文章目录
- 1.CMOS基本逻辑电路
- 2.异或逻辑
- 3.卡罗图简化函数
- 4.二进制,格雷码互转
- 5.产生锁存器latch
- 6.异步复位同步释放
- 7.SRAM,FALSHMEMORY,DRAM,SSRAM及SDRAM的区别?
- 8 如何防止亚稳态
- 9.奇数,偶数,任意分频
- 任意偶数分频:
- 任意奇数分频占空比(50%)
- 10.FIFO
- 十进制转格雷码
- 11.快时钟域脉冲信号到到慢时钟域信号
- 11.1脉冲同步
- 11.2电平同步
- 12.i++,i--,++i,--i
- *p++,*++P,++*p
- 13.BUCK电路
- 14.数字IC设计流程
- 15.为什么使用独热码,并不使用二进制编码或者格雷码
- 1.1编码方式也能降低功耗,比如格雷码每次只变化1bit,就比二进制编码降低了功耗。
- 16 RAM和ROM
- SDRAM / SRAM
- 17.&和&&
- 18.状态机
- 19.竞争与冒险
- 20.同步电路和异步电路
- 21.同步复位和异步复位
- 22.全加器和半加器
- 23.任务和函数
- 24.线性移位寄存器
- 25.CMOS实现Y=AB+C电路与版图
- 26.二四译码器
- 27.任意分频
- 28.静态时序分析
- 28.1中心对齐模式
- 28.2边沿对齐模式
- 28.3异步时钟,跨时钟域处理
- 29.异步双口RAM和同步双口RAM
- 30.阻塞赋值与function函数
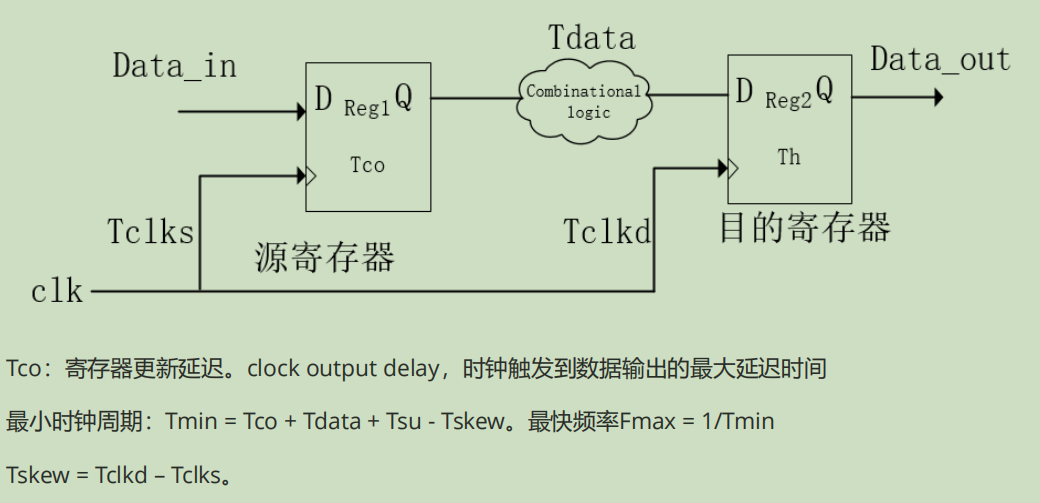
- 31.Tmin计算,即最大频率计算
- 32.FPGA底层知识
- 1.FPGA组成
- 2.MMCM,PLL
- 3. Bram,Dram
- 32.项目芯片型号以及资源使用情况
- 项目一:
- 项目二
- 项目三
- 33.静态功耗和动态功耗
- 34.Tsetup/Tholdup
- 1.clock jitter:
- 2.clock skew:
- 3.时序为例
- 35.前端设计的流程,每个流程是干什么的?
- 1.STA(StaticTiming Analysis, STA)静态时序分析,
- 2.formal形式验证:
- 3.DFT
- 36.请描述跨时钟域设计时会出现的问题及解决办法
- 37.一个16bit序列,每个clk左移一位,要求检测5的倍数。
- 38.负数的表示方法
- 39.initial串 / fork jion并
- 40.二态和四态变量
- 41. Verilog
- 1.描述语言4个层次
- 2. verilog 中缺省的数据类型为?
- 42.基本数据类型的存储空间长度排序为
- 43.补码二进制转十进制
- 44. 操作系统:
- 45. timescale
- 46.串行总线
- 47.大小端模式
- 48.缩写全称
- 49.Memory hierarchy (存储结构)
- 1.当前计算机一般都采用高速缓存-主存-辅存三级存储器结构
- 50.二值逻辑和四值逻辑
- 51.芯片参数
- 52.时钟抖动(jitter) 和时钟偏斜(skew)
- 53.DCM/PLL/DLL/MMCM
- 54.理解FPGA中的RAM、ROM和CAM;ROM、RAM、DRAM、SRAM、FLASH
- 55. 与非门、或非门可以表达任何逻辑表达式
- 56.锁存器(latch)和触发器(filp-flop)的概念和区别?为什么多用register。行为级描述中latch如何产生的?
- 57.时序分析案例
- 58.跨时钟域处理
- 59.outsatanding/out-of-order/interleaving
- 60.axi3和axi4的区别
- 1.burst length
- 2.增加QoS(quality of service)
- 3.增加Multiple region interface
- 4. 修改了write response dependencies
- 5.AWCACHE/ARCHACHE的修改
- 6.Removal of WID
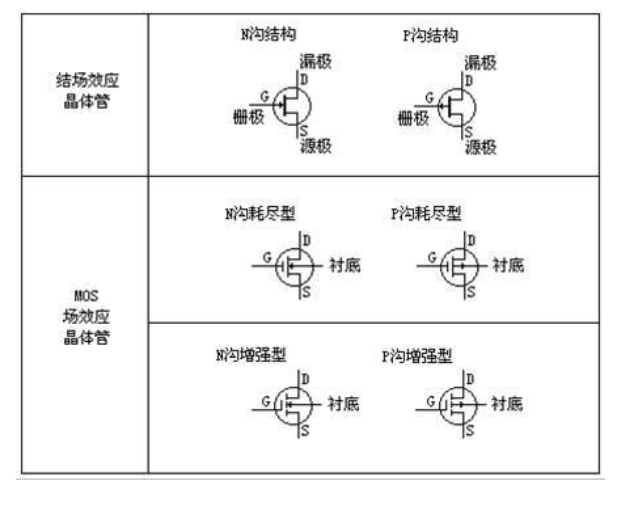
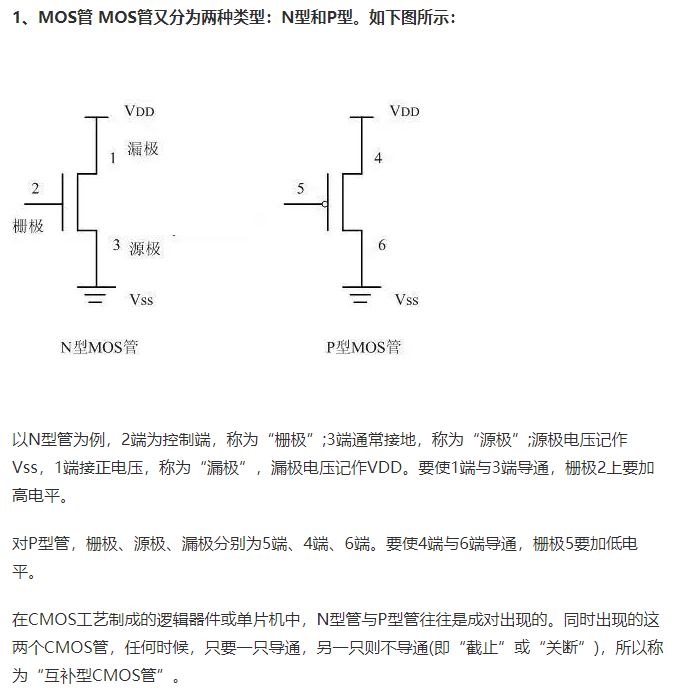
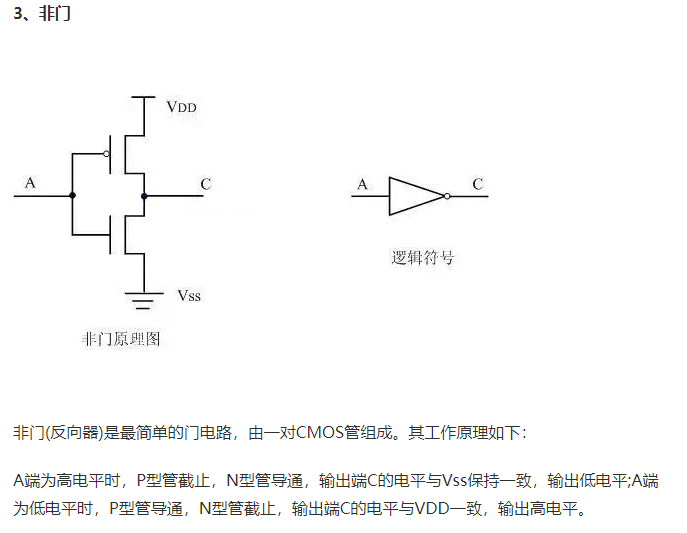
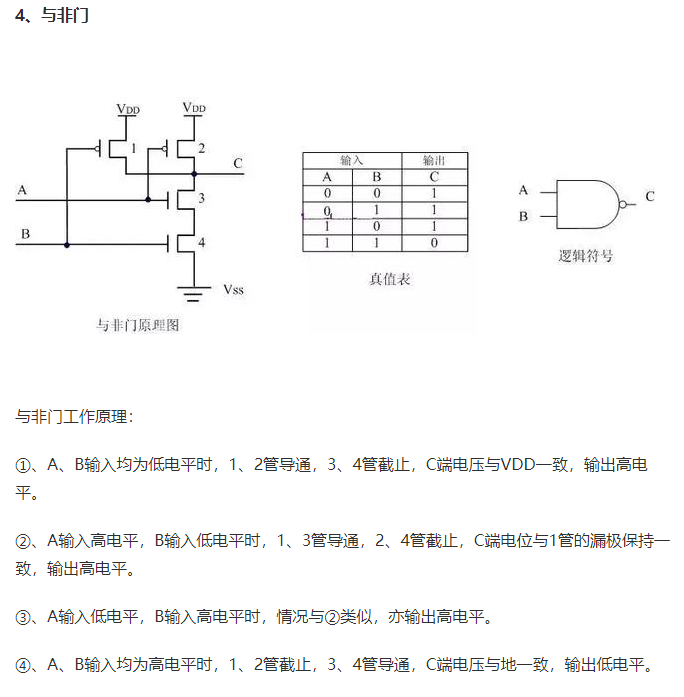
1.CMOS基本逻辑电路

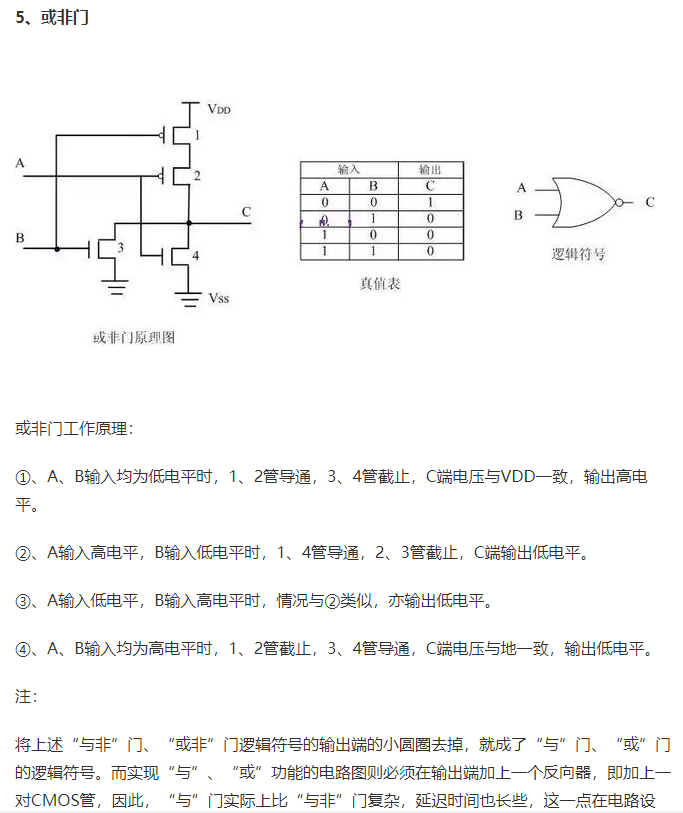
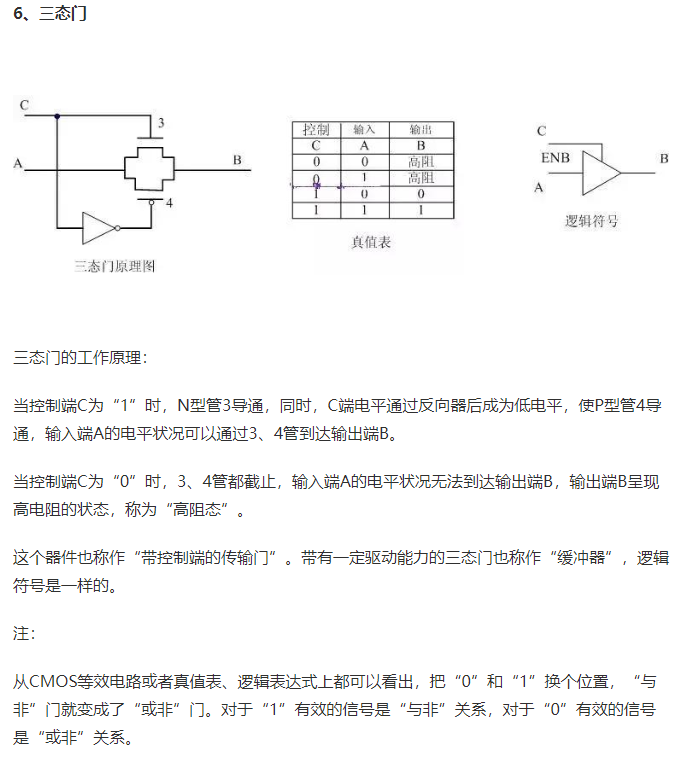

2.异或逻辑
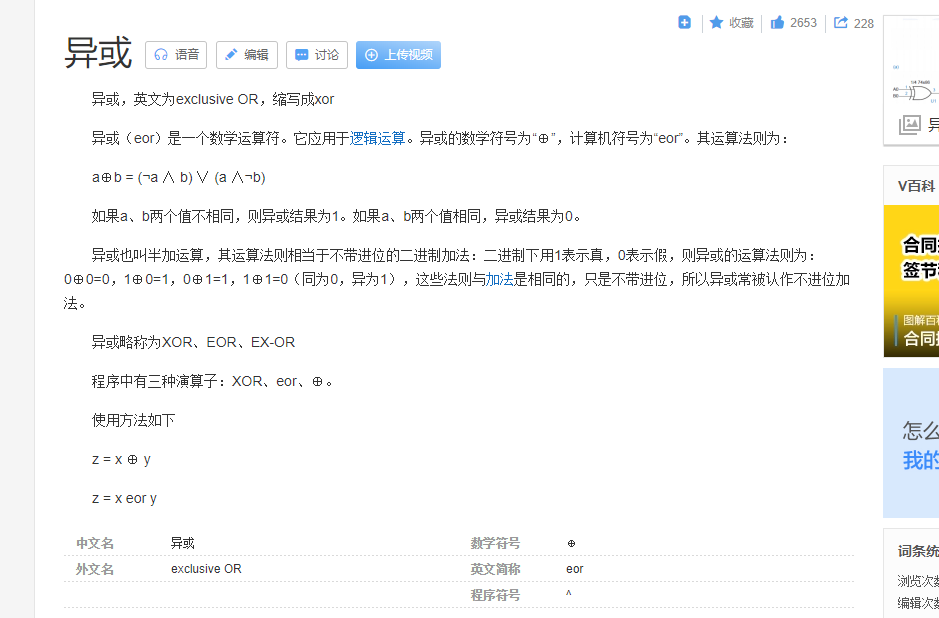



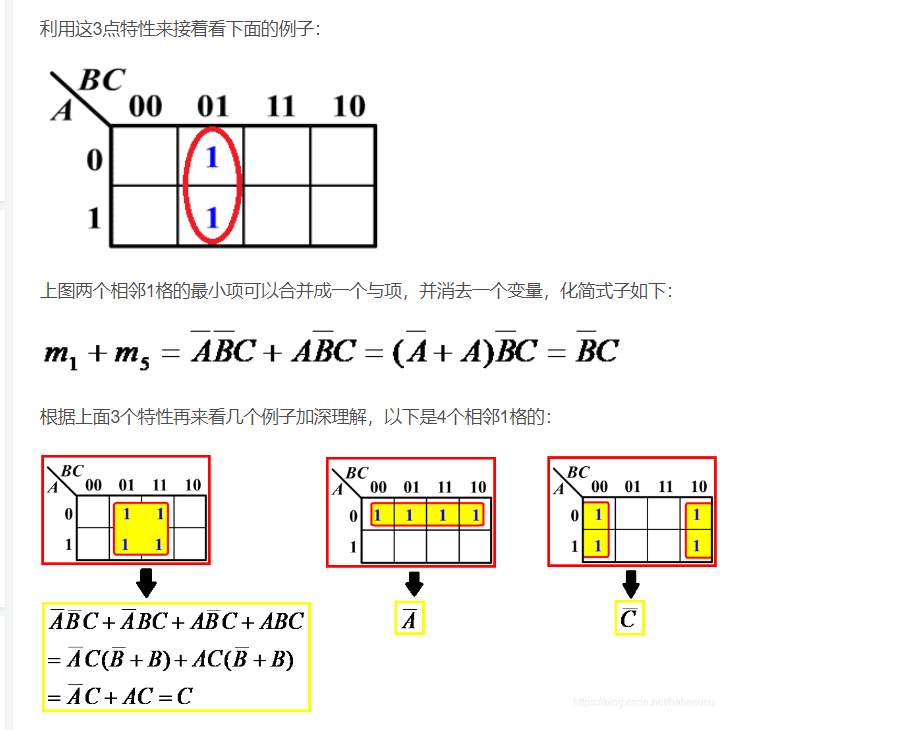
3.卡罗图简化函数
https://blog.csdn.net/hahasusu/article/details/88244155
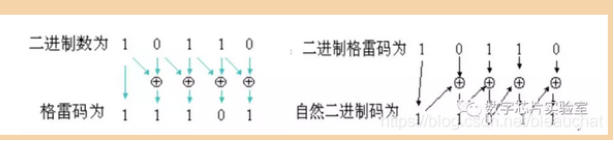
4.二进制,格雷码互转
5.产生锁存器latch


