前言
这几年一直在it行业里摸爬滚打,一路走来,不少总结了一些python行业里的高频面试,看到大部分初入行的新鲜血液,还在为各样的面试题答案或收录有各种困难问题
于是乎,我自己开发了一款面试宝典,希望能帮到大家,也希望有更多的Python新人真正加入从事到这个行业里,让python火不只是停留在广告上。
微信小程序搜索:Python面试宝典
或可关注原创个人博客:https://lienze.tech
也可关注微信公众号,不定时发送各类有趣猎奇的技术文章:Python编程学习
集群
集群首先要明白rq中两类节点工作原理
内存节点: 性能更好,将所有的队列,交换器,绑定关系,用户,权限,和vhost的元数据信息保存在内存中
磁盘节点: 将这些信息保存在磁盘中
在集群中的每个节点,要么是内存节点ram,要么是磁盘节点disk
-
如果是内存节点,会将所有的元数据信息仅存储到内存中
-
而磁盘节点则不仅会将所有元数据存储到内存上,还会将其持久化到磁盘
在 RabbitMQ 集群上,至少需要有一个磁盘节点
其它节点均设置为内存节点,这样会让队列和交换器声明之类的操作会更加快速,元数据同步也会更加高效
普通集群
rabbitmq的普通集群
集群模式下,仅仅只是同步元数据,每个队列内容还是在自己的服务器节点上,这样的集群模式,数据将在consumer获取数据时根据存储的元数据进行临时拉取
搭建环境
- ubuntu
- docker
- 单机
搭建流程
集群的搭建,主要基于erlang语言对于cookie之间的支持,节点直接通过erlang cookie进行交换认证
- 启动三台节点
docker run -d --name rabbitmq -e RABBITMQ_DEFAULT_USER=guest -e RABBITMQ_DEFAULT_PASS=guest -p 15672:15672 -p 5672:5672 rabbitmq:3-management
