java高级部分
一、异常处理
1.什么是异常处理,异常处理的继承结构
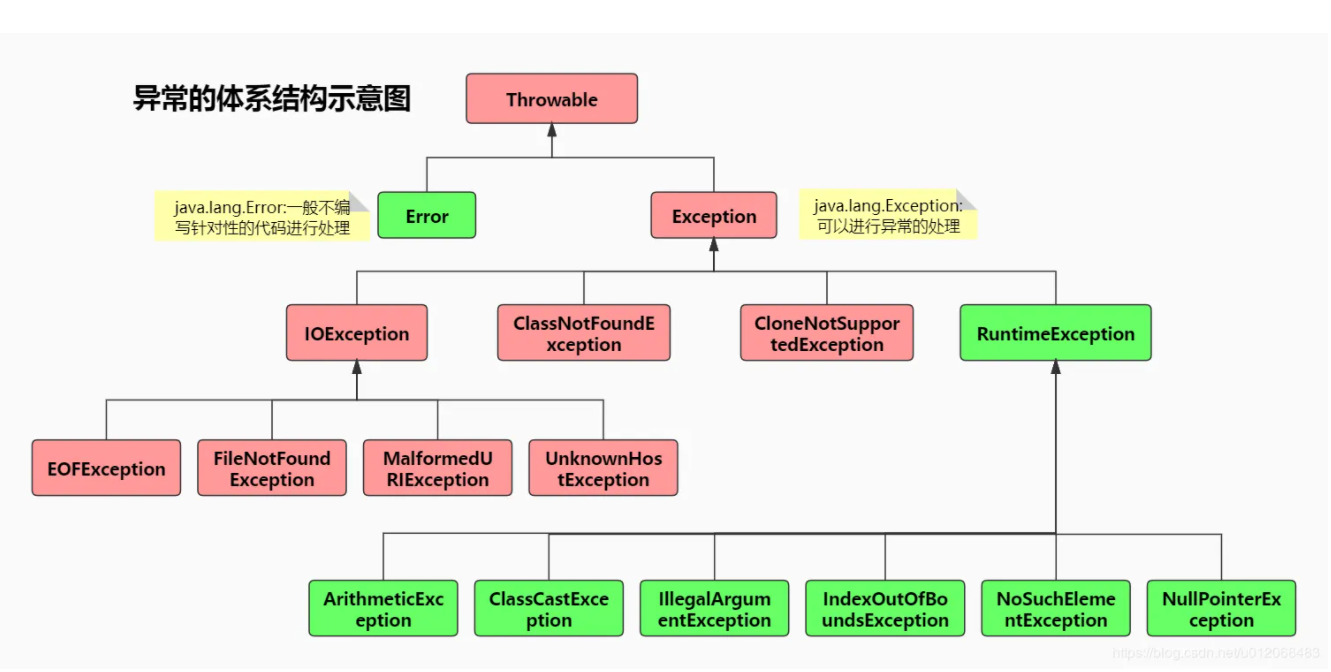
java程序出现问题的分类:Throwable-- Exception 一般是程序员可以控制的部分,你去控制可能会出现的异常的代码就是异常处理
– Error 一般是程序员不能控制的部分,JVM崩溃,操作系统出问题StackOverFlowError,出现error,jvm自动退出,程序自动退出
2.异常处理和错误的区别
3.常见的异常
编译时异常 需要强制使用try catch来处理的 IOException SQLException FileNotFoundException ,InterruptedException
运行时异常RuntimeException 一般不需要强制处理 NullPointerException,ArrayIndexOutOfBoundsException,ArithmaticException、ClassCastException
4.异常处理的五大关键字
try 一般包含可能会出现的异常的代码块
catch 捕获try代码块存在的对应的异常并处理,多重catch,捕获异常要从小到大
try{
....
}catch(IOException e){ //父类表示的范围更大,可以处理所有的异常
}catch(Exception e){
}
try{
.... //产生了SQLException的对象 se
}catch(Exception e){ //se instanceof IOException
}catch(IOException e){ //大的范围放在后边 Exception是SQLException的父类
se instanceof SQLException ==true
se instanceof Exception ==true
se instanceof Object ==true
}finally{
}
finally 无论程序是否出现异常,都会被执行,一定会被执行,比如一些释放资源,IO流,锁的释放等
throw 手动抛出异常 throw + 异常的对象 throw new IOException(); ,使用是放在方法中
throws 一般放在方法的声明之后,代指该方法可能会产生某个异常 throws +异常类 ,引用该方法必须要对该异常进行处理
5.finally 和return
public int a(){
int i = 0;
try{
System.out.println(i++);
return i; //会把return 1;压入栈中,出栈返回return 1,得到结果就是1
}catch(Exception e){
i++;
}finally{
i++; //i=2
}
}
System.out.println(a());//1?2?,结果是1
即使try中有return语句时,并执行时仍然会先去执行finally ,会
public int a(){
int i = 0;
try{
System.out.println(i++);
return i; //会把return 1;压入栈中,出栈返回return 1,得到结果就是1
}catch(Exception e){
i++;
}finally{
i++; //i=2
return i;//方法会直接return 2结束
}
}
System.out.println(a());//1?2?,结果是2
public int a(){
int i = 0;
try{
System.out.println(i++);
}catch(Exception e){
i++;
}finally{
i++; //i=2
}
return i;
}
6.finally,final 区别
final 可以修饰类 代表该类不能被继承 String
final修饰变量 代表常量,定义时必须初始化,而且不能再修改该值
final修饰方法 代表方法不能被重写
二、数据结构和算法
1.常见的数据结构(逻辑关系)
集合结构 - 数据之间没有任何关系 (桌子、椅子、电脑、足球)
线性结构 - 线性关系,除了第一个元素和最后一个元素,每一个元素都有前驱和后继 (比如排队)
树结构 - 层级关系(比如组织结构图),有且只有一个根节点
图结构 - 网状结构
2.存储结构
(1)线性存储结构 数组 --连续的存储空间
查询的效率高,但删除和添加的效率低
(2)链式存储结构 链式–不一定是连续的存储空间
