1 在hdfs上进行文件复制
Configuration conf=new Configuration();
conf.set("fs.hdfs.impl",org.apache.hadoop.hdfs.DistributedFileSystem.class.getName());
FileSystem fs=FileSystem.get(URI.create("hdfs://localhost/"),conf);
InputStream in=null;
OutputStream out=fs.create(new Path("hdfs://localhost/user/zh2.txt"));
try{
in=fs.open(new Path("hdfs://localhost/11.txt"));
IOUtils.copyBytes(in, out, 4096,true); //从hdfs上读取文件内容,然后输出到另一个文件中,复制
}finally{
IOUtils.closeStream(in);
}2 对FSDataInputStream类中的seek和getPos的探索
//对FSDataInputStream类中的seek和getPos的探索
fs.delete(new Path("hdfs://localhost/11.txt"),false);
newFile=fs.create(new Path("hdfs://localhost/11.txt"));
newFile.write("我".getBytes());
newFile.write("a".getBytes());
newFile.flush();
newFile.close();
in=fs.open(new Path("hdfs://localhost/11.txt"));
System.out.println(in.getPos()); //0
IOUtils.copyBytes(in, System.out, 4096, false); //我
System.out.println(in.getPos()); //4
System.out.println("***********");
in.seek(3);//a
IOUtils.copyBytes(in, System.out, 4096,false);可以看出getPos()获得当前文件offset距文件开头的长度(单位是字节),如果对文件进行读取,那么就有偏移量。seek()表示将文件offset定位在第几个字节后。
3 将文件从dfs上拷贝到本地
Configuration conf=new Configuration();
conf.set("dfs.client.block.write.replace-datanode-on-failure.policy","NEVER");
conf.set("dfs.client.block.write.replace-datanode-on-failure.enable","true");
conf.setInt("dfs.replication", 1);
FileSystem fs=FileSystem.get(URI.create("hdfs://localhost/11.txt"),conf);
OutputStream out=new FileOutputStream(new File("C:/Users/lei/Desktop/11.txt"));
//将文件从dfs上拷贝到本地
FSDataInputStream in=fs.open(new Path("hdfs://localhost/11.txt"));
try{
IOUtils.copyBytes(in, out,1024, false);
}finally{
IOUtils.closeStream(in);
IOUtils.closeStream(out);
}4.将文件从本地上拷贝到dfs上
Configuration conf=new Configuration();
conf.set("dfs.client.block.write.replace-datanode-on-failure.policy","NEVER");
conf.set("dfs.client.block.write.replace-datanode-on-failure.enable","true");
conf.setInt("dfs.replication", 1);
FileSystem fs=FileSystem.get(URI.create("hdfs://localhost/11.txt"),conf);
InputStream in=new FileInputStream(new File("C:/Users/lei/Desktop/11.txt"));
//将文件从本地拷贝到DFS上
FSDataOutputStream out=fs.create(new Path("hdfs://localhost/12.txt"));
try{
IOUtils.copyBytes(in, out,1024, false);
}finally{
IOUtils.closeStream(in);
IOUtils.closeStream(out);
}4.新建一个文件夹
FileSystem fs=FileSystem.get(URI.create("hdfs://localhost"),conf);
try{
System.out.println(fs.mkdirs(new Path("hdfs://localhost/Hadoop_test")));
}finally{
}5 文件或者文件夹的相关属性
FileSystem fs=FileSystem.get(URI.create("hdfs://localhost"),conf);
Path dir=new Path("/");
FileStatus stat=fs.getFileStatus(dir);
System.out.println(stat.getPath().toUri().getPath());
System.out.println(stat.isDirectory());
System.out.println(stat.getLen());
System.out.println(stat.getPermission().toString());
//将根目录下的所有文件文件夹的属性进行遍历,不进行递归
Path dir=new Path("/");
FileStatus stat=fs.getFileStatus(dir);
FileStatus[] statList=fs.listStatus(new Path("/zhanglei"));
for(FileStatus fileStatus:statList){
System.out.println(fileStatus.toString());
}6 遍历文件系统,并对文件进行筛选,使用FileSystem中的listFiles方法得到一个遍历器,然后筛选出是文件的,并且符合正则表达式的文件
FileSystem fs=FileSystem.get(URI.create("hdfs://localhost/user"),conf);