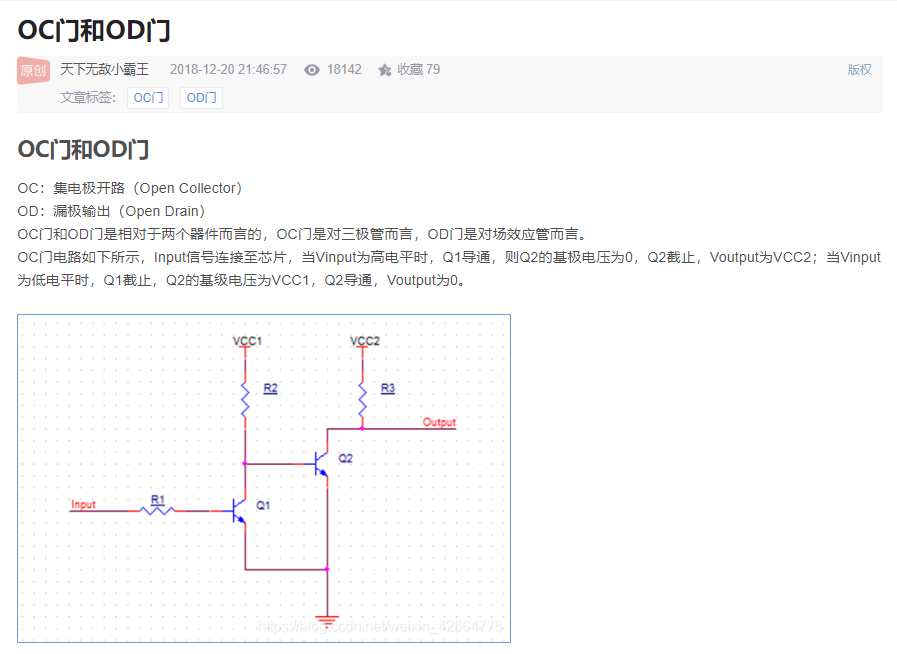
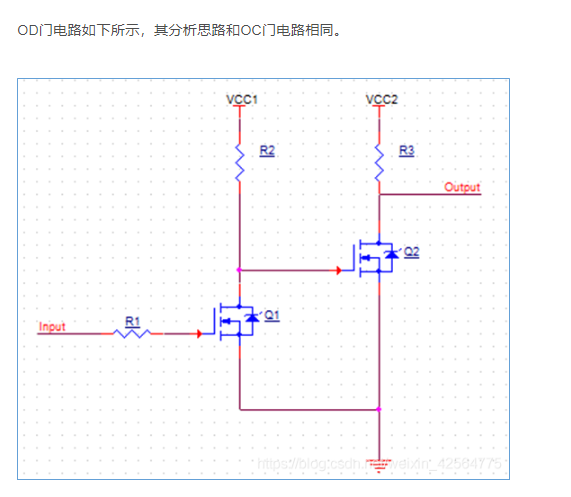
6.OC门,OD门
6.异步复位同步释放
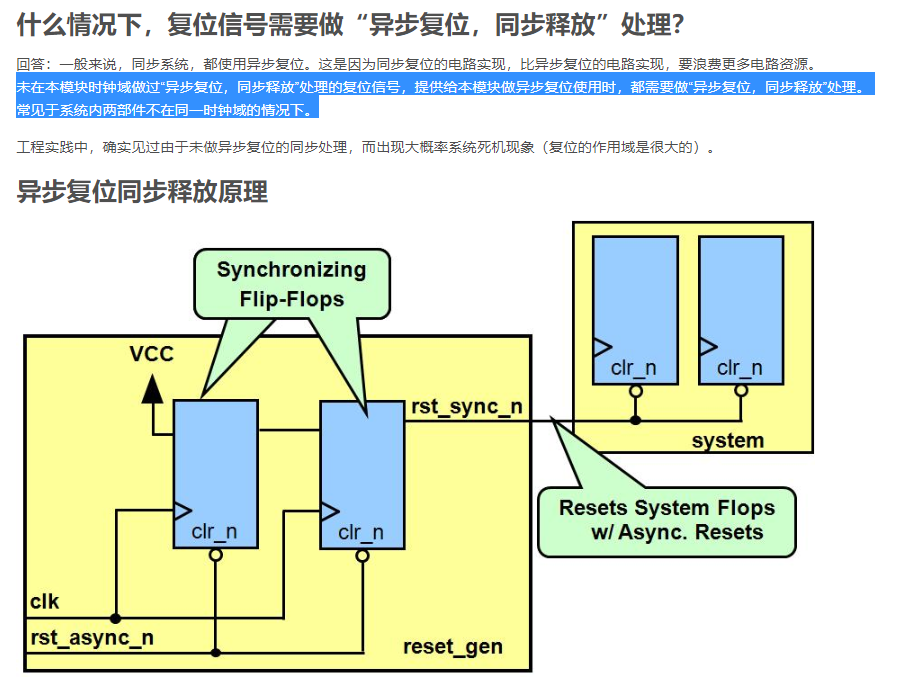
always @ (posedge clk or negedge rst_async_n)
if (!rst_async_n) begin
rst_s1 <= 1'b0;
rst_s2 <= 1'b0;
end
else begin
rst_s1 <= 1'b1;
rst_s2 <= rst_s1;
end
assign rst_sync_n = rst_s2;
endmodule
7.SRAM,FALSHMEMORY,DRAM,SSRAM及SDRAM的区别?
SRAM:静态随机存储器,存取速度快,但容量小,掉电后数据会丢失,不像DRAM 需要不停的REFRESH,制造成本较高,通常用来作为快取(CACHE) 记忆体使用。
FLASH:闪存,存取速度慢,容量大,掉电后数据不会丢失
DRAM:动态随机存储器,必须不断的重新的加强(REFRESHED) 电位差量,否则电位差将降低至无法有足够的能量表现每一个记忆单位处于何种状态。价格比SRAM便宜,但访问速度较慢,耗电量较大,常用作计算机的内存使用。
SSRAM:即同步静态随机存取存储器。对于SSRAM的所有访问都在时钟的上升/下降沿启动。地址、数据输入和其它控制信号均于时钟信号相关。
SDRAM:即同步动态随机存取存储器。
8 如何防止亚稳态
亚稳态是指触发器无法在某个规定时间段内达到一个可确认的状态。当一个触发器进入亚稳态时,既无法预测该单元的输出电平,也无法预测何时输出才能稳定在某个 正确的电平上。在这个稳定期间,触发器输出一些中间级电平,或者可能处于振荡状态,并且这种无用的输出电平可以沿信号通道上的各个触发器级联式传播下去。
解决方法:
1 降低系统时钟频率
2 用反应更快的FF
3 引入同步机制,防止亚稳态传播(可以采用前面说的加两级触发器)。
4 改善时钟质量,用边沿变化快速的时钟信号
9.奇数,偶数,任意分频
任意偶数分频:
module Divider(
input wire clk,
input wire rst_n,
output reg clk_div
);
parameter NUM_DIV = 6;
parameter Cyc_cnt = 3;//占空比
reg [3:0] cnt;
always @(posedge clk or posedge rst_n) begin
if (!rst_n) begin
cnt <= 'd0;
end
else if (cnt==NUM_DIV-1) begin
cnt <= 'd0;
end
else begin
cnt <= cnt + 1'b1;
end
end
always @(posedge clk or posedge rst_n) begin
if (!rst_n) begin
clk_div <= 1'b0;
end
else if (cnt > Cyc_cnt-1) begin
clk_div <= 1'b0;
end
else begin
clk_div <= 1'b1;
end
end
endmodule
任意奇数分频占空比(50%)
任意奇数分频占空比(50%)
module Divider(
input wire clk,
input wire rst_n,
output wire clk_div
);
//奇分频
parameter NUM_DIV = 7;
//parameter Cyc_cnt = 7;
reg [2:0] cnt1;
reg [2:0] cnt2;
reg clk_div1,clk_div2;
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
cnt1 <= 'd0;
end
else if (cnt1 == NUM_DIV-1) begin
cnt1 <= 'd0;
end
else begin
cnt1 <= cnt1 + 1'b1;
end
end
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
clk_div1 <= 1'b0;
end
else if (cnt1 < (NUM_DIV-1)/2) begin
clk_div1 <= 1'b1;
end
else
clk_div1 <= 1'b0;
end
always @(negedge clk or negedge rst_n) begin
if (!rst_n) begin
cnt2 <= 'd0;
end
else if (cnt2 == NUM_DIV-1 ) begin
cnt2 <= 'd0;
end
else begin
cnt2 <= cnt2 + 1'b1;
end
end
always @(negedge clk or negedge rst_n) begin
if (!rst_n) begin
clk_div2 <= 1'b0;
end
else if (cnt2 < (NUM_DIV-1)/2) begin
clk_div2 <= 1'b1;
end
else
clk_div2 <= 1'b0;
end
assign clk_div = clk_div1 | clk_div2;
always
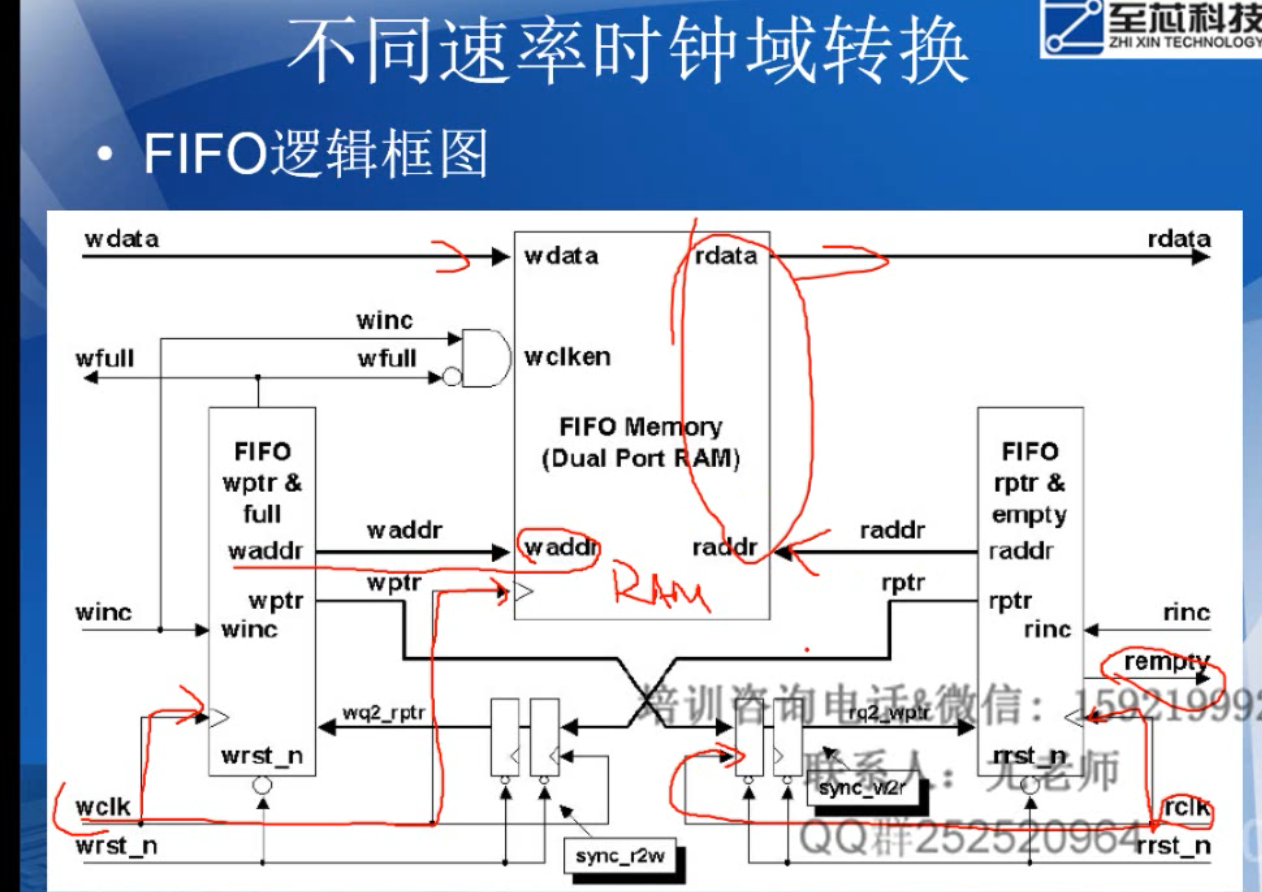
10.FIFO

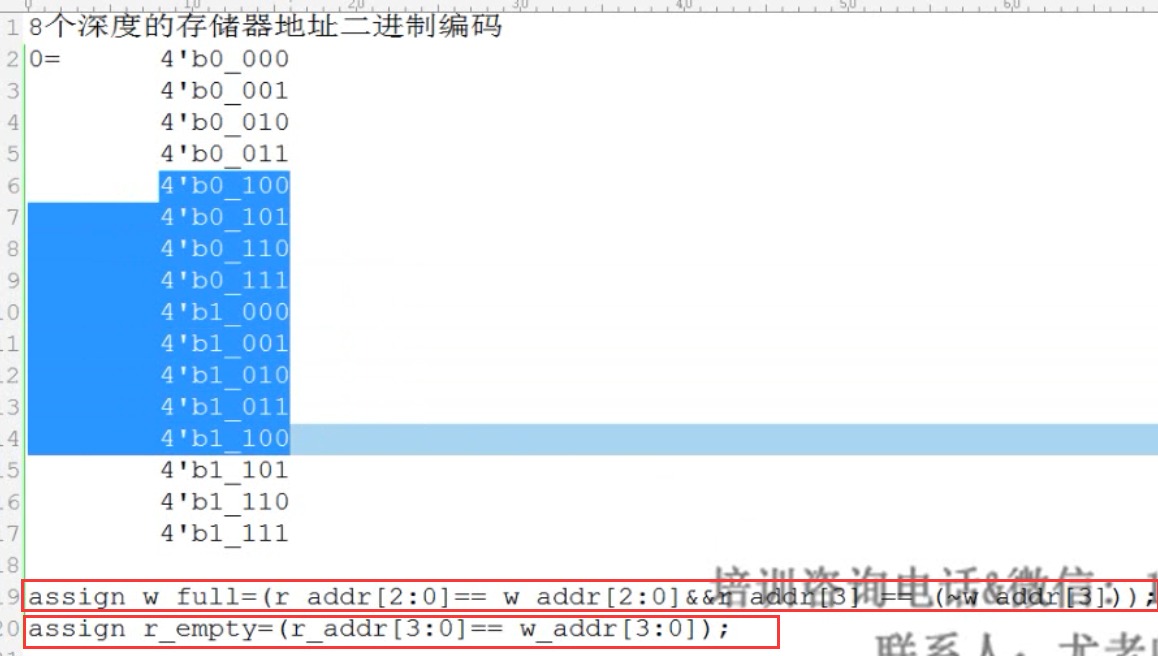
assign w_full = (r_addr[2:0]==w_addr[2:0]&&r_addr[3]==(~w_addr[3]));
assign r_empty = (r_addr[3:0]==w_addr[3:0]);
十进制转格雷码
格雷码=(十进制数》1)^(十进制数)

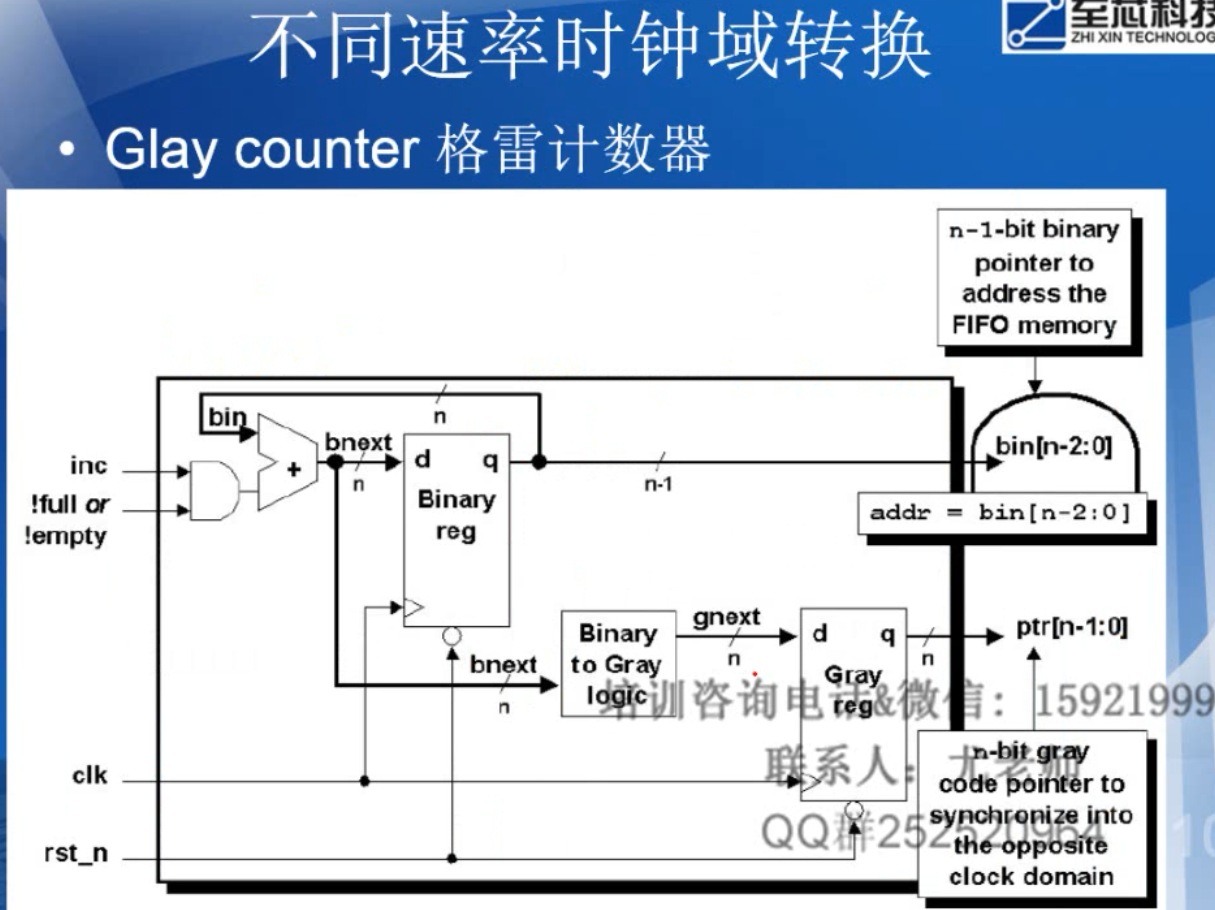

11.快时钟域脉冲信号到到慢时钟域信号
11.1脉冲同步
module top(
input rst_n,
input clka, //快时钟
input clkb, //慢时钟
input pulse_ina,
output pulse_outb
);
reg signal_a;
reg signal_b0,signal_b1,signal_b2,signal_b3;
reg [1:0] signal_a_r;
reg [1:0] signal_b_r;
assign pulse_outb= signal_b0^signal_b1;
//在clka时钟下将signal_a展宽
always @(posedge clka or negedge rst_n)
if(!rst_n)
signal_a <= 1'b0;
else if(pulse_ina)
signal_a <= ~signal_a;
always @(posedge clkb or negedge rst_n)
if(!rst_n)begin
signal_b0 <= 1'b0;
signal_b1 <= 1'b0;
signal_b2 <= 1'b0;
signal_b3 <= 1'b0;
end
else begin
signal_b0 <= signal_a;
signal_b1 <= signal_b0;
signal_b2 <= signal_b1;
signal_b3 <= signal_b2;
end
endmodule
11.2电平同步
module top(
input rst_n,
input clka, //快时钟
input clkb, //慢时钟
input pulse_ina,
output pulse_outb
);
reg signal_a;
reg signal_b0,signal_b1,signal_b2,signal_b3;
assign pulse_outb= signal_b1 &(~signal_b2);
//在clka时钟下将signal_a展宽
always @(posedge clkb or negedge rst_n)
if(!rst_n)begin
signal_b0 <= 1'b0;
signal_b1 <= 1'b0;
signal_b2 <= 1'b0;
signal_b3 <= 1'b0;
end
else begin
signal_b0 <= pulse_ina;
signal_b1 <= signal_b0;
signal_b2 <= signal_b1;
end
endmodule
12.i++,i–,++i,–i
1、i++,先引用i的值,后增加i的值,
如int i=10;
int a=i++;
该程序运行后,a=10,而i=11。
2、i–,先引用i的值,后i的值减1。
如int i=10;
int a=i–;
该程序运行之后,a=10,i=9。
除了以上的用法外,还有一种表示法是++i或者–i,这种表示法i的值也会相应的自增1或者自减1,i的结果和i++与i–是相同的,但是当赋值给另一个变量时,对赋值的变量,结果却存在差别,因为++i代表先增加,后引用,–i代表先减少,再引用。
例如同样的程序,i=10,
如果int a=i++,那么a=10;而int b=++i的话,b=11;
p++,++P,++*p