docker run -d
--hostname rabbit_node1
--name rabbitmq1
-p 15672:15672 -p 5672:5672
-e RABBITMQ_ERLANG_COOKIE='rabbitmq_cookie'
-e RABBITMQ_DEFAULT_USER=guest -e RABBITMQ_DEFAULT_PASS=guest
rabbitmq:3-management
sudo docker run -d
--hostname rabbit_node2
--name rabbitmq2
-p 15673:15672 -p 5673:5672
-e RABBITMQ_ERLANG_COOKIE='rabbitmq_cookie'
-e RABBITMQ_DEFAULT_USER=guest -e RABBITMQ_DEFAULT_PASS=guest
--link rabbitmq1:rabbit_node1
rabbitmq:3-management
sudo docker run -d
--hostname rabbit_node3
--name rabbitmq3
-p 15674:15672 -p 5674:5672
--link rabbitmq1:rabbit_node1 --link rabbitmq2:rabbit_node2
-e RABBITMQ_ERLANG_COOKIE='rabbitmq_cookie'
-e RABBITMQ_DEFAULT_USER=guest -e RABBITMQ_DEFAULT_PASS=guest
rabbitmq:3-management
- 进入docker容器,进行节点的加入
一个磁盘节点
docker exec -it rabbitmq1 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
两个内存节点,加入集群
docker exec -it rabbitmq2/3 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbit_node1
rabbitmqctl start_app
该配置启动了3个节点,1个磁盘节点和2个内存节点
–ram 表示设置为内存节点,忽略次参数默认为磁盘节点

在集群中对于某个node操作,都会同步至其余node
当某队列建立在节点2时,不管消费者或生产者未来在集群是否连接节点2,都将会对节点2造成一定压力的cpu访问
这也很好理解,因为数据的同步都将来自于节点2
镜像集群队列
镜像队列中最后一个停止的节点会是master,启动顺序必须是master先启动
如果slave先启动,它会有30秒的等待时间,等待master的启动,然后加入到集群中
如果30秒内master没有启动,slave会自动停止
当所有节点因故同时离线时,每个节点都认为自己不是最后一个停止的节点,要恢复镜像队列,可以尝试在30秒内启动所有节点
镜像队列实现了较普通集群更为靠谱的高可用
普通集群中,内存节点队列的数据并不真实存在,通过构建镜像队列,可以让每一个节点都实际备份复制一份主节点的数据
可以在控制台进行镜像队列集群的配置,也可以在命令行进行策略控制
rabbitmqctl set_policy my-policy "^order" '{"ha-mode": "all"}'
