得这个dataset类可以用于处理各种不同的任务,增加程序的稳定性
2、这里比较难理解的是关于 数据增强的部分,关于这部分可以这么理解:
- 首先,在MapFunc 初始化的时候,定义的是一系列的“生成数据增强的函数”,用于在每次 获取数据的时候,随机生成一组参数,用来生成 一个特定的数据增强方法,一个最简单的数据增强生成器(TransformGen)是RandomFlip:
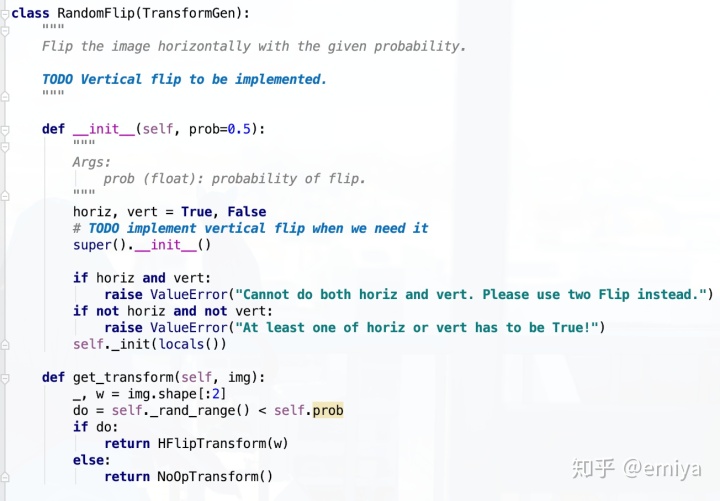
可以看到,每个TransformGen函数会有一个 get_transform函数用于生成一个特定的数据增强函数
- 其次,由于很多的数据增强方法可能会使用到图片的尺寸信息,所以会一边做get_transform ,一边做 apply_image , 得到下一个阶段的 图片,用于生成下一个阶段的transform
- 另外,对每个transform 方法,都需要实现如下的几个方法:
class 1.4 目前为止的框架图:

到目前为止,所有的内容可以总结为上面这张图:
1、通过某种方法 build_datasetlist ,获得数据的列表
2、设置一系列的TransformGen,生成一个用于数据处理MapFunc对象
3、在Mydataset 的 __getitem__方法中,利用map_func处理数据,获得最终的data_dict
目前为止,对map_func, 数据增强这两个模块都已经介绍完全了,但是对于如何获取datasetList ,还没有进行详细的介绍,在接下来的内容中,我们将补全这部分的内容
1.5 关于datasetList 的生成方法
首先来思考一下,detectron2在设计元数据加载的时候会遇到什么问题:
- 1、需要加载的数据类型多种多样,有coco,有voc
- 2、每种数据集类型下又有多个数据集,如 coco2017 , coco2014 等等
- 3、每次进行训练时,可能需要使用多个数据集
针对这样的三个需求,detectron2 对数据加载这部分内容,自下而上的,应该有如下的设计:
1、首先对不同种类的数据集,应该定义不同的数据加载方法
如coco数据集,应该定义如下方法:
def 而在定义的过程中,需要注意一下两点:
- 返回的内容应该是一个List ,每个元素为一个dict,记录了每张图片的 annotation 信息, 图片的meta信息,如图片的路径,等
- 定义的函数应该能够加载这个类型的各种数据集,如上面的这个函数,可以通过指定不同的dataset_name 来加载各种coco 数据集, 如 coco2017 , coco2014 ,等
2、在设计好每个数据集的创建方法后,需要建立一个字典,来记录所有的数据集的对应的初始化方法,如下
coco2017_path 这样,在训练时,只需要指明参数 ’coco2017‘ , 则可以通过如下方法获得数据:
cfg = 'coco2017'
datasetlist = datasetCatalog(cfg)()3、对于上面的加载多个数据集的问题,可以通过多次加载,然后拼接的方法
import 1.6 优化 datasetCatalog 的写法, 增加程序的扩展性
在上一个小节中,将datasetCatalog写成了字典,这样做的问题在于不具有很好的扩展性,当每个人希望定义自己的数据加载方法时都需要修改源代码中的这个字典。因此,回顾之前提过的detectron2 设计中的注册机制:
emiya:[Detectron2] 01-注册机制 Registry 实现zhuanlan.zhihu.com
在dataset 部分中,也可以将datasetCatalog设计成注册的形式:
class 随后,在导入相关模块的时候,注册各个方法:
def 这样就想所以的数据的加载方法存在在 DatasetCatalog中了
1.7 小结:完成的数据加载流程
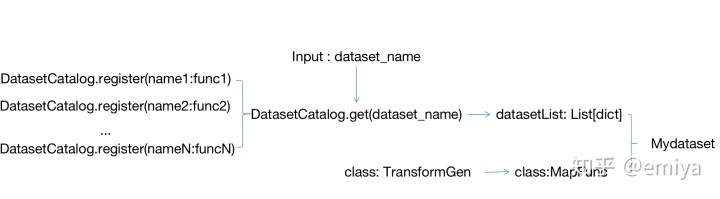

