现如今,我们已经从互联网时代过渡到大数据时代。无论你对大数据知识了解多少,这个名词肯定不会陌生。

今年年初开始接触大数据平台的相关测试,由于之前对大数据知识的积累并不多,所以测试期间也是恶补了许多大数据的知识。
下面将总结的一些常见、易混淆的大数据相关概念分享给大家。
什么是大数据
大数据,官方定义是指那些数据量特别大、数据类别特别复杂的数据集,这种数据集无法用传统的数据库进行存储,管理和处理。
大数据的主要特点为:
- 数据量大(Volume)
- 数据类别复杂(Variety)
- 数据处理速度快(Velocity)
- 和数据真实性高(Veracity)
合起来被称为4V。
还有的将大数据特点定义为6V模型,即增加了Valence(连接)、Value(价值)2V。
hadoop生态系统
在了解了什么是大数据之后,我们先了解下开源大数据的鼻祖——hadoop(2.0)生态环境。
可以用下面的层次结构图来表示。
大数据是未来的发展方向,正在挑战我们的分析能力及对世界的认知方式,因此,我们与时俱进,迎接变化,并不断的成长!大数据学习群:868加上【八四七】最后735 一起讨论进步学习
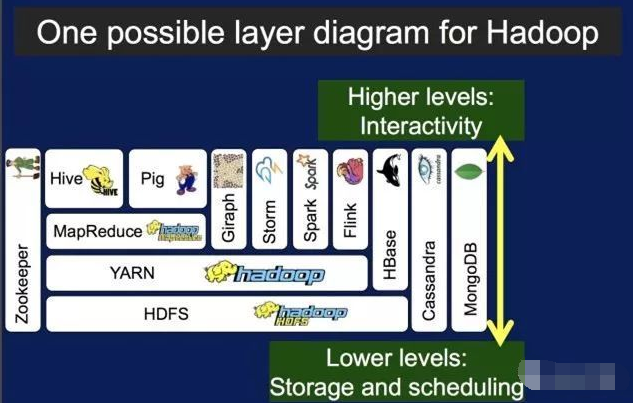
从图中我们可以看到Hadoop2.0分为四层架构。
- 底层为存储层。 HDFS:分布式存储文件系统,几乎所有上层应用的基础。
- 中间层是资源及数据管理层。 YARN:用于调配底层资源、管理进程的管理器
- 上层为计算引擎。 MapReduce:用于通过YARN调配的资源执行简单程序
- 顶层为查询分析层,主要对计算引擎进行封装。 Hive:高等级的编程模型,类似SQL的查询 Pig:高等级的编程模型,数据流脚本
在图中,我们可以很清楚的看到spark贯穿了计算引擎层以及顶层查询。
这里我们将Hadoop和Spark这两个易混淆的概念做下比较。
Hadoop实质上更多是一个分布式数据基础设施,它包含文件存储、计算框架、资源调度等部分。
而Saprk仅仅一个专门用来对那些分布式存储的大数据进行处理的工具,它并不会进行分布式数据的存储。
Hadoop提供MapReduce数据处理功能,所以可以完全抛开Spark,使用Hadoop自身的MapReduce来完成数据的处理。
相反,Spark也不是非要依附在Hadoop身上才能生存。但它没有提供文件管理系统,所以,它必须和其他的分布式文件系统进行集成才能运作。
这里我们可以选择Hadoop的HDFS,也可以选择其它基于云的数据系统平台。
大数据常见概念分类
大数据相关的概念大家都听过不少:HDFS、MapReduce、Spark、Storm、Spark Streaming、Hive、Hbase、Flume、Logstash、Kafka、Flink、Druid、ES等等。
是否感觉眼花缭乱?
下面我们将这些常见的概念进行分组。
同一组的框架(工具)可以完成相同的工作,但各自使用的场景有所差异。
01
计算框架
离线计算:Hadoop MapReduce、Spark
实时计算:Storm、Spark Streaming、Flink
02
存储框架
文件存储:Hadoop HDFS、Tachyon、KFS
NOSQL数据库:HBase、MongoDB、Redis
全文检索:ES、Solr
03
资源管理
YARN、Mesos
04
日志收集
Flume、Logstash
05
消息系统
Kafka、StormMQ、ZeroMQ、RabbitMQ
06
查询分析
Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、Kylin、Druid
大数据任务
下面笔者主要介绍数据处理平台中任务的一般流程来方便大家更好地了解上文提到的框架。
大数据任务一般分为离线任务和实时任务。
但不论是离线还是实时任务主要包含以下三个过程:数据源抽取数据、数据转换、加载到数据源。
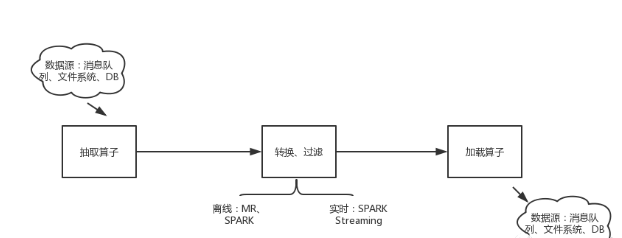
数据源概念:主要就是我们的存储系统。
笔者测试的大数据处理平台的离线任务的数据源一般包含Hdfs、Hive、Mysql。实时的数据源为Kafka。
下来重点说下具体的转换过程。
转换一般主要分为聚合(group by)、连接(join)等操作。
这里笔者以一个实际的例子-留存分析给大家介绍大数据平台是怎么处理的。
留存分析本质是求两个数据源之间交叉的部分占其中一个的比率,由此可见,在留存分析中最重要的算子就是连接运算和聚合运算。
离线任务与实时任务
最后,说下实时和离线任务的区别。
在很多人印象中,离线=批量,实时=流式,其实这种观点并不是完全正确的。
离线和实时指的是数据处理的延迟;
批量和流式指的是:数据处理的方式。
像我们熟悉的spark Streaming框架,其实是微批处理框架(累计一定时间,通常为几秒的数据为一个batch),每一次批处理的数据量较小,以此达到接近实时处理的目的。
总结
本篇主要介绍了大数据相关的一些基本概念以及各种框架的分类。作为大数据入门的一些必备知识。
最后
以上就是可爱乌冬面最近收集整理的关于大数据基本概念的全部内容,更多相关大数据基本概念内容请搜索靠谱客的其他文章。








发表评论 取消回复