try{
RemoteIterator<LocatedFileStatus> fileIterator=fs.listFiles(new Path("/"), true);
while(fileIterator.hasNext()){
Path path=fileIterator.next().getPath();
FileStatus stat=fs.getFileStatus(path);
if(stat.isFile()&&stat.getPath().toUri().getPath().matches("/user/.*")){
System.out.println(stat.getPath().toUri().getPath());
}
}
}finally{
}7 如果非递归遍历,可以用FileSystem中的listStatus方法
FileSystem fs=FileSystem.get(URI.create("hdfs://localhost/user"),conf);
try{
FileStatus[] fileS=fs.globStatus(new Path("/*/*"),new RegexExcludePathFilter(".*/zhanglei/.*"));
for(FileStatus fileStatus:fileS){
System.out.println(fileStatus.getPath().toString());
System.out.println(fileStatus.getPath().toUri().getPath());
}
}finally{
}
class RegexExcludePathFilter implements PathFilter {
private final String regex;
public RegexExcludePathFilter(String regex) {
this.regex = regex;
}
public boolean accept(Path path) {
return !path.toString().matches(regex);
}
}
globStatus方法的第一个参数是glob character ,可以写的格式有

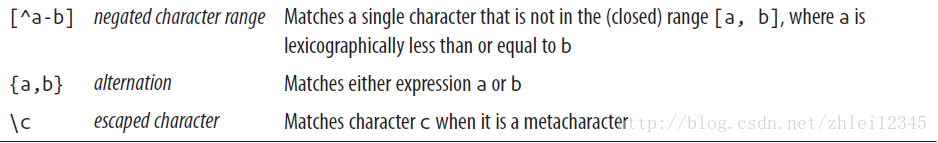
,同时globstatus提供一个过滤接口,可以实现这个接口,例如RegexExcludePathFilter,进行进一步过滤。
8.文件压缩
FileSystem fs=FileSystem.get(URI.create("hdfs://localhost/user"),conf);
InputStream input=null;
OutputStream output=null;
CompressionOutputStream out=null;
//压缩文件
try{
fs.delete(new Path("/1901ompress"),false);
input=fs.open(new Path("/1901"));
output=fs.create(new Path("/1901compress"));
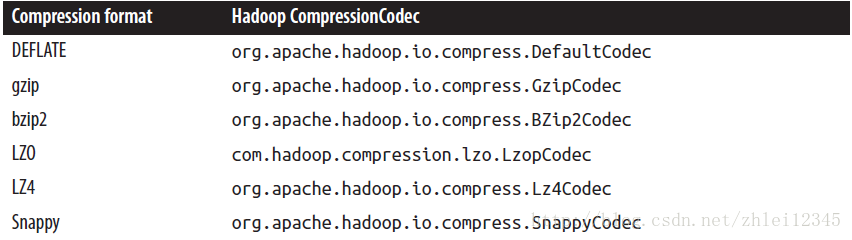
CompressionCodec codec=(CompressionCodec) ReflectionUtils.newInstance(org.apache.hadoop.io.compress.GzipCodec.class, conf);
out=codec.createOutputStream(output);
IOUtils.copyBytes(input, out, 4096,false);
}finally{
IOUtils.closeStream(input);
IOUtils.closeStream(out);
IOUtils.closeStream(output);
}
}9.文件解压
Configuration conf=new Configuration();
conf.set("dfs.client.block.write.replace-datanode-on-failure.policy","NEVER");
conf.set("dfs.client.block.write.replace-datanode-on-failure.enable","true");
conf.setInt("dfs.replication", 1);
FileSystem fs=FileSystem.get(URI.create("hdfs://localhost/user"),conf);
InputStream input=null;
OutputStream output=null;
CompressionOutputStream out=null;
CompressionInputStream in=null;
//解压文件
try{
fs.delete(new Path("/1901decompress"), false);
input=fs.open(new Path("/1901compress"));
output=fs.create(new Path("/1901decompress"));
CompressionCodec codec=(CompressionCodec) ReflectionUtils.newInstance(org.apache.hadoop.io.compress.GzipCodec.class, conf);
in=codec.createInputStream(input);
IOUtils.copyBytes(in, output, 4096,false);
}finally{
IOUtils.closeStream(input);
IOUtils.closeStream(out);
IOUtils.closeStream(output);
IOUtils.closeStream(in);
}
}
10 CodecPool,如果需要多次的压缩和解压,那么可以使用CodecPool来重复使用compressors 和decompressors
FileSystem fs=FileSystem.get(URI.create("hdfs://localhost/user"),conf);
InputStream input=null;
OutputStream output=null;
CompressionOutputStream out=null;
CompressionInputStream in=null;
Compressor compressor=null
//解压文件
try{
fs.delete(new Path("/1901compress"),false);
input=fs.open(new Path("/1901"));
output=fs.create(new Path("/1901compress"));
CompressionCodec codec=(CompressionCodec) ReflectionUtils.newInstance(org.apache.hadoop.io.compress.Lz4Codec.class, conf);
