题目要求
1.对你爬取下来的北京二手房数据,进行数据的预处理,并计算:
(1)四个区的平均总价、最高总价、最低总价;
(2)四个区的平均单价、最高单价、最低单价;
(3)按照房屋建成的年份,计算2000年以前、2000-2009.12.31、2010-至今,这三个时间段的平均单价。
2. 处理北京空气质量数据
对HUMI、PRES、TEMP三列,进行线性插值处理。修改cbwd列中值为“cv”的单元格,其值用后项数据填充。
实验环境
1.系统:11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz 2.42 GHz
2.python+ pycharm
实验步骤
1、对北京二手房数据进行预处理,计算相应数据
- 分别求四个区(海淀,朝阳,西城,东城)的平均总(单)价、最高总(单)价、最低总(单)价
- 注:因为步骤相似,本文以海淀区为例子进行阐述;
- 通过spiders爬虫,爬取 https://bj.lianjia.com/ershoufang/haidian/ 中小区名称、总价、房屋面积、房屋单价、房屋构造年份相关数据,存为lianjia-hd.json文件
-

图1 海淀区二手房节选前50条(共3000)
- 对lianjia-hd.json进行处理转换为hd1.csv文件
-
import csv import json def json_to_csv(): json_file = open("lianjia-hd.json", "r",encoding='utf-8') #输入需要转换格式的json文件 csv_file = open("hd1.csv", "w") #转换后的文件名和文件类型 item_list = [] for line in json_file: item_list.append(json.loads(line)) key_data = item_list[0].keys() value_data = [item.values() for item in item_list] # csv文件写入对象 csv_writer = csv.writer(csv_file) # 先写入表头字段数据 csv_writer.writerow(key_data) # 再写入表的值数据 csv_writer.writerows(value_data) csv_file.close() json_file.close() if __name__ == "__main__": json_to_csv() - 读取hd1.csv文件,进行数据处理以及提取需要的值;
-
