1. 概要
在过去五年间,负责过从数百万DAU到几千万DAU的成熟型数据算法团队,也曾负责从零开始的到几百万DAU增长型团队,积累了一些数据建设的想法思考以及数据团队管理经验。以前数据团队-启明星的好几个小伙伴,现在也陆续走上了数据团队负责人的管理岗位,时不时还会和我讨论数据团队的建设、管理遇到的问题和疑惑,讨论过程沉淀了不少的总结和思索。
于是乎写下这篇文章,旨在介绍在公司内大数据团队的定位作用,以及如何搭建一个高效精干(便宜)的大数据团队。本文面向的读者,首先应该最适合刚负责团队的数据TeamLeader,希望于此抛砖引玉,能够引发些许思考。其次创业中老板们也可以看看,能够知道你们花大价钱建立的数据团队能够给企业带来什么价值。最后,应该也适合期望成长的数据研发、BI工程师、算法工程师们,希望此文有些许insight,能够帮助你们加深对数据架构和团队工作的认知与理解。
2. 团队价值
时至今日,大数据团队应已成为移动互联网公司的标配,其价值和重要性被业界反复宣传多年,早已不言而喻。大数据的作用,其实可以大体归纳为两类,一类是数据驱动业务为核心,一类则是数据即业务。前者非常多见,基本能听到的故事,都是数据如何指导、驱动业务,什么Netflix通过大数据分析下重拍《纸牌屋》获得空前成功[1],什么Google持续改进的算法源源不断提升其广告收入[2]等等,不胜枚举,乱花迷眼。至于后者,数据即业务,最著名当属今日头条,海量的爬取数据作为起家之本,佐之强大无匹的推荐算法,在注意力的世界所向披靡,颇有将微信斩于马下之态势。AT漫漫铁幕之下,杀出一家近千亿美金级别的企业,其老板乃龙岩四杰之首,江湖人称「机器人」的张一鸣[3],曾宣称头条是全球单位面积内算法工程师数量最高的公司。管中窥豹,亦可想象大数据在此类公司的价值。
虽然经常存在的对大数据的神秘化、复杂化的行为,然而大数据它绝非万能:
世间并无银子弹,就像没有吸血鬼一样。 --尼古拉斯赵四
它通常适合或者擅长以下场景:
-
在复杂的市场情况下,通过大数据分析可以帮助公司更好了解用户的思考过程和反馈,甚至能够预测用户行为。
-
长期而言,大数据工具能够有效提高效率,降低企业成本。
-
新产品和服务。通过大数据来预估用户需求以及通过分析所带来的能力去满足用户需求。
具体到互联网公司,大数据团队大部分时候作为公司中台部门,最重要也是最基本的定位价值就是:反馈业务以及辅助决策。用以前所做的一页PPT结合业务简单解释以上三点。

大数据团队价值
-
高管会关心目前公司产品运转现状,数据是否录得好的增长,营收情况如何,企业效率是否有所提高。从宏观层面,大数据能够很好概括、监控公司的产品大盘,整体性反馈用户行为。 -
产品运营会关心,当前用户满意度如何,AB测试下的新功能是否显著有效,产品现有功能是否稳定,用户行为是怎样的,运营活动效果表现如何?从微观层面,大数据能够刻画每类乃至每个用户的行为模式和反馈,并且通过洞察这些行为打造相关的效率工具。 -
研发、测试和运维会关心,我们所打造所维护的软件服务、系统、客户端是否足够健壮,可用性是否得到保障,各个模块是否反应足够敏捷快速。大数据通过合理的数据埋点,能够轻易勾勒出全链路的产品服务质量,打造企业独有的APM工具系统。
在论证了大数据团队价值所致之后,接下来会讲一下较为硬核的内容,在互联网公司,如何打造大数据的架构和流程。在不同阶段的不同用户量级的公司,所采用的技术栈、团队规模、架构复杂程度都会不尽相同。我尽量抽象这些较为通用的内容来讨论,难免会出现纰漏不足,都敬请方家不吝指正。
3. 数据架构
