文章目录
- 一、问题描述
- 二、问题排查
- Java Heap Dump文件
- 使用Jmap获取运行中的jvm内存
- 在Jhat页面查找对应类实例具体的引用
- 问题定位
- 三、解决方案
- 四、总结
一、问题描述
有用户反馈访问httpfs服务偶尔出现502的情况,所以上httpfs服务器看了下,发现有一台因为OOM挂掉了(运维告警没弄好,所以没及时通知到)。
目前有两台HttpFs,通过nginx转发,如果刚好请求转发到挂掉的那台,就会出现502的问题。
因为是OOM问题,所以马上就想着去分析gc日志了。后面简单分析了gc日志,发现从httpfs启动以来,old区域内存呈不断递增的趋势:
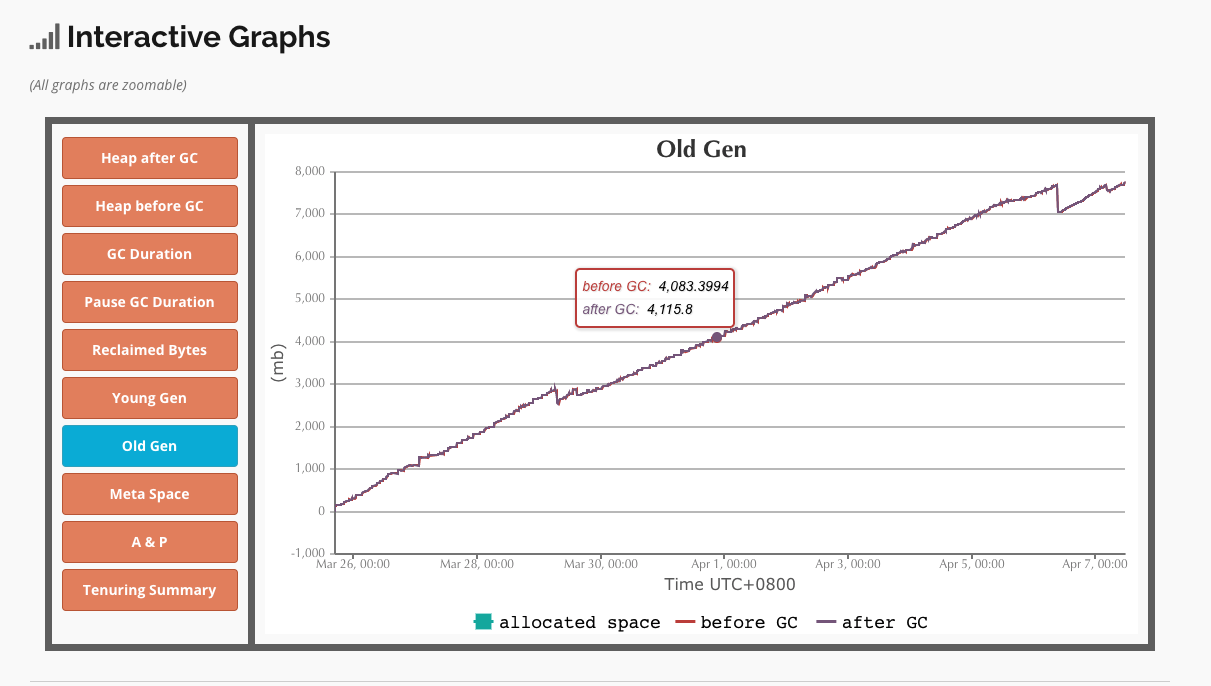
以上图表是通过 https://gceasy.io 网站分析得到