compressor=CodecPool.getCompressor(codec);
out=codec.createOutputStream(output,compressor);
IOUtils.copyBytes(input, out, 4096,false);
}finally{
IOUtils.closeStream(input);
IOUtils.closeStream(out);
IOUtils.closeStream(output);
IOUtils.closeStream(in);
CodecPool.returnCompressor(compressor);
}11.针对mapreduce的输出,如果需要压缩,可以由两种方法:
通过configuration 设定mapreduce.output.fileoutputformat.compress :true
和duce.output.fileoutputformat.compress.codec: GzipCodec.class
或者说使用
FileOutputFormat.setCompressOutput(job, true);
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);同样针对map的输出,如果需要压缩,使用在Configuration来设定
conf.setBoolean(Job.MAP_OUTPUT_COMPRESS, true);
conf.setClass(Job.MAP_OUTPUT_COMPRESS_CODEC, GzipCodec.class,
CompressionCodec.class);12 writable 接口
package org.apache.hadoop.io;
import java.io.DataOutput;
import java.io.DataInput;
import java.io.IOException;
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}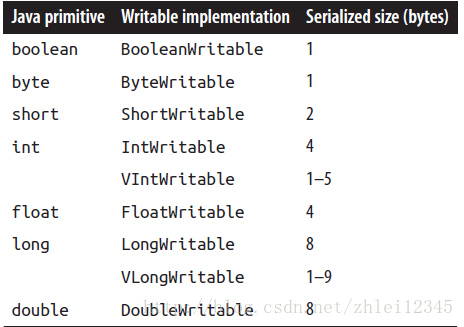
这些实现了writable的类,需要有两个功能write和readFields功能,也就是需要举个例子,IntWritable的write就是把一个整数写入输出流中,同时可以通过readField从输入流in中读取一个整数
public static void main( String[] args ) throws Exception
{
IntWritable writable=new IntWritable();
writable.set(163);
byte[] bytes=serialize(writable);
IntWritable newWritable=new IntWritable();
deserialize(newWritable, bytes);
System.out.println(newWritable.get());
System.out.println(bytes.length);
}
public static byte[] serialize(Writable writable) throws IOException{
ByteArrayOutputStream out=new ByteArrayOutputStream();
DataOutputStream dataOut=new DataOutputStream(out);
writable.write(dataOut);
dataOut.close();
return out.toByteArray();
}
public static byte[] deserialize(Writable writable,byte[] bytes) throws IOException{
ByteArrayInputStream in=new ByteArrayInputStream(bytes);
DataInputStream dataIn=new DataInputStream(in);
writable.readFields(dataIn);
dataIn.close();
return bytes;
}13 WritablComparable and comparators
package org.apache.hadoop.io;
public interface WritableComparable<T> extends Writable, Comparable<T> {
}
package org.apache.hadoop.io;
import java.util.Comparator;
public interface RawComparator<T> extends Comparator<T> {
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}public interface Comparator<T>{
int compare(T o1,T o2);
boolean equals(Object obj);
}public interface Comparable<T>{
int compareTo(T o);
}WritableComparator 是对RawComparator的一般化实现,提供的功能如下
public static void main(String[] args) throws Exception{
//功能1,提供一个comparator工厂
RawComparator<IntWritable> comparator=WritableComparator.get(IntWritable.class);
IntWritable w1=new IntWritable(163);
IntWritable w2=new IntWritable(67);
//功能2 提供比较策略
System.out.println(comparator.compare(w1, w2));
byte[] b1=serialize(w1);
byte[] b2=serialize(w2);
System.out.println(comparator.compare(b1,0,b1.length,b2,0,b2.length));
}
public static byte[] serialize(Writable writable) throws IOException{
ByteArrayOutputStream out=new ByteArrayOutputStream();
DataOutputStream dataOut=new DataOutputStream(out);
writable.write(dataOut);
dataOut.close();
return out.toByteArray();
}14 String和Text的区别
主要是针对String的length方法,charAt方法,indexOf方法,已经Text类与之对应的getlength方法,charAt方法,find方法.