目前互联网公司的大数据架构基本可以归纳成为以下两类:Lambda架构[4]以及Kappa架构[5]。
3.1 Lamda架构
由Strom作者Nathan Marz在Twitter开发实时数据计算引擎时候,所总结提出的通用数据架构。它融合了批式处理与流式处理方法的优点,尝试平衡大数据处理过程中的延迟、吞吐量以及容错性。lambda架构中,批量模块负责复杂精确的离线计算,与之同时流式模块负责实时的数据计算。Lambda架构图如下:
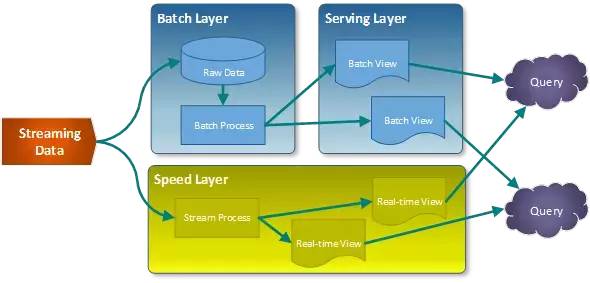
-
所有系统的数据都会被分发到批处理层(batch layer)和快速处理层(speed layer)
-
批处理层会持久化原始数据并批量处理计算这些数据,将结果视图提供给服务层。
-
快速处理层会流式处理数据,并直接提供实时数据视图。
-
任何查询,都能通过融合批处理视图和实时视图的结果来获得。
目前大部分互联网公司采用这种大数据架构,它不但能够同时满足不同时效不同复杂程度的数据需求,还能有效节省企业机器成本。在离线链路(批处理层),通常能够对数据做大量复杂的计算,数据产出通常会是T+1(隔天)的,在某些场景离线链路会分裂成离线(天级别)和近线(小时级别)的两条链路。实时链路(快速处理层),通常用于实现核心KPI指标计算、或者高时效要求业务计算(实时推荐等)。
可以见到,Lambda架构存在几个明显的缺点,对于焦急的现代人来说,离线计算太慢了,时效性跟不上,吃瓜都不甜。
我好了。 -- 步行街网友Kappa
另外一个不容忽视的问题是,离线计算和实时计算虽然采用同一套数据,但是不同的计算逻辑代码逻辑,最后的结果数据可能存在细微的差异。这种差异在对数据处理流程不够了解的老板或者其他部门同事来说确实比较疑惑。昨晚说好的2315亿,今天怎么就只剩2314亿9999万了?
不是说好双十一当天不能退货吗?
于是不少团队开始实践融合离线在线的数据架构,有人将它简化抽象为Kappa架构[6]。
3.2 Kappa架构
Kappa架构由LinkedIn工程师Jay Kreps 总结提出,其实是Lambda架构的简化版,它主张去掉Lambda架构的批量处理层,所有数据都通过流式计算引擎来实时计算处理。在Apache 社区,以Samza[7],Flink[8]为首的产品都旨在实现一个融合批处理、流式处理的实时计算引擎,而实时计算引擎正是Kappa架构实现的核心部件。
Kappa架构如下图所示:
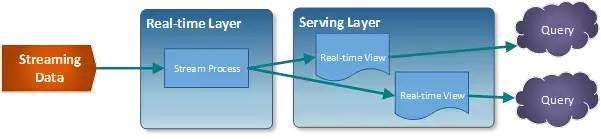
Kappa架构采用一套代码逻辑实时处理所有流入数据,给用户提供实时数据视图。Kappa架构确实能够解决Lambda的一些问题,但是依然存在以下几个问题:
-
实时计算框架对机器资源的消耗比离线处理要高。
只要有源源不断的钱,任何人都可以抄底成功 -- 饭否网友王先生
-
Hadoop/Spark的适用场景、稳定性、社区活跃度以及开发者数量都远高于Flink、Samza这些后起之秀。
综上所述,Kappa架构还在持续演化中,需要更多企业用户打磨和参与。目前它更多的部署在业务实时性要求比较高的公司、部门中,最著名的应该是阿里的双十一大屏项目[9]。
4.数据流程
抽象的数据架构能让我们剥离现实数据世界的繁复混乱,思考什么是对企业最好大数据实施方案。对于一线数据团队的同学们而言,具体、严格、规范的数据流程,才是真正核心需要关注的工作内容。
4.1 产品视角
首先回顾一下,从产品视角,我们是如何实现大数据分析挖掘的?