查询效率低,但删除和添加效率相对高一些
单向链表 双向链表 循环链表
3.线程结构的一些应用
栈stack - 先进后出
队列Queue - 先进先出
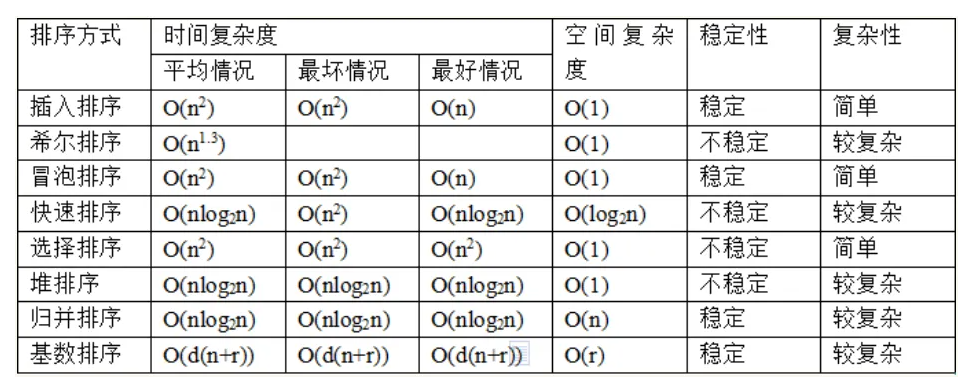
4.算法
查找算法 - 二分查找法,前提是必须是有序的序列
排序算法:
比较类 :
—交换排序(冒泡排序、快速排序)
—插入排序 (简单插入排序、希尔排序)
—选择排序(简单选择排序、堆排序)
—归并排序
非比较类:
计数排序
桶排序
基数排序
三、集合(重点中重点)
1.java中的集合分类
Collection体系
单列值
--Set集合
不可重复
--List集合
可重复
--Queue(队列)
Map体系
双列值 key-value
--Map集合
2.Set集合常用的Api
HashSet 无序 不可重复 基于线性结构(底层使用数组)
TreeSet 基于树结构存储,该集合中元素必须实现Comparable接口
LinkedHashSet 有序 ,采用链式存储结构,存入的顺序和读取的顺序是一致的
无序一般指添加的顺序和读取的顺序可能会不一致
3.List集合
ArrayList 线性列表 数组
LinkedList 链式结构
Vector 与ArrayList一致,线程安全的
Stack 栈 ,先进后出,继承的Vector
比如设计一个容器(集合),要求能装入重复的数据、查询比较多,并发比较多,暂时不考虑数据安全,偏重考虑效率
选择 ArrayList
4.Map集合
HashMap
LinkedHashMap
HashTable
TreeMap
5.hash哈希
(1)哈希的概念 – 散列
一般用在顺序存储结构中
Object类中的hashcode()可以获取,所有堆中的对象都有一个对应索引–真实地址的对应关系
可以通过hashcode()获取索引值,可以在索引表中查到其对应的真实地址,就可以直接获取到地址中的内容,这个效率是非常高
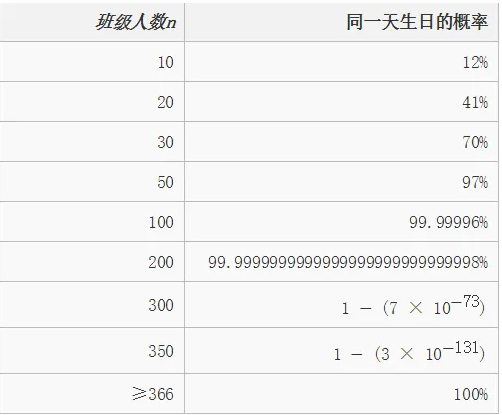
(2)哈希有可能在散列的时候出现哈希冲突
生日悖论 – 比如一个班有50个人,出现生日相同的概率有多少? 一年365天,50/365
hash冲突是需要尽力避免,但是不能完全避免的,需要尽量提供一个好的hash算法,尽量减少hash冲突
(3)如何解决hash冲突
扩容
使用链式方式存储
1.7之前 数组+链表
1.7之后 数组+链表+红黑树 链表转红黑树的条件: 元素个数>=64个 链表的长度>=8
红黑树转链表: 红黑树的节点个数<=6个
6.集合当中的hash
(1)HashSet如何保证数据的唯一性
a、HashSet使用HashMap,利用HashMap的key的唯一性来保证HashSet的唯一性
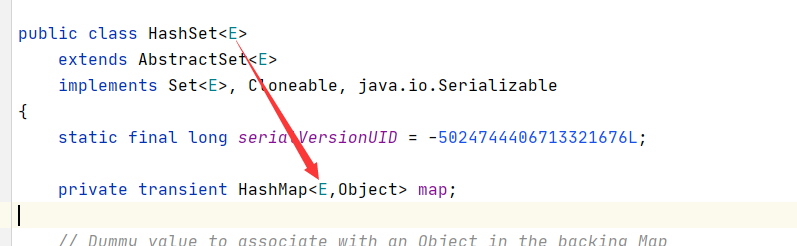 code()和equals()保证唯一性的
code()和equals()保证唯一性的
先比较hashcode值,假如hashcode值一致,继续比较equals(),返回true代表这是同一个对象,不加入该元素
假如hashcode值不一致,代表该元素不是同一个元素,可以加入该元素
hashcode一致,就代表是同一个对象,这句话是错的,因为可能会有hash冲突
只要hashcode一样,不论通过什么hash算法,只要是通过一个hash算法,它的散列值一定是一样的
同一个对象,他的hashcode一定是一致的
为什么这样设计?
因为大部分的对象大概率都是不一样的,使用hashcode的比较效率会比较高(因为这种算法查找比较快),可以过滤掉大部分的比较,当出现hashcode值一样的时候,才需要再通过equals进一步判断是否一致,所以这样的设计更优
(2)ArrayList的扩容机制
底层使用数组
初始大小就是10,当超过10个时候进行扩容(创建一个新的数组,数组大小会比原来数组更大),会进行数据迁移操作
//扩容的方法
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length; //获取旧的容量,比如默认大小10
int newCapacity = oldCapacity + (oldCapacity >> 1);//计算出扩容后的容量 10+ 10>>1=10+10/2=15,扩容就是从10--》15,下次再扩容的时候 旧容量就是15,15+15/2=15+7=22
(3)HashMap的原理(重点)
1.7和1.8的区别,如何解决hash冲突,如何扩容的,存在什么问题?
