
来源:机器学习AI算法工程
该项目所属数据挖掘类型:分类预测问题。
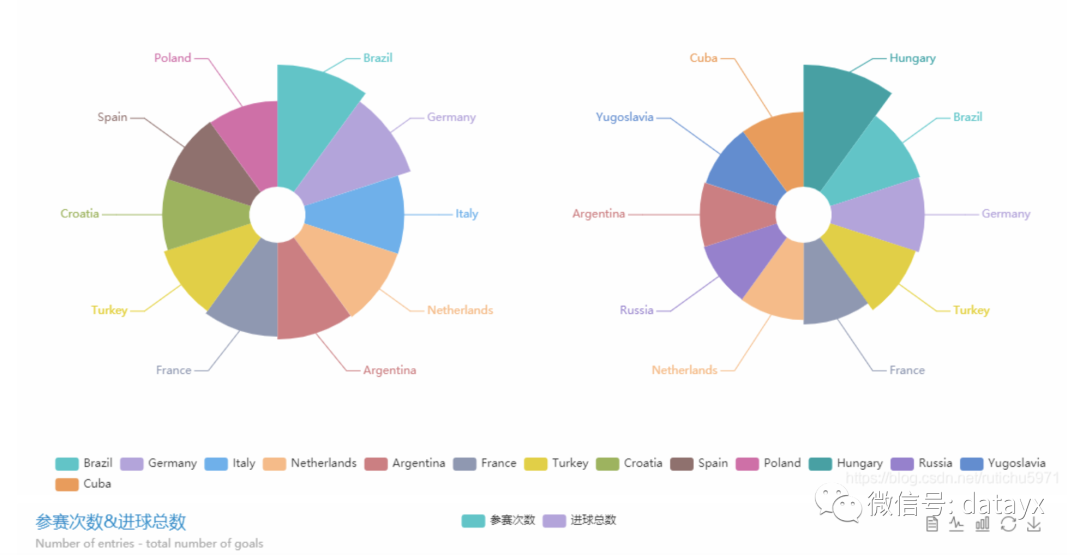
通过对2018年之前世界杯各个国家球队的表现以及比分结果进行数据分析,并结合以往各个球队在历届世界杯中的表现,通过机器学习算法建立模型,并对其进行评价以及模型优化之后,进行模拟2022年卡塔尔世界杯的冠军球队的归属。
首先从Kaggle网站上找到合适的历年世界杯的比赛结果数据集。
网址:https://www.kaggle.com/abecklas/fifa-world-cup
该数据存在诸多多余的属性:如比赛年份,比赛场地等。我们首先去掉无关的属性,只留下:主队、客队、主队进球数、客队进球数,比赛结果。其中结果集分为1为主队获胜,2为客队获胜,-1为平局。
此时,我们发现仅有主场客场比分并不能很好地分析每个队的实力,所以我们要进行数据统计,找出新的特征值来扩充数据集。