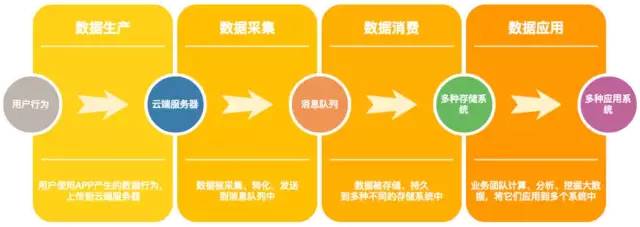
大数据产品数据流程
-
用户打开App或者小程序,一般会有一个数据规范权限的必读,里面说明本公司会对用户采集的数据种类、内容,以及使用范围。在用户接受该协议,后续用户在APP内的行为就会上报到云服务器上。具体数据上报的形式,一般有两种,一种是在线日志,也就是说用户在使用app过程中,将用户的数据请求、行为动作以URL请求的形式,从客户端向服务端发起,服务端一般会以与数据团队约定好的规范,以日志的形式记录下来这些请求。另外一种是离线日志,通常这些日志所代表的用户行为优先级较低,为了节省用户流量,这些日志会在客户端打印压缩存储,在客户端在wifi场景或者达到一定容量才会上传到服务器。
-
日志规范和采集是数据流程的第一步,源头出错后续基本无补救空间,同时涉及到的部门繁多,产品、运营、服务端、客户端、数据端研发、测试、项目经理等等,需要极端的重视。具体如何构建一个合理规范的用户追踪规范,可以参考我以前写的博文--用户行为的深度追踪[10]。
-
数据通常会分布在多台云服务器上,需要通过类似于flume[11],logstash[12]等采集工具,将日志数据导入类似于Kafka等消息队列中。
-
数据业务方,比如BI、搜索、推荐、广告等团队会根据自己的需求,通过多种不同手段来消费、存储、应用以及展示这些日志数据。
4.2 研发视角
从数据团队负责人的角度,来梳理从数据集成到数据消费全链路容易遇到的问题以及其应对的产品技术方法论,提供一个贯穿数据生命周期、统一化、规范化、智能化数据体系建设的解决方案。
大数据体系建设是一个相对复杂的系统工程,它涉及到数据集成、数据开发、数据质量管理、数据服务、数据管理、数据运维、数据安全多个方面的工作。这些模块它们相互依存、环环相扣,同时对研发人员的技术要求大相径庭,需要服务端工程师、大数据平台工程师、BI工程师、分析师、各种方向的算法工程师、前端工程师等来参与整个系统的建设。具体的数据流程如下图所示:
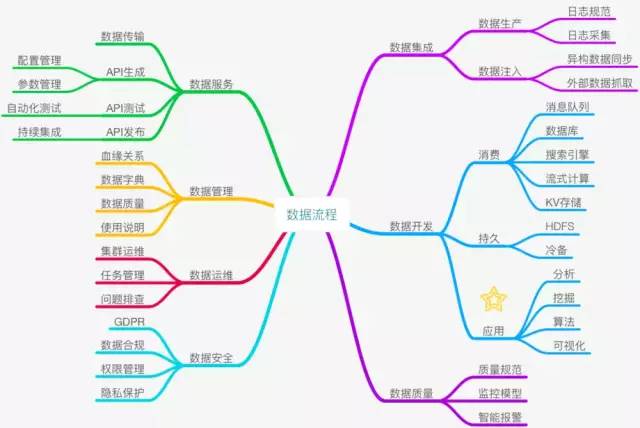
大数据研发视角下数据流程
整个大数据体系构建过程中,需要关注的重点工作内容:
-
数仓规划与建模:良好的数仓规划和建模,要求所有数据指标,严格遵循标准规范,同时需要数仓架构层次清晰,合理均衡存储与计算的取舍。
-
数据平台与工具:长期稳定、高可用的离线在线计算平台,高高效、可debug的任务调度系统,智能、可靠的监控系统,高性能、高可用的数据服务,敏捷、可快速迭代的数据开发系统。
-
数据挖掘与应用:它和企业业务息息相关,是将数据转化成为价值的最核心所在。不同规模不同阶段的企业,都有极其不同的挖掘应用内容,包括搜索、推荐、广告、用户画像、反作弊、风控、空间数据挖掘、计算机视觉、对话机器人等等。下一章,团队职责中会概略性讨论一下这块的内容(显然可以看出来,这块可谓包罗万象,几十本书也讲不完)。
企业的大数据体系建设容易遇到以下问题:
-
数据体系构建过程十分困难,数据建设周期比较长,效率很难保证。
-