my-policy: 策略名称
^order: 匹配的exchange/queue正则规则
同步策略中的参数
- ha-mode: 同步策略
all: 镜像将生效至集群的所有节点exctl: 结合ha-params使用,用来指定集群中复制几份机器复制nodes: 数组类型,指定复制的主机节点有哪些
- ha-params: 与
ha-mode搭配的参数ha-mode:all: 不生效ha-mode:exactly: 一个数字类型,集群中队列的镜像节点个数,这个个数里还包含主机- 如果指定2个数量的丛机节点都挂了,剩余数量的节点还大于等于2,那么rq会继续自动的从剩余节点中选两个从节点
ha-mode:nodes: 指定当前哪些具体节点成为镜像节点
参考配置
{
"ha-mode":"nodes",
"ha-params":["rabbit@node1","rabbit@node2"]
}
- ha-sync-mode: 队列同步参数
manual: 默认模式,新的队列镜像不会接收现有消息,它只会接收新消息automatic: 新镜像加入时,队列将自动同步
集群效果

某节点实际镜像效果
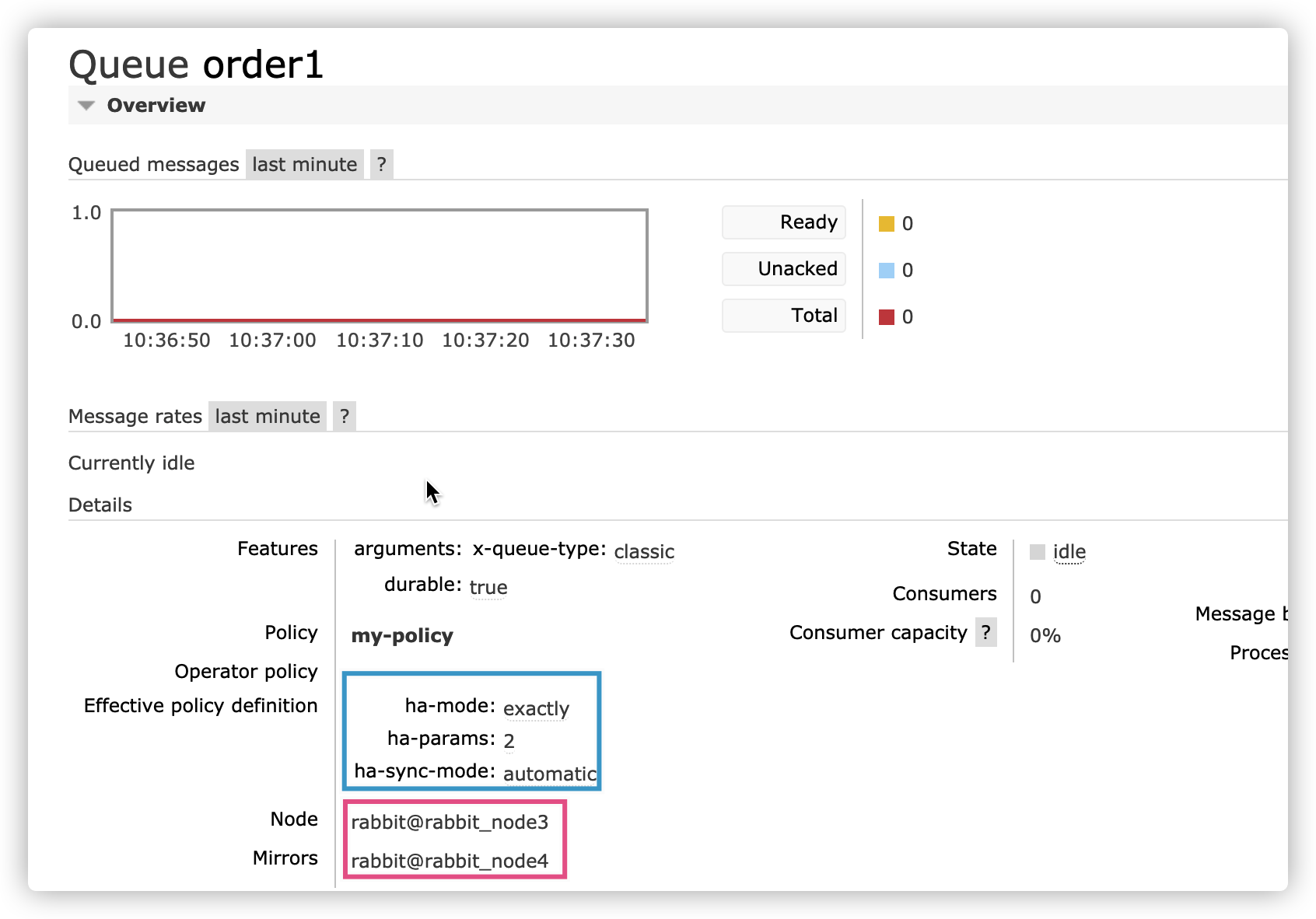
同步
队列同步是一个阻塞操作,建议在队列很小,或节点间网络io较小的情况下使用
- 手动同步
rabbitmqctl sync_queue {name}
- 手动取消同步
rabbitmqctl cancel_sync_queue {name}
查看节点同步状态
rabbitmqctl list_queues name slave_pids synchronised_slave_pids
- name: 队列名称
- slave_pids: 表示已经同步过的节点
