一、算法思想
孤立森林是属于无监督学习范畴中检测异常值的一种模型,他不同于其他通过计算距离和密度来识别样本点是否是孤立点,而是通过样本的疏密程度来判断样本的是否孤立。仅适用于连续数据。
孤立森林采用多重二分法将样本点进行分区,该算法将样本中所有样本进行切分,直到每个样本点或极少样本点被划分在同一区域呢,这样样本越密集的区域,区域中的点被孤立时所需要的切分次数就越多,同理样本是孤立点,则该点被孤立时切分的次数就越低。
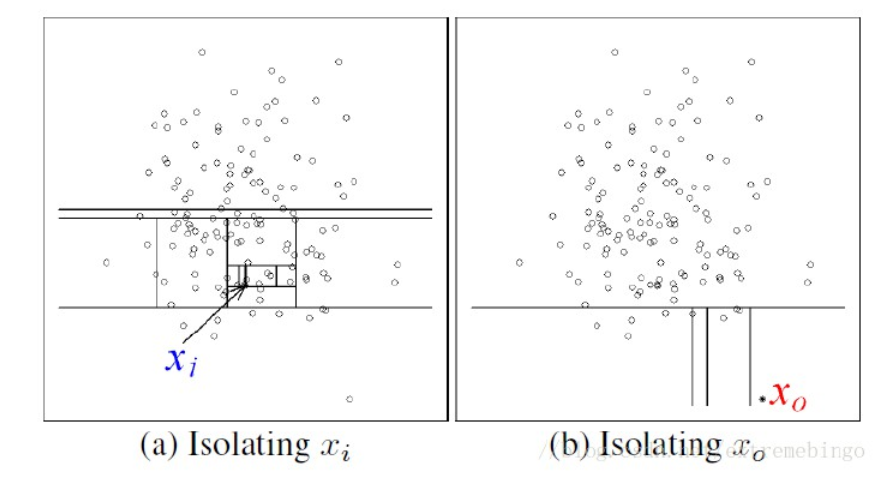
二、模型推理
在已经理解孤立森林算法思想后,如何通过数学公式实现孤立森林模型是我们需要解决的问题,接下来从模型步骤和计算公式、算法伪代码、模型python代码三个方面进一步深入了解掌握模型。
2.1 模型步骤及公式
孤立森林是和随机森林的概念类似,孤立森林是由多颗孤立树构成,先使用测试集训练每颗孤立树,然后再计算验证集每个样本的异常分数值(0,1]判断该样本是否异常,分值越接近1样本越孤立,即样本异常可能性越大。
在创建孤立森林之前,先创建一颗孤立树,孤立树的创建步骤如下:
1.从总体中,随机选择样本容量为n的样本,作为训练孤立树的训练集,也可以用总体;
2.在训练集中随机选择变量Q作为根节点,并随机在Q的取值范围内选择分割点p;
3.将≥p的样本放在左节点,将<p的样本放在右节点;
4.对左右节点的数据重复2、3步骤直到结束,结束的条件是以下三种情况之一:①达到最大限度树的高度;②节点上的样本对应特征的值全相等;③节点只有一个样本;
计算公式:
路径长度:从根节点到叶子节点所经过的边的个数
样本的期望路径长度:E(h(x)),样本在每个孤立树的路径长度的期望
树的平均路径长度:c(x,n),包含n个样本的数据集树的平均路径长度,其中H(i)为调和函数,可以被估值
为
样本的异常得分为,下图给出s和E(h(x))的关系:
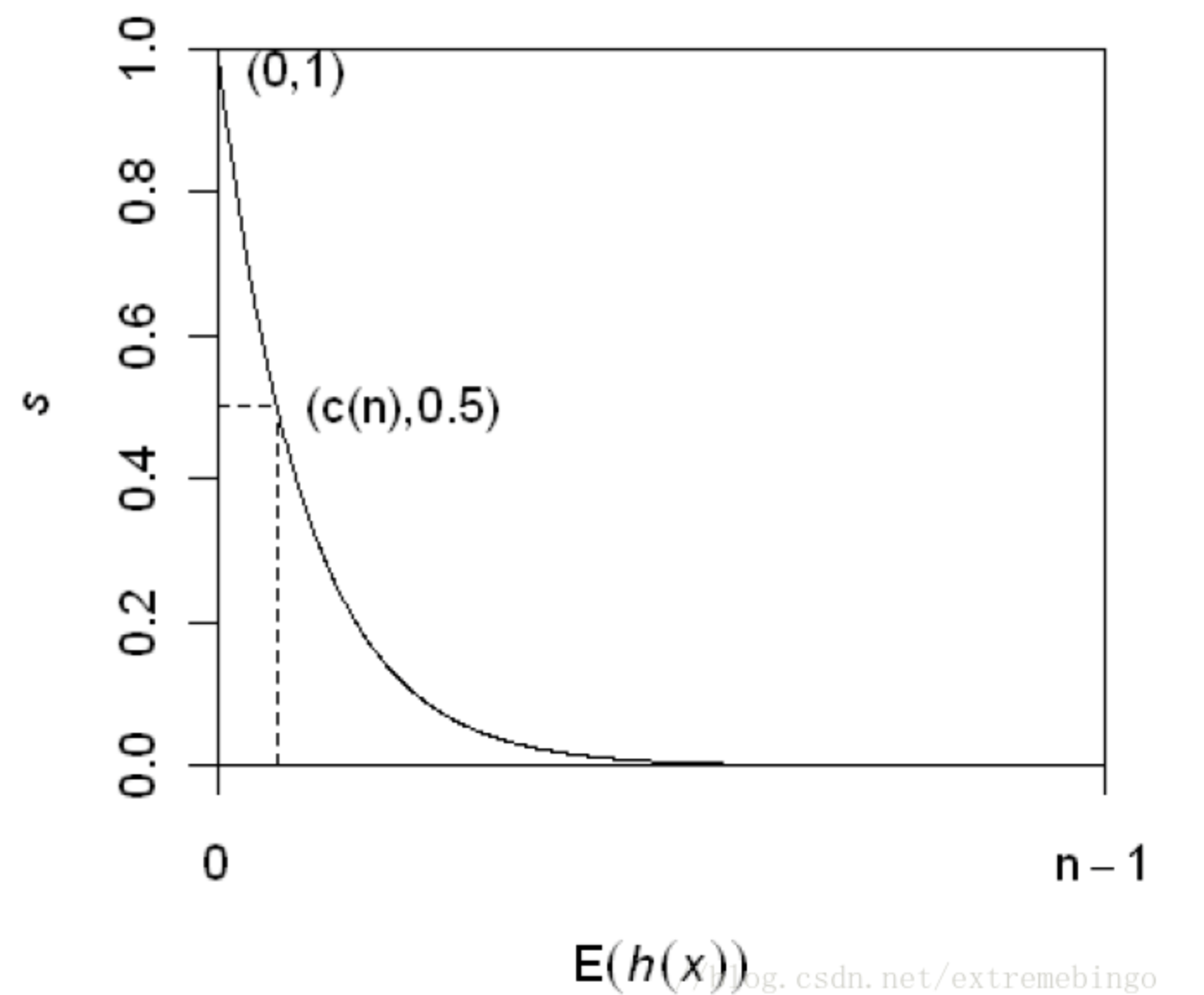
由上图可以得到一些结论:
当E(h(x))→c(n)E(h(x))→c(n)时,s→0.5s→0.5,即样本xx的路径平均长度与树的平均路径长度相近时,则不能区分是不是异常。
当E(h(x))→0E(h(x))→0时,s→1s→1,即xx的异常分数接近1时,被判定为异常。
当E(h(x))→n−1E(h(x))→n−1时,s→0s→0,被判定为正常。
2.2 算法伪代码
孤立树的建立是通过对样本的递归分割 实现的,直到孤立树达到最大高度或者独立样本,树的最大高度与样本数量
的关系是
他近似等于树的平均高度,我们只关心路径长度较小的那些点,他们更有可能是疑似异常点。
训练过程如下:


评估阶段:

2.3 模型python代码
在python中实现孤立森林的包是sklearn中ensemble中的 IsolationForest
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
rng = np.random.RandomState(42)
# 生成训练数据
X = 0.3 * rng.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# 产生一些常规的新观察
X = 0.3 * rng.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# 产生一些异常新奇的观察结果
X_outliers = rng.uniform(low=-4, high=4, size=(20, 2))
# fit the model
clf = IsolationForest(max_samples=100,
random_state=rng, contamination=0.05)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)sklearn.ensemble.iforest中关于孤立森林算法实现的函数及参数含义
IsolationForest(n_estimators=100, max_samples='auto', contamination='legacy', max_features=1.0, bootstrap=False, n_jobs=None, behaviour='old', random_state=None, verbose=0, warm_start=False)
n_estimators:孤立树的个数,默认是100个;
max_samples:从测试集中抽取的样本个数,这些样本会训练每一个孤立树,默认值是“auto”意思是最多的样本数不超过256个
contamination:数据集中异常数据的比例
max_features=1.0:测试集样本中纳入孤立树进行计算的特征个数
bootstrap=False:是否有放回取样,false是无放回取样,true是独立树从测试集中有放回取样
三、模型优缺点
孤立森林算法内存要求低,处理速度快,时间复杂度是线性的,可以处理高维数据和大数据,可以进行在线预测;
即能发现群异常数据,也能发现散点异常数据,也能处理训练数据中不包含异常数据的情况;
附:为什么采用子样本
1.数据量太大会出现swamping和masking两个问题,swamping是将正确样本预测为异常,masking是将错误样本预测为正常。
2.样本量过多会影响模型孤立异常点的能力,正常样本会干扰异常点的隔离过程,降低隔离异常点的能力,而小数据集较好。
3.孤立树的独有特点使孤立森林能够通过子采样建立局部模型,建设swamping和masking对模型效果的影响。
4.子采样可以控制每颗孤立树的数据量,每颗孤立树可以用来识别特定的子样本。
最后
以上就是潇洒大雁最近收集整理的关于孤立森林算法思想及代码实现一、算法思想二、模型推理三、模型优缺点的全部内容,更多相关孤立森林算法思想及代码实现一、算法思想二、模型推理三、模型优缺点内容请搜索靠谱客的其他文章。








发表评论 取消回复