数据容易重复建设、数据前后不一致问题严重
-
数据管理困难,数据复用率低
-
数据价值得不到充分挖掘应用
5. 团队建设
毋庸置疑的是大数据能够赋能企业,为企业带来不可替代的价值。但是又存在建设维护困难等问题。如何去搭建一个好大数据团队显得至关重要。
那么 …… 在哪里才能买得到呢? -- 华府武状元
5.1 职责分工
在上面一个章节梳理了大数据研发中主要的工作流程,要这些生产、集中、分发、消费、存储等过程都处理得妥妥帖帖、顺顺当当,那确实需要一支分工明确、又高度协作,充满责任心也相互担待,满怀技术好奇又处事谨慎的工程师团队的全力以赴。我尝试从总结之前团队分工情况,同时从工程师能力以及业务内容来划分数据团队的职责,如下图所示:
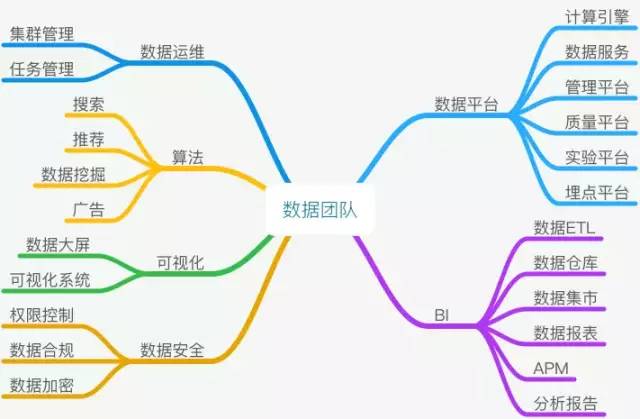
数据团队职责
养这支团队一年2000w打不住啊,银八老师! --望京 soho T2 李总以及张总
确实如此,在一个公司建立完整编制的这样一支团队,人数规模一般在数十到上百,对于中等规模(C、D轮)以下的企业,很难养得起。幸运的是,互联网是伟大的,它最重要的思想是开放透明、信息共享,开源社区在这个理念下快速健康成长,提供了大量的开源大数据套件,极大提升了大数据研发的生产力。再加上云计算的浪潮势不可挡地席卷这颗星球[13][14],基础设施、架构、平台由云供应商提供,大幅度减低了中小企业的数据团队门槛,节约了不少人力、建设成本。
-
A轮左右的初创公司,可能只需要
1~5人,尽量利用云平台提供的产品解决方案,主要在于把公司数据流程搭建好,数据目的在于辅助决策。(ELK这时候是一个非常赞的选择[15]) -
在B、C轮左右,百万DAU以内公司业务复杂度不大的时候,数据团队可能只需要
5~10人,负责BI、算法相关、数据服务,在于辅助决策同时支撑业务。当然像互联网金融行业、O2O这种,复杂度较高的业务,可能要人数 * 业务数。(ELK这时候还可以支撑) -
在C、D轮左右,千万DAU左右的公司,数据团队可能扩展到
数十到上百人,云计算公司提供的工具可能已经不太适用,或者需要更多对数据的挖掘应用。数据平台的更多角色也会加入,算法人才的需求也会增加。这里面灵活度很大,好的架构和负责人能够很好把握住人力成本和规模的均衡。(ELK适用于部分业务,需要替换部件) -
在上市公司,可能整套体系已经比较完善,人数可能在数百到几千不等。只有新的业务可能会像创业公司那样搭建整个大数据团队。
着重讲述下数据团队内的算法工程团队,部分公司选择将BI和算法团队独立,更多的公司将它们放在一个大部门下,小团队职能虽然可能相对独立,但是它们之间的业务、数据关联非常多而深,处于数据流程的不同位置,融合一起的公司架构会让整体协作效率更高。
其中在不同业务不同阶段的公司,算法团队的规模会从一个小组到数十个事业部巨大区间中波动,算法团队也有可能会因而组建自身的数据部门,从这点也可以看到,其实这些组织架构并非一成不变,也远非泾渭分明。尤其是近年来,随之深度神经网络的突破,不少创业公司核心能力就是算法本身,比如计算机视觉应用领域、自动化驾驶领域,这些企业的数据团队,可能和传统移动互联网的日志数据分析挖掘已经有明显的差异了。所以以下对算法工程团队职能划分,可能只能大概适用于较为主流的以用户为中心的互联网企业:
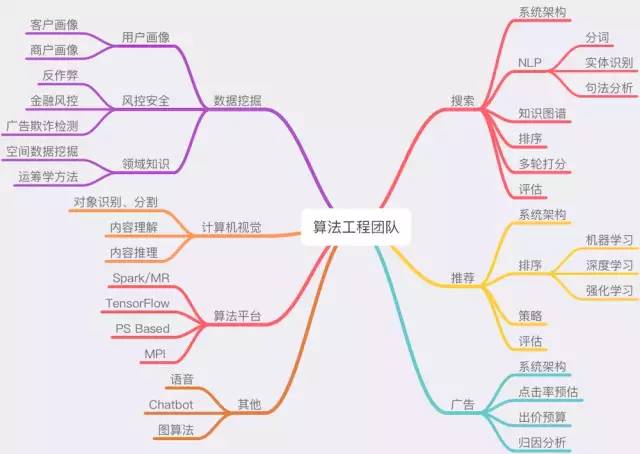
算法工程团队职责
数据算法都是具有复杂计算机、统计学背景的工作,本身要求对数据、算法开发过程以及结果有严格的规范和验证。同时与公司内部其他部门同事沟通关于数据与算法的内容时候,由于双方的教育背景的差异,存在可能导致沟通成本的上升,相互之间信任下降的情况。一套行之有效的工作方法论,相信能够有效凝聚团队,提升外部影响力,降低沟通成本。
5.2 工作方法论
这里所总结的数据团队的工作方法论,远称不上金科玉律。属于我个人过去五年工作、学习的一点心得。
1.数据算法平台是一个产品
-
产品化:数据算法平台可能只是企业内部的工具,但是作为互联网公司应该有将自己负责的业务打造成为一个优秀易用的产品的觉悟。团队负责人有义务和权利把控数据算法平台划分长期以及近期研发目标,在满足繁重的数据算法需求同时,需要思考如何抽象业务需求形成产品特性。同时建议,将产品feature的roadmap公开化、透明化,能让所有关心数据算法的团队了解当前、未来的产品研发规划。最后,经常性做数据算法平台的产品宣讲、培训,及时倾听收集用户反馈,都是ToB产品的重要步骤和不可或缺的环节。
-
迭代节奏:数据算法平台可能不需要像前端后端团队一般紧跟公司的ART[16]的发版节奏,但是依然建议自己实现固定的迭代节奏(数据一周一版,算法两周一版),用发版来保证整个团队的工作节奏,确保松弛有度。
2.数据是一种权力
-
必须竭尽全力保护用户数据。如同话语权一般,大数据也是一种强大的权力。随着国内外对知识产权、用户隐私保护日益严厉,GDPR[17]的颁发、执行也是对公司这种大数据权力的一种限制和监管。科技公司的公众形象大有从屠龙少年向恶龙堕落的趋势,从Facebook到滴滴出行深陷泥潭[[18]]。严格执行相应法律法规,加大数据安全的投入,绝对是划算的。
-
尽力增强数据算法的可解释性。很多数据和算法团队同学看来理所当然的基本知识、概念,在外部团队可能都难以理解,这样其实本质上也算是一种知识的权力。大数据团队的应该尽力使用图表、分析报告、文档解释等方式增强数据、算法的易用性、可读性。
3.数据工作的科学性
-
数据绝对不可造假。任何的数据作假,都很难圆谎。Data will talk。
-
算法需要严格验证。算法开发需要设置严格的线上线下验证流程,从统计意义上保证结果的可靠性。
4.团队文化
-
自由开放:互联网的无远弗届,自由开放为人类贡献了这个世纪以来最伟大的进步力量。大数据更是最直接得益于开源社区对自由开放的践行。法上得中,之前我的团队都秉持这种氛围。
-
Owner精神:阿里文化里面个人最为欣赏也是时刻在践行的owner精神。不管你是以何种身份参与到一个包括了数据团队的项目、产品中的时候,必须具备我会owner这件事情的精神劲头,与级别无关与身份无关,真正做到数据驱动业务。Data don't lie.