- synchronised_slave_pids: 未同步的节点
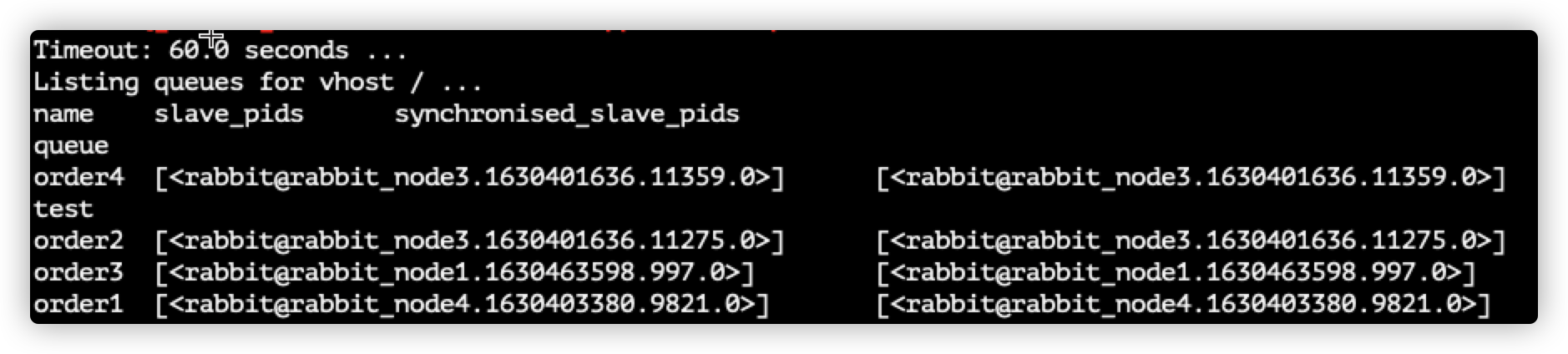
如果
slave_pids和synchronised_slave_pids里面的节点是一致的,那说明全都同步了
example
镜像集群内2个节点,并且匹配队列/交换机为order开头的
rabbitmqctl set_policy my-policy "^order" '{"ha-mode": "exactly","ha-sync-mode":"automatic","ha-params":2}'
负载均衡
安装haprocxy
sudo apt install haproxy
/usr/sbin/haproxy -Ws -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -S /run/haproxy-master.sock
默认配置修改
defaults
log global
mode tcp
option tcplog
option dontlognull
contimeout 5s
clitimeout 30s
srvtimeout 15s
负载均衡配置
listen rabbitmq_cluster
bind 0.0.0.0:5671
mode tcp
balance roundrobin
server server1 127.0.0.1:5672 check inter 5000 rise 2 fall 2
server server2 127.0.0.1:5673 check inter 5000 rise 2 fall 2