数据扩充
首先我们计算每个国家的参赛次数
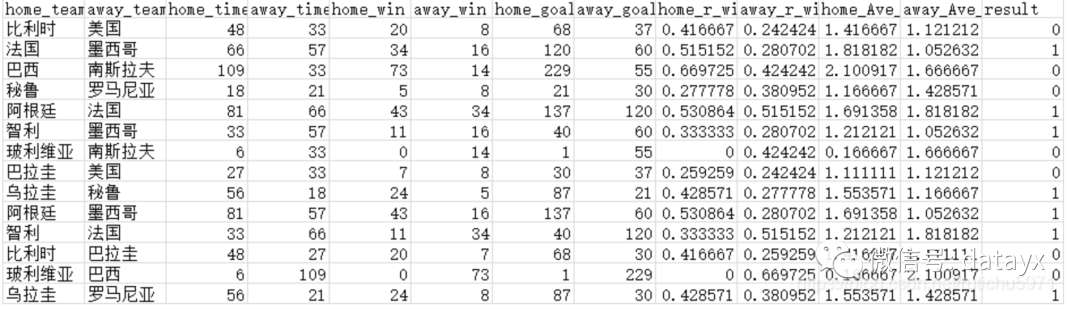
合并后生成的tr_data_after.csv中内容为:主队、客队、主队参赛次数、客队参赛次数、主队胜利次数、客队胜利次数、主队进球数、客队进球数、主队胜率、客队胜率、主队场均进球、客队场均进球、比赛结果。
数据预处理
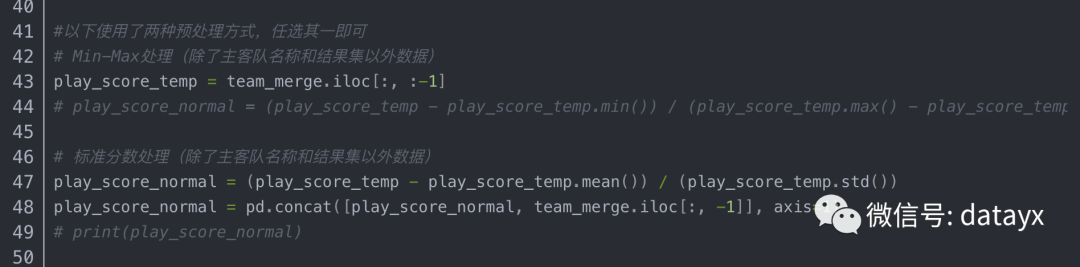
其中标准分数(z-score)是一个分数与平均数的差再除以标准差的过程。
用公式表示为:z=(x-μ)/σ。
其中x为某一具体分数,μ为平均数,σ为标准差。

预处理后的数据存放至play_score_normal.csv中:

机器学习模型
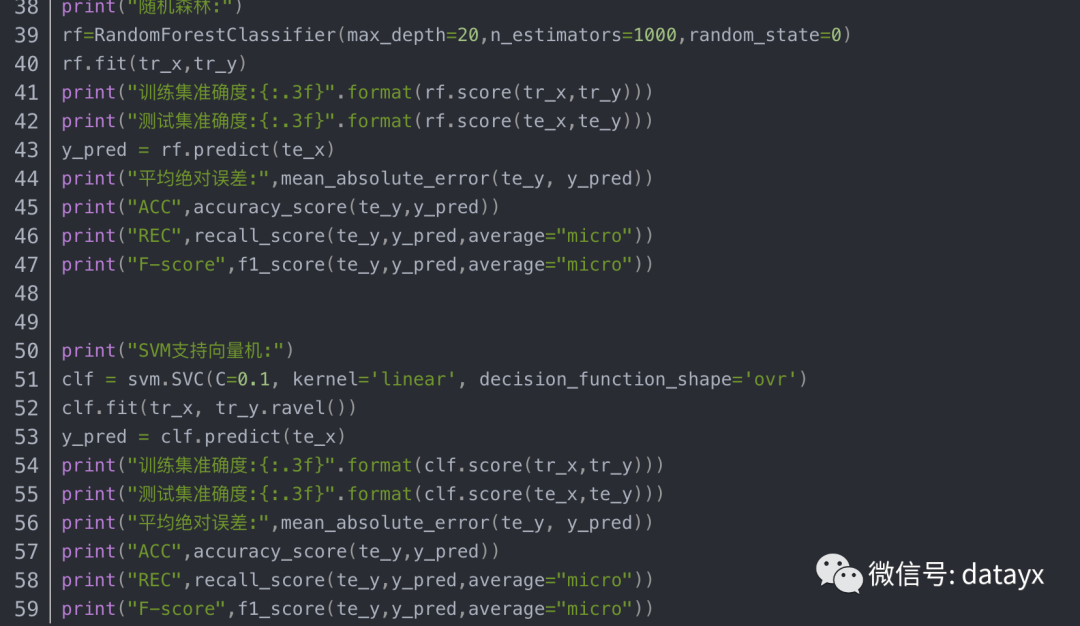
