BigKey 的弊端
BigKey 需要解决,根源就在于 BigKey 会带来的问题。
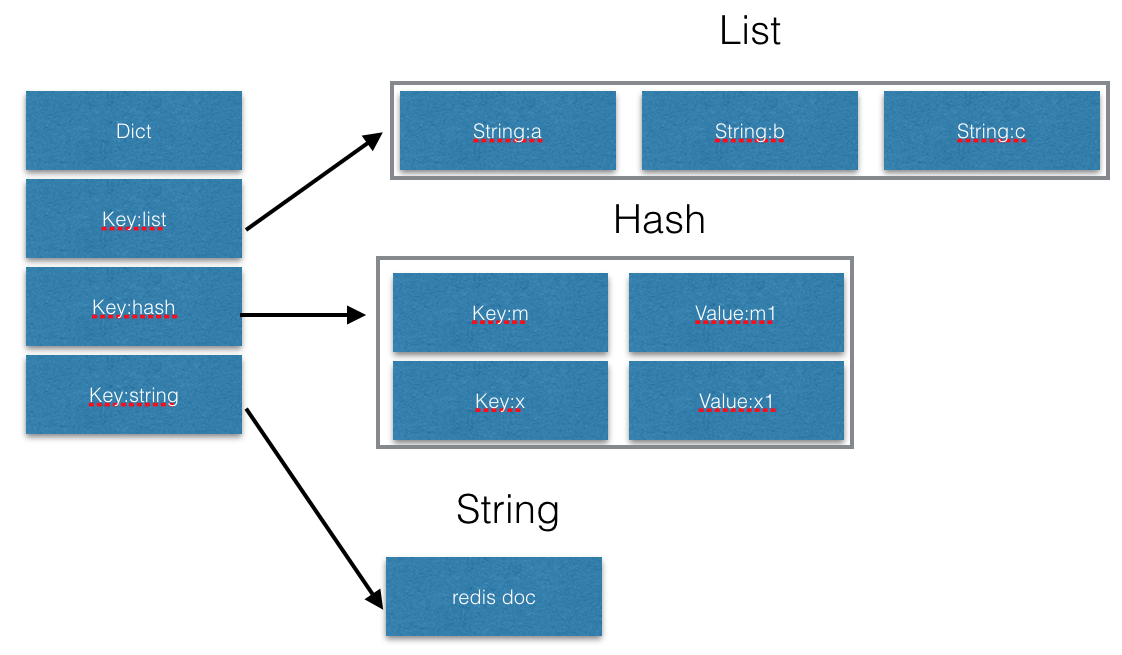
占用内存
因为 Redis 数据结构的底层数据结构,大 Key 会占用更多的内存空间,造成更大的内存消耗。
单线程模型
因为 Redis 的通信依赖于 Socket 连接,Redis 将服务器对 Socket 的操作抽象为文件事件,服务端与客户端的通信会产生文件事件。
Redis 通过单线程,并通过 I/O 多路复用来处理来自客户端的多个连接请求,当产生连接后,将 Socket 放入队列,并通过事件分派器来选择相应的处理程序。服务端通过监听这些事件,并完成相应的处理。
Redis 基于反应器模型(Reactor Pattern)开发了网络事件处理器,并称之为文件事件处理器。文件事件处理器使用 I/O 多路复用来同时监听多个 Socket 套接字,并根据不同的套接字所执行的任务选择相应的事件处理器。被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作,与操作相关的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
I/O 多路复用监听多个套接字,并向文件事件分派器分派产生事件的套接字。如果有多个文件事件,I/O 多路复用程序会将所有产生事件的套接字放到一个队列里,并通过有序、同步、一次一个套接字的方式向文件事件分派器传送套接字。当上一个套接字的事件被处理完毕后,I/O 多路复用才会向文件分派器传送下一个套接字。文件事件分派器接受到 I/O 多路复用程序分派的套接字后,根据套接字类型选择相应的事件处理器。服务器根据套接字类型的不同,关联不同的事件处理器,即发生某事件后,该执行哪些操作。
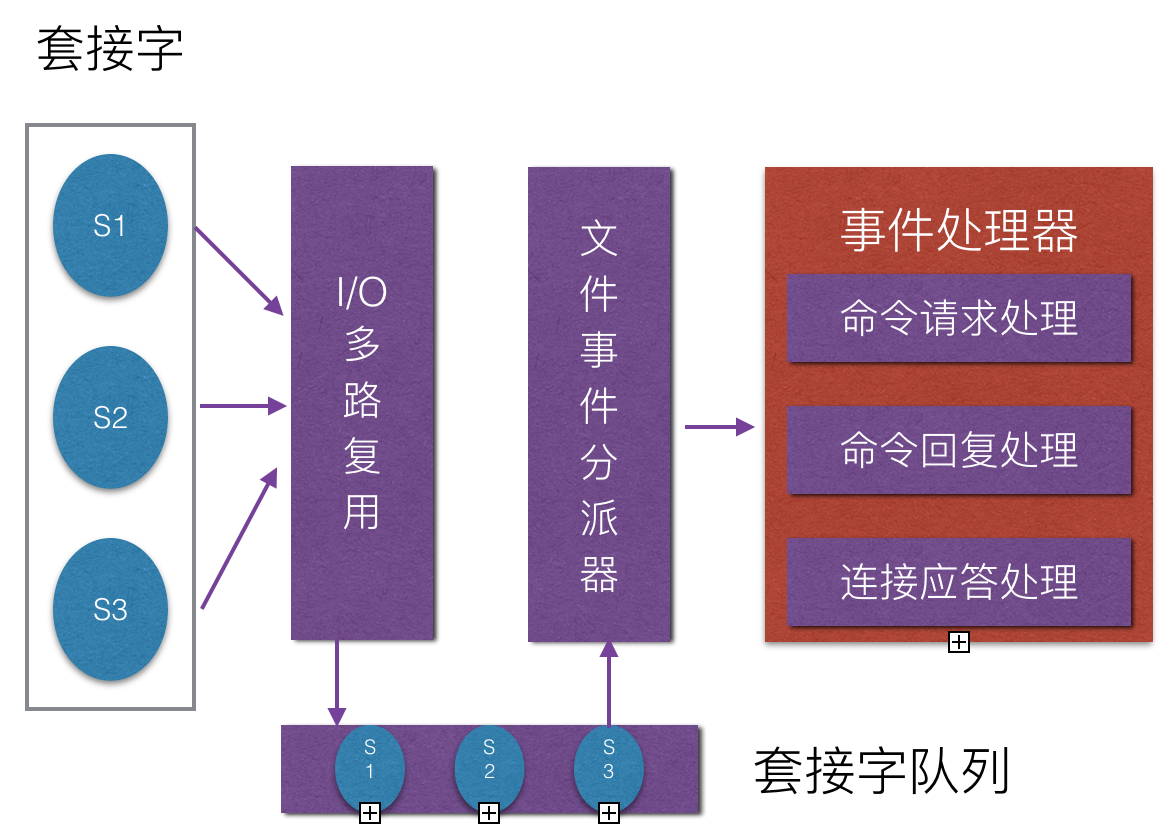
- 客户端连接请求交由 I/O 多路复用程序进行处理;
- 将 Socket 操作抽象为文件事件,放入 Socket 队列;
- 文件事件分派器将 Socket 队列取出,交给对应的事件处理器进行处理。
因为大 Key 的存在,所以在产生对应的 Socket 时,就会占用非常大的内存,影响网络 I/O 的效率,降低整个处理链路的效率。
参考文档:https://blog.csdn.net/Revivedsun/article/details/100006458
执行指令 bigkeys
在 redis 6.0 版本中,我们可以使用提供的--bigkeys参数得到各个数据类型占用空间最大的 Key。
在 docker 中,我们可以执行指令:
docker exec -it redis redis-cli -p 6379 --bigkeys
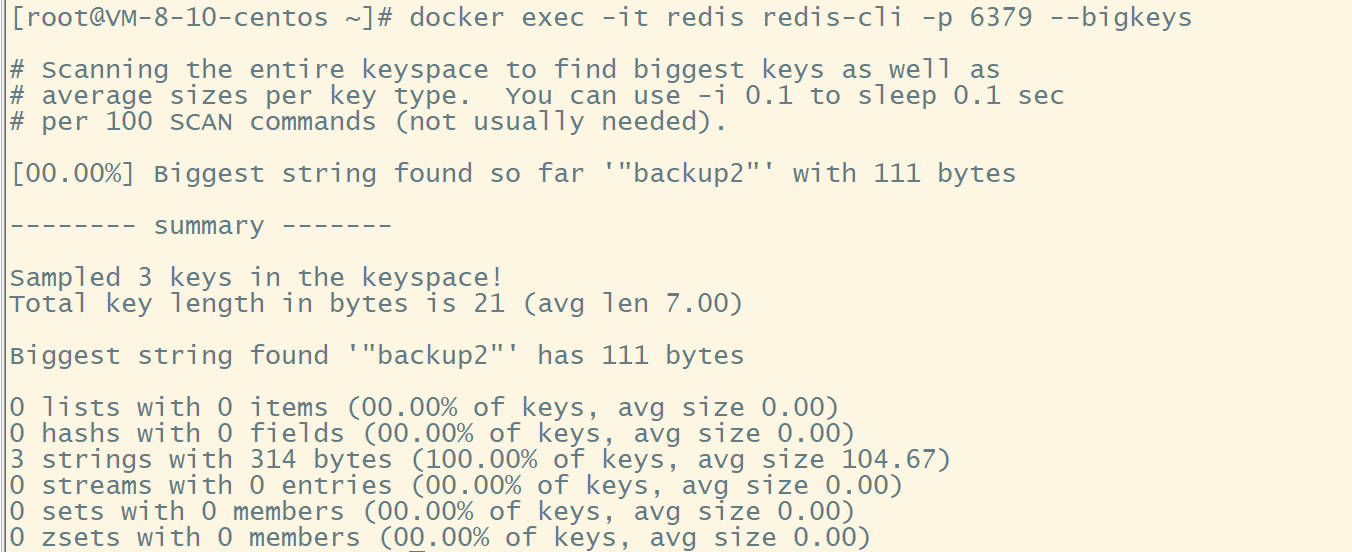
如果说存在大 Key ,我们可以得到:
# redis-cli -p 6379 --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28057c20"' with 4437 bytes
[00.00%] Biggest list found so far '"my-list"' with 17 items
-------- summary -------
Sampled 5 keys in the keyspace!
Total key length in bytes is 264 (avg len 52.80)
Biggest list found '"my-list"' has 17 items
Biggest string found '"my-string"' has 4437 bytes
1 lists with 17 items (20.00% of keys, avg size 17.00)
0 hashs with 0 fields (00.00% of keys, avg size 0.00)
4 strings with 4831 bytes (80.00% of keys, avg size 1207.75)
0 streams with 0 entries (00.00% of keys, avg size 0.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
0 zsets with 0 members (00.00% of keys, avg size 0.00
查看上述的打印结果,我们可以知道该命令只能得到每种数据类型的 Top 1 空间占用的 Key ,所以这个命令存在一定的局限性。而且,该命令会执行 Scan 扫描所有的 Key 空间去寻找最大的 Key ,会对 redis 的性能具有一定影响。
debug指令
除了 --bigkey 参数之外,还有一个参数也可以执行 Key 的分析。
DEBUG OBJECT <KeyName>
# 示例
redis> DEBUG OBJECT my_pc
Value at:0xb6838d20 refcount:1 encoding:raw serializedlength:9 lru:283790 lru_seconds_idle:150
redis> DEBUG OBJECT your_mac
(error) ERR no such key