import pandas as pd import numpy as np #读取hd1.csv文件 df = pd.read_csv('hd1.csv') # 分别提取总价列数据, # 单价列数据 # 两个数组 totprice_hd = np.array(df['totalprice']) Unit_hd = np.array(df['Unitprice']) tot1_hd = [] #总价 uni_hd = [] #单价 # print(_totprice) # #遍历总价数组,将数据有字符串型str变为浮点型float;删除出数字以外的字符; for i in range(len(totprice_hd)): str = totprice_hd[i] pos = str.find("'") pos1 = str.find("万", pos + 1) str1 = str[pos + 1:pos1] tot1_hd.append(float(str1)) #遍历单价数组,将数据有字符串型str变为浮点型float;删除出数字以外的字符; for j in range(len(Unit_hd)): str2 = Unit_hd[j] pos2 = str2.find("'") pos3 = str2.find("元", pos2 + 1) str3 = str2[pos2 + 1:pos3] str4 = str3.replace(',','') #去数据之间的逗号 uni_hd.append(float(str4)) tot1_hd.sort() #对总价数组进行排序 print("总价列表从小到大排序(单位:万):n",tot1_hd) print("海淀区n平均总价:",np.mean(tot1_hd),"万","n最高总价:",tot1_hd[-1],"万","n最低总价:",tot1_hd[0],"万") uni_hd.sort() #对单价数组进行排序 print("单价列表从小到大排序(单位:元/平):n",uni_hd) print("海淀区n平均单价:",np.mean(uni_hd),"元/平","n最高单价:",uni_hd[-1],"元/平","n最低单价:",uni_hd[0],"元/平") - 打印出结果为:
-
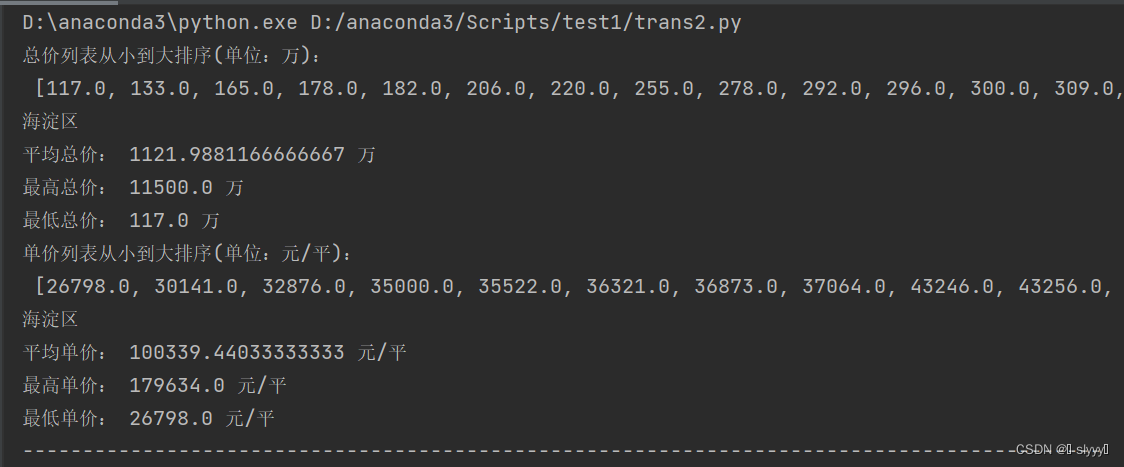
图2 海淀区相关数据
- 由图2可知:海淀区相关数据;
- 同海淀区操作步骤可得朝阳区、西城区、东城区数据如下图:
-
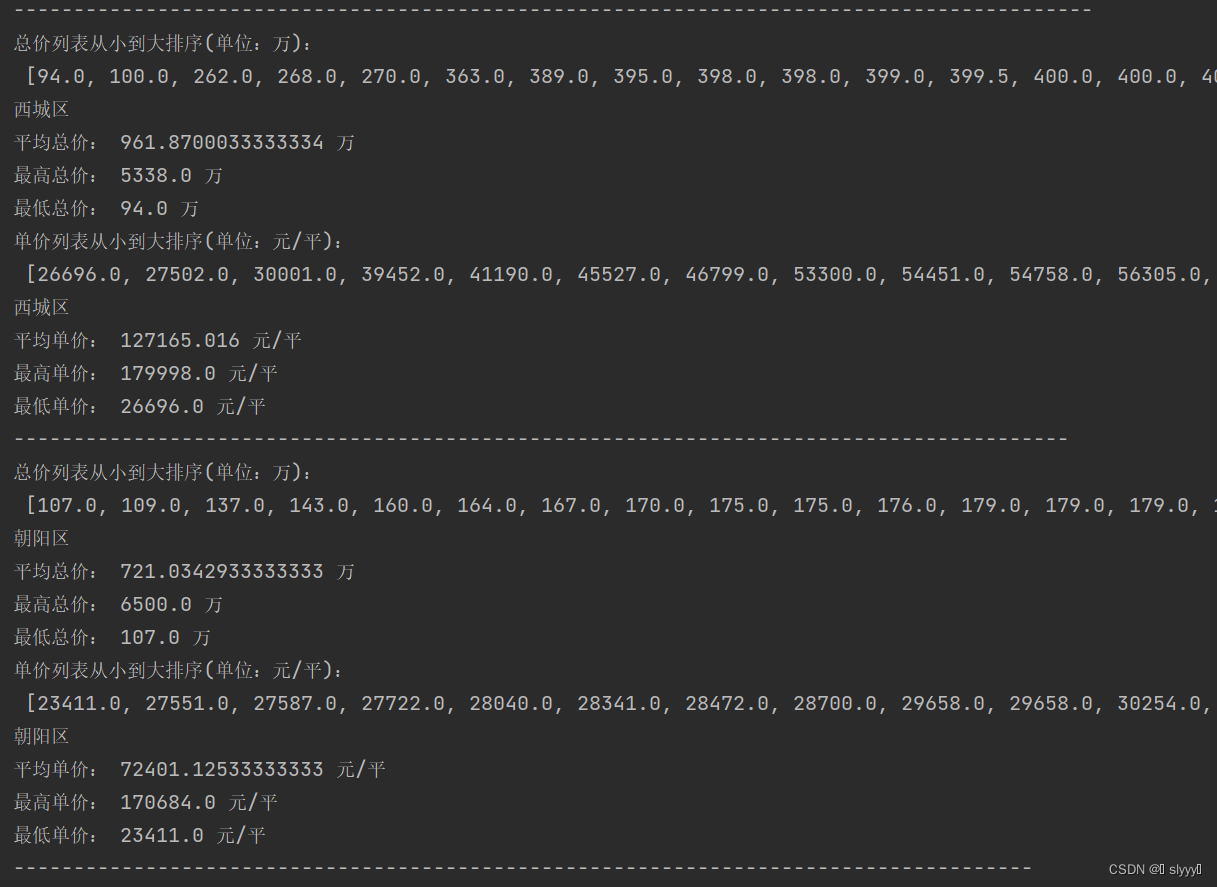
图3 西城区、朝阳区相关数据
-
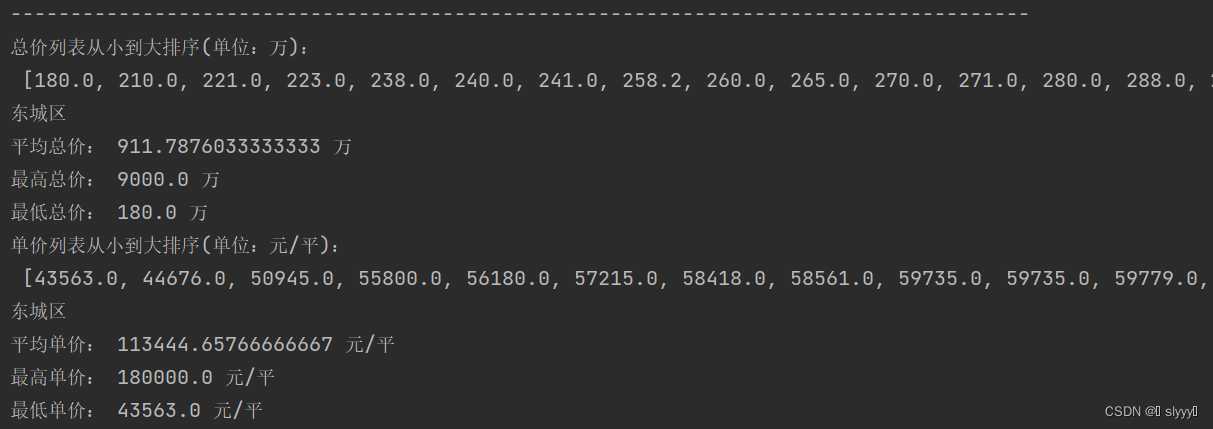
图4 东城区相关数据