如果int a=i–,那么a=10;而int b=–i的话,b=9。
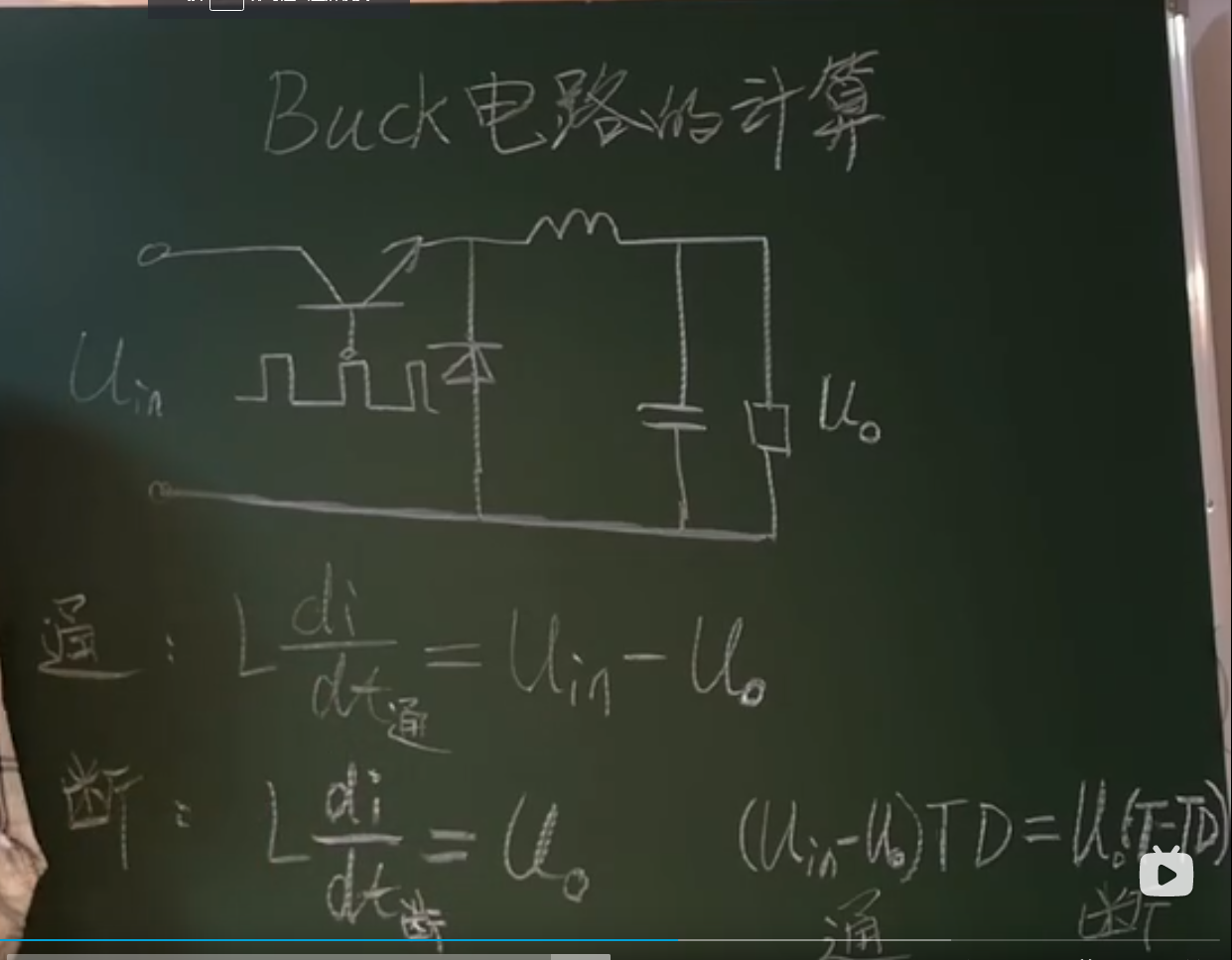
13.BUCK电路
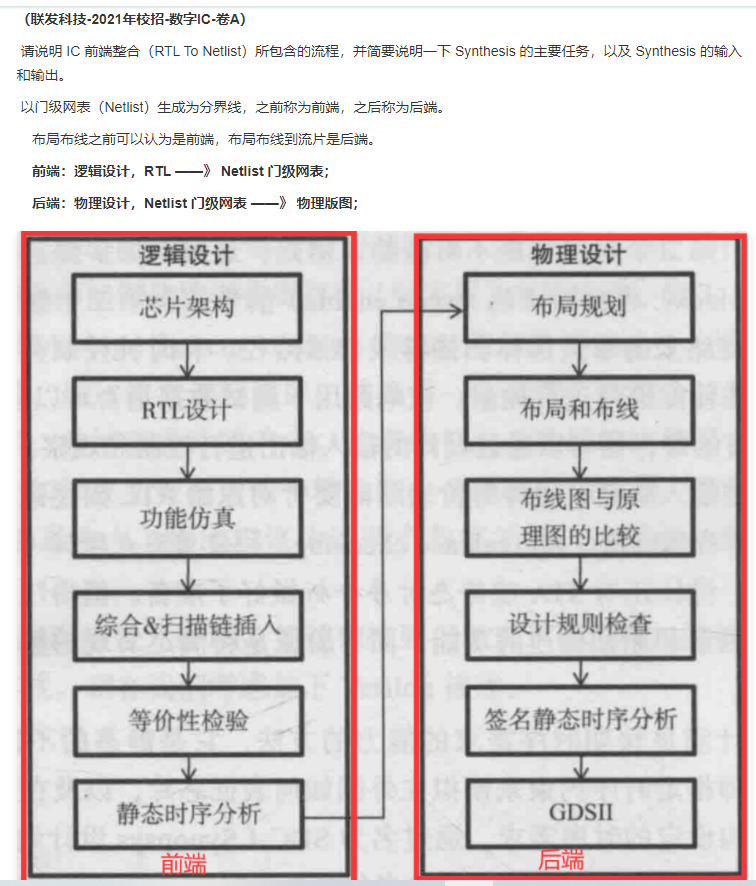
14.数字IC设计流程
15.为什么使用独热码,并不使用二进制编码或者格雷码
首先独热码因为每个状态只有1bit是不同的,所以在执行到43行时的(state == TWO)这条语句时,综合器会识别出这是一个比较器,而因为只有1比特为1,所以综合器会进行智能优化为(state[2] == 1’b1),这就相当于把之前3比特的比较器变为了1比特的比较器,大大节省了组合逻辑资源,但是付出的代价就是状态变量的位宽需要的比较多,而我们FPGA中组合逻辑资源相对较少,所以比较宝贵,而寄存器资源较多,所以很完美。而二进制编码的情况和独热码刚好相反,他因为使用了较少的状态变量,使之在减少了寄存器状态的同时无法进行比较器部分的优化,所以使用的寄存器资源较少,而使用的组合逻辑资源较多,我们还知道CPLD就是一个组合逻辑资源多而寄存器逻辑资源少的器件,因为这里我们使用的是FPGA器件,所以使用独热码进行编码。就因为这个比较部分的优化,还使得使用独热码编码的状态机可以在高速系统上运行,其原因是多比特的比较器每个比特到达比较器的时间可能会因为布局布线的走线长短而导致路径延时的不同,这样在高速系统下,就会导致采集到不稳定的状态,导致比较后的结果产生一个时钟的毛刺,使输出不稳定,而单比特的比较器就不用考虑这种问题。
用独热码编码虽然好处多多,但是如果状态数非常多的话即使是FPGA也吃不消独热码对寄存器的消耗,所以当状态数特别多的时候可以使用格雷码对状态进行编码。格雷码虽然也是和二进制编码一样使用的寄存器资源少,组合逻辑资源多,但是其相邻状态转换时只有一个状态发生翻转,这样不仅能消除状态转换时由多条信号线的传输延迟所造成的毛刺,又可以降低功耗,所以要优于二进制编码的方式,相当于是独热码和二进制编码的折中。
最后我们用一个表格来总结一下什么时候使用什么方式的编码效果最好 (有时候不管你使用哪种编码方式,综合器会根据实际情况在综合时智能的给你进行编码的转换,当然这需要你设置额外的综合约束,这里我们不再详细讲解) 。
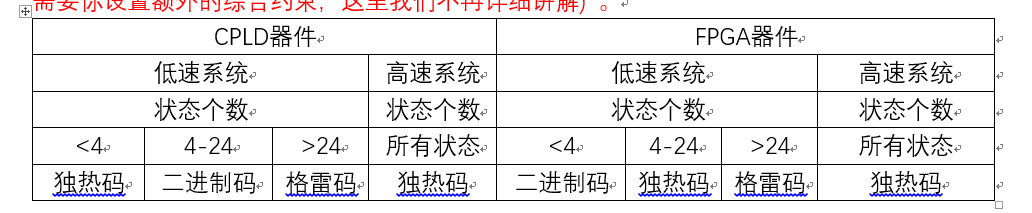
1.1编码方式也能降低功耗,比如格雷码每次只变化1bit,就比二进制编码降低了功耗。
16 RAM和ROM
一、易失性存储器的代表就是RAM,RAM又分为DRAM(动态随机存储器)和SRAM(静态随机存储器),它们之间主要在于生产工艺不同。
SRAM保存数据是通过晶体管进行锁存的,其工艺复杂,生产成本高,所以价格相对较贵,不易做大容量,但是速度更快;DRAM保存数据靠电容充电来维持容量,生产成本较SRAM低,所以价格相对便宜,容量可以做到很大,速度虽然不如SRAM快但是随着工艺技术的提升,速度也很可观,所以较为常用。DRAM和SRAM都是异步通信的,速率没有SDRAM(同步动态随机存储器)和SSRAM(同步静态随机存储器)快。所以现在大容量RAM存储器是选用SDRAM的。
CPU中的Cache实质属于SRAM,而内存条则是属于DRAM。SDRAM和DDR SDRAM的区别在于DDR(Double Data Rate)是双倍速率。SDRAM只在时钟的上升沿表示一个数据,而DDR SDRAM能在上升沿和下降沿都表示一个数据。DDR也一步步经过改良出现了一代、二代、三代、四代,以及低功耗版本,现在也有五代。
二、 非易失性存储器常见的有ROM,FLASH,光盘,软盘,硬盘。他们作用相同,只是实现工艺不一样。
ROM(Read Only Memory)在以前就是只读存储器,就是说这种存储器只能读取它里面的数据无法向里面写数据。实际是以前向存储器写数据不容易,所以这种存储器就是厂家造好了写入数据,后面不能再次修改。现在技术成熟了,ROM也可以写数据,但是名字保留了下来。ROM分为MASK ROM、OTPROM、EPROM、EEPROM。MASK ROM是掩膜ROM这种ROM是一旦厂家生产出来,使用者无法再更改里面的数据。OTPROM(One Time Programable ROM)一次可变成存储器,出厂后用户只能写一次数据,然后再也不能修改了,一般做存储密钥。EPROM(Easerable Programable ROM)这种存储器就可以多次擦除然后多次写入了。但是要在特定环境紫外线下擦除,所以这种存储器也不方便写入。EEPROM(Eelectrically Easerable Programable ROM)电可擦除ROM,现在使用的比较多因为只要有电就可擦除数据,就可以写入数据。
FLASH是一种可以写入和读取的存储器,叫闪存,FLASH也叫FLASH ROM,有人把FLASH当做ROM。FLASH和EEPROM相比,FLASH的存储容量大。FLASH的速度比现在的机械硬盘速度快,现在的U盘和SSD固态硬盘都是Nandflash。FLASH又分为Norflash和Nandflash。
NANDflash和NORflash的区别:
(1)、接口差别:
NOR型Flash采用的SRAM接口,提供足够的地址引脚来寻址,可以很容易的存取其片内的每一个字节;NAND型Flash使用复杂的I/O口来串行的存取数据,各个产品或厂商的方法可能各不相同,通常是采用8个I/O引脚来传送控制、地址、数据信息。
(2)、读写的基本单位:
NOR型Flash操作是以“字”为基本单位,而NAND型Flash以“页面”为基本单位,页的大小一般为512字节。
(3)、性能比较:
NOR型Flash的地址线和数据线是分开的,传输效率很高,程序可以在芯片内部执行,NOR型的读速度比NAND稍快一些;NAND型Flash写入速度比NOR型Flash快很多,因为NAND读写以页为基本操作单位。
(4)、容量和成本:
NAND型Flash具有较高的单元密度,容量可以做得比较大,加之其生产过程更为简单,价格较低;NOR型Flash占据了容量为1~16MB闪存市场的大部分,而NAND型Flash只是用在8~128MB的产品中,这也说明NOR主要用在代码存储介质中,NAND适合数据存储在CompactFlash、PC Cards、MMC存储卡市场上所占的份额最大。
(5)、软件支持:
NAND型和NOR型Flash在进行写入和擦除时都需要MTD(Memory Technology Drivers,MTD已集成在Flash芯片内部,它是对Flash进行操作的接口),这是它们的共同特点;但在NOR型Flash上运行代码不需要任何的软件支持,而在NAND型Flash上进行同样操作时,通常需要驱动程序,即内存技术驱动程序MTD
SDRAM / SRAM
SRAM与SDRAM的比较:
SRAM是靠双稳态触发器来记忆信息的;SDRAM是靠MOS电路中的栅极电容来记忆信息的。由于电容上的电荷会泄漏,需要定时给与补充,所以动态RAM需要设置刷新电路。但动态RAM比静态RAM集成度高、功耗低,从而成本也低,适于作大容量存储器。所以主内存通常采用SDRAM,而高速缓冲存储器(Cache)则使用SRAM,在存取速度上,SRAM>SDRAM。另外,内存还应用于显卡、声卡及CMOS等设备中,用于充当设备缓存或保存固定的程序及数据。
17.&和&&
“&”操作符有两种用途,既可以作为一元操作符(仅有一个操作数),也可以作为二元操作符(有两个操作数)。
当“&”作为一元操作符时表示归约与。&m是将m中所有比特相与,最后的结果为1bit。例:&4‘b1111 = 1&1&1&1 = 1’b1,&4’b1101 = 1&1&0&1 = 1’b0。
当“&”作为二元操作符时表示按位与。m&n是将m的每个比特与n的相应比特相与,在运算的时候要保证m和n的比特数相等,最后的结果和m(n)的比特数相同。例:4’b1010&4’b0101 = 4’b0000,4’b1101&4’b1111 = 4’b1101。
我们在写Verilog代码时常常当if的条件有多个同时满足时就执行使用“&&”逻辑与操作符。m &&n是判断m和n是否都为真,最后的结果只有1bit,如果都为真则输出1‘b1,如果不都为真则输出1’b0。要注意和“&”的功能区分。
18.状态机
Moore型状态机的输出只和当前状态有关而与输入无关;而Mealy型状态机的输出不仅和当前状态有关还与输入有关。所以A选项系统的状态保持或者变化情形取决于系统的输入及其当前状态正确。
19.竞争与冒险
在组合逻辑电路中我们将门电路两个输入信号同时向相反的逻辑电平跳变(一个从1变为0,另一个从0变为1)的现象称为竞争。由于竞争而在电路输出端可能产生尖峰脉冲的现象就称为竞争-冒险。通俗的理解就是组合逻辑电路中会在两个输入变化的地方产生干扰即毛刺,电路中的毛刺是我们不希望产生的,会使我们设计的电路产生不稳定因素,非常危险。
消除竞争冒险的方法常见有4种:
1)修改逻辑设计,这主要包括去除互补逻辑变量和增加冗余项。
2)输出端并联电容,这主要利用了电容的充放电特性,对毛刺滤波,对窄脉冲起到平波的作用。
3)利用格雷码每次只有一位跳变,消除了竞争冒险产生的条件。
4)利用D触发器对毛刺不敏感的特性。
在Verilog编程时,需要注意以下几方面,在绝大多数情况下可避免综合后仿真出现冒险问题。
1)时序电路建模时,用非阻塞赋值。
2)锁存器电路建模时,用非阻塞赋值。
3)用always和组合逻辑建模时,用阻塞赋值。
4)在同一个always块中建立时序和组合逻辑模型时,用非阻塞赋值。
5)在同一个always块中不要既使用阻塞赋值又使用非阻塞赋值。
6)不要在多个always块中为同一个变量赋值。