-
保持好奇:大数据还处于高速发展阶段,各种理论、方法、工具、算法层出不穷,团队整体保持好奇,保持学习,是保持竞争力的唯一途径。
-
导师制度: 阿里最棒的制度之一,能够很快凝聚新老员工的向心力。
6. 总结
本文主要是概略阐述了大数据团队的工作应该如何开展,团队应该如何建设。业界很容易高估或低估的大数据团队价值,大数据并非银子弹,它适用于复杂市场情况对用户了解和对企业效率提高。然后,概述了大数据架构现今的两种最流行架构,分析了两者的优劣,并讨论基于主流架构的数据流程应该如何开展。由于大数据研发流程复杂冗长,需要建设一支强大高效的大数据团队,又讨论了完整编制的大数据团队应该如何分工合作。最后总结了个人过去几年负责几个数据算法团队所总结的一些工作方法论,建议将数据算法平台当做产品来打造,慎用大数据这种强大的权力,同时保持团队平等自由开放的氛围,让团队成员敢于承担业务责任,保持对知识的好奇。
参考文献
[1] How Netflix built a House of Cards with big data https://www.cio.com/article/3207670/big-data/how-netflix-built-a-house-of-cards-with-big-data.html
[2] History of Google Algorithm Updates
https://www.searchenginejournal.com/google-algorithm-history/
[3] 对话张一鸣:世界不是只有你和你的对手 https://36kr.com/p/5059197.html
[4] Lambda architecture
https://searchbusinessanalytics.techtarget.com/definition/Lambda-architecture
[5] What is Kappa Architecture?
http://milinda.pathirage.org/kappa-architecture.com/
[6] Questioning the Lambda Architecture
https://www.oreilly.com/ideas/questioning-the-lambda-architecture
[7] What is Samza?
http://samza.apache.org/
[8]Apache Flink - Stateful Computations over Data Streams
https://flink.apache.org/
[9]一文揭秘阿里实时计算Blink核心技术:如何做到唯快不破?
https://yq.aliyun.com/articles/399401?spm=5176.10695662.1996646101.searchclickresult.bf495006uksRQA
[10]用户行为的深度追踪——事件与埋点
https://www.jianshu.com/p/d45235b51601
[11] Apache Flume https://flume.apache.org/
[12] Logstash https://www.elastic.co/cn/products/logstash
[13] Amazon Web Services (AWS) - Cloud Computing Services https://aws.amazon.com/
[14] 阿里云 - 上云就上阿里云 https://cn.aliyun.com/
[15] Elastic Stack https://www.elastic.co/elk-stack
[16]Agile Release Train https://www.scaledagileframework.com/agile-release-train/
[17] General Data Protection Regulation https://en.wikipedia.org/wiki/General_Data_Protection_Regulation
[18]从Facebook到滴滴出行:平台的黑化
https://mp.weixin.qq.com/s/mJ2VAEap6BIWC-lvGSLEIg
最后
以上就是谨慎斑马最近收集整理的关于大数据团队工作与建设的全部内容,更多相关大数据团队工作与建设内容请搜索靠谱客的其他文章。








发表评论 取消回复