从gc日志可以看出,old区域的占用大小一直从100M上升到了8G,后面有进行了几次fullGc,但是释放的空间并不多,最后程序由于内存空间不足导致OOM。同时看了一下另外一台没挂的httpfs服务,old区域也非常大了,接近OOM。
httpfs只是一个很简单的web代理服务,功能只有下载和上传数据,大部分对象应该在young gc就会清理回收掉才对。所以可以判断应该是哪里代码写的有问题导致了内存泄露。
二、问题排查
Java Heap Dump文件
在java程序启动时加上参数-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/toPath/heapdump.hprof可以在程序出现OOM时输出head dump文件。这样我们就可以通过这个heapdump文件分析哪些对象导致的内存泄露,最终定位到问题。
我们可以通过jhat来分析heapdump.hprof文件:
# heapdump.hprof比较大的话,需要调大jhat的堆内存,防止jhat分析过程中内存溢出
jhat -J-Xmx2048M heapdump.hprof
由于我们的httpfs服务在启动时已经加上了上面的JVM参数,所以在OOM时也输出了heapdump.hprof,但是比较尴尬的是,我们服务的堆内存比较大,因此OOM生成的heapdump.hprof也很大,达到14G的大小。
heapdump.hprof文件太大导致基本无法使用jhat分析。(我们尝试将jhat的堆内存调整到20G,但是在jhat运行一段时间后还是因为OOM而退出),所以放弃直接去分析这个14G的heapdump.hprof。
使用Jmap获取运行中的jvm内存
由于OOM生成的heapdump.hprof无法分析,我们只能让程序先运行一段时间,之后再通过jmap来获取jvm对象的相关信息,甚至也可以使用jmap输出heapdump文件来给jhat分析。
jmap -histo:live pid输出java堆的对象相关信息
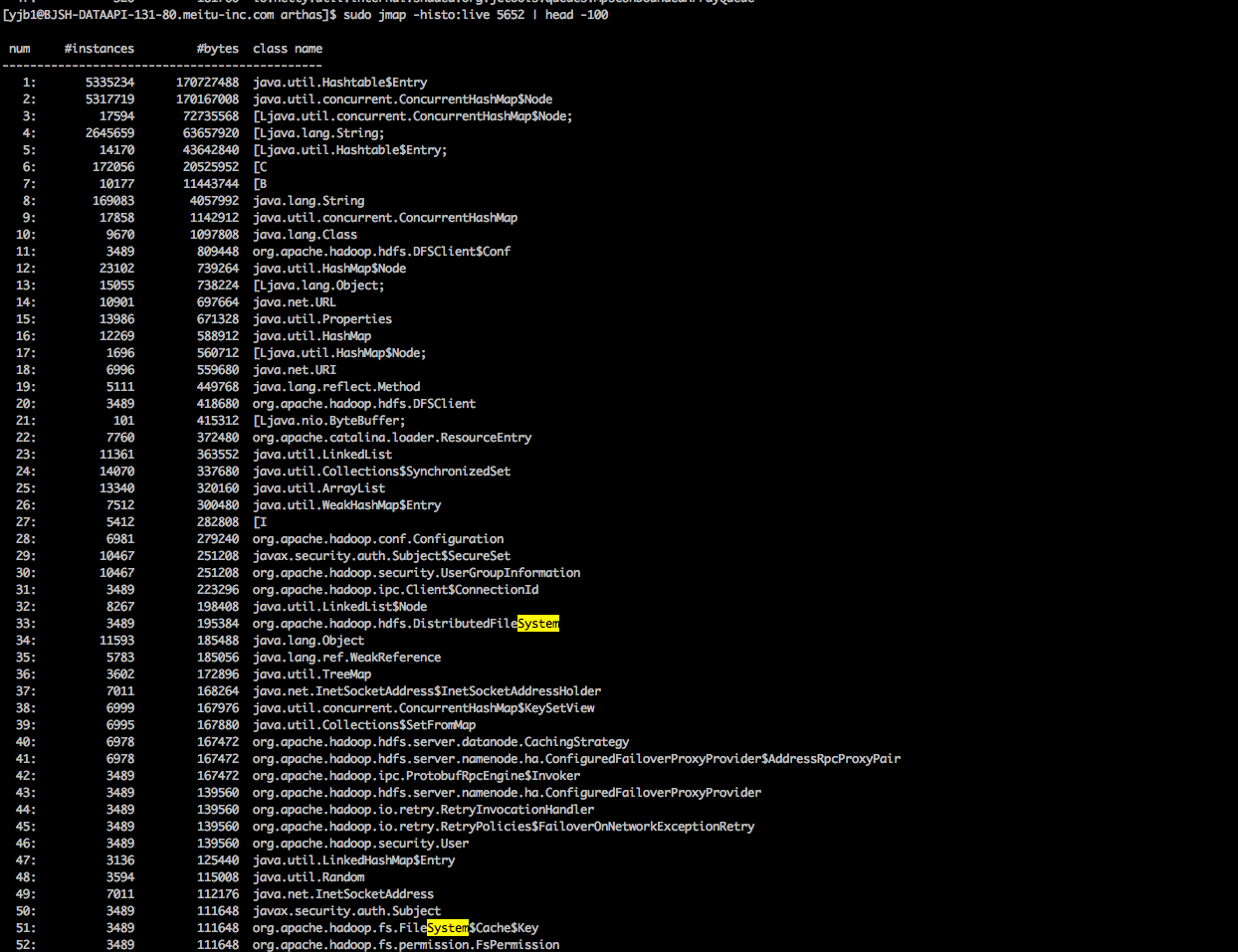