特点:双列值 key - value对的形式 map.put(“name”,“john”);
a.key的值是唯一的, hashcode()和equals()保证唯一
b.允许key的值是null ,map.put(null,“a”); map.put(null,“b”);
c.当key重复的时候,value是覆盖还是不能添加, 覆盖
d.hashmap底层的基本实现是通过数组的方式实现,初始化大小16
在解决HashMap冲突中,为什么选用红黑树,而不是其他数据结构,如:平衡二叉树、b/b+树之类的?
avl平衡树容易失去平衡,需要旋转的次数的比较多
红黑树要求没有这么严格,可以通过改色和旋转的方式调整平衡
相同点:
HashMap常见的属性及表示的意思
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final int MAXIMUM_CAPACITY = 1 << 30; //Hashmap最大能存储的元素个数,10亿多个
static final float DEFAULT_LOAD_FACTOR = 0.75f; //默认负载因子,用在扩容上16*0.75=12,当元素个数超过12个的时候就会进行扩容
//=============以上是jdk1.7 1.8都有的,以下的只有jdk1.8才有
static final int TREEIFY_THRESHOLD = 8; //树形化阈值,当链的长度大于8的时候可以转化成红黑树
static final int UNTREEIFY_THRESHOLD = 6;//从红黑树--》链式的阈值
static final int MIN_TREEIFY_CAPACITY = 64;//最小树形化容量,当集合中容量大于64的时候才会被树形化
不同点:
解决hash冲突的问题
jdk1.7中使用的数组+链表
采用的头插法,在多线程扩容中可能会造成死循环的问题
链表最大的缺点查询效率低,时间复杂度O(n)
jdk1.8中使用的数组+链表+红黑树结构,
采用尾插法,避免死循环的问题。
(4)ConcurrentHashMap juc包 java.util.concurrent 并发包(多线程操作)
hashmap最大的问题就是在并发中存在线程不安全的问题?
a.可以使用HashTable(注意,HashTable的key不能为null),大量使用synchronized,效率会比较差
b.juc(java.util.concurrent.*)包下 ConcurrentHashMap
在1.7中使用分段锁
在1.8中使用cas+synchronized
cas compare and swap 比较并交换 ,乐观锁机制
7.泛型
主要引用在集合中
List list = new ArrayList();
List list = new ArrayList<>();//使用了泛型
使用泛型有什么好处?
上边的定义可以添加任何类型的数据放入集合,取值的时候无法确认放入的类型
通过泛型的方式去约定该集合中只能放入什么类型的值,在编译的时候就会做类型检查,取得时候不需要类型转换
泛型的特点:
泛型的擦除性,其实java当中伪泛型,在编译后生成的class文件并没有泛型
在使用中一定要注意,以下代码会报错
public class Test3 {
public void a(List<String> list1){
}
public void a(List<Integer> list2){
}
}
上边的方法为什么会报错?
编译后由于泛型的擦除性会变成以下代码,已经不是重载了
public class Test3 {
public void a(List list1){
}
public void a(List list2){
}
}
List<? extends Human> List<? super Human> List<?> 上限下限通配符
使用当中一些习惯 K V E T等表示 key value element type
public class Test<X>{
X t;
public <X> void setT(X t){
this.t = t;
}
public X getT(){
return this.t;
}
}
Test<String> test = new Test<>();
四、多线程
1.多线程的概念
(1) 程序、线程、进程的区别(掌握)
程序就是静态的代码,进程就是运行的程序,线程是进程的一部分
进程是分配独立的存储空间,每个进程有自己独立的存储空间,线程没有独立的存储空间,共享进程的存储空间
(2) 多线程的生命周期(掌握)
public enum State {
/**
* Thread state for a thread which has not yet started.
*/
NEW,
/**
* Thread state for a runnable thread. A thread in the runnable
* state is executing in the Java virtual machine but it may
* be waiting for other resources from the operating system
* such as processor.
*/
RUNNABLE,
/**
* Thread state for a thread blocked waiting for a monitor lock.
* A thread in the blocked state is waiting for a monitor lock
* to enter a synchronized block/method or
* reenter a synchronized block/method after calling
* {@link Object#wait() Object.wait}.
*/
BLOCKED,
/**
* Thread state for a waiting thread.
* A thread is in the waiting state due to calling one of the
* following methods:
* <ul>
* <li>{@link Object#wait() Object.wait} with no timeout</li>
* <li>{@link #join() Thread.join} with no timeout</li>
* <li>{@link LockSupport#park() LockSupport.park}</li>
* </ul>
*
* <p>A thread in the waiting state is waiting for another thread to
* perform a particular action.
*
* For example, a thread that has called <tt>Object.wait()</tt>
* on an object is waiting for another thread to call
* <tt>Object.notify()</tt> or <tt>Object.notifyAll()</tt> on
* that object. A thread that has called <tt>Thread.join()</tt>
* is waiting for a specified thread to terminate.
*/
WAITING,
/**
* Thread state for a waiting thread with a specified waiting time.
* A thread is in the timed waiting state due to calling one of
* the following methods with a specified positive waiting time:
* <ul>
* <li>{@link #sleep Thread.sleep}</li>
* <li>{@link Object#wait(long) Object.wait} with timeout</li>
* <li>{@link #join(long) Thread.join} with timeout</li>
* <li>{@link LockSupport#parkNanos LockSupport.parkNanos}</li>
* <li>{@link LockSupport#parkUntil LockSupport.parkUntil}</li>
* </ul>
*/
TIMED_WAITING,
/**
* Thread state for a terminated thread.
* The thread has completed execution.