此处使用了神经网络、逻辑回归、支持向量机、决策树、随机森林算法分别进行训练。并输出其在训练集上的准确度、在测试集上的准确度以及平均绝对误差。
此时发现结果并不理想,准确度仅为六成左右。
误差原因分析:
(尝试方法一)分别输出以上机器学习算法的学习曲线:
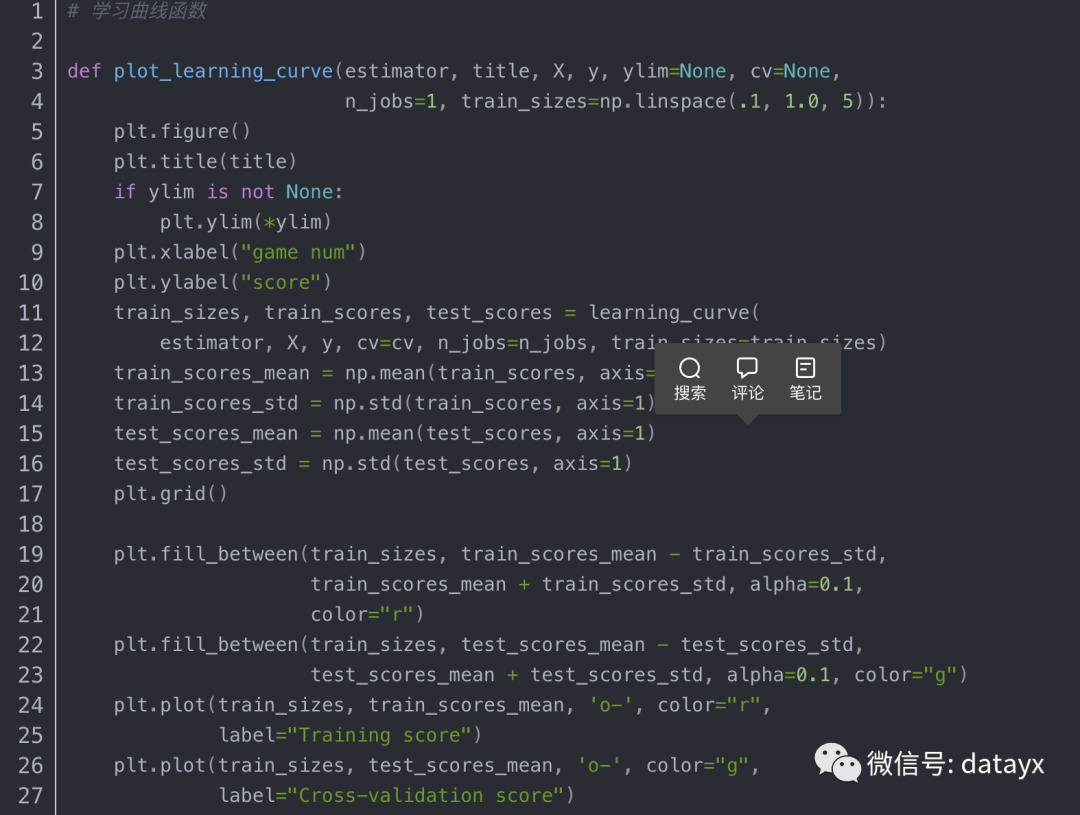
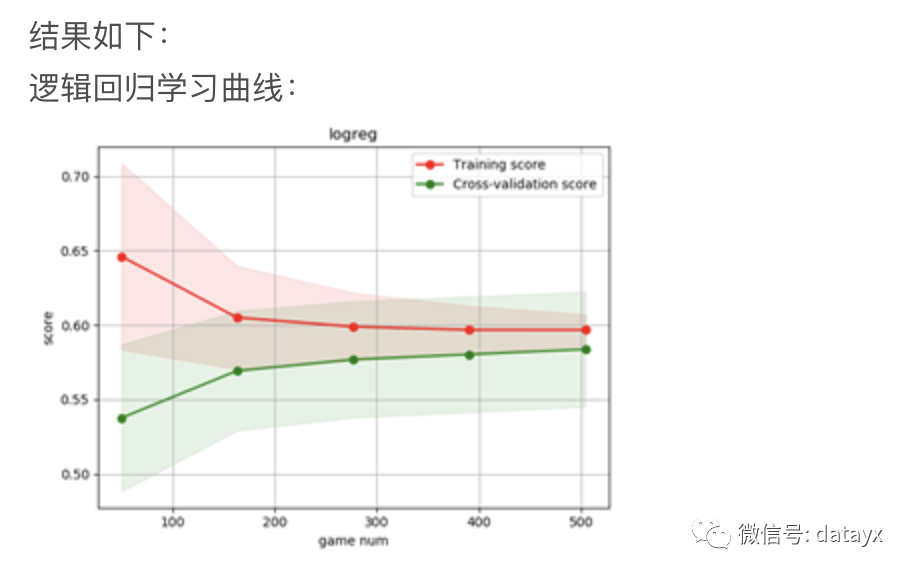
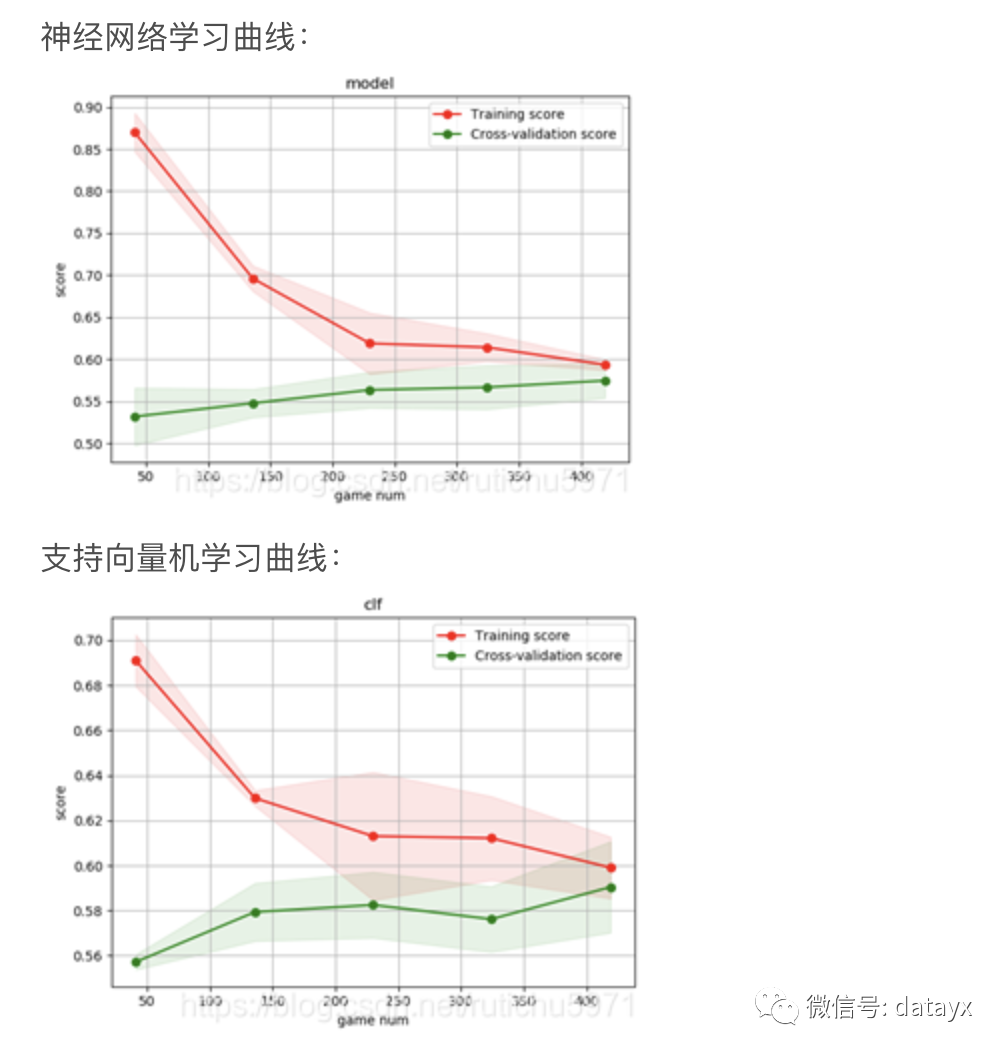
结果图上可以看出,随着数据量的增加,三组模型虽然趋近于收敛,但是在训练集和检验集上准确度表现都很差,仅有0.58左右。这预示着存在着很高的偏差,是欠拟合的表现。
决策树学习曲线:
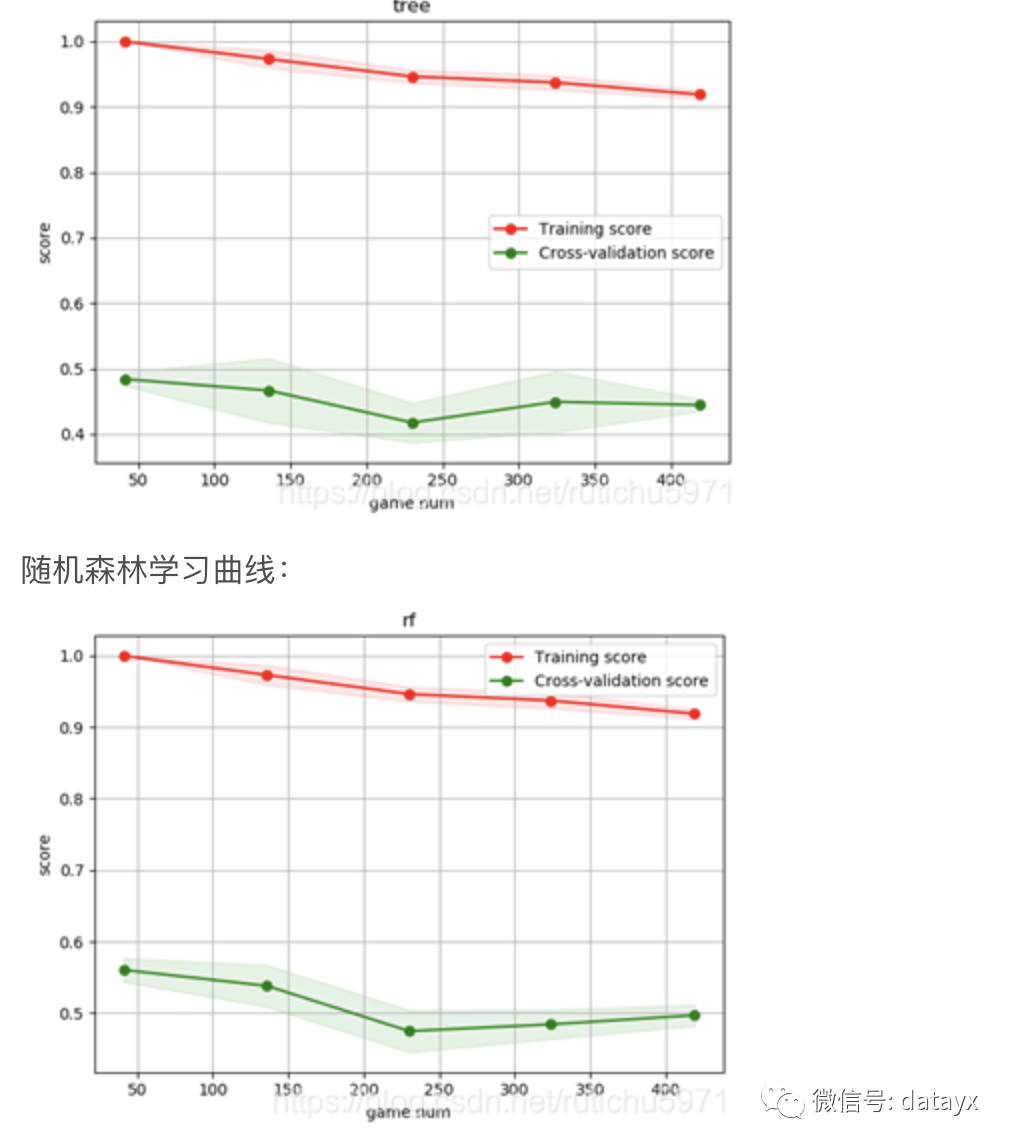