20.同步电路和异步电路
异步电路:
a) 电路核心逻辑是用组合电路实现;
b) 异步时序电路的最大缺点是容易产生毛刺;
c) 不利于器件移植;
d) 不利于静态时序分析(STA)、验证设计时序性能。
同步时序电路:
a) 电路核心逻辑是用各种触发器实现;
b) 电路主要信号、输出信号等都是在某个时钟沿驱动触发器产生的;
c) 同步时序电路可以很好的避免毛刺;
d) 利于器件移植;
e) 利于静态时序分析(STA)、验证设计时序性能。
21.同步复位和异步复位
22.全加器和半加器
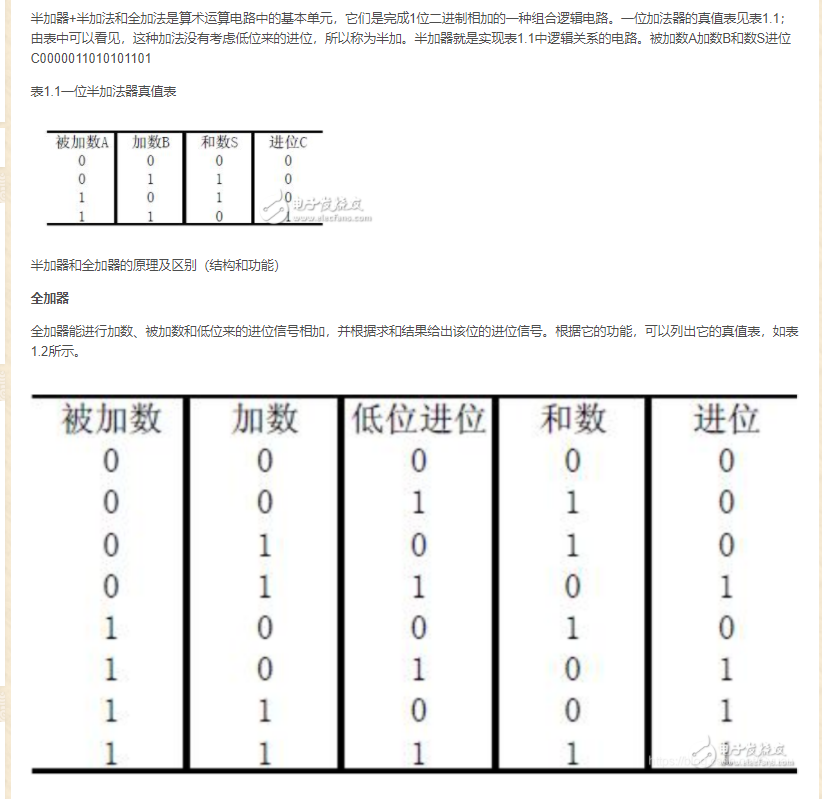
01 module full_adder(
02 input wire [3:0] in1 , //加数1
03 input wire [3:0] in2 , //加数2
04 input wire cin , //上一级的进位
05
06 output wire [3:0] sum , //两个数的加和
07 output wire cout //加和后的进位
08 );
09
10 assign {cout, sum} = in1 + in2 + cin;
11
12 endmodule
01 module half_adder(
02 input wire [3:0] in1 , //加数1
03 input wire [3:0] in2 , //加数2
05
06 output wire [3:0] sum , //两个数的加和
07 output wire cout //加和后的进位
08 );
09
10 assign {cout, sum} = in1 + in2 ;
11
12 endmodule
23.任务和函数
(正确率26%)关于任务和函数的区别,下列说法错误的是( A )。(华为硬件逻辑实习岗)
A 函数可以包含时延和时序控制 B 函数不能调用任务
C 函数必须带有至少一个输入 D 函数只能返回一个值
解析:本题目主要考察了Verilog中任务和函数的特点
任务和函数有助于简化程序,往往在编写用于仿真Testbench中使用较多。在《IEEE Standard Verilog Hardware Description Language》中有详细对任务和函数用法的介绍和示例。
任务和函数的共同点:
(1)任务和函数必须在模块内定义,其作用范围仅适用于该模块,可以在模块内多次调用。
(2)任务和函数中可以声明局部变量,如寄存器,时间,整数,实数和事件,但是不能声明线网类型的变量。
(3)任务和函数中只能使用行为级语句,但是不能包含always和initial块,设计者可以在always和initial块中调用任务和函数。
任务和函数的不同点:
(1)函数能调用另一个函数,但是不能调用任务;任务可以调用另一个任务,也可以调用函数。所以B选项正确。
(2)函数总是在仿真时刻0开始;任务可以在非零时刻开始执行。
(3)函数一定不能包含任何延迟,事件或者时序控制声明语句;任务可以包含延迟,事件或者时序控制声明语句。所以A选项错误。
(4)函数至少要有一个输入变量,也可以有多个输入变量;任务可以没有或者有多个输入,输出,输入输出变量。所以C选项正确。
(5)函数只能返回一个值,函数不能有输出或者双向变量 任务不返回任何值,或者返回多个输出或双向变量值。所以D选项正确。
由上述的特点决定:函数用于替代纯组合逻辑的Verilog代码,而任务可以代替Verilog的任何代码。
任务使用关键字task和endtask来进行声明,如果子程序满足下面任何一个条件,则必须使用任务而不能使用函数。自动(可重入)任务:Verilog任务中所有声明的变量地址空间都是静态分配的,因此如果在一个模块中多次调用任务时,可能会造成地址空间的冲突,为了避免这个问题,Verilog通过在task关键字后面添加automatic使任务称为可重入的,这时在调用任务时,会自动给任务声明变量分配动态地址空间,这样有效避免了地址空间的冲突。
函数使用关键字function和endfunction定义,对于子程序,如果满足下述所有条件则可以用函数来完成:跟任务调用一样,在模块中如果调用多次函数,也会碰到地址冲突的问题,因此也引入automatic关键字来对函数可重用性声明。没有进行可重用性声明的函数不可以多次或者递归调用,进行了可重用性声明的函数可以递归调用。
24.线性移位寄存器
https://blog.csdn.net/qq_34070723/article/details/100691478?ops_request_misc=&request_id=&biz_id=102&utm_term=%E4%B8%80%E4%B8%AA%E7%BA%BF%E6%80%A7%E5%8F%8D%E9%A6%88%E7%A7%BB%E4%BD%8D%E5%AF%84%E5%AD%98%E5%99%A8%EF%BC%88LSFR%EF%BC%89%E7%9A%84%E7%89%B9%E5%BE%81%E5%A4%9A%E9%A1%B9%E5%BC%8F%E4%B8%BAF(x)=x&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-5-.pc_search_result_before_js&spm=1018.2226.3001.4187#t4
25.CMOS实现Y=AB+C电路与版图
https://blog.csdn.net/qq_40223983/article/details/96170311
26.二四译码器
module decode_2_4(
input wire[1:0] data_in,
input wire select,
output wire[3:0] data_out
);
assign data_out[3]=~(data_in[1]&data_in[0]&select);
assign data_out[2]=~(data_in[1]&~data_in[0]&select);
assign data_out[1]=~(~data_in[1]&data_in[0]&select);
assign data_out[0]=~(~data_in[1]&~data_in[0]&select);
endmodule
27.任意分频
module divider(
input wire clk,
input wire rst_n,
input wire[2:0] divider_num,
output wire out_clk
);
reg [2:0] divider_num_reg;
reg out_clk_reg1,out_clk_reg2;
always @(posedge clk or negedge rst_n)
if(!rst_n)
divider_num_reg <= 'd0;
else
divider_num_reg <= divider_num;
reg[2:0] count;
always @(posedge clk or negedge rst_n)
if(!rst_n)begin
count <= 'd0;
out_clk_reg1<='d0;
end
else begin
count<=count+1'b1;
if(count==(divider_num_reg-1))begin
out_clk_reg1<=~out_clk_reg1;
count<='d0;
end
end
always @(negedge clk or negedge rst_n)
if(!rst_n)begin
count<='d0;
out_clk_reg2 <= 'd0;
end
else begin
count <= count + 1'b1;
if(count==(divider_num_reg-1))begin
out_clk_reg2<=~out_clk_reg2;
count<='d0;
end
end
assign out_clk = out_clk_reg1^out_clk_reg2;
endmodule
28.静态时序分析

一般建立时间违例,说明数据延时太大了
一般保持时间违例,说明始终延迟太大了
Tdata=Tlogic + Tnet;
Tclk>= Tco+Tdata+Tsu;
setup slack = data required time(steup)-data arrival time(setup)
hold slack = data arrival time(hold) - data required time(hold)
28.1中心对齐模式
28.2边沿对齐模式
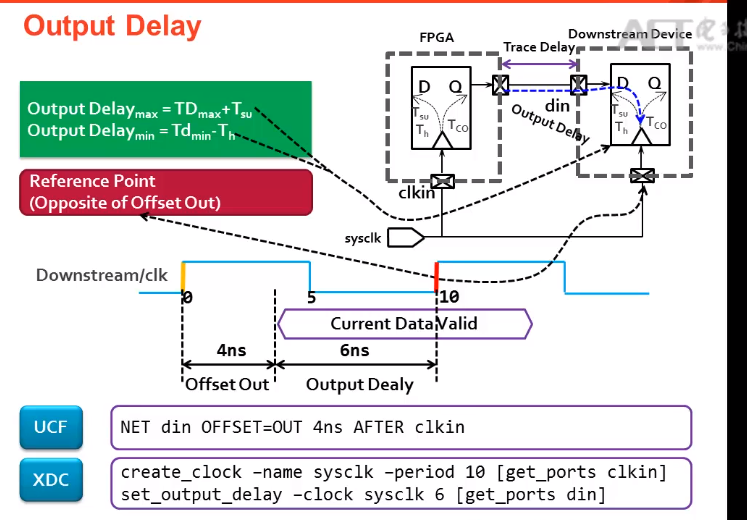
1.input delay:根据datasheet来设置input delay max,input delay min
2.当PCB布线时,data path 和 clk path 一样时,出现时序为例,可以对input delay采用PLL,进行相移;
1.1当进行负相位移动时,即第一个沿发射,第二个沿向前移动来采样
1.2当进行正相移动时,如果要进行第一个时钟发射第二个时钟采样,还需要进行multicycle path约束,第二个时钟沿来采样,不然它默认是第一个时钟发射,第一个时钟延时后采样,则不满足时序要求。
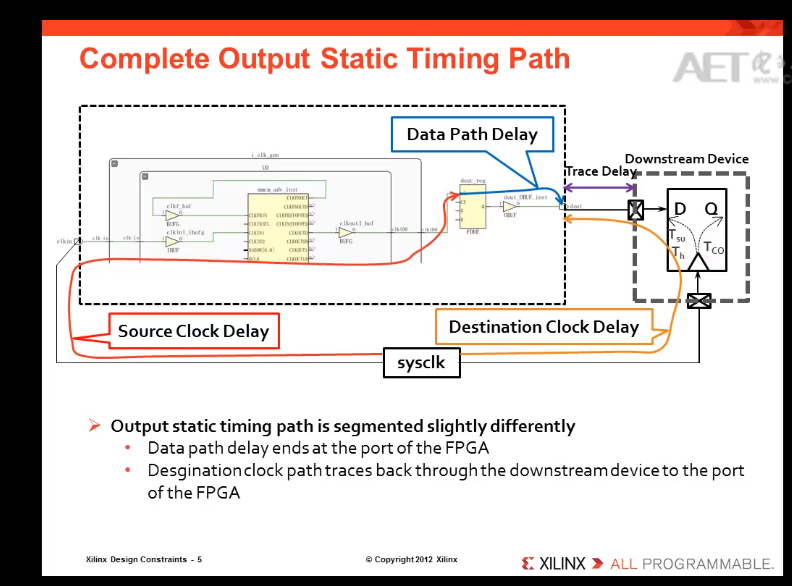
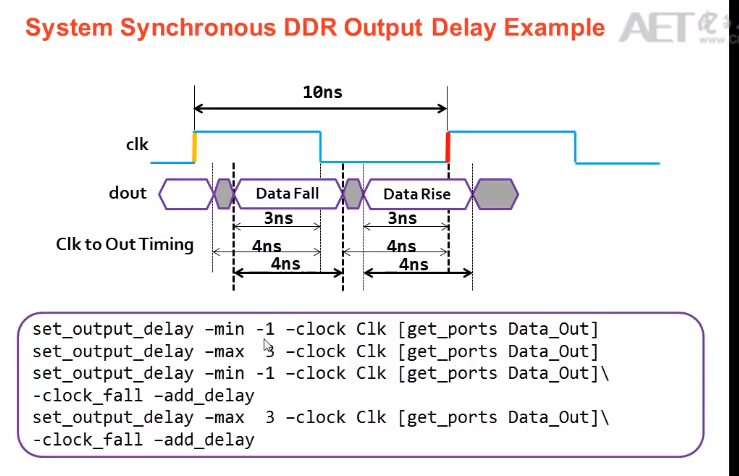
INPUT Delay:
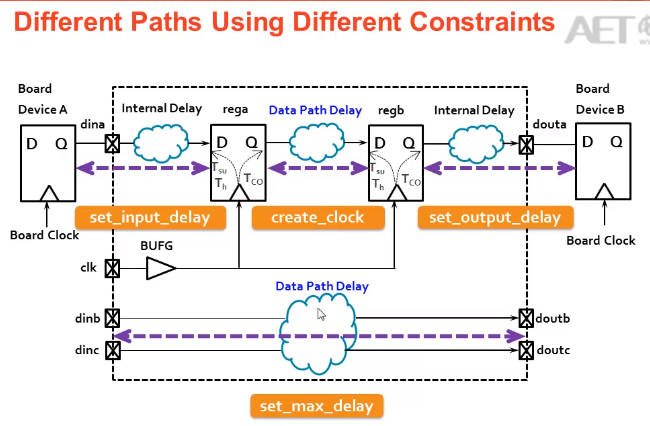
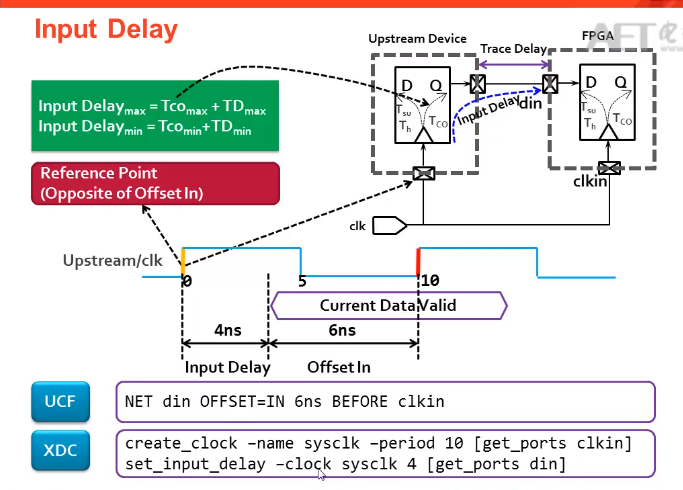
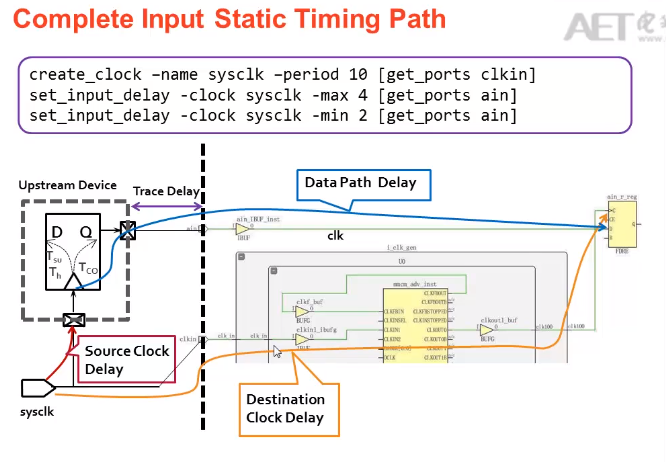

