赛题介绍
2020数字中国创新大赛
-
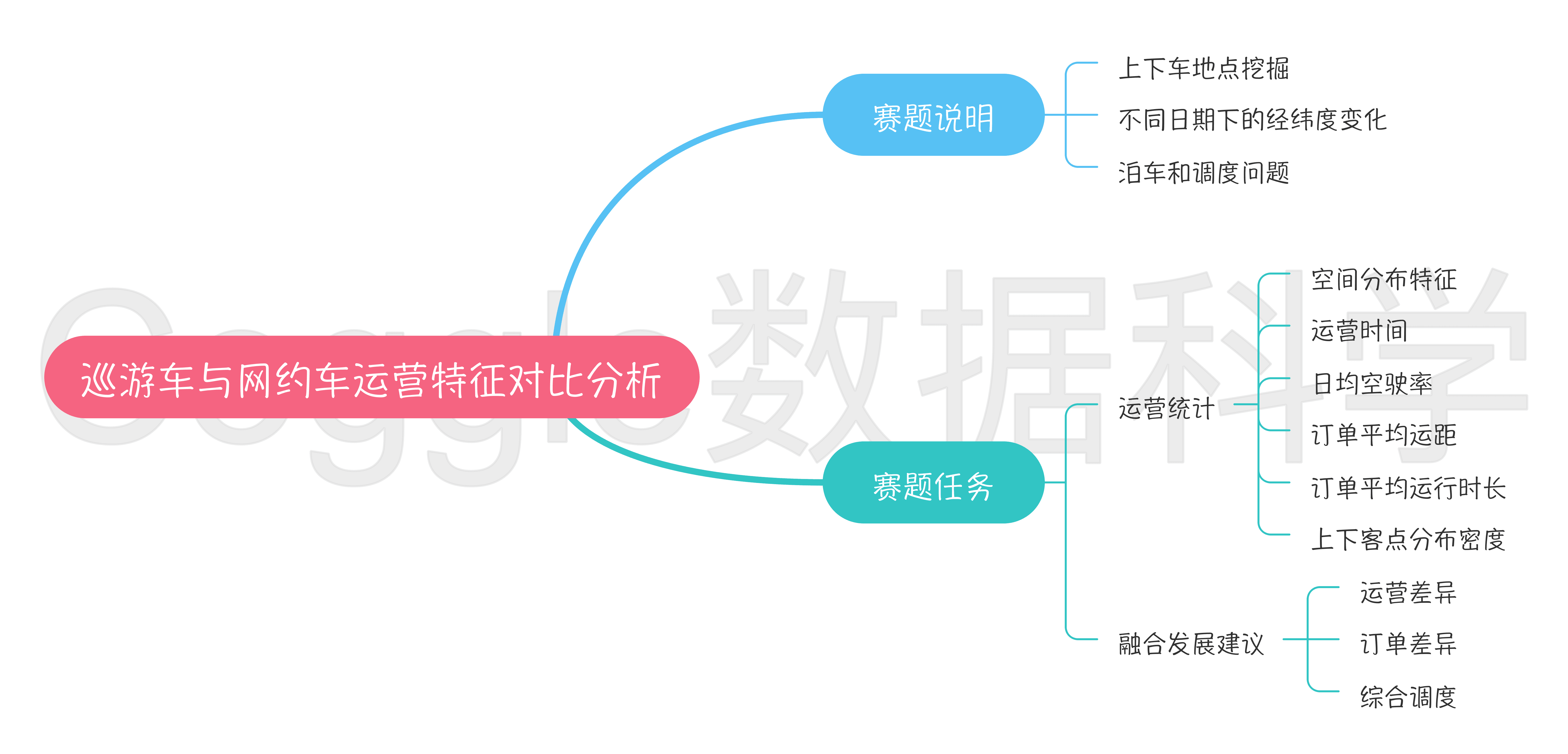
赛题说明
出租车作为城市客运交通系统的重要组成部分,以高效、便捷、灵活等优点深受居民青睐。出租车每天的运营中会产生大量的上下车点位相关信息,对这些数据进行科学合理的关联和挖掘,对比在工作日以及休息日、节假日的出租车数据的空间分布及其动态变化,对出租车候车泊位、管理调度和居民通勤特征的研究具有重要意义。
-
赛题任务
- 综合应用统计分析方法分别对所提供的巡游车和网约车运营的时间、空间分布特征进行量化计算,包括计算2年的每年工作日取日平均,非工作日取日平均和节假日取日平均,三种类型各自平均的时变分布变化,三种时间类型按网格划分的平均空间分布(网格划分颗粒度选手自选),并分别对比分析所提供的网约车、巡游车,计算2年每年按工作日取日平均,非工作日取日平均和节假日取日平均三种类型的日均空驶率、订单平均运距、订单平均运行时长、上下客点分布密度等时变特性。
- 根据巡游车和网约车的时空运营特征,并尝试对巡游车与网约车的融合发展提出相关建议。在分析过程,参赛者必须用到但不局限于提供的数据,可自行加入自有数据进行参赛,但需说明自带数据来源并保证数据合法合规使用。
-
赛题数据
- A城市路网矢量数据
- ROAD_ID:编号
- ROAD_NAME:路网名称
- A城市巡游车GPS数据
- CARNO:车牌号
- SPEED:GPS速度
- DIRECTION:行驶方向角
- GPS_DATE:卫星定位时间
- LONGITUDE:经度(WGS84 GPS标准)
- LATITUDE:纬度(WGS84 GPS标准)
- RUNNING_STATUS/OPERATING_STATUS: 运营状态(空车(1)、载客(2)、电召(4)、停运(8)、交班(16)、包车(32))
- A城市网约车GPS数据
- CARNO:车牌号
- POSITION_TIME:定位时间
- LONGITUDE:经度
- LATITUDE:纬度
- ENCRYPT:坐标系(1:GCJ-02标准;2:WGS84 GPS标准;3:BD-09 百度标准;4:CGCS2000 北斗标准0:其他)
- DIRECTION:行驶方向角
- SPEED:GPS速度
- BIZ_STATUS:运营状态(1:载客2:接单3:空驶 4:停运)
- ORDER_ID:订单号
- A城市巡游车订单数据
- CAR_NO:车牌号
- GETON_DATE:上车时间
- GETON_LONGITUDE:上车经度(WGS84 GPS标准)
- GETON_LATITUDE:上车纬度(WGS84 GPS标准)
- GETOFF_DATE:下车时间
- GETOFF_LONGITUDE:下车经度(WGS84 GPS标准)
- GETOFF_LATITUDE:下车纬度(WGS84 GPS标准)
- PASS_MILE:计程公里
- NOPASS_MILE:空驶公里
- WAITING_TIME:等待计时时间
- A城市网约车订单数据
- ORDER_ID:订单编号
- ON_AREA:上车位置行政区划编号
- CAR_NO:车辆号牌
- BOOK_DEP_TIME:预计上车时间
- WAIT_TIME:等待时间
- DEP_LONGITUDE:车辆出发经度(默认高德标准、GCJ-02标准,不排除部分坐标系有异常,需选手在图上作区分)