String:length ,Text:getlength
String 是以char字符单元计算长度,char字符单元可以是Ascii码,或者是一个中文。而text是以char字符单元对应的二进制表示的字节数来计算长度的,由于text是UTF-8编码的,所以中文占3个字节。
Text text=new Text("含");
String s="含";
System.out.println(text.getLength()); //3
System.out.println(s.length()); //1String:indexOf,Text:find
String的indexOf表示的是char字符单元在String字符串中的位置,位置的计算是以字符单元来进行的。Text的find表示的是char字符单元在text对应的二进制编码中的字节的位置,位置计算是以字节来进行的。
Text text=new Text("含a");
String s="含a";
System.out.println(text.find("a")); //3
System.out.println(s.indexOf("a")); //1String:charAt,Text:charAt
String的charAt表示表示字符串中对应位置的字符是什么,位置计算是以字符单元进行的,Text的charAt表示对应位置的字符是什么,位置计算是以字节进行的,返回的是10进制表示的Unicode scalar value.常见的还是他对应的16进制表示.
Text text=new Text("含a");
String s="含a";
System.out.println(text.charAt(0)); //21547
System.out.println(Integer.toHexString(text.charAt(0))); //542b
System.out.println(text.charAt(1)); //-1
System.out.println(text.charAt(3)); //97
System.out.println(s.charAt(0)); //含
System.out.println(s.charAt(1)); //atext的字符遍历
Text text=new Text("含有a");
ByteBuffer buf=ByteBuffer.wrap(text.getBytes(),0,text.getLength());
int cp;
while(buf.hasRemaining() && (cp=Text.bytesToCodePoint(buf))!=-1){
System.out.println(Integer.toHexString(cp));
}15.BytesWritable
针对byte类型的数组进行的封装。序列化格式为4个字节表示这个数组一共有多少个元素(字节),然后后面跟着相应的元素。
public static void main(String[] args) throws Exception{
BytesWritable b=new BytesWritable(new byte[]{3,5});
System.out.println(b.getLength()); //2 返回数组的元素个数
byte[] bytes=serialize(b);
System.out.println(bytes.length); //6
System.out.println(StringUtils.byteToHexString(bytes));//000000020305
}
public static byte[] serialize(Writable writable) throws IOException{
ByteArrayOutputStream out=new ByteArrayOutputStream();
DataOutputStream dataOut=new DataOutputStream(out);
writable.write(dataOut);
dataOut.close();
return out.toByteArray();
}16.Writable collection
ArrayWritable and TwoDArrayWritable:元素是Writable类型的数组,一个是一维的,一个是二维的. ArrayPrimitiveWritable :元素是Java 基本数据类型的数组. MapWritable :实现Map
MapWritable src=new MapWritable();
src.put(new IntWritable(1), new Text("cat"));
src.put(new VIntWritable(2), new LongWritable(163));
System.out.println(((Text)src.get(new IntWritable(1))).charAt(0)); //99
System.out.println(((LongWritable) src.get(new VIntWritable(2))).get()); //16317.writableComparator 和WritableComparable
MapReduce的过程就是不断的传递键值对,在传递过程中,需要对键进行排序,hadoop要求键是可序列化的。因此在hadoop的各种writable子类中,都需要实现writableComarable接口,以便MapReduce程序可以进行键的比较。而writableComparable进行比较时需要进行反序列化,然后才开始比较。这会增加计算复杂度。因此hadoop提供了一个WritableComparator,他进行比较时,可以不用反序列化,因此可以人为的指定键比较时所用的比较器,而不用writableComparable中的CompareTo方法。WritableComparator是实现了RawComparator接口。如果我们构造的新数据类型使用了writable的子类,那么就可以直接继承WritableComparator,使用现成的一些代码。而不用直接实现RawComparator接口。
举例如下:
public class TextPair implements WritableComparable<TextPair>{
private Text first;
private Text second;
public int compareTo(TextPair tp){
int cmp=first.compareTo(tp.first);
if(cmp!=0)
