前言
Paxos、Zab、Raft都属于在分布式环境保持数据一致性的相关算法。
对于这三个算法,初次接触的时候有很多疑惑的地方:
1. 这3个算法的实现是什么,复杂么
2. 为什么要存在这么多算法,一个不能解决么,都用在什么场景。
算法本身不太复杂,但是应用在实际场景中解决问题,开发起来还是比较复杂的。
下面尽可能简单易懂的进行描述。
Paxos
paxos算法是在不会出现拜占庭错误的环境下达成一致性协议的解决方案。
p.s. 分布式环境都是通过网络通讯,系统中的成员可能出错而发送错误的信息,用于传递信息的通讯网络也可能导致信息损坏,传输或响应的信息有误算是拜占庭错误,而非拜占庭错误就是说信息不会在传输过程中遭到篡改。
详细了解,查看:拜占庭将军问题
角色
paxos在分布式环境中存在多个节点,节点的角色如下:
- Client 在分布式系统中发送一个请求并等待响应,比如写一条数据的请求
- Proposer 发送prepare和accept请求,对于client发送的请求希望Acceptor能同意
- Acceptor 处理prepare和accept请求,就是对发送的请求进行投票
- Learner 对于上面的请求,获取paxos算法的结果
- Leader Paxos集群中选出唯一一个节点作为leader处理提议
Acceptor是对请求进行投票的,那在分布式环境中作为Acceptor的大部分节点都应当是存活的,来保证多票当选(同zab或raft的投票选举来理解)。
并不是一个节点只能作为一个角色,paxos实现的集群,每一个节点应该包含Proposer、Acceptor、Learner三种角色,可以处理Client请求并进行投票最终响应。
Paxos的实现也是不同的,比如Basic Paxos和Multi-Paxos,本文主要以基本实现进行说明。
算法
paxos算法实现分为两个阶段,通信过程中数据结构可以简化为(n, v)表示。
n表示一个提案号,v是与该提案号对应的值。
e.g. client要写入一条数据,Proposer提出一个提案号给集群中其它的Acceptor,如果有Quorum(可以认为是半数以上)的Acceptor同意这个提案,那么这个提案号对应的数据v就可以被写入。
这两个阶段如下:
阶段1a:Proposer发出一条“Prepare"消息,带着提案号n,发给Acceptor(包括它自身)
阶段1b:Acceptor收到Proposer的Prapare消息后,看一下这个提案号和之前收到的提案号相比,如果比之前的都大就同意(发一条Propose消息给Proposer),不是就忽略或表示拒绝
阶段2a:Proposer收到Qururm数量的Acceptor的Propose消息,说明都同意这个提案,就发送一个Accept(n,v)消息给这些Acceptor(带着提案号和该提案号对应的数据)
阶段2b:收到Proposer的Accept消息的Acceptor就把这个数据写入。
这样就算达成一个共识,如果上面提案最终失败,其实会重新开始新一轮提案。
下面这个流程图来自Paxos的wiki,可以看一下帮助理解下这个过程:
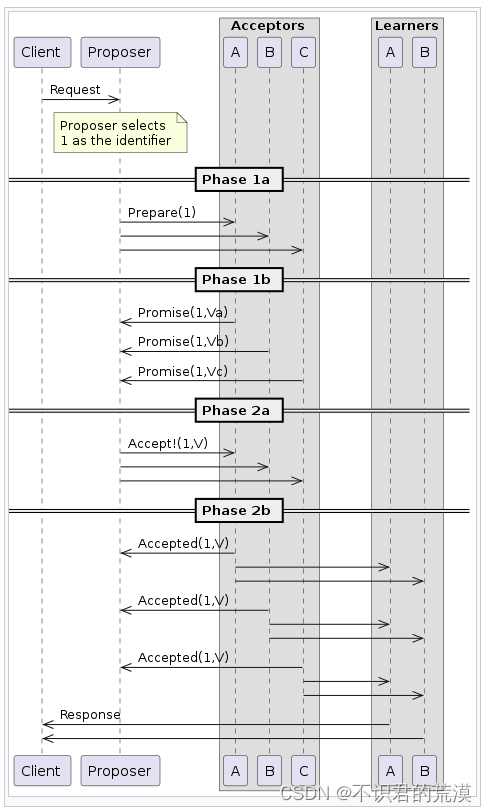
图片来源
注意,上面这个基本的paxos实现包括两个阶段会涉及很多消息交换,Multi-Paxos 实现会选举一个leader,只需要第2阶段即可确定一个值。
Paxos的实现案例 chubby:https://courses.cs.washington.edu/courses/csep552/13sp/lectures/5/chubby.pdf
Raft
目前使用相当广泛的一个一致性算法,比如ETCD,Consul,kafka,rocketmq的dledger都有用到。
p.s. 我在wiki搜索的搜索的搜到的是一款游戏
目前我实际接触到的都是leader选举、日志复制的解决方案。
角色
一个raft集群有若干个节点,角色如下:
- Leader 只有一个(比如kafka的分区、rocketmq的主节点(dledger),接受客户端的请求
- Follower 接受leader的写请求(数据同步过来)
- Candidate 在选举leader时的这些follower
比如我们说kafka消息主从复制就是说Leader和Follower。
对于Raft的快速理解,推荐一个网站(新手都容易看懂):Raft
算法
以实际项目来举例,其实很简单,以rocketmq dledger来说明。
日志复制
p.s. 不以kafka示例,有两个原因,一个是kafka的ack数量可以配置,写入一条消息的可以配置ack数量算是成功。rocketmq dledger如是1主2从,只要有一个从节点写入成功(集群中一主一从2个节点已经写入,超过半数节点)便可以认为成功写入,更容易理解。第二个原因,是我本地刚好有一版rocketmq的源码。
代码版本是4.9.1
DLedgerCommitLog:DLedgerCommitLog
BatchAppendEntryRequest request = new BatchAppendEntryRequest();
request.setGroup(dLedgerConfig.getGroup());
request.setRemoteId(dLedgerServer.getMemberState().getSelfId());
request.setBatchMsgs(encodeResult.batchData);
// 写入消息
dledgerFuture = (BatchAppendFuture<AppendEntryResponse>) dLedgerServer.handleAppend(request);看handleAppend()方法:dledger/DLedgerServer.java at master · openmessaging/dledger · GitHub
看方法注释:
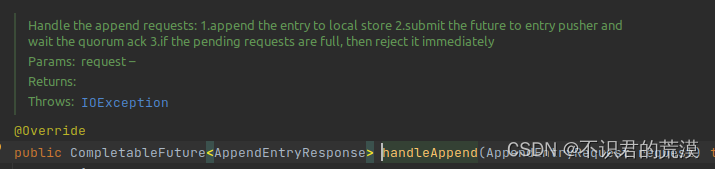
关键是第2步,等待Quorum节点的ack.