决策树和随机森林出现了高方差情形,也就是过拟合的情况。这都预示着我们要找到正确率低原因,并且优化我们的模型。
(尝试方法二)输出灰色关联矩阵:
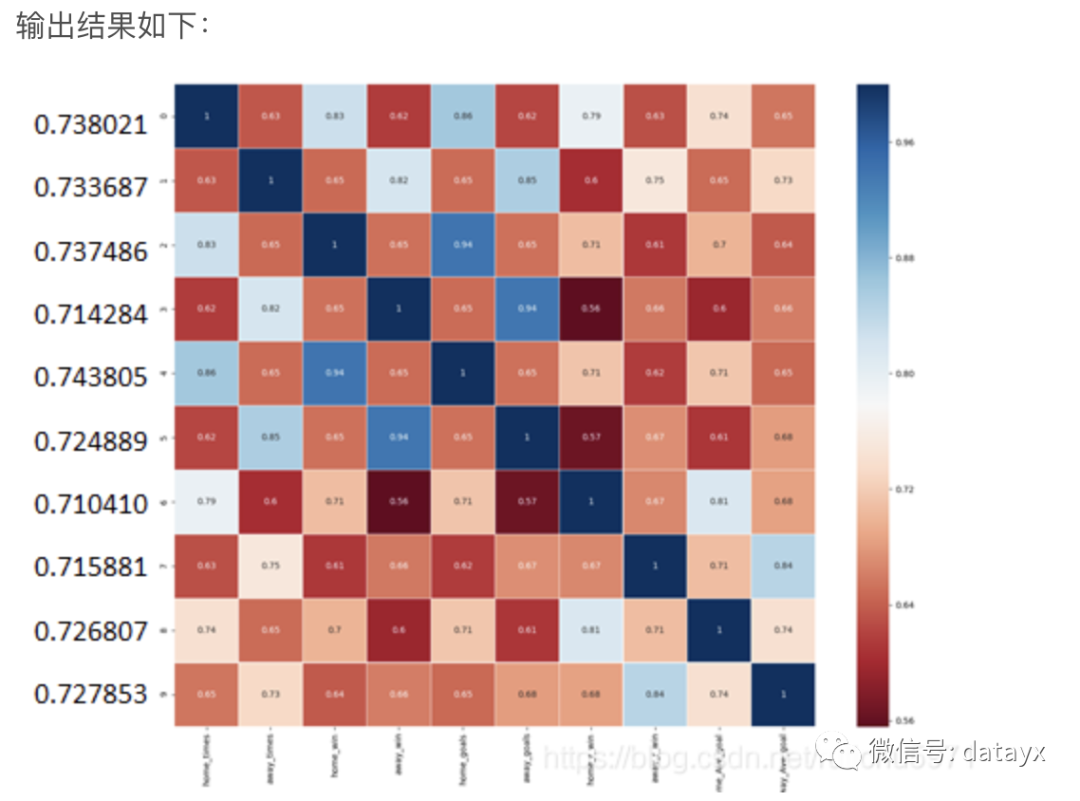
统计出每个特征关联度的均值后,我们发现大部分的特征关联度都在0.738021~0.710410之间,也就是说大部分特征都与结果呈现出了相对较高的关联性。
这也意味着已有的数据源的特征关联度对之前模型的影响是有限的。
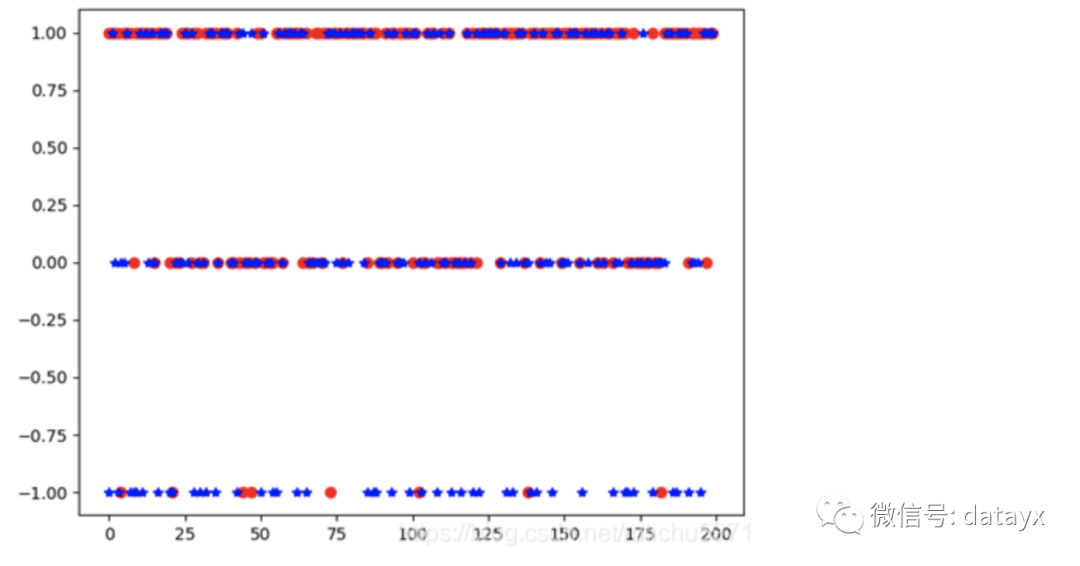
(尝试方法三)以上两种方法进一步缩小了误差原因,于是重新分析测试集与预测结果如图:
测试集:蓝色的*
预测结果:红色的o
发现在预测平局方面,算法预测结果有着较大的误差。于是我们推测由于结果集中的平局拉低了模型的准确度。