return cmp;
return second.compareTo(tp.second);
}
public static void main(String[] args) throws Exception{
TextPair textPair1=new TextPair("cat","dog");
TextPair textPair2=new TextPair("apple","pine");
WritableComparator textPairComparator=WritableComparator.get(TextPair.class);
System.out.println(textPairComparator.compare(textPair2, textPair1));
TextPair.Comparator textPairComparator2=new TextPair.Comparator();
System.out.println(textPairComparator2.compare(textPair2, textPair1));
}
public static byte[] serialize(Writable writable) throws IOException{
public static class Comparator extends WritableComparator{
private static final Text.Comparator TEXT_COMPARATOR =new Text.Comparator();
public Comparator(){
super(TextPair.class);
}
public int compare(byte[] b1,int s1,int l1,byte[] b2,int s2,int l2){
try{
int firstL1=WritableUtils.decodeVIntSize(b1[s1])+readVInt(b1, s1);
int firstL2=WritableUtils.decodeVIntSize(b2[s2])+readVInt(b2, s2);
int cmp=TEXT_COMPARATOR.compare(b1, s1,firstL1,b2,s2,firstL2);
if(cmp!=0){
return cmp;
}
return TEXT_COMPARATOR.compare(b1, s1+firstL1,l1-firstL1,b2,s2+firstL2,l2-firstL2);
}catch(IOException e){
throw new IllegalArgumentException(e);
}
}
static{
WritableComparator.define(TextPair.class, new Comparator());
}
}
}为了简化起见,我们只给出了compareTo方法。如果我们需要重新定义一个数据类型用作键,那么它应该实现WritableComparable的compareTo方法。当然还可以自定义比较器,也就是内部静态类Comparator.static中的代码
static{WritableComparator.define(TextPair.class, new Comparator());}是在WritableComparator中注册TextPair.class的比较器。然后我们就可以使用
WritableComparator textPairComparator=WritableComparator.get(TextPair.class);
得到一个比较器。当然也可以通过
TextPair.Comparator textPairComparator2=new TextPair.Comparator();这种方法得到一个比较器。
其次在Comparator 类compare方法中
WritableUtils.decodeVIntSize(b1[s1])用来指出b1的字符串对应byte数组长度。原因是b1是Text类型,在序列化是首先会指定字符串的编码字节长度,然后指定字符串的编码字节。readVInt(b1, s1)用来指定b1是用几个字节存放字符串的长度的。
那么在MapReduce程序中可以通过如下的方法指定键比较器
job.setSortComparatorClass(TextPair.Comparator.class);18 . 序列化文件
将一个writable类型的键值对写入一个序列化文件中
public class SequencefileWriteDemo {
private static final String[] DATA={
"one,two,buckle my shoe",
"three,four shut the door",
"five ,six,pick up sticks",
"seven,eight,lay them Straight"
};
public static void main(String[] args) throws IOException{
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(URI.create("hdfs://localhost/"),conf);
Path path=new Path("/user/number.seq");
IntWritable key =new IntWritable();
Text value=new Text();
SequenceFile.Writer writer=null;
try{
writer=SequenceFile.createWriter(fs, conf, path, key.getClass(), value.getClass() );
for(int i=0;i<100;i++){
key.set(100-i);
value.set(DATA[i%DATA.length]);
System.out.printf("[%s]t%st%sn", writer.getLength(), key, value);
writer.append(key, value);
}
}finally{
IOUtils.closeStream(writer);
}
}
}输出结果:
[128] 100 one,two,buckle my shoe
[171] 99 three,four shut the door
[216] 98 five ,six,pick up sticks
[259] 97 seven,eight,lay them Straight
