kubernetes pod内容器状态OOMKilled和退出码137全流程解析 - 简书
使用event_control监听memory cgroup的oom事件 - 简书
kubernetes/k8s CRI分析-kubelet删除pod分析 - 良凯尔 - 博客园
在kubernetes的实际生产实践中,经常会看到pod内的容器因为内存使用超限被内核kill掉,使用kubectl命令查看pod,可以看到容器的退出原因是OOMKilled,退出码是137。
文章导读
cgroup简介与使用
linux epoll原理分析
containerd代码解析
kubelet代码解析
使用event_control监听oom事件
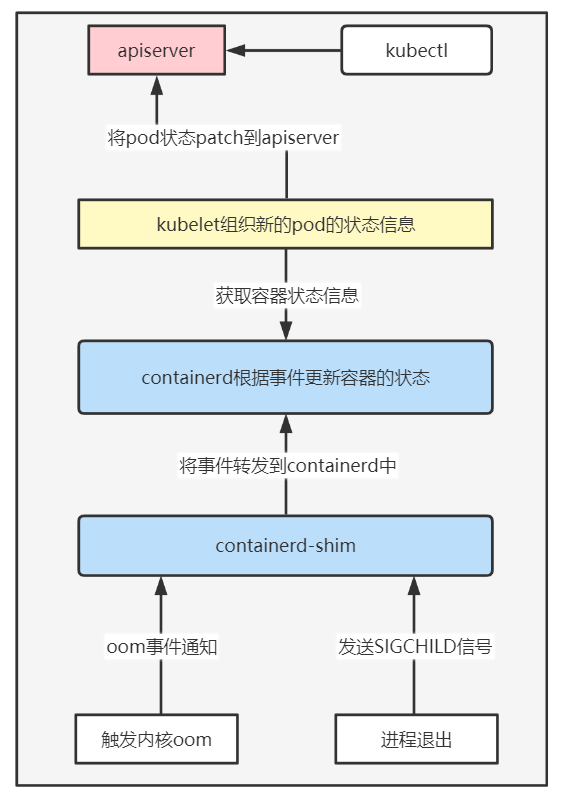
经过前面几篇文章的铺垫与递进,本篇终于可以进入正题,已以下两条主线进行分析。
- 容器的退出原因OOMKilled是如何经由containerd更新到kubelet,并最终更新到Pod的status中。
- 退出码为何是137。
本文的分析思路是由下至上,先分析内核的oom是如何触发的,再分析进程被kill掉后,退出码是何时赋值的,最后再分析containerd-shim,containerd,kubelet是如何处理进程的oom状态和退出码。
场景再现
本次实验基于4.19内核的centos的系统,kubernetes版本为1.23.1,kubelet的运行时配置为containerd,containerd版本为1.4,cgroup使用v1版本。
首先,编辑一个Pod的yaml文件,配置Pod的restartPolicy为Nerver,内存限额设置为50M,容器镜像为mem_alloc:v1。该容器启动后会不断申请并使用内存,直到内存超限,被内核kill掉。
[root@localhost oom]# cat pod_oom.yaml
apiVersion: v1
kind: Pod
metadata:
name: lugl-oom-test
spec:
restartPolicy: Never
containers:
- name: oom-test
image: docker.io/registry/mem_alloc:v1
imagePullPolicy: IfNotPresent
resources:
limits:
memory: "50Mi"
使用kubectl create -f pod_oom.yaml创建该pod,过一会儿使用kubectl查看pod的状态(删除掉不相关的字段信息)。可以看到容器的退出原因(reason)为OOMKilled,退出码(exitCode)为137。其中还有个字段lastState可以记录上一次的容器的状态信息,这里为了简化分析,忽略该字段。
[root@localhost oom]# kubectl get pods lugl-oom-test -o yaml
apiVersion: v1
kind: Pod
spec:
containers:
- image: docker.io/registry/mem_alloc:v1
imagePullPolicy: IfNotPresent
name: oom-test
resources:
limits:
memory: 50Mi
requests:
memory: 50Mi
restartPolicy: Never
status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2022-02-20T02:10:30Z"
status: "True"
type: Initialized
containerStatuses:
- containerID: containerd://388f01cfb6b8ba2817ff85ef8e72c654f866200d96123a623a73e0304e4934cf
image: docker.io/registry/mem_alloc:v1
imageID: sha256:3bd194272e76fa429b1c5df19d91bcf47eacc1ed07e3afe378ec3d7b49524ef0
lastState: {}
name: oom-test
ready: false
restartCount: 0
started: false
state:
terminated:
containerID: containerd://388f01cfb6b8ba2817ff85ef8e72c654f866200d96123a623a73e0304e4934cf
exitCode: 137
finishedAt: "2022-02-20T02:10:42Z"
reason: OOMKilled
startedAt: "2022-02-20T02:10:31Z"
oom机制和信号处理