进一步查询有关资料发现,我们所使用的决策树算法,随机森林算法,还有逻辑回归,都典型二分类的算法。而此时我们的结果集有三类。
我们重新检查数据源,发现平局的情况仅有199条,而仅凭借着这些较少数据量去很好的训练数据是不合适的。于是我们开始探讨简化结果集即去掉平局结果的可行性。
在充分了解世界杯的规则后,从16强开始,就意味着告别了小组赛,开始了淘汰赛。如遇到平局,就开始加时赛以及点球大战。即比赛结果只有胜负两种结果。而数据集中的比赛结果是将点球大战排除在外的90分钟内的比赛结果。所以含有平局的情况。
模型改良
将play_score_normal.csv中所有的结果集为-1(即平局的数据去掉)
重新采用上述机器学习算法进行训练学习。
训练结果如下:
神经网络:
训练集准确度:0.570
测试集准确度:0.570
平均绝对误差: 0.5740740740740741
逻辑回归:
训练集准确度:0.554
测试集准确度:0.622
平均绝对误差: 0.5296296296296297
决策树:
训练集准确度:0.894
测试集准确度:0.407
平均绝对误差: 0.8074074074074075
随机森林:
训练集准确度:0.894
测试集准确度:0.485
平均绝对误差: 0.7111111111111111
SVM支持向量机:
训练集准确度:0.592
测试集准确度:0.530
平均绝对误差: 0.6222222222222222
由上可见,准确度有了略微的提升,但这还不是我们想要达到的准确度。于是我们继续研究,并尝试使用深度学习算法继续提升模型的准确度。
深度神经网络
于是我们使用了Sequential模型,它是多个网络层的线性堆叠,通过堆叠许多层,构建出深度神经网络。

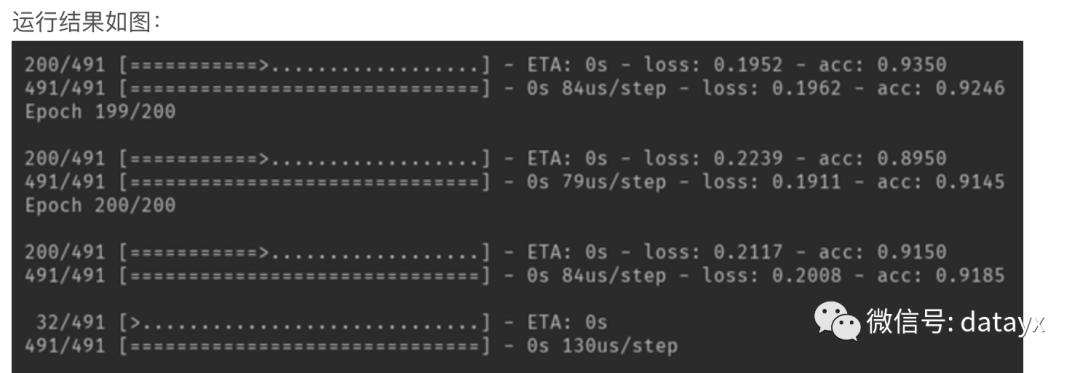