[307] 96 one,two,buckle my shoe
[350] 95 three,four shut the door
[395] 94 five ,six,pick up sticks
[438] 93 seven,eight,lay them Straight方括号表示的是相对于文件头的字节偏移量。首先文件头会包换一些这样的信息:


从序列化文件中读取键值对数据
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(URI.create("hdfs://localhost"),conf);
Path path=new Path("hdfs://localhost/user/number.seq");
SequenceFile.Reader reader=null;
try{
reader =new SequenceFile.Reader(fs, path,conf);
Writable key=(Writable)ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value=(Writable)ReflectionUtils.newInstance(reader.getValueClass(),conf);
long position =reader.getPosition();
while(reader.next(key,value)){
System.out.printf("[%s%s]t%st%sn", position, syncSeen, key, value);
position=reader.getPosition();
}
}finally{
IOUtils.closeStream(reader);
}
}19 . hadoop的Configuration相关(1)
在启动new Configuration()时,默认加载两个配置文件core-default.xml, core-site.xml,这可可以通过
Configuration conf=new Configuration();
System.out.println(conf.toString());查看。
如果希望添加自己的相关property可以直接通过
conf.set("apple", "1");来设定,如果希望添加的property比较多,可以放在一个properties.xml文件中。然后通过
conf.addResource(URI.create(properties.xml详细的路径信息).toURI().toURL())可以使用java的System.setProperty来设定一些property值。举个例子
conf.set("apples", "${apple}");
System.setProperty("apple", "2");
System.out.println(conf.get("apples")); //2首先现在conf中定义一个property,然后使用System.setProperty来设定apple的值,最终通过
System.out.println(conf.get(“apples”))输出值。这也可以在properties.xml中定义apples,但是不直接给出其值而是用${apple}代替。
<?xml version="1.0"?>
<configuration>
<property>
<name>apples</name>
<value>${apple}</value>
</property>
</configuration>20.hadoop input Format
hadoop为了处理不同的数据源(从文本数据,二进制数据,到数据库数据等等)给出了InputFormat类
1.处理split问. InputFormat需要处理Input splits 问题,也就是针对数据源进行分片处理,以便不同的map处理一个数据片。这个在hadoop 中的抽象就是InputSplit类。
public abstract class InputSplit {
public abstract long getLength() throws IOException, InterruptedException;
public abstract String[] getLocations() throws IOException,
InterruptedException;
}public abstract class InputFormat<K, V> {
public abstract List<InputSplit> getSplits(JobContext context)
throws IOException, InterruptedException;
public abstract RecordReader<K, V>
createRecordReader(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException;
}首先客户端运行作业,通过方法getSplits得到针对这个作业的splits(注意这是在客户端完成的),注意返回的是InputSplit列表,也就是InputSplit类的一个对象对应一个split,其中包括了这个split所在的节点(通过getLocations方法得到,由于一个切片可能包含多个数据块 ,所以可能一个split在多个节点上,因此getLocations返回一个字符串数组)。InputSplit类中的getLength方法显然返回的是这个split的大小(字节多少)。
然后将这些InputSplits发送到application master上,application master
根据每哥split中存储的位置信息,将相应的任务分发到相应的节点上。
当一个节点接到一个任务之后,会使用InputFormat类中的createRecordReader方法将split转换成RecordReader,类似一个迭代器,然后传给Mapper类中的run函数。
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
cleanup(context);
}注意mapper类中的run方法是使用context.nextkeyvalue方法,但是context对象中是包含RecordReader的,其实是间接的调用recordReader的nextKeyValue方法。
2.FileInputFormat input paths,