中心对齐:
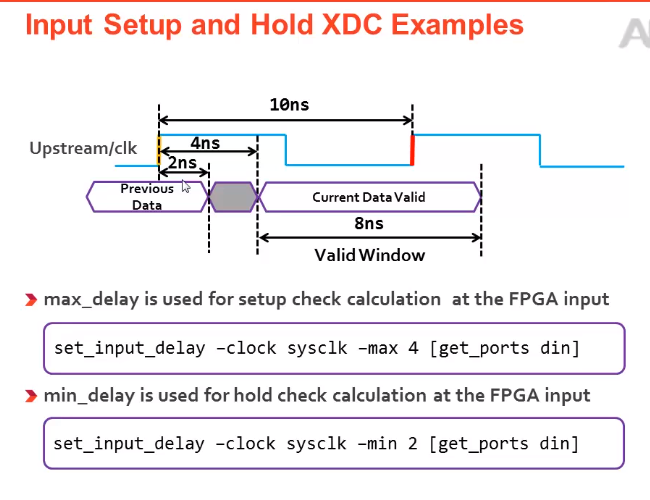
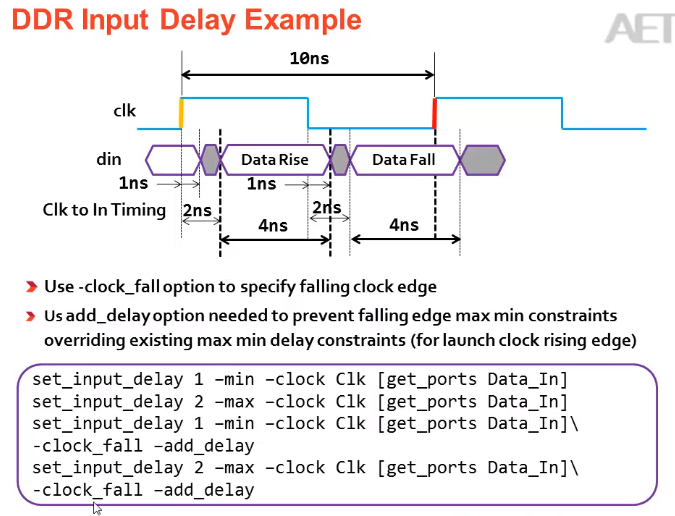
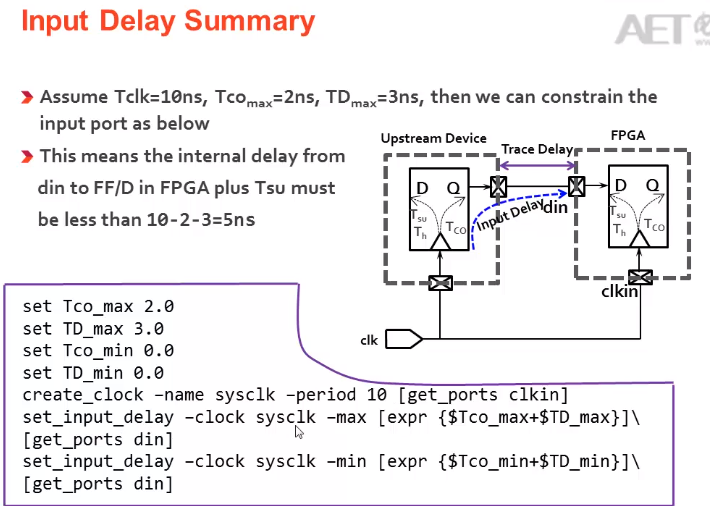
28.3异步时钟,跨时钟域处理
(1)可以
set_clock_group -name async_clk0_clk1 -asynchronous
-group [get_clocks -include_generated_clocks clk0]
-group [get_clocks -include_generated_clocks clk1]
(2)可以设置伪路径 set_false_path
但是注意,设置伪路径是单向的,如果两个寄存器之间 的传输是双向的需要设置从A到B,也要设置从B到A;
29.异步双口RAM和同步双口RAM
module single_dualram(
input wire clk1,//写时钟
input wire clk2,//读时钟
input wire we,//写使能
input wire rd,//读使能
input wire [2:0] we_addr,//写地址
input wire [2:0] rd_addr,//读地址
input wire [7:0] datain,//写数据
output reg [7:0] dataout//读数据
);
reg [7:0]mem[7:0];
always @(posedge clk1) begin
if (we == 1'b1) begin
mem[we_addr] <= datain;
end
end
always @(posedge clk2) begin
if (rd == 1'b1) begin
dataout <= mem[rd_addr];
end
end
endmodule
-------------------------------------------------------
module asyn_ram
#(parameter DWIDTH=4,//data width
AWIDTH=10)//address width
(
input wr_clk,
input[DWIDTH-1:0] wr_data,
input wr_en,
input[AWIDTH-1:0] wr_addr,
input rd_clk,
output [DWIDTH-1:0] rd_data,
input rd_en,
input[AWIDTH-1:0] rd_addr
);
reg[DWIDTH-1:0] rw_mem [2**AWIDTH-1:0];//define the memory
reg[AWIDTH-1:0] raddr;
always@(posedge wr_clk )
begin
if(wr_en) begin
rw_mem[wr_addr]<=wr_data;
end
end
always@(posedge rd_clk)
begin
if(rd_en) begin
raddr<=rd_addr;
end
end
assign rd_data=rw_mem[raddr];
endmodule
======================================================================
`timescale 1ns/1ns
module tb_single_dualram();
reg clk1,clk2;
reg we,rd;
reg [7:0] we_addr,rd_addr;
reg [7:0] datain;
wire[7:0] dataout;
initial begin
clk1 = 0;
clk2 = 0;
we = 0;
rd = 0;
we_addr = 0;
rd_addr = 0;
datain = 0;
end
always #10 clk1 = ~clk1;
always #10 clk2 = ~clk2;
initial begin
#25
we = 1;
#50
rd = 1;
#100
we = 0;
end
initial begin
#20
repeat(7)
#20
begin
we_addr = we_addr +1;
datain = datain + 1;
end
end
initial begin
#75
repeat(7)
#20
begin
rd_addr = rd_addr +1;
end
end
initial
#240
rd = 0;
single_dualram inst_single_dualram(
.clk1 (clk1),
.clk2 (clk2),
.we (we),
.rd (rd),
.we_addr (we_addr),
.rd_addr (rd_addr),
.datain (datain),
.dataout (dataout)
);
endmodule
30.阻塞赋值与function函数
----------------------采用阻赋值来实现一个周期for循环-------------------------------------
//always时序逻辑中采用阻塞赋值,其实相当于用一堆组合逻辑加上一个D触发器构成
module test1(
input wire sclk,
input wire rst_n,
input wire[7:0] data,
output reg [7:0] check_data
);
integer i;
always @(posedge sclk or negedge rst_n)
if(!rst_n)begin
check_data = 'd0;
end
else
begin
ccc=data;
for(i=0;i<8;i=i+1)
begin
ccc={ccc[6:0],1'b0}^({8{ccc[7]}}&8'h31);
end
check_data =ccc;
end
function:
function <返回值的类型或范围>(函数名);
<端口说明语句> // input XXX
<变量类型说明语句> // reg YYY
......
begin
<语句>
......
函数名 = ZZZ; // 函数名就相当于输出变量;
end
endfunction
函数的语法为:
定义函数时至少要有一个输入参量;可以按照ANSI和module形式直接定义输入端口。例如:
function[63:0] alu (input[63:0] a, b, input [7:0] opcode);
在函数的定义中必须有一条赋值语句给函数名具备相同名字的变量赋值;
在函数的定义中不能有任何的时间控制语句,即任何用#,@或wait来标识的语句。
函数不能启动任务。
//-----------------------------采用function在一个周期内实现for循环----------------------------------------
//function中因为不涉及时间
module test1(
input wire sclk,
input wire rst_n,
input wire[7:0] data,
output reg [7:0] check_data
);
integer i;
function [7:0] cal_table;
input [7:0] value;
reg[7:0] ccc;
reg[7:0] flag;
begin
ccc=value;
for(i=0;i<8;i=i+1)begin
flag = ccc&8'h80;
if(flag != 0)ccc=(ccc<<1)^8'h31;
else
ccc = (ccc << 1);
end
cal_table=ccc;
end
endfunction
always @(posedge sclk or negedge rst_n)
if(!rst_n)
check_data <= 'd0;
else
check_data <= cal_table(data);
31.Tmin计算,即最大频率计算
32.FPGA底层知识
1.FPGA组成
https://blog.csdn.net/qq_31568011/article/details/115349468?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162747775216780262597761%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=162747775216780262597761&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_v2~rank_v29-2-115349468.pc_search_result_before_js&utm_term=fpga中资源利用&spm=1018.2226.3001.4187
7-series FPGA上,Slice具有4个6输入LUT和8个寄存器,可用于执行许多不同的功能函数,包括组合逻辑、算术、移位寄存器、存储功能
2.MMCM,PLL
https://blog.csdn.net/weiaipan1314/article/details/104295132?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163030719416780262570120%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=163030719416780262570120&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~rank_v29_ecpm-6-104295132.first_rank_v2_pc_rank_v29&utm_term=MMCM与PLL&spm=1018.2226.3001.4187
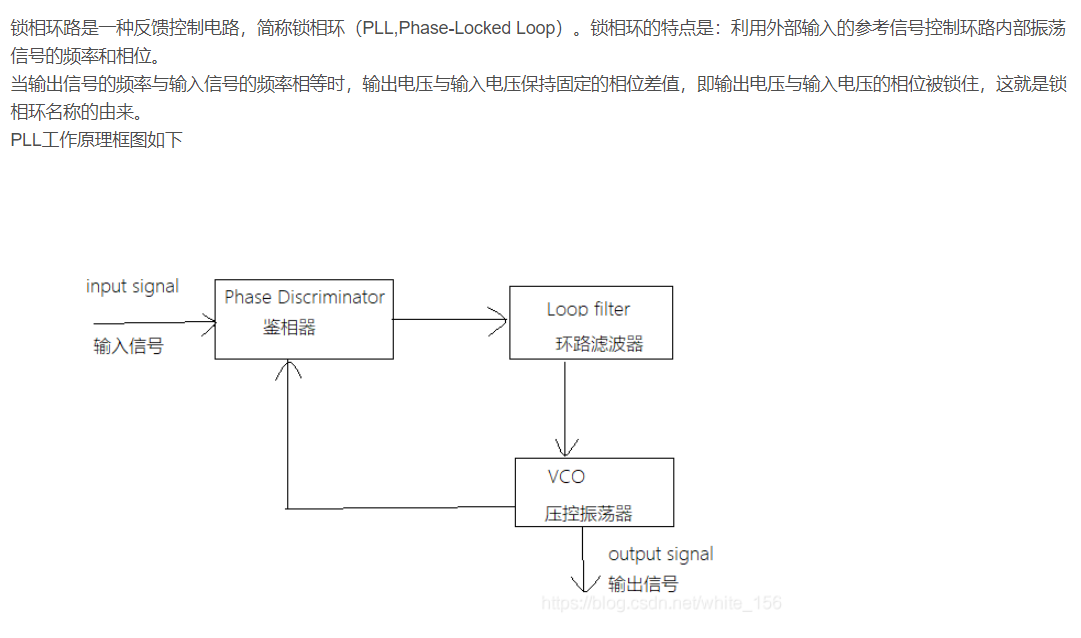
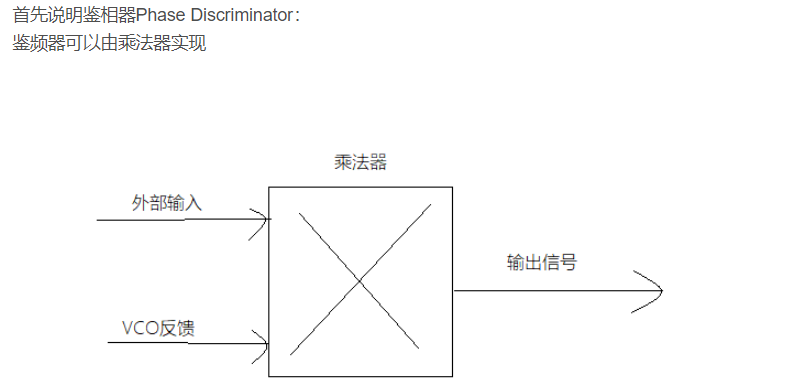
MMCM、PLL均可实现时钟整数倍的频率综合、去抖、去偏斜,但MMCM还可以实现分数倍的频率综合、反相时钟输出以及动态的时钟相位调整。
3. Bram,Dram
块RAM 和 分布式RAM
分布式RAM(DRAM):查找表存储器
只有成为SLICEM的逻辑块里的查找表(LUT)才可以用做分布式RAM。
利用查找表为电路实现存储器,既可以实现芯片内部存储,又能提高资源利用率。分布式RAM的特点是可以实现BRAM不能实现的异步访问。 不过使用分布式RAM实现大规模的存储器会占用大量的LUT,可用来实现逻辑的查找表就会减少。因此建议仅在需要小规模存储器时,使用这种分布式RAM。
————————————————
原文链接:https://blog.csdn.net/qq_40147893/article/details/119875970
① Xilinx 的FPGA结构主要由CLB、IOB、IR、Block RAM组成,其中CLB是最最重要的资源。
② 以V5为例,1个CLB包括的2个Slice,每个Slice包括4个6输入查找表,4个FlipFlop和相关逻辑。在这里需要注意的是Slice分两种,SliceM和SliceL,它们都包括前面的东西,但是很特别的是SliceM还增加了基于查找表的分布式RAM和移位寄存器。
③ 每个CLB中都包含SliceL,但并不是每个CLB中都包含SliceM,整个一块V5芯片中SliceM和SliceL的比例为1:3。SliceM的放置有一定的规则,这里不做阐述。
④ Xilinx的FPGA中有 分布式RAM 和 Block RAM 两种存储器。用分布式RAM 时其实要用到其所在的SliceM,所以要占用其中的逻辑资源;而Block RAM 是单纯的存储资源,但是要一块一块的用,不像分布式RAM 想要多少bit都可以。
⑤ 用户申请存储资源,FPGA先提供Block RAM ,当Block RAM 数量不够时再用分布式RAM补充。
来源:http://www.eefocus.com/zpshao/blog/11-01/201525_d33fc.html
区别:
1.Bram 的输出需要时钟,Dram在给出地址后既可输出数据。
2.Dram使用根灵活方便些
3.Bram有较大的存储空间,Dram浪费LUT资源
补充:
1.物理上看,Bram是fpga中定制的ram资源,Dram就是用逻辑单元拼出来的。
2.较大的存储应用,建议用Bram;零星的小ram,一般就用Dram。但这只是个一般原则,具体的使用得看整个设计中资源的冗余度和性能要求
3.Dram可以是纯组合逻辑,即给出地址马上出数据,也可以加上register变成有时钟的ram。而Bram一定是有时钟的。

32.项目芯片型号以及资源使用情况
项目一:

项目二
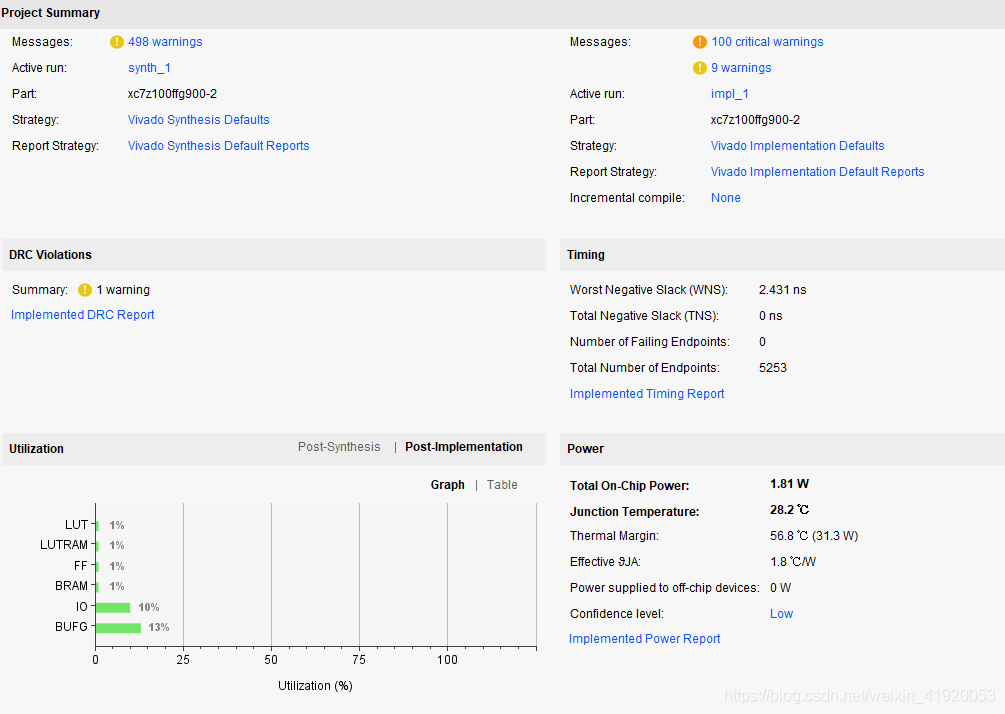
项目三
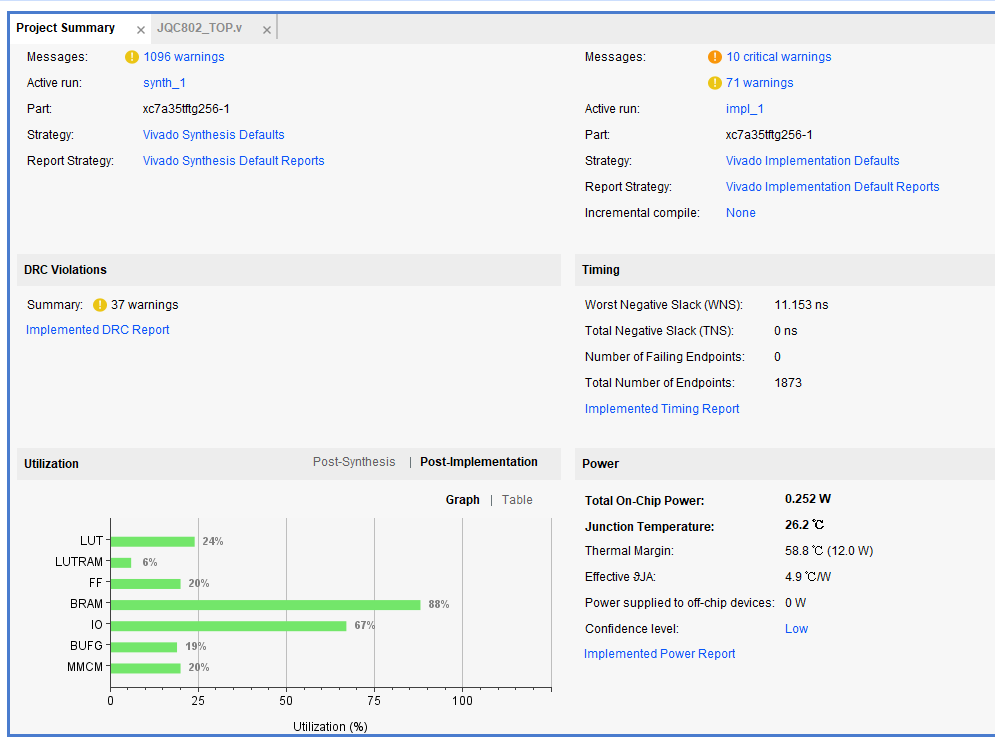
33.静态功耗和动态功耗
动态功耗是电路逻辑转换期间消耗的功耗,由两个部分组成,开关功耗和短路功耗。 开关功耗来自对电路负载电容充放电的功耗。短路功耗来自在电路逻辑转换期间,流过PMOS-NMOS的短路电流。所以,动态功耗取决于电源电压和电容负载以及时钟频率和开关活动。
然而,随着晶体管尺寸和阈值电压降低,静态(泄漏)功耗正在变得越来越大,通过减慢或 停止时钟不能减少泄漏功耗。但是,可以通过降低或关闭电源电压来减少或消除泄漏功耗。
阈值电压Vt对静态功耗有什么影响?对电路速度有什么影响?
HVt可以有效地降低静态功耗。但电路的速度会降低。
LVt可以提高电路的速度,但是静态功耗会增大。