server server3 127.0.0.1:5674 check inter 5000 rise 2 fall 2
rabbitmq集群节点配置
- inter 每隔五秒对mq集群做健康检查
- 2次正确证明服务器可用
- 2次失败证明服务器不可用
- 并且配置主备机制
监控配置
listen stats
bind 0.0.0.0:15671
mode http
option httplog
stats enable
stats uri /rabbitmq-stats
stats refresh 5s
haproxy提供了负载均衡的web监控台,查看地址为http://ip/rabbitmq-stats
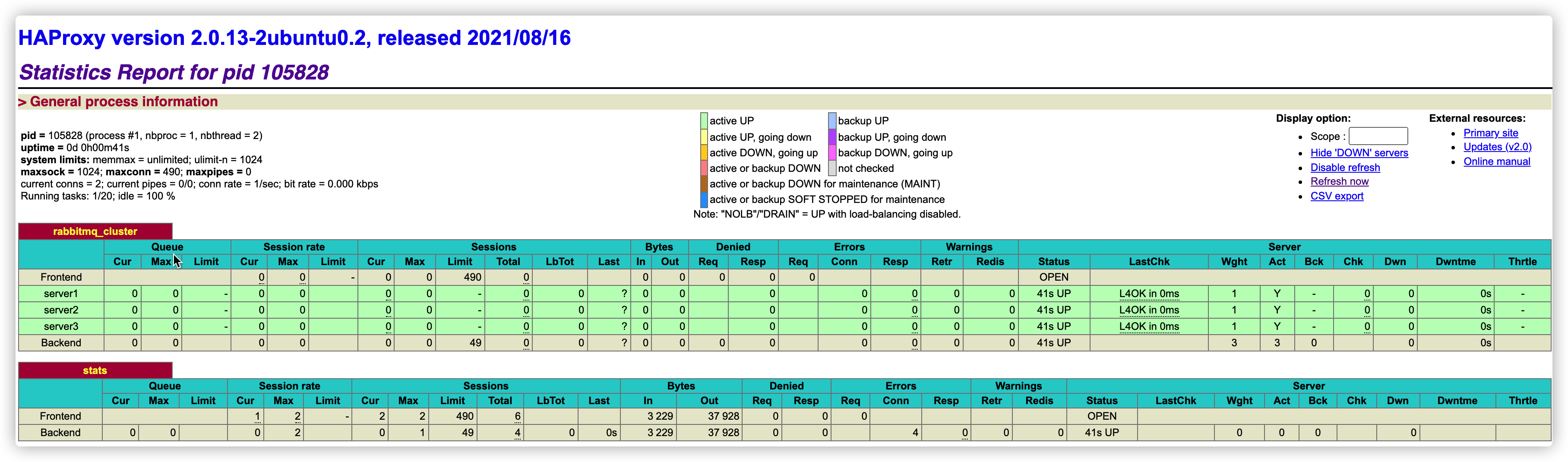
压测
在正常的单机节点进行测试,一生产者、一消费者,十万的消息吞吐,cpu占用率如下

而在负载均衡情况下,一主两丛,三台集群节点,一生产者、两消费者,cpu占用如下

由于rabbitmq1与rabbitmq2此时的队列为镜像,所以生产者的额外负担将会带给镜像队列一份
其他
- 镜像队列发布
对于镜像队列,客户端basic.publish操作会同步到所有节点,
- 镜像队列个数
镜像到所有节点是最保守的选择。它会给所有集群节点带来额外的压力,包括网络 I/O、磁盘 I/O 和磁盘空间使用
在大多数情况下,不需要在每个节点上都有一个副本
选举策略
当主节点挂掉之后,集群会出现如下事情
- 与master连接的客户端连接全部断开
- 选举最老的slave作为新的master
- 新的master重新入队所有unack的消息,此时客户端可能会有重复消息
rabbitmq提供了以下两个参数让用户决策是保证队列的可用性,还是保证队列的一致性