Debug Object 命令是一个调试命令,它不应被客户端所使用。当 key 存在时,返回有关信息。 当 key 不存在时,返回一个错误。
其中 serializedlength 的值为该 Key 的序列化长度。但是 Key 的序列化长度并不等同于它在内存空间中的真实长度。此外 debug object 属于调试命令,运行代价较大,并且在其运行时,进入 Redis 的其余请求将会被阻塞直到其执行完毕,且每次只能查找单个 key 的信息,官方不推荐使用。
该指令用于分析,主要有以下的特点:
① 分析与实际存在差异,内存和序列化结果不一致;
② 运行指令代价比较大;
③ 运行时阻塞。
参考文档:http://redisdoc.com/debug/debug_object.html
https://blog.csdn.net/Weixiaohuai/article/details/125391957
分析 RDB 文件
通过分析 RDB 文件来找出 big key。前提是 Redis 采用的是 RDB 持久化方式。
网上有现成的代码/工具可以直接拿来使用:
- redis-rdb-tools :Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具。
- rdb_bigkeys : Go 语言写的用来分析 Redis 的 RDB 快照文件用的工具,性能更好。
对于线上生产环境,如果需要分析一段时间内的大 Key ,同时采用的并不是 RDB 持久化方式,我们在条件允许的环境下,可以采取以下的步骤进行:
- 导出 AOF 文件,在备份机器上执行复原;
- 在机器上使用 save 指令获得 RDB 文件;
- 使用工具分析 RDB 文件。
事实上到这一步,只是解决了 BigKey 的排查问题。但是真正需要解决大 Key ,要依赖一些其他的手段。
BigKey解决/减少内存占用
对于 BigKey ,无非就是减小 key 对应的 value 值的大小,也就是对于 String 数据结构的话,减少存储的字符串的长度;对于 List、Hash、Set、ZSet 数据结构则是减少集合中元素的个数。
拆分集合类元素
如果针对集合类数据结构,例如 List、Hash、Set、ZSet 数据结构,我们需要减少其中元素的个数。以 List 为例,具体做法:
- 原 List 的 Key 非常大,我们拆分为 5 个小的 Key;
- 先计算 Key 的哈希值,利用 hash(原key)%5 得到目标的 Key 处于 5 个小 Key 中的哪一个 Key。
这只是简单的拆分,基本思想遵循拆分元素个数解决。
异步删除大Key
参考文档:https://www.modb.pro/db/390777