(1) 本环境中的PAGESIZE为4K,mem_alloc程序在运行中,会申请内存并使用,所以会不断触发缺页异常,内核在每次申请内存页时都会去比较该cgroup进程的内存使用量 是否超过了该cgroup内设置的阈值(memory.limit_in_bytes),如果超过阈值,并且在该cgroup内也没法通过内存回收释放足够的内存,则内核会在该cgroup内选择一个进程kill掉(oom_badness)。
(2)当触发oom时,内核会向进程发送SIGKILL信号,这里的发送信号是拟人化的写法,方便人去理解,但实际的内核发送信号仅仅是对进程数据结构(task_struct)中的信号相关字段的修改,如将SIGKILL这个sig添加到该进程的信号处理队列中,这样就算内核完成了信号的发送。
SIGKILL(对应信号值9)和SIGSTOP(对应信号值19)是两个特权信号,即用户不可以注册这两个信号的信号处理函数,由内核的默认函数进行处理。 SIGTERM(对应信号值15)是可以被注册信号处理函数的。kill命令不加参数默认就是向进程发送SIGTERM信号。kubelet停止pod时,也是先发送SIGTERM信号,经过terminationGracePeriodSeconds时间后,如果pod没有退出再发送SIGKILL信号。所以容器内的进程最好是注册SIGTERM对应的信号处理函数,在进程退出的时候做一些资源清理的操作,减少异常的发生,如关闭远端连接。容器内的init进程退出时,内核会向该init进程命名空间下的其他进程发送SIGKILL信号,更完善的做法是init进程拦截SIGTERM信号后,将SIGTERM转发给子进程,这样init和init的子进程都可以实现优雅退出,如docker的 --init参数就是使用一个专用的init进程接管用户的程序。
下面就是mem_alloc进程因为oom被kil掉的堆栈信息。
# 设置以下关注函数
[root@node-135 tracing]# cat set_ftrace_filter
__send_signal
do_send_sig_info
__oom_kill_process
out_of_memory
mem_cgroup_out_of_memory
try_charge
# cat trace_pipe
=> __send_signal -- 向进程发送SIGKILL信号
=> do_send_sig_info
=> __oom_kill_process -- kill掉一些进程
=> oom_kill_process
=> out_of_memory -- 内存不足
=> mem_cgroup_out_of_memory
=> try_charge
=> mem_cgroup_try_charge -- cgroup内的内存是否充足
=> mem_cgroup_try_charge_delay
=> __handle_mm_fault
=> handle_mm_fault
=> __do_page_fault
=> do_page_fault
=> page_fault -- 缺页异常
(3)内核修改了进程的task_struct,表明该进程有信号需要处理。用户注册的信号处理函数在用户态,此时还在内核中执行异常处理流程,那么信号处理函数的执行时机是什么呢? 在返回到用户态的时候是一个执行时机。信号处理的实现比较复杂,具体细节分析可以参见极客时间《趣谈linux操作系统》中的信号处理章节,详细介绍了信号处理函数执行的时机,以及执行完信号处理函数又是如何返回到正常的执行流程中的整个过程。
以下堆栈信息展示了mem_alloc程序的退出过程。
# 以下的函数堆栈是一个SIGKILL信号的处理
=> __send_signal -- 向父进程发送SIGCHILD信号
=> do_notify_parent
=> do_exit -- 在这个函数里会设置进程的退出码
=> do_group_exit -- 这个函数的参数只有一个退出码
=> get_signal -- 获取需要处理的信号
=> do_signal
=> exit_to_usermode_loop -- 返回到用户态
=> prepare_exit_to_usermode
=> swapgs_restore_regs_and_return_to_usermode
(4)正常的程序在退出时是调用exit系统调用,exit是调用do_exit函数,在(3)的堆栈中可以看到处理SIGKILL也会调用do_exit,区别在于正常的退出,错误码是经过了处理的,而在处理SIGKILL信号时,是直接将信号的值赋值给了进程的退出码(task_struct.exit_code)。
SYSCALL_DEFINE1(exit, int, error_code)
{
do_exit((error_code&0xff)<<8);
}
(5)使用$?查看程序的退出码,这也上面的分析不一致,错误码应该是9,还不是137,问题在哪里呢?