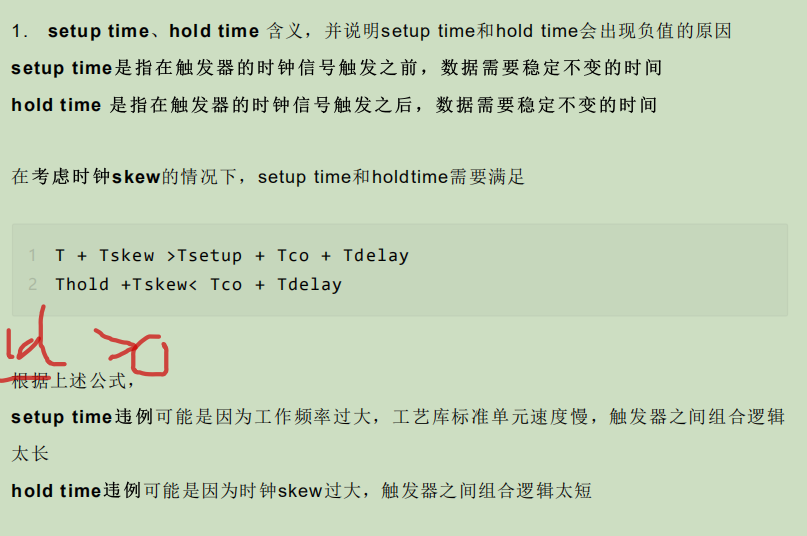
34.Tsetup/Tholdup
https://blog.csdn.net/qq_40147893/article/details/117018443
1.clock jitter:
指的是两个时钟周期之间存在的差值,这个误差是在时钟发生器内部产生的,和晶振或者PLL内部电路有关,布线对其没有影响。
2.clock skew:
是指同样的时钟产生的多个子时钟信号之间的延时差异。
3.时序为例
https://www.cnblogs.com/poiu-elab/archive/2012/10/29/2744759.html
35.前端设计的流程,每个流程是干什么的?
1.STA(StaticTiming Analysis, STA)静态时序分析,
根据设计的约束和电路结构将设计 划分为一条条时序路径,计算各路径的时序是否满足要求。它主要考虑通过每个逻辑门的最 12 T + Tskew >Tsetup + Tco + Tdelay Thold +Tskew< Tco + Tdelay差延迟,而不是电路的逻辑功能。与动态仿真相比,静态时序分析不需要测试向量,能更 快地检查所有路径下的时序。
formal形式验证:使用数学方式进行设计的形式验证,主要用来对设计过程中不同阶段的设 计进行逻辑功能一致性的对比,判断工具是否对电路工作造成了影响。
2.formal形式验证:
使用数学方式进行设计的形式验证,主要用来对设计过程中不同阶段的设 计进行逻辑功能一致性的对比,判断工具是否对电路工作造成了影响。
3.DFT
可测性设计:在设计规模变得复杂时,需要考虑设计的可测 试性,在设计中插入设计功能之外的测试逻辑。
36.请描述跨时钟域设计时会出现的问题及解决办法
在同步设计中,可以使用工具方便地分析电路的时序以优化设计满足建立时间和保持时间, 而对于异步设计则无法使用静态时序分析进行时序分析。这可能会造成时序违例,进而导 致电路的亚稳态发生。 通常可以使用两级同步器,握手信号和异步FIFO解决跨时钟域问题
37.一个16bit序列,每个clk左移一位,要求检测5的倍数。
那么假设该数为ABCD,则这个数字10进制为A*16^3+B*16^2+C*16^1+D*16^0,可以 展开为A*(15+1)^3+B* (15+1)^2+C* (15+1)+D,移除能被5整除的项 →A+B+C+D,所以只需要判断A+B+C+D能否被5整除。
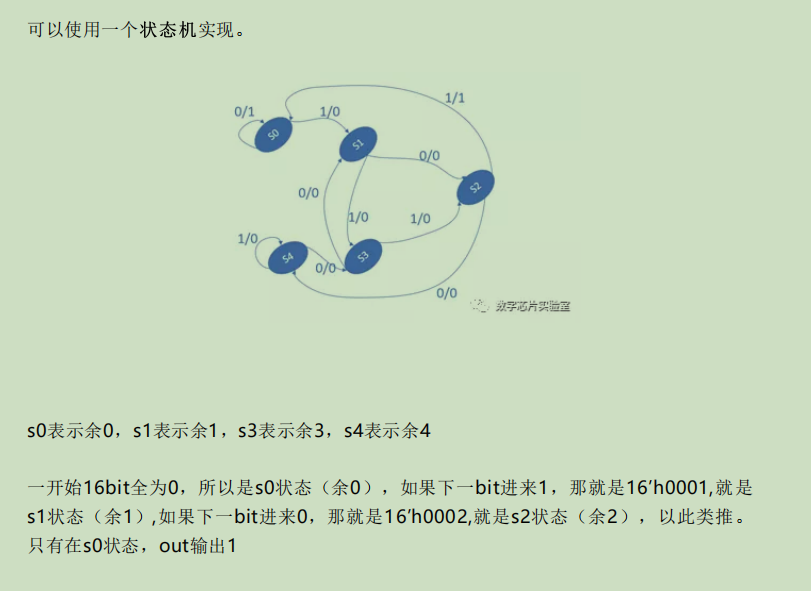
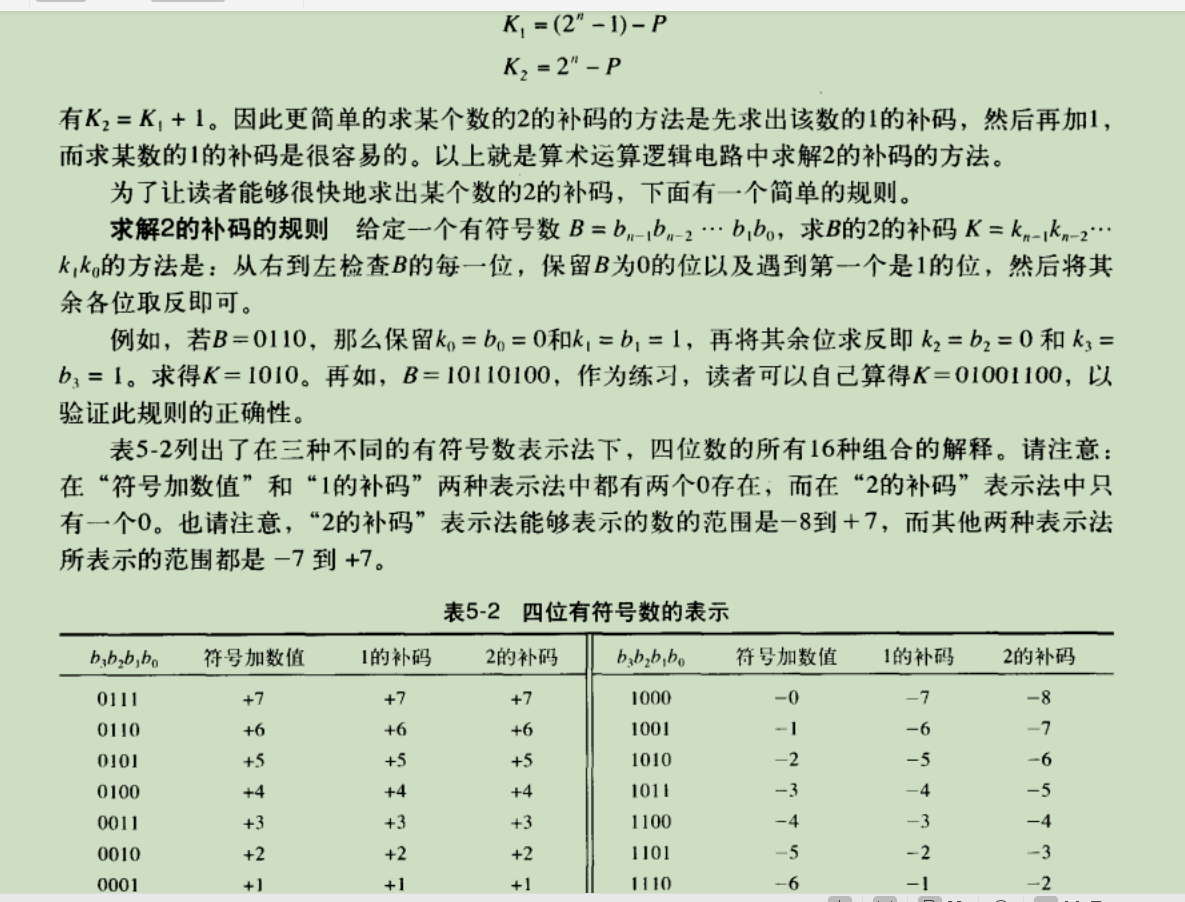
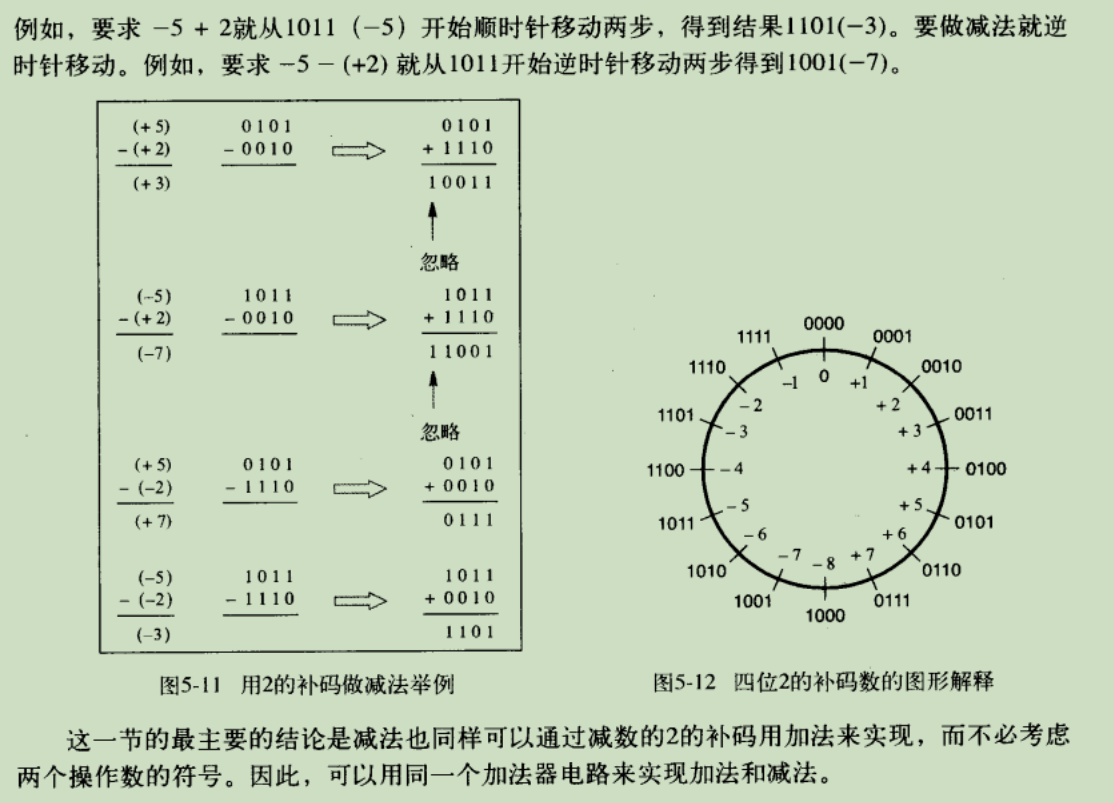
38.负数的表示方法



39.initial串 / fork jion并
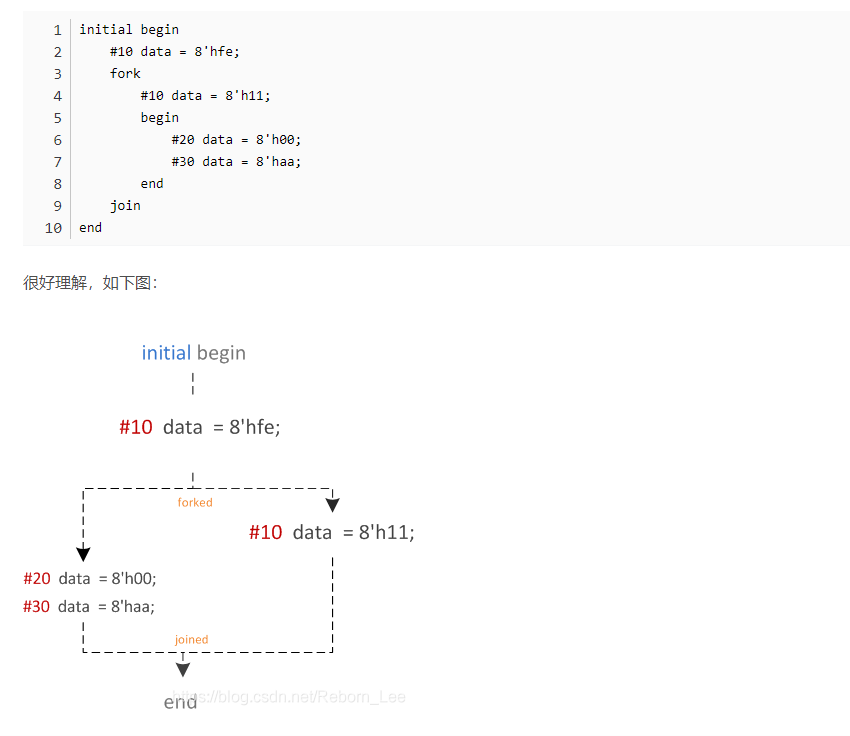
40.二态和四态变量

41. Verilog
1.描述语言4个层次

2. verilog 中缺省的数据类型为?
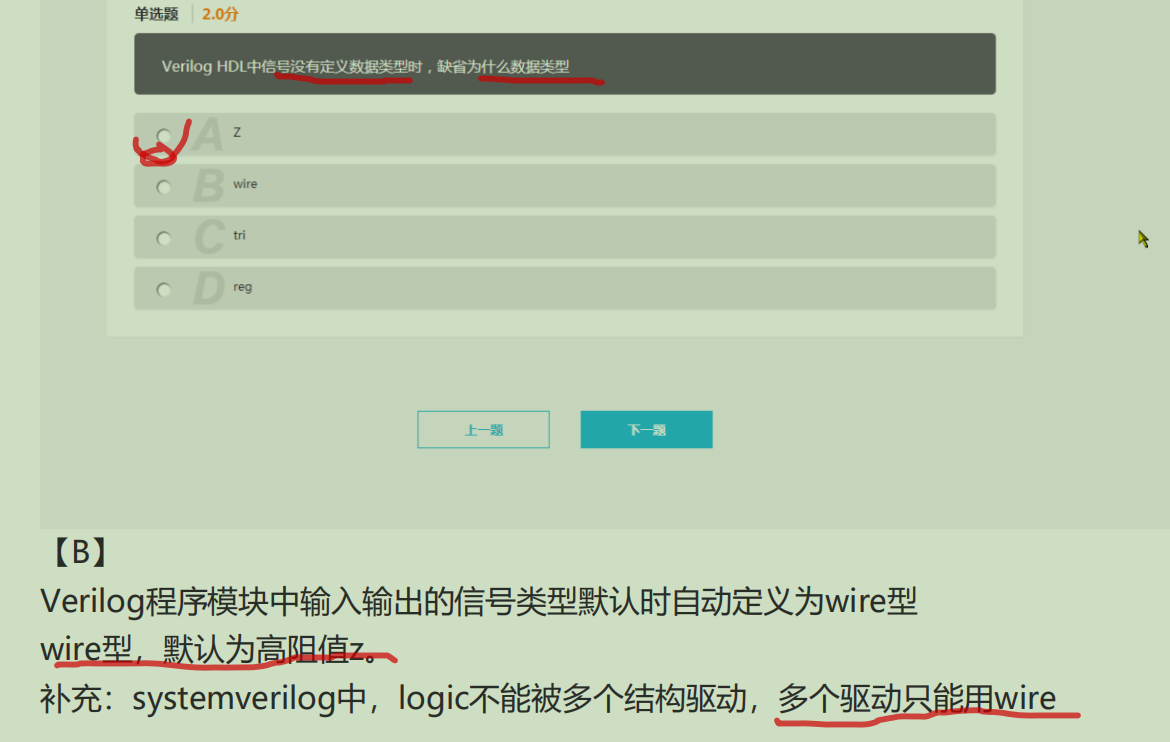
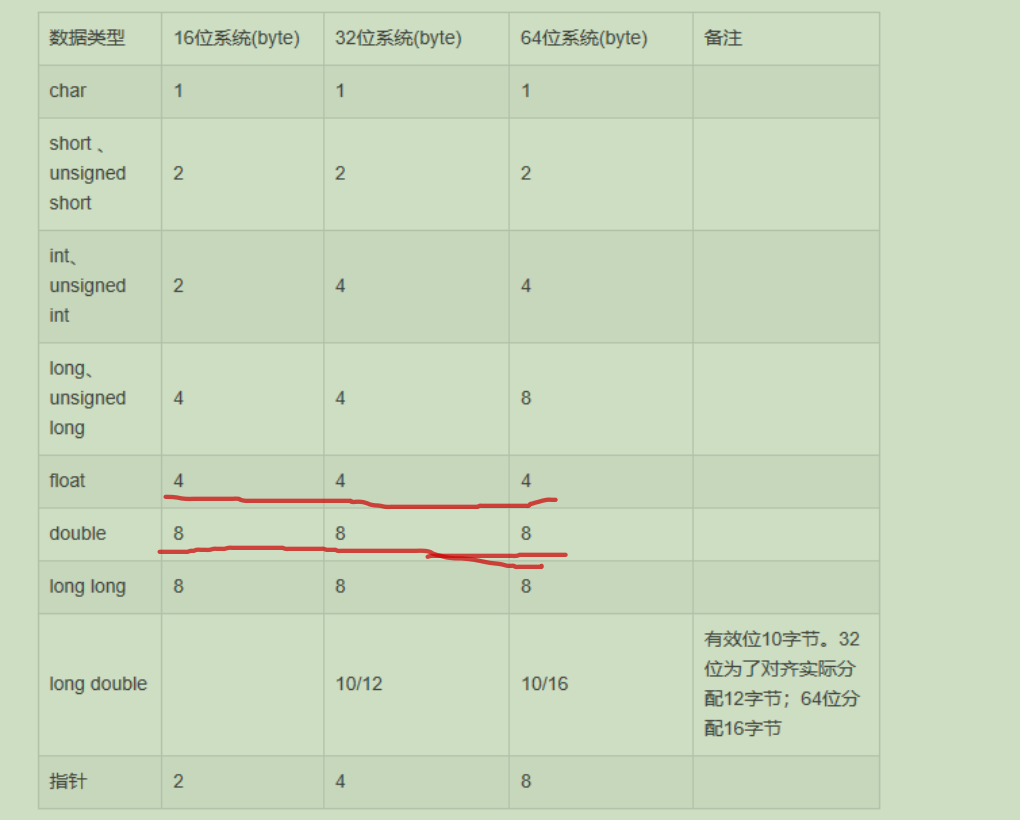
42.基本数据类型的存储空间长度排序为
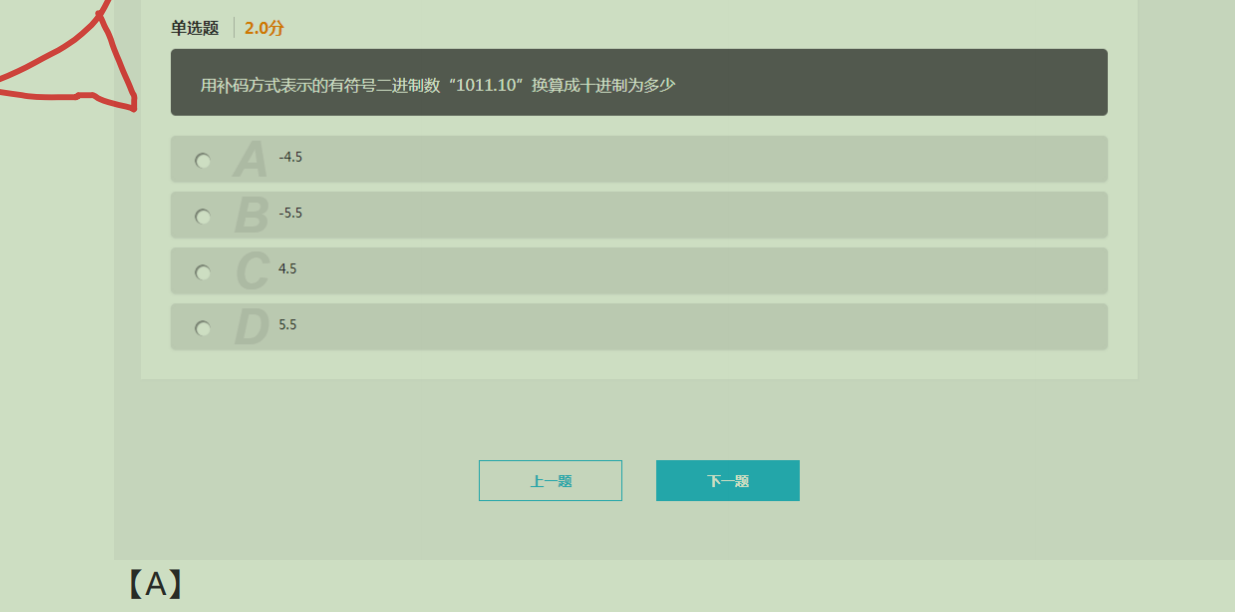
43.补码二进制转十进制
44. 操作系统:
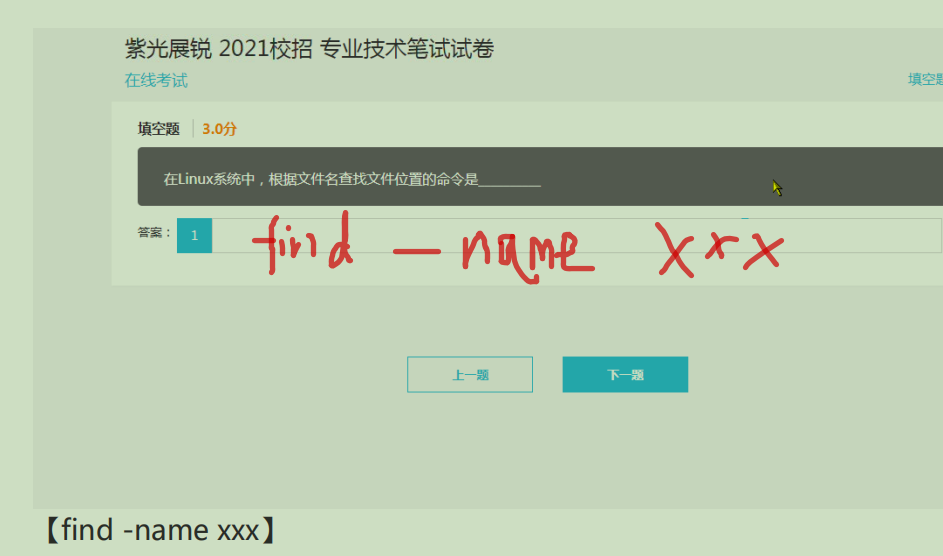