FileInputFormat 有两个功能,首先提供作业所需的文件,以及实现了对这些文件的分片(split)。如何将分片转化成RecordReader 由他的子类实现。也就是说FileInputFormat是抽象类。在指定作业的inputFormat的时候是直接使用FileInputformat.class,只能使用它的子类,
接下来一一列举 。首先就是FileInputFormat 的添加输入文件路径。有如下4中方法:
public static void addInputPath(Job job, Path path)
public static void addInputPaths(Job job, String commaSeparatedPaths)
public static void setInputPaths(Job job, Path... inputPaths)
public static void setInputPaths(Job job, String commaSeparatedPaths)但是如果有多个小文件(文件大小小于128M),就可以使用CombineFileInputFormat,其好处就是可以将小文件集中到一个split中,这样更有利于hadoop的处理。因为hadoop处理100个10M左右的小文件,和hadoop处理10个100兆的,默认生成的split是不一样的,前者是生成100个split,后者是生成10个split。同时前者需要在硬盘上进行多次的查询,这样传输时间和读取时间就会变小,这样hadoop性能更低。
这样的话,建议将多个小文件合并在一起,一种方法就是将多个小文件合并到一个sequence文件中。
3.当然,我们也可以自己实现自己的inputFormat.最关键的地方就是要实现createRecordReader()方法。这里借用hadoop权威指南中的一个例子来说明
package com.zhanglei.MapReduce4;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class WholeFileRecordReader extends RecordReader<NullWritable,BytesWritable>{
private FileSplit fileSplit;
private Configuration conf;
private BytesWritable value=new BytesWritable();
private boolean processed =false;
@Override
public void initialize(InputSplit split,TaskAttemptContext context) throws IOException,InterruptedException{
this.fileSplit=(FileSplit)split;
this.conf=context.getConfiguration();
}
@Override
public boolean nextKeyValue() throws IOException,InterruptedException{
if(!processed){
byte[] contents=new byte[(int) fileSplit.getLength()];
Path file=fileSplit.getPath();
FileSystem fs=file.getFileSystem(conf);
FSDataInputStream in =null;
try{
in=fs.open(file);
IOUtils.readFully(in, contents,0,contents.length);
value.set(contents,0,contents.length);
}finally{
IOUtils.closeStream(in);
}
processed =true;
return true;
}
return false;
}
@Override
public NullWritable getCurrentKey() throws IOException ,InterruptedException{
return NullWritable.get();
}
@Override
public BytesWritable getCurrentValue() throws IOException,InterruptedException{
return value;
}
@Override
public float getProgress() throws IOException{
return processed?1.0f:0.0f;
}
@Override
public void close() throws IOException{
}
}
package com.zhanglei.MapReduce4;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class WholeFileInputFormat extends FileInputFormat<NullWritable,BytesWritable>{
@Override
protected boolean isSplitable(JobContext context,Path file){
return false;
}
@Override
public RecordReader<NullWritable,BytesWritable> createRecordReader(
InputSplit split,TaskAttemptContext context) throws IOException,InterruptedException
{
WholeFileRecordReader reader=new WholeFileRecordReader();
reader.initialize(split, context);
return reader;
}
}
wholeFileInputFormat这个类继承FileInputFormat
<NullWritable,BytesWritable>
<script type="math/tex" id="MathJax-Element-1">
</script>,这里说明Mapper类中的map方法接受的键类型为NullWritable ,值类型为BytesWritable。 其中的isSplitable()方法返回false表示文件不可被切分,这个inputFormat的目的是将一个文件内容当做一个值。CreateRecordReader方法的目的在于根据InputSplit生成相应的迭代器RecordReader