*/
TERMINATED;
}
NEW - 新创建的线程还没有执行start(),这时候的状态就是new
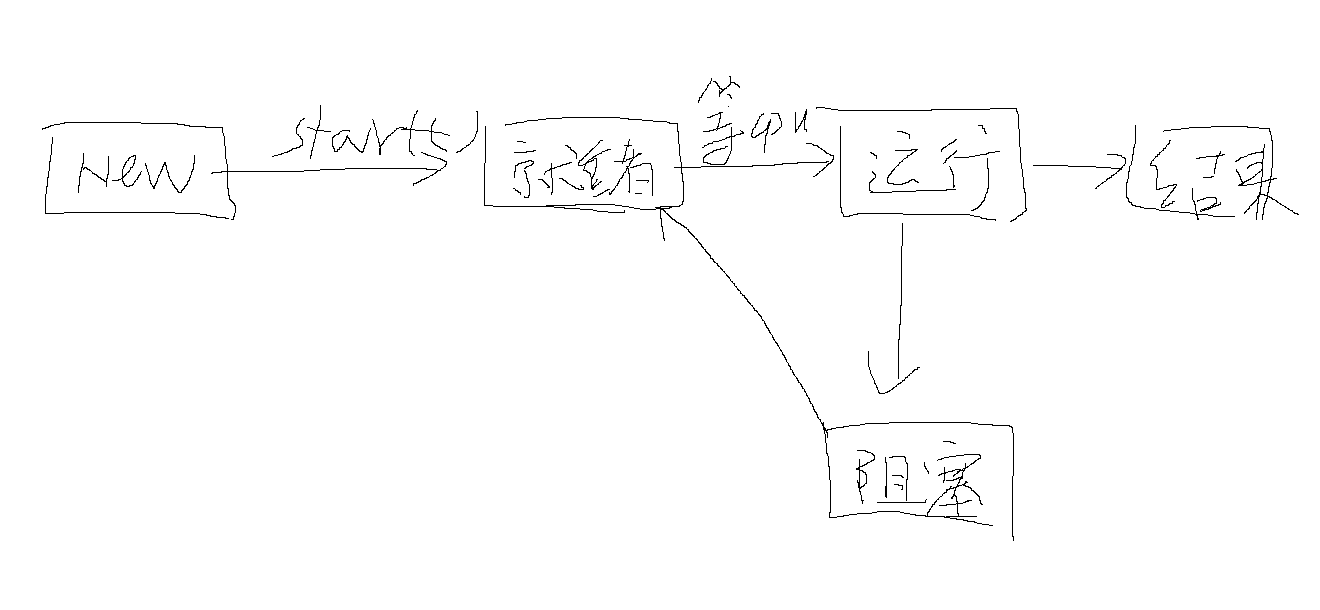
线程执行之前都首先进入就绪状态,等待cpu的调度执行,程序员是无法控制多线程并发异步时的执行先后顺序
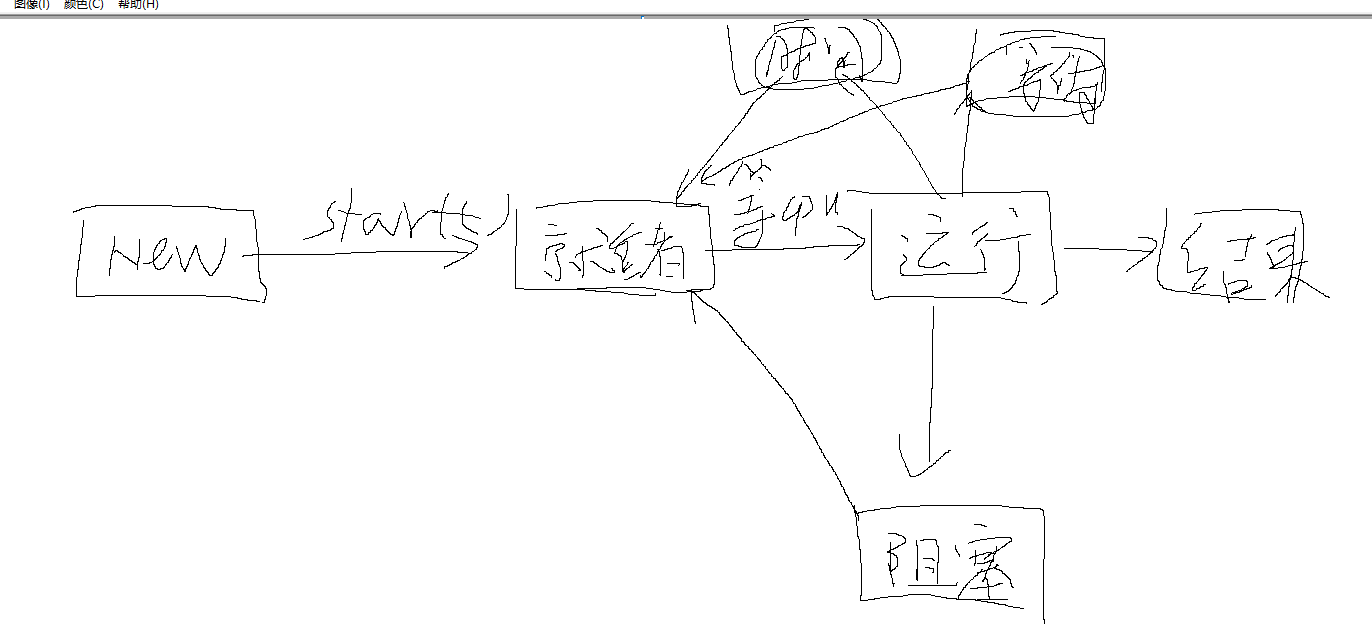
(3)状态的转换
new – 》 就绪 start()
就绪–》运行 程序员无法控制,全权由cpu自己控制
运行–》阻塞 一个线程获取到锁,其他线程就处于阻塞状态,等线程运行完释放锁后,其他线程从阻塞状态进入就绪状态再竞争cpu
运行–》时间等待 sleep(1000) , wait(1000),join(1000) ,超过时间后会从时间等到回到就绪状态
运行–》等待状态 wait() join() wait等待notify(),join()等待加入的线程执行完毕,从等待状态–》就绪状态
运行–》结束 线程执行完毕,从运行状态转到结束
sleep()和wait()的区别?
sleep()进入时间等待状态,wait()进入等待状态
sleep()不会释放锁,而wait()会释放锁,通过notify进行协作
2.线程的创建的方式(掌握)
(1)extends Thread 线程执行完后没有返回值
(2)implements Runnable 线程执行完后没有返回值
public void run(){}
(3)implements Callable 线程执行完后可以接受返回值
(4)使用线程池的方式创建线程
3.守护线程
守护线程就是伴随主线程,主线程退出,守护线程会自动跟着退出
4.多线程的数据共享出现数据不安全的问题,使用同步
使用多线程的目的?
充分利用cpu的资源,提升程序执行的效率(操作任务中可能有些会比较耗时,出现cpu资源浪费)
在使用多线程的时候数据不共享那是没有问题的。
但多线程要使用共享数据的话可能就会出现数据不安全的问题(线程不安全)
ArrayList和HashMap属于线程不安全的,但多线程操作该集合的时候,可能会出现数据不一致或者数据丢失等问题。
Vector和HashTable属于线程安全的,在多线程的并发环境下能保证数据的一致性
如何实现线程的安全性?