综上所述,可以获得如上的完整的数据加载流程:
1、首先,对每种数据集,定义不同的数据加载函数,每个函数的返回值为一个List,每个元素为一个字典,对应一张图片和图片上的检测框信息,一般形式为:
{
"image_id": 用于查找图片和读取图片,
"annotations" : [{"boxes": ..., "seg" : ...} , {"boxes": ... , "seg": ...} , ...] ,
# 其他元信息
...
}2、定义register() 函数, 如 register_all_coco , 在模块加载的时候执行,通过调用 DatasetCatalog.set(name , func) 的方法将读取数据的函数都注册到DatasetCatalog中
3、在面对实际的训练任务中提供的数据集名称dataset_name, 通过DatasetCatalog.get 方法获取数据, 并进一步包装成datasetList, 送入dataset 中
4、在数据加载之外,定义好一系列的Transform方法和TransformGen方法,并用于初始化一个MapFunc 数据处理对象,
5、利用MapFunc 方法和 datasetList ,建立自己的数据集,从而完成数据的获取
Part2 : dataloader 相关代码介绍
2.1 数据部分的代码结构
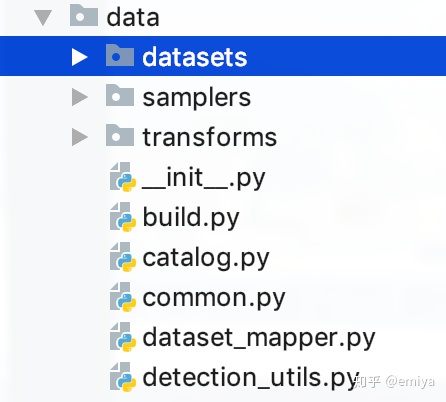
对应着Part1 中1.7 小节设计的内容,detectron2 中相关的代码都设计在 data 目录下:
其中:
- datasets主要负责定义各个数据集的具体的加载分析方法
- sampler 负责dataloader 生成batch 数据时对dataset 的抽样方法
- transforms 就负责记录所有的数据增强操作
- build.py 负责 build_data_loader ,
- catalog.py 中定义了 DatasetCatalog 和 MetaCatalog , 后者用于对每个数据集记录元信息,如每个类别idx对应什么具体类别等
- common.py 定义了MapDataset , 即上文一直在说的MyDataset
- dataset_mapper 中定义了MapFunc 类, 用于进行数据的增强和标签的处理
接下来我将逐一讲解
2.2 detectron2 代码走读
这里以coco instance 检测数据集为例,介绍detectron2是如何完成数据的加载的
2.2.1 导入模块时,记录下读取数据集的方法到DataSetCatalog中
目录结构及跳转大致如下:
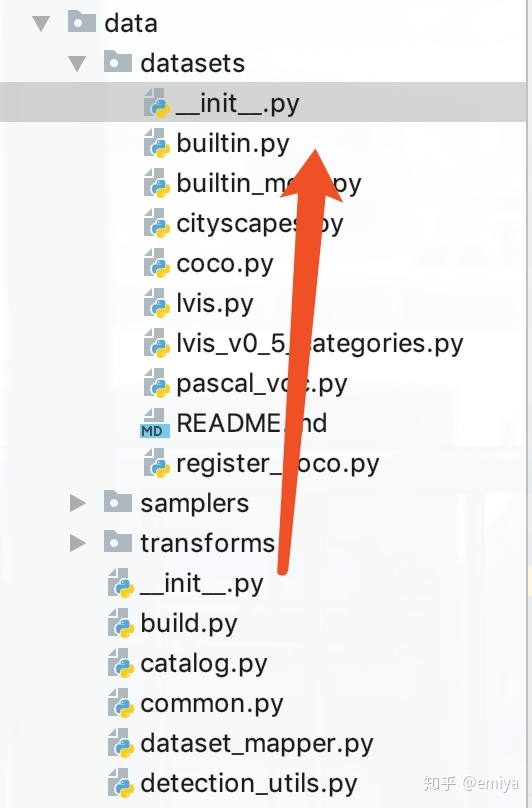
在 data 目录的__init__.py 中可以看到