正确率已经能够到达92%。但需要进一步的调参,找到更合适的参数,防止过拟合。
接下来我们暂时用此模型,对世界杯的结果进行模拟预测。
冠军预测
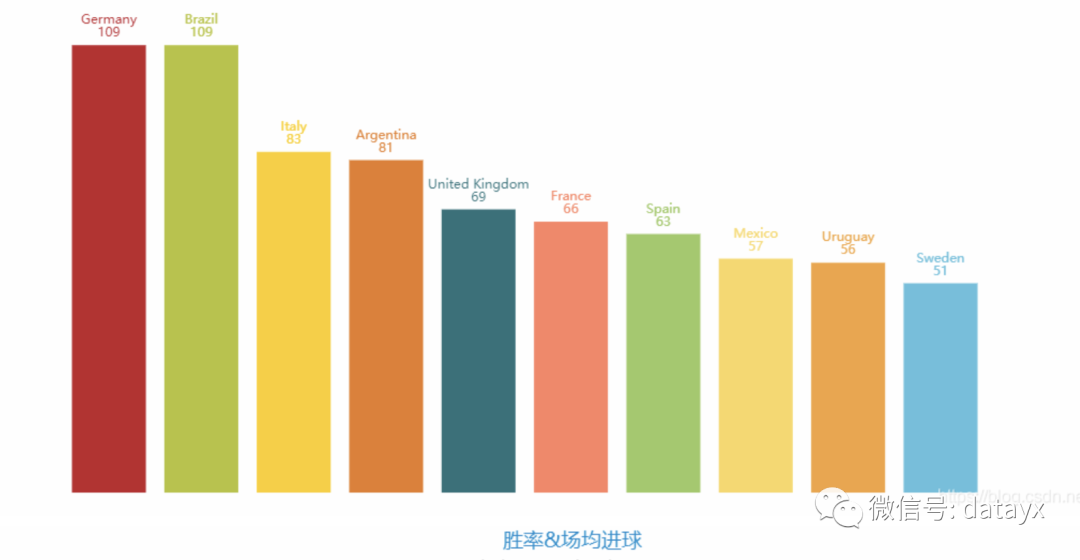
对于2022年的16强队的选择,考虑到近几年球队的数据更能反映出该球队的状态,于是我们统计了近几年(2002-2018)年共5次世界杯进入16强次数最多的队伍。
从16支队伍里面随机选中8支队伍,分为两队:
从数据集里面找到这16支队伍相对应的数据:
比赛的两支队伍的数据进行合并用作待预测数据,并使用深度学习算法进行预测:
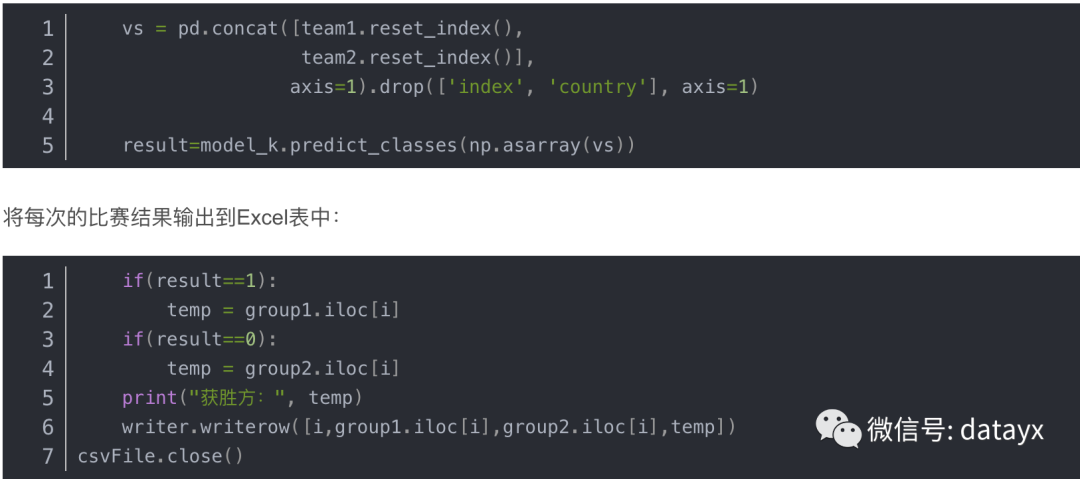
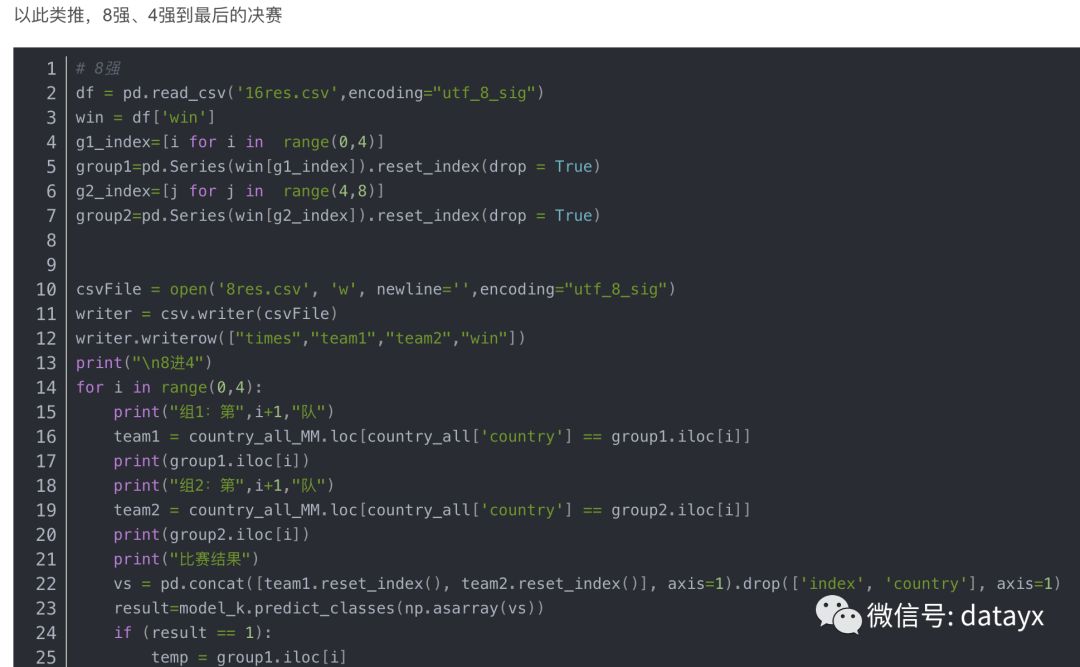
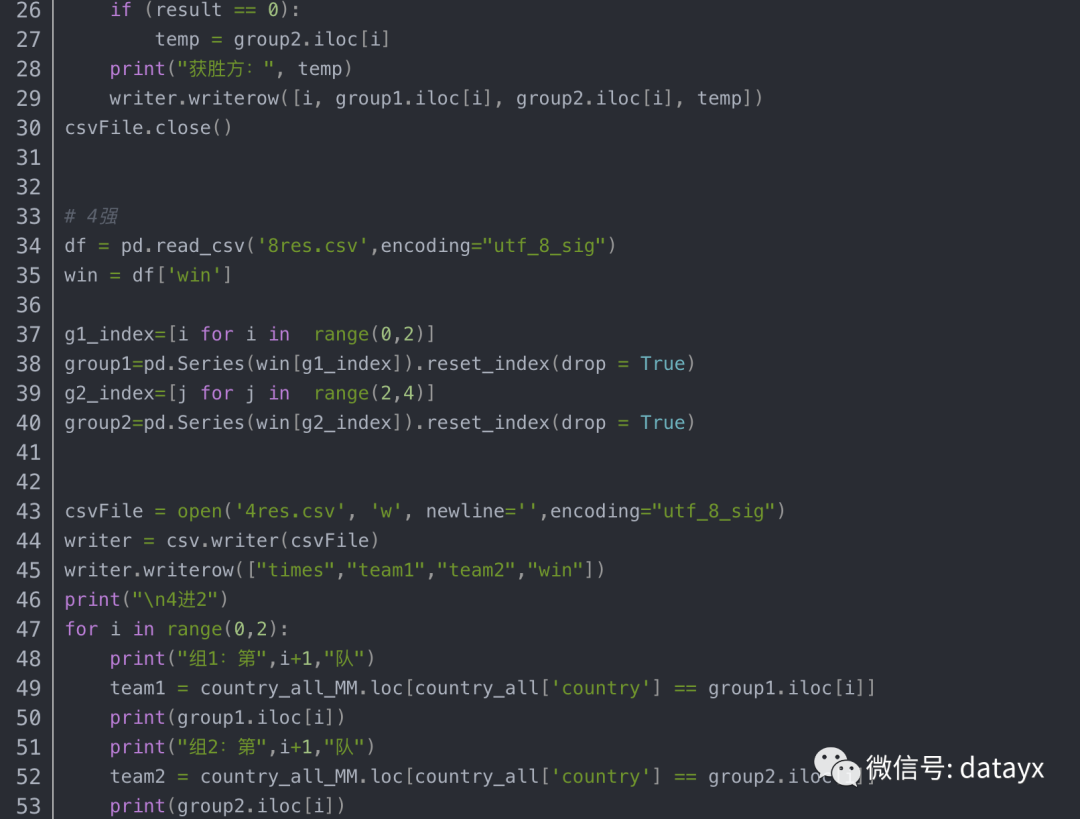

代码+数据集在公众号Python小二后台回复世界杯获取~
以上预测结果仅为参考,原因如下:
1、数据量较少。
2、小组赛是由抽签结果确定的,而且分为了各个地区(如亚洲区、欧州区),抽签的结果无法预测,即每个队伍有特定地区的对手,且是由抽签决定的。
3、本预测结果16强队均为历史上进入16强次数最多的队伍,且比赛时为两两随机比赛,而真正进入世界杯16强队伍中会有很多“黑马”杀入,并且有很多洲际规则需要考虑。
若要真正预测结果,则需等待小组分组结果后,决出16强或32强。这样会比较然后将其球队数据代入,最终决出冠军。
???? Python 毕设实战项目
???? Python 练手必备神器
???? Python 爬虫实战必备神器
最后
以上就是矮小盼望最近收集整理的关于YYDS!用Python预测了世界杯冠军的全部内容,更多相关YYDS内容请搜索靠谱客的其他文章。








发表评论 取消回复