要使用到锁的机制
5.synchronized关键字
(1)synchronized关键字的用法
可以用来修饰代码块,也可以用来修饰方法
public void a(){
synchronized(object或者是一个类Student.class){
//需要上锁的同步代码块放在这
}//代码块执行完才能释放锁
}
Lock lock = new ReentrantLock(true);//true是代表是公平锁
try{
lock.lock();
i++;
i = i + 5;
}catch(Exception e) {
System.out.println("123");
} finally {
lock.unlock();//一定要定义在finally
}
注: (1)object就是承担了锁的作用,多线程操作的时候都是抢这把锁,这个锁是一个互斥锁,但一个线程抢到了这把锁,会排斥其他的线程
(2)什么可以作为锁? 类可以作为锁,对象也可以作为锁,区别主要是在锁的范围上,一定要注意一点,只有是同一把锁才能锁住其他的线程
(3)synchronized关键字修饰普通方法和静态方法的区别?
修饰普通方法就相当于使用当前对象this作为锁
修饰静态方法就相当于使用当前类作为锁(所有的线程都使用这一把锁)
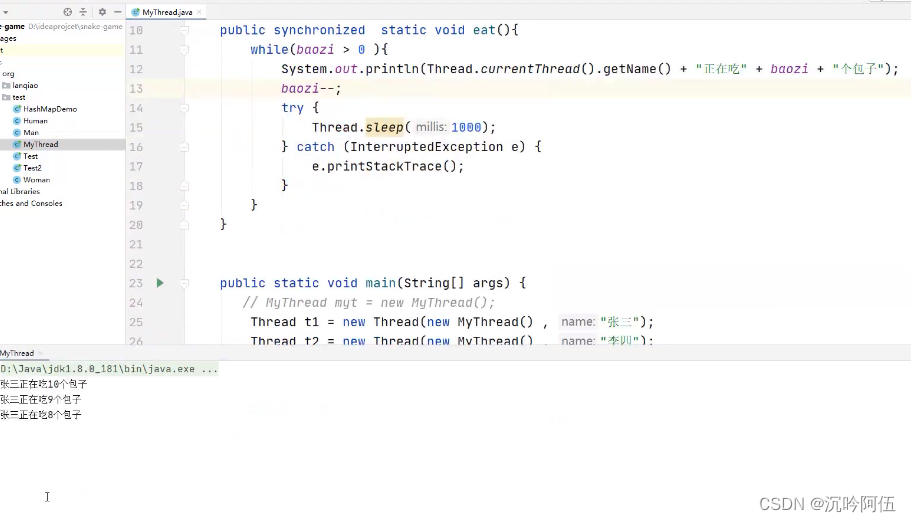
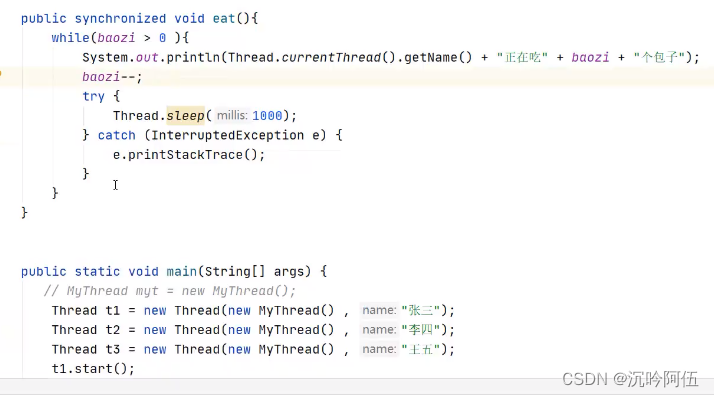

举例:(四种方法,一种将锁设置为类本身(内存中唯一),一种将线程对象设置为同一个,还可以自己定义一个对象当作锁(前提是线程对象唯一),如果线程对象不唯一且要自定义对象当作锁,自定义对象必须是静态的才行)
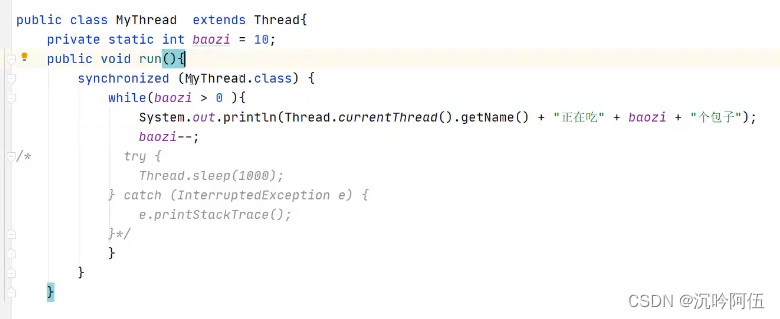
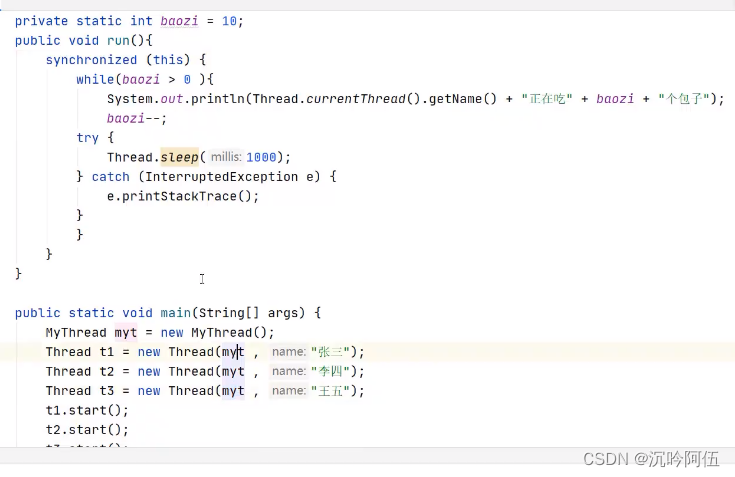
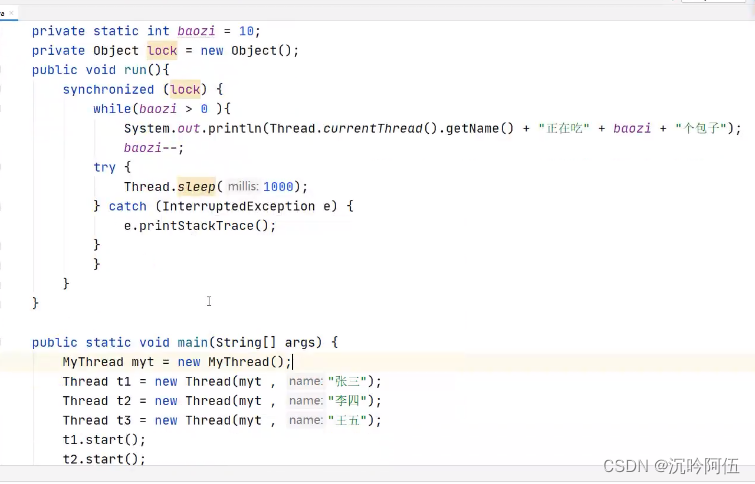
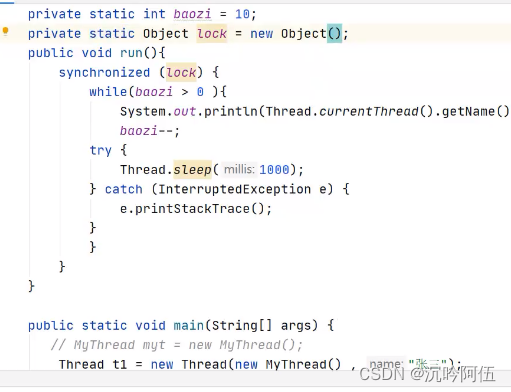
6.死锁的问题
即多线程在执行访问的时候,都需要对方先释放资源才能自己执行导致的问题
死锁如何解决?