对于大 key ,我们可以执行删除操作。删除操作主要依赖于异步操作指令:
unlink <keyName>
为什么不使用 del 指令而是使用 unlink 指令?
- del 指令在删除 key 的时候会阻塞主线程;
- unlink 指令属于异步操作,在执行的时候只会在主线程执行一些判断和其他操作,并不会造成长时间的主线程阻塞;
- unlink 不建议用来删除比较小的 Key ,可能会出现在主线程执行判断和其他操作的成本远大于 del 指令的情况出现。
监控 Redis 的内存
可以通过给 Redis 设置最大内存的方式,保持机器的 redis 内存占用维持在一个水平线以下。一旦即将超过最大内存限制,将会触发内存淘汰策略。
config set maxmemory 1G
config rewrite
此外,监控 Redis 还可以通过一些第三方软件来完成,比如 Application Manager 等。在现在流行的云服务厂商,也会提供有高级的配套监控服务。
我们可以自己利用内存监控,设置合理的 Redis 内存报警阈值来提醒我们此时可能有大 Key 正在产生,如:Redis 的内存使用率、内存固定时间内增长率等。
参考文档:https://zhuanlan.zhihu.com/p/476713841
https://www.jianshu.com/p/4917f733a239
定期清理失效数据
如果部分 Key 有业务不断以增量方式写入大量的数据,并且忽略了时效性,这样会导致大量的失效数据堆积。可以通过定时任务的方式,对失效数据进行清理。
定时清理失效数据,也可以降低 redis 的内存使用。
压缩 Value 数据
使用序列化、压缩算法将 Key 的大小控制在合理范围内,但是需要注意,序列化、反序列化都会带来一定的消耗。如果压缩后,value 还是很大,那么可以进一步对 key 进行拆分。
减少相同 Key 存储
对于相同元素的 Key 值,我们可以将多个非常小的 Key 进行整合,使用适当的数据结构进行存储,可以减少相同的 Key 前缀的空间占用。
user.name = michael;
user.age=20
user.id=1840800
# 可以使用 hash 进行改造
Key: user:1840800
Value: user Object
最后
以上就是温柔黑猫最近收集整理的关于【中间件】Redis如何解决BigKey的全部内容,更多相关【中间件】Redis如何解决BigKey内容请搜索靠谱客的其他文章。







![[swift]4.0原生字符串](https://www.shuijiaxian.com/files_image/reation/bcimg15.png)
发表评论 取消回复