- 数据汇总如下图:
-

图5 汇总数据
2、处理北京空气质量数据
- 读取BeijingPM20100101_20151231.csv文件进行处理
-
import pandas as pd print("开始处理数据。") data = pd.read_csv('BeijingPM20100101_20151231.csv',encoding='utf-8') - 对HUMI、PRES、TEMP三列,进行线性插值处理
-
# 对HUMI、PRES、TEMP三列,进行线性插值处理 data['HUMI'] = data['HUMI'].interpolate() data['PRES'] = data['PRES'].interpolate() data['TEMP'] = data['TEMP'].interpolate() - 修改cbwd列中值为“cv”的单元格,其值用后项数据填充
-
# 修改cbwd列中值为“cv”的单元格,其值用后项数据填充。 print("before",len(data[data.cbwd =='cv' ].index.tolist())) for i in reversed(range(len(data))): if data["cbwd"][i] =='cv': data["cbwd"][i] = data["cbwd"][i+1] print("after",len(data[data.cbwd =='cv' ].index.tolist())) - 存为.csv新文件
-
print("处理数据完成") data.to_csv("PM_bj.csv",index=False) - 实验结果与没有处理前的对比(节选)如图6
-
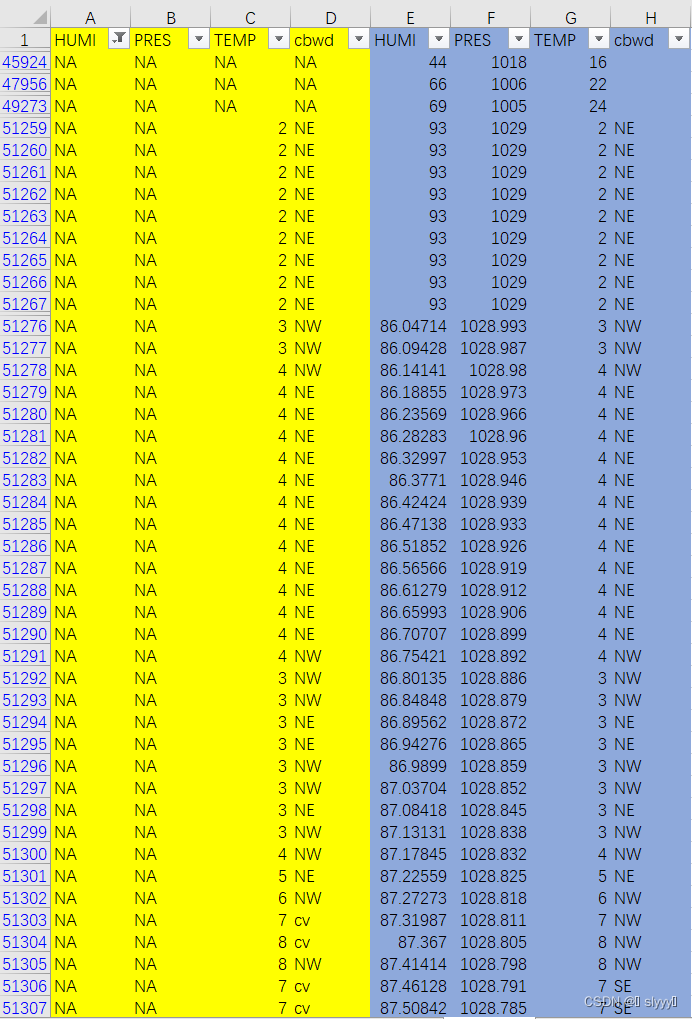
图6 结果对比
实验总结
1、遇到问题
在处理北京二手房数据时遇到问题,一开始不知道如何将列表中数据从str类型转换为float类型;后来通过上网搜索和查找,一步步解决了问题;主要步骤是:整理数据通过find函数将列表中每一项的数字提取,再通过float()强制转换,最后存储到列表中。
2、总结
通过整理数据、对数据进行操作,发现爬虫中将数据从网页上爬取下来是很简单的一个步骤了,对于爬取下来的数据进行清洗的到有用的数据并不是想象中那么简单的,需要对python基础知识有很强的应用能力,所以要学习的还有很多,继续加油吧。
最后
以上就是高高钢笔最近收集整理的关于实验三:数据预处理1题目要求实验环境实验步骤实验总结的全部内容,更多相关实验三内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复