[root@localhost test]# echo 104857600 > memory.limit_in_bytes
[root@localhost test]# echo $$ > cgroup.procs
[root@localhost test]# /root/training/memory/oom/mem-alloc/mem_alloc 40000
Allocating,set to 40000 Mbytes
Killed
[root@localhost test]# echo $?
137
(6)重复(5)中的步骤,使用ftrace查看函数do_exit的参数值。从下面的trace_pipe中确实看到mem_alloc的退出码确实是9,而不是137。这里直接说结论,在下面会再次验证,bash进程是mem_alloc的父进程,在处理mem_alloc进程的返回值时,如果是9,说明是被SIGKILL掉的,所以将9加上一个偏移量128,结果就是137,这样做可能是为了与linux系统标准的错误码做一个区分吧。
# 设置kprobe
[root@localhost tracing]# echo 'p:myprobe do_exit exit_code=%di' > kprobe_events
[root@localhost tracing]# echo 1 > events/kprobes/myprobe/enable
# 设置过滤条件
[root@localhost tracing]# echo exit_code==9 > events/kprobes/myprobe/filter
[root@localhost tracing]# /root/training/memory/oom/mem-alloc/mem_alloc 40000
Allocating,set to 40000 Mbytes
Killed
#查看结果
[root@localhost tracing]# cat trace_pipe
mem_alloc-17077 [001] .... 875.147095: myprobe: (do_exit+0x0/0xc60) exit_code=0x9
containerd-shim 进程的处理
containerd-shim监听cgroup内进程的oom事件与使用event_control监听oom事件中的一致,这里不再赘述。
(1) 在Run函数中会监听eventfd,如果epoll_wait返回,则说明该cgroup内有进程触发了oom。
func (e *epoller) Run(ctx context.Context) {
var events [128]unix.EpollEvent
for {
select {
default:
n, err := unix.EpollWait(e.fd, events[:], -1)
for i := 0; i < n; i++ {
e.process(ctx, uintptr(events[i].Fd))
}
}
}
}
(2) process函数中会通过GRPC消息将TaskOOMEvent转发到containerd中。
func (e *epoller) process(ctx context.Context, fd uintptr) {
if err := e.publisher.Publish(ctx, runtime.TaskOOMEventTopic, &eventstypes.TaskOOM{
ContainerID: i.id,
});
}
(3)在进程退出时,内核会向其父进程(containerd-shim)发送SIGCHILD信号。handleSignals会处理SIGCHILD信号,调用Reap,进而使用系统调用wait4拿到进程的退出码。
// runtime/v2/shim/shim_unix.go
func handleSignals(ctx context.Context, logger *logrus.Entry, signals chan os.Signal) error {
for {
select {
case s := <-signals:
switch s {
case unix.SIGCHLD:
if err := reaper.Reap(); err != nil {
logger.WithError(err).Error("reap exit status")
}
}
}
}
(4)在containerd-shim启动的时候,会启动goroutine监听容器进程的退出,checkProcess中会将容器id,进程id,退出码,退出时间等信息通过GRPC消息转发到containerd中。
func New(ctx context.Context, id string, publisher shim.Publisher, shutdown func()) (shim.Shim, error) {
if cgroups.Mode() == cgroups.Unified {
ep, err = oomv2.New(publisher)
} else {
ep, err = oomv1.New(publisher)
}
go ep.Run(ctx)
go s.processExits()
go s.forward(ctx, publisher)
}
func (s *service) checkProcesses(e runcC.Exit) {
for _, container := range s.containers {
for _, p := range container.All() {
p.SetExited(e.Status)
s.sendL(&eventstypes.TaskExit{
ContainerID: container.ID,
ID: p.ID(),
Pid: uint32(e.Pid),
ExitStatus: uint32(e.Status),
ExitedAt: p.ExitedAt(),
})
}
}
}
(5)回收子进程会调用reap函数,在exitStatus中,会判断进程是否是被信号中断的,如果是的话,则加上一个偏移量128,这里就验证了上面说的结论,137 = 9 + 128。那么可以推断bash中 $?也是同样的处理。
func reap(wait bool) (exits []exit, err error) {
for {
pid, err := unix.Wait4(-1, &ws, flag, &rus)
exits = append(exits, exit{
Pid: pid,
Status: exitStatus(ws),
})
}
}
// sys/reaper/reaper_unix.go
const exitSignalOffset = 128
func exitStatus(status unix.WaitStatus) int {
if status.Signaled() {
return exitSignalOffset + int(status.Signal())
}
return status.ExitStatus()
}
// unix/syscall_linux.go
const (
mask = 0x7F
core = 0x80
exited = 0x00
stopped = 0x7F
shift = 8
)
func (w WaitStatus) Signaled() bool {
return w&mask != stopped && w&mask != exited
}
containerd的处理
(1)在handleEvent中会处理containerd-shim转发过来的容器的事件信息,如果是TaskOOM,则调用UpdateSync更新容器的退出原因。
(2)如果是进程退出,则调用handleContainerExit,再调用UpdateSync更新容器的退出码。
// handleEvent handles a containerd event.