DLedgerEntry dLedgerEntry = new DLedgerEntry();
dLedgerEntry.setBody(request.getBody());
DLedgerEntry resEntry = dLedgerStore.appendAsLeader(dLedgerEntry);
return dLedgerEntryPusher.waitAck(resEntry, false);基本流程就是客户端生产者发送一条消息到主节点,主节点发送给从节点,等待其中部分从节点写入成功返回ack,主节点响应客户端消息提交成功。
选举
关于ledaer选举主要在:DLedgerLeaderElector
通过心跳维护leader和follower之间的关系:
/**
* The core method of maintainer. Run the specified logic according to the current role: candidate => propose a
* vote. leader => send heartbeats to followers, and step down to candidate when quorum followers do not respond.
* follower => accept heartbeats, and change to candidate when no heartbeat from leader.
*
* @throws Exception
*/
private void maintainState() throws Exception {
if (memberState.isLeader()) {
maintainAsLeader();
} else if (memberState.isFollower()) {
maintainAsFollower();
} else {
maintainAsCandidate();
}
}
private void maintainAsLeader() throws Exception {
if (DLedgerUtils.elapsed(lastSendHeartBeatTime) > heartBeatTimeIntervalMs) {
long term;
String leaderId;
synchronized (memberState) {
if (!memberState.isLeader()) {
//stop sending
return;
}
term = memberState.currTerm();
leaderId = memberState.getLeaderId();
lastSendHeartBeatTime = System.currentTimeMillis();
}
sendHeartbeats(term, leaderId);
}
}
private void maintainAsFollower() {
if (DLedgerUtils.elapsed(lastLeaderHeartBeatTime) > 2 * heartBeatTimeIntervalMs) {
synchronized (memberState) {
if (memberState.isFollower() && (DLedgerUtils.elapsed(lastLeaderHeartBeatTime) > maxHeartBeatLeak * heartBeatTimeIntervalMs)) {
logger.info("[{}][HeartBeatTimeOut] lastLeaderHeartBeatTime: {} heartBeatTimeIntervalMs: {} lastLeader={}", memberState.getSelfId(), new Timestamp(lastLeaderHeartBeatTime), heartBeatTimeIntervalMs, memberState.getLeaderId());
changeRoleToCandidate(memberState.currTerm());
}
}
}
}超过2个心跳的超时,follower就会进入candidate重新选举。
看下这段代码,作为不同的角色在实现会有不同的行为:
/**
* The core method of maintainer. Run the specified logic according to the current role: candidate => propose a
* vote. leader => send heartbeats to followers, and step down to candidate when quorum followers do not respond.
* follower => accept heartbeats, and change to candidate when no heartbeat from leader.
*
* @throws Exception
*/
private void maintainState() throws Exception {
if (memberState.isLeader()) {
maintainAsLeader();
} else if (memberState.isFollower()) {
maintainAsFollower();
} else {
maintainAsCandidate();
}
}成为candidate 候选者的时候,就会投票选举leader,实现就在maintainAsCandidate()方法:
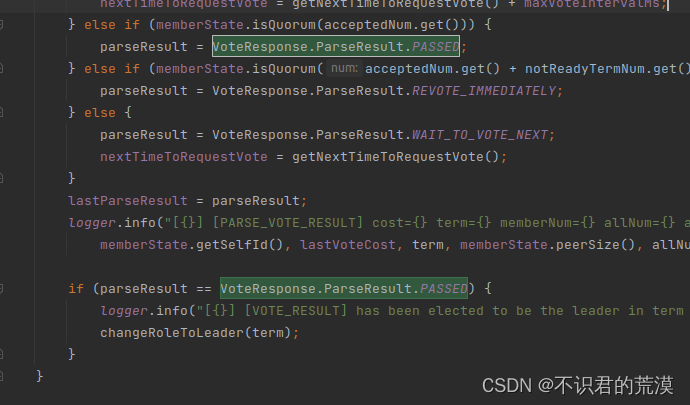
同意票数超过Quorum数量,就是投票通过,选举为leader。
raft的应用正如上面说的,比较多了:kafka, rocketmq dledger, etcd...