<NullWritable,BytesWritable>
<script type="math/tex" id="MathJax-Element-2">
</script>,而InputSplit是由父类FileInputFormat
<NullWritable,BytesWritable>
<script type="math/tex" id="MathJax-Element-3">
</script>实现。这里可以不用关心。
WholeFileRecordReader 继承RecordReader
<NullWritable,BytesWritable>
<script type="math/tex" id="MathJax-Element-4">
</script>,而RecordReader中有6个抽象方法,必须实现,分别是
close() ,getCurrentKey(),getCurrentvalue(),getProgress(),initialize(),nextKeyValue()。
- 数据从原始的文件开始,到结束,都需要经过哪些步骤。
作业的提交是在客户端完成的。在作业提交之前,客户端需要做如下几件事情:
- 向资源管理器请求作业ID
- 检查作业输入和输出,确保输出目录是不存在的。否则报错。 针对作业的输入,需要针对输入文件进行分片。
- 将运行作业需要的配置文件,jar文件,以及分片信息保存在HDFS中的以作业ID命名的文佳夹中,以便各个节点复制
- 资源管理器接受到客户端提交的任务。启动资源调度器,选择一个节点管理器节点,启动一个容器,然后再容器中启动application master程序。
- Application master启动之后,需要针对每个分片生成map任务,以及生成reduce任务。如果作业大小比较小的话,map任务和reduce任务将和application master在同一个JVM中运行。否则application master想资源管理器请求容器,资源管理器选择一个节点管理器,启动一个容器,然后在这个容器中运行map或者reduce任务。
细化:
1. 分片
输入文件的分片是有InputFormat类来控制的。InputFormat除去实现分片之外,还确定了map任务输入的键和值类型,因为它是一个泛化类型。首先InputFormat类中的getSplit根据JodContext来生成一个Inpursplit列表,InputSplit类中包含两个信息,分片大小已经分片的位置。当需要启动一个Map任务的时候,调用InputFormat类中的createRecordReader方法,根据inputSplit信息生成一个RecordReader迭代器。然后将这些信息封装在Mapper.context中。当运行mapper类对象的run方法时,使用recordReader迭代访问分片的每条记录。
Shuffle和排序
这里是如何将map的输出结果传递给reduce任务。针对一个map任务,输出结果首先会存储在内存中,如果超过一定阈值,需要把这些输出结果写到硬盘上,在写在硬盘之前需要对内存中的输出结果根据最终要传的reduce进行分区,然后再每个分区中进行排序。这样每个map任务都会生成若干的spill文件(由于大小超过而被溢出到硬盘中),每个spill文件都是已经分区并排好序的。那么在这些spill文件写到硬盘之前,如果有combine任务,就在这时进行,然后将combine任务的输出结果写到硬盘上。这样每个map任务都会生成若干个spill文件,然后将这些spill文件合并成一个文件,这个文件已经分好区,并在区内排好序。接下来,每个reduce复制每个map任务的输出结果中相应区中文件,注意每个reduce对应着不同的区。所以数据也是不一样的。这便是reduce的复制阶段然后进入融合阶段,由于一个reduce任务获得了所有的map上的确定分区的数据,需要将这些文件进行融合(保持顺序),如何并不一定如何成一个文件,可能融合成多个文件之后,就进入reduce阶段。
22 通常情况下,由reduce函数处理的partition内部是根据键排好序的,但是不同的partition的键的顺序并没有排好。我们通常需要在job对象中设定partition类,也就是job.setPartitionerClass(TotalOrderPartitioner.class),从而确定需要获得的reduce任务的数量。hadoop默认使用hashpartition,但是这里可以使用不同的partition类,如果,我们需要对不同的partition的键也排好序,那么在进行partition的时候,就需要对key值分布进行分析,从而选出若干的截点,进行partition类的构造。TotalOrderPartition类便是是想了全局排序。使用全局排序,需要给出partitionFile,而partitionfile的生成可以通过InputSampler的writePartitionFile生成,也就是
InputSampler.Sampler<LongWritable, Text> sampler=new InputSampler.RandomSampler(0.1, 10000, 10);
InputSampler.writePartitionFile(job, sampler);InputSampler.writePartitionFile将生成一个名为_partition.lst文件。然后调用
String partitionFile=TotalOrderPartitioner.getPartitionFile(conf);获得该文件的位置信息,将相应的文件添加到共享文件系统中。
InputSampler.Sampler<LongWritable, Text> sampler=new InputSampler.RandomSampler(0.1, 10000, 10);
InputSampler.writePartitionFile(job, sampler);- 通过secureCRT从本地上传文件到hadoop集群中。
首先执行rz命令,CRT会弹出一个对话框,然后再对话框中选择需要上传的文件。完成第一步,将制定文件上传到服务器,然后 执行 hadoop fs -copyFromLocal 命令,将文件从服务器上传至hdfs.注意对于hdfs来说服务器才是本地文件系统。
最后
以上就是舒适草莓最近收集整理的关于hadoop 练习(1)的全部内容,更多相关hadoop内容请搜索靠谱客的其他文章。








发表评论 取消回复