func (em *eventMonitor) handleEvent(any interface{}) error {
switch e := any.(type) {
case *eventtypes.TaskExit:
logrus.Infof("TaskExit event %+v", e)
cntr, err := em.c.containerStore.Get(e.ID)
handleContainerExit(ctx, e, cntr);
case *eventtypes.TaskOOM:
logrus.Infof("TaskOOM event %+v", e)
// For TaskOOM, we only care which container it belongs to.
cntr, err := em.c.containerStore.Get(e.ContainerID)
err = cntr.Status.UpdateSync(func(status containerstore.Status) (containerstore.Status, error) {
status.Reason = oomExitReason
return status, nil
})
return nil
}
func handleContainerExit(ctx context.Context, e *eventtypes.TaskExit, cntr containerstore.Container) error {
err = cntr.Status.UpdateSync(func(status containerstore.Status) (containerstore.Status, error) {
if status.FinishedAt == 0 {
status.Pid = 0
status.FinishedAt = e.ExitedAt.UnixNano()
status.ExitCode = int32(e.ExitStatus)
}
return status, nil
})
}
(3)UpdateSync是containerd中用来更新容器存储状态的函数。
func (s *statusStorage) UpdateSync(u UpdateFunc) error {
newStatus, err := u(s.status)
data, err := newStatus.encode()
continuity.AtomicWriteFile(s.path, data, 0600)
s.status = newStatus
}
(4)containerd的处理就算完成了,接下来就等kubelet来获取容器的状态了。
kubelet的处理
kubelet的细节分析参见 kubelet代码解析
(1)relist函数会定期执行,对比pod状态的变化。
(2)通过computeEvent、updateEvents和generateEvents对比内存中的pod的状态和从runtime接口获取的实时的pod的状态差异,从而可以推断出pod内的容器发生了状态变化。
func (g *GenericPLEG) Start() {
go wait.Until(g.relist, g.relistPeriod, wait.NeverStop)
}
func (g *GenericPLEG) relist() {
klog.V(5).InfoS("GenericPLEG: Relisting")
for pid := range g.podRecords {
oldPod := g.podRecords.getOld(pid)
pod := g.podRecords.getCurrent(pid)
// Get all containers in the old and the new pod.
allContainers := getContainersFromPods(oldPod, pod)
for _, container := range allContainers {
events := computeEvents(oldPod, pod, &container.ID)
for _, e := range events {
updateEvents(eventsByPodID, e)
}
}
}
}
(3)如因oom产生一个类型为ContainerDied的PodLifecycleEvent事件
func generateEvents(podID types.UID, cid string, oldState, newState plegContainerState) []*PodLifecycleEvent {
klog.V(4).InfoS("GenericPLEG", "podUID", podID, "containerID", cid, "oldState", oldState, "newState", newState)
switch newState {
case plegContainerRunning:
return []*PodLifecycleEvent{{ID: podID, Type: ContainerStarted, Data: cid}}
case plegContainerExited:
return []*PodLifecycleEvent{{ID: podID, Type: ContainerDied, Data: cid}}
case plegContainerUnknown:
return []*PodLifecycleEvent{{ID: podID, Type: ContainerChanged, Data: cid}}
}
(4)在syncLoopIteration中会处理该pleg事件,继而调用Podworker的sync方法。
func (kl *Kubelet) syncLoopIteration(configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
case e := <-plegCh:
handler.HandlePodSyncs([]*v1.Pod{pod})
}
(5)generateAPIPodStatus会将容器的状态转换为 v1.PodStatus定义中的字段。再调用statusManager的SetPodStatus方法更新pod的状态信息。
func (kl *Kubelet) syncPod(ctx context.Context, updateType kubetypes.SyncPodType, pod, mirrorPod *v1.Pod, podStatus *kubecontainer.PodStatus) error {
klog.V(4).InfoS("syncPod enter", "pod", klog.KObj(pod), "podUID", pod.UID)
// Generate final API pod status with pod and status manager status
apiPodStatus := kl.generateAPIPodStatus(pod, podStatus)
kl.statusManager.SetPodStatus(pod, apiPodStatus)
// Call the container runtime's SyncPod callback
result := kl.containerRuntime.SyncPod(pod, podStatus, pullSecrets, kl.backOff)
}
(6)根据状态做不同的赋值,如ContainerStateExited,则要更新容器的退出码,原因等。