- DEP_LATITUDE:车辆出发纬度(默认高德标准、GCJ-02标准,不排除部分坐标系有异常,需选手在图上作区分)、DEP_TIME:上车时间、 DEST_LONGITUDE:车辆到达经度(默认高德标准、GCJ-02标准,不排除部分坐标系有异常,需选手在图上作区分)
- DEST_LATITUDE:车辆到达纬度(默认高德标准、GCJ-02标准,不排除部分坐标系有异常,需选手在图上作区分)
- DEST_TIME:下车时间
- DRIVE_MILE:载客里程(公里)
- DRIVE_TIME:载客时间(秒)
- WAIT_MILE:空驶里程(公里)
- ORDER_MATCH_TIME:订单完成时间
- A城市路网矢量数据
可以看出:
- 巡游车的数据较为规范,网约车的数据在某些字段上(如 ENCRYPT)不统一,可能需要转换为统一的数据
- 巡游车与网约车的大部分字段相同,存在少数不相同的字段
- 官网上给出的数据按照日期分成了多个文件,在分析时间变化趋势的时候需要进行合并
赛题分析
-
每年工作日取日平均,非工作日取日平均和节假日取日平均,三种情况下出租车&网约车:
- 运营时间规律:出车时间和运行时间
- 空间分布规律:城市分布规律,订单分布规律
- 日均空驶率:空驶里程(没有载客)在车辆总运行里程中所占的比例
- 订单平均运距:订单平均距离计算
- 订单平均运行时长:订单平时时长计算
- 上下客点分布密度:上下车位置分布
-
对出租车&网约车的调度、融合发展提出建议:
- 如何进行订单调度,识别打不到车的位置
- 如何进行停车场推荐
- 订单差异性分析
准备工作
数据分析简介
数据分析是指用适当的统计分析方法对收集来的大量数据进行分析,将它们加以汇总和理解并消化,以求最大化地开发数据的功能,发挥数据的作用。数据分析是为了提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。
数据也称为观测值,是实验、测量、观察、调查等的结果。在我们日常生活中所有的观测值都是数据,可以拿来进行分析。需要注意的是,数据分析是有目的的、有步骤的和有结果的行为。
数据分析的具体步骤可分为数据处理与统计和数据可视化,在现有的工具中都或多或少包含上述两种功能。对于数据处理与统计,基本上所有可以完成基本计算的软件都可以用来进行统计。
数据统计的关键指标包括:
-
均值、中位数、众数体现了数据的集中趋势
-
极差、方差、标准差体现了数据的离散程度
-
偏度、峰度体现了数据的分布形状
注:标准差等于方差开根号,标准差和均值的量纲(单位)是一致的,在描述一个波动范围时标准差比方差更方便。
数据分析软件

数据类型与可视化方法
我们日常生活中充满了各类数据,也有多种数据类型划分方法:
- 定性数据与定量数据
- 数据类型划分:可以将统计数据分为布尔型、类别型、数值型和日期型数据
不同类型的数据会有不同的数据存储方法和统计方法,也需要不同类型的可视化方法来完成。
参考资料:
- https://datavizcatalogue.com/index.html
- https://python-graph-gallery.com/
数据分析流程
- 明确分析目的和思路
- 收集数据
- 数据统计处理
- 数据分析与可视化
- 撰写报告
描述型数据分析