也可以先输出dump文件,然后通过jhat分析:
jmap -dump:live,format=b,file=/path/heapdump.hprof pid
jhat -J-Xmx2048M heapdump.hprof
# jhat启动后在浏览器输入 http://ip:7000 就可以看到对应的信息了
在Jhat页面查找对应类实例具体的引用
通过上面的jmap -histo:live我们可以看出,内存中有大量的Hashtable$Entity和ConcurrentHashMap$Entity对象。但是使用Hashtable和ConcurrentHashMap可能存在很多,我们依旧无法很直观的看出是代码的哪部分出现问题。因此我们还需要借助jhat来找到这些Hashtable和ConcurrentHashMap对象是被哪些对象所引用的。
下面我们随机找一个类演示一下如何通过jhat查看对象实例之间的引用:
先通过http://ip:7000进入jhat的首页面,然后拉到最下方
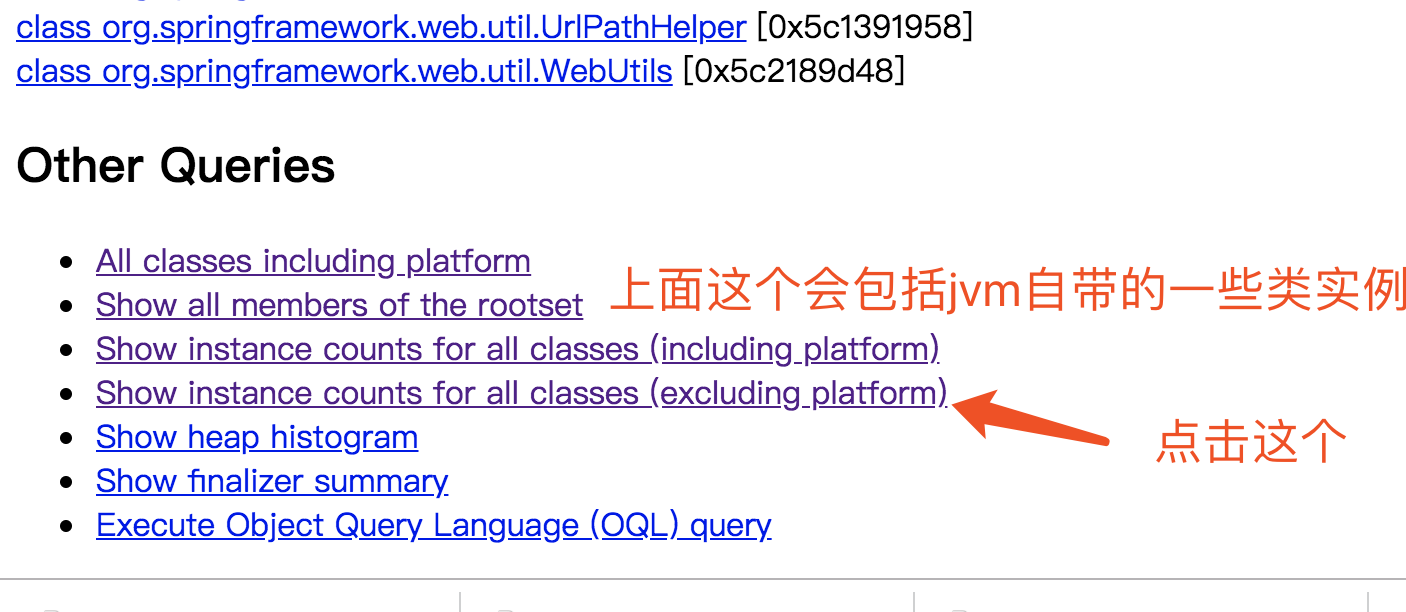
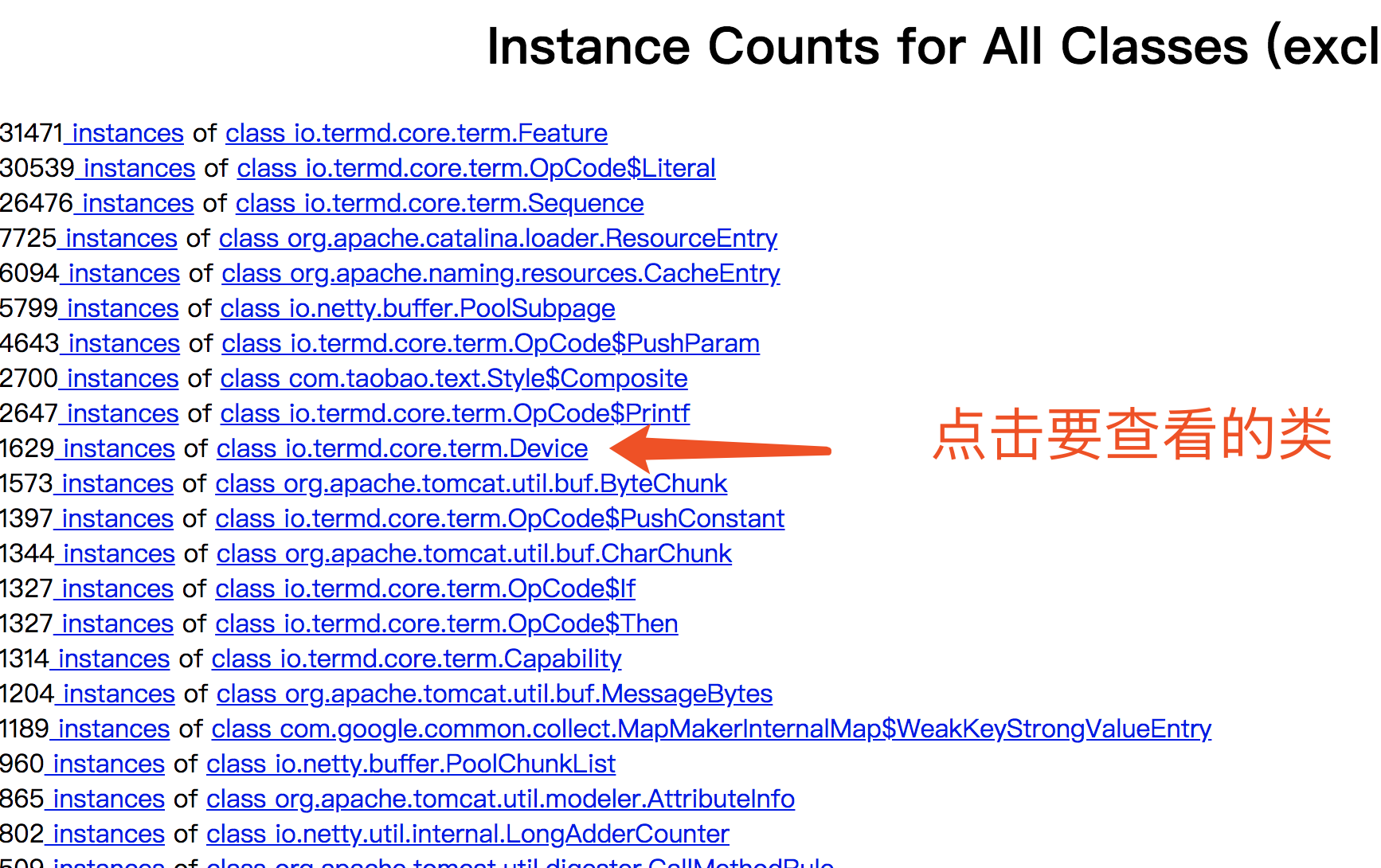

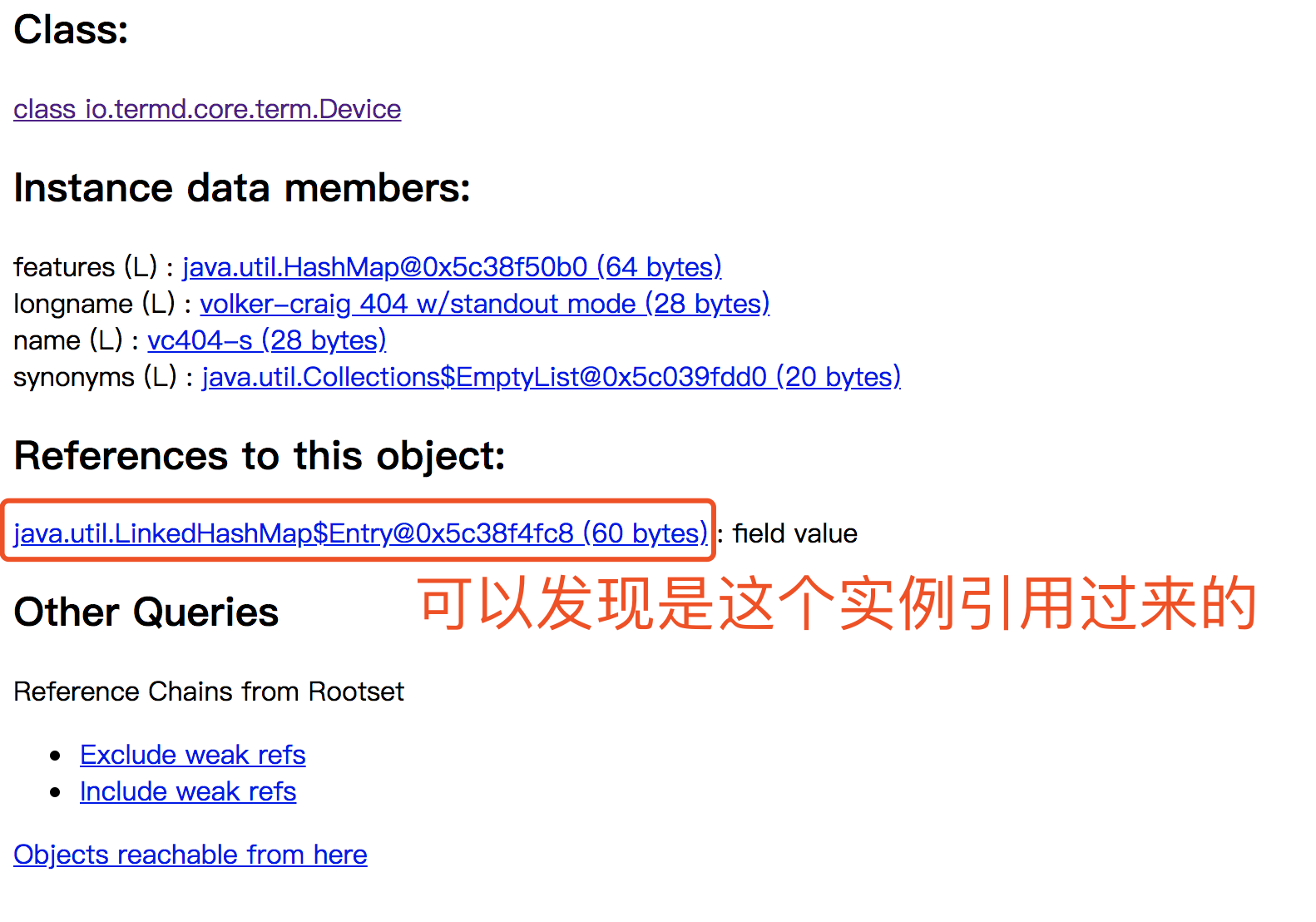
按照上面的方法,通过不断的查询,最终我们会发现到底是哪些类引用了这些类。
问题定位
经过排查,我们发现问题的源头在于org.apache.hadoop.fs.FileSystem这个类,httpfs仅仅运行一天,这个类就产生了几千个实例。这些实例虽然占用的大小不大,但是每产生一个FileSystem实例时,它都会维护一个Properties对象(Hashtable的子类),用来存储hadoop的那些配置信息。hadoop的配置有几百个很正常,因此一个FileSystem实例实例就会对应上百个的Hashtable$Entity实例,就会占用大量内存。
那为什么会有如此多的FileSystem实例呢?