(1)尽量不要用相互嵌套锁的方式
(2)可以设置超时时间,但获取锁超过一定的时间让线程释放锁
7.线程的协作
wait() notify() notifyAll() 消费者-生产者 都是Object里的方法(任何对象都可以充当锁)
lock.wait();===> 让当前的线程处在等待状态,把线程挂起来,可以执行其他
lock.notify()===>唤醒锁上的一个线程
lock.notifyAll()===>唤醒锁上的所有线程使其从monitor的等待集合中出来进入就绪状态等待cpu的调用
消费者消费商品,假如商品已经消费完,可以使消费者进入等待状态,
生成者生成商品,当生产出商品后唤醒消费者,当生成到限制的量时候进入等待状态
8.线程池(重点)
(1)为什么使用线程池??
a、由于创建线程和销毁线程都需要耗费cpu和内存的资源,使用线程池提前创建好节约创建和消耗的时间,
使用池 ===》 使用空间换时间,可以重复利用线程池的线程
b、线程池可以控制线程的数量,避免程序员无节制创建线程导致OOM
内存溢出和内存的泄露的区别?
内存溢出: 8g内存,程序大于8g大小, 基于JVM内存控制 StackOverflow 堆栈溢出
内存泄漏: 在使用对象的完成以后没有及时回收导致该块存储空间没有释放给其他对象使用,在开发中尽量避免(了解GC的机制)
(2)java中的线程池 ThreadPoolExecutor类
ThreadPoolExecutor自定义线程池(推荐使用)
-
线程池的参数
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)corePoolSize核心线程数 线程池中创建的核心线程,即使不用也会创建出来maximumPoolSize最大线程数 线程池中能存放的最大线程数量(包括核心线程数和非核心线程数),非核心线程在非必要条件下不会创建出来keepAliveTime非核心线程在闲置下能存货的时间unit存活的时间单位workQueue阻塞队列,当核心线程数被全部使用后,其他的线程会加入到该阻塞队列threadFactory线程工厂,创建线程的工厂类,可以通过这个类创建线程,比如可以通过这个定义线程的名称等handler拒绝策略 当最大线程数满了后,再进入的线程使用什么样的拒绝策略线程池执行的原理
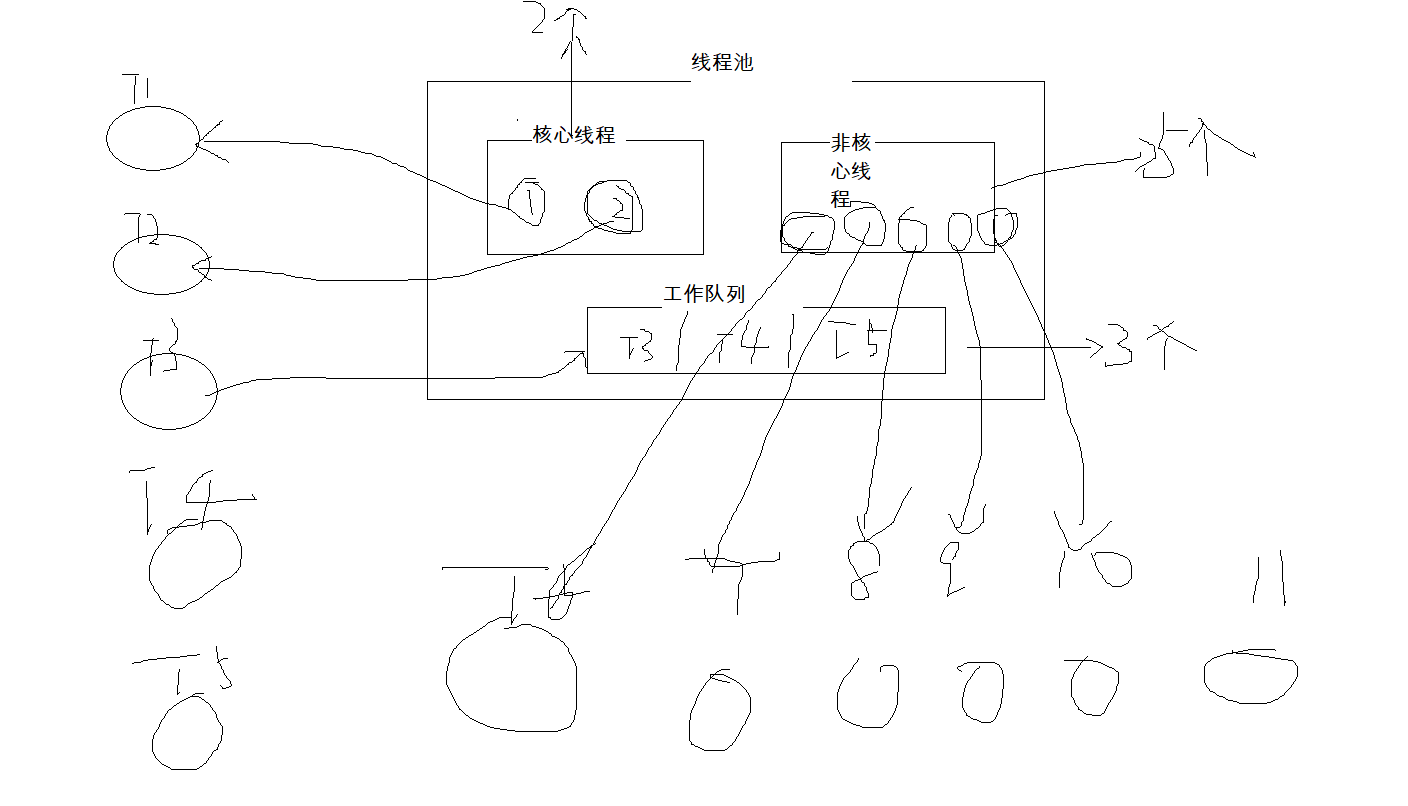
为什么先放入队列而不是创建非核心线程执行?