45. timescale
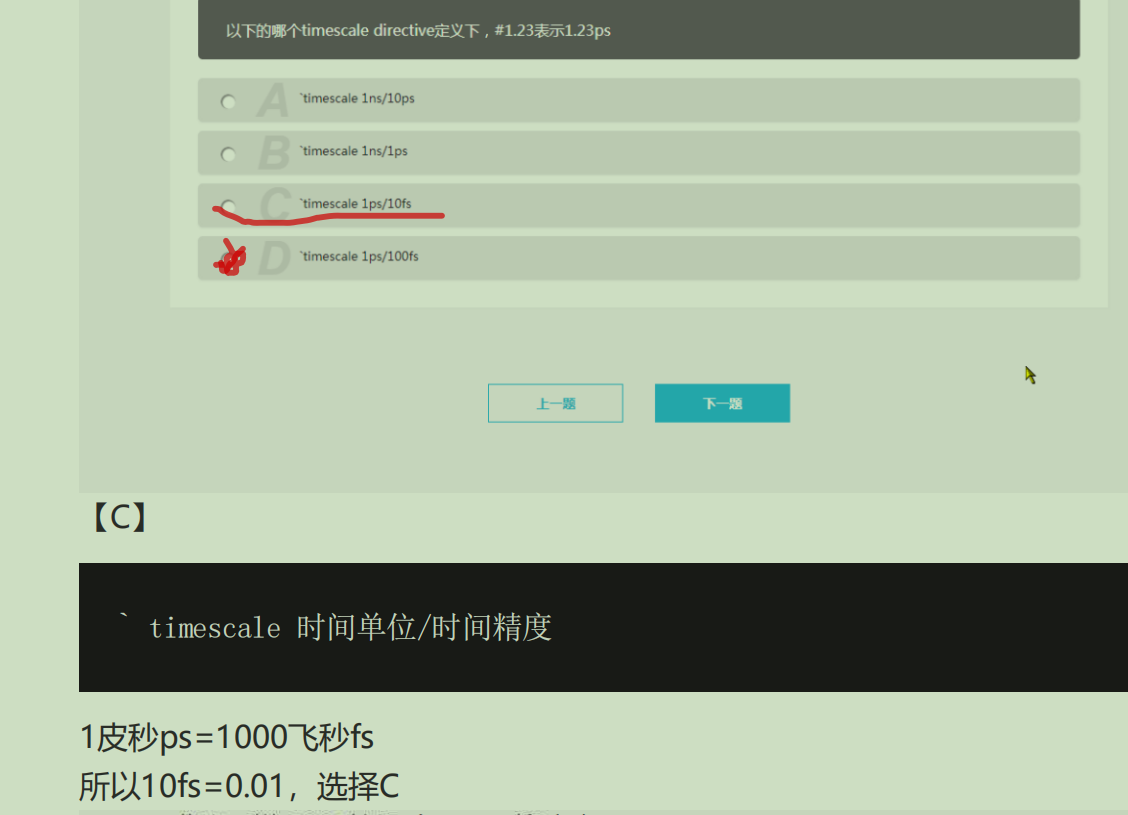
46.串行总线
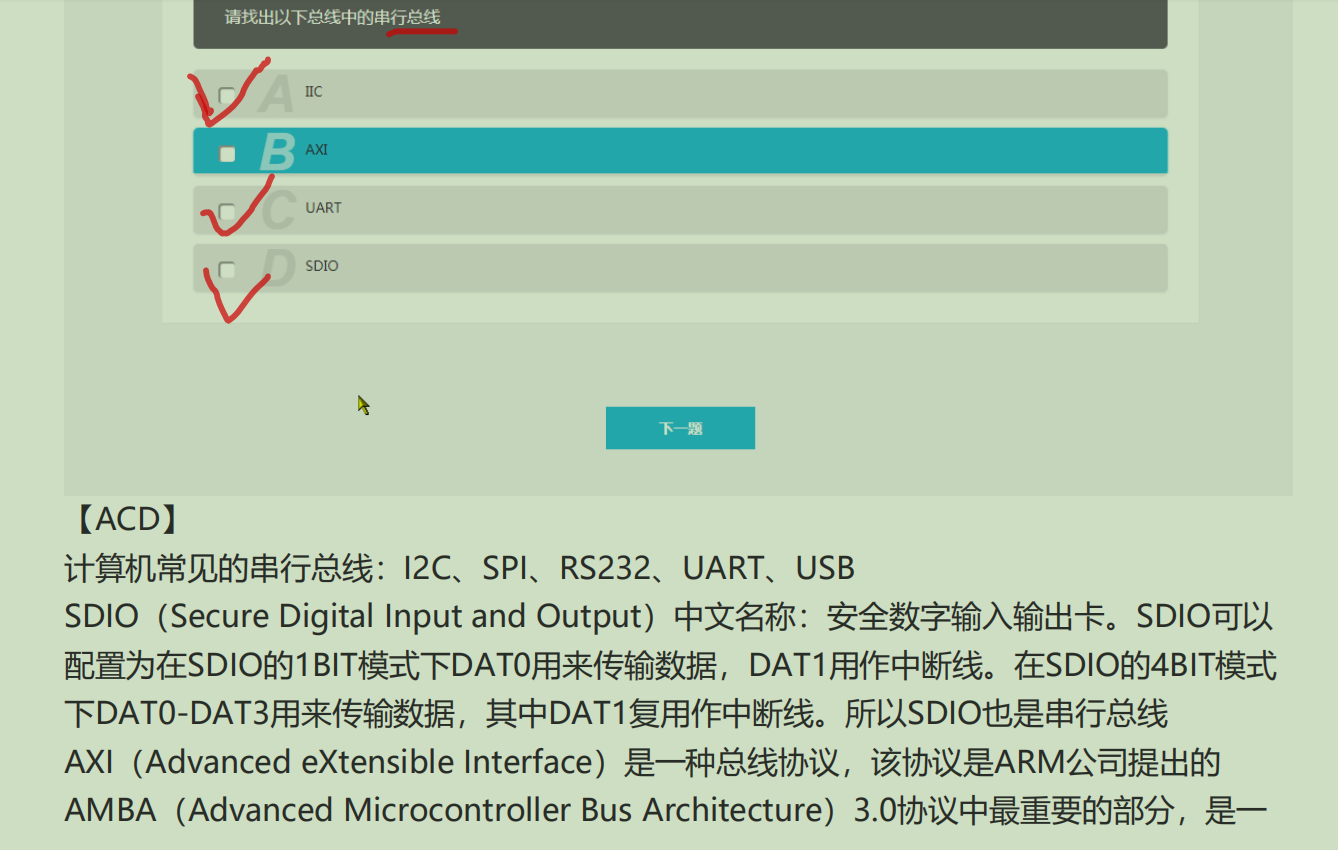

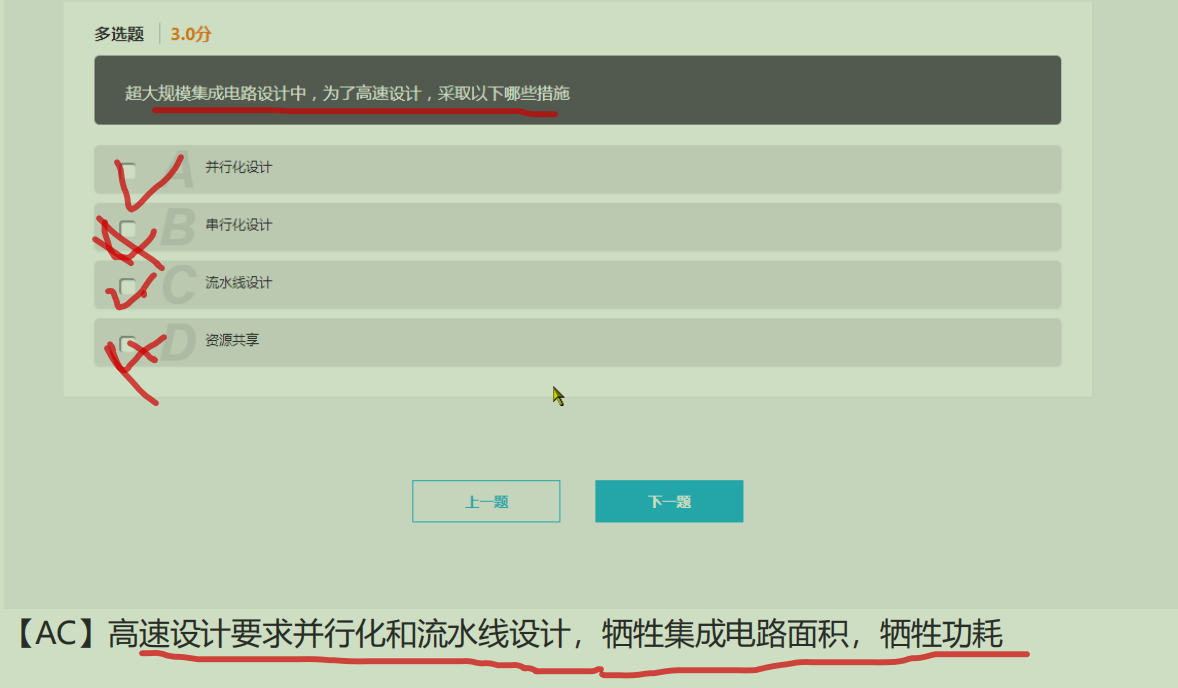
47.大小端模式
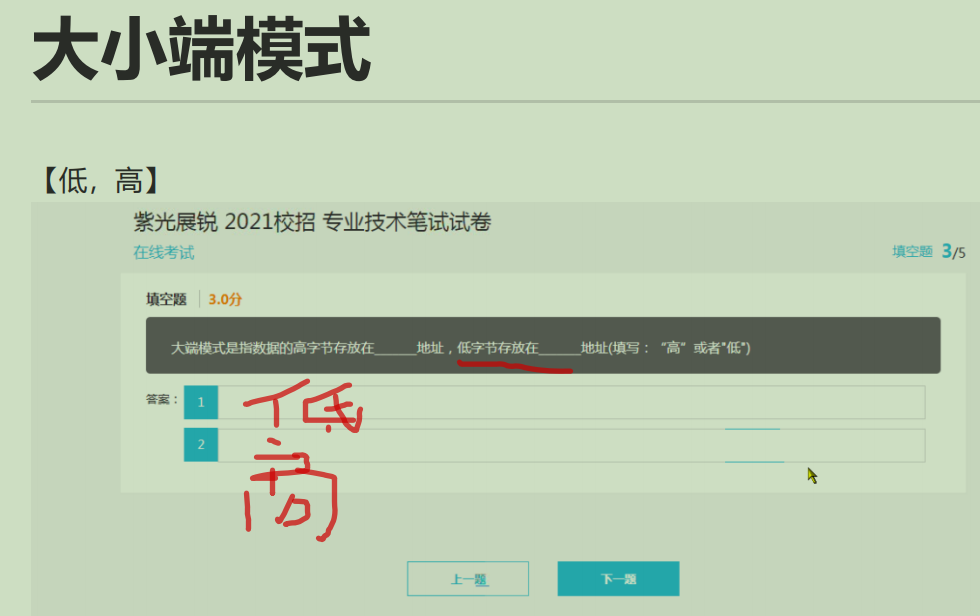
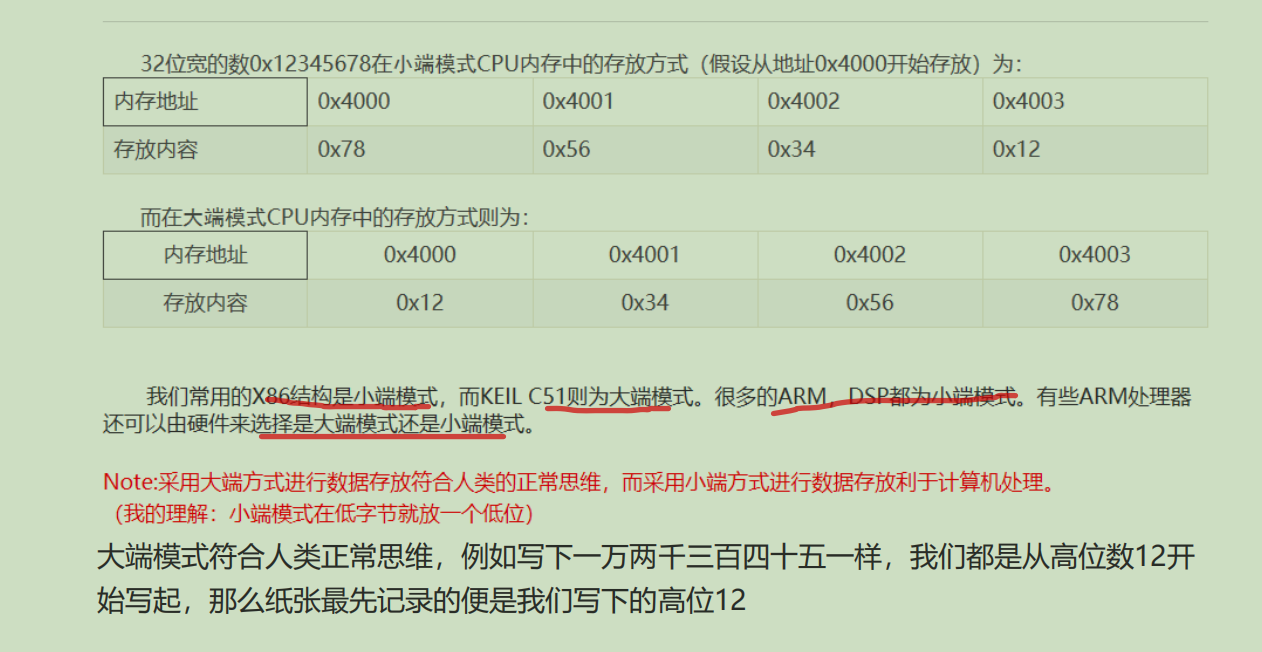
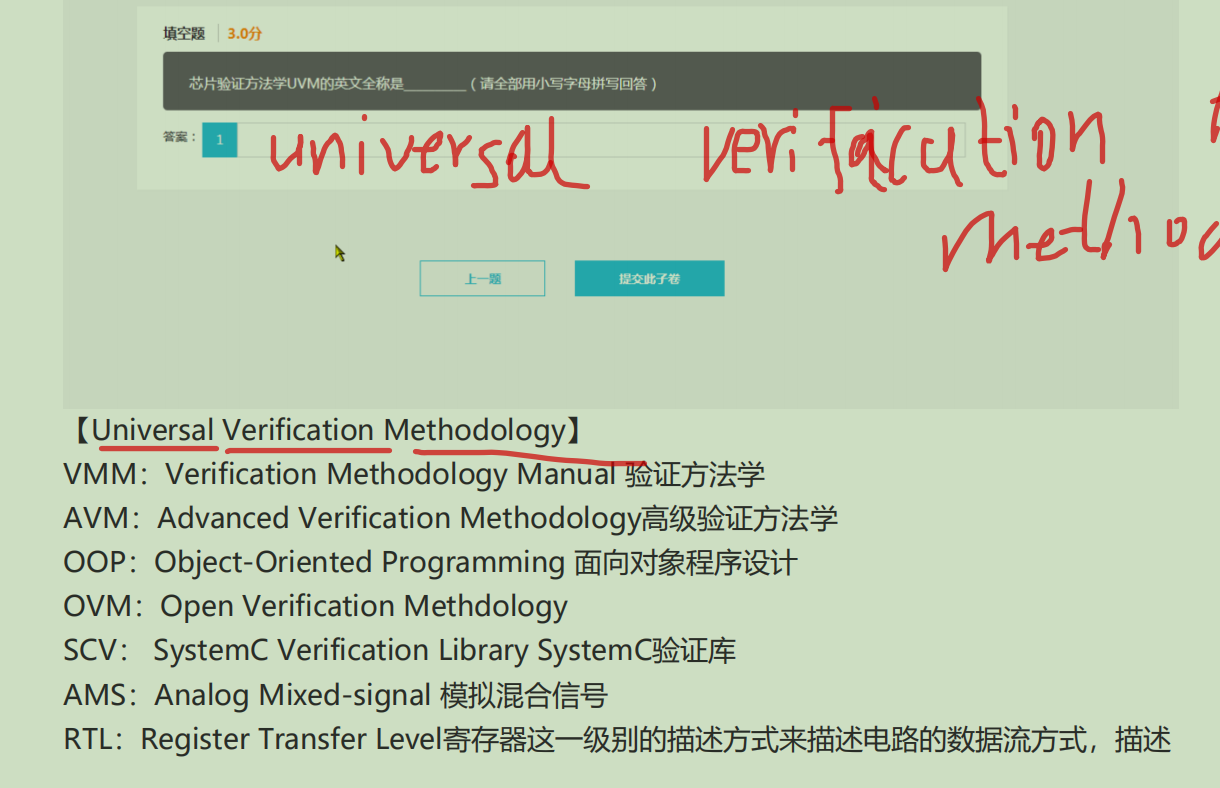
48.缩写全称

49.Memory hierarchy (存储结构)
1.当前计算机一般都采用高速缓存-主存-辅存三级存储器结构
https://mp.weixin.qq.com/s?__biz=Mzg5MDIwNjIwMA==&mid=2247487373&idx=1&sn=6597932fccbf8f6b71a360fbf7fe8814&chksm=cfe16d1af896e40ca91be8fe210603f637392dae165b43a81331c0973d6d7c58d12aa78fbe97&scene=21#wechat_redirect
高速缓存也称为Cache,它是位于CPU与主存之间的一种高速存储器,Cache分为片内Cache和片外Cache,片内Cache速度已接近CPU的速度,Cache由SRAM组成,存储量最小,速度最快
5、以下是对Cache-主存-辅存三级存储系统中各级存储器的作用,速度,容量的描述,其中完全正确的是(b )。(大疆FPGA逻辑岗B卷)
A 主存用于存放CPU正在执行的程序,速度慢,容量极大
B Cache用于存放CPU当前访问频繁的程序和数据,速度快,容量小
C 加大Cache的容量可以使主存储能够存放更多的程序和数据
D 辅存用存放需要联机保存但暂不执行的程序和数据,速度快,容量极大
解析:本题目主要考察了计算机系统中Cache的认识
当前计算机一般都采用高速缓存-主存-辅存三级存储器结构。高速缓存也称为Cache,它是位于CPU与主存之间的一种高速存储器,Cache分为片内Cache和片外Cache,片内Cache速度已接近CPU的速度,Cache由SRAM组成,存储量最小,速度最快,所以B选项正确。
常用有一级缓存(L1)、二级缓存(L2)、三级缓存(L3)。设置 Cache的目的在于将当前程序运行中快速将使用的一组数据或即将执行的一组指令由主存复制到Cache中,使CPU可以从 Cache中快速地获取所需要的指令和数据,当CPU访问存储器时,首先检查 Cache,如果要访问的信息已经在Cache中则CPU可以快速地获取信息,若不在,CPU必须访问主存,同时把包含所访可的信息的数块复制到Cache中更新,即Cache用来改善主存与CPU的速度匹配回题。
所以主存是电脑中主要部件,是CPU能直接寻址的存储空间,计算机中的主存储器主要由存储体、控制线路、地址寄存器、数据寄存器和地址译码电路五部分组成,它与辅助存储器相比有容量小、读写速度快;与Cache相比容量大、读写速度慢,所以总的来说容量适中,速度适中,所以A选项错误。主存一般采用半导体存储单元,包括随机存储器(RAM)、只读存储器(ROM)。
辅存为外部存储器,如硬盘、U盘、光盘等,它不能直接被CPU直接访问,一般用于存放暂时不用或主存放不下的程序和数据。当CPU处理信息时,首先查看所需要的数据是否在内存,若已经在则直接访问,此时称Cache命中。若不在,由辅助软硬件将有关信息从辅存上分段或分页调入内存,再由CPU访问。辅助存储器用于扩大存储空间,所以D选项错误。
使用 Cache-主存-辅存结构的存储器系统,提高了存储器的速度,同时总存储量又相当于辅存容量,有效解决了对存储器高速度,大容量,低成本的矛盾。而C选项中提到的方法与之矛盾,所以C选项也错误。Cache-主存和主存-辅存的相同点:都是在CPU的控制下进行信息交换Cache-主存和主-存辅存的不同点:前者是主机内部进行信息交换;后者是主机与外部设备之间进行信息交换。
存储系统的层次结构
寄存器-(通过指令)-Cache-(通过块)-内存-(通过页表)-磁盘-(通过文件)-磁带
50.二值逻辑和四值逻辑
编码时一定要注意操作符左右两侧的符号类型要一致
二值逻辑:包括 bit, byte, shortint, int, longint等,均为有符号类型(bit除外);这些类型的值只包含{0,1},目的是模拟计算机验证环境,提高仿真性能,节约空间。若有四值逻辑数给其赋值,x,z会默认被赋值为0,因此二值逻辑数要远离DUT
四值逻辑:包括logic, integer, reg, wire,time等,均为无符号变量(integer除外);目的是模拟外部物理世界
51.芯片参数