以下是我们获取FIleSystem的方式:
FileSystem fileSystem = FileSystem.get(uri, conf, "hadoopuser");
FileSystem.get底层是有使用缓存的,因此我们在每次使用完并没有关闭fileSystem,只是httpfs服务关闭时才去关闭FileSystem。
FileSystem.get底层的一些代码:
public static FileSystem get(URI uri, Configuration conf) throws IOException {
String scheme = uri.getScheme();
String authority = uri.getAuthority();
if (scheme == null && authority == null) { // use default FS
return get(conf);
}
if (scheme != null && authority == null) { // no authority
URI defaultUri = getDefaultUri(conf);
if (scheme.equals(defaultUri.getScheme()) // if scheme matches default
&& defaultUri.getAuthority() != null) { // & default has authority
return get(defaultUri, conf); // return default
}
}
//如果cache被关闭了,每次都会创建一个新的FileSystem
String disableCacheName = String.format("fs.%s.impl.disable.cache", scheme);
if (conf.getBoolean(disableCacheName, false)) {
return createFileSystem(uri, conf);
}
//直接从cache获取
return CACHE.get(uri, conf);
}
//Cache.class
FileSystem get(URI uri, Configuration conf) throws IOException{
Key key = new Key(uri, conf);
return getInternal(uri, conf, key);
}
//Cache.class
private FileSystem getInternal(URI uri, Configuration conf, Key key) throws IOException{
FileSystem fs;
synchronized (this) {
fs = map.get(key);
}
if (fs != null) {
return fs;
}
fs = createFileSystem(uri, conf);
synchronized (this) { // refetch the lock again
FileSystem oldfs = map.get(key);
if (oldfs != null) { // a file system is created while lock is releasing
fs.close(); // close the new file system
return oldfs; // return the old file system
}
// now insert the new file system into the map
if (map.isEmpty()
&& !ShutdownHookManager.get().isShutdownInProgress()) {
ShutdownHookManager.get().addShutdownHook(clientFinalizer, SHUTDOWN_HOOK_PRIORITY);
}
fs.key = key;
map.put(key, fs);
if (conf.getBoolean("fs.automatic.close", true)) {
toAutoClose.add(key);
}
return fs;
}
}
我们httpfs服务的fs.%s.impl.disable.cache并没有开启,因此肯定有使用cache。所以问题很可能是Cache的key判断有问题。
看了下Cache的Key,判断Key是否相等主要有三个因素
static class Key {
final String scheme;
final String authority;
final UserGroupInformation ugi;
}
scheme和authority基本都是一样的,因此问题大概率是出在ugi上面。后面我们通过arthas查看了此处的ugi的hashcode,确实每次请求的都不一样。
虽然使用cache,但是由于Key的判断问题,所以基本每次请求都会生成一个新的实例,就会出现内存泄露的问题。
最后我们发现,ugi对象的不同是由于我们获取FileSystem时指定了用户有关,我们看一下指定用户时的方法:
public static FileSystem get(final URI uri, final Configuration conf,
final String user) throws IOException, InterruptedException {
String ticketCachePath =
conf.get(CommonConfigurationKeys.KERBEROS_TICKET_CACHE_PATH);
//这里每次获取的ugi的hashcode都不一样
UserGroupInformation ugi =
UserGroupInformation.getBestUGI(ticketCachePath, user);
return ugi.doAs(new PrivilegedExceptionAction<FileSystem>() {
@Override
public FileSystem run() throws IOException {
return get(uri, conf);
}
});
}
//UserGroupInformation.getBestUGI
public static UserGroupInformation getBestUGI(
String ticketCachePath, String user) throws IOException {
if (ticketCachePath != null) {
return getUGIFromTicketCache(ticketCachePath, user);
} else if (user == null) {
return getCurrentUser();
} else {
//最终走到这里
return createRemoteUser(user);
}
}
//UserGroupInformation.createRemoteUser
public static UserGroupInformation createRemoteUser(String user, AuthMethod authMethod) {
if (user == null || user.isEmpty()) {
throw new IllegalArgumentException("Null user");
}
Subject subject = new Subject();
subject.getPrincipals().add(new User(user));
UserGroupInformation result = new UserGroupInformation(subject);
result.setAuthenticationMethod(authMethod);
return result;
}
我们没有开启kerberos配置。UserGroupInformation其实只是对JAAS进行了一些封装,因此UserGroupInformation的hashcode其实就是计算其封装的Subject的hashcode。
从代码可以看出,如果指定了用户,每次都会构造一个新的Subject,因此计算出来的UserGroupInformation的hashcode也都不一样。这样也最终导致FileSystem的Cache不生效。
三、解决方案
- 修改源码:Cache$Key的hashcode方法,让其直接根据UserGroupInformation的userName来判定是否相等。
- 自己构建一个简单的Cache
四、总结
这个内存泄露的问题其实并不难,只需要进行简单的排查即可找到问题所在,解决方法也很简单。写这篇博客主要还是为了记录一下排查这种内存泄露的问题一个大体思路。
本文也详细介绍了如何使用jmap和jhat来定位问题,另外,我们平常也要记得在启动java程序时都带上-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/toPath/heapdump.hprof参数,这样当出现OOM时,我们才可以更方便的排查问题所在。
最后
以上就是笨笨蜻蜓最近收集整理的关于Hdfs FileSystem 使用姿势不对导致的内存泄露的全部内容,更多相关Hdfs内容请搜索靠谱客的其他文章。








发表评论 取消回复