为了寻求一个空间和时间的一个平衡,最大化利用线程池又不浪费时间和空间
Executors创建的线程池模板
newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, //最大线程数21亿多,可以允许无节制创建非核心线程,导致服务器扛不住
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
newScheduledThreadPool
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE); //定义工作队列的大小,21亿多
}
/**
* Creates a {@code LinkedBlockingQueue} with the given (fixed) capacity.
*
* @param capacity the capacity of this queue
* @throws IllegalArgumentException if {@code capacity} is not greater
* than zero
*/
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()); //队列能接受21亿多线程
}
为什么阿里不推荐大家使用Executors创建的线程池?
newSingleThreadExecutor,newFixedThreadPool存在的问题是不是定义的工作队列太大,正常服务器是无法承担21亿多个线程
newCachedThreadPool是有最大线程数可以是21亿多导致的问题
-
线程的各个参数优化
根据实际情况来设定核心线程数、最大核心线程数,等待时间,工作队列,拒绝策略
阻塞队列
为什么使用阻塞队列BlockingQueue?
阻塞队列自动有阻塞通知功能,当核心线程有空余的时候,阻塞队列会自动获知可以出列交由核心线程执行
SynchronousQueue进和出是同时完成的,该队列无法保存任务线程LinkedBlockingQueue常用的链式阻塞队列,先进先出FIFO,设定大小长度拒绝策略
当核心线程、工作队列、非核心线程都满了以后,再有任务请求线程池中的线程
-
AbortPolicy 拒绝执行,并抛出异常
-
CallerRunsPolicy 不让线程池执行,让调用该任务的调用者线程执行
-
DiscardOldestPolicy 丢弃到工作队列中排在最前边的那个任务,把新任务加入到队列中
-
DiscardPolicy 直接丢弃不执行新任务,没有任何响应
-
-
线程池的生命周期
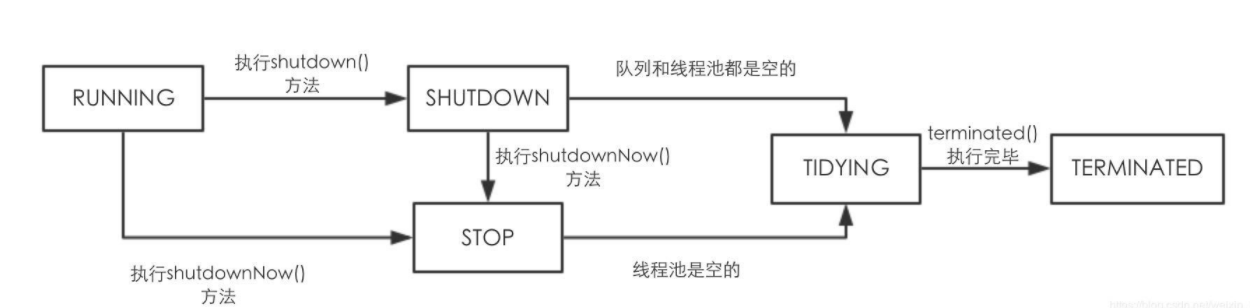
RUNNING: 线程池运行状态
SHUTDOWN: shutdown() 正常关闭,线程池的工作队列,核心线程都能保证正常的处理完毕,不能接受新的线程请求
STOP: shutdownnow() 立即关闭,保证核心线程能正常完成,工作队列中的任务不执行,不能接受新的线程请求
TIDYING: 关闭,现在不能执行任何的线程,做一些后续的保存等工作
TERMINATED: 完全关闭,线程池已经完全关闭
9.了解一些常见的锁的概念
乐观锁和悲观锁
乐观锁: 每次在读取数据的时候都认为其他的人不会去修改该数据,所以不上锁,CAS
悲观锁: 每次读取数据的时候都认为别人会修改数据,所以每次都上锁,其他人都不能访问该数据
公平锁和非公平锁
在多个线程竞争的时候,主要看线程的执行顺序
公平锁: 根据先来后到的方式进行访问,有一定的顺序,轮流访问
非公平锁: 谁抢到的谁用,不一定有固定的顺序 synchronized非公平锁
可重入锁和非重入锁
可重入锁: 当线程获取到锁后可以继续获取该锁,synchronized和ReentrantLock
synchronized(lock1){
---------
synchronized(lock1){ //可以继续获取该锁,可重入锁
}
}
非可重入锁:线程不能重复获取该锁,使用很少
自旋锁和自适应自旋锁
循环判断时候可以获取锁 ReentrantLock tryLock()返回值是boolean代表是否获取到锁实现自旋的效果
偏向锁
在单线程执行的环境下,一直保持这一个线程访问,会记录成偏向锁,锁对象会把线程id记录到对象头中并且把偏向值改为1
轻量级锁和重量级锁
轻量级锁:偏向锁升级,当有另外的线程交替执行时,不存在竞争(2个线程同时抢锁) ,自旋的方式
重量级锁:当出现线程的竞争的时候,object-monitor ,监控锁对象,当一个线程抢到锁后,monitor启动monitorenter和monitorexit指令,当其他线程获取不到锁的时候会进入阻塞状态
独享锁(排他锁)和共享锁
独享锁:一次只能被一个线程持有 ReentrantReadWriteLock里的WriteLock 写锁
共享锁:可以被多个线程共享使用 ReentrantReadWriteLock里的ReadLock 读锁
分段锁
ConcurrentHashMap1.7采用的分段锁,segment
10.volatile关键字(重点)
重点掌握:
volatile关键字作用:
(1)内存可见性
每个线程会有自己的工作内存,多线程环境下,可能会出现工作内存的值与主内存值不一致造成数据安全的问题,可以通过volatile关键字强制保证工作内存的值与主内存保持同步

(2)禁止指令重排
重排序是指编译器和处理器为了优化程序性能而对指令进行排序一种方式。
由于JVM会指令的执行顺序进行优化,所以有可能会造成指令重排,有些时候没有问题,但有些时候可能会产生问题,可以使用volatile进行禁止指令重排
int a = 3;
int b = 4;//可能会产生指令重排
int a = 3;
int b = a;//这一句要依赖上一句,这种情况不会出现指令重排
volatile int a = 1;
boolean status = false;
public void a(){
a = 2;
stutas = true;
}
public void run(){
if(status){
sout(a);
}
}
以上代码没有出现指令重排:
由于status默认值是false,所以不会输出,但status改为true后,a的值已经变为2,输出的结果就是2
指令重排:
由于status先改为true,a的值还没改变,这时候输出结果就是1
stutas = true; a = 2;
假如要求输出的结果就是2,这时候就需要禁止指令重排,如何禁止指令重排,使用到volatile关键字