而在datasets 的__init__.py中 有一句
from . import builtin而在builtin 模块中,会去注册加载coco数据集的方法:

函数register_all_coco 会在模块被导入的时候执行,函数中:
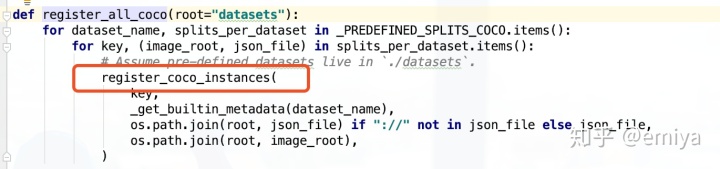
register_coco_instances 会把各个coco instance 数据集都做相应的注册,对应的注册方法也很简单:
def - 第一行,通过底层调用通用的load_coco_json 方法,并封装成一个匿名函数注册进DatasetCatalog 即可
而load_coco_json 的返回值大概如下:
def 结合Part1 的内容,不难理解上述数据加载的函数希望提供什么
- 第二行,这里定义了一个MetadataCatalog , 本质就是存储关于数据集的元信息,比如每个类别id 对应的类别名称之类的,在数据创立时同时建立MetadataCatalog , 可以为后面做infer 的时候,利用MetadataCatalog 来进行可视化啊,之类的,不多做介绍,具体内容可以看类的定义
2.2.2 模型训练过程中的dataloader 初始化
整个detectron2 基本的训练流程都定义在这个 engine - defaults.py 的 DefaultTrainer 当中:
class 对train后面会有详细的介绍,但是在这里,让我们首先来关注build_detection_train_loader 函数,在传入的参数cfg中,会指明需要建立的数据集的名称,从而可以使用DatasetCatalog 来建立数据集
2.2.3 build_detection_train_loader 解析
这个函数,大体可以视为如下几个核心流程:
def 关于DatasetCatalog,在1.6中都有所介绍
而关于DatasetMapper、MapDataset(不做赘述) 其实也和前面介绍的相差无几:
class 而在DatasetMapper 和前面的介绍中的一个细小的区别就是,detectron2中会使用Instance类来包装每一个检测的信息,而不是简单的使用字典

因此,在后续自定数据集的时候,要注意把自己定义的数据变成一个Instance的形式才可以
在一般的检测类任务中会去读取 target.gt_boxes 和 target.gt_classes 来计算loss , 要特别注意
在下一篇专栏中,我将会介绍定义自己的数据集的方法
最后
以上就是魔幻电脑最近收集整理的关于el-tab 内容每次重新加载_[Detectron2] 03-数据加载模块(dataloader)的全部内容,更多相关el-tab内容请搜索靠谱客的其他文章。




![el-tab 内容每次重新加载_[Detectron2] 03-数据加载模块(dataloader)](https://www.shuijiaxian.com/files_image/reation/bcimg2.png)



发表评论 取消回复