描述性数据分析(Descriptive Data Analysis,DDA)属于比较初级的数据分析,常见的分析方法包括对比分析法、平均分析法、交叉分析法等。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形。
- 集中趋势的描述性统计量
- 均值:是指一组数据的算术平均数,描述一组数据的平均水平,是集中趋势中波动最小、最可靠的指标,但是均值容易受到极端值(极小值或极大值)的影响。
- 中位数:是指当一组数据按照顺序排列后,位于中间位置的数,不受极端值的影响,对于定序型变量,中位数是最适合的表征集中趋势的指标。
- 众数:是指一组数据中出现次数最多的观测值,不受极端值的影响,常用于描述定性数据的集中趋势。
- 离散程度的描述性统计量
- 最大值和最小值:是一组数据中的最大观测值和最小观测值
- 极差:又称全距,是一组数据中的最大观测值和最小观测值之差,记作R,一般情况下,极差越大,离散程度越大,其值容易受到极端值的影响。
- 方差和标准差:是描述一组数据离散程度的最常用、最适用的指标,值越大,表明数据的离散程度越大。
- 分布形态的描述性统计量
- 偏度:用来评估一组数据的分布呈先的对称程度,当偏度=0时,分布是对称的;当偏度>0时,分布呈正偏态;当偏度<0时,分布呈负偏态。
探索型数据分析
探索性数据分析(Exploratory Data Analysis,EDA)主要的工作是:对数据进行清洗,对数据进行描述(描述统计量,图表),查看数据的分布,比较数据之间的关系,培养对数据的直觉,对数据进行总结等。
探索性数据分析(EDA)与传统统计分析(Classical Analysis)的区别:
传统的统计分析方法通常是先假设样本服从某种分布,然后把数据套入假设模型再做分析。但由于多数数据并不能满足假设的分布,因此,传统统计分析结果常常不能让人满意。
探索性数据分析方法注重数据的真实分布,强调数据的可视化,使分析者能一目了然看出数据中隐含的规律,从而得到启发,以此帮助分析者找到适合数据的模型。“探索性”是指分析者对待解问题的理解会随着研究的深入不断变化。
应用传统统计分析方法的数据分析步骤:
应用探索性数据分析方法的数据分析步骤:
验证型数据分析
验证型数据分析(Confirmatory Data Analysis, CDA)根据数据样本所提供的证据,肯定还是否定有关总体的声明。
假设验证的基本流程:
-
提出零假设(我们希望推翻的结论),及备择假设(我们希望证明的结论)
-
在零假设的前提下,推断目前样本统计量出现的概率 * 统计量可符合不同分布,即对应不同的检验方法
-
设定一个拒绝零假设的阈值(常见5%,及统计学意义“显著”,significant),如果目前样本统计量在零假设下出现的概率小于阈值,则拒绝零假设,承认备择假设。
Python环境下的数据分析
- Python 基础:语法、网络编程基础、爬虫
- Pandas、Numpy 等数据处理软件
- Matplotlib、Searborn 和 folium 等数据可视化软件
参考资料:
- Introduction to Numpy
- joyful-pandas
- hands-on-data-analysis
- EDA介绍
最后
以上就是单纯橘子最近收集整理的关于A城市巡游车与网约车运营特征对比分析—赛题介绍与准备工作赛题介绍准备工作的全部内容,更多相关A城市巡游车与网约车运营特征对比分析—赛题介绍与准备工作赛题介绍准备工作内容请搜索靠谱客的其他文章。








发表评论 取消回复