func (kl *Kubelet) convertToAPIContainerStatuses(pod *v1.Pod, podStatus *kubecontainer.PodStatus, previousStatus []v1.ContainerStatus, containers []v1.Container, hasInitContainers, isInitContainer bool) []v1.ContainerStatus {
switch {
case cs.State == kubecontainer.ContainerStateRunning:
status.State.Running = &v1.ContainerStateRunning{StartedAt: metav1.NewTime(cs.StartedAt)}
case cs.State == kubecontainer.ContainerStateCreated:
fallthrough
case cs.State == kubecontainer.ContainerStateExited:
status.State.Terminated = &v1.ContainerStateTerminated{
ExitCode: int32(cs.ExitCode),
Reason: cs.Reason,
Message: cs.Message,
StartedAt: metav1.NewTime(cs.StartedAt),
FinishedAt: metav1.NewTime(cs.FinishedAt),
ContainerID: cid,
}
}
(7)getPhase也是一个比较重要的函数,这里会决定pod的状态,PodSpec中的restartPolicy是在这里生效的。
func getPhase(spec *v1.PodSpec, info []v1.ContainerStatus) v1.PodPhase {
for _, container := range spec.Containers {
containerStatus, ok := podutil.GetContainerStatus(info, container.Name)
if !ok {
unknown++
continue
}
switch {
case containerStatus.State.Running != nil:
running++
case containerStatus.State.Terminated != nil:
stopped++
if containerStatus.State.Terminated.ExitCode == 0 {
succeeded++
}
}
switch {
case running > 0 && unknown == 0:
return v1.PodRunning
case running == 0 && stopped > 0 && unknown == 0:
if spec.RestartPolicy == v1.RestartPolicyAlways {
// All containers are in the process of restarting
return v1.PodRunning
}
if stopped == succeeded {
return v1.PodSucceeded
}
if spec.RestartPolicy == v1.RestartPolicyNever {
return v1.PodFailed
}
return v1.PodRunning
}
}
(8)status_manager中的syncPod方法会将新的pod状态通过patch方法更新到apiserver。
func (m *manager) syncPod(uid types.UID, status versionedPodStatus) {
pod, err := m.kubeClient.CoreV1().Pods(status.podNamespace).Get(context.TODO(), status.podName, metav1.GetOptions{})
newPod, patchBytes, unchanged, err := statusutil.PatchPodStatus(m.kubeClient, pod.Namespace, pod.Name, pod.UID, *oldStatus, mergePodStatus(*oldStatus, status.status))
klog.V(3).InfoS("Patch status for pod", "pod", klog.KObj(pod), "patch", string(patchBytes))
}
mem_alloc代码
参考极客时间 《容器高手实战课》
[root@localhost mem-alloc]# cat mem_alloc.c
#include <stdio.h>
#include <malloc.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#define BLOCK_SIZE (10*1024*1024)
int main(int argc, char **argv)
{
int thr, i;
char *p1;
if (argc != 2) {
printf("Usage: mem_alloc <num (MB)>n");
exit(0);
}
thr = atoi(argv[1]);
printf("Allocating," "set to %d Mbytesn", thr);
sleep(10);
for (i = 0; i < thr; i++) {
p1 = malloc(BLOCK_SIZE);
memset(p1, 0x00, BLOCK_SIZE);
}
sleep(600);
return 0;
}
[root@localhost oom]# cat Dockerfile
FROM nginx:latest
COPY ./mem-alloc/mem_alloc /
CMD ["/mem_alloc", "2000"]
[root@localhost oom]# cat Makefile
all: image
mem_alloc: mem-alloc/mem_alloc.c
gcc -o mem-alloc/mem_alloc mem-alloc/mem_alloc.c
image: mem_alloc
docker build -t registry/mem_alloc:v1 .
clean:
rm mem-alloc/mem_alloc -f
docker stop mem_alloc;docker rm mem_alloc;docker rmi registry/mem_alloc:v1
总结
本文研究的都是确定性的问题,好像没有什么意义,话说回来,如果没有学习这些确定性问题的积累,又如何去应对不确定的问题呢?
作者:免帅叫哥
链接:https://www.jianshu.com/p/0a9718199428
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
最后
以上就是畅快白羊最近收集整理的关于kubernetes pod内容器状态OOMKilled和退出码137全流程解析文章导读场景再现oom机制和信号处理containerd-shim 进程的处理containerd的处理kubelet的处理mem_alloc代码总结的全部内容,更多相关kubernetes内容请搜索靠谱客的其他文章。








发表评论 取消回复