52.时钟抖动(jitter) 和时钟偏斜(skew)
https://www.cnblogs.com/zeushuang/archive/2012/07/04/2575849.html

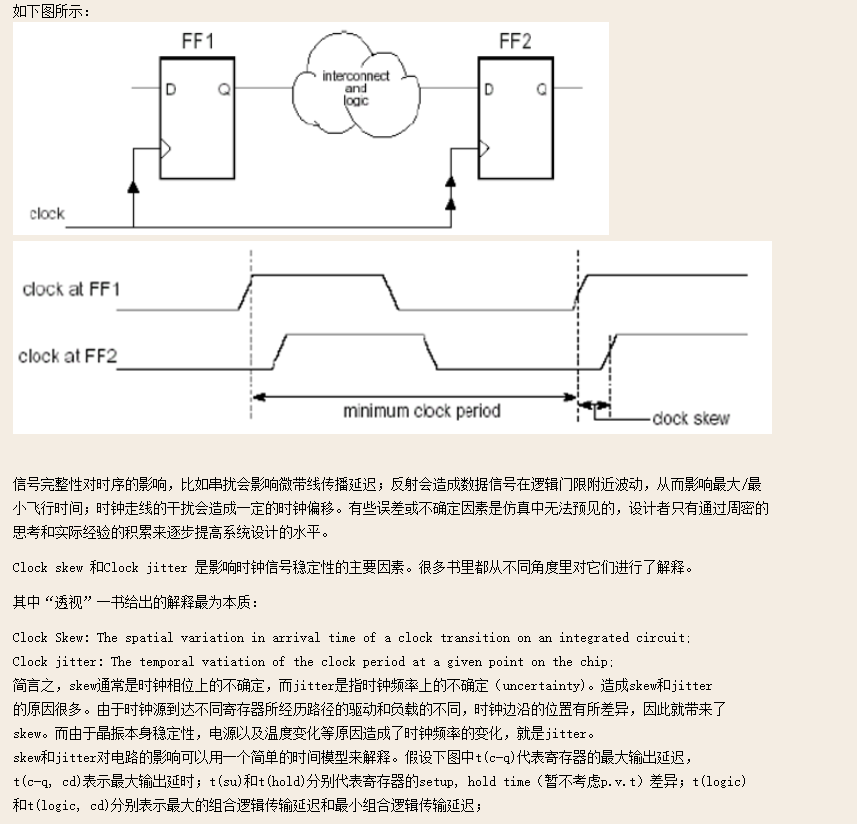
53.DCM/PLL/DLL/MMCM
https://blog.csdn.net/hxt691083776/article/details/116449749
54.理解FPGA中的RAM、ROM和CAM;ROM、RAM、DRAM、SRAM、FLASH
https://blog.csdn.net/i13919135998/article/details/52117053
55. 与非门、或非门可以表达任何逻辑表达式

56.锁存器(latch)和触发器(filp-flop)的概念和区别?为什么多用register。行为级描述中latch如何产生的?
原文链接:https://blog.csdn.net/gemengxia/article/details/108409881
解析:
1)锁存器是什么?
从概念上讲,锁存器是电平触发的存储单元,数据存储的动作取决于输入时钟(或者使能)信号的电平值。简单而言,锁存器的输入有数据信号和使能信号,当处于使能状态时,输出随着输入变化而变化,当不处于使能状态时,输入信号怎么变化都不会影响输出。
2)触发器是什么?
触发器是对脉冲边沿敏感的器件,它的变化只会在时钟的上升沿或者下降沿到来的瞬间变化。
3)区别?
锁存器是电平触发的,触发器是边沿触发的。如果是电平触发的,当使能的时候,如果输入信号不稳定,那么输出就会出现毛刺。而触发器就不会出现这种情况,它的变化只会在边沿有效的时候触发。
4)register是什么?
register是寄存器,用来暂时存放参与运算的数据和运算结果。在实际的数字系统中,通常把能够用来存储一组二进制代码的同步时序逻辑电路称为寄存器。由于触发器有记忆功能,因此利用触发器可以方便地构成寄存器。由于一个触发器能够存储一位二进制码,所以把n个触发器的时钟端口连接起来就能构成一个存储n位二进制码的寄存器。
5)为什么多用register?
换个角度讲,为什么少用latch呢?首先,latch是电平触发的,这样就容易产生毛刺;其次,latch将静态时序变得极其复杂;再者latch会浪费硬件资源(对FPGA而言)。因为FPGA当中,是没有latch单元的,要生成latch单元需要耗费其他资源。
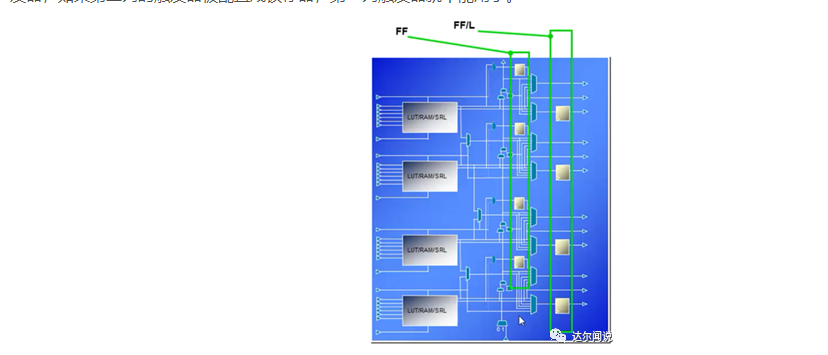
以xilinx器件为例,如下图所示,是slice的结构,每个slice包含两列触发器,第一列只可以配置成触发器,第二列可以配置成锁存器和触发器,如果第二列的触发器被配置成锁存器,第一列触发器就不能用了
6)latch是如何产生的?
网上大多数指出,由于if或者case语句的逻辑表达不完全产生的。其实就我个人而言,这样说并不完全正确。首先需要区分一点,我们定义一个类型的时候,单纯的定义reg或者wire其实并不代表它最终实现的真正类型,这得看我们写的代码,下面代码:
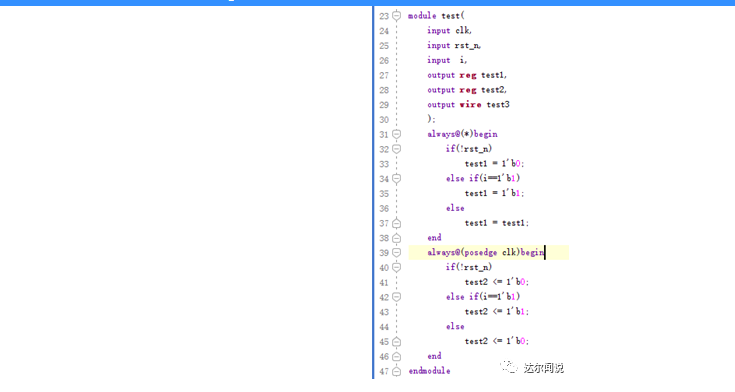
在这段代码里面,test1和test2都是定义为reg类型的,都放在了always语句块里面,除了触发条件不同,其他都相同,下面看看在Vivado综合之后的结果:
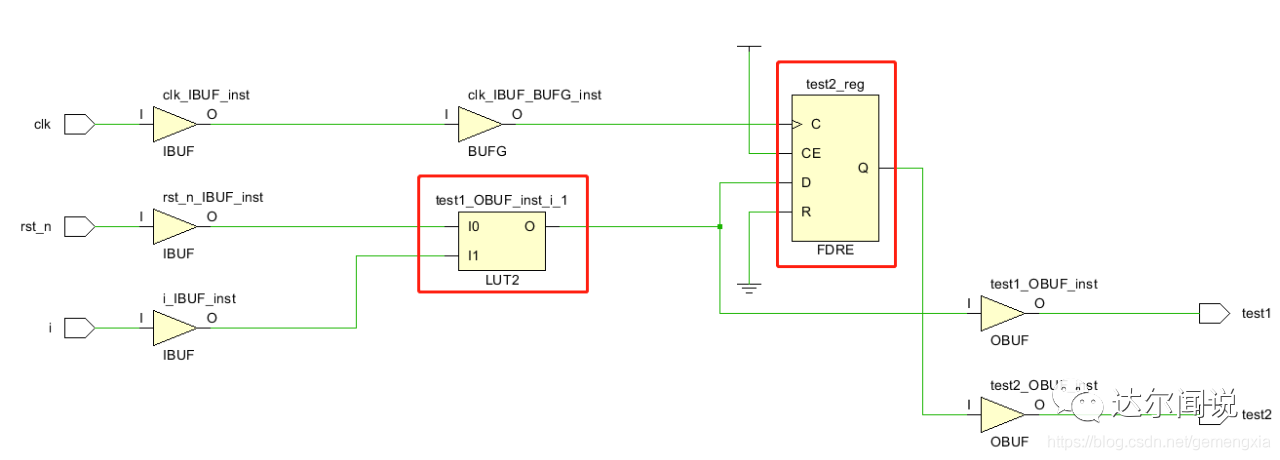
可以看到test2是综合成寄存器(触发器)的,而test1直接就“消失”了,被“安排”在了一个LUT“里面”,这也正说明,定义并不代表着最终的结果。在这里,always(*)里面的所谓“reg”,其实和wire没有区别,为了方便称呼,我把wire和这类“reg”统称作“类wire”。
前面铺垫了这个是为了什么呢?为了说明以下会产生latch的两种情况:
①类wire型的数据“自己等于自己”的情况下会产生latch;
②类wire型的数据,由于if或者case语句的逻辑表达不完全,会产生latch。
57.时序分析案例
题目中分别给出的每个参数的max delay和min delay,分别对应的慢速模型和快速模型,在分析建立时间时是应该用慢速模型,在分析保持时间时应该用快速模型。
https://blog.csdn.net/gemengxia/article/details/108409881
这个链接的最后一题是时序分析题,但是我分析完发现第一题其实他分析的有点问题;
F1到F2的保持时间余量:Thold=Tcq+Tbuf+Tmux-(0-Tbuf)-Thold=2.5ns>0
F2到F1的保持时间余量:Tcq+Tmux-(Tbuf-0)-Tsetup=-0.5ns<0
所以还应该在F2与F1之间加一个BUF。
58.跨时钟域处理
.以下不能对多bit的数据总线的时钟异步处理的是: (C )
A、Dmux synchronizer
B、Gray-code
C、寄存器同步
D、FIFO
解析:寄存器同步用来做单bit数据的异步处理;Dmux Synchronizer(数据总线同步器)是用来同步多比特数据的【https://www.cnblogs.com/lyc-seu/p/12441366.html#方法五:dmux同步器】;
https://www.cnblogs.com/lyc-seu/p/12441366.html
59.outsatanding/out-of-order/interleaving
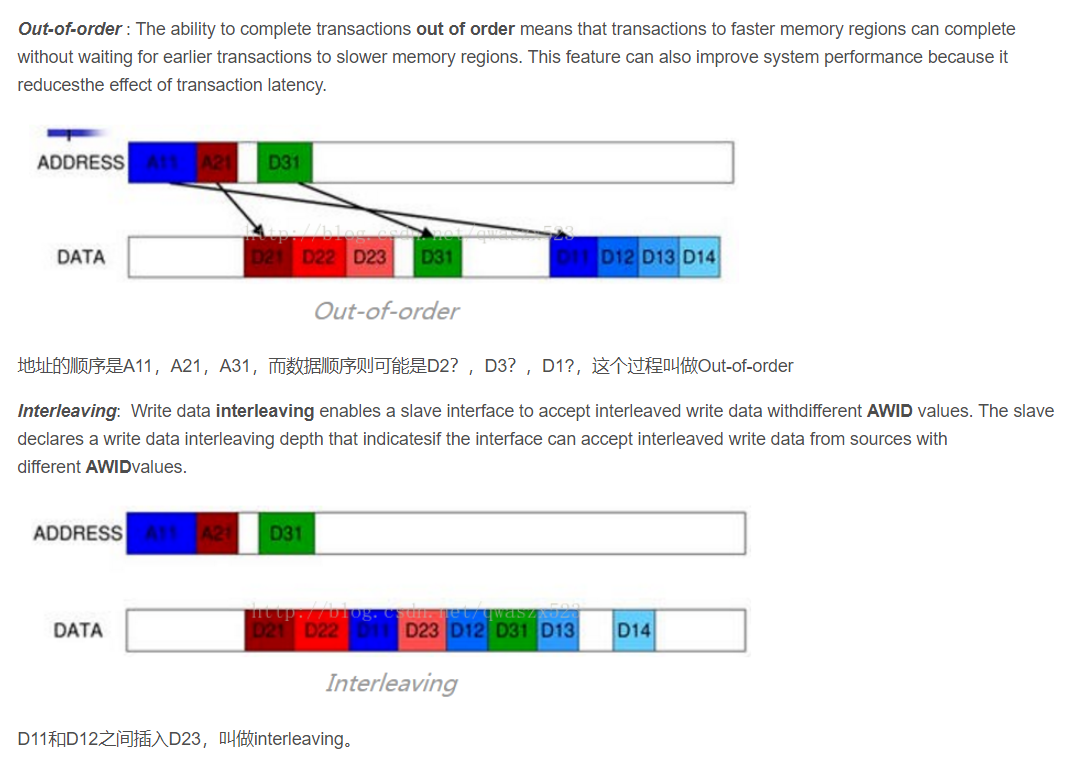
简单而言,outsatanding是对地址而言,一次burst还没结束,就可以发送下一相地址。而out-of-order和interleaving则是相对于 transaction,out-of-order说的是发送transaction和接收的cmd之间的顺序没有关系,如先接到A的cmd,再接到B的cmd,则可以先发B的data,再发A的data;interleaving指的是A的data和B的data可以交错,如A1 B1 A2 B2 B3……(同一个事务之间的不同数据要按顺序,例如不能出现A1 B2 A2 B1,)
https://blog.csdn.net/fengxiaocheng/article/details/97128708?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163057259116780271519525%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=163057259116780271519525&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v29_ecpm-1-97128708.first_rank_v2_pc_rank_v29&utm_term=AXI总线中讲到的interleaved和out+of+order&spm=1018.2226.3001.4187

60.axi3和axi4的区别
1.burst length
AXI4对burst length进行了扩展:AXI3最大burst length是16 beats,而AXI4支持最大到256 beats,但是仅支持INCR burst type 超过16 beats,exclusive access也不能超过16beats;。但是根据经验来讲各家公司好像也没太遵循这个规则,很多AXI3的IP awlen/arlen的位宽是多少,支持多大的burst length也是根据自己的情况来定的,其实这个对protocol的完整性没什么影响,所以大家也是根据自己的系统需求来定,但一般还是2的n次方。
2.增加QoS(quality of service)
其实ARM自己也没有明确认为好AWQOS和ARQOS的意义,比较像sideband信号,spec里面举例是说用于标识command的priority。但其实很多IP自己有urgent,ultra,flush等sideband信号实现的。
增加Multiple region interface
3.增加Multiple region interface
增加了AWREGION和ARREGION,这个比较属于系统组的应用。以我实际碰到case的经验来讲有几个好处。
1.给transaction标识region,从而很方便的实现logical adress到physical address的address mapping,如一个logical address标识为不同的region,就可以mapping到不同的物理地址上去。所以不需要slave用额外的decoder去支援不同的逻辑地址。
2. 通过划分region,对某些physical allocation进行保护,别如某个region只能被non-secure write,某个region只能被secure write
4. 修改了write response dependencies
在AXI3中规定一定要在write channel结束之后slave才能B channel response; 而在AXI4中额外规定AW channel结束才可以回write response。
这是因为,如果发生W channel before AW channel的case时,没有AXI4的规定,B channel也有可能先于AW channel完成。
说实话,即使碰到过W channel before AW channel的情况,也是说W可以先于AW,但是slave一般会把wready先拉低,等AW channel完成后才收data。所以没有碰到过B channel先于AW channel完成的情况。
5.AWCACHE/ARCHACHE的修改
AXI3中对bit0定义为cacheable bit,但在AXI4中定义为modifiable bit。用于标识tansaction是否被允许修改,比如拆分成多个小的transaction或被merged成其它transaction.(除大于16beats以上的transaction)
其它bit没太接触过,不做解释。感觉这一块对系统应该比较相关,修改也比较大
6.Removal of WID
为了减小设计复杂度,减小pin-count,AXI4将W channel的WID给拿掉了,也就是说,AXI4没有W channel的out of order和interleave特性了。所有data必须是in order的。
7.AXI4-lite
这个lite协议其实主要目的是简化protocol,用于系统上对register的访问,到目前接触的项目一般都是通过APB,I2C,RGST或自己定义的ATB类似的协议处理寄存器相关的访问,所以只简单了解过AXI4-LITE,不作说明
最后
以上就是清脆黑米最近收集整理的关于FPGA备战秋招---常用知识点1.CMOS基本逻辑电路2.异或逻辑3.卡罗图简化函数4.二进制,格雷码互转5.产生锁存器latch6.异步复位同步释放7.SRAM,FALSHMEMORY,DRAM,SSRAM及SDRAM的区别?8 如何防止亚稳态9.奇数,偶数,任意分频10.FIFO11.快时钟域脉冲信号到到慢时钟域信号12.i++,i–,++i,–i13.BUCK电路14.数字IC设计流程15.为什么使用独热码,并不使用二进制编码或者格雷码16 RAM和ROM17.&和&&18.状态机19.的全部内容,更多相关FPGA备战秋招---常用知识点1.CMOS基本逻辑电路2.异或逻辑3.卡罗图简化函数4.二进制,格雷码互转5.产生锁存器latch6.异步复位同步释放7.SRAM,FALSHMEMORY,DRAM,SSRAM及SDRAM的区别?8内容请搜索靠谱客的其他文章。








发表评论 取消回复