- ha-promote-on-shutdown: 主节点选择参数配置,在可控的主节点关闭时,其它节点如何替代主节点,选取主节点的行为
when-syned(默认): 如果是主动停止主节点,如果salve未同步,此时不会接管master- 优先保证消息可靠不丢失,放弃可用性
always: 不论master因为何种原因停止,非同步的slave都有机会接管master- 优先保证可用性
- ha-promote-on-failure: 主节点选择参数配置,在不可控的主节点关闭时,其它节点如何替代主节点,选取主节点的行为
when-syned: 确保不提升未同步的镜像always: 可提升未同步的镜像
如果ha-promote-on-failure策略键设置为when-synced,即使ha-promote-on-shutdown键设置为always,也不会提升未同步的镜像
ha-promote-on-shutdown默认设置为when-synced,而ha-promote-on-failure默认设置为always
选举测试
此时启动三台节点,认为node1位主节点,并且设置镜像策略,镜像队列数量为2
rabbitmqctl set_policy my-policy "^order" '{"ha-mode": "exactly","ha-params":2}'
新建节点一队列
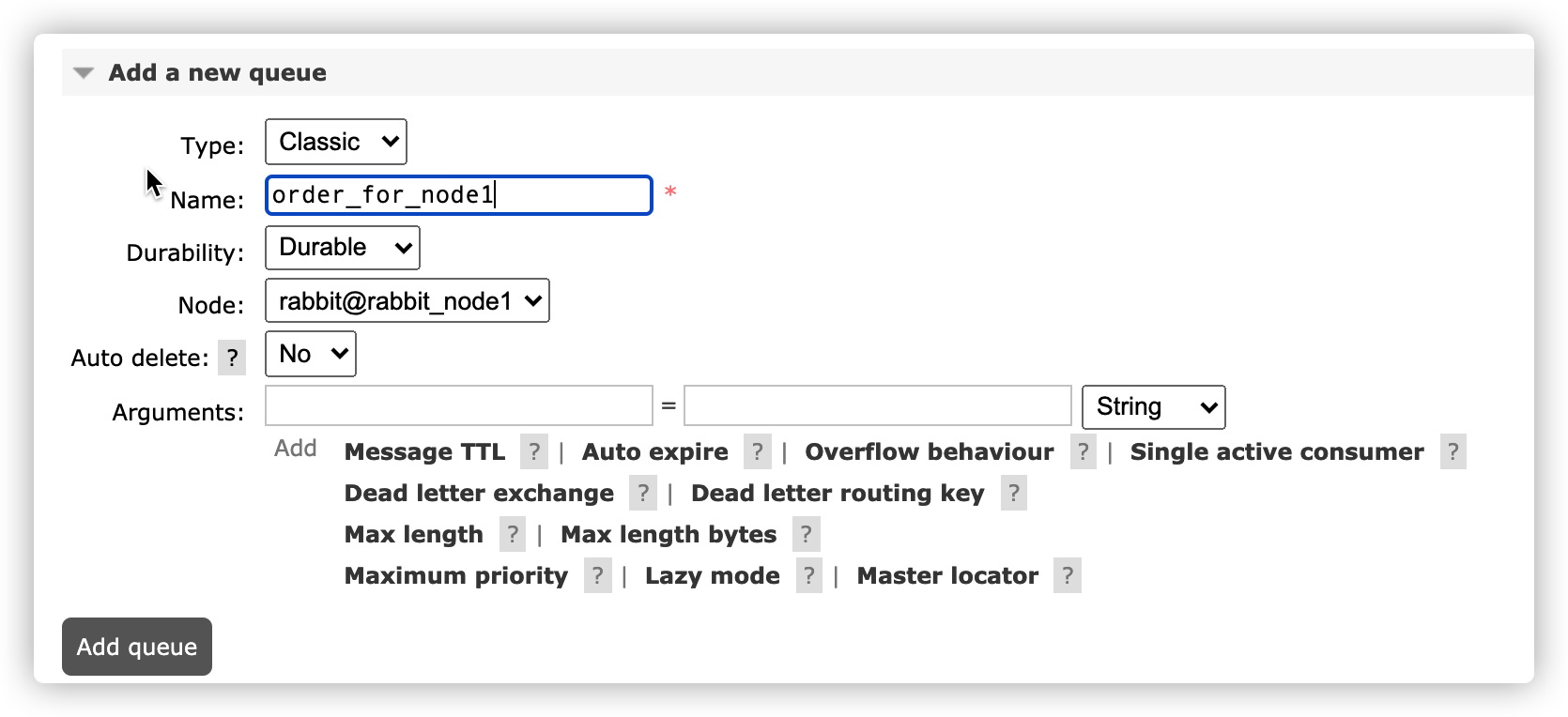
已经完成了基本的镜像

停止节点2,3
sudo docker stop rabbitmq2
sudo docker stop rabbitmq3
此时节点暂无可同步对象

为主节点队列添加5万消息,尽可能多

此时重启从节点,由于策略ha-sync-mode为默认,并不会同步主节点历史消息
