《Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation》—Google
1.MobileNetV2结构是基于倒置残差结构,原来的残差结构的主分支是有三个卷积,两个逐点卷积通道数较多,而倒置的残差结构刚好相反,中间的卷积通道数(依旧使用深度可分离卷积结构)较多,两端的较少。另外,我们发现去除主分支中的非线性变换是有效的,这可以保持模型的表现力。
2.论文的主要贡献是提出了一种新型层结构:具有线性瓶颈的倒置残差结构(the inverted residual with linear bottleneck)。
该模块首先将输入的低维压缩表示(low-dimensional compressed representation)扩展到高维,使用轻量级深度卷积做过滤,最后用linear convolution将特征投回低维表示。也就是 [扩张-卷积-压缩] 。
- (1)Linear Bottlenecks
在MobileNetV1中除了引入depthwise separable convolution代替了传统的卷积,还做了一个实验是用width multiplier参数来做模型通道的缩减,相当于给模型“瘦身”,这样特征信息就能更集中在缩减后的通道中(类似于降维(PCA),让网络自己去选择起主要作用的channel),但是如果此时加上一个非线性激活层,比如ReLU,就会有较大的信息损失,因此为了减少信息损失,就有了文中的linear bottleneck,意思就是bottleneck(维度缩减的那一层)的输出不接非线性激活层,而是linear。

第一点的意思是: 对于ReLU层输出的非零值而言,ReLU层起到的就是一个线性变换的作用(ReLU公式可知)。
第二点的意思是: ReLU层可以保留input manifold的信息,但是只有当input manifold是输入空间的一个低维子空间时才有效。
图1证明了ReLU对不同维度的输入的信息丢失对比。显然,当把原始输入维度增加到15或30后再作为ReLU的输入,输出恢复到原始维度后基本不会丢失太多的输入信息;相比之下,如果原始输入维度只增加到2或3后再作为ReLU的输入,输出恢复到原始维度后信息丢失较多。因此在MobileNetV2中,执行降维的卷积层后面不会接类似ReLU这样的非线性激活层,也就是linear bottleneck的含义。

- (2)Inverted residuals
图2展示了从传统卷积到depthwise separable convolution再到本文中的inverted residual block的差异。(a)表示传统的3x3卷积操作,假设输入channel数量为n,那么(a)中红色立方体(卷积核)的维度就是3x3xn。(b)就是在MobileNet V1中采用的depthwise separable convolution。(c)是在(b)的基础上增加了一个类似bottleneck的操作(最窄的那个)。(d)和(c)在本质上是一样的,想象无数个相连的(c)和无数个相连的(d)。另外要注意的是在(c)和(d)中虚线框后面是没有激活层的,这正是前面第一部分的内容。(d)正是本文MobileNet V2的inverted residual block结构,和原来ResNet中residual block对维度的操作正好是相反的。
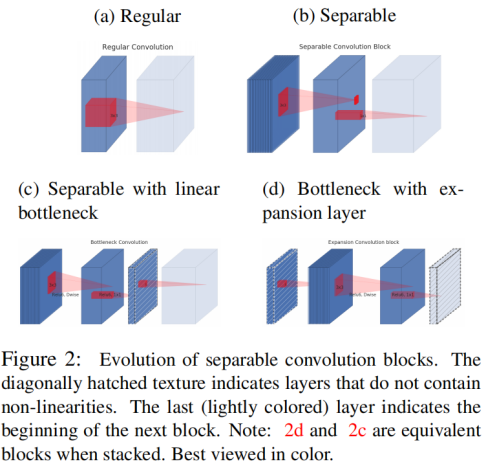
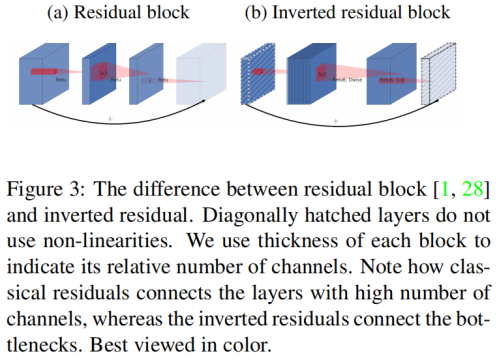
图3是residual block和本文的inverted residual block的对比。在residual block中是先降维再升维,在inverted residual block中是先升维再降维。
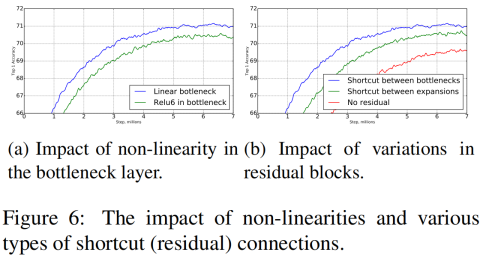
下面的这两张图是原文中的图6,分别是对前面两部分的效果做的总结。
图(a)是关于non-linearity的效果(蓝色曲线),显然top1准确率要高于在bottleneck后加relu层(绿色曲线),证明了Linear Bottlenecks的有效性。
图(b)是关于shotcut连接在不同维度的feature map上的影响,换句话说就是inverted residual(蓝色曲线)和传统residual(绿色曲线)的差别,证明了inverted residual的有效性,红色曲线是不加shotcut的情况。
选择这样的结构,可以提升梯度在卷积层之间的传播能力,有着更好的内存使用效率。下表是bottleneck convolution的基本实现:

- 1)首先是1×1 conv2d变换通道,后接ReLU6激活(ReLU6即最高输出为6,超过了会clip下来)
- 2)中间是深度卷积,后接ReLU6
- 3)最后的1×1 conv2d后面不接ReLU了,而是论文提出的linear bottleneck
3. MobileNetV2的网络结构
整体的网络结构如图2所示。

MobileNetV2结构单元示意图如下(方块的高度即代表通道数):
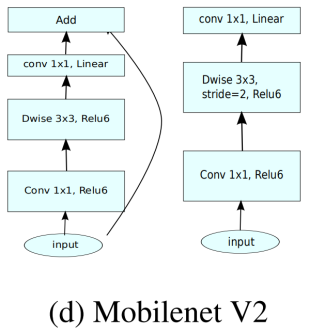
可以看到相比与之前的残差模块,中间的深度卷积较宽,除了开始的升维的1×1卷积,做shortcut的1×1卷积通道数较少,呈现的是倒立状态,故称为Inverted residuals。
这样的结构在构建block时,自然的将输入和输出分离了。把模型的网络expressivity (expansion layers,由扩展层决定)和capacity(encoded by bottleneck inputs,由bottleneck通道决定)分开。
ReLU6:
- 首先说明一下ReLU6,卷积之后通常会接一个ReLU非线性激活,在MobileV1里面使用ReLU6,ReLU6就是普通的ReLU但是限制最大输出值为6(对输出值做clip),这是为了在移动端设备float16的低精度的时候,也能有很好的数值分辨率,如果对ReLU的激活范围不加限制,输出范围为0到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的float16无法很好地精确描述如此大范围的数值,带来精度损失。
本文提出,最后输出的ReLU6去掉,直接线性输出。因为Xception已经实验证明了Depthwise卷积后再加ReLU效果会变差,作者猜想可能是Depthwise输出太浅了应用ReLU会带来信息丢失,而MobileNet还引用了Xception的论文,但是在Depthwise卷积后面还是加了ReLU。在MobileNetV2这个ReLU终于去掉了,并用了大量的篇幅来说明为什么要去掉。
总之,结论就是最后那个ReLU要去掉,效果更好。
4. 实验结果
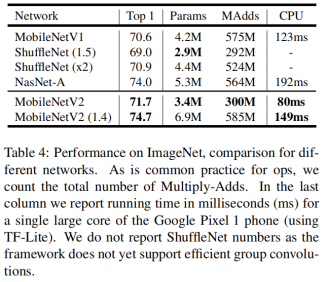
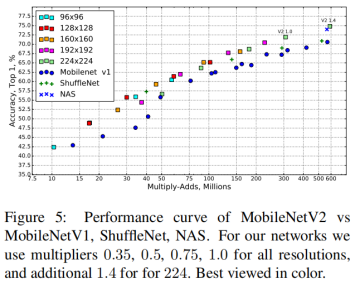
图4、5是几个加速模型在ImageNet数据集上的Top1准确率以及模型大小、速度的对比。
MobileNetV2小结:
- 论文设计的新的Inverted residual bottleneck结构,能够构建一系列高效移动模型,基本的构建单元具有多种特性,同时在内存处理上有极好的性质。新提出的Inverted residual bottleneck结构在理论上具有独特的性质,允许将网络expressivity (expansion layers,由扩展层决定)和capacity(encoded by bottleneck inputs,由bottleneck通道决定)分开,这是未来研究的重要方向。
注:博众家之所长,集群英之荟萃。
最后
以上就是哭泣冰淇淋最近收集整理的关于轻量化网络结构——MobileNetV2的全部内容,更多相关轻量化网络结构——MobileNetV2内容请搜索靠谱客的其他文章。








发表评论 取消回复