(3)不具备原子性
volatile int i = 0;//无法使对i的操作具备原子性
public void run(){
i++;//不是一个原子性的操作,可能会造成在多线程场景下会出现数据的异常
//第一步,获取i的值,第二步把i的值+1,第三步把+1后得到值赋值给
}
synchronized关键字可以实现原子性
int i = 0;//无法使对i的操作具备原子性
public void run(){
synchronized(lock){
i++;//不是一个原子性的操作,可能会造成在多线程场景下会出现数据的异常
}
}
另外一种就是通过juc(java.util.concurrent.*)里AtomicInteger 原子类
AtomicInteger i = new AtomicInteger(0);//无法使对i的操作具备原子性
public void run(){
i.getAndIncrease();//类似i++,具备原子性
}
设计模式:
单例singleton模式和多例prototype(原型)模式
工厂就是来生产对象的
原型模式:
public class ToyFactory{
//每次调用的时候都会产生一个新的toy
public static Toy getToy(){
Toy toy = new Toy();
//给toy添加一些初始化的值等
return toy;
}
}
Toy toy1 = ToyFactory.getToy();
Toy toy2 = ToyFactory.getToy();//和toy1不是同一个对象
单例模式:
饿汉式:
public class ToyFactory{
//饿汉式,一开始不管使用不使用getToy(),都会先生成toy对象,立即创建
private static Toy toy = new Toy();
//每次调用的时候都会产生一个新的toy
public static Toy getToy(){
return toy;
}
}
Toy toy1 = ToyFactory.getToy();
Toy toy2 = ToyFactory.getToy();//和toy1是同一个对象,所以叫单例模式
懒汉式:
1.有可能会造成线程安全的问题
public class ToyFactory{
//懒汉式,没有用的时候,不着急创建这个对象,只有在用的时候再创建,延迟创建
private static Toy toy;
//每次调用的时候都会产生一个新的toy
public static Toy getToy(){
if(toy == null){
toy = new Toy();
}
return toy;
}
}
Toy toy1 = ToyFactory.getToy();
Toy toy2 = ToyFactory.getToy();//和toy1是同一个对象,所以叫单例模式
2.双重判断方式(线程安全的问题)
public class ToyFactory{
//懒汉式,没有用的时候,不着急创建这个对象,只有在用的时候再创建,延迟创建
private static Toy toy;
//每次调用的时候都会产生一个新的toy
public static Toy getToy(){
if(toy == null){
synchronized(ToyFactory.class){
if(toy == null){
toy = new Toy();
}
}
}
return toy;
}
}
Toy toy1 = ToyFactory.getToy();
Toy toy2 = ToyFactory.getToy();//和toy1是同一个对象,所以叫单例模式
五、IO输入输出流、XML和网络编程
1.IO流体系
一种分法:
按方向分:
-
输入流 InputStream Reader 从外设读入内存的过程就是输入
-
输出流 OutputStream Writer 把内存中的数据写到外设中过程就是输出
读入写出,都是相对内存(程序执行在内存中)来说
按内容分:
- 字节流 InputStream OutputStream 传输的单位是一个byte一个byte的传,二进制文件视频,音频,图片
- 字符流 Reader Writer 传输的单位是一个char一个char的传(2个byte),文本文件
FileInputStream FileOutputStream ObjectInputStream ObjectOutputStream FileReader PrintWriter BufferedReader等
序列化的概念
序列化的实现很简单,就是实现Serializable这个接口即可
为什么要实现序列化?
网络传输也好,还是内存数据存入硬盘等对象都不能直接传输,必须先转化成二进制数才能进行传输
对象==》二进制数的操作就是 序列化
二进制数==》对象 反序列化
2.XML
(1)XML概念
扩展标记型语言
<?xml version="1.0"?>
<students>
<student>
<name>john</name>
<age>31</age>
</student>
<student>
<name>rose</name>
<age>31</age>
</student>
</students>
xml的主要作用就是存放数据
(2)XML的解析(读数据/写数据)
SAX解析
基于事件触发的方式进行解析,逐行解析,startDocument() startElement()
DOM解析
把文档一次性读入到内存,把xml的各个节点构建一个tree,可以通过遍历tree的方式操作xml
3.网络编程
java.net.* InetAddress URL等
了解Socket编程
网络通信(聊天工具),基于TCP/UDP进行通讯
BIO NIO AIO的区别?
BIO block io 同步阻塞IO
NIO non-block io 同步非阻塞IO
AIO asynchronous io 异步非阻塞IO
同步和异步的区别?
同步:发送一个请求,等待返回后再发送下一个请求,同步可以避免出现死锁,脏读等问题,有执行顺序
异步:发送一个请求,不需要等待返回,直接可以再发送下一个请求,可以提高,保证并发
同步和异步关注点在于消息的通讯机制
阻塞和非阻塞程序再等待调用结果时(消息,返回值)的状态
最后
以上就是着急烧鹅最近收集整理的关于javase高级部分面试知识点总结java高级部分的全部内容,更多相关javase高级部分面试知识点总结java高级部分内容请搜索靠谱客的其他文章。








发表评论 取消回复