Zab
Zab的全称是Zookeeper Atomic Broadcast协议,听名字好像是专用于zookeeper的协议,目前我主要了解到的也是在zookeeper上的应用。
p.s. zab的读法,我目前听到过两个版本(zai bi)或者(za bi),至于哪个标准我也不知道。
zab是相对来说是属于非常强一致的协议了(zookeeper不算是最强一致性,业内好像是还有比zk更强一致性的实现)。CAP理论,如果有了解应该听说个,zookeeper是CP,集群中必须半数以上节点存在才可用,牺牲可用性来满足一致性。
下面以zookeeper来说明。
角色
- Leader 集群通过投票选举出来的唯一节点,主要接受客户端对集群的写请求
- Follower 参与投票选举leader,当客户端发起写请求的时候,处理leader的Proposal,leader在收到超过Quorum(大多数节点,zk是半数节点)的follower的accept的ack后,ledaer才会提交这条消息。follower其实跟leader保持数据同步。
在zookeeper中还个observer的节点角色,但是这个并参与选举和事务提交,所以在zab协议中不再提现。zookeeper的observer只是集群读性能的一种优化。
p.s. zookeeper集群的所有类型的节点都可以处理读请求,但是写请求都是转发给leader处理。
算法
在zab中事务提交时的数据同步术语好像不像是raft的复制而broadcast,我这里就叫做广播了。
在zab中有个zxid是一个自增值,叫做事务id,每次一条写请求可以看做是一个事务。
广播
- 客户端发一起提条数据更新的请求
- leader进行处理,发送 PROPOSE(zxid, data)(带着zxid和更新的数据)请求包给所有连接的follower
- follower收到请求会将数据同步到本地,然后返回一个ACK(zxid)数据包给leader
- leader收到quorum(超过半数)的节点的ack就发送一个提交请求COMMIT(zxid) 给所有的follower
- 响应客户端
选举
直接拿zookeeper的源码进行说明。源码在:zookeeper/FastLeaderElection.java at master · apache/zookeeper · GitHub
zookeeper投票的主要数据是(epoch,zxid,sid),epoch是zookeeper的选举轮次,这个数据会备份到数据目录下的一个文件(哪个目录下,具体我也记不清了);zxid就是上文提到的事务id,在数据目录下增量文件的名,sid是集群配置的server id,在配置文件中。
zookeeper的follower发起投票选举,如果谁收获大多数(Querum)的票就当选leader。
if (voteSet.hasAllQuorums()) {
// Verify if there is any change in the proposed leader
// 获得多数投票的时候还是等一会,看这期间是否会收到新的投票不
// 因为可能有一些更符合leader条件的节点由于网络的原因,投票的请求传输慢了,其它节点收到的晚了
while ((n = recvqueue.poll(finalizeWait, TimeUnit.MILLISECONDS)) != null) {
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
recvqueue.put(n);
break;
}
}
/*
* This predicate is true once we don't read any new
* relevant message from the reception queue
*/
if (n == null) {
setPeerState(proposedLeader, voteSet);
Vote endVote = new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}对当前收到的投票是否有效的判断逻辑,在totalOrderPredicate方法:
return ((newEpoch > curEpoch)
|| ((newEpoch == curEpoch)
&& ((newZxid > curZxid)
|| ((newZxid == curZxid)
&& (newId > curId)))));如果一个follower收到的票比自己的更有效(上面这个判断),设置这个票为自己的投票并重新投出去。
在选举出leader后,跟follower有一个数据同步的动作。具体说明感兴趣可以看一下:Zab1.0 - Apache ZooKeeper - Apache Software Foundation
总结
在raft之前,paxos使用的比较多。
基本的paxos,对于一次数据更新请求,集群各个节点可能要进行多轮消息交换,而raft因为必须要选择一个leader,通过leader只需要一轮消息交换。
raft论文描述了一个基于raft复制状态机的完整方案,paxos论文只给了一个一致性算法。
目前业内使用比较广泛的是raft。
zab协议是为zookeeper专门设计的支持崩溃恢复的原子广播协议,目前主要了解到的也是在zookeeper上的应用和实现。
最后
以上就是野性往事最近收集整理的关于快速理清Paxos、Zab、Raft协议前言PaxosRaftZab总结的全部内容,更多相关快速理清Paxos、Zab、Raft协议前言PaxosRaftZab总结内容请搜索靠谱客的其他文章。








发表评论 取消回复