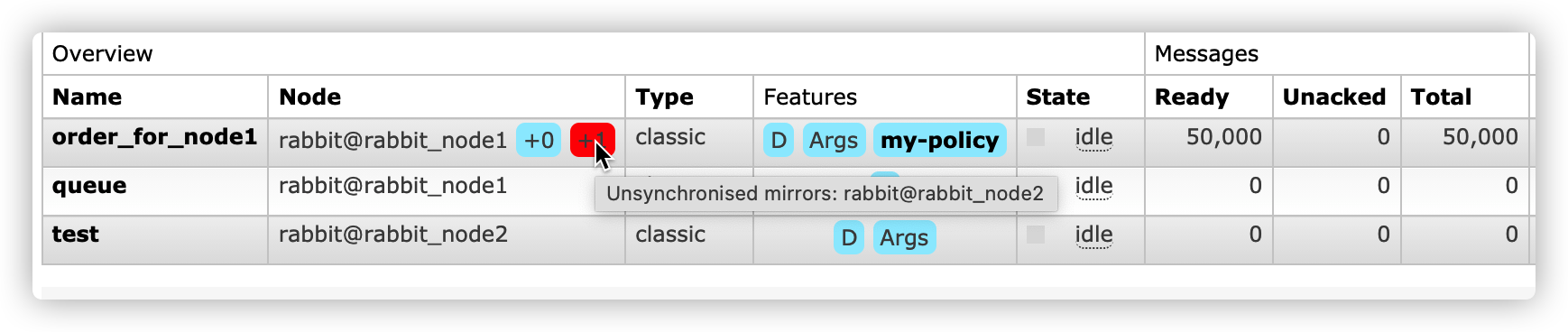
关闭主节点node1,查看节点选举状态
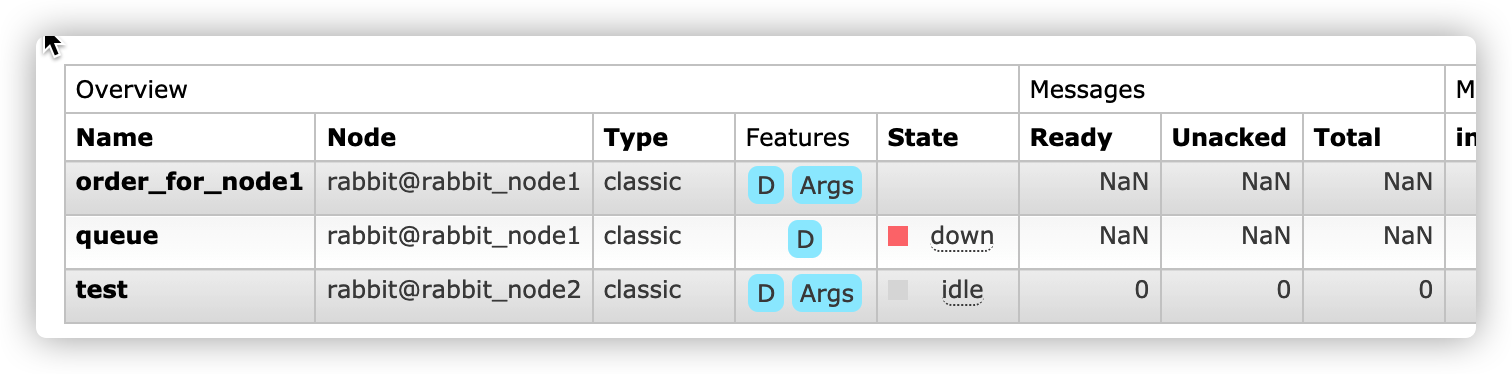
此时由于选举策略所致,节点2,3均为未同步节点,无法成为主master,那么当前队列数据为空
详细信息如下
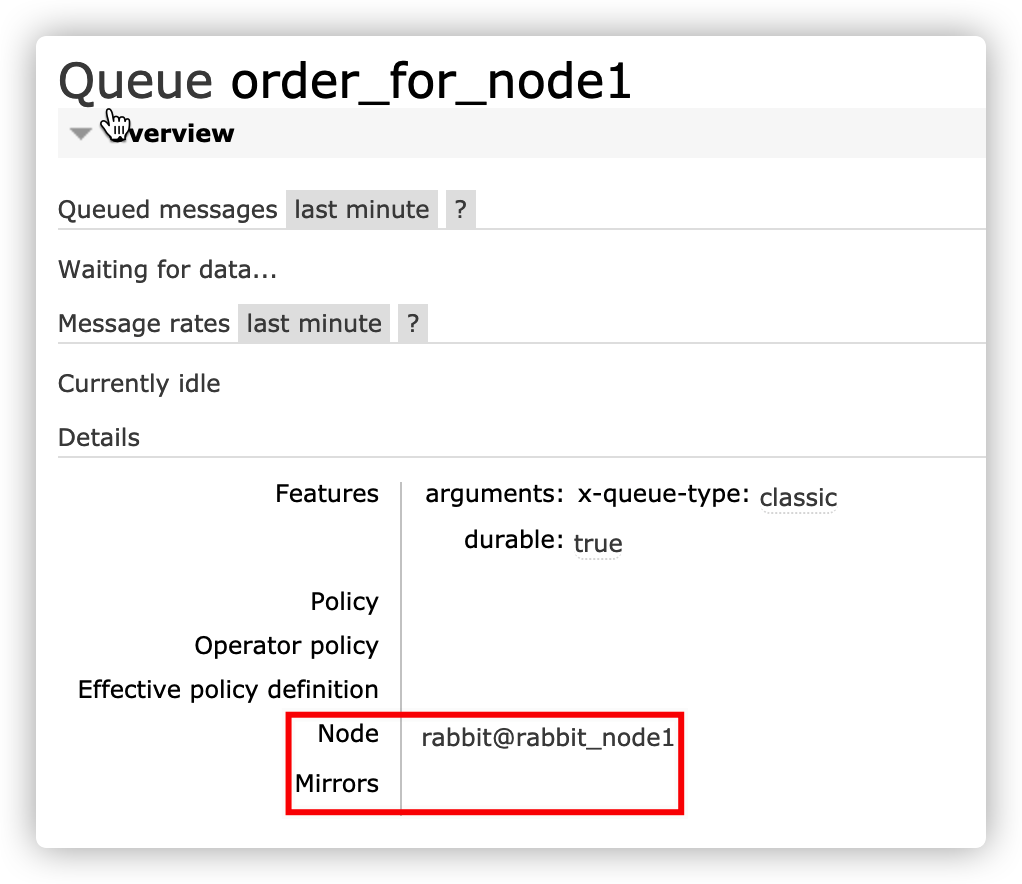
故障恢复
遇到主节点宕机问题,且无法正常选举新节点
需要重新启动主节点
docker start rabbitmq1
之后进行正常消费,当旧有任务消费完成,主节点与从节点处于同步完全状态
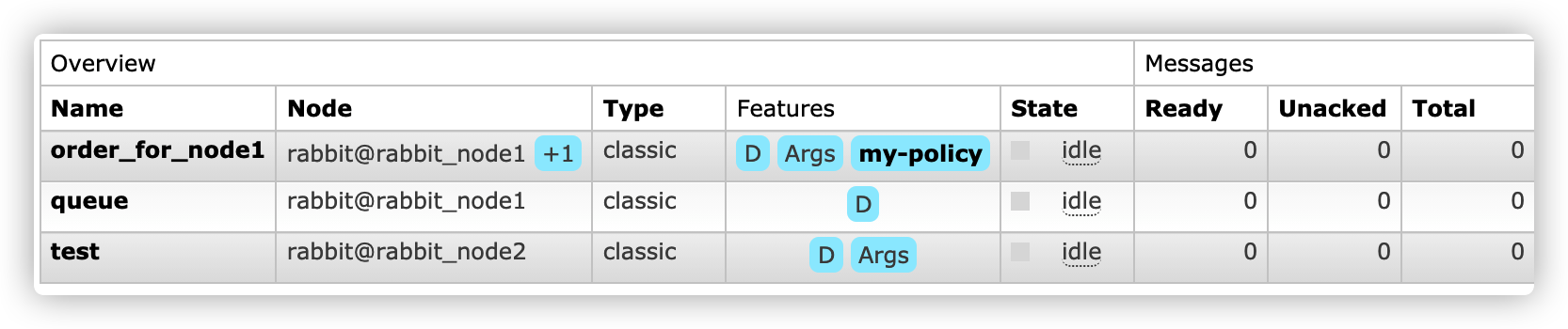
如果遇主节点与从节点都断掉,由于主停,此时从节点无法正常启动
可以通过
rabbitmqctl forget_cluster_node master --offline
--offline: 允许rabbitmqctl在离线节点上执行
forget_cluster_node命令将节点从集群中删除,这将迫使RabbitMQ在未启动的slave节点中选择一个作为master
当关闭整个RabbitMQ集群时,重启的第一个节点应该是最后关闭的节点,因为它可以看到其它节点所看不到的事情
如节点无法启动,则可通过磁盘文件进行拷贝恢复即可,要记着修改hostname

最后
以上就是俊逸八宝粥最近收集整理的关于RabbitMQ普通集群、镜像集群、集群负载均衡、压力测试、选举策略及测试、集群故障恢复【集群超大全详解】的全部内容,更多相关RabbitMQ普通集群、镜像集群、集群负载均衡、压力测试、选举策略及测试、集群故障恢复【集群超大全详解】内容请搜索靠谱客的其他文章。








发表评论 取消回复